Calcite 自定义优化器规则
1)总结
1.创建 CSVProjectRule 继承 RelRule<CSVProjectRule.Config>
a)在 CSVProjectRule.Config 接口中实现匹配规则
Config DEFAULT = EMPTY.withOperandSupplier(b0 ->b0.operand(LogicalProject.class).anyInputs()).as(Config.class);
b)在 CSVProjectRule 实现类中,如果匹配上了规则,则进行转换
@Overridepublic void onMatch(RelOptRuleCall call) {final LogicalProject project = call.rel(0);final RelNode converted = convert(project);if (converted != null) {call.transformTo(converted);}}------------------------------------------------public RelNode convert(RelNode rel) {final LogicalProject project = (LogicalProject) rel;final RelTraitSet traitSet = project.getTraitSet();return new CSVProject(project.getCluster(), traitSet,project.getInput(), project.getProjects(),project.getRowType());}
2.创建转换后的RelNode 即 CSVProject
2)代码示例
CSVProjectRule
package cn.com.ptpress.cdm.optimization.RelBuilder.optimizer;import cn.com.ptpress.cdm.optimization.RelBuilder.csvRelNode.CSVProject;
import org.apache.calcite.plan.RelOptRuleCall;
import org.apache.calcite.plan.RelRule;
import org.apache.calcite.plan.RelTraitSet;
import org.apache.calcite.rel.RelNode;
import org.apache.calcite.rel.logical.LogicalProject;public class CSVProjectRule extends RelRule<CSVProjectRule.Config> {@Overridepublic void onMatch(RelOptRuleCall call) {final LogicalProject project = call.rel(0);final RelNode converted = convert(project);if (converted != null) {call.transformTo(converted);}}/** Rule configuration. */public interface Config extends RelRule.Config {Config DEFAULT = EMPTY.withOperandSupplier(b0 ->b0.operand(LogicalProject.class).anyInputs()).as(Config.class);@Override default CSVProjectRule toRule() {return new CSVProjectRule(this);}}private CSVProjectRule(Config config) {super(config);}public RelNode convert(RelNode rel) {final LogicalProject project = (LogicalProject) rel;final RelTraitSet traitSet = project.getTraitSet();return new CSVProject(project.getCluster(), traitSet,project.getInput(), project.getProjects(),project.getRowType());}
}
CSVProjectRuleWithCost
package cn.com.ptpress.cdm.optimization.RelBuilder.optimizer;import cn.com.ptpress.cdm.optimization.RelBuilder.csvRelNode.CSVProject;
import cn.com.ptpress.cdm.optimization.RelBuilder.csvRelNode.CSVProjectWithCost;
import org.apache.calcite.plan.RelOptRuleCall;
import org.apache.calcite.plan.RelRule;
import org.apache.calcite.plan.RelTraitSet;
import org.apache.calcite.rel.RelNode;
import org.apache.calcite.rel.logical.LogicalProject;public class CSVProjectRuleWithCost extends RelRule<CSVProjectRuleWithCost.Config> {@Overridepublic void onMatch(RelOptRuleCall call) {final LogicalProject project = call.rel(0);final RelNode converted = convert(project);if (converted != null) {call.transformTo(converted);}}/** Rule configuration. */public interface Config extends RelRule.Config {Config DEFAULT = EMPTY.withOperandSupplier(b0 ->b0.operand(LogicalProject.class).anyInputs()).as(Config.class);@Override default CSVProjectRuleWithCost toRule() {return new CSVProjectRuleWithCost(this);}}private CSVProjectRuleWithCost(Config config) {super(config);}public RelNode convert(RelNode rel) {final LogicalProject project = (LogicalProject) rel;final RelTraitSet traitSet = project.getTraitSet();return new CSVProjectWithCost(project.getCluster(), traitSet,project.getInput(), project.getProjects(),project.getRowType());}
}
CSVProject
package cn.com.ptpress.cdm.optimization.RelBuilder.csvRelNode;import com.google.common.collect.ImmutableList;
import org.apache.calcite.plan.RelOptCluster;
import org.apache.calcite.plan.RelOptCost;
import org.apache.calcite.plan.RelOptPlanner;
import org.apache.calcite.plan.RelTraitSet;
import org.apache.calcite.rel.RelNode;
import org.apache.calcite.rel.core.Project;
import org.apache.calcite.rel.metadata.RelMetadataQuery;
import org.apache.calcite.rel.type.RelDataType;
import org.apache.calcite.rex.RexNode;import java.util.List;public class CSVProject extends Project {public CSVProject(RelOptCluster cluster, RelTraitSet traits, RelNode input, List<? extends RexNode> projects, RelDataType rowType) {super(cluster,traits, ImmutableList.of(),input,projects,rowType);}@Overridepublic Project copy(RelTraitSet traitSet, RelNode input, List<RexNode> projects, RelDataType rowType) {return new CSVProject(getCluster(),traitSet,input,projects,rowType);}@Overridepublic RelOptCost computeSelfCost(RelOptPlanner planner, RelMetadataQuery mq) {return planner.getCostFactory().makeZeroCost();}
