Azure 机器学习 - 使用 AutoML 和 Python 训练物体检测模型
目录
- 一、Azure环境准备
- 二、计算目标设置
- 三、试验设置
- 四、直观呈现输入数据
- 五、上传数据并创建 MLTable
- 六、配置物体检测试验
- 适用于图像任务的自动超参数扫描 (AutoMode)
- 适用于图像任务的手动超参数扫描
- 作业限制
- 七、注册和部署模型
- 获取最佳试用版
- 注册模型
- 配置联机终结点
- 创建终结点
- 配置联机部署
- 创建部署
- 更新流量
- 八、测试部署
- 九、直观呈现检测结果
- 十、清理资源
本教程介绍如何通过 Azure 机器学习 Python SDK v2 使用 Azure 机器学习自动化 ML 训练物体检测模型。 此物体检测模型可识别图像是否包含对象(如罐、纸箱、奶瓶或水瓶)。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、Azure环境准备
-
若要使用 Azure 机器学习,你首先需要一个工作区。 如果没有工作区,请完成创建开始使用所需的资源以创建工作区并详细了解如何使用它。
-
此功能支持 Python 3.6 或 3.7
-
下载并解压缩 odFridgeObjects.zip 数据文件*。 数据集以 Pascal VOC 格式进行注释,其中每个图像对应一个 xml 文件。 每个 xml 文件都包含有关其对应图像文件所在位置的信息,还包含有关边界框和对象标签的信息。 若要使用此数据,首先需要将其转换为所需的 JSONL 格式,如笔记本的将下载的数据转换为 JSONL 部分中所示。
-
使用计算实例来学习本教程,无需安装其他软件。 (请参阅如何创建计算实例。)或者安装 CLI/SDK 以使用你自己的本地环境。
-
适用于:Python SDK azure-ai-ml v2(当前版本)
使用以下命令安装 Azure 机器学习 Python SDK v2:
卸载以前的预览版:
pip uninstall azure-ai-ml
安装 Azure 机器学习 Python SDK v2:
pip install azure-ai-ml azure-identity
二、计算目标设置
首先需要设置用于自动化 ML 模型训练的计算目标。 用于图像任务的自动化 ML 模型需要 GPU SKU。
本教程将使用 NCsv3 系列(具有 V100 GPU),因为此类计算目标会使用多个 GPU 来加速训练。 此外,还可以设置多个节点,以在优化模型的超参数时利用并行度。
以下代码创建一个大小为 Standard_NC24s_v3 的 GPU 计算,其中包含四个节点。
from azure.ai.ml.entities import AmlCompute
compute_name = "gpu-cluster"
cluster_basic = AmlCompute(name=compute_name,type="amlcompute",size="Standard_NC24s_v3",min_instances=0,max_instances=4,idle_time_before_scale_down=120,
)
ml_client.begin_create_or_update(cluster_basic)
稍后在创建特定于任务的 automl 作业时会用到此计算。
三、试验设置
可以使用试验来跟踪模型训练作业。
稍后在创建特定于任务的 automl 作业时会用到此试验名称。
exp_name = "dpv2-image-object-detection-experiment"
四、直观呈现输入数据
以 JSONL(JSON 行)格式准备好输入图像数据后,就可以直观呈现图像的地面实况边界框。 若要执行此操作,请确保你已安装 matplotlib。
%pip install --upgrade matplotlib
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import matplotlib.patches as patches
from PIL import Image as pil_image
import numpy as np
import json
import osdef plot_ground_truth_boxes(image_file, ground_truth_boxes):# Display the imageplt.figure()img_np = mpimg.imread(image_file)img = pil_image.fromarray(img_np.astype("uint8"), "RGB")img_w, img_h = img.sizefig,ax = plt.subplots(figsize=(12, 16))ax.imshow(img_np)ax.axis("off")label_to_color_mapping = {}for gt in ground_truth_boxes:label = gt["label"]xmin, ymin, xmax, ymax = gt["topX"], gt["topY"], gt["bottomX"], gt["bottomY"]topleft_x, topleft_y = img_w * xmin, img_h * yminwidth, height = img_w * (xmax - xmin), img_h * (ymax - ymin)if label in label_to_color_mapping:color = label_to_color_mapping[label]else:# Generate a random color. If you want to use a specific color, you can use something like "red".color = np.random.rand(3)label_to_color_mapping[label] = color# Display bounding boxrect = patches.Rectangle((topleft_x, topleft_y), width, height,linewidth=2, edgecolor=color, facecolor="none")ax.add_patch(rect)# Display labelax.text(topleft_x, topleft_y - 10, label, color=color, fontsize=20)plt.show()def plot_ground_truth_boxes_jsonl(image_file, jsonl_file):image_base_name = os.path.basename(image_file)ground_truth_data_found = Falsewith open(jsonl_file) as fp:for line in fp.readlines():line_json = json.loads(line)filename = line_json["image_url"]if image_base_name in filename:ground_truth_data_found = Trueplot_ground_truth_boxes(image_file, line_json["label"])breakif not ground_truth_data_found:print("Unable to find ground truth information for image: {}".format(image_file))
