基于深度学习的植物识别算法 - cnn opencv python 计算机竞赛
文章目录
- 0 前言
- 1 课题背景
- 2 具体实现
- 3 数据收集和处理
- 3 MobileNetV2网络
- 4 损失函数softmax 交叉熵
- 4.1 softmax函数
- 4.2 交叉熵损失函数
- 5 优化器SGD
- 6 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习的植物识别算法 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:4分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
植物在地球上是一种非常广泛的生命形式,直接关系到人类的生活环境,目前,植物识别主要依靠相关行业从业人员及有经验专家实践经验,工作量大、效率低。近年来,随着社会科技及经济发展越来越快,计算机硬件进一步更新,性能也日渐提高,数字图像采集设备应用广泛,设备存储空间不断增大,这样大量植物信息可被数字化。同时,基于视频的目标检测在模式识别、机器学习等领域得到快速发展,进而基于图像集分类方法研究得到发展。
本项目基于深度学习实现图像植物识别。
2 具体实现


3 数据收集和处理
数据是深度学习的基石
数据的主要来源有: 百度图片, 必应图片, 新浪微博, 百度贴吧, 新浪博客和一些专业的植物网站等
爬虫爬取的图像的质量参差不齐, 标签可能有误, 且存在重复文件, 因此必须清洗。清洗方法包括自动化清洗, 半自动化清洗和手工清洗。
自动化清洗包括:
- 滤除小尺寸图像.
- 滤除宽高比很大或很小的图像.
- 滤除灰度图像.
- 图像去重: 根据图像感知哈希.
半自动化清洗包括:
- 图像级别的清洗: 利用预先训练的植物/非植物图像分类器对图像文件进行打分, 非植物图像应该有较低的得分; 利用前一阶段的植物分类器对图像文件 (每个文件都有一个预标类别) 进行预测, 取预标类别的概率值为得分, 不属于原预标类别的图像应该有较低的得分. 可以设置阈值, 滤除很低得分的文件; 另外利用得分对图像文件进行重命名, 并在资源管理器选择按文件名排序, 以便于后续手工清洗掉非植物图像和不是预标类别的图像.
- 类级别的清洗
手工清洗: 人工判断文件夹下图像是否属于文件夹名所标称的物种, 这需要相关的植物学专业知识, 是最耗时且枯燥的环节, 但也凭此认识了不少的植物.
3 MobileNetV2网络
简介
MobileNet网络是Google最近提出的一种小巧而高效的CNN模型,其在accuracy和latency之间做了折中。
主要改进点
相对于MobileNetV1,MobileNetV2 主要改进点:
- 引入倒残差结构,先升维再降维,增强梯度的传播,显著减少推理期间所需的内存占用(Inverted Residuals)
- 去掉 Narrow layer(low dimension or depth) 后的 ReLU,保留特征多样性,增强网络的表达能力(Linear Bottlenecks)
- 网络为全卷积,使得模型可以适应不同尺寸的图像;使用 RELU6(最高输出为 6)激活函数,使得模型在低精度计算下具有更强的鲁棒性
- MobileNetV2 Inverted residual block 如下所示,若需要下采样,可在 DW 时采用步长为 2 的卷积
- 小网络使用小的扩张系数(expansion factor),大网络使用大一点的扩张系数(expansion factor),推荐是5~10,论文中 t = 6 t = 6t=6
倒残差结构(Inverted residual block )
ResNet的Bottleneck结构是降维->卷积->升维,是两边细中间粗
而MobileNetV2是先升维(6倍)-> 卷积 -> 降维,是沙漏形。
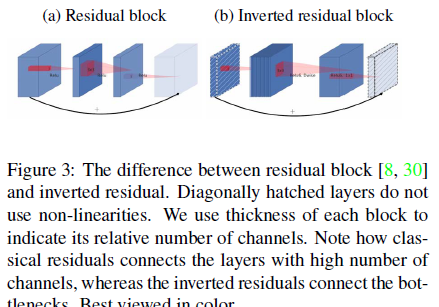 区别于MobileNetV1,
区别于MobileNetV1,
MobileNetV2的卷积结构如下:
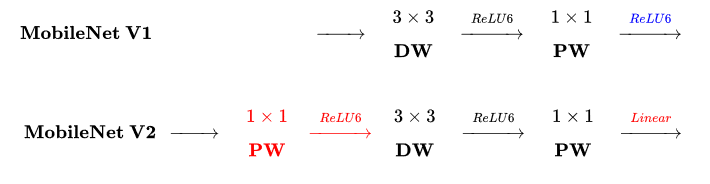
因为DW卷积不改变通道数,所以如果上一层的通道数很低时,DW只能在低维空间提取特征,效果不好。所以V2版本在DW前面加了一层PW用来升维。
同时V2去除了第二个PW的激活函数改用线性激活,因为激活函数在高维空间能够有效地增加非线性,但在低维空间时会破坏特征。由于第二个PW主要的功能是降维,所以不宜再加ReLU6。
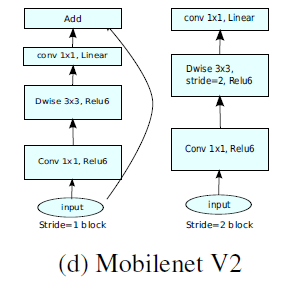
tensorflow相关实现代码
