CVPR 2023 | 主干网络FasterNet 核心解读 代码分析
本文分享来自CVPR 2023的论文,提出了一种快速的主干网络,名为FasterNet。
论文提出了一种新的卷积算子,partial convolution,部分卷积(PConv),通过减少冗余计算和内存访问来更有效地提取空间特征。
创新在于部分卷积(PConv),它选择一部分通道的特性进行常规卷积,剩余部分通道的特性保持不变,降低了计算复杂度,从而实现了快速高效的神经网络。
区别于常规卷积:PConv只对输入通道的一部分应用卷积,而保留其余部分不变。
论文地址:Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
代码地址:https://github.com/JierunChen/FasterNet/tree/master
目录
一、PConv算子设计原理
二、PConv算子的代码解析
三、FasterNet模型原理
四、FasterNet模型测试
五、实验分析
背景:
- MobileNet、ShuffleNet和GhostNet等利用深度卷积(DWConv)或 组卷积(GConv)来提取空间特征。
- 然而,在减少FLOPs的过程中,算子经常会受到内存访问增加的副作用的影响。
- MicroNet进一步分解和稀疏网络,将其FLOPs推至极低水平。尽管这种方法在FLOPs方面有所改进,但其碎片计算效率很低。
- 上述网络通常伴随着额外的数据操作,如级联、Shuffle和池化,这些操作的运行时间对于小型模型来说往往很重要。
一、PConv算子设计原理
1、这种部分卷积的核心思想是对输入特征图的部分通道应用卷积操作,而保留其他通道不变。这种操作可以有效地减少计算冗余,提高计算效率。

对于连续或规则的内存访问,将第一个或最后一个连续的通道视为整个特征图的代表进行计算。
在不丧失一般性的情况下认为输入和输出特征图具有相同数量的通道。
设计原因
通过利用特征图的冗余度可以进一步优化成本。
如下图所示,特征图在不同通道之间具有高度相似性。许多其他著作也涵盖了这种冗余,但很少有人以简单而有效的方式充分利用它。

