从零开始实现神经网络(一)_NN神经网络
参考文章:神经网络介绍
一、神经元
这一神经网络的基本单元,神经元接受输入,对它们进行一些数学运算,并产生一个输出。
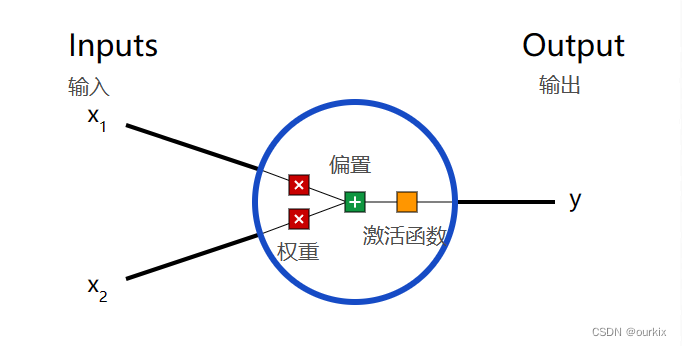
这里有三步。
首先,将每个输入(X1)乘以一个权重![]() :
:
接下来,将所有加权输入与偏置![]() 相加:
相加:
最后,总和通过激活函数![]() 传递:
传递:
激活函数
激活函数用于将无界输入转换为具有良好、可预测形式的输出。常用的激活函数是sigmoid功能:
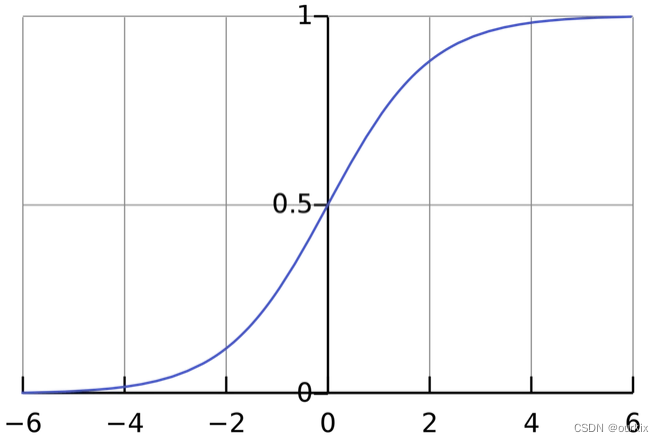
你可以把它想象成,压缩零到负无穷的数字到[-1,0],压缩0到正无穷的数字到[0,1]
举个例子:
这里写成向量形式,假设权重W = {w1,w2} = {0,1},输入X = {x1,x2} = {2,3},偏置b为1。
那么有一下计算:
下面来实现下代码:
import numpy as npdef sigmoid(x):# Our activation function: f(x) = 1 / (1 + e^(-x))return 1 / (1 + np.exp(-x))class Neuron:def __init__(self, weights, bias):self.weights = weightsself.bias = biasdef feedforward(self, inputs):# Weight inputs, add bias, then use the activation functiontotal = np.dot(self.weights, inputs) + self.biasreturn sigmoid(total)weights = np.array([0, 1]) # w1 = 0, w2 = 1
bias = 4 # b = 4
n = Neuron(weights, bias)x = np.array([2, 3]) # x1 = 2, x2 = 3
print(n.feedforward(x)) # 0.9990889488055994二. 将神经元组合成神经网络
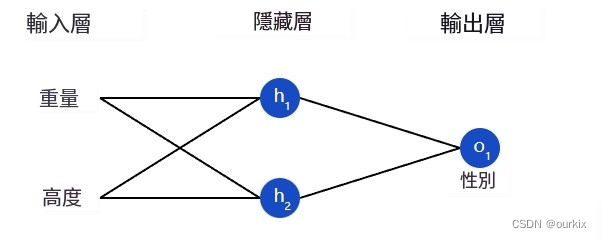
神经网络只不过是一堆连接在一起的神经元。下面是一个简单的神经网络的样子:
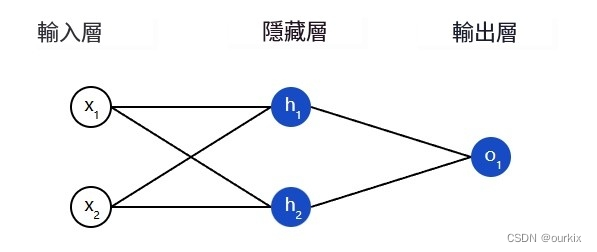
该网络有 2 个输入(x1和x2),一个带有 2 个神经元的隐藏层 (ℎ1和ℎ2),以及具有 1 个神经元 (o1).请注意,输入o1是来自ℎ1和h2- 这就是使它成为一个网络的原因。
隐藏层是输入(第一层)和输出(最后一层)之间的任何层。可以有多个隐藏层!
示例:前馈
让我们使用上图的网络,并假设所有神经元具有相同的权重w=[0,1],相同的偏差b=0,以及相同的 S 形激活函数。让h1,h2,o1表示它们所代表的神经元的输出。
如果我们传入输入会发生什么x=[2,3]?
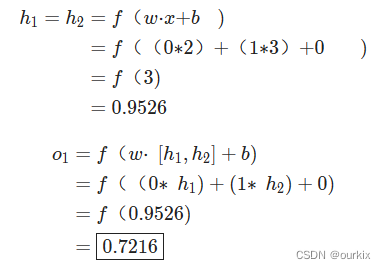
用于输入的神经网络的输出x=[2,3]是0.7216很简单,对吧?
神经网络可以有任意数量的层,这些层中可以有任意数量的神经元。基本思想保持不变:通过网络中的神经元向前馈送输入,以在最后获得输出。为简单起见,在本文的其余部分,我们将继续使用上图的网络。
神经网络的代码实现:
import numpy as np# ... code from previous section hereclass OurNeuralNetwork:'''A neural network with:- 2 inputs- a hidden layer with 2 neurons (h1, h2)- an output layer with 1 neuron (o1)Each neuron has the same weights and bias:- w = [0, 1]- b = 0'''def __init__(self):weights = np.array([0, 1])bias = 0# The Neuron class here is from the previous sectionself.h1 = Neuron(weights, bias)self.h2 = Neuron(weights, bias)self.o1 = Neuron(weights, bias)def feedforward(self, x):out_h1 = self.h1.feedforward(x)out_h2 = self.h2.feedforward(x)# The inputs for o1 are the outputs from h1 and h2out_o1 = self.o1.feedforward(np.array([out_h1, out_h2]))return out_o1network = OurNeuralNetwork()
x = np.array([2, 3])
print(network.feedforward(x)) # 0.7216325609518421三. 训练神经网络,第 1 部分
假设我们有以下测量值:
| 名字 | 重量(磅) | 高度(英寸) | 性 |
|---|---|---|---|
| 爱丽丝 | 133 | 65 | F |
| 鲍勃 | 160 | 72 | M |
| 查理 | 152 | 70 | M |
| 黛安娜 | 120 | 60 | F |
让我们训练我们的网络,根据某人的体重和身高预测他们的性别:
我们将用0代表男性,1代表女性,我们还将处理数据以使其更易于使用:
| 名字 | 重量(减去 135) | 高度(减去 66) | 性 |
|---|---|---|---|
| 爱丽丝 | -2 | -1 | 1 |
| 鲍勃 | 25 | 6 | 0 |
| 查理 | 17 | 4 | 0 |
| 黛安娜 | -15 | -6 | 1 |
我随意选择了减去的数值(135和66) 以使数值看起来更好。通常,会按平均值移动。
损失
在我们训练网络之前,我们首先需要一种方法来量化它做得有多“好”,以便它可以尝试做得“更好”。这就是损失所在。
我们将使用均方误差 (MSE) 损失:
让我们分解一下:
- n是样本数,即4(爱丽丝,鲍勃,查理,戴安娜)。
- y表示要预测的变量,即性别。
- yTrue是变量的真实值(“正确答案”)。例如yTRue因为爱丽丝的性别为1(女)。
- yPred是变量的预测值。这是我们的网络输出的任何内容。
称为平方误差。我们的损失函数只是取所有平方误差的平均值(因此得名均方误差)。我们的预测越好,我们的损失就越低!
更好的预测=更低的损失。
训练网络=试图将其损失降至最低。
损失计算示例
假设我们的网络总是输出0换句话说,它相信所有人类都是男性🤔。我们的损失会是什么?
| 名字 | yTRue | yPRED | |
|---|---|---|---|
| 爱丽丝 | 1 | 0 | 1 |
| 鲍勃 | 0 | 0 | 0 |
| 查理 | 0 | 0 | 0 |
| 黛安娜 | 1 | 0 | 1 |
均方误差的代码实现:
import numpy as npdef mse_loss(y_true, y_pred):# y_true and y_pred are numpy arrays of the same length.return ((y_true - y_pred) ** 2).mean()y_true = np.array([1, 0, 0, 1])
y_pred = np.array([0, 0, 0, 0])print(mse_loss(y_true, y_pred)) # 0.5四. 训练神经网络,第 2 部分
反向传播
我们现在有一个明确的目标:尽量减少神经网络的损失。我们知道我们可以改变网络的权重和偏差来影响其预测,但是我们如何以减少损失的方式做到这一点呢?
为简单起见,让我们假设我们的数据集中只有 爱丽丝:
| 名字 | 重量(减去 135) | 高度(减去66) | 性 |
|---|---|---|---|
| 爱丽丝 | -2 | -1 | 1 |
那么只是爱丽丝的均方误差损失(最后会带入yTrue的值进去):
另一种考虑损失的方法是作为权重和偏差的函数。让我们标记网络中的每个权重和偏差:

然后,我们可以将损失写为多变量函数:
L(w1,w2,w3,w4,w5,w6,b1,b2,b3)
想象一下,我们想调整w1.损失将如何L如果我们改变了,就改变w1?
这是一个偏导数的问题 可以回答。我们如何计算它?
首先,让我们根据以下方法(链式法则)重写偏导数:
这里我们可以求得,由于前面的MSE均方误差计算的就是神经网络的误差,MSE作为损失函数,所以有等式:
所以可以得出:
这里使用符合函数求导法则(对于函数的x进行求导,将得到
):
然后我们再搞清楚,由于yPred是预测值,而预测值由激活函数输出,所以能够得到等式:
由于改变w1只对h1有影响,所以可以写成: 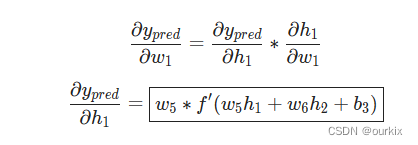
我们再对h1做同样的步骤(h1是上一层的激活函数),,同样是复合函数求导法则:

对于激活函数sigmoid的倒数:
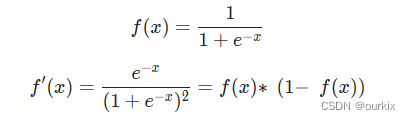
最终整合起来:
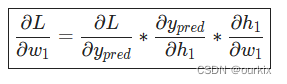
这种通过逆向计算偏导数的系统称为反向传播。
推导当前神经网络反向传播所用到的所有偏导公式:
例子:
我们将继续假设数据集中只有 爱丽丝:
| 名字 | 重量(减去 135) | 高度(减去 66) | 性 |
|---|---|---|---|
| 爱丽丝 | -2 | -1 | 1 |
让我们将所有权重初始化为1以及所有偏置为0.如果我们通过网络进行前馈传递,我们会得到:

网络输出yPred=0.524,这并不强烈支持男性 或女性 .让我们计算一下
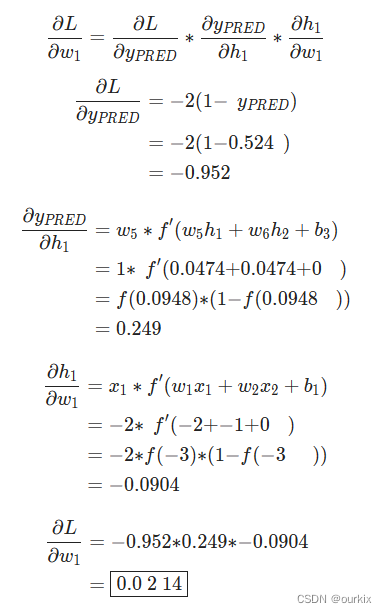
这里用到了上面所求得的sigmoid的倒数。
我们成功了!这告诉我们,由于所求的偏导结果为0.0214,是个正数,函数单调递增,所以
如果我们要增加w1(权重),L(损失)结果会增大一点点。
训练:随机梯度下降
我们现在拥有训练神经网络所需的所有工具!我们将使用一种称为随机梯度下降 (SGD) 的优化算法,该算法告诉我们如何改变权重和偏差以最小化损失。
就是这个方程式:
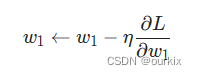
η是一个称为学习率的常数,它控制着我们训练的速度。我们所做的只是用旧权重减去学习率*偏导值:
- 如果
的值为正数,w1的减少,会使得L减少。
- 如果
如果我们对网络中的每个权重和偏差都这样做,损失将慢慢减少,我们的网络将得到改善。
我们的训练过程将如下所示:
- 从我们的数据集中选择一个样本。这就是它随机梯度下降的原因——我们一次只对一个样本进行操作。
- 计算所有损失相对于权重或偏差的偏导数(例如
等)。
- 使用更新公式更新每个权重和偏差。
- 返回步骤 1。
让我们看看它的实际效果吧!
代码:一个完整的神经网络
终于到了实现一个完整的神经网络的时候了:
| 名字 | 重量(减去 135) | 高度(减去 66) | 性 |
|---|---|---|---|
| 爱丽丝 | -2 | -1 | 1 |
| 鲍勃 | 25 | 6 | 0 |
| 查理 | 17 | 4 | 0 |
| 黛安娜 | -15 | -6 | 1 |
import numpy as npdef sigmoid(x):# Sigmoid activation function: f(x) = 1 / (1 + e^(-x))return 1 / (1 + np.exp(-x))def deriv_sigmoid(x):# Derivative of sigmoid: f'(x) = f(x) * (1 - f(x))fx = sigmoid(x)return fx * (1 - fx)def mse_loss(y_true, y_pred):# y_true and y_pred are numpy arrays of the same length.return ((y_true - y_pred) ** 2).mean()class OurNeuralNetwork:'''A neural network with:- 2 inputs- a hidden layer with 2 neurons (h1, h2)- an output layer with 1 neuron (o1)*** DISCLAIMER ***:The code below is intended to be simple and educational, NOT optimal.Real neural net code looks nothing like this. DO NOT use this code.Instead, read/run it to understand how this specific network works.'''def __init__(self):# Weightsself.w1 = np.random.normal()self.w2 = np.random.normal()self.w3 = np.random.normal()self.w4 = np.random.normal()self.w5 = np.random.normal()self.w6 = np.random.normal()# Biasesself.b1 = np.random.normal()self.b2 = np.random.normal()self.b3 = np.random.normal()def feedforward(self, x):# x is a numpy array with 2 elements.h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2)o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)return o1def train(self, data, all_y_trues):'''- data is a (n x 2) numpy array, n = # of samples in the dataset.- all_y_trues is a numpy array with n elements.Elements in all_y_trues correspond to those in data.'''learn_rate = 0.1epochs = 1000 # number of times to loop through the entire datasetfor epoch in range(epochs):for x, y_true in zip(data, all_y_trues):# --- Do a feedforward (we'll need these values later)sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1h1 = sigmoid(sum_h1)sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2h2 = sigmoid(sum_h2)sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3o1 = sigmoid(sum_o1)y_pred = o1# --- Calculate partial derivatives.# --- Naming: d_L_d_w1 represents "partial L / partial w1"d_L_d_ypred = -2 * (y_true - y_pred)# Neuron o1d_ypred_d_w5 = h1 * deriv_sigmoid(sum_o1)d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1)d_ypred_d_b3 = deriv_sigmoid(sum_o1)d_ypred_d_h1 = self.w5 * deriv_sigmoid(sum_o1)d_ypred_d_h2 = self.w6 * deriv_sigmoid(sum_o1)# Neuron h1d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)d_h1_d_b1 = deriv_sigmoid(sum_h1)# Neuron h2d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2)d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2)d_h2_d_b2 = deriv_sigmoid(sum_h2)# --- Update weights and biases# Neuron h1self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w1self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w2self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_b1# Neuron h2self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w3self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w4self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_b2# Neuron o1self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_w5self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_w6self.b3 -= learn_rate * d_L_d_ypred * d_ypred_d_b3# --- Calculate total loss at the end of each epochif epoch % 10 == 0:y_preds = np.apply_along_axis(self.feedforward, 1, data)loss = mse_loss(all_y_trues, y_preds)print("Epoch %d loss: %.3f" % (epoch, loss))# Define dataset
data = np.array([[-2, -1], # Alice[25, 6], # Bob[17, 4], # Charlie[-15, -6], # Diana
])
all_y_trues = np.array([1, # Alice0, # Bob0, # Charlie1, # Diana
])# Train our neural network!
network = OurNeuralNetwork()
network.train(data, all_y_trues)随着网络学习,我们的损失稳步减少: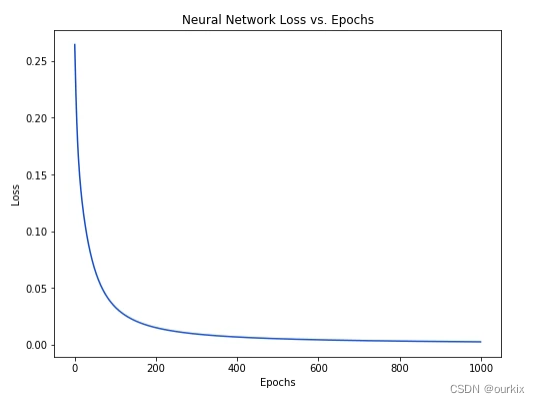
我们现在可以使用网络来预测性别:
# Make some predictions
emily = np.array([-7, -3]) # 128 pounds, 63 inches
frank = np.array([20, 2]) # 155 pounds, 68 inches
print("Emily: %.3f" % network.feedforward(emily)) # 0.951 - F
print("Frank: %.3f" % network.feedforward(frank)) # 0.039 - M相关文章:
从零开始实现神经网络(一)_NN神经网络
参考文章:神经网络介绍 一、神经元 这一神经网络的基本单元,神经元接受输入,对它们进行一些数学运算,并产生一个输出。 这里有三步。 首先,将每个输入(X1)乘以一个权重: 接下来&…...

