Hadoop PseudoDistributed Mode 伪分布式
Hadoop PseudoDistributed Mode 伪分布式加粗样式
| hadoop101 | hadoop102 | hadoop103 |
|---|---|---|
| 192.168.171.101 | 192.168.171.102 | 192.168.171.103 |
| namenode | secondary namenode | recource manager |
| datanode | datanode | datanode |
| nodemanager | nodemanager | nodemanager |
| job history | ||
| job log | job log | job log |
1. 升级内核和软件
yum -y update
2. 安装常用软件
yum -y install gcc gcc-c++ autoconf automake cmake make \zlib zlib-devel openssl openssl-devel pcre-devel \rsync openssh-server vim man zip unzip net-tools tcpdump lrzsz tar wget
3. 关闭防火墙
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
systemctl stop firewalld
systemctl disable firewalld
4. 修改主机名和IP地址
hostnamectl set-hostname hadoop101
hostnamectl set-hostname hadoop102
hostnamectl set-hostname hadoop103
vim /etc/sysconfig/network-scripts/ifcfg-ens32
参考如下:
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="none"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens32"
DEVICE="ens32"
ONBOOT="yes"
IPADDR="192.168.171.101"
PREFIX="24"
GATEWAY="192.168.171.2"
DNS1="192.168.171.2"
IPV6_PRIVACY="no"
5. 修改hosts配置文件
vim /etc/hosts
修改内容如下:
192.168.171.101 hadoop101
192.168.171.102 hadoop102
192.168.171.103 hadoop103
重启系统 注意:如果是虚拟机环境请关机 克隆
reboot
6. 下载安装JDK和Hadoop并配置环境变量
在所有主机节点创建软件目录
mkdir -p /opt/soft
以下操作在 hadoop101 主机上完成
进入软件目录
cd /opt/soft
下载 JDK
wget https://download.oracle.com/otn/java/jdk/8u391-b13/b291ca3e0c8548b5a51d5a5f50063037/jdk-8u391-linux-x64.tar.gz?AuthParam=1698206552_11c0bb831efdf87adfd187b0e4ccf970
下载 hadoop
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
解压 JDK 修改名称
解压 hadoop 修改名称
tar -zxvf jdk-8u391-linux-x64.tar.gz -C /opt/soft/
mv jdk1.8.0_391/ jdk-8
tar -zxvf hadoop-3.3.5.tar.gz -C /opt/soft/
mv hadoop-3.3.5/ hadoop-3
配置环境变量
vim /etc/profile.d/my_env.sh
编写以下内容:
export JAVA_HOME=/opt/soft/jdk-8
export set JAVA_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED"export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=rootexport YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootexport HADOOP_HOME=/opt/soft/hadoop-3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin生成新的环境变量
注意:分发软件和配置文件后 在所有主机执行该步骤
source /etc/profile
7. 配置ssh免密钥登录
创建本地秘钥并将公共秘钥写入认证文件
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
ssh-copy-id root@hadoop101
ssh-copy-id root@hadoop102
ssh-copy-id root@hadoop103
ssh root@hadoop101
exit
ssh root@hadoop102
exit
ssh root@hadoop101
exit
8. 修改配置文件
cd $HADOOP_HOME/etc/hadoop
hadoop-env.sh
core-site.xml
hdfs-site.xml
workers
mapred-site.xml
yarn-site.xml
hadoop-env.sh
hadoop-env.sh 文件末尾追加
export JAVA_HOME=/opt/soft/jdk-8
export set JAVA_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED"export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=rootexport YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootcore-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop101:8020</value></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop_data</value></property><property><name>hadoop.http.staticuser.user</name><value>root</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