import tensorflow as tfimport numpy as npfrom tensorflow.keras import layers, Sequential, Modelclass ConvBNReLU(layers.Layer):def __init__(self, out_channel, kernel_size=3, strides=1, **kwargs):super(ConvBNReLU, self).__init__(**kwargs)self.conv = layers.Conv2D(filters=out_channel, kernel_size=kernel_size, strides=strides, padding='SAME', use_bias=False,name='Conv2d')self.bn = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='BatchNorm')self.activation = layers.ReLU(max_value=6.0) # ReLU6def call(self, inputs, training=False, **kargs):x = self.conv(inputs)x = self.bn(x, training=training)x = self.activation(x)return xclass InvertedResidualBlock(layers.Layer):def __init__(self, in_channel, out_channel, strides, expand_ratio, **kwargs):super(InvertedResidualBlock, self).__init__(**kwargs)self.hidden_channel = in_channel * expand_ratioself.use_shortcut = (strides == 1) and (in_channel == out_channel)layer_list = []# first bottleneck does not need 1*1 convif expand_ratio != 1:# 1x1 pointwise convlayer_list.append(ConvBNReLU(out_channel=self.hidden_channel, kernel_size=1, name='expand'))layer_list.extend([# 3x3 depthwise conv layers.DepthwiseConv2D(kernel_size=3, padding='SAME', strides=strides, use_bias=False, name='depthwise'),layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='depthwise/BatchNorm'),layers.ReLU(max_value=6.0),#1x1 pointwise conv(linear) # linear activation y = x -> no activation functionlayers.Conv2D(filters=out_channel, kernel_size=1, strides=1, padding='SAME', use_bias=False, name='project'),layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='project/BatchNorm')])self.main_branch = Sequential(layer_list, name='expanded_conv')def call(self, inputs, **kargs):if self.use_shortcut:return inputs + self.main_branch(inputs)else:return self.main_branch(inputs)
4 损失函数softmax 交叉熵
4.1 softmax函数
Softmax函数由下列公式定义
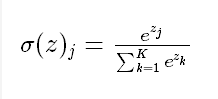
softmax 的作用是把 一个序列,变成概率。
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,所有概率的和将等于1。
python实现
def softmax(x):shift_x = x - np.max(x) # 防止输入增大时输出为nanexp_x = np.exp(shift_x)return exp_x / np.sum(exp_x)
PyTorch封装的Softmax()函数
dim参数:
-
dim为0时,对所有数据进行softmax计算
-
dim为1时,对某一个维度的列进行softmax计算
-
dim为-1 或者2 时,对某一个维度的行进行softmax计算
import torch x = torch.tensor([2.0,1.0,0.1]) x.cuda() outputs = torch.softmax(x,dim=0) print("输入:",x) print("输出:",outputs) print("输出之和:",outputs.sum())
4.2 交叉熵损失函数
定义如下:

python实现
def cross_entropy(a, y):return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))# tensorflow version
loss = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y), reduction_indices=[1]))# numpy version
loss = np.mean(-np.sum(y_*np.log(y), axis=1))
PyTorch实现
交叉熵函数分为二分类(torch.nn.BCELoss())和多分类函数(torch.nn.CrossEntropyLoss()
# 二分类 损失函数loss = torch.nn.BCELoss()l = loss(pred,real)# 多分类损失函数loss = torch.nn.CrossEntropyLoss()
5 优化器SGD
简介
SGD全称Stochastic Gradient Descent,随机梯度下降,1847年提出。每次选择一个mini-
batch,而不是全部样本,使用梯度下降来更新模型参数。它解决了随机小批量样本的问题,但仍然有自适应学习率、容易卡在梯度较小点等问题。
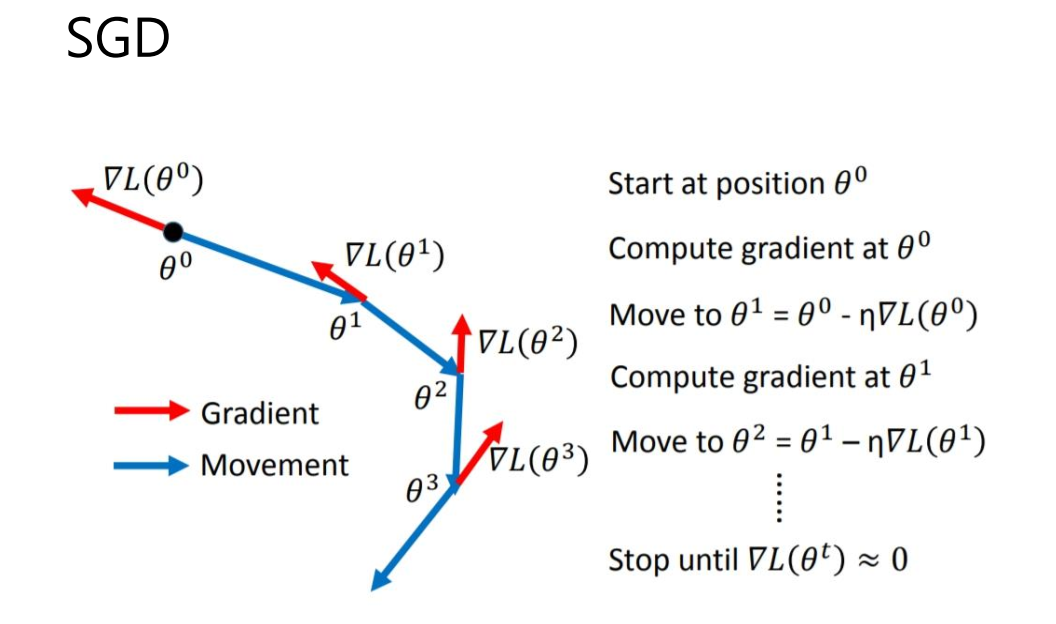
pytorch调用方法:
torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)
相关代码:
def step(self, closure=None):"""Performs a single optimization step.Arguments:closure (callable, optional): A closure that reevaluates the modeland returns the loss."""loss = Noneif closure is not None:loss = closure()for group in self.param_groups:weight_decay = group['weight_decay'] # 权重衰减系数momentum = group['momentum'] # 动量因子,0.9或0.8dampening = group['dampening'] # 梯度抑制因子nesterov = group['nesterov'] # 是否使用nesterov动量for p in group['params']:if p.grad is None:continued_p = p.grad.dataif weight_decay != 0: # 进行正则化# add_表示原处改变,d_p = d_p + weight_decay*p.datad_p.add_(weight_decay, p.data)if