于是出了PConv,对输入特征图的部分通道应用卷积操作,而保留其他通道不变,同时减少计算冗余和内存访问。
2、为了充分有效地利用来自所有通道的信息,进一步将逐点卷积(PWConv)附加到PConv。
它们在输入特征图上的有效感受野看起来像一个T形Conv,与均匀处理补丁的常规Conv相比,它更专注于中心位置。
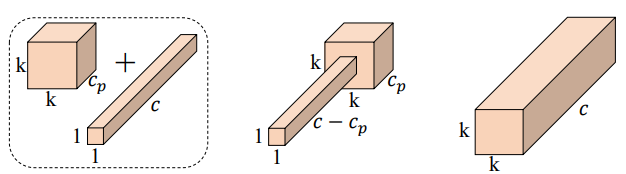
通过实验表明:中心位置是卷积操作中最常见的突出位置,即中心位置的权重比周围的更重。这与集中于中心位置的T形计算一致。
虽然T形卷积可以直接用于高效计算,但作者表明,将T形卷积分解为PConv和PWConv更好,因为该分解利用了卷积操作间冗余并进一步节省了FLOPs。
二、PConv算子的代码解析
PConv算子的代码:
'''
输入三个参数:dim(输入特征图的通道数),n_div(分割的组数)和forward(前向传播的方法)
输出:卷积后的特征图
'''
class Partial_conv3(nn.Module):def __init__(self, dim, n_div, forward):super().__init__()self.dim_conv3 = dim // n_div # 计算出卷积部分的通道数self.dim_untouched = dim - self.dim_conv3 # 计算出不需要卷积部分的通道数# 定义一个3*3卷积,输入通道数为self.dim_conv3,输出通道数也为self.dim_conv3,步长为1,填充为1,且不使用bias。self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)if forward == 'slicing':self.forward = self.forward_slicingelif forward == 'split_cat':self.forward = self.forward_split_catelse:raise NotImplementedError# 只适合推理def forward_slicing(self, x: Tensor) -> Tensor:# 对输入x进行深拷贝,以保持原始输入的完整性。后面的操作不会改变原始输入x。x = x.clone() # 对输入x中前self.dim_conv3个通道应用卷积操作,并将结果保存回x中对应的位置。x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])return x# 适合训练/推理def forward_split_cat(self, x: Tensor) -> Tensor:# 使用torch.split函数将输入x沿着通道维度(即第1维,索引从0开始)分割成两个部分,# 分别为x1和x2。分割的长度为[self.dim_conv3, self.dim_untouched],# 即分割后的x1的通道数为self.dim_conv3,x2的通道数为self.dim_untouched。x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)x1 = self.partial_conv3(x1)x = torch.cat((x1, x2), 1)return x
这段代码定义了一个名为 Partial_conv3 的 PyTorch 模块,它是nn.Module的子类。这个模块主要实现了一种部分卷积(Partial Convolution);
