数据库面试题整理
目录
- MySQL
- 事务隔离级别有哪几种?
- MySQL的常用的存储引擎有哪些?特点是什么,分别适合什么场景下使用
- MySQL有数据缓存吗?原理是怎么样的?
- InnoDB的缓冲池默认是开启的吗?基本原理是什么?会有脏数据的问题吗?
- Redo Log(重做日志) 和 Bin Log(二进制日志)的区别是什么?
- MySQL的查询缓存默认是开启的吗?
- MySQL的sql注入怎么解决?
- Redis
MySQL
事务隔离级别有哪几种?
MySQL支持 4 种事务隔离级别,这些隔离级别定义了事务之间的可见性和并发控制方式。
- READ UNCOMMITTED(读未提交):这是最低的隔离级别。在该级别下,事务可以读取未提交事务的数据,可能会导致脏读、不可重复读和幻像读问题。一般情况下不建议使用此级别。
- READ COMMITTED(读已提交):在这个级别下,事务只能读取已经提交的数据,可以避免脏读,但仍可能出现不可重复读和幻像读问题。
- REPEATABLE READ(可重复读):这是MySQL默认的隔离级别。在该级别下,事务能够读取和锁定事务开始时的数据快照,从而避免了脏读和不可重复读。但幻像读问题仍然可能出现。
- SERIALIZABLE(串行化):这是最高的隔离级别。在该级别下,事务完全隔离,不会发生脏读、不可重复读和幻像读。但它也是最慢的级别,因为它会在读取数据时对数据进行锁定,阻止其他事务的并发操作。