</configuration>hdfs.site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 指定副本数量 --><property><name>dfs.replication</name><value>3</value></property><!-- 指定 secondarynamenode 运行位置 --><property><name>dfs.namenode.secondary.http-address</name><value>hadoop102:50090</value></property>
</configuration>
workers
注意:
hadoop2.x中该文件名为slaves
hadoop3.x中该文件名为workers
hadoop101
hadoop102
hadoop103
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property><!-- yarn历史服务端口 --><property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value></property><!-- yarn历史服务web访问端口 --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value></property>
</configuration>yarn-site.xml
<?xml version="1.0"?>
<configuration><!-- 指定YARN的主角色(ResourceManager)的地址 --><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value></property><!-- 是否将对容器实施物理内存限制 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!-- 是否将对容器实施虚拟内存限制。 --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><!-- 开启日志聚集 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置yarn历史服务器地址 --><property><name>yarn.log.server.url</name><value>http://hadoop102:19888/jobhistory/logs</value></property><!-- 保存的时间7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
</configuration>9. 分发软件和配置文件
分发 ssh 免密钥
scp -r ~/.ssh root@hadoop102:~/
rsync -av --progress ~/.ssh root@hadoop103:~/
分发 hosts 文件
rsync -v --progress /etc/hosts root@hadoop102:/etc/
rsync -v --progress /etc/hosts root@hadoop103:/etc/
分发软件
rsync -av --progress /opt/soft/jdk-8 root@hadoop102:/opt/soft
rsync -av --progress /opt/soft/hadoop-3 root@hadoop102:/opt/soft
rsync -av --progress /opt/soft/jdk-8 root@hadoop103:/opt/soft
rsync -av --progress /opt/soft/hadoop-3 root@hadoop103:/opt/soft分发环境变量
rsync -v --progress /etc/profile.d/my_env.sh root@hadoop102:/etc/profile.d/
rsync -v --progress /etc/profile.d/my_env.sh root@hadoop103:/etc/profile.d/
在所有主机节点 使新的环境变量生效
source /etc/profile
10. 初始化集群
hadoop101
# 格式化文件系统
hdfs namenode -format
# 启动 NameNode SecondaryNameNode DataNode
start-dfs.sh
# 查看启动进程
jps
# hadoop101 看到 NameNode DataNode
# hadoop102 看到 SecondaryNameNode DataNode
# hadoop101 看到 DataNode
hadoop103
# 启动 ResourceManager daemon 和 NodeManager
start-yarn.sh
# 查看启动进程
jps
# hadoop101 看到 NameNode DataNode NodeManager
# hadoop102 看到 SecondaryNameNode DataNode NodeManager
# hadoop101 看到 DataNode ResourceManager NodeManager
hadoop102
# 启动 JobHistoryServer
mapred --daemon start historyserver
# 查看启动进程
jps
# hadoop101 看到 NameNode DataNode NodeManager
# hadoop102 看到 SecondaryNameNode DataNode NodeManager JobHistoryServer
# hadoop101 看到 DataNode ResourceManager NodeManager
重点提示:
# 关机之前 依关闭服务
# Hadoop102
mapred --daemon stop historyserver
# hadoop103
stop-yarn.sh
# hadoop101
stop-dfs.sh
# 开机后 依次开启服务
# hadoop101
start-dfs.sh
# hadoop103
start-yarn.sh
# hadoop102
mapred --daemon start historyserver
11. 修改windows下hosts文件
C:\Windows\System32\drivers\etc\hosts
追加以下内容:
192.168.171.101 hadoop101
192.168.171.102 hadoop102
192.168.171.103 hadoop103
Windows11 注意 修改权限
- 开始搜索 cmd
找到命令头提示符 以管理身份运行