这种部分卷积的核心思想是对输入特征图的部分通道应用卷积操作,而保留其他通道不变。这种操作可以有效地减少计算冗余,提高计算效率。
方式1:slicing
# 只适合推理def forward_slicing(self, x: Tensor) -> Tensor:# 对输入x进行深拷贝,以保持原始输入的完整性。后面的操作不会改变原始输入x。x = x.clone() # 对输入x中前self.dim_conv3个通道应用卷积操作,并将结果保存回x中对应的位置。x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])return x方式2:split_cat
# 适合训练/推理def forward_split_cat(self, x: Tensor) -> Tensor:# 使用torch.split函数将输入x沿着通道维度(即第1维,索引从0开始)分割成两个部分,# 分别为x1和x2。分割的长度为[self.dim_conv3, self.dim_untouched],# 即分割后的x1的通道数为self.dim_conv3,x2的通道数为self.dim_untouched。x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)x1 = self.partial_conv3(x1)x = torch.cat((x1, x2), 1)return x三、FasterNet模型原理
基于部分卷积算子PConv和逐点卷积PWConv,作为主要的算子,进一步提出FasterNet。
这是一个新的神经网络家族,运行速度非常快,对许多视觉任务有效。模型架构如下:
它有4个层次级,每个层次级前面都有一个嵌入层(步长为4的常规4×4卷积)或一个合并层(步长为2的常规2×2卷积),用于空间下采样和通道数量扩展。每个阶段都有一堆FasterNet块。
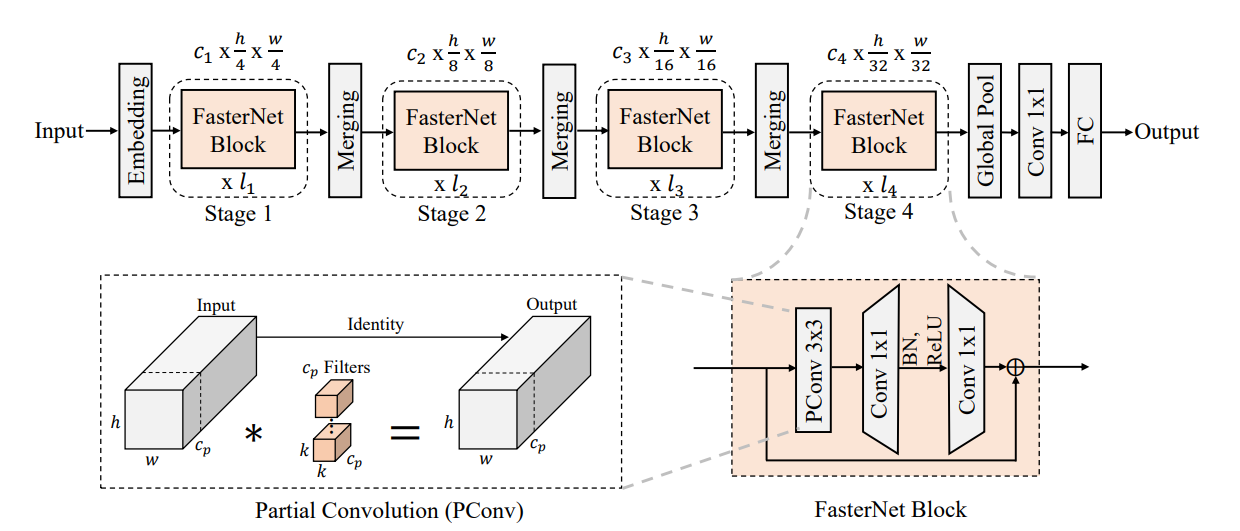
每个FasterNet块有一个PConv层,后跟2个PWConv(或Conv 1×1)层。它们一起显示为倒置残差块,其中中间层具有扩展的通道数量,并且放置了Shorcut以重用输入特征。
最后两个阶段中的块消耗更少的内存访问,并且倾向于具有更高的FLOPS,因此,放置了更多FasterNet块,并相应地将更多计算分配给最后两个阶段。
补充一下标准化和激活层:
标准化和激活层对于高性能神经网络也是不可或缺的。
然而,许多先前的工作在整个网络中过度使用这些层,这可能会限制特征多样性,从而损害性能。它还可以降低整体计算速度。
相比之下,只将它们放在每个中间PWConv之后,以保持特征多样性并实现较低的延迟。
四、FasterNet模型测试
使用默认的参数构建FasterNet
mlp_ratio=2.0,
embed_dim=96,
depths=(1, 2, 8, 2),
drop_path_rate=0.10,
看一下的模型参数 :
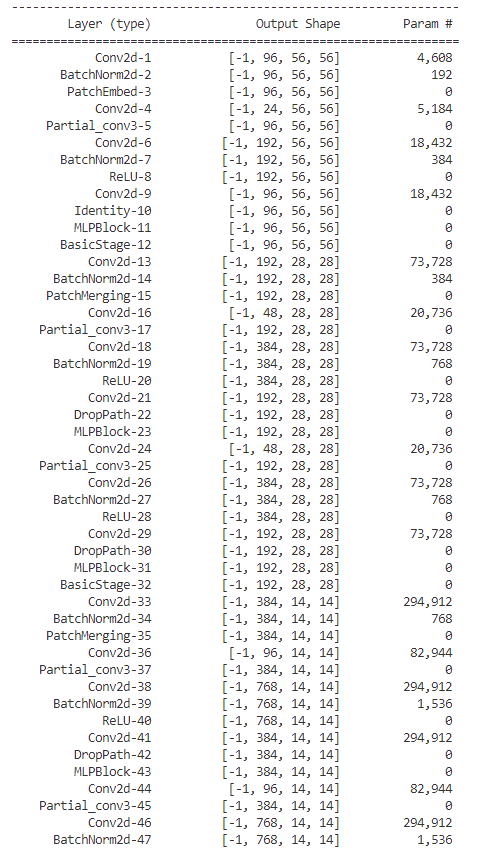
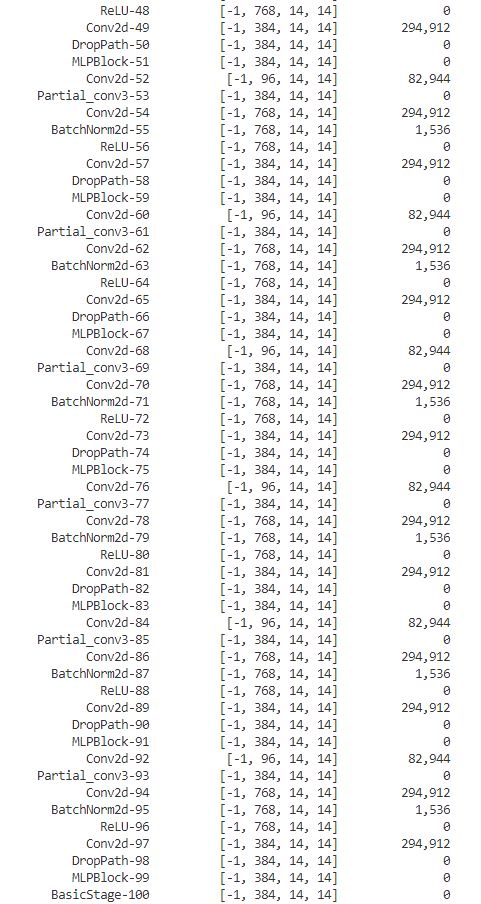
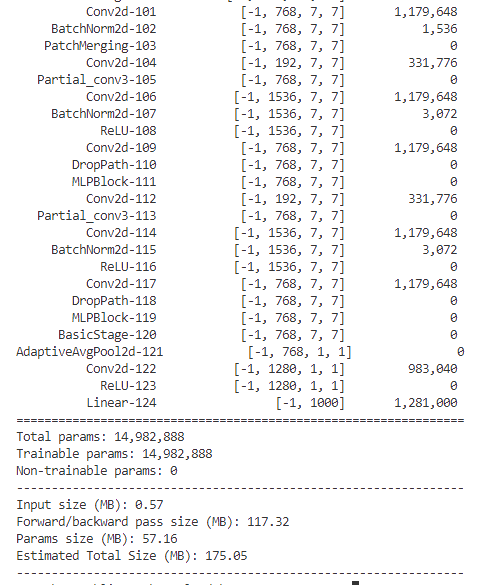
感觉模型也不小的。。。。。。。
测试代码分享给大家(代码存放路径:models/model_summary.py)
import torch.nn as nn
from fasternet import FasterNet
from torchsummary import summary# 默认参数
