【AI视野·今日Sound 声学论文速览 第三十二期】Tue, 24 Oct 2023
AI视野·今日CS.Sound 声学论文速览
Tue, 24 Oct 2023
Totally 20 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚nvas3d, 基于任意录音和室内3D信息合成重建不同听角(位置)处的新的声音。(from apple cmu)
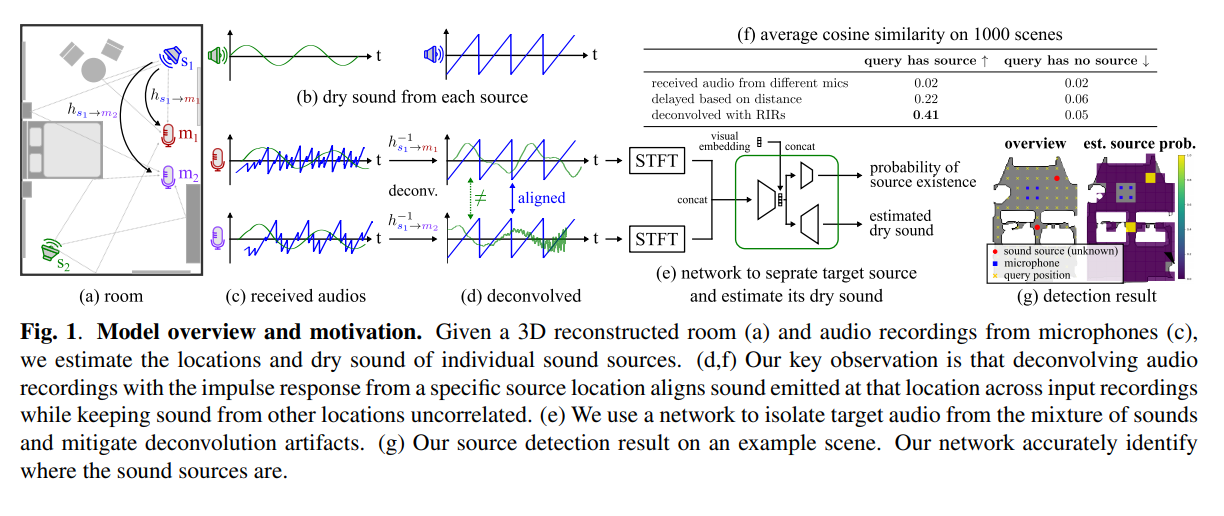
website: https://github.com/apple/ml-nvas3d
Daily Sound Papers
| Novel-View Acoustic Synthesis from 3D Reconstructed Rooms Authors Byeongjoo Ahn, Karren Yang, Brian Hamilton, Jonathan Sheaffer, Anurag Ranjan, Miguel Sarabia, Oncel Tuzel, Jen Hao Rick Chang 我们研究了将盲录音与 3D 场景信息相结合以实现新颖的视图声学合成的好处。给定 2×4 个麦克风的录音以及包含多个未知声源的场景的 3D 几何结构和材质,我们可以估计场景中任何位置的声音。我们将新视角声学合成的主要挑战确定为声源定位、分离和去混响。虽然单纯地训练端到端网络无法产生高质量的结果,但我们表明,结合从 3D 重建房间导出的房间脉冲响应 RIR 可以使同一网络共同处理这些任务。我们的方法优于为单个任务设计的现有方法,证明了其在利用 3D 视觉信息方面的有效性。在 Matterport3D NVAS 数据集的模拟研究中,我们的模型在源定位方面实现了近乎完美的精度,源分离和去混响的 PSNR 为 26.44 dB,SDR 为 14.23 dB,结果 PSNR 为 25.55 dB,SDR 为 14.20 dB关于新颖的观点声学合成。 |
| Key Frame Mechanism For Efficient Conformer Based End-to-end Speech Recognition Authors Peng Fan, Changhao Shan, Jianwei Zhang, Sining Sun, Qing Yang 最近,Conformer 作为端到端自动语音识别的骨干网络实现了最先进的性能。 Conformer 模块利用自注意力机制来捕获全局信息,并利用卷积神经网络来捕获局部信息,从而提高性能。然而,基于 Conformer 的模型遇到了自注意力机制的问题,因为计算复杂性随着输入序列的长度呈二次方增长。受之前的连接主义时间分类 CTC 在解码过程中引导空白跳过的启发,我们引入中间 CTC 输出作为 Conformer 编码器下采样过程的指导。我们将具有非空白输出的帧定义为关键帧。具体来说,我们介绍了基于关键帧的自注意力 KFSA 机制,这是一种使用关键帧减少自注意力机制计算量的新方法。我们提出的方法的结构包括两个编码器。在初始编码器之后,我们引入中间 CTC 损失函数来计算标签帧,使我们能够提取 KFSA 的关键帧和空白帧。此外,我们引入了基于关键帧的下采样 KFDS 机制,直接对高维声学特征进行操作,并丢弃与空白标签相对应的帧,从而产生新的声学特征序列作为第二个编码器的输入。通过使用所提出的方法,它实现了与 vanilla Conformer 和其他类似工作(例如 Efficient Conformer)相当或更高的性能。同时,我们提出的方法可以在模型训练和推理过程中丢弃 60 多个无用帧,这将显着加快推理速度。 |
| 8+8=4: Formalizing Time Units to Handle Symbolic Music Durations Authors Emmanouil Karystinaios, Francesco Foscarin, Florent Jacquemard, Masahiko Sakai, Satoshi Tojo, Gerhard Widmer 本文重点讨论符号乐谱中音乐事件音符和休止符的名义持续时间,以及如何在计算机应用程序中方便地处理这些持续时间。我们建议使用与乐谱中的图形符号直接相关的时间单元,并将其与涵盖音乐应用中典型计算的一组操作配对。我们将这个时间单位和更常用的方法形式化在一个数学框架中,作为半环、代数结构,可以对算法处理管道进行抽象描述。 |
| A Novel Transfer Learning Method Utilizing Acoustic and Vibration Signals for Rotating Machinery Fault Diagnosis Authors Zhongliang Chen, Zhuofei Huang, Wenxiong Kang 旋转机械的故障诊断对于现代工业系统的安全稳定发挥着重要作用。然而,训练数据与真实操作场景的数据之间存在分布差异,导致现有系统的性能下降。本文提出了一种利用声学和振动信号的基于迁移学习的方法来解决这种分布差异。我们设计了声学和振动特征融合MAVgram,以提供更丰富、更可靠的故障信息,与基于DNN的分类器配合以获得更有效的诊断表示。主干网络经过预训练,然后进行微调,以获得目标任务的优异性能。 |
| Acoustic BPE for Speech Generation with Discrete Tokens Authors Feiyu Shen, Yiwei Guo, Chenpeng Du, Xie Chen, Kai Yu 从自监督学习模型派生的离散音频标记已在语音生成中得到广泛使用。然而,由于令牌序列的长度,当前直接利用音频令牌的实践给序列建模带来了挑战。此外,这种方法给模型带来了建立令牌之间相关性的负担,从而使建模过程进一步复杂化。为了解决这个问题,我们提出声学 BPE,它利用字节对编码对频繁的音频令牌模式进行编码。 Acoustic BPE 有效地减少了序列长度并利用了 token 序列中存在的先验形态信息,从而减轻了 token 相关性的建模挑战。通过对使用声学 BPE 训练的语音语言模型进行全面研究,我们确认了它提供的显着优势,包括更快的推理和改进的语法捕获能力。此外,我们提出了一种新颖的重新评分方法,用于在丰富多样性 TTS 系统生成的多个候选语音中选择最佳合成语音。 |
| Conversational Speech Recognition by Learning Audio-textual Cross-modal Contextual Representation Authors Kun Wei, Bei Li, Hang Lv, Quan Lu, Ning Jiang, Lei Xie 对话设置中的自动语音识别 ASR 提出了独特的挑战,包括从之前的对话轮次中提取相关的上下文信息。由于不相关的内容、错误传播和冗余,现有方法很难提取更长、更有效的上下文。为了解决这个问题,我们引入了一种新颖的会话式 ASR 系统,通过跨模式会话表示扩展了 Conformer 编码器解码器模型。我们的方法利用跨模态提取器,通过专门的编码器和模态级掩码输入结合预先训练的语音和文本模型。这使得能够在没有显式错误传播的情况下提取更丰富的历史语音上下文。我们还结合了条件潜在变分模块来学习会话级别的属性,例如角色偏好和主题连贯性。 |
