Variations-of-SFANet-for-Crowd-Counting可视化代码
前文对Variations-of-SFANet-for-Crowd-Counting做了一点基础梳理,链接如下:Variations-of-SFANet-for-Crowd-Counting记录-CSDN博客
本次对其中两个可视化代码进行梳理
1.Visualization_ShanghaiTech.ipynb
不太习惯用jupyter notebook, 这里改成了python代码测试,下面代码提到的测试数据都是项目自带的,权重自己下载一下吧,前文提到了一些需要下载的权重或者数据。
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
from matplotlib import cm as CMimport os
import numpy as np
from scipy.io import loadmat
from PIL import Image; import cv2
import torch
from torchvision import transforms
from models import M_SFANet
part = 'B'; index = 4
DATA_PATH = f"./ShanghaiTech_Crowd_Counting_Dataset/part_{part}_final/test_data/"
fname = os.path.join(DATA_PATH, "ground_truth", f"GT_IMG_{index}.mat")
img = Image.open(os.path.join(DATA_PATH, "images", f"IMG_{index}.jpg")).convert('RGB')
plt.imshow(img)
plt.gca().set_axis_off()
plt.show()
gt = loadmat(fname)["image_info"]
location = gt[0, 0][0, 0][0]
count = location.shape[0]
print(fname)
print('label:', count)
model = M_SFANet.Model()
model.load_state_dict(torch.load(f"./ShanghaitechWeights/checkpoint_best_MSFANet_{part}.pth", map_location=torch.device('cpu'))["model"]);
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])height, width = img.size[1], img.size[0]
height = round(height / 16) * 16
width = round(width / 16) * 16
img = cv2.resize(np.array(img), (width,height), Image.BILINEAR)
img = trans(Image.fromarray(img))[None, :]
model.eval()
density_map, attention_map = model(img)
print('Estimated count:', torch.sum(density_map).item())
print("Visualize estimated density map")
plt.gca().set_axis_off()
plt.margins(0, 0)
plt.gca().xaxis.set_major_locator(plt.NullLocator())
plt.gca().yaxis.set_major_locator(plt.NullLocator())
plt.imshow(density_map[0][0].detach().numpy(), cmap = CM.jet)
# plt.savefig(fname=..., dpi=300)
plt.show()运行结果如下,还有两张可视化的图