def fasternet(**kwargs):model = FasterNet(**kwargs)return model# S
def fasternet_s(**kwargs):model = FasterNet(mlp_ratio=2.0,embed_dim=128,depths=(1, 2, 13, 2),drop_path_rate=0.15,act_layer='RELU',fork_feat=True,**kwargs)return model# M
def fasternet_m(**kwargs):model = FasterNet(mlp_ratio=2.0,embed_dim=144,depths=(3, 4, 18, 3),drop_path_rate=0.2,act_layer='RELU',fork_feat=True,**kwargs)return model# L
def fasternet_l(**kwargs):model = FasterNet(mlp_ratio=2.0,embed_dim=192,depths=(3, 4, 18, 3),drop_path_rate=0.3,act_layer='RELU',fork_feat=True,**kwargs)return modelprint("fasternet:", fasternet)
model = fasternet()
summary(model, input_size=(3, 224, 224))print("fasternet_s:", fasternet_s)
model = fasternet_s()
summary(model, input_size=(3, 224, 224))print("fasternet_m:", fasternet_m)
model = fasternet_m()
summary(model, input_size=(3, 224, 224))print("fasternet_l:", fasternet_l)
model = fasternet_l()
summary(model, input_size=(3, 224, 224))
github有各个版本的预训练模型,大家可以测试一下。
| name | resolution | acc | #params | FLOPs | model |
|---|---|---|---|---|---|
| FasterNet-T0 | 224x224 | 71.9 | 3.9M | 0.34G | model |
| FasterNet-T1 | 224x224 | 76.2 | 7.6M | 0.85G | model |
| FasterNet-T2 | 224x224 | 78.9 | 15.0M | 1.90G | model |
| FasterNet-S | 224x224 | 81.3 | 31.1M | 4.55G | model |
| FasterNet-M | 224x224 | 83.0 | 53.5M | 8.72G | model |
| FasterNet-L | 224x224 | 83.5 | 93.4M | 15.49G | model |
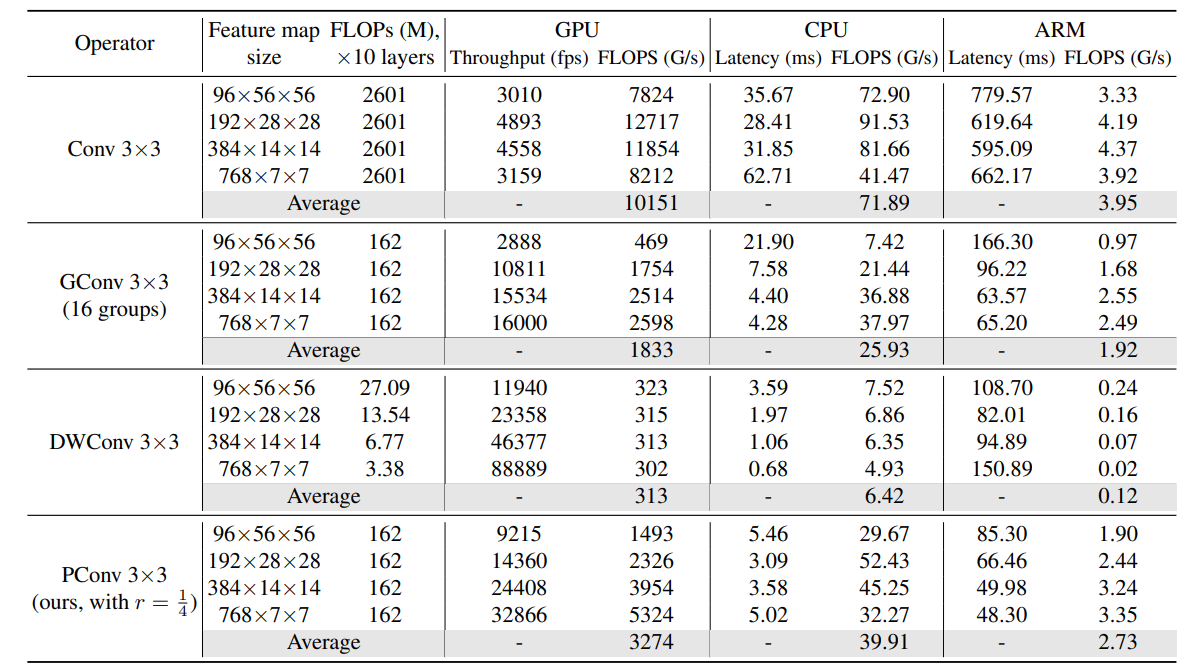
官方给的数据:
五、实验分析
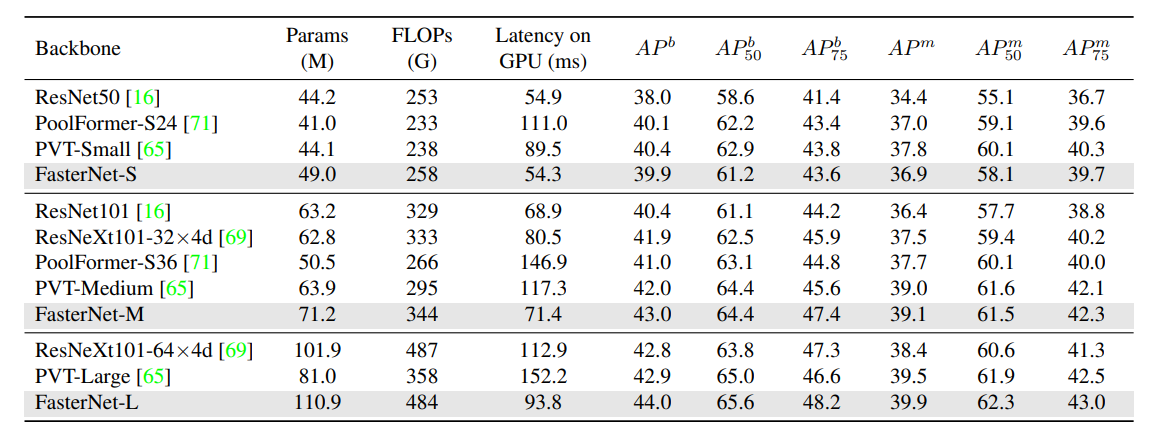
FasterNet在不同设备(CPU、GPU、ARM),精度-吞吐量和精度-延迟权衡方面具有最高的效率。