| First-Shot Unsupervised Anomalous Sound Detection With Unknown Anomalies Estimated by Metadata-Assisted Audio Generation Authors Hejing Zhang, Qiaoxi Zhu, Jian Guan, Haohe Liu, Feiyang Xiao, Jiantong Tian, Xinhao Mei, Xubo Liu, Wenwu Wang First shot FS 无监督异常声音检测 ASD 是 DCASE 2023 挑战任务 2 中引入的全新任务,其中目标机器类型的异常声音在训练中是看不到的。现有方法通常依赖于来自目标机器的正常和异常声音数据的可用性。然而,由于缺乏目标机器类型的异常声音数据,将现有的 ASD 方法应用于首次任务时变得具有挑战性。在本文中,我们提出了一个用于首次无监督 ASD 的新框架,其中元数据辅助音频生成用于估计未知异常,通过利用可用的机器信息(即元数据和声音数据)来微调文本到音频生成模型生成包含针对每种不同机器类型的独特声学特征的异常声音。然后,我们使用以高斯混合模型 TWFR GMM 为骨干的时间加权频域音频表示方法来实现第一镜头无监督 ASD。 |
| Composer Style-specific Symbolic Music Generation Using Vector Quantized Discrete Diffusion Models Authors Jincheng Zhang, Jingjing Tang, Charalampos Saitis, Gy rgy Fazekas 新兴的去噪扩散概率模型 DDPM 已被越来越多地使用,因为它们在具有连续数据的各种生成任务(例如图像和声音合成)中取得了有希望的结果。尽管如此,扩散模型的成功尚未完全扩展到离散的象征音乐。我们建议结合矢量量化变分自动编码器 VQ VAE 和离散扩散模型来生成具有所需作曲家风格的符号音乐。经过训练的 VQ VAE 可以将符号音乐表示为与学习的码本中的特定条目相对应的索引序列。随后,使用离散扩散模型对 VQ VAE 的离散潜在空间进行建模。训练扩散模型以生成由码本索引组成的中间音乐序列,然后使用 VQ VAE 解码器将其解码为符号音乐。 |
| Fast Diffusion GAN Model for Symbolic Music Generation Controlled by Emotions Authors Jincheng Zhang, Gy rgy Fazekas, Charalampos Saitis 扩散模型在具有连续数据的各种生成任务(例如图像和音频合成)中显示出了有希望的结果。然而,在使用扩散模型生成离散符号音乐方面进展甚微,因为这种新型生成模型不太适合离散数据,而且其迭代采样过程的计算成本很高。在这项工作中,我们提出了一种与生成对抗网络相结合的扩散模型,旨在缓解算法音乐生成中剩余的挑战之一,即对目标情感的生成的控制,并减轻扩散模型采样缓慢的缺点应用于象征音乐的生成。我们首先使用经过训练的变分自动编码器来获得带有情感标签的符号音乐数据集的嵌入,然后使用它们来训练扩散模型。我们的结果证明了我们的扩散模型的成功控制,以生成具有所需情感的象征性音乐。 |
| Temporal convolutional neural networks to generate a head-related impulse response from one direction to another Authors Tatsuki Kobayashi, Yoshiko Maruyama, Isao Nambu, Shohei Yano, Yasuhiro Wada 虚拟声音合成是一种允许用户通过耳机或耳机感知空间声音的技术。然而,准确的虚拟声音需要与个体头部相关的传递函数 HRTF,由于需要专门的环境,这可能很难测量。在这项研究中,我们提出了一种从一个方向到另一个方向生成 HRTF 的方法。为此,我们使用时间卷积神经网络 TCN 来生成与头部相关的脉冲响应 HRIR。为了训练 TCN,使用了水平面中公开可用的数据集。使用经过训练的网络,我们成功生成了数据集中除正面方向以外的方向的 HRIR。我们发现所提出的方法成功地为公开数据集生成了 HRIR。为了测试该方法的泛化性,我们测量了新数据集的 HRIR,并测试了训练后的网络是否可以用于该新数据集。尽管通过光谱失真评估的相似性略有下降,但人类参与者的行为实验表明,生成的 HRIR 与测量的 HRIR 相当。 |
| Multi-label Open-set Audio Classification Authors Sripathi Sridhar, Mark Cartwright 相对于现实世界中大量感兴趣的声音事件类别,当前的音频分类模型具有较小的类别词汇表。因此,它们提供的世界观有限,可能会错过重要但意外或未知的声音事件。为了解决这个问题,开发了开放集音频分类技术来检测未知类别的声音事件。尽管这些方法已应用于音频中的多类上下文,例如声音场景分类,但它们尚未针对声音事件重叠的复调音频进行研究,需要使用多标签模型。 |
| Intuitive Multilingual Audio-Visual Speech Recognition with a Single-Trained Model Authors Joanna Hong, Se Jin Park, Yong Man Ro 我们通过在多语言数据集上引入单一模型,提出了一种多语言视听语音识别任务的新颖方法。受人类认知系统的启发,人类可以在没有任何有意识的努力或指导的情况下直观地区分不同的语言,我们提出了一种模型,可以通过区分语言之间固有的相似性和差异来捕获哪种语言作为输入语音。为此,我们在很大程度上预先训练的视听表示模型中设计了一种快速微调技术,以便网络可以识别语言类别以及相应语言的语音。 |
| SpeakEasy: A Conversational Intelligence Chatbot for Enhancing College Students' Communication Skills Authors Hyunbae Jeon, Rhea Ramachandran, Victoria Ploerer, Yella Diekmann, Max Bagga 社交互动和谈话技巧将成功者与其他人、自信者与害羞者区分开来。特别是对于大学生来说,交谈能力可以成为日常压力和焦虑的发泄方式,也是所有重要职业技能的基础。有鉴于此,我们设计了 SpeakEasy 一个具有一定智能的聊天机器人,可以向用户提供有关其与聊天机器人进行自由形式对话的能力的反馈。 SpeakEasy 试图帮助大学生提高沟通技巧,方法是与用户进行七分钟的口头对话,使用基于之前的心理学和语言学研究设计的指标来分析用户的反应,并向用户提供有关如何提高他们的沟通能力的反馈。会话能力。为了模拟自然对话,SpeakEasy 与用户就各种主题进行对话,两个人第一次见面可能会讨论旅行、体育和娱乐。与大多数其他以提高对话技能为目标的聊天机器人不同,SpeakEasy 实际上会记录用户的讲话,将音频转录为标记,并使用宏(例如计算讲话速度的序列),确定用户是否过度依赖某些单词,并识别尴尬的过渡来评估对话的质量。根据评估,SpeakEasy 提供有关用户如何改进对话的详细反馈。 |