对于任何给定的图像,利用上述帮助程序函数,可以运行以下代码来显示边界框。
image_file = "./odFridgeObjects/images/31.jpg"
jsonl_file = "./odFridgeObjects/train_annotations.jsonl"plot_ground_truth_boxes_jsonl(image_file, jsonl_file)
五、上传数据并创建 MLTable
为了将数据用于训练,请将数据上传到 Azure 机器学习工作区的默认 Blob 存储并将其注册为资产。 注册数据的好处包括:
- 便于与团队其他成员共享
- 对元数据(位置、描述等)进行版本控制
- 世系跟踪
# Uploading image files by creating a 'data asset URI FOLDER':from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import Inputmy_data = Data(path=dataset_dir,type=AssetTypes.URI_FOLDER,description="Fridge-items images Object detection",name="fridge-items-images-object-detection",
)uri_folder_data_asset = ml_client.data.create_or_update(my_data)print(uri_folder_data_asset)
print("")
print("Path to folder in Blob Storage:")
print(uri_folder_data_asset.path)
下一步是使用 jsonl 格式的数据创建 MLTable,如下所示。 MLtable 会将数据打包为一个可供训练使用的对象。
paths:- file: ./train_annotations.jsonl
transformations:- read_json_lines:encoding: utf8invalid_lines: errorinclude_path_column: false- convert_column_types:- columns: image_urlcolumn_type: stream_info
可以使用以下代码从训练和验证 MLTable 创建数据输入:
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(type=AssetTypes.MLTABLE, path=training_mltable_path)# Validation MLTable defined locally, with local data to be uploaded
my_validation_data_input = Input(type=AssetTypes.MLTABLE, path=validation_mltable_path)# WITH REMOTE PATH: If available already in the cloud/workspace-blob-store
# my_training_data_input = Input(type=AssetTypes.MLTABLE, path="azureml://datastores/workspaceblobstore/paths/vision-classification/train")
# my_validation_data_input = Input(type=AssetTypes.MLTABLE, path="azureml://datastores/workspaceblobstore/paths/vision-classification/valid")
六、配置物体检测试验
若要为图像相关任务配置自动化 ML 作业,请创建特定于任务的 AutoML 作业。
# Create the AutoML job with the related factory-function.image_object_detection_job = automl.image_object_detection(compute=compute_name,experiment_name=exp_name,training_data=my_training_data_input,validation_data=my_validation_data_input,target_column_name="label",primary_metric=ObjectDetectionPrimaryMetrics.MEAN_AVERAGE_PRECISION,tags={"my_custom_tag": "My custom value"},
)
适用于图像任务的自动超参数扫描 (AutoMode)
在 AutoML 作业中,可以执行自动超参数扫描,以查找最佳模型(我们将此功能称为 AutoMode)。 你将仅指定试用次数;不需要超参数搜索空间、采样方法和提前终止策略。 系统会自动根据试用次数确定要扫描的超参数空间的区域。 介于 10 到 20 之间的值可能适用于许多数据集。
然后,你可以提交作业来训练图像模型。
将 AutoML 作业配置为所需的设置后,就可以提交作业了。
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(image_object_detection_job
) # submit the job to the backendprint(f"Created job: {returned_job}")
适用于图像任务的手动超参数扫描
在 AutoML 作业中,可以使用 model_name 参数指定模型体系结构,并配置设置以对定义的搜索空间执行超参数扫描,以查找最佳模型。
在本示例中,我们将使用 yolov5 和 fasterrcnn_resnet50_fpn 训练一个物体检测模型,这两者都在 COCO 上预先进行了训练,COCO 是一个大规模物体检测、分段和字幕数据集,其中包含 80 多个标签类别的数千个带标签的图像。
可以对已定义的搜索空间执行超参数扫描,以查找最佳模型。
作业限制
可以通过在限制设置中为作业指定 timeout_minutes``max_trials 和 max_concurrent_trials 来控制 AutoML 映像训练作业上花费的资源。 请参阅有关作业限制参数的详细说明。
# Set limits
image_object_detection_job.set_limits(timeout_minutes=60,max_trials=10,max_concurrent_trials=2,
)
以下代码定义了搜索空间,准备对每个已定义的体系结构 yolov5 和 fasterrcnn_resnet50_fpn 进行超参数扫描。 在搜索空间中,指定 learning_rate、optimizer、lr_scheduler 等的值范围,以便 AutoML 在尝试生成具有最佳主要指标的模型时从中进行选择。 如果未指定超参数值,则对每个体系结构使用默认值。