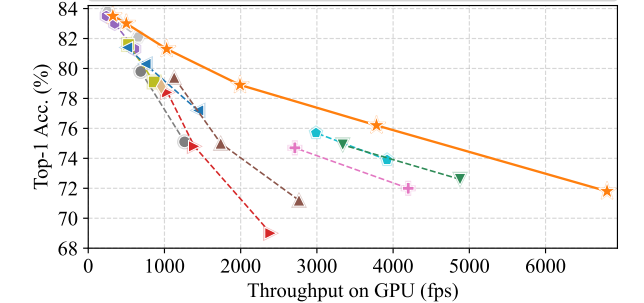

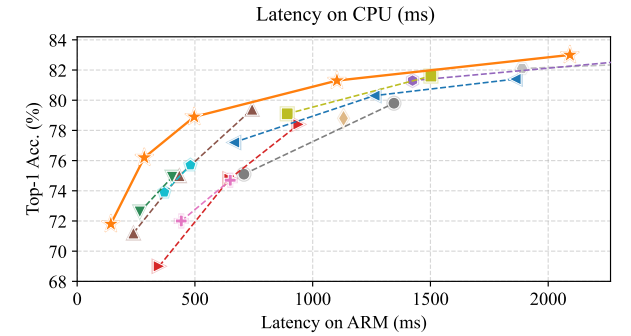
图像分类中,比较ImageNet-1k基准。具有类似TOP-1精度的模型被组合在一起。除MobileViT和EdgeNeXt的分辨率为256×256外,所有型号的分辨率均为224×224。OOM是内存不足的缩写。