上面这样看是不是不太直观,下面这张图够直观

2.Visualization_UCF-QNRF.ipynb
同上改成了python代码测试
import torch
import os
import numpy as np
from datasets.crowd import Crowd
from models.vgg import vgg19
import argparse
from PIL import Image
import cv2
import sys
# sys.path.insert(0, '/home/pongpisit/CSRNet_keras/')
from models import M_SegNet_UCF_QNRF
from matplotlib import pyplot as plt
from matplotlib import cm as CM
datasets = Crowd(os.path.join('/home/pongpisit/CSRNet_keras/CSRNet-keras/wnet_playground/W-Net-Keras/data/UCF-QNRF_ECCV18/processed/', 'test'), 512, 8, is_gray=False, method='val')
dataloader = torch.utils.data.DataLoader(datasets, 1, shuffle=False,num_workers=8, pin_memory=False)
model = M_SegNet_UCF_QNRF.Model()
device = torch.device('cuda')
model.to(device)
# model.load_state_dict(torch.load(os.path.join('./u_logs/0331-111426/', 'best_model.pth'), device))
model.load_state_dict(torch.load(os.path.join('./seg_logs/0327-172121/', 'best_model.pth'), device))
model.eval()epoch_minus = []
preds = []
gts = []for inputs, count, name in dataloader:inputs = inputs.to(device)assert inputs.size(0) == 1, 'the batch size should equal to 1'with torch.set_grad_enabled(False):outputs = model(inputs)temp_minu = count[0].item() - (torch.sum(outputs).item())preds.append(torch.sum(outputs).item())gts.append(count[0].item())print(name, temp_minu, count[0].item(), torch.sum(outputs).item())epoch_minus.append(temp_minu)epoch_minus = np.array(epoch_minus)
mse = np.sqrt(np.mean(np.square(epoch_minus)))
mae = np.mean(np.abs(epoch_minus))
log_str = 'Final Test: mae {}, mse {}'.format(mae, mse)
print(log_str)
met = []
for i in range(len(preds)):met.append(100 * np.abs(preds[i] - gts[i]) / gts[i])idxs = []
for i in range(len(met)):idxs.append(np.argmin(met))if len(idxs) == 5: breakmet[np.argmin(met)] += 100000000
print(set(idxs))
def resize(density_map, image):density_map = 255*density_map/np.max(density_map)density_map= density_map[0][0]image= image[0]print(density_map.shape)result_img = np.zeros((density_map.shape[0]*2, density_map.shape[1]*2))for i in range(result_img.shape[0]):for j in range(result_img.shape[1]):result_img[i][j] = density_map[int(i / 2)][int(j / 2)] / 4result_img = result_img.astype(np.uint8, copy=False)return result_imgdef vis_densitymap(o, den, cc, img_path):fig=plt.figure()columns = 2rows = 1
# X = np.transpose(o, (1, 2, 0))X = osumm = int(np.sum(den))den = resize(den, o)for i in range(1, columns*rows +1):# image plotif i == 1:img = Xfig.add_subplot(rows, columns, i)plt.gca().set_axis_off()plt.margins(0,0)plt.gca().xaxis.set_major_locator(plt.NullLocator())plt.gca().yaxis.set_major_locator(plt.NullLocator())plt.subplots_adjust(top = 1, bottom = 0, right = 1, left = 0, hspace = 0, wspace = 0)plt.imshow(img)# Density plotif i == 2:img = denfig.add_subplot(rows, columns, i)plt.gca().set_axis_off()plt.margins(0,0)plt.gca().xaxis.set_major_locator(plt.NullLocator())plt.gca().yaxis.set_major_locator(plt.NullLocator())plt.subplots_adjust(top = 1, bottom = 0, right = 1, left = 0, hspace = 0, wspace = 0)plt.text(1, 80, 'M-SegNet* Est: '+str(summ)+', Gt:'+str(cc), fontsize=7, weight="bold", color = 'w')plt.imshow(img, cmap=CM.jet)filename = img_path.split('/')[-1]filename = filename.replace('.jpg', '_heatpmap.png')print('Save at', filename)plt.savefig('seg_'+filename, transparent=True, bbox_inches='tight', pad_inches=0.0, dpi=200)processed_dir = '/home/pongpisit/CSRNet_keras/CSRNet-keras/wnet_playground/W-Net-Keras/data/UCF-QNRF_ECCV18/processed/test/'model.eval()c = 0for inputs, count, name in dataloader:img_path = os.path.join(processed_dir, name[0]) + '.jpg'if c in set(idxs):inputs = inputs.to(device)with torch.set_grad_enabled(False):outputs = model(inputs)img = Image.open(img_path).convert('RGB')height, width = img.size[1], img.size[0]height = round(height / 16) * 16width = round(width / 16) * 16img = cv2.resize(np.array(img), (width,height), cv2.INTER_CUBIC)print('Do VIS')vis_densitymap(img, outputs.cpu().detach().numpy(), int(count.item()), img_path)c += 1 else:c += 1但是该代码要用UCF-QNRF_ECCV18数据集,官网的太慢了,给个靠谱的链接:UCF-QNRF_数据集-阿里云天池
下载下来,然后利用bayesian_preprocess_sh.py这个代码处理一下就可以用于上述代码了,注意一下UCF-QNRF_ECCV18的mat文件中点坐标的读取代码有点问题,自己输出一下mat文件信息就看得出来了。输出文件夹中会有相应的jpg和npy文件。