如果不考虑隔离性,可能会引发如下问题:
- 脏读(Dirty Read):脏读指的是一个事务读取了另一个事务尚未提交的数据。如果另一个事务在最终没有提交的情况下回滚了,那么读取的数据就是无效的。脏读可能导致不一致的数据和不准确的查询结果。
- 幻读(Phantom Read):幻读是指在同一事务内的两次查询中,第二次查询发现了更多的数据行,这是由于在两次查询之间有另一个事务插入了新的数据行。幻读与不可重复读不同之处在于,不可重复读是由于已提交事务的更新导致的数据不一致,而幻读是由于新插入的数据导致的数据不一致。
- 不可重复读(Non-Repeatable Read):不可重复读是指在同一事务内的两次查询中,第二次查询发现了不同的数据。这是由于在两次查询之间有另一个事务修改了数据并提交了事务。不可重复读可能导致事务内部的一致性问题,因为事务在两次查询之间看到了不一致的数据。
MySQL的常用的存储引擎有哪些?特点是什么,分别适合什么场景下使用
MySQL的表类型由存储引擎决定,主要包括:myisam、innodb、memory等
- innodb 存储引擎:支持事务和外键,行级锁
- myisam 存储引擎:不支持事务和外键,支持全文搜索,添加速度快,表级锁
- memory 存储引擎:不支持事务和外键,表级锁,数据存储在内存中(关闭了MySQL服务,数据丢失,但是表结构还在), 执行速度很快(没有IO读写),默认支持索引(hash表)
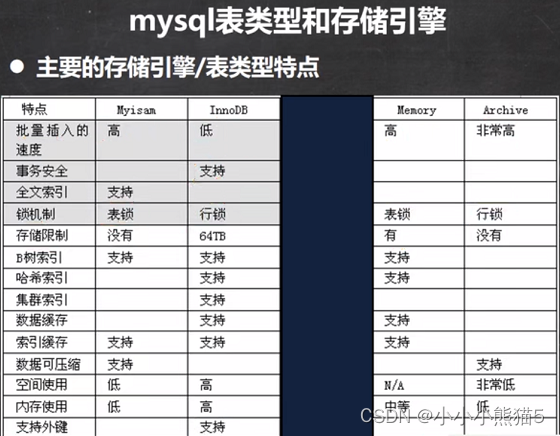
如何选择存储引擎
- 如果不需要事务,读多写少的业务,选择 myisam。
- 如果需要支持事务和数据完整性和外键约束等要求,选择 innodb。
- memory存储引擎将表数据存储在内存中,因此速度非常快。但它的数据是临时的,重启MySQL后数据会丢失,适用于临时数据存储或缓存。(经典用法:用户的在线状态)
MySQL有数据缓存吗?原理是怎么样的?
MySQL具有数据缓存机制,其中包括查询缓存和innodb缓冲池(Buffer Pool)。
MySQL的数据库缓存机制默认是开启的,但不同部分的缓存可以根据配置进行调整。
不同存储引擎对数据缓存的支持程序可能不同。一般来说,innodb存储引擎具有较强的缓冲机制,而其他存储引擎比如myisam也支持一些缓存机制。
- innodb缓冲池:innodb存储引擎默认启用了缓冲池,用于缓存表数据和索引。可以通过配置
innodb_buffer_pool_size参数来控制缓冲池的大小。- 原理:用于存储数据库表数据和索引的内存缓存区域。当查询需要访问表数据或索引时,MySQL会先检查缓冲池中是否有相应的数据页。如果有,将从内存中获取数据,而不是从磁盘读取,以提高查询性能。
- 作用:提高查询性能,因为内存访问比磁盘访问快的多。可以显著减少 IO 操作。特别是在大型数据库中。缓冲池还可以存储最常用的数据,以减少磁盘访问的需求。
- 数据一致性保护措施:默认情况下,innodb存储引擎已经采取了一些措施来确保数据的一致性。
- 查询缓存:在MySQL8.0 版本已被弃用。因为它在高并发和写入频繁的数据库中可能引发性能问题。在较早的MySQL版本中,可以通过设置
query_cache_type和query_cache_size参数来启用和配置查询缓存。- 原理:是MySQL的查询结果缓存,会存储已经执行过的查询的结果集。当一个查询执行时,MySQL会检查查询缓存是否已经有了相同查询的结果,如果有,就直接返回缓存中的结果,而不执行实际的查询。以减少查询的执行时间,提高性能。
- 问题:可以提供性能,但存在限制。比如:如果数据库中的数据发生了变化,查询缓存可能导致脏数据的返回。因此,在高并发、频繁写入的数据库中不太适用。
- 键缓存:MySQL支持键缓存,用于缓存表的索引。可以使用
key_buffer_size参数来配置键缓存的大小。
如何避免缓存带来的脏数据问题?
- 合理配置缓冲区大小:确保为缓冲池和其他缓冲区分配合理的大小,以适应数据库的工作负载和可用内存。不要过分依赖缓存,否则可能导致脏数据问题。
- 使用事务隔离级别:通过配置适当的事务隔离级别,减少脏读和不可重复读的可能性,从而提高数据一致性。
- 定期刷新缓存:在高并发的写入场景中,定期刷新缓存可以确保数据的一致性。使用
innodb_flush_method等参数来配置刷新策略。 - 监控性能和缓存命中率:通过监视数据库性能和缓存命中率,及时发现性能问题和缓存引起的脏数据问题。
InnoDB的缓冲池默认是开启的吗?基本原理是什么?会有脏数据的问题吗?
InnoDB的缓冲池是默认启用的,而且在大多数情况下,使用默认配置的InnoDB缓冲池不会导致脏数据问题。
默认情况下,InnoDB存储引擎已经采取了一些措施来确保数据的一致性,即使在默认的事务隔离级别下也应该是安全的。
以下是一些有关InnoDB缓冲池和脏数据的重要考虑因素:
- 默认配置:默认情况下,InnoDB使用行级锁和可重复读(REPEATABLE READ)的事务隔离级别。这意味着InnoDB在默认情况下已经配置为尽量减少脏数据的风险。
- 缓冲池管理:InnoDB缓冲池会根据需要自动管理,它会将频繁访问的数据页加载到内存中,并根据LRU(最近最少使用)算法来替换不常使用的数据页。这有助于提高性能,并减少脏数据的可能性。
- 脏数据问题:脏数据问题通常出现在高并发写入的情况下,当多个事务同时修改相同数据时,可能会导致脏数据。但默认的InnoDB配置和事务隔离级别通常会确保数据的一致性,尽管可能会导致一些性能开销。