关于COCO目标检测和实例分割基准的结果,Flop是根据图像大小(1280,800)计算的。
分享完成~
相关文章:
CVPR 2023 | 主干网络FasterNet 核心解读 代码分析
本文分享来自CVPR 2023的论文,提出了一种快速的主干网络,名为FasterNet。 论文提出了一种新的卷积算子,partial convolution,部分卷积(PConv),通过减少冗余计算和内存访问来更有效地提取空间特征。 创新在于部分卷积…...
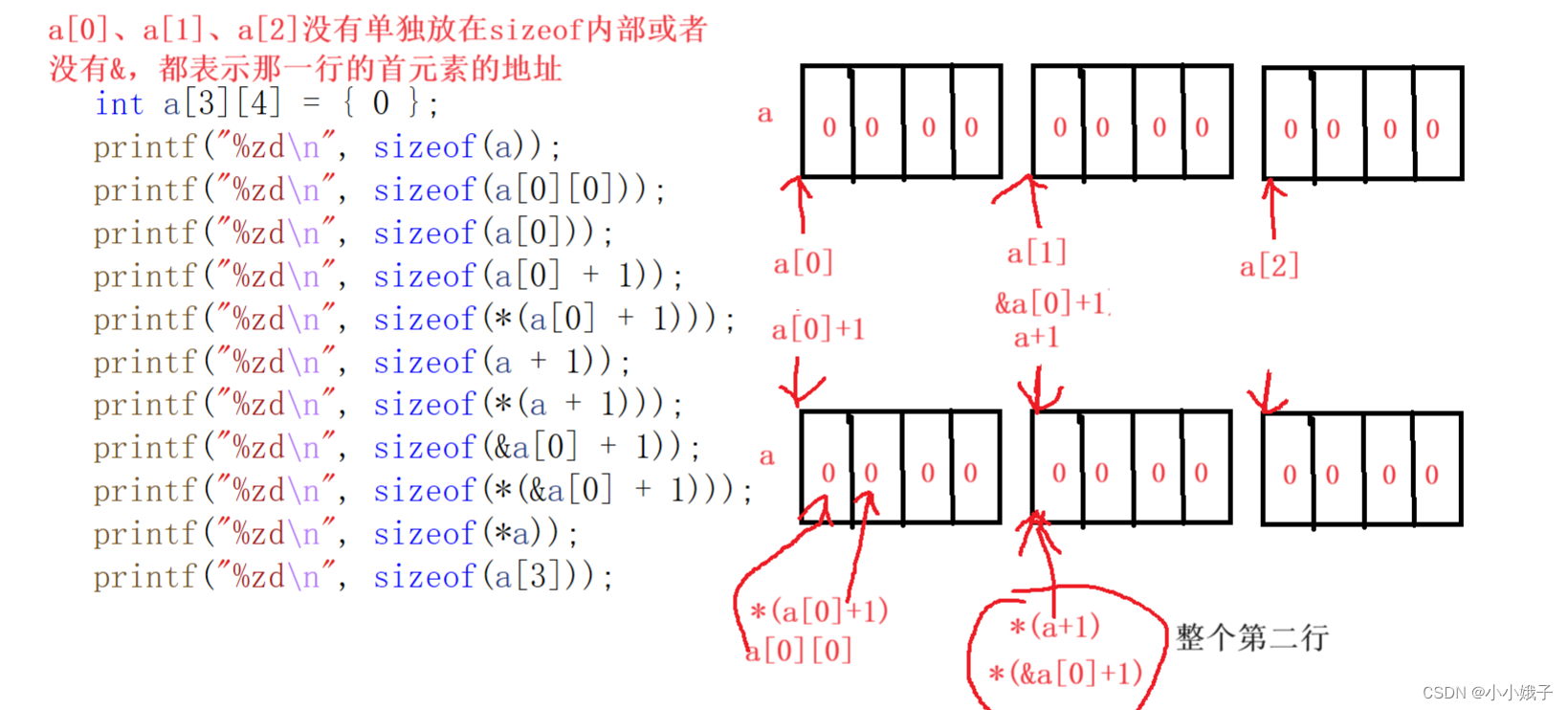
【进阶C语言】数组笔试题解析
本节内容以刷题为主,大致目录: 1.一维数组 2.字符数组 3.二维数组 学完后,你将对数组有了更全面的认识 在刷关于数组的题目前,我们先认识一下数组名: 数组名的意义:表示数组首元素的地址 但是有两个例外…...
 --- 动态添加路由)
vue-router学习(四) --- 动态添加路由
我们一般使用动态添加路由都是后台会返回一个路由表前端通过调接口拿到后处理(后端处理路由)。比如不同权限显示不同的路由。 主要使用的方法就是router.addRoute 添加路由 动态路由主要通过两个函数实现。router.addRoute() 和 router.removeRoute()。它们只注册一个新的路…...