对于优化设置,通过使用 random sampling_algorithm,借助随机抽样从此参数空间中选取样本。 上面配置的作业限制可以让自动化 ML 尝试使用这些不同样本总共进行 10 次试验,在使用四个节点进行设置的计算目标上一次运行两次试验。 搜索空间的参数越多,查找最佳模型所需的试验次数就越多。
还使用了“Bandit 提前终止”策略。 此策略将终止性能不佳的试用;也就是那些与最佳性能试用版相差不在 20% 容许范围内的试用版,这样可显著节省计算资源。
# Configure sweep settings
image_object_detection_job.set_sweep(sampling_algorithm="random",early_termination=BanditPolicy(evaluation_interval=2, slack_factor=0.2, delay_evaluation=6),
)
# Define search space
image_object_detection_job.extend_search_space([SearchSpace(model_name=Choice(["yolov5"]),learning_rate=Uniform(0.0001, 0.01),model_size=Choice(["small", "medium"]), # model-specific# image_size=Choice(640, 704, 768), # model-specific; might need GPU with large memory),SearchSpace(model_name=Choice(["fasterrcnn_resnet50_fpn"]),learning_rate=Uniform(0.0001, 0.001),optimizer=Choice(["sgd", "adam", "adamw"]),min_size=Choice([600, 800]), # model-specific# warmup_cosine_lr_warmup_epochs=Choice([0, 3]),),]
)
定义搜索空间和扫描设置后,便可以提交作业以使用训练数据集训练图像模型。
将 AutoML 作业配置为所需的设置后,就可以提交作业了。
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(image_object_detection_job
) # submit the job to the backendprint(f"Created job: {returned_job}")
执行超参数扫描时,使用 HyperDrive UI 直观呈现所尝试的不同试用版会很有用。 可以导航到此 UI,方法是从上级(即 HyperDrive 父作业)转到主 automl_image_job 的 UI 中的“子作业”选项卡。 然后,可以转到此项的“子作业”选项卡。
也可在下面直接查看 HyperDrive 父作业,然后导航到其“子作业”选项卡:
七、注册和部署模型
作业完成后,可以注册从最佳试用(产生了最佳主要指标的配置)创建的模型。 可在下载后注册模型,也可通过指定具有相应 jobid 的 azureml 路径进行注册。
获取最佳试用版
# Get the best model's child runbest_child_run_id = mlflow_parent_run.data.tags["automl_best_child_run_id"]
print(f"Found best child run id: {best_child_run_id}")best_run = mlflow_client.get_run(best_child_run_id)print("Best child run: ")
print(best_run)
# Create local folder
local_dir = "./artifact_downloads"
if not os.path.exists(local_dir):os.mkdir(local_dir)
# Download run's artifacts/outputs
local_path = mlflow_client.download_artifacts(best_run.info.run_id, "outputs", local_dir
)
print(f"Artifacts downloaded in: {local_path}")
print(f"Artifacts: {os.listdir(local_path)}")
注册模型
使用 azureml 路径或本地下载的路径注册模型。
model_name = "od-fridge-items-mlflow-model"
model = Model(path=f"azureml://jobs/{best_run.info.run_id}/outputs/artifacts/outputs/mlflow-model/",name=model_name,description="my sample object detection model",type=AssetTypes.MLFLOW_MODEL,
)# for downloaded file
# model = Model(
# path=mlflow_model_dir,
# name=model_name,
# description="my sample object detection model",
# type=AssetTypes.MLFLOW_MODEL,
# )registered_model = ml_client.models.create_or_update(model)
注册要使用的模型后,可以使用托管联机终结点 deploy-managed-online-endpoint 进行部署
配置联机终结点
# Creating a unique endpoint name with current datetime to avoid conflicts
import datetimeonline_endpoint_name = "od-fridge-items-" + datetime.datetime.now().strftime("%m%d%H%M%f"
)# create an online endpoint
endpoint = ManagedOnlineEndpoint(name=online_endpoint_name,description="this is a sample online endpoint for deploying model",auth_mode="key",tags={"foo": "bar"},
)
print(online_endpoint_name)
创建终结点
使用之前创建的 MLClient,我们现在将在工作区中创建终结点。 此命令会启动终结点创建操作,并在终结点创建操作继续时返回确认响应。
ml_client.begin_create_or_update(endpoint).result()
还可以创建一个批处理终结点,用于针对一段时间内的大量数据执行批量推理。 签出用于使用批处理终结点执行批量推理的物体检测批处理评分笔记本。
配置联机部署