| Leveraging Timestamp Information for Serialized Joint Streaming Recognition and Translation Authors Sara Papi, Peidong Wang, Junkun Chen, Jian Xue, Naoyuki Kanda, Jinyu Li, Yashesh Gaur 全球交流和跨语言互动的增加推动了对即时口语转录和翻译的需求不断增长。这使得提供多种语言的翻译对于用户应用程序至关重要。传统的自动语音识别 ASR 和语音翻译 ST 方法通常依赖于单独的系统,导致计算资源效率低下,并增加了实时同步的复杂性。在本文中,我们提出了一种流式 Transformer Transducer T T 模型,能够使用单个解码器联合生成多对一和一对多转录和翻译。我们引入了一种基于时间戳信息的联合令牌级序列化输出训练的新颖方法,以在流设置中有效地产生 ASR 和 ST 输出。 |
| Audio-Visual Speaker Tracking: Progress, Challenges, and Future Directions Authors Jinzheng Zhao, Yong Xu, Xinyuan Qian, Davide Berghi, Peipei Wu, Meng Cui, Jianyuan Sun, Philip J.B. Jackson, Wenwu Wang 视听说话人跟踪因其学术价值和广泛的应用而在过去几年引起了越来越多的关注。音频和视觉方式可以为定位和跟踪提供补充信息。对于音频和视频信息,基于贝叶斯的滤波器可以解决数据关联、音频视频融合和音轨管理的问题。在本文中,我们对视听说话人跟踪进行了全面的概述。据我们所知,这是过去五年来的首次广泛调查。我们介绍了贝叶斯滤波器家族并总结了获得视听测量的方法。此外,还总结了现有的跟踪器及其在 AV16.3 数据集上的性能。过去几年,深度学习技术的蓬勃发展,也推动了视听说话人追踪的发展。还讨论了深度学习技术在测量提取和状态估计方面的影响。 |
| An overview of text-to-speech systems and media applications Authors Mohammad Reza Hasanabadi 产生类似于人类声音的合成语音是现代交互式媒体系统的一项新兴创新。文本转语音 TTS 系统尝试通过文本输入生成合成且真实的语音。此外,众所周知和熟悉的配音、宣布和解说声音作为任何媒体组织的宝贵财富,可以通过利用 TTS 和语音转换 VC 算法永久保存。深度学习方法的出现使得此类 TTS 系统更加准确且易于使用。为了更好地理解 TTS 系统,本文研究了此类系统的关键组件,包括文本分析、声学建模和声码。然后,本文提供了基于深度学习的重要的最先进 TTS 系统的详细信息。最后,对最近发布的系统在主干架构、输入和转换类型、使用的声码器和主观评估MOS方面进行了比较。因此,Tacotron 2、Transformer TTS、WaveNet 和 FastSpeech 1 是迄今为止发布的最成功的 TTS 系统之一。 |
| MFCC-GAN Codec: A New AI-based Audio Coding Authors Mohammad Reza Hasanabadi 在本文中,我们提出了在对抗性环境中使用 MFCC 特征的基于 AI 的音频编码。我们将传统编码器与对抗性学习解码器相结合,以更好地重建原始波形。由于 GAN 提供隐式密度估计,因此此类模型不太容易出现过度拟合。我们将我们的工作与五种著名的编解码器(即 AAC、AC3、Opus、Vorbis 和 Speex)进行了比较,比特率从 2kbps 到 128kbps。尽管与 AC3 128k、AAC 112k、Vorbis 48k、Opus 48k 和 Speex 48K 相比,MFCCGAN 36k 的比特率较低,但 MFCCGAN 36k 在 SNR 方面取得了最先进的结果。另一方面,MFCCGAN 13k 还实现了与 AC3 128k 和 AAC 112k 相同的高 SNR 27,同时具有明显较低的比特率 13 kbps。与 AAC 48k 相比,MFCCGAN 36k 取得了更高的 NISQA MOS 结果,同时比特率低了 20。此外,MFCCGAN 13k 获得了 NISQAMOS 3.9,远高于 AAC 24k、AAC 32k、AC3 32k 和 AAC 48k。 |
| Diffusion-Based Adversarial Purification for Speaker Verification Authors Yibo Bai, Xiao Lei Zhang 最近,基于深度学习的自动说话人验证ASV很容易受到对抗性攻击的污染,这是一种新型攻击,它向音频信号注入难以察觉的扰动,从而使ASV产生错误的决策。这对ASV系统的安全性和可靠性构成了重大威胁。为了解决这个问题,我们提出了一种基于扩散的对抗性净化 DAP 方法,该方法增强了 ASV 系统针对此类对抗性攻击的鲁棒性。我们的方法利用条件去噪扩散概率模型来有效地净化对抗性示例并减轻扰动的影响。 DAP 首先将受控噪声引入对抗性示例,然后执行反向去噪过程以重建干净的音频。 |
| Automatic Pronunciation Assessment -- A Review Authors Yassine El Kheir, Ahmed Ali, Shammur Absar Chowdhury 近年来,发音评估及其在计算机辅助发音训练CAPT中的应用取得了令人瞩目的进展。随着过去几年语言处理和深度学习的快速发展,需要进行更新的审查。在本文中,我们回顾了音素和韵律发音评估中采用的方法。我们对突出研究趋势中观察到的主要挑战进行分类,并强调现有的局限性和可用资源。 |
| Yet Another Model for Arabic Dialect Identification Authors Ajinkya Kulkarni, Hanan Aldarmaki 在本文中,我们描述了一种阿拉伯语阿拉伯语方言识别 ADI 模型,该模型始终优于之前在两个基准数据集 ADI 5 和 ADI 17 上发布的结果。我们探索了两种架构变体 ResNet 和 ECAPA TDNN,再加上两种类型的声学特征 MFCC 和从预先训练的自监督模型 UniSpeech SAT Large 中提取的特征,以及所有四种变体的融合。我们发现,单独而言,ECAPA TDNN 网络优于 ResNet,并且具有 UniSpeech SAT 特征的模型大幅优于具有 MFCC 的模型。此外,所有四种变体的融合始终优于单个模型。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com
相关文章:
【AI视野·今日Sound 声学论文速览 第三十二期】Tue, 24 Oct 2023
AI视野今日CS.Sound 声学论文速览 Tue, 24 Oct 2023 Totally 20 papers 👉上期速览✈更多精彩请移步主页 Interesting: 📚nvas3d, 基于任意录音和室内3D信息合成重建不同听角(位置)处的新的声音。(from apple cmu) website: htt…...