-
进入 C:\Windows\System32\drivers\etc 目录
cd drivers/etc
-
去掉 hosts文件只读属性
attrib -r hosts
-
打开 hosts 配置文件
start hosts
-
追加以下内容后保存
192.168.171.101 hadoop101 192.168.171.102 hadoop102 192.168.171.103 hadoop103
12. 测试
12.1 浏览器访问hadoop集群
浏览器访问: http://hadoop101:9870


浏览器访问:http://hadoop102:50090/

浏览器访问:http://hadoop103:8088

浏览器访问:http://hadoop102:19888/

12.2 测试 hdfs
本地文件系统创建 测试文件 wcdata.txt
vim wcdata.txt
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
在 HDFS 上创建目录 /wordcount/input
hdfs dfs -mkdir -p /wordcount/input
查看 HDFS 目录结构
hdfs dfs -ls /
hdfs dfs -ls /wordcount
hdfs dfs -ls /wordcount/input
上传本地测试文件 wcdata.txt 到 HDFS 上 /wordcount/input
hdfs dfs -put wcdata.txt /wordcount/input
检查文件是否上传成功
hdfs dfs -ls /wordcount/input
hdfs dfs -cat /wordcount/input/wcdata.txt
12.2 测试 mapreduce
计算 PI 的值
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar pi 10 10
单词统计
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount /wordcount/input/wcdata.txt /wordcount/result
hdfs dfs -ls /wordcount/result
hdfs dfs -cat /wordcount/result/part-r-00000
相关文章:
Hadoop PseudoDistributed Mode 伪分布式
Hadoop PseudoDistributed Mode 伪分布式加粗样式 hadoop101hadoop102hadoop103192.168.171.101192.168.171.102192.168.171.103namenodesecondary namenoderecource managerdatanodedatanodedatanodenodemanagernodemanagernodemanagerjob historyjob logjob logjob log 1. …...

个人职业规划
职业规划 软件体系结构 内容 组件 关系 视图 技术 抽象 封装 信息隐藏 模块化 事务分离 耦合和内聚 充分性、完整性和原始性 策略和实现的分离 接口和实现的分离 单一引用点 分而治之 结构 层 管道和过滤器 黑板 系统 分布式系统 代理者 交互式系统 …...
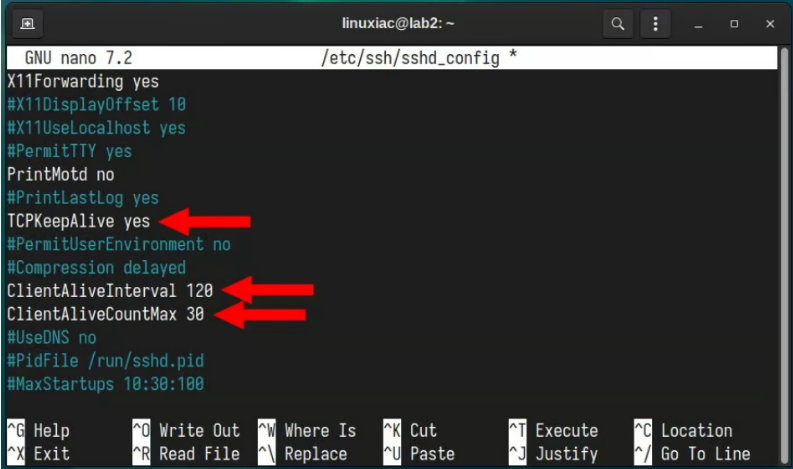
Linux | 如何保持 SSH 会话处于活动状态
在远程服务器管理和安全数据传输中,SSH(Secure Shell)是不可或缺的工具。然而,它的便利性和安全性有时会因常见的问题而受到损害:冻结 SSH 会话。 此外,session 的突然中断可能会导致工作丢失、项目延迟和无…...

树结构及其算法-二叉树节点的插入
目录 树结构及其算法-二叉树节点的插入 C代码 树结构及其算法-二叉树节点的插入 二叉树节点插入的情况和查找相似,重点是插入后仍要保持二叉查找树的特性。如果插入的节点已经在二叉树中,就没有插入的必要了,如果插入的值不在二叉树中&…...
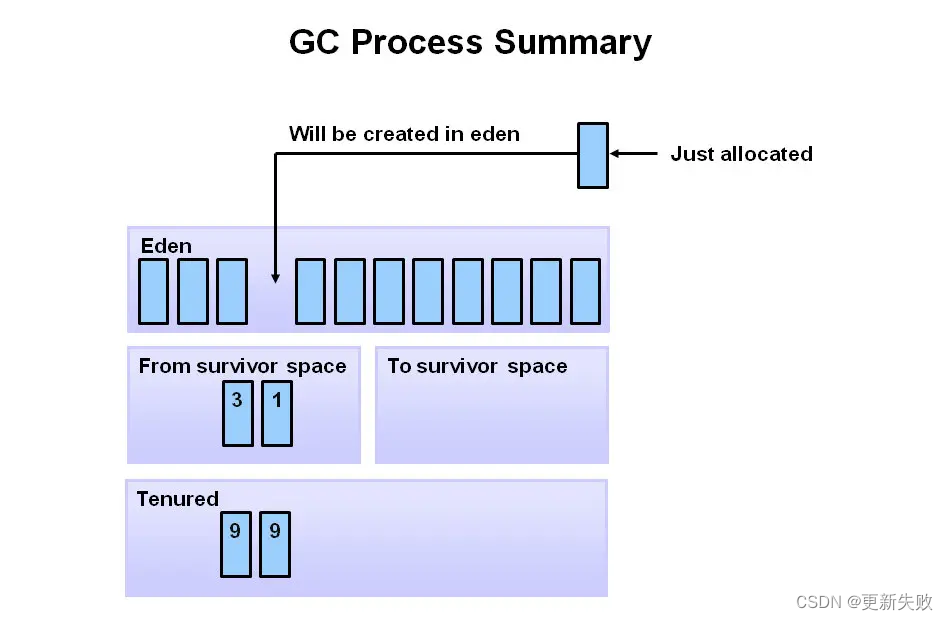
JVM 分代垃圾回收过程
堆空间划分了代: 年轻代(Young Generation)分为 eden 和 Survivor 两个区,Survivor 又分为2个均等的区,S0 和 S1。 首先,新对象都分配到年轻代的 eden 空间,Survivor 刚开始是空的。 当 eden …...

