决策树、随机森林、极端随机树(ERT)
声明:本文仅为个人学习记录所用,参考较多,如有侵权,联系删除
决策树
通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?母亲:26。女儿:长的帅不帅?母亲:挺帅的。女儿:收入高不?母亲:不算很高,中等情况。女儿:是公务员不?母亲:是,在税务局上班呢。女儿:那好,我去见见。这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,下图表示了女孩的决策逻辑。
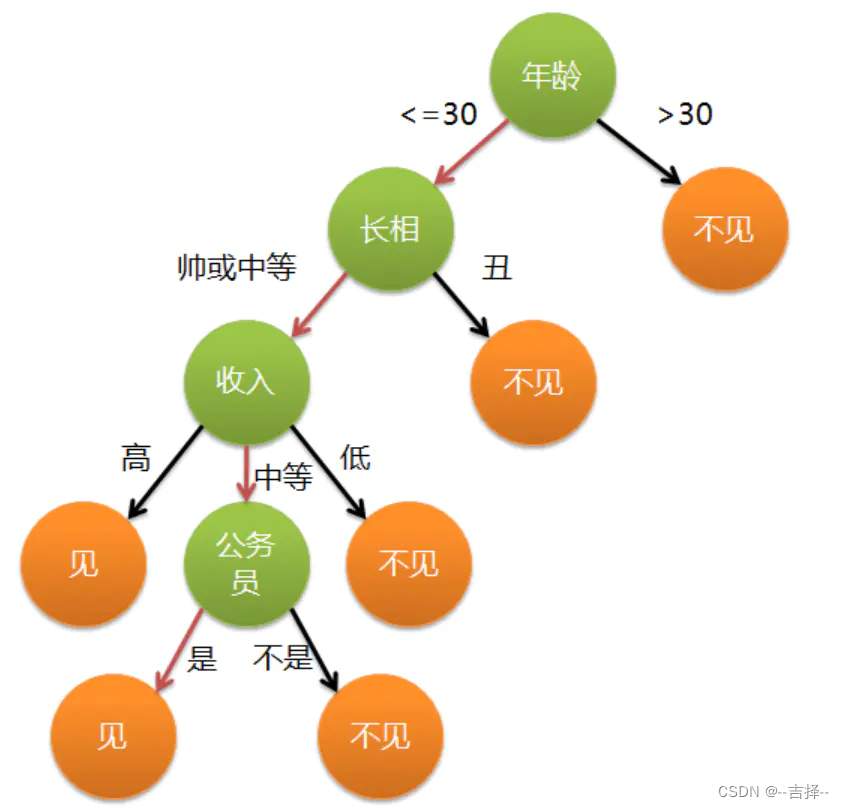
如果你作为一个女生,你会优先考虑哪个条件:长相?收入?还是年龄。在考虑年龄条件时使用25岁为划分点,还是35岁为划分点。有这么多条件,用哪个条件特征先做if,哪个条件特征后做if比较优呢?还有怎么确定用特征中的哪个数值作为划分的标准。这就是决策树机器学习算法的关键了。
集成学习
假设我们现在提出了一个复杂的问题,并抛给几千个随机的人,然后汇总他们的回答。在很多情况下,我们可以看到这种汇总后的答案会比一个专家的答案要更好。这个称为“群众的智慧”。同理,如果我们汇总一组的预测器(例如分类器与回归器)的预测结果,我们可以经常获取到比最优的单个预测器要更好的预测结果。这一组预测器称为一个集成,所以这种技术称为集成学习,一个集成学习算法称为一个集成方法。
随机森林
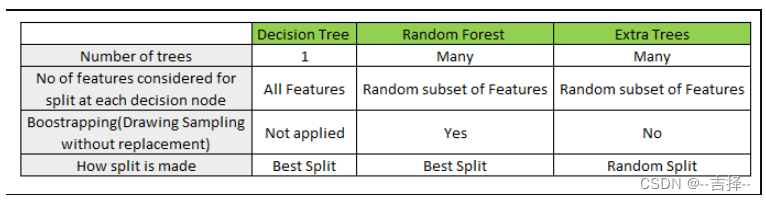
假如训练一组决策树分类器,每个都在训练集的一组不同的随机子集上进行训练。在做决策时,我们可以获取所有单个决策树的预测结果,然后根据各个结果对每个类别的投票数,最多票的类别获胜。这种集成决策树称为随机森林。尽管它非常简单,不过它是当前最强大的机器学习算法之一。
一个树和1000个树
假如有一个弱学习者(weak learner,也就是说它的预测能力仅比随机猜稍微高一点),分类正确的概率是51%。本来不应该考虑这种弱分类器(分类能力强的还有很多种方法),但是,假如我们考虑把1000个这样的树放在一起(一个集合),预测结果如何呢?
·每个决策树都使用所有数据作为训练集
·节点的选择是通过在所有特征中进行搜索选出最好的划分方式得到的
·每个决策树的最大深度都是1
import pandas as pd
import numpy as np# 导入鸢尾花数据集
from sklearn.datasets import load_iris# 从样本中随机按比例选取训练集和测试集
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
# To measure performance
from sklearn import metrics
# 该数据集一共包含4个特征变量,1个类别变量。共有150个样本。
iris = load_iris()
X = pd.DataFrame(iris.data[:, :], columns = iris.feature_names[:])
# print(X)
y = pd.DataFrame(iris.target, columns =["Species"])# 划分数据集
# 随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。
# 随便填一个大于0的数据就能保证,其他参数一样的情况下得到的随机数组是一样的。但填0或不填,每次都会不一样。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 20, random_state = 100)# 定义决策树
stump = DecisionTreeClassifier(max_depth = 1)# bagging集成方法
ensemble = BaggingClassifier(estimator = stump, n_estimators = 1000,bootstrap = False)# 训练分类器
stump.fit(X_train, np.ravel(y_train))
ensemble.fit(X_train, np.ravel(y_train))# 预测
y_pred_stump = stump.predict(X_test)
y_pred_ensemble = ensemble.predict(X_test)# 决策表现
stump_accuracy = metrics.accuracy_score(y_test, y_pred_stump)
ensemble_accuracy = metrics.accuracy_score(y_test, y_pred_ensemble)print(f"The accuracy of the stump is {stump_accuracy*100:.1f} %")
print(f"The accuracy of the ensemble is {ensemble_accuracy*100:.1f} %")
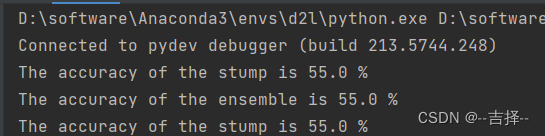
可以看到无论是一棵树还是1000棵树,预测准确率都一样。
随机森林-RandomForest
上面1000棵树虽然构成了一片森林,但是每棵树都一样,相当于你问一只兔子爱吃青菜还是爱吃肉,问1000遍,结果都是一样的,这不叫群众的智慧!
如果我们:
·每个决策树都使用随机采样得到的子集作为训练集,采样方式为bootstrap(一种有放回抽样)
·节点的选择是通过在子集中随机选择特征(不是所有特征)中进行搜索选出最好的划分方式得到的
·每个决策树的最大深度都是1
# max_features:寻找最佳切分时考虑的最大特征数,默认是所有特征都用
# splitter:用于在每个节点上选择拆分的策略。可选“best”, “random”,默认“best”。
stump = DecisionTreeClassifier(max_depth = 1, splitter = "best", max_features = "sqrt")# 随机森林
# n_estimators基分类器的个数
ensemble = BaggingClassifier(estimator = stump, n_estimators = 1000,bootstrap = True)
stump.fit(X_train, np.ravel(y_train))
ensemble.fit(X_train, np.ravel(y_train))y_pred_tree = stump.predict(X_test)
y_pred_ensemble = ensemble.predict(X_test)stump_accuracy = metrics.accuracy_score(y_test, y_pred_stump)
ensemble_accuracy = metrics.accuracy_score(y_test, y_pred_ensemble)print(f"The accuracy of the stump is {stump_accuracy*100:.1f} %")
print(f"The accuracy of the Random Forest is {ensemble_accuracy*100:.1f} %")