C语言 每日一题 Day10
1.使用函数判断完全平方数 本题要求实现一个判断整数是否为完全平方数的简单函数。 函数接口定义: int IsSquare(int n); 其中n是用户传入的参数,在长整型范围内。如果n是完全平方数,则函数IsSquare必须返回1,否则返回0。 代码实…...
C++继承——矩形和长方体
Rectangle矩形类 /*矩形类*/ class Rectangle { private:double L 0;double W 0; public:Rectangle() default;Rectangle(double a, double b);double GetArea(); /*矩形面积*/double GetGirth(); /*矩形周长*/ }; /*构造函数*/ Rectangle::Rectangle(double a, double b) …...

代码随想录打卡第五十八天|● 583. 两个字符串的删除操作 ● 72. 编辑距离
583. 两个字符串的删除操作 题目: 给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。 每步 可以删除任意一个字符串中的一个字符。 题目链接: 583. 两个字符串的删除操作 解题思路: dp数组的含义&am…...

面试流程之——程序员如何写项目经验
在简历中介绍IT项目经验,你可以遵循以下步骤: 明确项目目标:首先,清晰地阐述项目的目标。这可以是提升某个软件的性能,改进某个系统的用户界面,或者增加某款产品的功能。让读者了解你的工作与项目的整体目…...
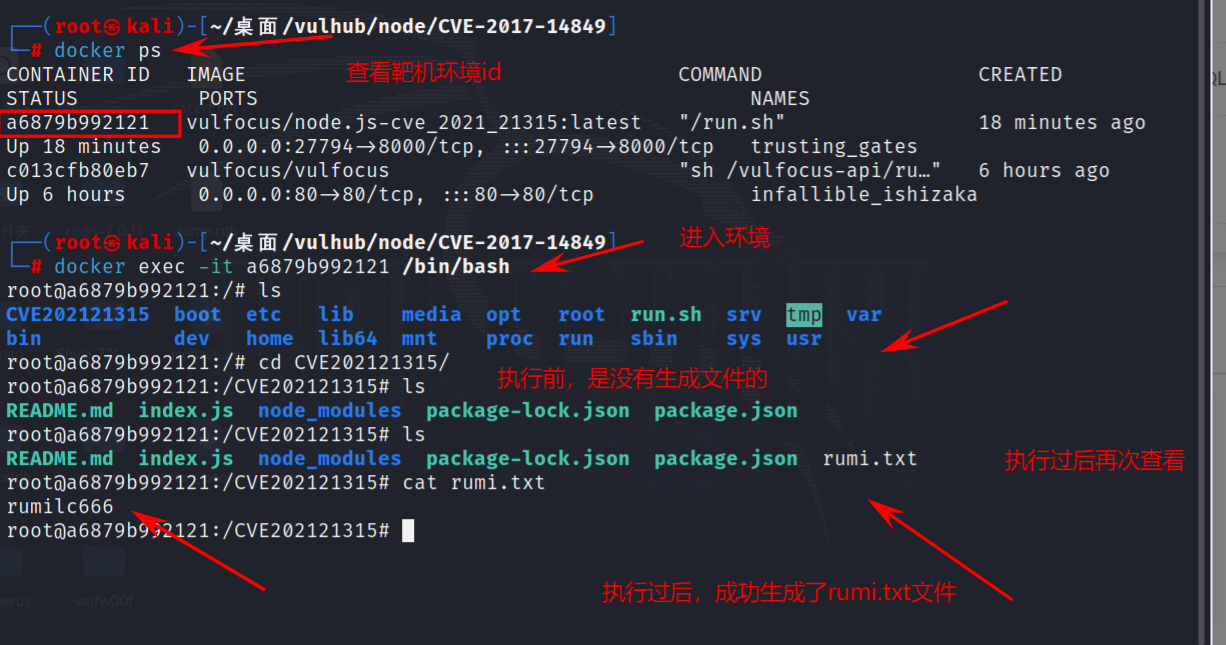
框架安全-CVE 漏洞复现DjangoFlaskNode.jsJQuery框架漏洞复现
目录 服务攻防-框架安全&CVE复现&Django&Flask&Node.JS&JQuery漏洞复现中间件列表介绍常见语言开发框架Python开发框架安全-Django&Flask漏洞复现Django开发框架漏洞复现CVE-2019-14234(Django JSONField/HStoreField SQL注入漏洞ÿ…...