}
CSVProjectWithCost
package cn.com.ptpress.cdm.optimization.RelBuilder.csvRelNode;import com.google.common.collect.ImmutableList;
import org.apache.calcite.plan.RelOptCluster;
import org.apache.calcite.plan.RelOptCost;
import org.apache.calcite.plan.RelOptPlanner;
import org.apache.calcite.plan.RelTraitSet;
import org.apache.calcite.rel.RelNode;
import org.apache.calcite.rel.core.Project;
import org.apache.calcite.rel.metadata.RelMetadataQuery;
import org.apache.calcite.rel.type.RelDataType;
import org.apache.calcite.rex.RexNode;import java.util.List;public class CSVProjectWithCost extends Project{public CSVProjectWithCost(RelOptCluster cluster, RelTraitSet traits, RelNode input, List<? extends RexNode> projects, RelDataType rowType) {super(cluster,traits, ImmutableList.of(),input,projects,rowType);}@Overridepublic Project copy(RelTraitSet traitSet, RelNode input, List<RexNode> projects, RelDataType rowType) {return new CSVProjectWithCost(getCluster(),traitSet,input,projects,rowType);}@Overridepublic RelOptCost computeSelfCost(RelOptPlanner planner, RelMetadataQuery mq) {return planner.getCostFactory().makeInfiniteCost();}
}
SqlToRelNode
package cn.com.ptpress.cdm.optimization.RelBuilder.Utils;import cn.com.ptpress.cdm.ds.csv.CsvSchema;
import org.apache.calcite.config.CalciteConnectionConfigImpl;
import org.apache.calcite.config.CalciteConnectionProperty;
import org.apache.calcite.jdbc.CalciteSchema;
import org.apache.calcite.jdbc.JavaTypeFactoryImpl;
import org.apache.calcite.prepare.CalciteCatalogReader;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.sql.parser.SqlParser;
import org.apache.calcite.tools.Frameworks;import java.util.Properties;public class CatalogReaderUtil {public static CalciteCatalogReader createCatalogReader(SqlParser.Config parserConfig) {SchemaPlus rootSchema = Frameworks.createRootSchema(true);rootSchema.add("csv", new CsvSchema("data.csv"));return createCatalogReader(parserConfig, rootSchema);}public static CalciteCatalogReader createCatalogReader(SqlParser.Config parserConfig, SchemaPlus rootSchema) {Properties prop = new Properties();prop.setProperty(CalciteConnectionProperty.CASE_SENSITIVE.camelName(),String.valueOf(parserConfig.caseSensitive()));CalciteConnectionConfigImpl calciteConnectionConfig = new CalciteConnectionConfigImpl(prop);return new CalciteCatalogReader(CalciteSchema.from(rootSchema),CalciteSchema.from(rootSchema).path("csv"),new JavaTypeFactoryImpl(),calciteConnectionConfig);}
}
CatalogReaderUtil
package cn.com.ptpress.cdm.optimization.RelBuilder.Utils;import cn.com.ptpress.cdm.ds.csv.CsvSchema;
import org.apache.calcite.config.CalciteConnectionConfigImpl;
import org.apache.calcite.config.CalciteConnectionProperty;
import org.apache.calcite.jdbc.CalciteSchema;
import org.apache.calcite.jdbc.JavaTypeFactoryImpl;
import org.apache.calcite.prepare.CalciteCatalogReader;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.sql.parser.SqlParser;
import org.apache.calcite.tools.Frameworks;import java.util.Properties;public class CatalogReaderUtil {public static CalciteCatalogReader createCatalogReader(SqlParser.Config parserConfig) {SchemaPlus rootSchema = Frameworks.createRootSchema(true);rootSchema.add("csv", new CsvSchema("data.csv"));return createCatalogReader(parserConfig, rootSchema);}public static CalciteCatalogReader createCatalogReader(SqlParser.Config parserConfig, SchemaPlus rootSchema) {Properties prop = new Properties();prop.setProperty(CalciteConnectionProperty.CASE_SENSITIVE.camelName(),String.valueOf(parserConfig.caseSensitive()));CalciteConnectionConfigImpl calciteConnectionConfig = new CalciteConnectionConfigImpl(prop);return new CalciteCatalogReader(CalciteSchema.from(rootSchema),CalciteSchema.from(rootSchema).path("csv"),new JavaTypeFactoryImpl(),calciteConnectionConfig);}
}
PlannerTest
import cn.com.ptpress.cdm.optimization.RelBuilder.Utils.SqlToRelNode;