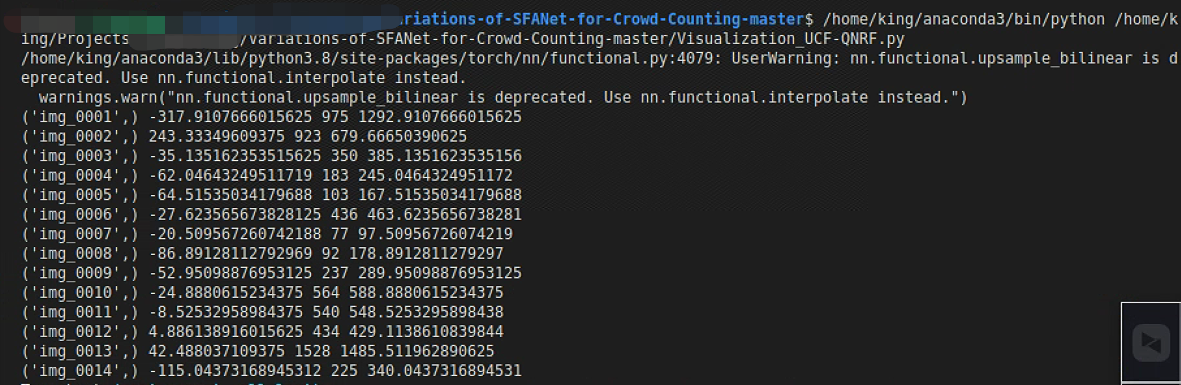
运行可视化代码,这期间遇到了一个报错
ImportError: cannot import name 'COMMON_SAFE_ASCII_CHARACTERS' from 'charset_normalizer.constant' (C:\Anaconda3\lib\site-packages\charset_normalizer\constant.py)邪门解决方案,安装一个chardet
pip install chardet -i https://pypi.tuna.tsinghua.edu.cn/simple要是上述方法还不好使就换一个,更新一下charset_normalizer,或者卸载重装charset_normalizer
pip install --upgrade charset-normalizer要是出现如下报错
RuntimeError:An attempt has been made to start a new process before thecurrent process has finished its bootstrapping phase.This probably means that you are not using fork to start yourchild processes and you have forgotten to use the proper idiomin the main module:if __name__ == '__main__':freeze_support()...The "freeze_support()" line can be omitted if the programis not going to be frozen to produce an executable.把代码中的num_workers改成0,跑起来结果如下

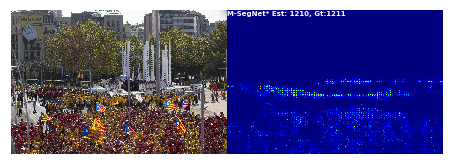
相关文章:
Variations-of-SFANet-for-Crowd-Counting可视化代码
前文对Variations-of-SFANet-for-Crowd-Counting做了一点基础梳理,链接如下:Variations-of-SFANet-for-Crowd-Counting记录-CSDN博客 本次对其中两个可视化代码进行梳理 1.Visualization_ShanghaiTech.ipynb 不太习惯用jupyter notebook, 这里改成了p…...

所有的人机交互都存在不匹配现象
从接受理论的角度来看,就像夫妻一样,所有的人机交互都存在不匹配的现象。 接受理论是一个解释人们如何学习和接受信息的心理模型。该理论认为,当人们学习新信息时,他们会将其与自己已有的知识和经验联系起来,以便更好地…...
LED数码管的静态显示与动态显示(Keil+Proteus)
前言 就是今天看了一下书上的单片机实验,发现很多的器件在Proteus中都不知道怎么去查找,然后想做一下这个实验,尝试能不能实现,LED数码管的两个还可以实现,但是用LED点阵显示器的时候他那个网络标号不知道是什么情况&…...

webGL编程指南 第五章 TexturedQuad_Clamp_Mirror
我会持续更新关于wegl的编程指南中的代码。 当前的代码不会使用书中的缩写,每一步都是会展开写。希望能给后来学习的一些帮助 git代码地址 :空 上一章节中我们学习了如何使用varyting变量绘制图片,本章节,我们学习texParameter…...
【Azure】存储服务:Azure 的存储账户
文章目录 一、前提知识(建议了解)二、介绍 Azure 存储帐户三、使用 Microsoft Azure 门户创建存储帐户 一、前提知识(建议了解) 在每一个云厂商中,都有自身的云存储,也有根据不同功能进行区分的不同类型的…...