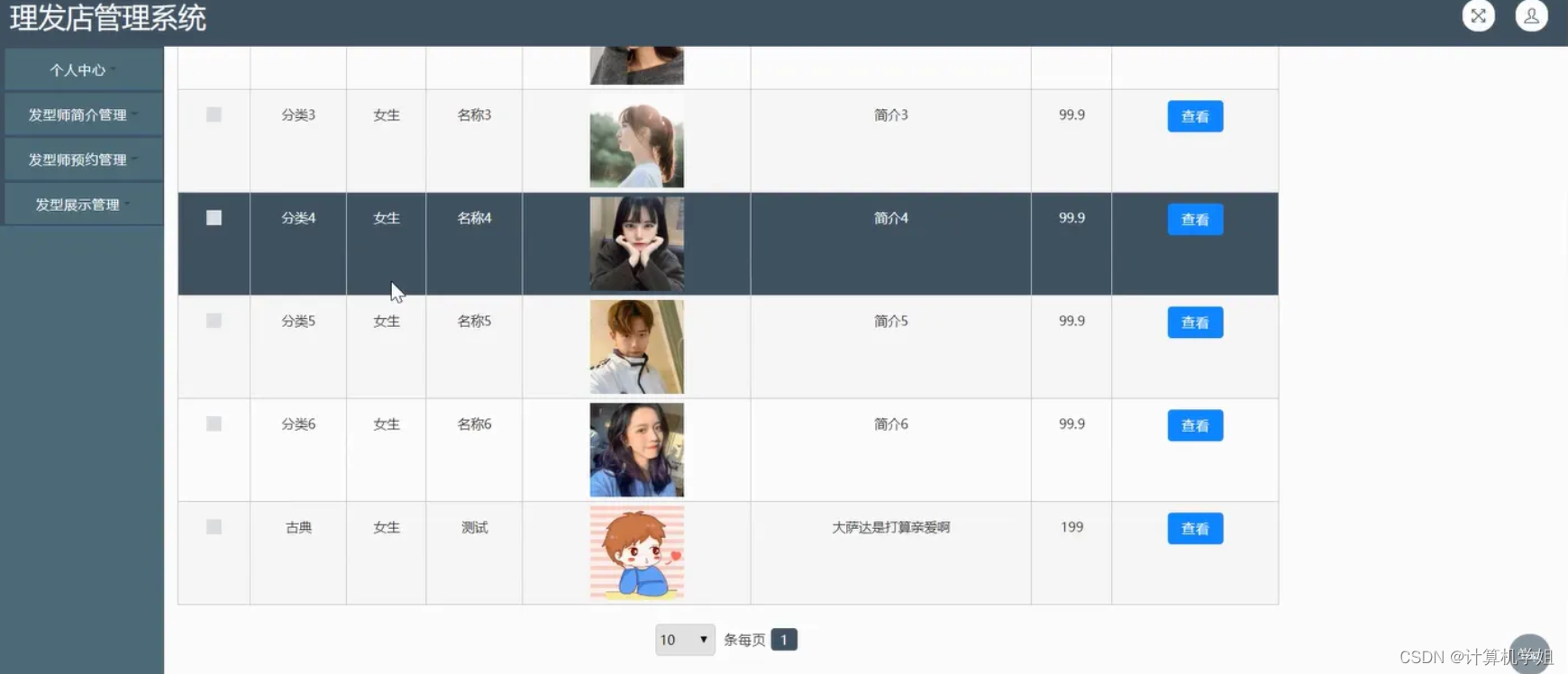
基于SSM的理发店管理系统
基于SSM的理发店管理系统的设计与实现~ 开发语言:Java数据库:MySQL技术:SpringSpringMVCMyBatis工具:IDEA/Ecilpse、Navicat、Maven 系统展示 主页 公告信息 管理员界面 用户界面 摘要 基于SSM(Spring、Spring MVC、…...
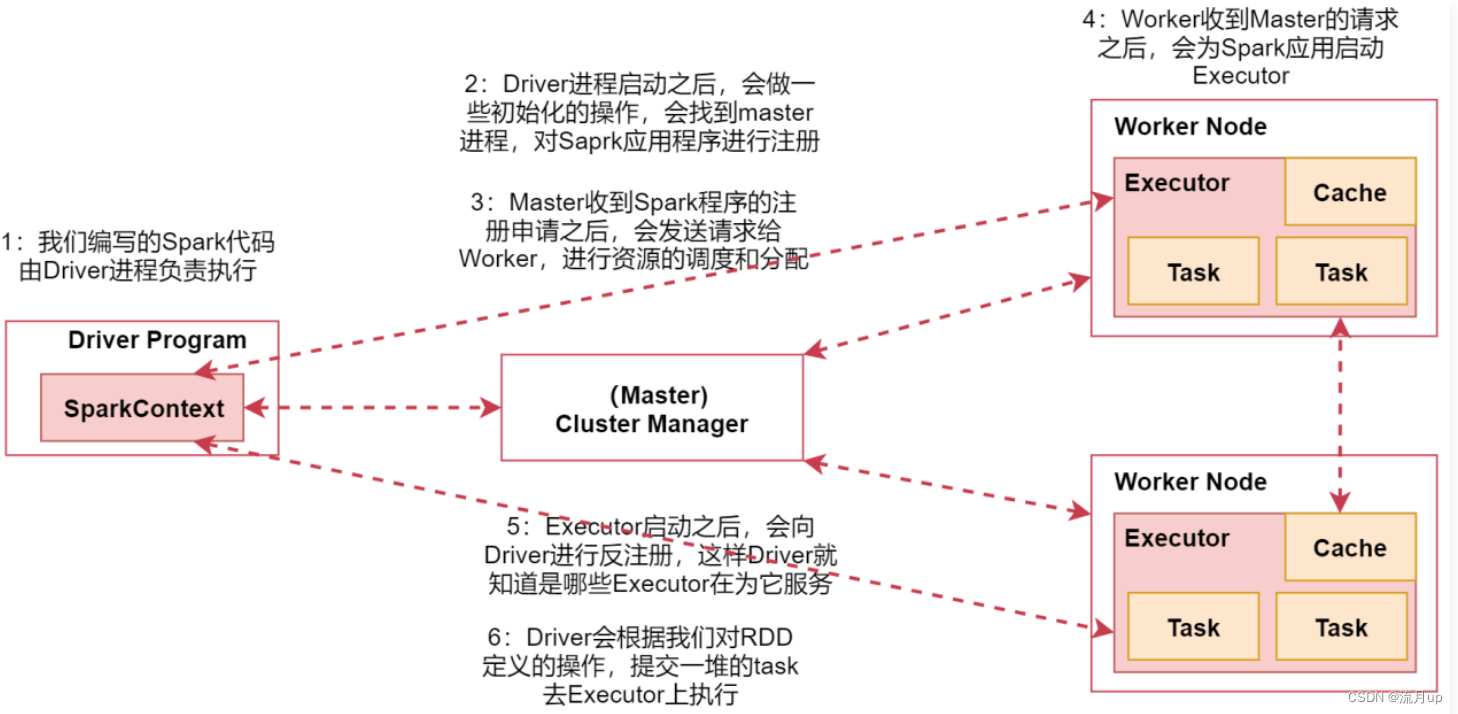
2.Spark的工作与架构原理
概述 目标: spark的工作原理spark数据处理通用流程rdd 什么是rddrdd 的特点 spark架构 spark架构相关进程spark架构原理 spark的工作原理 spark 的工作原理,如下图 图中中间部分是spark集群,也可以是基于 yarn 的,图上可以…...
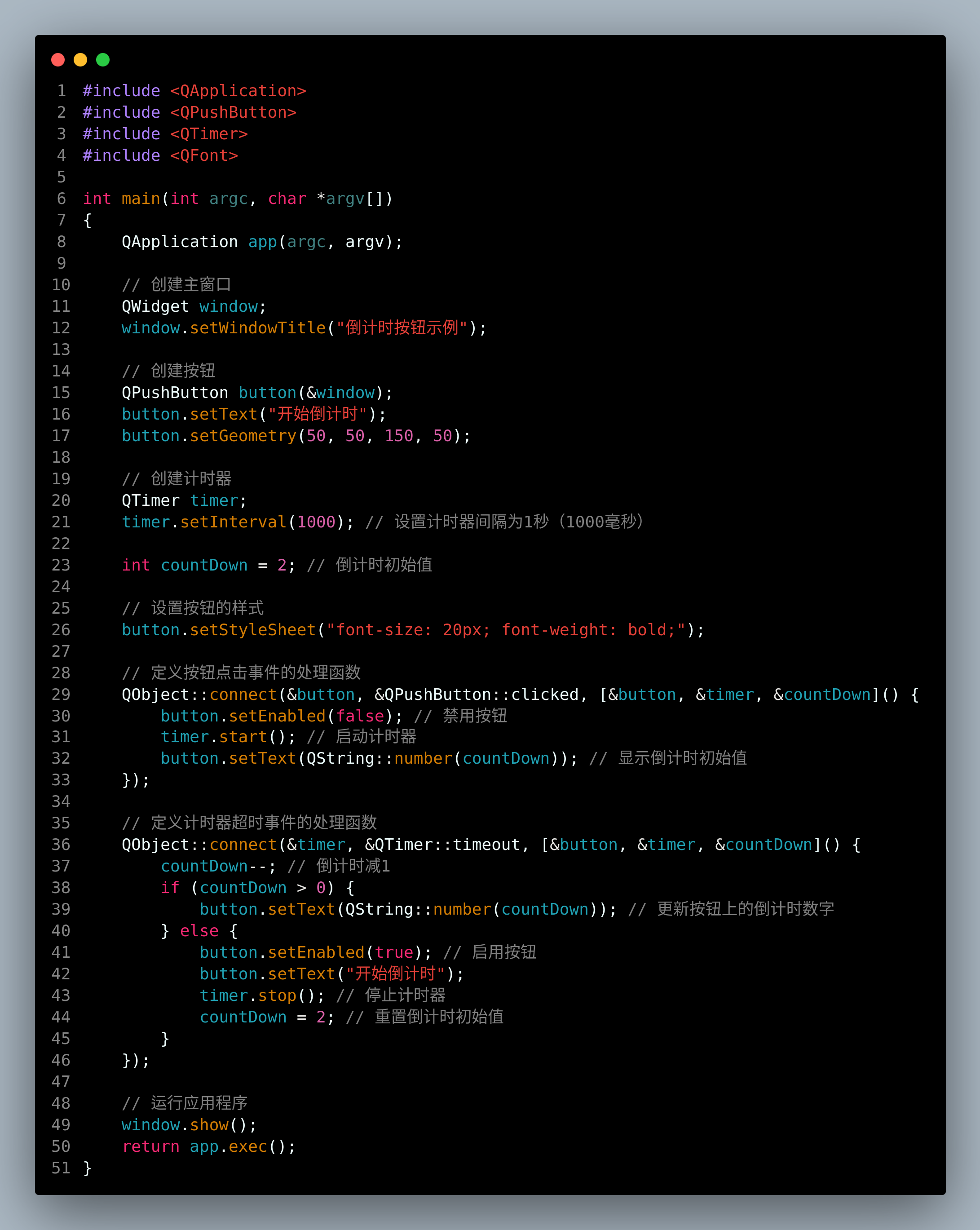
qt-C++笔记之带有倒计数显示的按钮,计时期间按钮锁定
qt-C笔记之带有倒计数显示的按钮,计时期间按钮锁定 code review! 文章目录 qt-C笔记之带有倒计数显示的按钮,计时期间按钮锁定1.运行2.main.cc3.main.pro 1.运行 2.main.cc 代码 #include <QApplication> #include <QPushButton> #includ…...
有哪些?)
HTML全局属性(global attribute)有哪些?
HTML全局属性是指在HTML元素上可用的基本属性,它们适用于所有HTML元素。以下是一些常见的HTML全局属性: 1:class:为元素指定一个或多个类名,用于与CSS样式表关联。 2:id::为元素指定唯一的标识…...