【C++】 常对象与常函数
常函数: 成员函数后加const后我们称为这个函数为常函数常函数内不可以修改成员属性成员属性声明时加关键字mutable后,在常函数中依然可以修改 常对象: 声明对象前加const称该对象为常对象常对象只能调用常函数 一、this指针本质 this指针…...
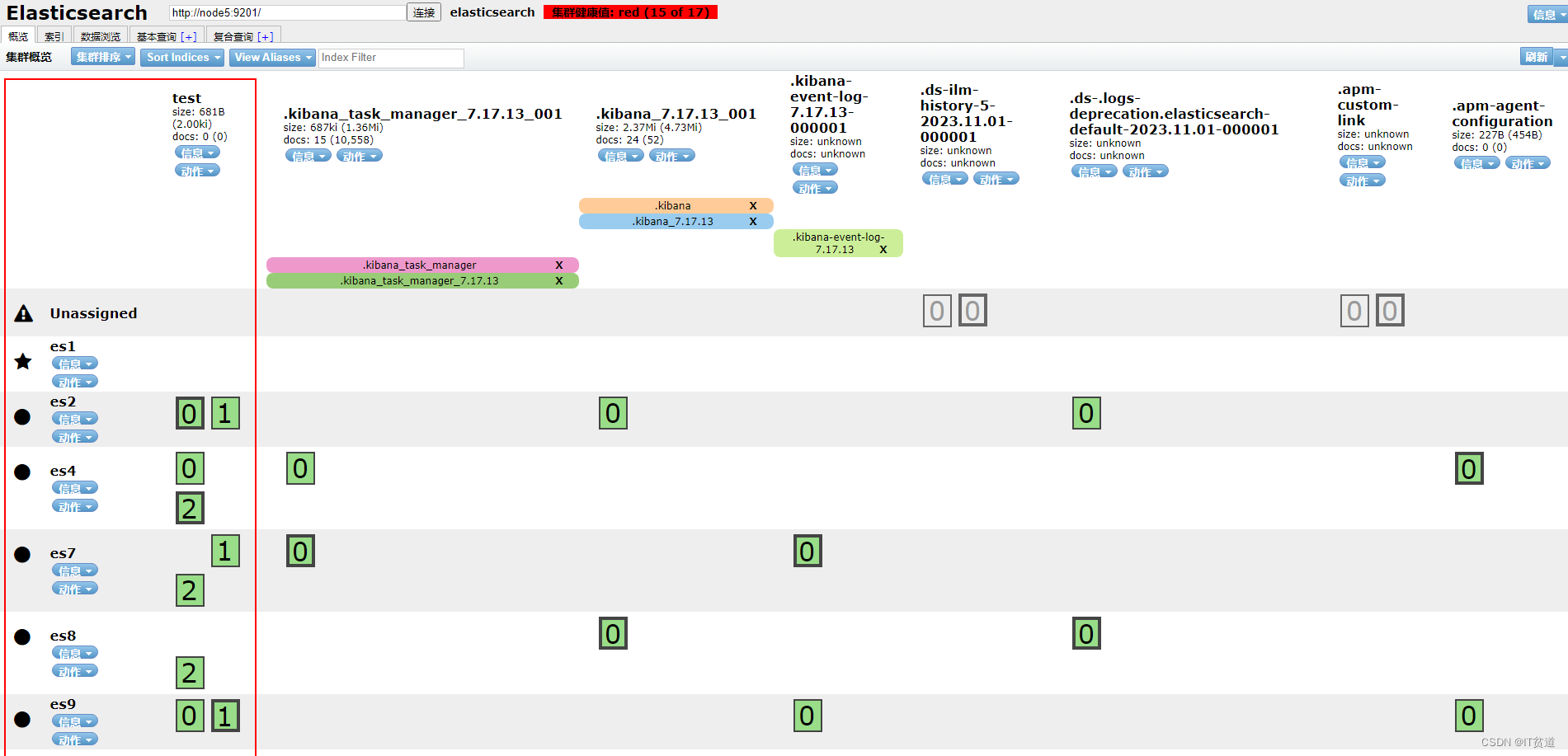
Elasticsearch 集群分片出现 unassigned 其中一种原因详细还原
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹…...