momentum != 0:param_state = self.state[p] # 之前的累计的数据,v(t-1)# 进行动量累计计算if 'momentum_buffer' not in param_state:buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()else:# 之前的动量buf = param_state['momentum_buffer']# buf= buf*momentum + (1-dampening)*d_pbuf.mul_(momentum).add_(1 - dampening, d_p)if nesterov: # 使用neterov动量# d_p= d_p + momentum*bufd_p = d_p.add(momentum, buf)else:d_p = buf# p = p - lr*d_pp.data.add_(-group['lr'], d_p)return loss
6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
基于深度学习的植物识别算法 - cnn opencv python 计算机竞赛
文章目录 0 前言1 课题背景2 具体实现3 数据收集和处理3 MobileNetV2网络4 损失函数softmax 交叉熵4.1 softmax函数4.2 交叉熵损失函数 5 优化器SGD6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习的植物识别算法 ** …...
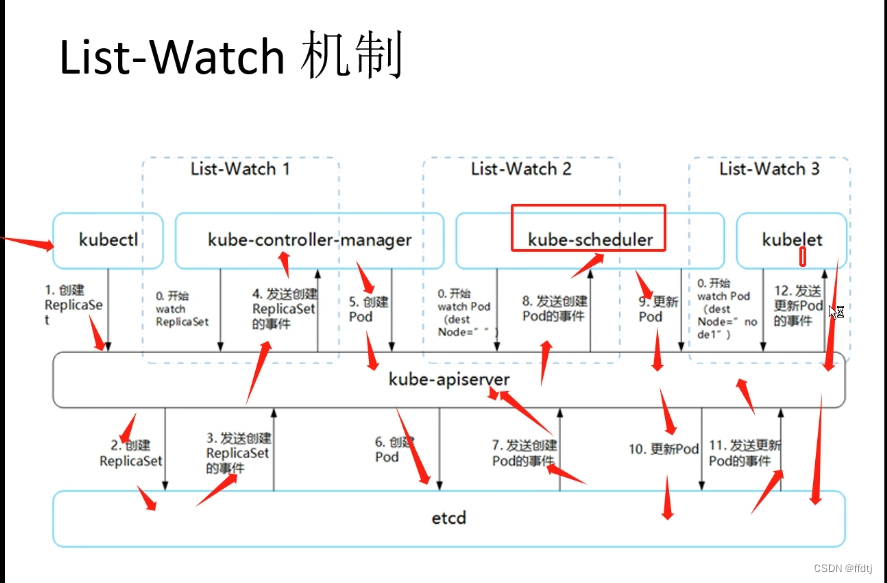
k8s调度约束
List-Watch Kubernetes 是通过 List-Watch的机制进行每个组件的协作,保持数据同步的,每个组件之间的设计实现了解耦。 List-Watch机制 工作机制:用户通过 kubectl请求给 APIServer 来建立一个 Pod。APIServer会将Pod相关元信息存入 etcd 中…...
面经(面试经验)第一步,从自我介绍开始说起
看到一位同学讲自己的面试步骤和过程,我心有所感,故此想整理下面试的准备工作。以便大家能顺利应对面试,通过面试... 求职应聘找工作,面试是必然的关卡,如今竞争激烈呀,想要得到自己喜欢的工作,…...
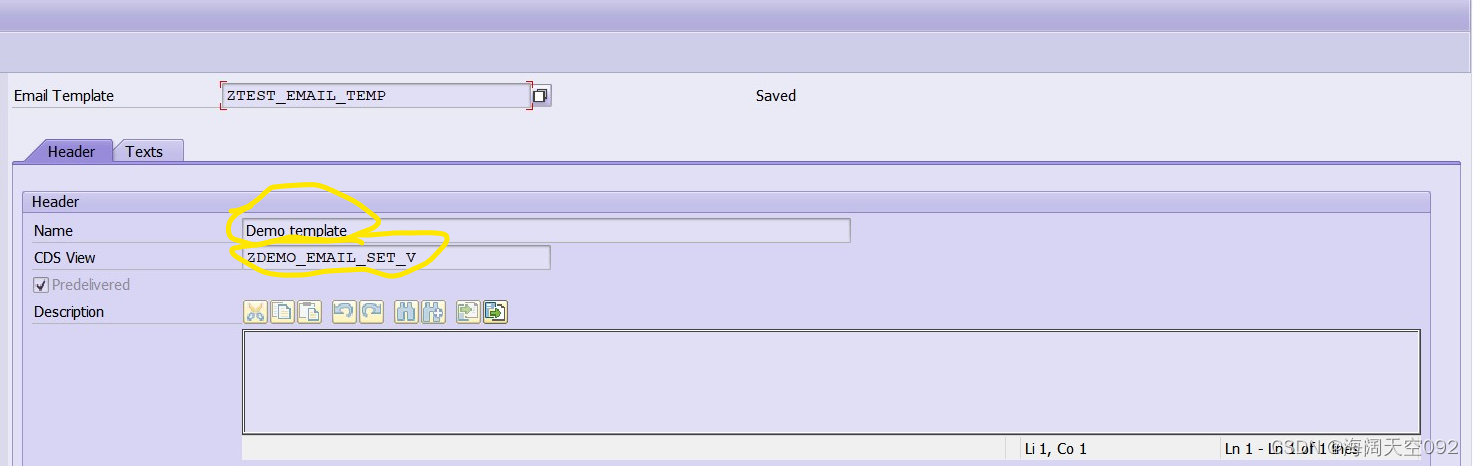
S/4 HANA 中的 Email Template
1 如何创建Email Template? 没有特定的事务用于创建电子邮件模板,我们可以将其创建为 SE80 事务中的存储库对象,如下所示: 1,选择包(或本地对象)并右键单击。 2,选择“创建”->“更多”->“电子邮件模板” 尽管如此,对于已有的Email Template,可以使用程序…...