部署是一组资源,用于承载执行实际推理的模型。 我们将使用 ManagedOnlineDeployment 类为终结点创建一个部署。 可为部署群集使用 GPU 或 CPU VM SKU。
deployment = ManagedOnlineDeployment(name="od-fridge-items-mlflow-deploy",endpoint_name=online_endpoint_name,model=registered_model.id,instance_type="Standard_DS4_V2",instance_count=1,request_settings=req_timeout,liveness_probe=ProbeSettings(failure_threshold=30,success_threshold=1,timeout=2,period=10,initial_delay=2000,),readiness_probe=ProbeSettings(failure_threshold=10,success_threshold=1,timeout=10,period=10,initial_delay=2000,),
)
创建部署
使用前面创建的 MLClient,我们将在工作区中创建部署。 此命令将启动部署创建操作,并在部署创建操作继续时返回确认响应。
ml_client.online_deployments.begin_create_or_update(deployment).result()
更新流量
默认情况下,当前部署设置为接收 0% 的流量。 可以设置当前部署应接收的流量百分比。 使用一个终结点的所有部署接收的流量百分比总和不应超过 100%。
# od fridge items deployment to take 100% traffic
endpoint.traffic = {"od-fridge-items-mlflow-deploy": 100}
ml_client.begin_create_or_update(endpoint).result()
八、测试部署
# Create request json
import base64sample_image = os.path.join(dataset_dir, "images", "1.jpg")def read_image(image_path):with open(image_path, "rb") as f:return f.read()request_json = {"input_data": {"columns": ["image"],"data": [base64.encodebytes(read_image(sample_image)).decode("utf-8")],}
}
import jsonrequest_file_name = "sample_request_data.json"with open(request_file_name, "w") as request_file:json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(endpoint_name=online_endpoint_name,deployment_name=deployment.name,request_file=request_file_name,
)
九、直观呈现检测结果
为测试图像评分后,可以直观呈现此图像的边界框。 若要执行此操作,请确保已安装 matplotlib。
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import matplotlib.patches as patches
from PIL import Image
import numpy as np
import jsonIMAGE_SIZE = (18, 12)
plt.figure(figsize=IMAGE_SIZE)
img_np = mpimg.imread(sample_image)
img = Image.fromarray(img_np.astype("uint8"), "RGB")
x, y = img.sizefig, ax = plt.subplots(1, figsize=(15, 15))
# Display the image
ax.imshow(img_np)# draw box and label for each detection
detections = json.loads(resp)
for detect in detections[0]["boxes"]:label = detect["label"]box = detect["box"]conf_score = detect["score"]if conf_score > 0.6:ymin, xmin, ymax, xmax = (box["topY"],box["topX"],box["bottomY"],box["bottomX"],)topleft_x, topleft_y = x * xmin, y * yminwidth, height = x * (xmax - xmin), y * (ymax - ymin)print(f"{detect['label']}: [{round(topleft_x, 3)}, {round(topleft_y, 3)}, "f"{round(width, 3)}, {round(height, 3)}], {round(conf_score, 3)}")color = np.random.rand(3) #'red'rect = patches.Rectangle((topleft_x, topleft_y),width,height,linewidth=3,edgecolor=color,facecolor="none",)ax.add_patch(rect)plt.text(topleft_x, topleft_y - 10, label, color=color, fontsize=20)
plt.show()
十、清理资源
如果打算运行其他 Azure 机器学习教程,请不要完成本部分。
如果不打算使用已创建的资源,请删除它们,以免产生任何费用。
- 在 Azure 门户中,选择最左侧的“资源组”。
- 从列表中选择已创建的资源组。
- 选择“删除资源组”。
- 输入资源组名称。 然后选择“删除”。
还可保留资源组,但请删除单个工作区。 显示工作区属性,然后选择“删除”。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
相关文章:
Azure 机器学习 - 使用 AutoML 和 Python 训练物体检测模型
目录 一、Azure环境准备二、计算目标设置三、试验设置四、直观呈现输入数据五、上传数据并创建 MLTable六、配置物体检测试验适用于图像任务的自动超参数扫描 (AutoMode)适用于图像任务的手动超参数扫描作业限制 七、注册和部署模型获取最佳试用版注册模型配置联机终结点创建终…...
【深度学习】pytorch——快速入门
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ pytorch快速入门 简介张量(Tensor)操作创建张量向量拷贝张量维度张量加法函数名后面带下划线 _ 的函数索引和切片Tensor和Numpy的数组之间的转换张量(tensor)与标量…...