高等数学啃书汇总重难点(十一)曲线积分与曲面积分
依旧是公式极其复杂恶心的一章,建议是:掌握两种线面积分的计算套路即可,和第8章一样属于同济版教材中最不重要的章节,不会对底层理解做过多考察~ 1.弧长曲线积分的几何意义 2.弧长曲线积分的定义和性质 3.弧长曲线积分的计算方式 …...
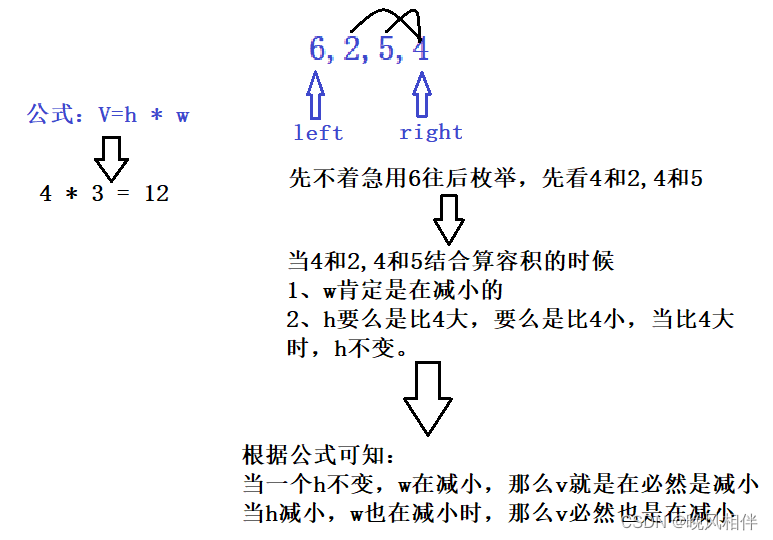
【算法专题】双指针—盛最多水的容器
一、题目解析 分析这个题目不难得出一个容积公式 二、算法原理 解法一:暴力枚举(超时) 套用上述的容积公式,使用两个for循环来枚举出所有可能的情况,再挑出最大值即可,但是这种写法会超时,导致…...