InnoDB存储引擎使用了一种称为写前日志(Write-Ahead Logging,WAL)的机制来确保数据的一致性和持久性。具体操作流程如下:
- 当有数据更新操作时,InnoDB首先将这个更新操作记录在事务的写前日志(redo log)中。这个写前日志是磁盘上的一个特殊文件。
- 同时,InnoDB会将数据修改操作应用到内存中的缓冲池(Buffer Pool),从而提高读取和写入性能。这意味着数据的修改首先是在内存中的缓冲池中进行的。
- 为了确保数据的持久性,InnoDB在适当的时机将缓冲池中的数据异步刷新到磁盘。这个操作通常发生在后台线程中,而不会阻塞用户事务。
- 当事务提交时,InnoDB将事务的写前日志记录标记为已提交,从而使这个事务的修改在崩溃恢复时可以被应用。
这个操作流程保证了数据的持久性和一致性,即使在数据修改过程中出现了崩溃或故障。这是InnoDB存储引擎的核心特性,确保了数据在事务隔离下的一致性。
在这个过程中,InnoDB使用了行级锁来确保多个事务之间的并发性。每个数据行都可以被多个事务并发访问,而行级锁会确保数据的一致性。如果多个事务尝试同时修改相同的数据行,InnoDB会使用锁机制来协调它们的访问,以避免数据损坏和不一致。
总之,InnoDB存储引擎通过使用写前日志、内存缓冲池、异步刷新到磁盘以及行级锁等机制,来确保数据的一致性和持久性,即使在高并发和崩溃情况下也能保持数据的完整性。这是InnoDB在事务隔离下操作的基本原理。
Redo Log(重做日志) 和 Bin Log(二进制日志)的区别是什么?
Redo Log(重做日志)和Binary Log(二进制日志) 是MySQL中两种不同的日志文件,它们有不同的目的和用途。
- Redo Log(重做日志):
- 目的:Redo Log是InnoDB存储引擎特有的一种日志,其主要目的是确保事务的持久性。它记录了每个事务所做的修改操作,以便在数据库发生故障或崩溃时进行恢复。Redo Log用于保证数据的一致性和完整性。
- 持久性:Redo Log是持久性的,它通常存储在磁盘上,并且不会轻易被删除。
- 格式:Redo Log是二进制格式,记录了事务的修改操作,但不包含SQL语句。
- Binary Log(二进制日志):
- 目的:Binary Log用于记录数据库的所有变更操作,包括数据修改、DDL语句、数据导入等。它的主要目的是实现数据复制和恢复,以便在不同服务器之间同步数据或进行数据恢复。
- 持久性:Binary Log通常也是持久性的,但它可以配置为自动删除旧日志以减少磁盘空间占用。
- 格式:Binary Log可以以文本格式或二进制格式存储,它包含了SQL语句或二进制事件。
主要区别在于目的和内容:
* Redo Log 是InnoDB存储引擎用来确保事务持久性和一致性的日志,它记录了事务的修改操作,是二进制格式,通常不包含SQL语句。
* Binary Log 用于数据复制和恢复,它记录了数据库的所有变更操作,包括数据修改、DDL语句等,可以以文本或二进制格式存储。
MySQL的查询缓存默认是开启的吗?
自 MySQL 5.7.20 版本起,查询缓存(Query Cache)已被弃用,并且从 MySQL 8.0.20 版本开始,查询缓存已完全删除,不再可用。
在这之前的 MySQL 版本中,查询缓存默认是启用的,但随着时间的推移,它被认为不再适合高性能和高并发的数据库系统,因此被弃用并删除。
MySQL的sql注入怎么解决?
SQL注入是一种常见的数据库攻击,它可以允许攻击者执行恶意SQL查询或修改数据库数据。为了防止SQL注入,可以采取以下措施:
- 使用参数化查询:最有效的防止SQL注入的方法是使用参数化查询,也叫预编译语句或绑定变量。在参数化查询中,SQL查询中的参数值是作为参数传递给数据库,而不是通过字符串拼接直接插入SQL查询中。这样可以防止恶意输入作为SQL代码执行。
示例(使用Golang的database/sql包):query := "SELECT * FROM users WHERE username = ? AND password = ?" rows, err := db.Query(query, username, password) - 输入验证和过滤:对用户输入进行验证和过滤,确保只允许合法的字符和数据。这可以通过正则表达式或其他验证方法来实现。
- 避免拼接SQL查询:避免使用字符串拼接来构建SQL查询,因为这样容易受到注入攻击。使用参数化查询或ORM(对象关系映射)工具来构建和执行数据库查询。
- 限制数据库用户权限:数据库用户应该被授予最小必要的权限。不要为应用程序使用的数据库用户授予过多的权限,以降低潜在攻击的影响。
- 错误信息处理:不要向用户显示详细的数据库错误信息,因为攻击者可能会利用这些信息来发起攻击。将错误信息记录到服务器日志而不是向用户显示。
- 定期更新和维护:定期更新数据库管理系统以获得最新的安全性修复和补丁。同时,确保应用程序的依赖项也是最新的,包括数据库驱动程序。
- 安全编码实践:编写安全的代码,包括防止SQL注入。审查和审计应用程序代码以识别潜在的漏洞。
- 使用Web应用程序防火墙(WAF):WAF可以检测和阻止常见的注入攻击尝试,为应用程序提供额外的保护层。
Redis
相关文章:
数据库面试题整理
目录 MySQL事务隔离级别有哪几种?MySQL的常用的存储引擎有哪些?特点是什么,分别适合什么场景下使用MySQL有数据缓存吗?原理是怎么样的?InnoDB的缓冲池默认是开启的吗?基本原理是什么?会有脏数据…...