git本地项目同时推送提交到github和gitee同步
git本地项目同时推送提交到github和gitee同步 同时推送到GitHub和Gitee(码云)可以通过设置多个远程仓库地址来实现。具体步骤如下: 一、分别推送 # 初始化仓库 git init# 添加远程仓库 git remote add gitee gitgitee.com:bealei/test.git…...

结构体数据类型使用的一些注意点
1.结构体定义时的注意事项: 1.错误定义结构体: struct students {char name[9] "Mike";int height 185; }; 这是不对的,在 C 语言中,这是由语言的设计原则所决定的。结构体的定义(struct declaration&…...

Serverless化云产品超40款 阿里云发布全球首款容器计算服务
10月31日,杭州云栖大会上,阿里云宣布推出全球首款容器计算服务ACS,大幅提升操作的易用性并节省20%资源成本,真正将Serverless理念大规模落地,同时阿里云 Serverless化进程进入快车道,有超40款云产品提供了S…...
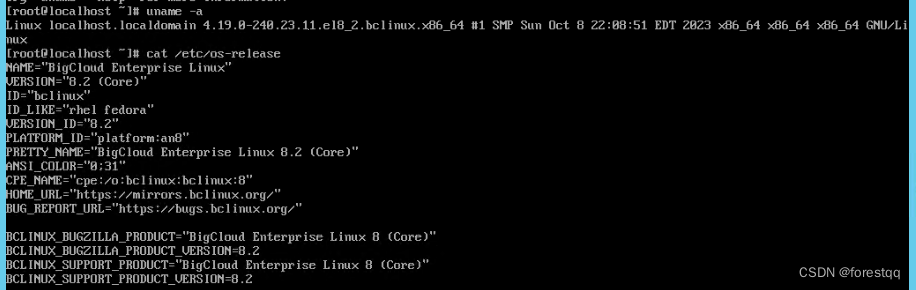
最小化安装移动云大云操作系统--BCLinux-R8-U2-Server-x86_64-231017版
有个业务系统因为兼容性问题,需要安装el8.2的系统,因此对应安装国产环境下的BCLinuxR8U2系统来满足用户需求。BCLinux-R8-U2-Server是中国移动基于AnolisOS8.2深度定制的企业级X86服务器通用版操作系统。本文记录在DELL PowerEdge R720xd服务器上最小化安…...