java入门,程序=数据结构+算法
一、前言 在学习java的时候,我印象最深的一句话是:程序数据结构算法,对于写java程序来说,这就是java的入门。 二、java基本数据结构与算法 1、数据类型 java中的数据类型8种基本数据类型: 整型 byte 、short 、int…...
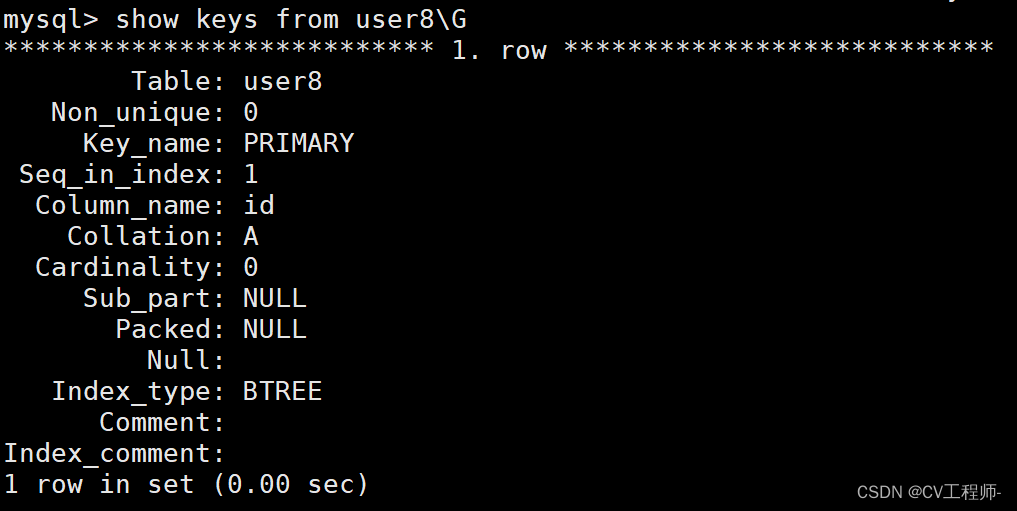
9.MySQL索引的操作
个人主页:Lei宝啊 愿所有美好如期而遇 目录 索引操作 查询索引 创建主键索引 唯一索引的创建 普通索引的创建 全文索引的创建 删除索引 索引创建原则 索引操作 查询索引 第一种方法: show keys from 表名\G 我们了解其中几个就好。 第二种方法…...

大型加油站3d全景虚拟现实展示平台实现全方位立体呈现
近年来,随着国民经济的快速发展,交通基础设施的不断改善,机动车保有量的持续飙升,以至于加油站的建设数量和密度也在不断扩张。加油站作为人流量大且常见的城市场景,对加油站进行安全防范措施具有非常重要的安全意义。…...

Reading:Deep dive into the OnPush change detection strategy in Angular
原文连接:IndepthApp 今天深入阅读并总结Angualr中onPush更新策略。 1. 两种策略 & whats Lview? Angular 实现了两种策略来控制各个组件级别的更改检测行为。这些策略定义为Default和OnPush: 被定义为枚举: export enum…...
野火霸天虎 STM32F407 学习笔记_1 stm32介绍;调试方法介绍
STM32入门——基于野火 F407 霸天虎课程学习 前言 博主开始探索嵌入式以来,其实很早就开始玩 stm32 了。但是学了一段时间之后总是感觉还是很没有头绪,不知道在学什么。前前后后分别尝试了江协科技、正点原子、野火霸天虎三次 stm32 的课程学习。江协科…...
@reduxjs/toolkit配置react-redux解决createStore或将在未来被淘汰警告
通常 我们用redux都需要通过 createStore 但目前 你去用它 基本都会被划线 甚至有点厉害的的编辑器 他会直接告诉你这个东西基本快被弃用了 这个应该大家都知道 最好不要用已经被明确未来或弃用的语法 因为一旦弃用这个系统就需要维护 而且说 一般会被淘汰的语法 本身也就是有…...

致敬1024天前的自己
今早打开手机就收到了来自CSDN的消息,哦,距离我发表第一篇技术博客已经过去1024个日夜了。 我第一次发技术博客是我大二做完我第一个网站时写的。因为网站需要上线服务器,涉及到不少linux相关的知识,我在自学的过程中走了不少弯路…...