Java调用HTTPS接口,绕过SSL认证
1:说明 网络编程中,HTTPS(Hypertext Transfer Protocol Secure)是一种通过加密的方式在计算机网络上进行安全通信的协议。网络传输协议,跟http相比更安全,因为他加上了SSL/TLS协议来加密通信内容。 Java调…...

前端小技巧: TS实现数组转树,树转数组
将数组转为树 interface IArrayItem {id: number,name: string,parentId: number }interface ITreeNode {id: numbername: stringchildren?: ITreeNode[] }const arr [{id: 1, name: 部门A, parentId: 0},{id: 2, name: 部门B, parentId: 1},{id: 3, name: 部门C, parentId:…...
谷歌动态搜索广告被滥用引发恶意软件泛滥
研究人员发现了一种新方法,可以利用易受攻击的网站向搜索引擎用户发送恶意的、有针对性的广告,这种方法能够传播大量恶意软件,使受害者完全不知所措。 关键是“动态搜索广告”,谷歌利用网站登陆页面的内容将目标广告与搜索配对的…...
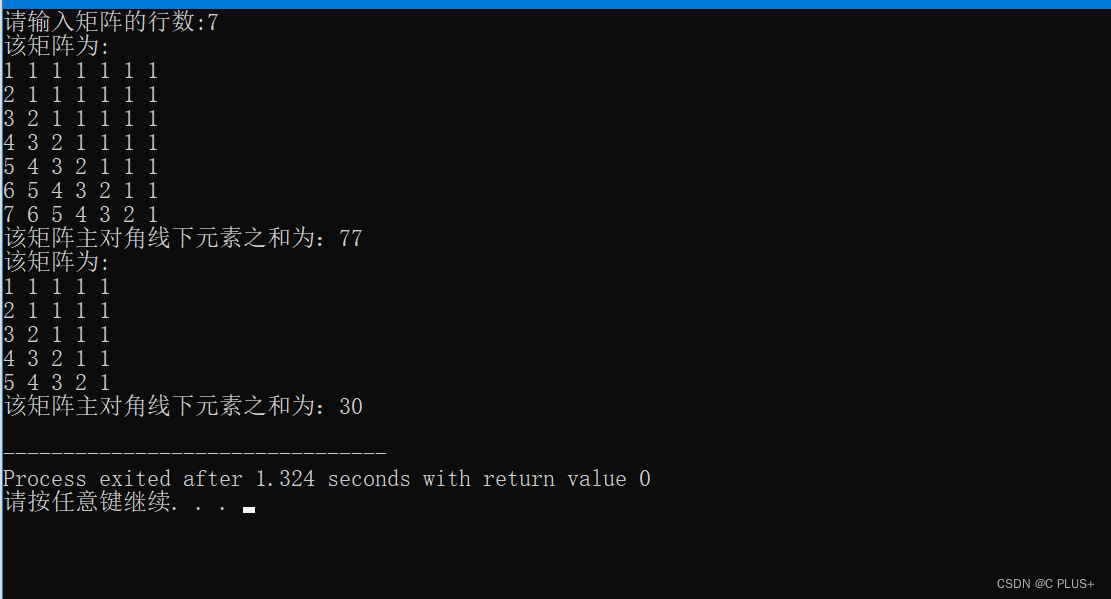
C语言实现 1.在一个二维数组中形成 n 阶矩阵,2.去掉靠边元素,生成新的 n-2 阶矩阵;3.求矩阵主对角线下元素之和:4.以方阵形式输出数组。
矩阵形式: 1 1 1 1 1 2 1 1 1 1 3 2 1 1 1 4 3 2 1 1 5 4 3 2 1 完整代码: /*编写以下函数 1.在一个二维数组中形成如以下形式的 n 阶矩阵: 1 1 1 1 1 2 1 1 1 1 3 2 1 1 1 4 3 2 1 1 5 4 3 2 1 2.去掉…...
我在Vscode学OpenCV 处理图像
既然我们是面向Python的OpenCV(OpenCV for Python)那我们就必须要熟悉Numpy这个库,尤其是其中的数组的库,Python是没有数组的,唯有借助他库才有所实现想要的目的。 # 老三样库--事先导入 import numpy as np import c…...