科东软件受邀参加2023国家工业软件大会,共话工业软件未来
10月28日,由中国自动化学会主办的2023国家工业软件大会在浙江湖州开幕。大会以“工业软件智造未来”为主题,一批两院院士、千余名专家学者齐聚一堂,共同探讨工业软件领域前沿理论和技术创新应用问题,共同谋划我国工业软件未来发展…...

ros启动节点的launch文件你真的会写吗?
<launch><!-- 启动节点 --><node name="lidar_data_feature_detection_node" pkg="lidar_data_feature_detection" type="lidar_data_feature_detection" output="screen" />...

AMEYA360:循序积累立体布局,北京君正实景展示AI-ISP
北京君正集成电路股份有限公司(下称“北京君正”)是国内较早深耕智能安防及泛视觉解决方案的芯片供应商之一,也是国内同时掌握CPU、VPU、ISP、AIE等核心技术的创新企业之一,自成立以来始终深耕行业,并持续迭代创新产品及创新方案。 在2023 CP…...
)
10.31 知识总结(选择器、css属性相关)
一、选择器 1.1 属性选择器 通过标签的属性来查找标签,标签都有属性 <div class"c1" id"d1"></div> id值和class值是每个标签都自带的属性,还有另外一种:自定义属性 <div class"c1" id"d1…...
【网络协议】聊聊TCP如何做到可靠传输的
网络是不可靠的,所以在TCP协议中通过各种算法等机制保证数据传输的可靠性。生活中如何保证消息可靠传输的,那么就是采用一发一收的方式,但是这样其实效率并不高,所以通常采用的是累计确认或者累计应答。 如何实现一个靠谱的协议&…...

记一次flask框架环境综合渗透测试
PART.01 登入过程 访问靶场地址http://101.43.22.226/?name2023,框架为Flask。 2. 测试存在ssti注入。 3. 直接执行以下命令。 http://101.43.22.226/?name{% for c in [].class.base.subclasses() %} {% if c.name ‘catch_warnings’ %} {% for b in c.i…...
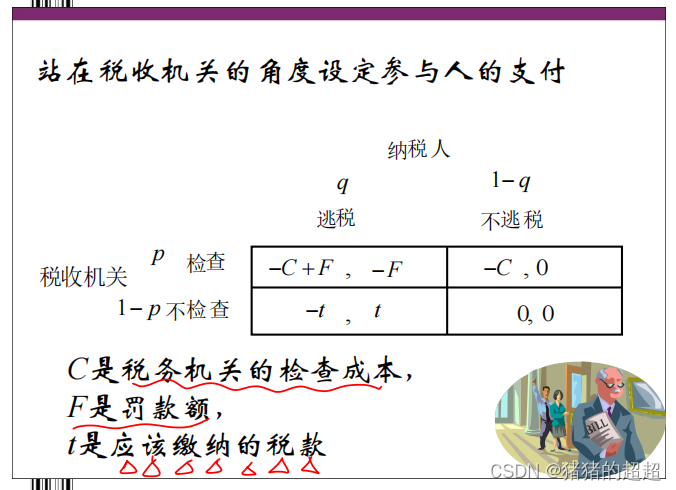
博弈论学习笔记(2)——完全信息静态博弈
前言 这部分我们学习的是完全信息静态博弈,主要内容包括博弈论的基本概念、战略式博弈、Nash均衡、Nash均衡解的特性、以及Nash均衡的应用。 零、绪论 1、什么是博弈论 1)博弈的定义 博弈论:研究决策主体的行为发生直接相互作用时候的决策…...