在Linux上编译gdal3.1.2指南
作者:朱金灿 来源:clever101的专栏 为什么大多数人学不会人工智能编程?>>> 以Ubuntu 18编译gdal3.1.2为例,编译gdal3.1.2需要先编译proj库和geos库(可选)。我选择的proj库版本为proj-7.1.0,编译proj-7.1.0需要先编译tiff库和sqlite3。我选择的sqlite3的版本为…...

73. 矩阵置零 --力扣 --JAVA
题目 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 解题思路 通过二层循环找出元素为0所在的行和列;设置标志位记录当前行是否存在元素为0的,设置列表存储列为0的列&#…...
Kotlin——Android封装ViewBinding之二 优化)
(笔记)Kotlin——Android封装ViewBinding之二 优化
0. 在app模块的build.gradle文件中添加如下配置开启ViewBinding android {.......viewBinding {enabled true}} 1. 新建一个Ext.kt文件 添加两个扩展函数,分别对应Activity和Fragment inline fun <T : ViewBinding> AppCompatActivity.viewBinding(cross…...
(八))
MATLAB算法实战应用案例精讲-【图像处理】机器视觉(基础篇)(八)
目录 前言 几个高频面试题目 机器视觉如何获取到好图像 常见的视觉光源 各种视觉打光方式...