import cn.com.ptpress.cdm.optimization.RelBuilder.optimizer.CSVProjectRule;
import cn.com.ptpress.cdm.optimization.RelBuilder.optimizer.CSVProjectRuleWithCost;
import org.apache.calcite.plan.RelOptPlanner;
import org.apache.calcite.plan.RelOptUtil;
import org.apache.calcite.plan.hep.HepPlanner;
import org.apache.calcite.plan.hep.HepProgram;
import org.apache.calcite.plan.hep.HepProgramBuilder;
import org.apache.calcite.rel.RelNode;
import org.apache.calcite.rel.rules.FilterJoinRule;
import org.apache.calcite.sql.parser.SqlParseException;
import org.junit.jupiter.api.Test;class PlannerTest {@Testpublic void testCustomRule() throws SqlParseException {final String sql = "select Id from data ";HepProgramBuilder programBuilder = HepProgram.builder();// 测试交换 CSVProjectRule 和 CSVProjectRuleWithCost 的顺序HepPlanner hepPlanner =new HepPlanner(programBuilder.addRuleInstance(CSVProjectRule.Config.DEFAULT.toRule()).addRuleInstance(CSVProjectRuleWithCost.Config.DEFAULT.toRule()).build());// HepPlanner hepPlanner =
// new HepPlanner(
// programBuilder
// .addRuleInstance(CSVProjectRuleWithCost.Config.DEFAULT.toRule())
// .addRuleInstance(CSVProjectRule.Config.DEFAULT.toRule())
// .build());RelNode relNode = SqlToRelNode.getSqlNode(sql, hepPlanner);System.out.println(RelOptUtil.toString(relNode));RelOptPlanner planner = relNode.getCluster().getPlanner();planner.setRoot(relNode);RelNode bestExp = planner.findBestExp();System.out.println(RelOptUtil.toString(bestExp));RelOptPlanner relOptPlanner = relNode.getCluster().getPlanner();relOptPlanner.addRule(CSVProjectRule.Config.DEFAULT.toRule());relOptPlanner.addRule(CSVProjectRuleWithCost.Config.DEFAULT.toRule());relOptPlanner.setRoot(relNode);RelNode exp = relOptPlanner.findBestExp();System.out.println(RelOptUtil.toString(exp));}/*** 未优化算子树结构* LogicalProject(ID=[$0])* LogicalFilter(condition=[>(CAST($0):INTEGER NOT NULL, 1)])* LogicalJoin(condition=[=($0, $3)], joinType=[inner])* LogicalTableScan(table=[[csv, data]])* LogicalTableScan(table=[[csv, data]])** 优化后接结果* LogicalProject(ID=[$0])* LogicalJoin(condition=[=($0, $3)], joinType=[inner])* LogicalFilter(condition=[>(CAST($0):INTEGER NOT NULL, 1)])* LogicalTableScan(table=[[csv, data]])* LogicalTableScan(table=[[csv, data]])*/@Testpublic void testHepPlanner() throws SqlParseException {final String sql = "select a.Id from data as a join data b on a.Id = b.Id where a.Id>1";HepProgramBuilder programBuilder = HepProgram.builder();HepPlanner hepPlanner =new HepPlanner(programBuilder.addRuleInstance(FilterJoinRule.FilterIntoJoinRule.Config.DEFAULT.toRule()).build());RelNode relNode = SqlToRelNode.getSqlNode(sql, hepPlanner);//未优化算子树结构System.out.println(RelOptUtil.toString(relNode));RelOptPlanner planner = relNode.getCluster().getPlanner();planner.setRoot(relNode);RelNode bestExp = planner.findBestExp();//优化后接结果System.out.println(RelOptUtil.toString(bestExp));}/*** 未转化Dag算子树结构* LogicalProject(Id=[$0], Name=[$1], Score=[$2])* LogicalFilter(condition=[=(CAST($0):INTEGER NOT NULL, 1)])* LogicalTableScan(table=[[csv, data]])** 转化为Dag图* Breadth-first from root: {* rel#8:HepRelVertex(rel#7:LogicalProject.(input=HepRelVertex#6,inputs=0..2)) = rel#7:LogicalProject.(input=HepRelVertex#6,inputs=0..2), rowcount=15.0, cumulative cost=130.0* rel#6:HepRelVertex(rel#5:LogicalFilter.(input=HepRelVertex#4,condition==(CAST($0):INTEGER NOT NULL, 1))) = rel#5:LogicalFilter.(input=HepRelVertex#4,condition==(CAST($0):INTEGER NOT NULL, 1)), rowcount=15.0, cumulative cost=115.0* rel#4:HepRelVertex(rel#1:LogicalTableScan.(table=[csv, data])) = rel#1:LogicalTableScan.(table=[csv, data]), rowcount=100.0, cumulative cost=100.0* }*/@Testpublic void testGraph() throws SqlParseException {final String sql = "select * from data where Id=1";HepProgramBuilder programBuilder = HepProgram.builder();HepPlanner hepPlanner =new HepPlanner(programBuilder.build());RelNode relNode = SqlToRelNode.getSqlNode(sql, hepPlanner);//未转化Dag算子树结构System.out.println("未转化Dag算子树结构");System.out.println(RelOptUtil.toString(relNode));//转化为Dag图System.out.println("转化为Dag图");hepPlanner.setRoot(relNode);//查看需要把log4j.properties级别改为trace}
}
data.csv
Id:VARCHAR Name:VARCHAR Score:INTEGER
1,小明,90
2,小红,98
3,小亮,95
相关文章:

Calcite 自定义优化器规则
1)总结 1.创建 CSVProjectRule 继承 RelRule<CSVProjectRule.Config> a)在 CSVProjectRule.Config 接口中实现匹配规则 Config DEFAULT EMPTY.withOperandSupplier(b0 ->b0.operand(LogicalProject.class).anyInputs()).as(Config.class);b…...

【flink】flink获取-D参数方式
参考官网 一、idea 本地运行 使用Flink官方的ParameterTool或者其他工具都可以。 二、集群运行flink run/run-application (1)ParameterTool 获取参数 以-D开头的参数: ParameterTool parameter ParameterTool.fromSystemProperties()…...

NLP之多循环神经网络情感分析
文章目录 代码展示代码意图代码解读知识点介绍 代码展示 import pandas as pd import tensorflow as tf# 构建RNN神经网络 tf.random.set_seed(1) df pd.read_csv("../data/Clothing Reviews.csv") print(df.info())df[Review Text] df[Review Text].astype(str) …...
)
【AutoML】AutoKeras 的安装和环境配置(VSCode)
本地环境中已经有太多的工作配置了(Python、Java、Maven、Docker 等等),为了不影响其他环境运行,我选择直接在 VSCode 中创建工作空间并配置好 AutoKeras(反正最后也是要在 VSCode 中进行开发的)。 打开 V…...
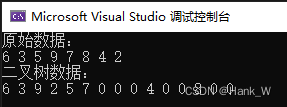
树结构及其算法-用数组来实现二叉树
目录 树结构及其算法-用数组来实现二叉树 C代码 树结构及其算法-用数组来实现二叉树 使用有序的一维数组来表示二叉树,首先可将此二叉树假想成一棵满二叉树,而且第层具有个节点,按序存放在一维数组中。首先来看看使用一维数组建立二叉树的…...
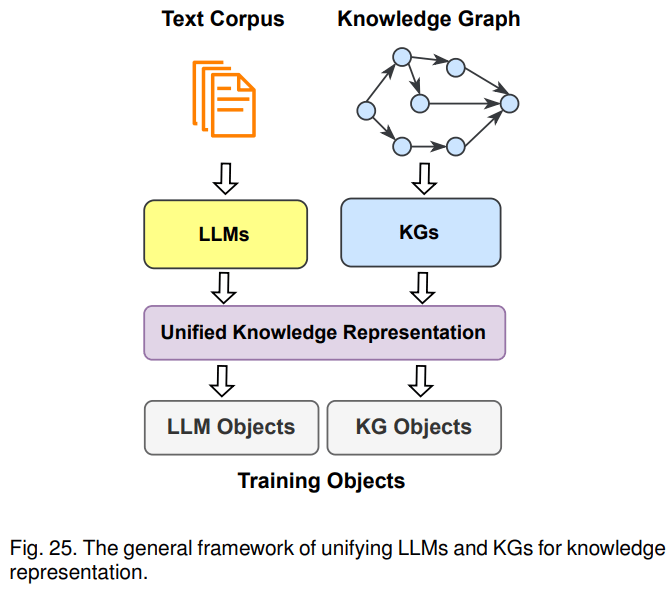
知识图谱与大模型结合方法概述
《Unifying Large Language Models and Knowledge Graphs: A Roadmap》总结了大语言模型和知识图谱融合的三种路线:1)KG增强的LLM,可在LLMs的预训练和推理阶段引入KGs;2)LLM增强KG,LLM可用于KG构建、KG emb…...