群众的智慧这不就体现出来了吗!
在不同的训练集随机子集上进行训练(也就是将训练集上的数据随机抽样为若干个子集,然后用这些不同子集在同一种模型上训练,这样就形成了不一样的预测器)
极度随机树-Extremely randomized trees,Extra tree
在选定了划分特征后,RF的决策树会基于信息增益,基尼系数,均方差之类的原则,选择一个最优的特征值划分点,这和传统的决策树相同。但是Extra tree比较的激进,会随机的选择一个特征值来划分决策树。
由于随机选择了特征值的划分点位,而不是最优点位,这样会导致生成的决策树的规模一般会大于RF所生成的决策树。也就是说,模型的方差相对于RF进一步减少,但是bias相对于RF进一步增大。在某些时候,Extra tree的泛化能力比RF更好.
stump = DecisionTreeClassifier(max_depth=1, splitter="random", max_features="sqrt")
ensemble = BaggingClassifier(estimator=stump, n_estimators=1000, bootstrap=False)stump.fit(X_train, np.ravel(y_train))
ensemble.fit(X_train, np.ravel(y_train))y_pred_tree = stump.predict(X_test)
y_pred_ensemble = ensemble.predict(X_test)stump_accuracy = metrics.accuracy_score(y_test, y_pred_stump)
ensemble_accuracy = metrics.accuracy_score(y_test, y_pred_ensemble)print(f"The accuracy of the stump is {stump_accuracy * 100:.1f} %")
print(f"The accuracy of the Extra Trees is {ensemble_accuracy * 100:.1f} %")