【无标题】输入日期是当年的第n天
从键盘输入正确日期,程序输出是当年的第n天。 (本笔记适合熟悉循环和列表的 coder 翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么…...

金蝶云星空自定义校验器和使用
文章目录 金蝶云星空自定义校验器和使用 金蝶云星空自定义校验器和使用 1、创建类,并继承抽象接口 using Kingdee.BOS.Core; using Kingdee.BOS.Core.Validation; using System;namespace mm.K3.SCM.App.Service.PlugIn.SC.Validator {public class AfterOrderChe…...

MyBatis实验(四)——关联查询
前言 多表关联查询是软件开发中最常见的应用场景,多表查询需要将数据实体之间的一对多、多对多、一对一的关系的转换为复杂的数据对象。mybaits提供的association和collection元素,通过映射文件构造复杂实体对象,在构造实体过程中࿰…...
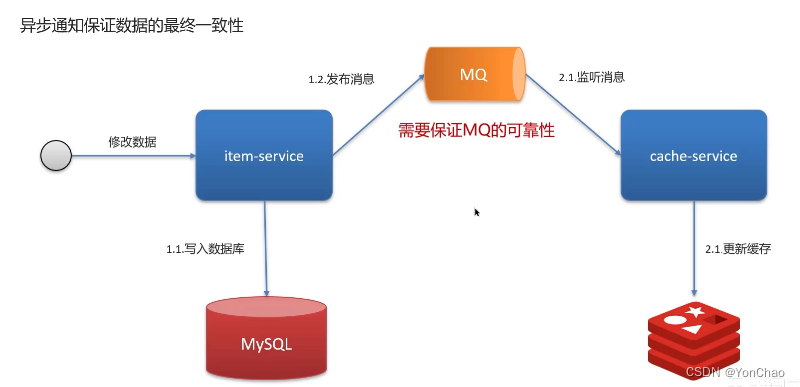
Redis与Mysql的数据一致性(双写一致性)
双写一致性:当修改了数据库的数据也要同时的更新缓存的数据,使缓存和数据库的数据要保持一致。 一般是在写数据的时候添加延迟双删的策略 先删缓存 再修改数据 延迟一段时间后再次删除缓存 这种方式其实不是很靠谱 一致性要求高 共享锁:读…...
sql-50练习题16-20
sql-50练习题16-20 前言数据库表结构介绍学生表课程表成绩表教师表 1-6 检索"01"课程分数小于60,按分数降序排列的学生信息1-7 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩1-8 查询各科成绩最高分、最低分和平均分:以如下形式…...