ASO优化之如何制作Google Play的长短描述
应用的描述以及标题和图标是元数据中最关键的元素,可以影响用户是否决定下载我们的应用程序。简短描述的长度限制为80个字符,它提供了更多的有关应用背景信息的机会。 1、简短描述帮助用户快速了解我们应用。 确保内容丰富的同时,保持简洁和…...

Python-platform模块
platform目录 前言一、platform.system()二、platform.release()三、platform.python_version()四、platform.machine()五、platform.python_implementation()六、其他代码示例七、help总结前言 Python platform模块是一个用于获取和操作操作系统相关信息的内置模块。它提供了…...
检测自己的数据集,附带代码模型可以收敛)
Yolov5旋转框(斜框)检测自己的数据集,附带代码模型可以收敛
文章目录 1. 制作数据集1.1 标注数据集1.2标签转换1.3 数据集划分2. 环境搭建1.安装nms_rotated2.安装DOTA_devkit3. 代码讲解3.1坐标表示3.2 损失函数4.训练+测试链接后面附上百度网盘链接,内部包含数据集。 下一篇介绍tensorRT部署yolov5-obb 1. 制作数据集 标注软件为…...
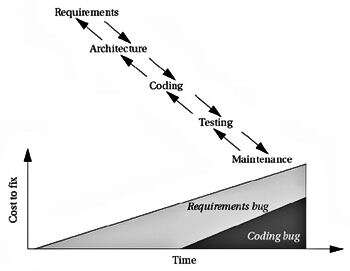
嵌入式应用选择正确的系统设计方法:第三部分
产品质量低下的原因有很多,例如,产品制造粗糙,组件设计不当,架构不佳以及对产品的要求了解不多。点击领取嵌入式物联网学习路线 必须设计质量。 您不能测试出足够的错误来交付高质量的产品。的质量保证(QA)…...

pthread_attr_getstacksize 问题
最近公司里遇到一个线程栈大小的问题,借此机会刚好学习一下这个线程栈大小相关的函数。如果公司里用的还是比较老的代码的话,都是用的 pthread 库支持线程的,而不是 c11 里的线程类。主要有两个相关函数:pthread_attr_setstacksiz…...

anaconda常见语法
anaconda常见语法 一、镜像 1.添加镜像channel conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/2.删除镜像channel conda config --remove channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/3.展示目前已有的镜像…...

reactive与ref VCA
简介 Vue3 最大的一个变动应该就是推出了 CompositionAPI,可以说它受ReactHook 启发而来;它我们编写逻辑更灵活,便于提取公共逻辑,代码的复用率得到了提高,也不用再使用 mixin 担心命名冲突的问题。 ref 与 reactive…...