补充 hard voting soft voting

补充 Bootstrap
Bootstrap又称自展法、自举法、自助法、靴带法 , 是统计学习中一种重采样(Resampling)技术,用来估计标准误差、置信区间和偏差
子样本之于样本,可以类比样本之于总体
举例
栗子:我要统计鱼塘里面的鱼的条数,怎么统计呢?
假设鱼塘总共有鱼N,不知道N是多少条
步骤:
承包鱼塘,不让别人捞鱼(规定总体分布不变)。
自己捞鱼,捞100条,都打上标签(构造样本)
把鱼放回鱼塘,休息一晚(使之混入整个鱼群,确保之后抽样随机)
开始捞鱼,每次捞100条,数一下,自己昨天标记的鱼有多少条,占比多少(一次重采样取分布)。
然后把这100条又放回去
重复3,4步骤n次。建立分布。
(原理是中心极限定理)
假设一下,第一次重新捕鱼100条,发现里面有标记的鱼12条,记下为12%,
放回去,再捕鱼100条,发现标记的为9条,记下9%,
重复重复好多次之后,假设取置信区间95%,
你会发现,每次捕鱼平均在10条左右有标记,
它怎么来的呢?
10/N=10%
所以,我们可以大致推测出鱼塘有1000条左右。
其实是一个很简单的类似于一个比例问题。这也是因为提出者Efron给统计学顶级期刊投稿的时候被拒绝的理由–“太简单”。这也就解释了,为什么在小样本的时候,bootstrap效果较好,
你这样想,如果我想统计大海里有多少鱼,你标记100000条也没用啊,因为实际数量太过庞大,
你取的样本相比于太过渺小,最实际的就是,你下次再捕100000的时候,发现一条都没有标记,就尴尬了。。。
参考文献
[1] 决策树(Decision Tree)
[2] 集成学习与随机森林(一)投票分类器
[3] Hard Voting 与 Soft Voting 的对比
[4] 统计学中的Bootstrap方法(Bootstrap抽样)用来训练bagging算法,如果随机森林Random Forests
[5] An Intuitive Explanation of Random Forest and Extra Trees Classifiers
相关文章:
决策树、随机森林、极端随机树(ERT)
声明:本文仅为个人学习记录所用,参考较多,如有侵权,联系删除 决策树 通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿&#x…...

软件测试之因果图法
因果图法 1. 概述 因果图法是一种**利用图解法分析输入条件、输出结果的各种组合情况,**从而设计测试用例的方法. 因果图法适用于有多个输入和多个输出,而且输入和输入之间有相互的组合关系,输入和输出之间有相互的制约和依赖关系. 使用场景和判定表…...
vue中子组件间接修改父组件传递过来的值
一、前言 Vue官方文档Props单向数据流讲解 Vue中遵循单向数据流,所有的 props 都遵循着单向绑定原则,props 因父组件的更新而变化,自然地将新的状态向下流往子组件,而不会逆向传递。这避免了子组件意外修改父组件的状态的情况&a…...

Java I/O
前言 关于IO, 想必你听过很多中I/O方式, 有的是OS视角的, 有的是JDK本身支持的, 有的是纯实现视角。但是作为一个developer, 我希望你能先搞清楚上下文之后, 再去理解内容, 否则容易抬杠。这个上下文有横向和纵向两个维度。纵向维度包括JDK底层, JDK上层包装库, 开发框架(如Ne…...

pytorch学习日记之图片的简单卷积、池化
导入图片并转化为张量 import torch import torch.nn as nn import matplotlib.pyplot as plt import numpy as np from PIL import Image mymi Image.open("pic/123.png") # 读取图像转化为灰度图片转化为numpy数组 myimgray np.array(mymi.convert("L"…...

【java基础】抽象类和抽象方法
文章目录基本介绍抽象类抽象方法使用总结基本介绍 在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就…...