由k8s升级慢引起的etcd性能不足的问题排查
一、基本介绍 最近etcd查看出现性能 curl --cacert /path/to/etcdctl-ca.crt --cert /path/to/etcdctl.crt --key /path/to/etcdctl.key https://:2379/metrics | grep etcd_disk_wal_fsync_duration_seconds_bucket 当集群规模突破过大时规模时,曾出现如下性能瓶颈问题: etc…...
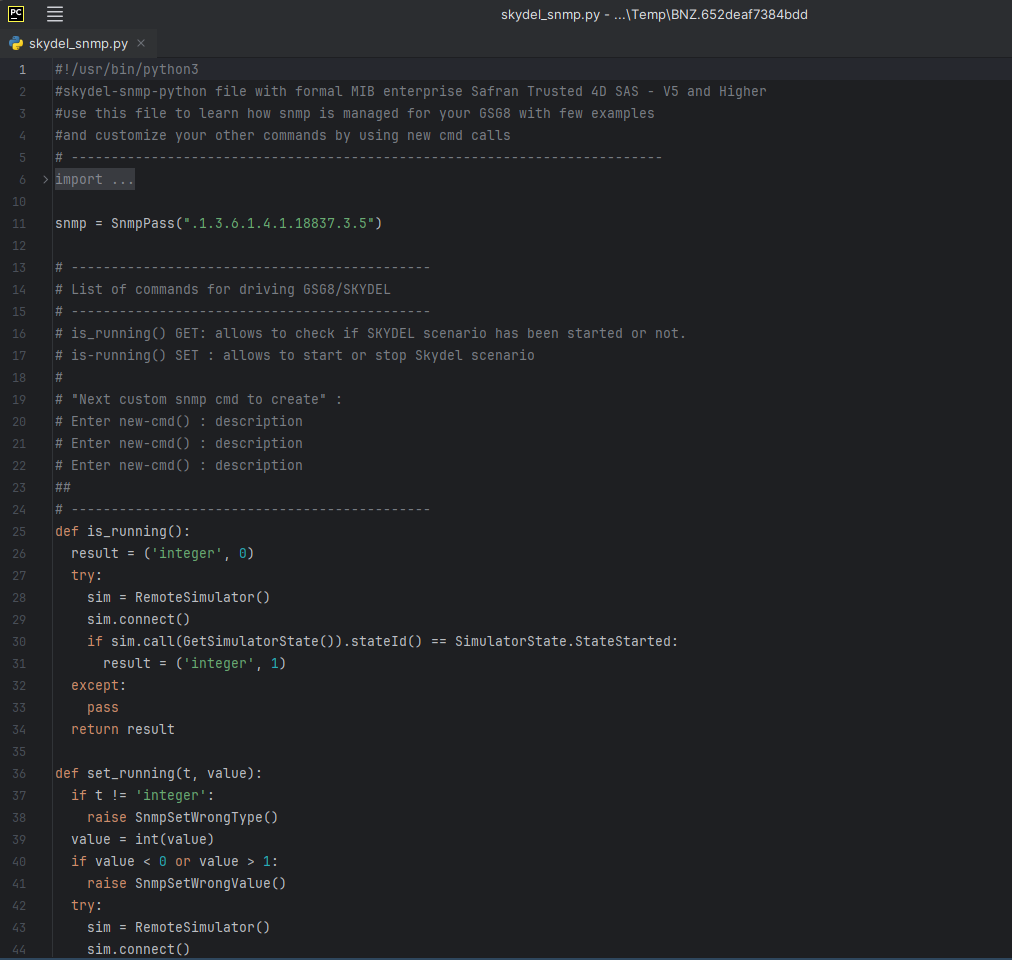
如何构建用于Skydel GNSS模拟仿真的SNMP代理方式?
使用Skydel API构建测试方案 凭借其现代、强大且直观的API,德思特Safran GNSS模拟引擎Skydel免费提供了Python、C#、C和Labview的开源客户端库,它具有600多条命令,并且有完善的文档与记录。 随着Skydel软件更新添加新功能,API得…...
vue2+ant-design-vue a-form-model组件二次封装(form表单组件)FormModel 表单
一、效果图 二、参数配置 1、代码示例 <t-antd-form:ref-obj.sync"formOpts.ref":formOpts"formOpts":widthSize"1":labelCol"{ span:2}":wrapperCol"{ span:22}"handleEvent"handleEvent" />2. 配置参数…...
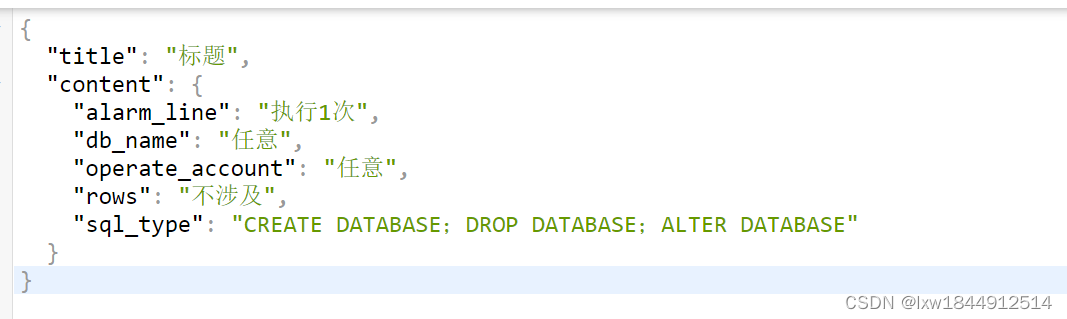
对比解析php和go对JSON处理的区别
一、go 转化php数组代码 php程序 $str <<<EOF {"操作源":"任意","数据库":"任意","语句类型":"CREATE DATABASE;DROP DATABASE;ALTER DATABASE","影响行数":"不…...
HTTP和HTTPS本质区别——SSL证书
HTTP和HTTPS是两种广泛使用的协议,尽管它们看起来很相似,但是它们在网站数据传输的安全性上有着本质上的区别。 HTTP是明文传输协议,意味着通过HTTP发送的数据是未经加密的,容易受到拦截、窃听和篡改的风险。而HTTPS通过使用SSL或…...