\r\n和\n的区别 回车/换行 在不同系统下的区别
文章目录 1 \r\n和\n的区别2 什么是 回车/换行3 \r\n和\n 故事 1 \r\n和\n的区别 \r\n和\n是两个常见的控制字符符号,它们在计算机领域中有着不同的作用和用途。 \r\n在Windows系统中被广泛使用,而\n在Unix和Linux系统中更为常见。 在Windows操作系统中…...

机械应用笔记
1. 螺纹转换头:又名金属塞头,例如M20-M16;适合于大小螺纹转换用; 2. 螺纹分英制和公制,攻丝同样也有英制和公制之分; 3. DB9头制作,M6.5的线,用M6.5的钻头扩线孔,在根…...

机房精密空调发生内部设备通信故障不一会压缩机就停止工作,怎么处理?
环境: 山特AT-DA810U 精密空调 问题描述: 机房精密空调发生内部设备通信故障不一会压缩机就停止工作,怎么处理? 回风处不显示温湿度 解决方案: 1.进入诊断模式工程师密码333333 看到压缩机关闭了,强制输出测试一下压缩机正常 2.尝试更换温湿度传感器模块网口,重启…...

手机端运维管理系统——图扑 HT for Web
随着信息技术的快速发展,网络技术的应用涉及到人们生活的方方面面。其中,手机运维管理系统可提供数字化、智能化的方式,帮助企业和组织管理监控企业的 IT 环境,提高运维效率、降低维护成本、增强安全性、提升服务质量,…...

中期科技:智慧公厕打造智能化城市设施,提升公共厕所管理与服务体验
智慧公厕是利用先进的技术和创新的解决方案来改进公厕的设施和管理。借助物联网、互联网、5G/4G通信、人工智能、大数据、云计算等新兴技术的集成,智慧公厕具备了一系列令人惊叹的应用功能。从监测公厕内部人体活动状态、人体存在状态,到空气质量情况、环…...

innovus: set_ccopt_property的基本用法
我正在「拾陆楼」和朋友们讨论有趣的话题,你⼀起来吧? 拾陆楼知识星球入口 clock route clock route的net type分为三种,分别是root、trunk和leaf,其中root是指fanout超过routing_top_fanout_count约束的net,leaf是指…...

打造美团外卖新体验,HarmonyOS SDK持续赋能开发者共赢鸿蒙生态
从今年8月起,所有升级到HarmonyOS 4的手机用户在美团外卖下单后,可通过屏幕上的一个“小窗口”,随时追踪到“出餐、取餐、送达”等订单状态。这个能让用户实时获悉订单进度的神奇“小窗口”,就是实况窗功能。 实况窗:简…...