RDD的内核调度【博学谷学习记录】
RDD的依赖关系RDD的依赖: 指的一个RDD的形成可能是有一个或者多个RDD得出, 此时这个RDD和之前的RDD之间产生依赖关系在Spark中, RDD之间的依赖关系,主要有二种依赖关系:1- 窄依赖:目的: 为了实现并行计算操作, 并且提高容错的能力指的: 一个RDD上的一个分区的数据, 只能完整的交…...
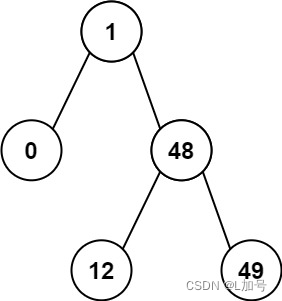
二叉树——二叉搜索树的最小绝对差
二叉搜索树的最小绝对差 链接 给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。 差值是一个正数,其数值等于两值之差的绝对值。 示例 1: 输入:root [4,2,6,1,3] 输出:1 示例 2&…...

git的使用(终端输入指令)下
文章目录前言1、git 分支创建分支查看分支切换分支合并分支删除分支2.提交到远程仓库远程提交链接一下自己仓库总结前言 上章链接 :git的使用(终端输入指令)上 我们接着上着来说 上章把 git 的 功能实现了一部分,本章我们接着上文…...

python使用influxdb-client管理InfluxDB的bucket
bucket的概念类似数据库的“库”,同时每个库中的数据都因为存在“时间戳”,每个数据都会有一个对应的时间点 influxdb-client-python官方github页面:https://github.com/influxdata/influxdb-client-python 管理bucket的官方示例࿱…...

【c++】模板2—类模板
文章目录类模板语法类模板与函数模板区别类模板中成员函数常见时机类模板对象做函数参数类模板与继承类模板成员函数类外实现类模板分文件编写类模板与友元类模板语法 类模板作用: 建立一个通用类,类中的成员数据类型可以不具体制定,用一个虚…...
)
基于SpringCloud的可靠消息最终一致性03:项目骨架代码(下)
上一节把整个项目的演示内容、项目结构、POM文件和配置文件都讲完了,接下来继续。 先安装并启动Nacos,然后在其中建立一个名为xiangwang-payment-dev.yaml的配置文件,内容为: # 指定运行环境 spring:autoconfigure:exclude: com.alibaba.druid.spring.boot.autoconfigure.D…...

linux如何彻底的删除文件
一、使用rm命令删除 直接用rm 先用ls -alt看下文件信息及拥有者等 可以看到拥有者是eve用户,所以在eve用户的终端中rm命令即可, 如果是root或者其他,则优先用root或其他账号进行删除 (base) eveEve:~$ ls -alt a.txt -rw-rw-r-- 1 eve eve …...

数据仓库Hive的安装和部署
1)去apache.hive.org官网下载hive 目前hive主要有三大版本,Hive1.x、Hive2.x、Hive3.x Hive1.x已经2年没有更新了,所以这个版本后续基本不会再维护了,不过这个版本已经迭代了很多年了,也是比较稳定的 Hive2.x最近一直…...

Python调用CANoe常见问题
一、Win32com已经安装成功但是在pycharm中提示错误 No module named win32com.clientPyCharm中出现unresolved reference的解决方法 一直提示需要升级pip版本Pywin32已成功安装,但仍提示没有win32com模块...
)
一起Talk Android吧(第五百零七回:图片滤镜ImageFilterView)
文章目录背景介绍功能介绍图片滤镜图片圆角图片缩放图片旋转图片平移各位看官们大家好,上一回中咱们说的例子是"如何调整组件在约束布局中的角度",这一回中咱们说的例子是" 图片滤镜ImageFilterView"。闲话休提,言归正转,…...
之间的区别)
Java 解释器和即时解释器(JIT)之间的区别
区别是: 翻译 .class (字节码文件) 的粒度和方式不同 解释器是一个逐条解释并执行字节码指令的组件,每次**只翻译一条**指令并执行,然后再翻译下一条指令。 它的翻译粒度是一条指令,而且是按需翻译&#x…...

Acwing 蓝桥杯 第二章 二分与前缀和
今天来补一下之前没写的总结,题是写完了,但是总结没写感觉没什么好总结的啊,就当打卡了789. 数的范围 - AcWing题库思路:一眼二分,典中典先排个序,再用lower_bound和upper_bound维护相同的数的左界和右界就…...