小程序day01
简介: 小程序项目的基本结构 页面的组成部分 一个页面对应一个文件夹,所有有关的内容都放在一起。 JSON配置文件 2.app.json文件 3.project.config.json文件 4.sitemap.json文件 5.页面的.json配置文件 6. 新建小程序页面 7.修改项目首页 小程序代码构成 小程序的宿…...

redis主要支持的数据类型有哪些?—— 筑梦之路
Redis支持的主要数据类型: 1、字符串(String):字符串是最简单的数据结构,可以存储文本或二进制数据。常用操作:设置值、获取值、追加、自增自减等。 2、列表(List):列表是…...

解决国际阿里云服务器挂载云盘的问题!!
跟着云计算技术的开展,越来越多的企业和个人挑选运用云服务器。然而,在运用过程中,可能会遇到一些问题,比如云服务器无法挂载云盘。这篇文章将详细说明如何处理这个问题。 一、云服务器无法挂载云盘的原因 云服务器无法挂载云盘可…...

基于吉萨金字塔建造算法的无人机航迹规划-附代码
基于吉萨金字塔建造算法的无人机航迹规划 文章目录 基于吉萨金字塔建造算法的无人机航迹规划1.吉萨金字塔建造搜索算法2.无人机飞行环境建模3.无人机航迹规划建模4.实验结果4.1地图创建4.2 航迹规划 5.参考文献6.Matlab代码 摘要:本文主要介绍利用吉萨金字塔建造算法…...

高频SQL50题(基础版)-1
文章目录 主要内容一.SQL练习题1.1757-可回收且抵制的产品代码如下(示例): 2.584-寻找用户推荐人代码如下(示例): 3.595-大的国家代码如下(示例): 4.1148-文章浏览代码如下(示例): 5…...

RecyclerView自定义LayoutManager从0到1实践
此前大部分涉及到 RecyclerView 页面的 LayoutManager基本上用系统提供的 LinearLayoutManager 、GridLayoutManager 就能解决,但在一些特殊场景上还是需要我们自定义 LayoutManager。之前基本上没有自己写过,在网上看各种源码各种文章,刚开始…...

【虹科干货】5个关于微服务的误解
你认为微服务架构能为你带来什么?难道微服务真的是一劳永逸的吗?又或者,难道微服务的威力并不如传闻所言?微服务架构应当如何设计才能真正彰显它作为一种解决方案的好处呢? 文章速览: 误解一:…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...

机器学习在射电天文数据分类中的应用:以MIGHTEE巡天SFG/AGN分类为例
1. 项目概述:当机器学习遇见深空射电巡天在射电天文学领域,我们正经历一场数据洪流。以MeerKAT望远镜阵列主导的MIGHTEE巡天项目为例,其在COSMOS天区的一次早期科学数据释放,就在不到1平方度的天区内探测到了超过6000个射电源。传…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

LLM驱动的高性能计算日志解析技术实践
1. 项目概述:LLM驱动的HPC日志解析革命高性能计算(HPC)系统如同数字世界的巨型望远镜,每天产生PB级的观测数据——系统日志。这些日志记录了从硬件底层到应用层的所有活动,但它们的价值长期被埋没在非结构化文本的泥沼中。传统日志解析方法就…...

Taotoken的APIKey管理与访问控制功能保障了企业级安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的APIKey管理与访问控制功能保障了企业级安全 当团队开始规模化使用大语言模型时,一个核心挑战随之而来&#…...

RISC-V模拟器终极指南:如何快速掌握处理器可视化调试
RISC-V模拟器终极指南:如何快速掌握处理器可视化调试 【免费下载链接】Ripes A graphical processor simulator and assembly editor for the RISC-V ISA 项目地址: https://gitcode.com/gh_mirrors/ri/Ripes RISC-V模拟器Ripes是一款强大的图形化处理器仿真…...

TrollInstallerX终极指南:3分钟完成iOS TrollStore安装的强力工具
TrollInstallerX终极指南:3分钟完成iOS TrollStore安装的强力工具 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款专为iOS设备设计的T…...