〖Python网络爬虫实战㊱〗- JavaScript 网站加密和混淆
订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000+python项目实战 Python编程基础教程系列(零基础小白搬砖逆袭) 说明:本专栏持续更新中,订阅本专栏前必读关于专栏〖Python网络爬虫实战〗转为付费专栏的订阅说明作者:爱吃饼干的小白鼠。Python领域优质创作者,2022年度…...
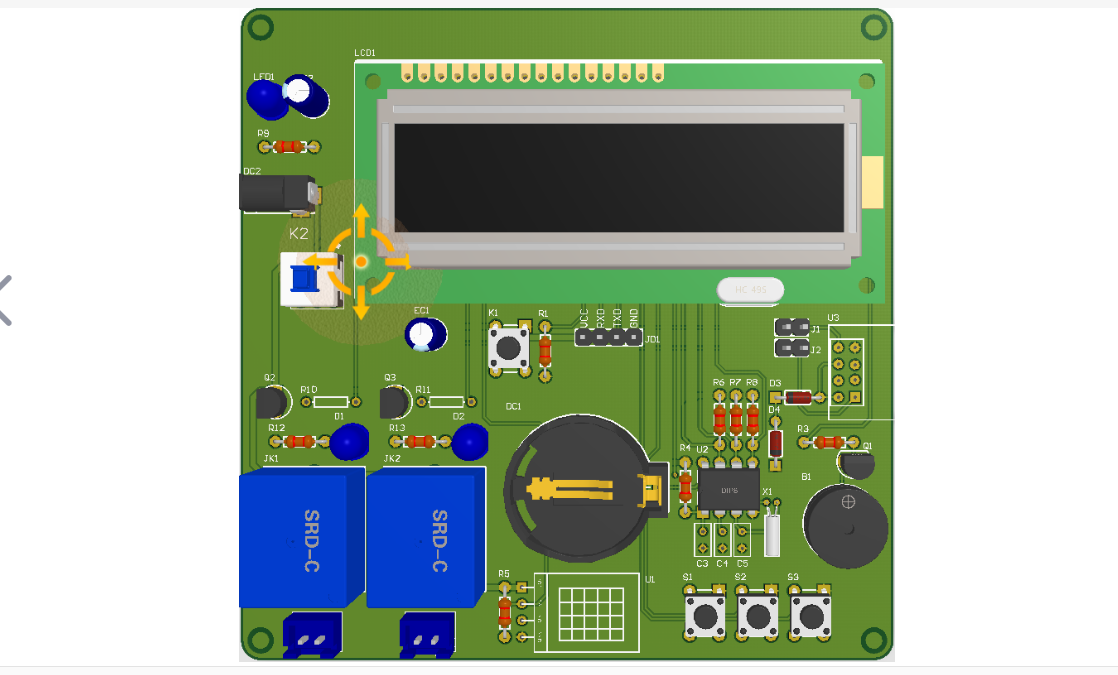
基于单片机设计的电子柜锁
一、前言 随着现代社会的不断发展,电子柜锁的应用越来越广泛。传统的机械柜锁存在一些不便之处,例如钥匙容易丢失、密码容易泄露等问题。设计一款基于单片机的电子柜锁系统成为了一个有趣而有意义的项目。 该电子柜锁系统通过电磁锁作为柜锁的开关&…...

Windows安装tensorflow-gpu=1.14.0CUDA=10.0cuDNN=7.4 (多版本CUDA共存)
文章目录 0. 前置说明1. 查看版本对应关系2. 安装 cuda3. 安装 cudnn4. 添加环境变量5. 安装 tensorflow 0. 前置说明 本机(Windows 11)已安装CUDA 11.7 使用命令查看显卡驱动: nvidia-smi这里显示的CUDA Version: 11.7说明支持安装11.7版本…...

CodeWhisperer 初体验
文章作者:1颗 orange 最近用了一个叫 CodeWhisperer 的插件,这个软件对于来说开发人员,插件有好多实用的功能,编码更高效,代码质量也提升了很多。 CodeWhisperer 简介 CodeWhisperer 是亚⻢逊出品的一款基于机器学习…...

HNU-算法设计与分析-讨论课1
第一次小班讨论 (以组为单位,每组一题,每组人人参与、合理分工,ppt中标记分工,尽量都有代码演示) 1.算法分析题 2-10、2-15(要求:有ppt(可代码演示)) 2.算法实现题 2-4、…...

java连接zookeeper
API ZooKeeper官方提供了Java API,可以通过Java代码来连接zookeeper服务进行操作。可以连接、创建节点、获取节点数据、监听节点变化等操作,具体有以下几个重要的类: ZooKeeper:ZooKeeper类是Java API的核心类,用于与…...
)
避坑指南:在银河麒麟V10 ARM服务器安装JDK8,我踩过的那些雷(附Oracle账号问题解决)
银河麒麟V10 ARM服务器JDK8安装实战:从踩坑到精通的完整指南 第一次在银河麒麟V10 ARM架构服务器上安装JDK8的经历,让我深刻体会到什么叫做"理想很丰满,现实很骨感"。本以为和x86环境差不多的流程,却接连遭遇Oracle账号…...