【python】路径管理+路径拼接问题
路径管理 问题相对路径问题绝对路径问题 解决os库pathlib库最终解决 问题 环境:python3.7.16 win10 相对路径问题 因为python的执行特殊性,使用相对路径时,在不同路径下用python指令会有不同的索引效果(python的项目根目录根据执…...
笔记——结构、联合和枚举)
C现代方法(第16章)笔记——结构、联合和枚举
文章目录 第16章 结构、联合和枚举16.1 结构变量16.1.1 结构变量的声明16.1.2 结构变量的初始化16.1.3 指示器(C99)16.1.4 对结构的操作 16.2 结构类型16.2.1 结构标记的声明16.2.2 结构类型的定义16.2.3 结构作为参数和返回值16.2.4 复合字面量(C99)16.2.5 匿名结构(C1X) 16.3…...
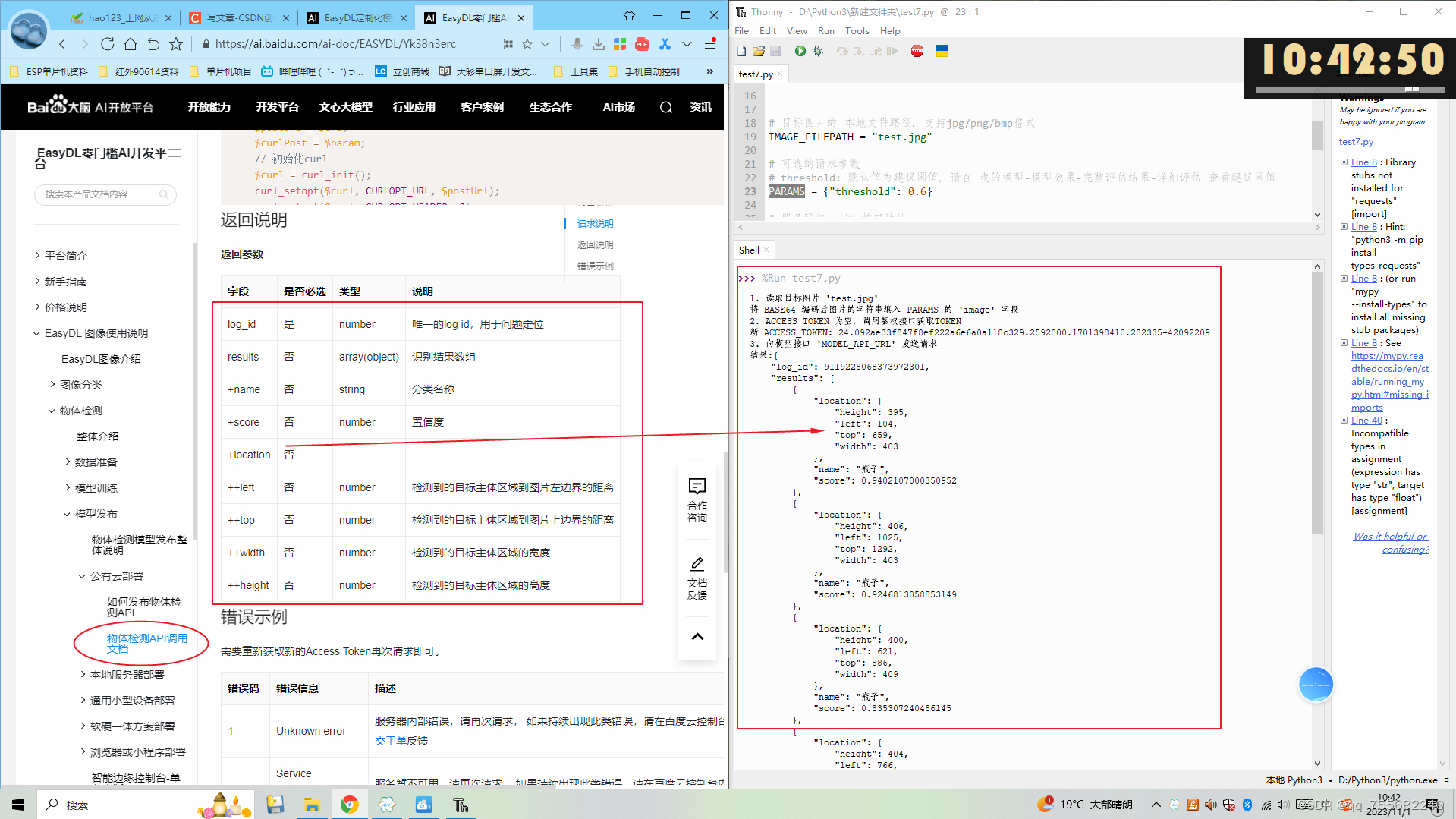
Python项目——识别指定物品