CSDN原力增长规则解读 实测一个月
CSDN原力越来越难了,当然,这对生态发展来说也是好事。介绍下原力增长有哪些渠道吧。发布原创文章:10分/次,每日上限为15分、2篇回答问题:1分/次,每日上限2分,2回答发动态:1分/次&…...
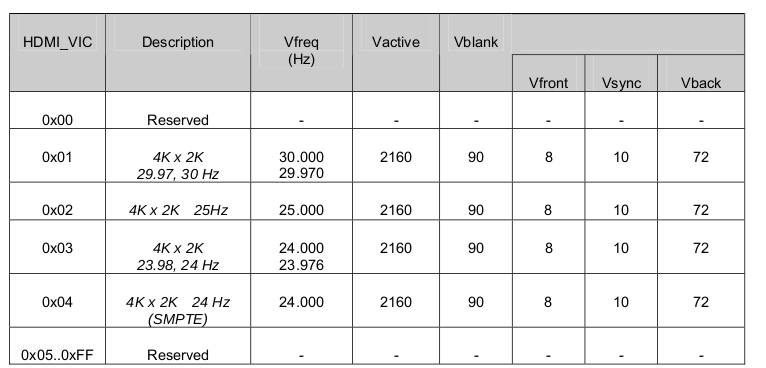
HDMI协议介绍(三)--InfoFrame
目录 Auxiliary Video information (AVI) InfoFrame AVI InfoFrame包结构 Header Body 举个例子 附录 Audio InfoFrame Audio InfoFrame包结构 Header Body Vendor Specific InfoFrame Vendor Specific InfoFrame包结构 Header Body AVI/AUDIO/VSI Infoframe都…...

如何高效使用DdddOcr:免费开源的离线验证码识别终极指南
如何高效使用DdddOcr:免费开源的离线验证码识别终极指南 【免费下载链接】ddddocr 带带弟弟 通用验证码识别OCR pypi版 项目地址: https://gitcode.com/gh_mirrors/dd/ddddocr 在当今数字世界中,验证码识别已成为自动化测试、数据采集和网络安全测…...

寄生电感容易被忽略,却是电路不稳定的隐形元凶
调试电路板的时候,最让人抓狂的并不是那些明面上能查到文档的参数问题。示波器一抓波形,明明电源电压已经稳定,负载也没动,可偏偏就是有那种挥之不去的毛刺,幅度不大,频率不低,排查了半天才发现…...

macOS OBS虚拟摄像头技术实现指南:CoreMediaIO架构与DAL插件开发
macOS OBS虚拟摄像头技术实现指南:CoreMediaIO架构与DAL插件开发 【免费下载链接】obs-mac-virtualcam ARCHIVED! This plugin is officially a part of OBS as of version 26.1. See note below for info on upgrading. 🎉🎉🎉Cr…...

为AI编程助手构建持久化项目记忆库:告别上下文遗忘,提升团队协作效率
1. 项目概述:为AI编程助手构建持久化项目记忆库如果你和我一样,每天都要和Claude Code、Cursor这些AI编程助手打交道,肯定遇到过这个烦人的问题:每次新开一个对话,AI就像得了失忆症,完全不记得你刚才在做什…...

喜马拉雅音频下载器:三分钟学会批量保存心爱内容
喜马拉雅音频下载器:三分钟学会批量保存心爱内容 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 在数字音频内容日益丰…...

5分钟极简安装:免费Ghidra逆向工程工具完整配置指南
5分钟极简安装:免费Ghidra逆向工程工具完整配置指南 【免费下载链接】ghidra_installer Helper scripts to set up OpenJDK 11 and scale Ghidra for 4K on Ubuntu 18.04 / 18.10 项目地址: https://gitcode.com/gh_mirrors/gh/ghidra_installer 你是否曾因复…...

Windows和Office激活难题终结者:KMS智能激活脚本全攻略
Windows和Office激活难题终结者:KMS智能激活脚本全攻略 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾为Windows系统那恼人的激活提醒而烦恼?是否因为Office突然…...

Hotkey Detective:Windows快捷键冲突终极解决方案,3分钟快速定位占用程序
Hotkey Detective:Windows快捷键冲突终极解决方案,3分钟快速定位占用程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/h…...

微信小程序二维码生成神器:5分钟搞定前端二维码生成
微信小程序二维码生成神器:5分钟搞定前端二维码生成 【免费下载链接】weapp-qrcode weapp.qrcode.js 在 微信小程序 中,快速生成二维码 项目地址: https://gitcode.com/gh_mirrors/we/weapp-qrcode 还在为微信小程序中的二维码功能而烦恼吗&#…...

企业AI转型的底层逻辑与路径选择
文章核心内容围绕企业如何实现AI原生转型展开。首先,强调AI转型重点在于如何实现“AI原生”,而非简单叠加AI功能。其次,提出AI产品应超越对话框,实现隐形化与自动化,并成为记录系统。再次,建议企业技术路径…...