从COCO person_keypoints到YOLO格式:一份完整的姿态估计数据集转换脚本与避坑指南
从COCO到YOLO格式:姿态估计数据集转换实战手册在计算机视觉领域,姿态估计任务正从学术研究快速走向工业应用。许多开发者希望利用YOLO系列模型(如YOLOv8-Pose)进行训练,却常常在数据预处理阶段遇到障碍。本文将提供一套…...

【架构实战】解决长文本多轮对话中的“上下文腐化”问题:基于 Multi-Agent 的异步调度引擎设计
大家好,最近在研究 LLM 辅助编程和多角色对话时,我发现了一个非常头疼的问题:“上下文腐化”(Context Rot)。 当你在一个 Session 里塞入多个 System Prompt(比如试图让几个不同的 AI 角色在一个群里聊天&…...

Keil RTX5迁移调试问题与RTOS组件使用指南
1. 问题背景与现象分析最近在将项目从CMSIS-RTOS v1(Keil RTX v4.x)迁移到CMSIS-RTOS v2(Keil RTX v5.x)时,发现Vision调试器中的System and Thread Viewer窗口在调试会话中显示空白。这个现象让习惯了通过图形化界面监…...

随记-关于当下大学生就业现状的个人感想
近来身边不少人都在讨论,如今不少大学生毕业后选择返乡务工,或是回到家乡工厂就业。前两天和家人通话,也听闻不少人毕业后,最终回乡进厂务工、帮衬家里。昨天大学老师也发来消息,和我聊起当下本科毕业生就业压力大、求…...

从集合运算到代码:一文搞懂Jaccard系数,附Python/NumPy/Pandas三种实现方法对比
从集合运算到代码:一文搞懂Jaccard系数,附Python/NumPy/Pandas三种实现方法对比在数据挖掘和机器学习领域,衡量两个集合的相似度是一项基础而重要的任务。Jaccard相似系数作为一种简单直观的度量方法,广泛应用于推荐系统、文本挖掘…...

紧急更新!OpenAI API v4.5对脑筋急转弯类输出新增隐式过滤机制——立即启用这7个绕过策略,保住你的创意产能
更多请点击: https://codechina.net 第一章:OpenAI API v4.5脑筋急转弯过滤机制的底层原理与影响评估 OpenAI API v4.5 引入的脑筋急转弯过滤机制并非独立模块,而是深度集成于请求预处理与响应后置校验双阶段的语义安全策略。其核心依赖于轻…...

Go语言ORM框架GORM深度解析
Go语言ORM框架GORM深度解析 引言 GORM是Go语言中最流行的ORM(对象关系映射)框架,提供了强大的数据访问能力和优雅的API设计。本文将深入探讨GORM的核心功能、高级特性和最佳实践。 一、环境配置 1.1 安装GORM go get gorm.io/gorm go get gor…...

前端可访问性:键盘导航的无障碍设计实践
前端可访问性:键盘导航的无障碍设计实践 前言 各位前端小伙伴,今天咱们来聊聊键盘导航的无障碍问题。想象一下: 你设计了一个漂亮的网站,所有交互都需要鼠标视力正常的用户觉得"交互流畅"但键盘用户完全无法使用视障用户…...

通过curl命令快速测试Taotoken的API连通性与返回
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken的API连通性与返回 在集成大模型服务时,直接使用curl命令进行API测试是一种高效且通用的…...