算法通关村第四关|青铜|自己实现栈
1.自己实现栈——基于数组 top 有的地方指向栈顶元素,有的地方指向栈顶再往上的一个空单位,根据题目要求设计。 *这里将 top 设置为栈顶再往上的一个空单位。 import java.util.Arrays; class Mystack<T> {private Object[] stack;// 指向栈顶…...

Calcite 自定义优化器规则
1)总结 1.创建 CSVProjectRule 继承 RelRule<CSVProjectRule.Config> a)在 CSVProjectRule.Config 接口中实现匹配规则 Config DEFAULT EMPTY.withOperandSupplier(b0 ->b0.operand(LogicalProject.class).anyInputs()).as(Config.class);b…...

【flink】flink获取-D参数方式
参考官网 一、idea 本地运行 使用Flink官方的ParameterTool或者其他工具都可以。 二、集群运行flink run/run-application (1)ParameterTool 获取参数 以-D开头的参数: ParameterTool parameter ParameterTool.fromSystemProperties()…...

NLP之多循环神经网络情感分析
文章目录 代码展示代码意图代码解读知识点介绍 代码展示 import pandas as pd import tensorflow as tf# 构建RNN神经网络 tf.random.set_seed(1) df pd.read_csv("../data/Clothing Reviews.csv") print(df.info())df[Review Text] df[Review Text].astype(str) …...
)
【AutoML】AutoKeras 的安装和环境配置(VSCode)
本地环境中已经有太多的工作配置了(Python、Java、Maven、Docker 等等),为了不影响其他环境运行,我选择直接在 VSCode 中创建工作空间并配置好 AutoKeras(反正最后也是要在 VSCode 中进行开发的)。 打开 V…...
树结构及其算法-用数组来实现二叉树
目录 树结构及其算法-用数组来实现二叉树 C代码 树结构及其算法-用数组来实现二叉树 使用有序的一维数组来表示二叉树,首先可将此二叉树假想成一棵满二叉树,而且第层具有个节点,按序存放在一维数组中。首先来看看使用一维数组建立二叉树的…...
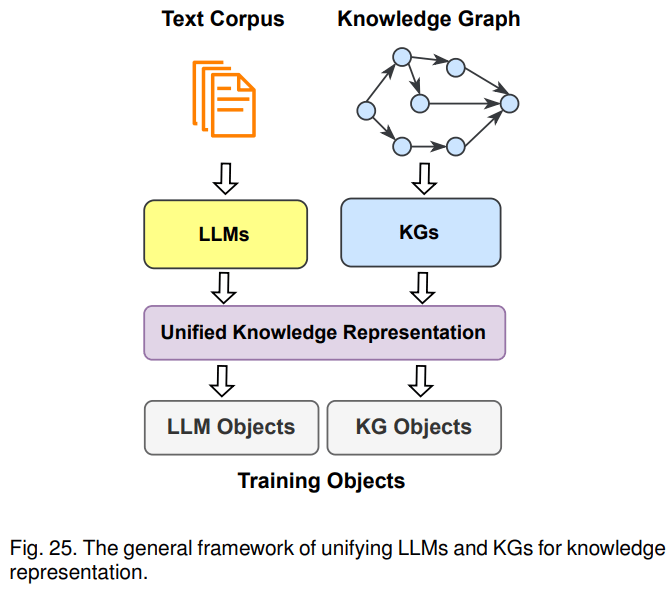
知识图谱与大模型结合方法概述
《Unifying Large Language Models and Knowledge Graphs: A Roadmap》总结了大语言模型和知识图谱融合的三种路线:1)KG增强的LLM,可在LLMs的预训练和推理阶段引入KGs;2)LLM增强KG,LLM可用于KG构建、KG emb…...