MyBatis-Plus返回getOne返回null疑惑
getOne返回null 问题描述分析过程总结 问题描述 在数据库建了一张表主要包括两个字段master_id和slave_id;主要的额外字段max_lots 默认值是null; 当调用getOne进行查询结果是null,但实际情况是数据库时应该返回值的; AotfxMasterSlave ex…...
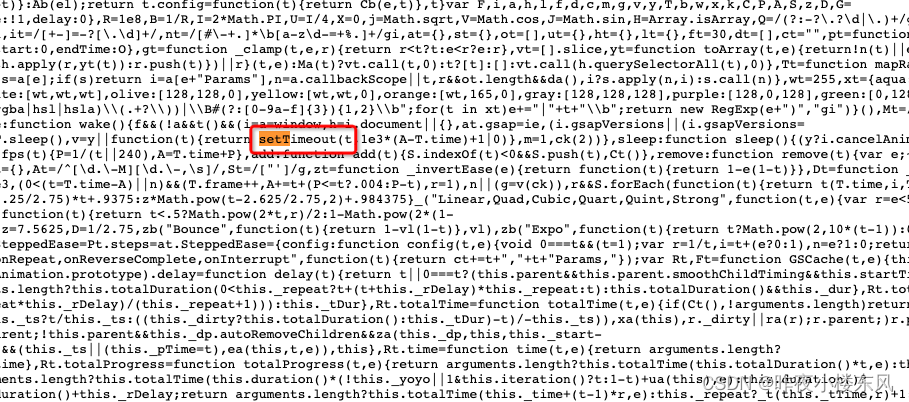
Physics2DPlugin3加载后会跳转gsap官网解决
因工作需要使用Physics2DPlugin3库,目标效果 加载他里面的在线js,使用效果正常,但是几秒会跳转官网,我们app内部、浏览器都会这样。 于是研究js代码,发现里面有setTimeout跳转。 删掉就好了 分享我改好的文件&#x…...
【AI视野·今日Sound 声学论文速览 第三十二期】Tue, 24 Oct 2023
AI视野今日CS.Sound 声学论文速览 Tue, 24 Oct 2023 Totally 20 papers 👉上期速览✈更多精彩请移步主页 Interesting: 📚nvas3d, 基于任意录音和室内3D信息合成重建不同听角(位置)处的新的声音。(from apple cmu) website: htt…...