目录 1、百度EasyDL平台数据配置 1.1、训练图像上传 1.2、训练图像进行标注 1.3、训练模型 1.4、检验识别 1.5、申请发布 1.6、控制台权限配置 2、Python调用物体识别API 本项目是基于百度EasyDL平台制作的识别转盘内瓶子,且识别瓶子位置的一个项目。通过在…...
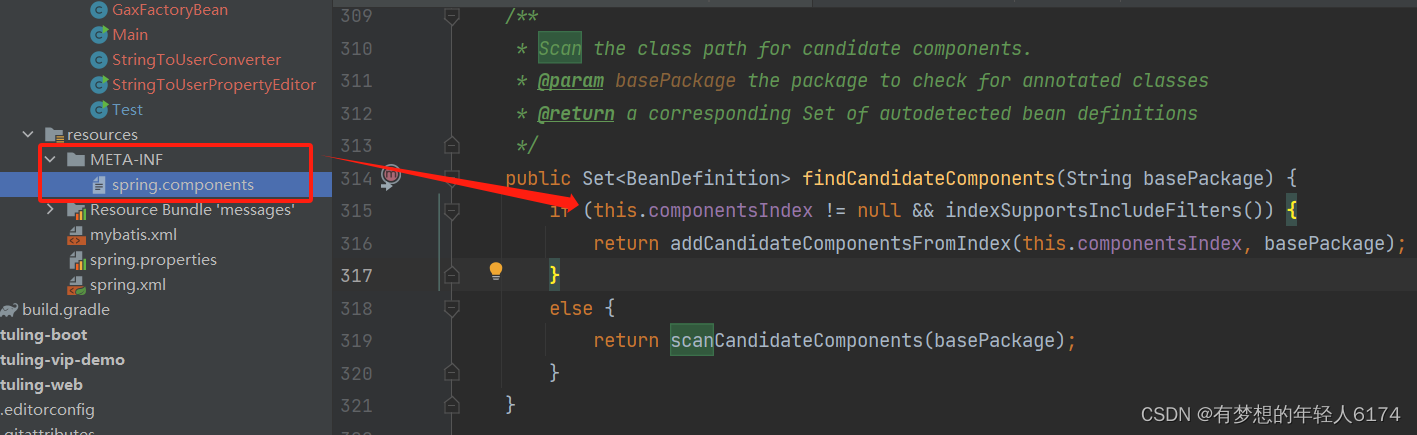
Spring-创建非懒加载的单例Bean源码
补充:关于扫描的逻辑 /*** Scan the class path for candidate components.* param basePackage the package to check for annotated classes* return a corresponding Set of autodetected bean definitions*/ public Set<BeanDefinition> findCandidateCo…...