索引创建的原则
索引的创建是数据库优化中非常重要的一部分,正确创建索引可以大大提高查询效率。以下是一些创建索引时需要考虑的原则: 根据查询频率创建索引: 频繁用于检索的列: 那些频繁用于查询的列或经常出现在 WHERE、JOIN、ORDER BY 和 GR…...
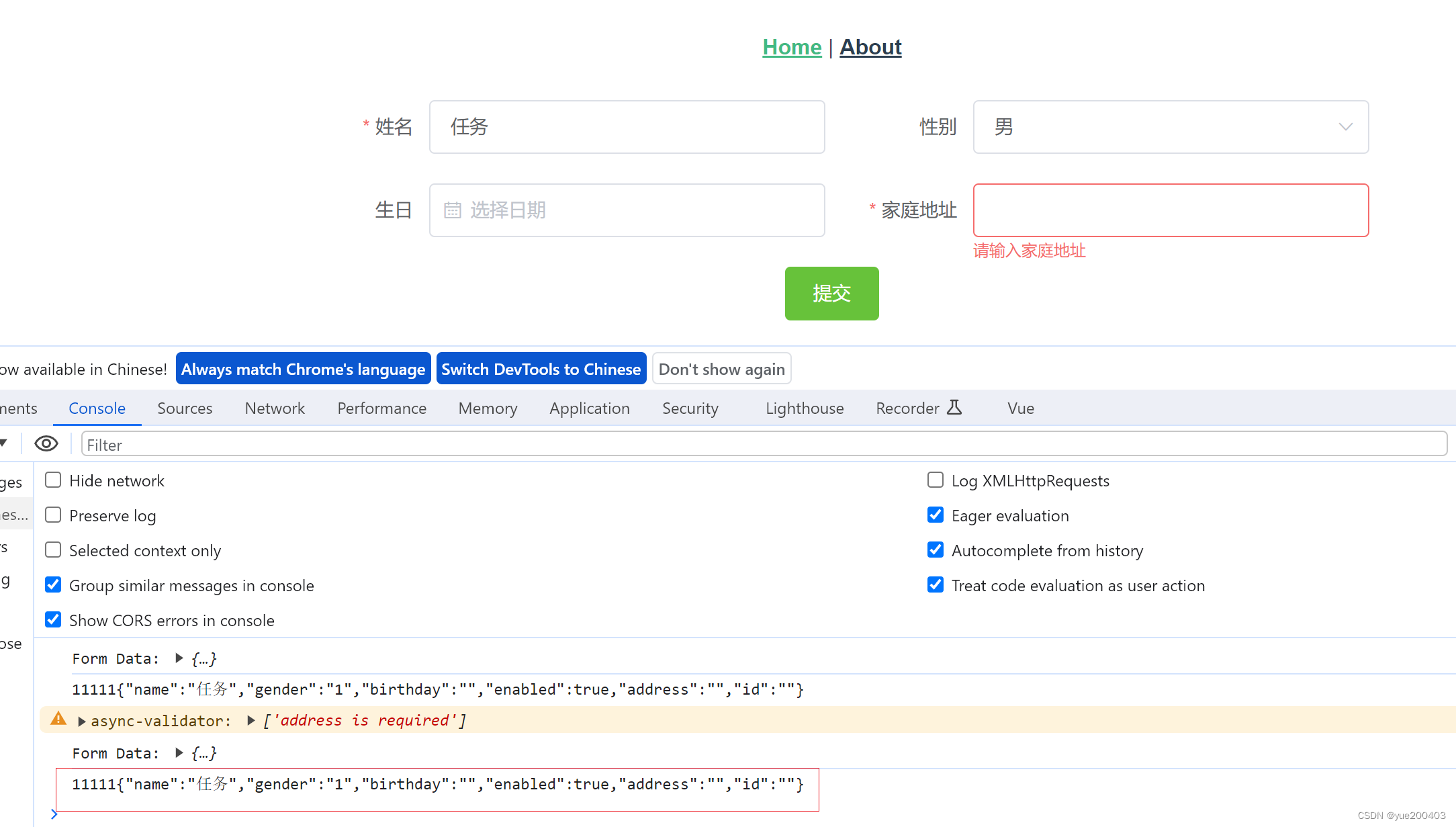
动态表单生成Demo(Vue+elment)
摘要:本文将介绍如何使用vue和elment ui组件库实现一个简单的动态表单生成的Demo。主要涉及两个.vue文件的书写,一个是动态表单生成的组件文件,一个是使用该动态表单生成的组件。 1.动态表单生成组件 这里仅集成了输入框、选择框、日期框三种…...