【COMP304 LEC4 LEC5】
LEC 4 1. Truth-Functionality Propositional logic 的connectives(连接词)are truth-functional 但是,有时候的描述不是true-functional的,比如:"Knowing that", "It is necessary that",&quo…...

表白墙(服务器)
目录 0.需求 1.创建Maven项目 2.给pom.xml内引入三个依赖 3.完善目录,并补充web.xml中的内容 4.编写代码 后端代码 编辑前端代码 5.引入数据库 创建message表 创建工具类 往MessageServlet类中添加方法 0.需求 前面写好了表白墙页面,但存…...

在 Mac 中卸载 Node.js
在 Mac 中卸载 Node.js,可以选择以下两种方法: 使用命令行卸载 Node.js 第一步:打开终端,输入以下命令显示 Node.js 的安装路径: which node 执行该命令后,会显示安装路径:/usr/local/bin/n…...

Hafnium构建选项及FVP模型调用
安全之安全(security)博客目录导读 目录 一、Hafnium构建选项 二、FVP模型调用 一、Hafnium构建选项 本节解释了在支持基于FF-A的SPM (SPMD位于EL3, SPMC位于S-EL1、S-EL2或EL3)的情况下进行构建时涉及的TF-A构建选项:...

第44天:前端及html、Http协议
前端 前端是所有跟用户直接打交道的都可以称之为是前端,比如:PC页面、手机页面、平板页面、汽车显示屏、大屏幕展示出来的都是前端内容。 前端的用处: 学了前端以后我们就可以做全栈工程师(会后端、会前端、会DB、会运维等),能够写一些简单的…...

shell_63.Linux产生信号
Linux 系统信号 信号 值 描述 1 SIGHUP 挂起(hang up)进程 2 SIGINT 中断(interrupt)进程 3 SIGQUIT 停止(stop)进程 9 …...
)
互联网摸鱼日报(2023-11-01)
互联网摸鱼日报(2023-11-01) 36氪新闻 毫末智行张凯:2023年高阶智能辅助驾驶市场迎来大爆发 撕开三星、金士顿市场,国产老牌存储器企业出海三年,营收翻三倍|insight全球 给医生一双“透视眼”,「锦瑟医疗」专注开…...

AR的光学原理?
AR智能眼镜的光学成像系统 AR眼镜的光学成像系统由微型显示屏和光学镜片组成,可以将其理解为智能手机的屏幕。 增强现实,从本质上说,是将设备生成的影像与现实世界进行叠加融合。这种技术基本就是通过光学镜片组件对微型显示屏幕发出的光线…...

语义分割 实例分割的异同点
语义分割和实例分割是计算机视觉领域中两个相关但不同的任务,它们都涉及对图像像素进行分类和标记,但关注的对象和目标有所不同。 目标对象: 语义分割:语义分割的目标是将图像中的每个像素标记为对应的语义类别,即将…...

C++学习初探---‘C++面向对象‘-继承函数重载与运算符重载
文章目录 前言继承继承是什么?三种访问权限的继承: 函数重载与运算符重载函数重载运算符重载可重载运算符&不可重载运算符 前言 第三次学习记录,依旧是C面向对象的内容。 继承 继承是什么? C中的继承是一种面向对象编程&am…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...

PCL 基于强度的双边滤波【2026最新版】
目录 一、算法原理 1、计算步骤 2、算法源码 3、函数解析 4、参考文献 二、代码实现 三、结果展示 四、滤波后未发生变化的原因 五、解决办法 六、结果展示 七、相关链接 本文由CSDN点云侠原创,博客长期更新,本文最近一次更新时间为:2026年5月24日。 一、算法原理 1、计算…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南
如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download 在数字时代,百度网盘已成为我们存储和分享大型文件的默认…...

5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南
5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...