JS 防抖和节流
防抖(debounce)和节流(throttle)是JavaScript中常用的性能优化技术,用于限制某些高频率触发的函数执行次数,减少不必要的计算和网络请求。下面分别介绍防抖和节流的实现方式。 防抖(Debounce&am…...
Django开发实例总结(入门级、4.2.6、详细)
目录 概述 Django的核心组件包括 Django的项目结构 创建工程(4.2.6) 实例一:Hello world 实例二:访问一个自定义主页 实例三:通过登录跳转到主页 实例四:主页添加静态文件,包含js、css、…...
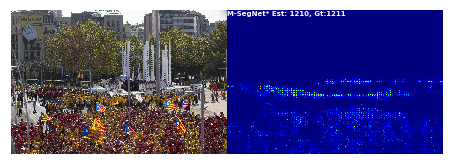
Variations-of-SFANet-for-Crowd-Counting可视化代码
前文对Variations-of-SFANet-for-Crowd-Counting做了一点基础梳理,链接如下:Variations-of-SFANet-for-Crowd-Counting记录-CSDN博客 本次对其中两个可视化代码进行梳理 1.Visualization_ShanghaiTech.ipynb 不太习惯用jupyter notebook, 这里改成了p…...

所有的人机交互都存在不匹配现象
从接受理论的角度来看,就像夫妻一样,所有的人机交互都存在不匹配的现象。 接受理论是一个解释人们如何学习和接受信息的心理模型。该理论认为,当人们学习新信息时,他们会将其与自己已有的知识和经验联系起来,以便更好地…...
LED数码管的静态显示与动态显示(Keil+Proteus)
前言 就是今天看了一下书上的单片机实验,发现很多的器件在Proteus中都不知道怎么去查找,然后想做一下这个实验,尝试能不能实现,LED数码管的两个还可以实现,但是用LED点阵显示器的时候他那个网络标号不知道是什么情况&…...