JMeter断言之JSON断言
JSON断言 若服务器返回的Response Body为JSON格式的数据,使用JSON断言来判断测试结果是较好的选择。 首先需要根据JSON Path从返回的JSON数据中提取需要判断的实际结果,再设置预期结果,两者进行比较得出断言结果。 下面首先介绍JSON与JSON…...
--mqtt - mqtt客户端)
LuatOS-SOC接口文档(air780E)--mqtt - mqtt客户端
常量 常量 类型 解释 mqtt.STATE_DISCONNECT number mqtt 断开 mqtt.STATE_SCONNECT number mqtt socket连接中 mqtt.STATE_MQTT number mqtt socket已连接 mqtt连接中 mqtt.STATE_READY number mqtt mqtt已连接 mqttc:subscribe(topic, qos) 订阅主题 参数 …...

安装Python环境
Python 安装包下载地址:https://www.python.org/downloads/ 打开该链接,可以看到有两个版本的 Python,分别是 Python 3.x 和 Python 2.x,如下图所示: Python下载页面截图 图 1 Python 下载页面截图(包含…...
[nodejs] 爬虫加入并发限制并发实现痞客邦网页截图
今晚想给偶像的相册截个图,避免某一天网站挂了我想看看回忆都不行,用的是js的木偶师来爬虫台湾的部落格,效果图大概是这样,很不错 问题来了.我很贪心, 我想一次性把相册全爬了,也就是并发 ,这个人的相册有19个!!我一下子要开19个谷歌浏览器那个什么进程, 然后程序就崩了, 我就想…...
GEE——Publisher Data Catalogs发布者数据目录
发布者数据目录 发布者数据目录由数据集发布者策划,供更大范围的 Google 地球引擎社区使用,并作为地球引擎资产集公开共享。这些目录并非由 Google 编制。这里是GEE团队简政放权的一个过程,也就是说这些数据集的后续更新和维护并不由GEE团队负…...

计算10的阶乘
一、不好的写法 public static void main(String[] args) {long fun fun(10);System.out.println(fun);}public static long fun(long n) {if (n 1) {return 1;}return n * fun(n - 1);}使用递归完成需求,fun1方法会执行10次,并且第一次执行未完毕&…...

6.卷积神经网络
#pic_center R 1 R_1 R1 R 2 R^2 R2 目录 知识框架No.1 卷积层一、从全连接到卷积二、卷积层三、代码四、QA No.2 卷积层里的填充和步幅一、填充和步幅二、D2L代码注意点三、QA No.3 卷积层里的多输入和多输出通道一、多输入和多输出通道二、D2L代码注意点三、QA No.4 池化层…...

postgresql|数据库|SQL语句冲突的解决
前言: postgresql数据库是比较复杂的一个关系型数据库,而有些时候,即使是简单的插入更新操作也是有很多复杂的机制。 那么,什么是冲突?什么时候会遇到冲突(也就是冲突的常见场景)?…...
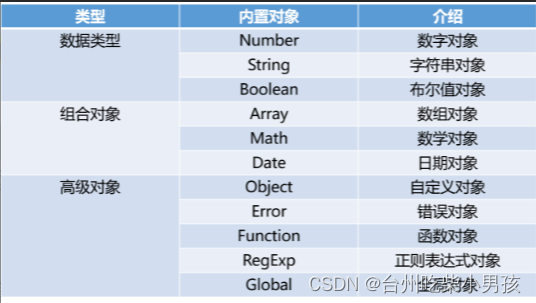
overflow溢出属性、定位、前端基础之JavaScript
overflow溢出属性 值 描述 visible 默认值。内容不会被修剪,会呈现在元素框之外。 hidden 内容会被修剪,并且其余内容是不可见的。 scroll 内容会被修剪,但是浏览器会显示滚动条以便查看其余的内容。 auto 如果内容被修剪࿰…...