ASO优化之如何制作Google Play的长短描述
应用的描述以及标题和图标是元数据中最关键的元素,可以影响用户是否决定下载我们的应用程序。简短描述的长度限制为80个字符,它提供了更多的有关应用背景信息的机会。 1、简短描述帮助用户快速了解我们应用。 确保内容丰富的同时,保持简洁和…...

Python-platform模块
platform目录 前言一、platform.system()二、platform.release()三、platform.python_version()四、platform.machine()五、platform.python_implementation()六、其他代码示例七、help总结前言 Python platform模块是一个用于获取和操作操作系统相关信息的内置模块。它提供了…...
检测自己的数据集,附带代码模型可以收敛)
Yolov5旋转框(斜框)检测自己的数据集,附带代码模型可以收敛
文章目录 1. 制作数据集1.1 标注数据集1.2标签转换1.3 数据集划分2. 环境搭建1.安装nms_rotated2.安装DOTA_devkit3. 代码讲解3.1坐标表示3.2 损失函数4.训练+测试链接后面附上百度网盘链接,内部包含数据集。 下一篇介绍tensorRT部署yolov5-obb 1. 制作数据集 标注软件为…...
嵌入式应用选择正确的系统设计方法:第三部分
产品质量低下的原因有很多,例如,产品制造粗糙,组件设计不当,架构不佳以及对产品的要求了解不多。点击领取嵌入式物联网学习路线 必须设计质量。 您不能测试出足够的错误来交付高质量的产品。的质量保证(QA)…...

pthread_attr_getstacksize 问题
最近公司里遇到一个线程栈大小的问题,借此机会刚好学习一下这个线程栈大小相关的函数。如果公司里用的还是比较老的代码的话,都是用的 pthread 库支持线程的,而不是 c11 里的线程类。主要有两个相关函数:pthread_attr_setstacksiz…...

anaconda常见语法
anaconda常见语法 一、镜像 1.添加镜像channel conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/2.删除镜像channel conda config --remove channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/3.展示目前已有的镜像…...

reactive与ref VCA
简介 Vue3 最大的一个变动应该就是推出了 CompositionAPI,可以说它受ReactHook 启发而来;它我们编写逻辑更灵活,便于提取公共逻辑,代码的复用率得到了提高,也不用再使用 mixin 担心命名冲突的问题。 ref 与 reactive…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

告别虚频困扰:用VASP+DynaPhoPy搞定高温材料声子谱的保姆级教程
高温材料声子谱计算实战:从虚频困境到非谐解决方案 引言:虚频问题的根源与突破路径 在计算材料学领域,声子谱分析是理解材料动力学稳定性和热力学性质的核心手段。然而许多研究者都遭遇过这样的困境:对实验合成的材料进行简谐近似…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参
Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参 【免费下载链接】gz-sim Open source robotics simulator. The latest version of Gazebo. 项目地址: https://gitcode.com/gh_mirrors/gz/gz-sim Gazebo Sim是一款功能强大的开源机器人模拟器ÿ…...

php有什么版本,php语言有几个版本
php有什么版本,php语言有几个版本PHP的大版本主要分四支:PHP4/PHP5/PHP6/PHP7 其中,PHP4由于太古老、对OO支持不力已基本被淘汰,请无视PHP4。 PHP6由于基本没有生产线上的应用,还基本只是一款概念产品,很多功能已在PHP…...