Realtek 5G pcie网卡 RTL8126-CG简介
总shu:PCIE 5G网卡方案“RTL8126-CG”采用QFN56封装,面积8 x 8毫米,非常小巧,提供一个RJ-45网口、两个USB 3.x接口。它走的是PCIe 3.0 x1系统通道,搭配超五类网线,可以在长达100米的距离上提供满血的5Gbps网…...
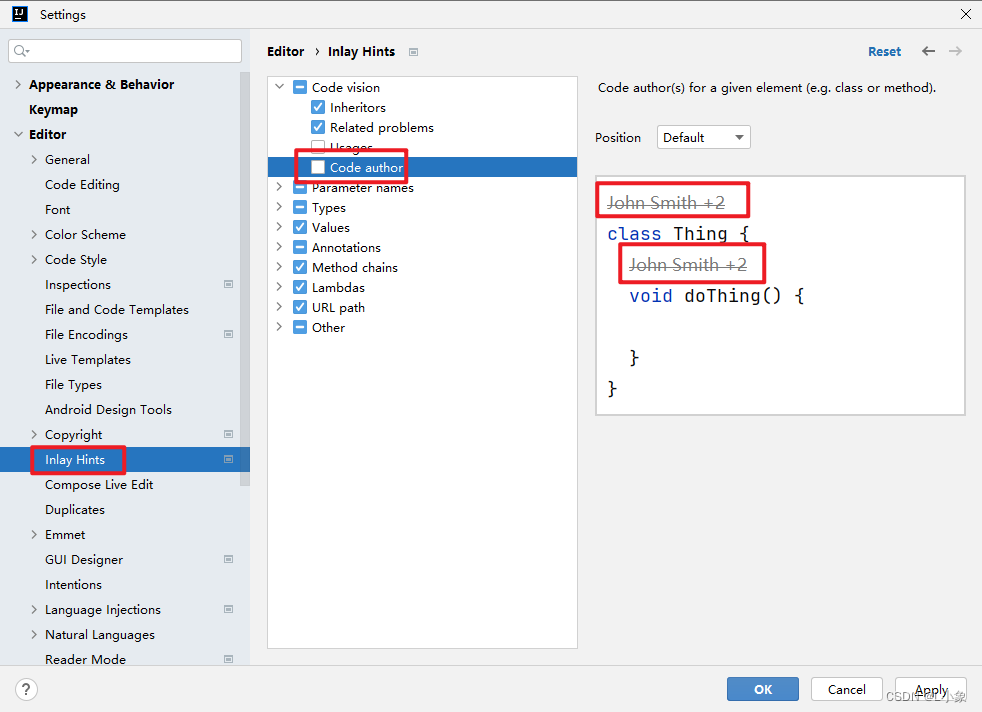
新版Idea显示Git提交人信息
新版Idea的类和方法上会展示开发者信息 不想展示的话可以做以下配置:...

外贸网站建设攻略:如何建设一个高效的外贸网站
外贸网站是外贸企业展示自己的产品和服务,吸引和沟通国外客户,实现网络营销的重要工具。一个高效的外贸网站不仅要有美观的界面,还要有强大的功能和优化。那么,九凌网络分享如何建设一个高效的外贸网站呢? 第一步&…...

【机器学习合集】模型设计之网络宽度和深度设计 ->(个人学习记录笔记)
文章目录 网络宽度和深度设计1. 什么是网络深度1.1 为什么需要更深的模型浅层学习的缺陷深度网络更好拟合特征学习更加简单 2. 基于深度的模型设计2.1 AlexNet2.2 AlexNet工程技巧2.3 VGGNet 3. 什么是网络宽度3.1 为什么需要足够的宽度 4. 基于宽度模型的设计4.1 经典模型的宽…...

使用Objective-C和ASIHTTPRequest库进行Douban电影分析
概述 Douban是一个提供图书、音乐、电影等文化内容的社交网站,它的电影频道包含了大量的电影信息和用户评价。本文将介绍如何使用Objective-C语言和ASIHTTPRequest库进行Douban电影分析,包括如何获取电影数据、如何解析JSON格式的数据、如何使用代理IP技…...