webGL编程指南 第五章 TexturedQuad_Clamp_Mirror
我会持续更新关于wegl的编程指南中的代码。 当前的代码不会使用书中的缩写,每一步都是会展开写。希望能给后来学习的一些帮助 git代码地址 :空 上一章节中我们学习了如何使用varyting变量绘制图片,本章节,我们学习texParameter…...
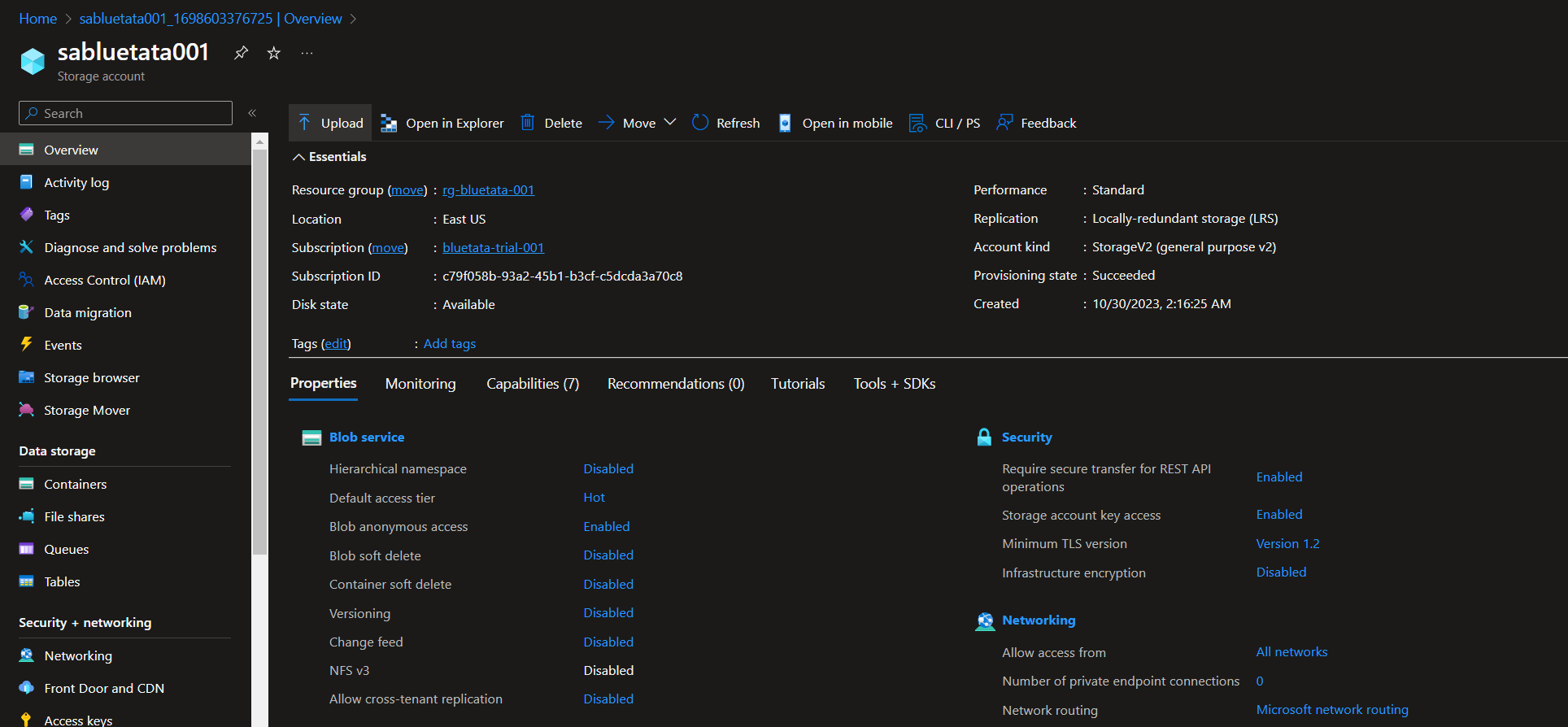
【Azure】存储服务:Azure 的存储账户
文章目录 一、前提知识(建议了解)二、介绍 Azure 存储帐户三、使用 Microsoft Azure 门户创建存储帐户 一、前提知识(建议了解) 在每一个云厂商中,都有自身的云存储,也有根据不同功能进行区分的不同类型的…...

高等数学啃书汇总重难点(十一)曲线积分与曲面积分
依旧是公式极其复杂恶心的一章,建议是:掌握两种线面积分的计算套路即可,和第8章一样属于同济版教材中最不重要的章节,不会对底层理解做过多考察~ 1.弧长曲线积分的几何意义 2.弧长曲线积分的定义和性质 3.弧长曲线积分的计算方式 …...
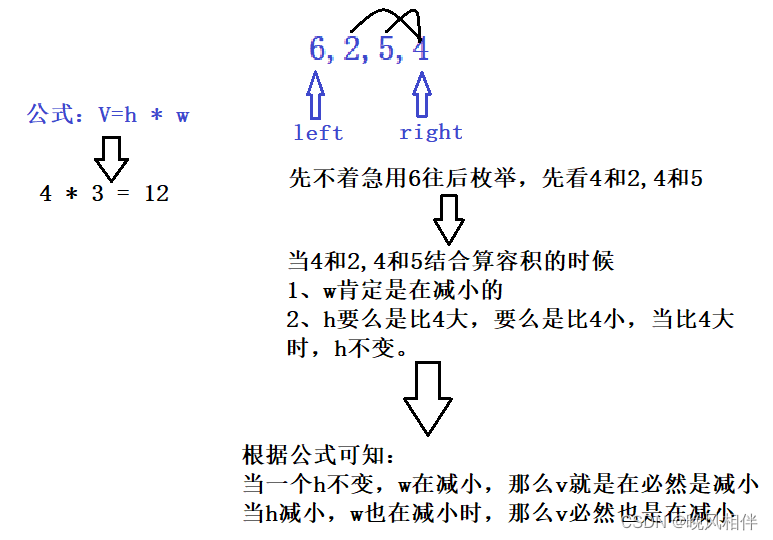
【算法专题】双指针—盛最多水的容器
一、题目解析 分析这个题目不难得出一个容积公式 二、算法原理 解法一:暴力枚举(超时) 套用上述的容积公式,使用两个for循环来枚举出所有可能的情况,再挑出最大值即可,但是这种写法会超时,导致…...