Techlink TL24G06 网络变压器 10G 基座单端口变压器
功能特征: 1、符合IEEE 802.3标准。 2、符合RoHS。 3、工作温度范围:0C至70C。 4、储存温度范围:-20C至125C。...

Python操作PDF:PDF文件合并与PDF页面重排
处理大量的 PDF 文档是非常麻烦的事情,频繁地打开关闭文件会严重影响工作效率。对于一大堆内容相关的 PDF 文件,我们在处理时可以将这些 PDF 文件合并起来,作为单一文件处理,从而提高处理效率。同时,我们也可以选取不同…...

删除链表的倒数第n个节点(C++解法)
题目 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5]示例 2: 输入:head [1], n 1 输出:[]示例 3&#…...

Apache服务的搭建与配置(超详细版)
前言 Apache是一种常见的Web服务器软件,广泛用于Linux和其他UNIX操作系统上。它是自由软件,可以通过开放源代码的方式进行自由分发和修改。Apache提供了处理静态和动态内容的能力,而且还支持多种编程语言和脚本,如PHP、Python和P…...

为什么83%的Gemini CSR活动陷入“形式主义陷阱”?顶级科技公司首席可持续官亲述3个致命断层与修复路径
更多请点击: https://codechina.net 第一章:Gemini CSR活动策划的底层逻辑重构 传统CSR(企业社会责任)活动策划常陷于“项目驱动”与“KPI导向”的线性思维,而Gemini平台引入的CSR框架则以AI原生协同为前提࿰…...
详解与应用)
Keil开发工具中的计算机识别码(CID)详解与应用
1. 什么是计算机识别码(CID)?计算机识别码(CID)是Keil开发工具中用于唯一标识一台计算机或工作站的10位字母数字代码(格式为XXXXX-XXXXX)。这个标识符由Vision IDE自动生成,包含从硬…...
)
仅限前500名获取:ChatGPT+B站策划私密工作台(含实时热点抓取模块、弹幕情绪预判模型、完播率模拟器v2.3)
更多请点击: https://codechina.net 第一章:ChatGPTB站策划私密工作台的核心价值与准入机制 为什么需要私密工作台 在B站内容生态快速迭代的背景下,策划人员面临选题同质化、数据响应滞后、创意灵感枯竭等现实挑战。ChatGPT 提供了语义理解…...

Java 零基础全套教程,File 类与 IO 流,笔记 175-176
Java 零基础全套教程,File 类与 IO 流,笔记 175-182 一、参考资料 【Java视频教程,java入门神器(附300道Java面试题剖析)】 https://www.bilibili.com/video/BV1PY411e7J6/?p175&share_sourcecopy_web&vd_sou…...

面试官最爱问的“反转字符串”,为什么能看出你是不是高手?
面试官最爱问的“反转字符串”,为什么能看出你是不是高手? 很多人第一次看到“反转字符串(Reverse String)”这道题时,都会有一种感觉: 就这? 不就是把 "hello" 变成 "olleh" 吗? 结果真正面试时。 有人写了 3 行。 有人写了 30 行。 还有人直…...

macOS百度网盘终极加速方案:解锁SVIP高速下载功能
macOS百度网盘终极加速方案:解锁SVIP高速下载功能 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 对于macOS用户而言,百度网盘的…...

BiliBiliCCSubtitle架构解析:C++实现的B站CC字幕高效下载与转换技术方案
BiliBiliCCSubtitle架构解析:C实现的B站CC字幕高效下载与转换技术方案 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle BiliBiliCCSubtitle是一款基于C…...

如何高效安装Adobe插件:ZXPInstaller终极指南
如何高效安装Adobe插件:ZXPInstaller终极指南 【免费下载链接】ZXPInstaller Open Source ZXP Installer for Adobe Extensions 项目地址: https://gitcode.com/gh_mirrors/zx/ZXPInstaller 还在为Adobe插件安装而烦恼吗?每次遇到.zxp文件时&…...
)
Arduino入门教程十三|自制模拟传感器(分压原理详解+光敏夜灯+constrain范围限制)
我整理了一套Arduino 零基础 从入门到高级 完整系统课程,包含视频讲解、全套源码、接线图纸、库文件、ESP32/ESP32-S3 摄像头 & 物联网实战项目,循序渐进,新手也能零基础吃透。需要系统学习可以查看我主页专属课程(零基础保姆级Arduino教程从入门到实战_在线视频教程-C…...

Zotero中文文献管理神器:茉莉花插件3分钟快速上手指南
Zotero中文文献管理神器:茉莉花插件3分钟快速上手指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为Zotero无…...