2.数据结构-链表
概述 目标 链表的存储结构和特点链表的几种分类及各自的存储结构链表和数组的差异刷题(反转链表) 概念及存储结构 先来看一下动态数组 ArrayList 存在哪些弊端 插入,删除时间复杂度高需要一块连续的存储空间,对内存要求比较高,比如要申请…...
B站数据质量保障体系建设与实践
本文将分享 B 站数据质量保障体系的建设和实践。文章将关注数仓和建模的相关方法论,讲解 B 站数仓平台团队在数仓建设和建模过程中所做的工作,并分享质量保障方面取得的成果。 一、背景目标 首先,分享一下 B 站数据质量保障的背景和目标。 …...

uniapp开发小程序无法上传图片的解决方法
登录小程序后台,第一步菜单栏 设置 第二步,用户隐私保护 更新 第三步 选2 第四步 勾选需要的接口,并说明 等审核通过后,一会就能正常上传图片。...

shell基础回顾
0.vim命令 vim gg 移动到文档第一行 G 移动到文档最后一行 :set nu 显示行号 :set noun 取消行号 nG 移动到指定n行,例如20G $ 移动到行尾 0 移动到行头 clrtf 屏幕向下移动一页 clrtb 屏幕向上移动一页 :%sword1word2g 搜索文本ÿ…...

FanControl深度配置指南:解决Windows散热控制三大痛点
FanControl深度配置指南:解决Windows散热控制三大痛点 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa…...

排序算法指南:归并排序
前言:归并排序的核心思想是利用分治法(Divide and Conquer)策略,它将一个大的问题分解成小的、容易解决的子问题,然后将子问题的解合并起来,从而得到原问题的解。一、归并排序的核心思想分(Divi…...

3种方法在Windows上直接安装Android应用:告别模拟器的完整指南
3种方法在Windows上直接安装Android应用:告别模拟器的完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了笨重的Android模拟器࿱…...

.NET 11原生AI推理引擎深度评测:实测TensorRT/ONNX Runtime/ML.NET在x64与ARM64服务器上提速3.8倍的关键配置
第一章:.NET 11原生AI推理引擎的演进与企业级定位.NET 11标志着微软在统一AI与传统企业开发范式上的关键跃迁——其内置的原生AI推理引擎(Native AI Inference Engine)不再依赖外部Python运行时或模型服务桥接层,而是深度集成于Co…...

PL/SQL:xml数据
在PL/SQL中,使用Oracle数据库提供的XML解析功能来处理XML数据。Oracle数据库提供了多种方式来处理XML数据,包括使用内置的XML数据类型、XMLTable函数、XML序列和XPath查询等。 1. 使用XMLTypeXMLType是Oracle提供的一个内置类型,用于存储和操…...

ScriptCat脚本猫完整指南:为什么它是浏览器脚本管理的终极选择
ScriptCat脚本猫完整指南:为什么它是浏览器脚本管理的终极选择 【免费下载链接】scriptcat ScriptCat, a browser extension that can execute userscript; 脚本猫,一个可以执行用户脚本的浏览器扩展 项目地址: https://gitcode.com/gh_mirrors/sc/scr…...

【VirtualBox】Vbox 7.2.6 不让安装在其他盘?这篇保姆级权限修复指南让你 D 盘起飞
在编程的艺术世界里,代码和灵感需要寻找到最佳的交融点,才能打造出令人为之惊叹的作品。 而在这座秋知叶i博客的殿堂里,我们将共同追寻这种完美结合,为未来的世界留下属于我们的独特印记。 【VirtualBox】Vbox 7.2.6 不让安装在其他盘?这篇保姆级权限修复指南让你 D 盘起飞…...

Testsigma企业级自动化测试平台架构设计与高可用部署指南
Testsigma企业级自动化测试平台架构设计与高可用部署指南 【免费下载链接】testsigma Testsigma is an agentic test automation platform powered by AI-coworkers that work alongside QA teams to simplify testing, accelerate releases and improve quality across web, m…...

使用Anaconda配置清华镜像源加速PyTorch安装
1. 为什么需要配置清华镜像源? 如果你在国内使用Anaconda安装PyTorch,可能会遇到下载速度慢、安装失败的问题。这主要是因为PyTorch的默认下载源位于国外服务器,网络传输距离远,再加上某些网络限制,导致下载速度很不理…...

如何用Calibre-Douban插件解决豆瓣API关闭后的电子书元数据管理难题
如何用Calibre-Douban插件解决豆瓣API关闭后的电子书元数据管理难题 【免费下载链接】calibre-douban Calibre new douban metadata source plugin. Douban no longer provides book APIs to the public, so it can only use web crawling to obtain data. This is a calibre D…...