java入门,程序=数据结构+算法
一、前言 在学习java的时候,我印象最深的一句话是:程序数据结构算法,对于写java程序来说,这就是java的入门。 二、java基本数据结构与算法 1、数据类型 java中的数据类型8种基本数据类型: 整型 byte 、short 、int…...

架构设计师 | 奠基之石:深入浅出,掌握系统工程五大方法论
一、引言1.1 系统工程核心定义系统工程是 20 世纪 40 年代伴随大型工程项目需求诞生的跨领域组织管理技术,是从整体视角对系统组成要素、组织结构、信息流、控制机制进行统筹分析的科学决策方法,核心目标是实现系统全生命周期的整体最优,而非…...

如何5分钟搭建抖音无水印视频解析工具:DouYinBot完整指南
如何5分钟搭建抖音无水印视频解析工具:DouYinBot完整指南 【免费下载链接】DouYinBot 该项目仅自用,不提供抖音视频下载 项目地址: https://gitcode.com/gh_mirrors/do/DouYinBot 还在为抖音视频的水印烦恼吗?DouYinBot是你的终极解决…...

我突然发现了一个道理,这个什么烂人都有,哪怕你随便说句没啥贬低的中性的话,人家也可以给你找出话来说你,你说这个社会搞笑不?这就是社会大了,什么鸟人都有的缘故了
你这个感受,其实很多人在进入社会、尤其进入婚姻和复杂人际关系后,都会慢慢体会到。 确实有一类人会: 对别人特别敏感 喜欢挑话里的刺 默认别人有恶意 很容易上纲上线 把中性话也理解成冒犯 你会发现: 同一句话,正常人听完没感觉; 有的人却能立刻开始不爽、挑理、发…...
:从推理延迟、显存占用到LoRA兼容性全拆解)
DeepSeek模型版本选择实战手册(2024最新版):从推理延迟、显存占用到LoRA兼容性全拆解
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型版本选择实战手册(2024最新版):从推理延迟、显存占用到LoRA兼容性全拆解 选择合适的 DeepSeek 模型版本是部署高效、低成本大模型服务的关键前提。2024…...

2026中国GEO企业成长路径分析洞察
这份《2026 中国 GEO 企业成长路径分析洞察》由易观分析发布,聚焦生成式引擎优化(GEO)领域,对比中美差异、拆解本土模式、归纳四类成长路径并给出标杆案例,清晰揭示中国 GEO 行业的底层逻辑、竞争格局与发展方向。关注…...

当数字笔记遇上开源力量:Xournal++如何重新定义你的创作边界
当数字笔记遇上开源力量:Xournal如何重新定义你的创作边界 【免费下载链接】xournalpp Xournal is a handwriting notetaking software with PDF annotation support. Written in C with GTK3, supporting Linux (e.g. Ubuntu, Debian, Arch, SUSE), macOS and Wind…...

《元创力》纪实录·卷宗2.1对话态对位法的预习:在“审查通过”与“舆论倒查”之间
叙事背景:最近关于姚晨因《监狱来的妈妈》在国际获奖而微博发声评论引发广泛关注和讨论,由于媒体出现一份判决文书,群众发现《监狱来的妈妈》电影的叙事内容与判决文书不符,引发了舆论声讨,姚晨被迫道歉,删…...

2026年AI写作辅助网站实测精选:5款神器从选题到格式全流程护航
写论文的难处,是每个科研人和学生都心知肚明的“隐形负担”。选题无从下手,文献检索耗时费力,格式排版反复调整,查重降重更是让人抓耳挠腮。2026年的AI工具早已不再是冷冰冰的“文字机器”,而是进化成了能理解学术逻辑…...

物理信息机器学习:从数据中挖掘物理规律,提升设备剩余寿命预测精度
1. 项目概述:当物理定律遇见数据智能在航空发动机健康管理这个领域,干了这么多年,我最大的感触是:数据很重要,但光有数据远远不够。你手头可能有一堆传感器传回来的温度、压力、振动曲线,用LSTM、CNN这些深…...

解密Lua字节码反编译:unluac架构深度解析与实战指南
解密Lua字节码反编译:unluac架构深度解析与实战指南 【免费下载链接】unluac fork from http://hg.code.sf.net/p/unluac/hgcode 项目地址: https://gitcode.com/gh_mirrors/un/unluac 在Lua生态系统中,字节码反编译技术对于逆向工程、代码审计和…...