【JS】Chapter6-Dom 获取属性操作
站在巨人的肩膀上 黑马程序员前端JavaScript入门到精通全套视频教程,javascript核心进阶ES6语法、API、js高级等基础知识和实战教程 (六)Dom 获取&属性操作 以下的变量可以将 let 改为 const: let arr [red, green] arr.pu…...
太极培训机构展示服务预约小程序的作用如何
太极是适合男女老幼的,很多地方也有相关的学校或培训机构,由于受众广且不太受地域影响,因此对培训机构来说,除了线下经营外,线上宣传、学员获取和发展也不可少。 接下来让我们看下通过【雨科】平台制作太极教培服务预…...

node使用path模块的基本使用
文章目录 一、path.resolve(常用)二、path.sep三、path.parse其他 一、path.resolve(常用) 由于node 中使用 __dirname 获取的绝对路径是/ ,而我们拼接的路径为‘/’导致路径不统一。 作用:拼接规范的绝对路径 const fs require(fs) const path require(path)// 1…...

基于ISDN信令的来电语音播报系统:从原理到树莓派实现
1. 项目概述:一个基于ISDN的来电语音播报系统如果你家里或办公室里还有一台老式的ISDN路由器,别急着把它当电子垃圾处理掉。我最近就利用手头一台闲置的ISDN路由器,折腾出了一个挺有意思的小玩意儿:一个能自动识别来电号码&#x…...

3步终结Windows热键冲突:Hotkey Detective终极排查指南
3步终结Windows热键冲突:Hotkey Detective终极排查指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾…...

密码学入门:区块链中的密码学原理
密码学入门:区块链中的密码学原理 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊密码学这个重要话题。作为一个Web3探索者,密码学是区块链的基础。今天就来分享一下区块链中常用的密码学原理。 为什么密码学很重要&a…...

动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿
动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Anim…...

谷歌CEO承认Coding落后了
梦瑶 发自 凹非寺量子位 | 公众号 QbitAI谷歌CEO皮查伊这次真没藏着掖着,直接一个真心话大放送了:在Coding这事儿上,我们家Gemini确实有点了落后哈…..(Gemini:怎么这话还从我自家老板嘴里说出来了呢!&…...

终极指南:如何在Windows上直接访问Linux RAID阵列数据
终极指南:如何在Windows上直接访问Linux RAID阵列数据 【免费下载链接】winmd WinMD 项目地址: https://gitcode.com/gh_mirrors/wi/winmd 你是否曾面临这样的困境:企业Linux服务器上存储着重要的业务数据,使用mdadm创建的RAID阵列运行…...

数据库原理核心考点全解析
数据库原理期末考试核心知识点可系统性地划分为基础理论、数据模型与设计、SQL与查询优化、事务管理与并发控制、数据库安全与完整性以及数据库新技术六大模块。其核心内容与逻辑关系如下表所示: 模块核心知识点简要说明1. 基础理论数据库系统特点、三级模式结构、…...

毕业论文难写?2026年AI写作辅助平台排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...
实战避坑)
别再死记硬背了!用COMSOL 5.6搞定声学建模,从房间特征频率到完美匹配层(PML)实战避坑
别再死记硬背了!用COMSOL 5.6搞定声学建模,从房间特征频率到完美匹配层(PML)实战避坑 声学建模在工程应用中越来越重要,无论是建筑声学设计、噪声控制还是医疗超声设备开发,都需要精确的声场模拟。但对于初…...

字节校招7000人转正率50%:大厂HR体系,正在“去经验化“
字节跳动刚刚用一组校招数据,扯下了大厂老兵最后一块遮羞布。 2026年春,ByteIntern规模狂飙至7000人,转正率史无前例地超过50%。 短短3到6个月,字节用远低于市场价的成本,批量生产出了3500个能够直接上岗的替代者。 同样的薪酬包,大厂宁愿招两个高潜应届生,也不愿意留…...