在Linux上编译gdal3.1.2指南
作者:朱金灿 来源:clever101的专栏 为什么大多数人学不会人工智能编程?>>> 以Ubuntu 18编译gdal3.1.2为例,编译gdal3.1.2需要先编译proj库和geos库(可选)。我选择的proj库版本为proj-7.1.0,编译proj-7.1.0需要先编译tiff库和sqlite3。我选择的sqlite3的版本为…...

73. 矩阵置零 --力扣 --JAVA
题目 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 解题思路 通过二层循环找出元素为0所在的行和列;设置标志位记录当前行是否存在元素为0的,设置列表存储列为0的列&#…...
Kotlin——Android封装ViewBinding之二 优化)
(笔记)Kotlin——Android封装ViewBinding之二 优化
0. 在app模块的build.gradle文件中添加如下配置开启ViewBinding android {.......viewBinding {enabled true}} 1. 新建一个Ext.kt文件 添加两个扩展函数,分别对应Activity和Fragment inline fun <T : ViewBinding> AppCompatActivity.viewBinding(cross…...
(八))
MATLAB算法实战应用案例精讲-【图像处理】机器视觉(基础篇)(八)
目录 前言 几个高频面试题目 机器视觉如何获取到好图像 常见的视觉光源 各种视觉打光方式...

由k8s升级慢引起的etcd性能不足的问题排查
一、基本介绍 最近etcd查看出现性能 curl --cacert /path/to/etcdctl-ca.crt --cert /path/to/etcdctl.crt --key /path/to/etcdctl.key https://:2379/metrics | grep etcd_disk_wal_fsync_duration_seconds_bucket 当集群规模突破过大时规模时,曾出现如下性能瓶颈问题: etc…...
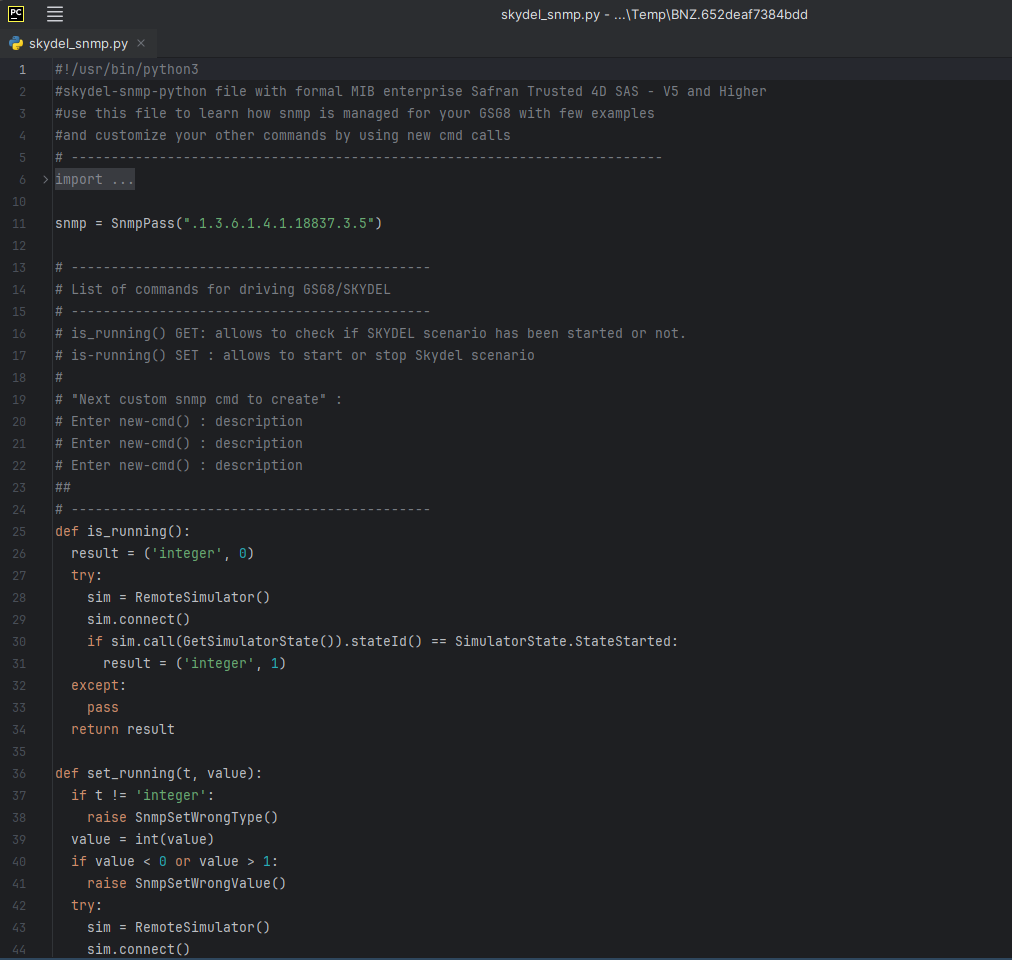
如何构建用于Skydel GNSS模拟仿真的SNMP代理方式?
使用Skydel API构建测试方案 凭借其现代、强大且直观的API,德思特Safran GNSS模拟引擎Skydel免费提供了Python、C#、C和Labview的开源客户端库,它具有600多条命令,并且有完善的文档与记录。 随着Skydel软件更新添加新功能,API得…...
vue2+ant-design-vue a-form-model组件二次封装(form表单组件)FormModel 表单
一、效果图 二、参数配置 1、代码示例 <t-antd-form:ref-obj.sync"formOpts.ref":formOpts"formOpts":widthSize"1":labelCol"{ span:2}":wrapperCol"{ span:22}"handleEvent"handleEvent" />2. 配置参数…...

SpringBoot+Vue汽车4S店销售管理系统源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...

美国RTP全系列材料:全面解析高性能导电塑料产品服务
宏裕塑胶代理美国RTP全系列材料,专注于为制造业企业提供高性价比、稳定可控的工程塑料原料供应及全流程技术支持,凭借源头直采优势与专业技术服务,助力客户降低采购成本、提升生产效率,适用于塑胶制品厂、精密注塑厂、汽车零部件厂…...

【审计专栏】【财务领域】第二十八篇 全球/中国货币流动中离钱最近的岗位01
全球/中国货币流动和流入/流出最近的距离相关信息,特别关注“离钱最近的岗位”,按照指定表格格式输出如下: 编号 类型 国家 省/市/区县 行业 公司类型 岗位类型【含管理岗/基层岗位】 离货币收入/投放的距离指标和偏差指数和期望/方差 指标类型 模型逐步推理思考的…...

【优化调度】基于改进遗传算法求解带时间窗约束多卫星任务规划附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

C# MQTT性能优化:工业级高可靠低带宽实战指南
上个月给某汽车零部件厂做产线改造,差点栽在MQTT上。 现场环境你懂的,几百个传感器同时发数据,带宽只有可怜的2Mbps,还时不时断网。一开始用的是网上随便找的MQTT客户端代码,结果上线第一天就炸了。 消息延迟最高到了3…...

通过Taotoken的Token Plan套餐实现项目成本的可预测与精细控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken的Token Plan套餐实现项目成本的可预测与精细控制 对于有长期、稳定大模型调用需求的团队而言,项目预算的…...

高校邮件安全体系升级与 Proofpoint 部署实践研究 —— 以特拉华大学为例
摘要:随着网络钓鱼、垃圾邮件与恶意邮件攻击持续威胁高校信息系统,电子邮件安全已成为校园网络防护的核心环节。特拉华大学自 2026 年 6 月 1 日起全面启用 Proofpoint 邮件安全平台,构建覆盖邮件过滤、威胁隔离、用户自助处置与安全运营的全…...

DLSS Swapper:免费高效的DLSS智能管理解决方案
DLSS Swapper:免费高效的DLSS智能管理解决方案 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为游戏玩家设计的免费开源工具,它通过智能管理DLSS、FSR和XeSS文件ÿ…...

Kubernetes云原生数据库部署方案:构建高可用数据库集群
Kubernetes云原生数据库部署方案:构建高可用数据库集群 一、云原生数据库概述 云原生数据库是为云环境设计的数据库系统,具备弹性伸缩、高可用性和自动化运维能力。在Kubernetes上部署数据库需要考虑持久化存储、高可用、备份恢复等关键因素。 1.1 数…...

第41天:MySQL新特性
Python学习100天(从入门到精通系列文章) 文章目录 Python学习100天(从入门到精通系列文章) 前言 一、JSON类型 1.1 JSON类型的基本形式 1.2 JSON类型的实际应用场景 1.3 用户画像场景中的JSON应用 二、窗口函数 2.1 窗口函数的概念 2.2 窗口函数实战示例 总结 前言 在掌握…...