自定义的卷积神经网络模型CNN,对图片进行分类并使用图片进行测试模型-适合入门,从模型到训练再到测试,开源项目
自定义的卷积神经网络模型CNN,对图片进行分类并使用图片进行测试模型-适合入门,从模型到训练再到测试:开源项目
开源项目完整代码及基础教程:
https://mbd.pub/o/bread/ZZWclp5x
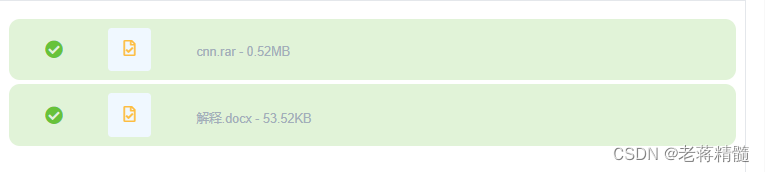
CNN模型:
1.导入必要的库和模块:
torch:PyTorch深度学习框架。
torchvision:PyTorch的计算机视觉库,用于处理图像数据。
transforms:包含数据预处理的模块。
nn:PyTorch的神经网络模块。
F:PyTorch的函数模块,包括各种激活函数等。
optim:优化算法模块。
2.数据预处理:
transforms.Compose:将一系列数据预处理步骤组合在一起。
transforms.ToTensor():将图像数据转换为张量。
transforms.Normalize:对图像数据进行归一化处理,以均值0.5和标准差0.5。
定义批处理大小:
batch_size:每个训练批次包含的图像数量。
加载训练集:
trainset:使用CIFAR-10数据集,设置训练标志为True。
torch.utils.data.DataLoader:创建用于加载训练数据的数据加载器,指定批处理大小和其他参数。
加载测试集:
testset:使用CIFAR-10数据集,设置训练标志为False。
torch.utils.data.DataLoader:创建用于加载测试数据的数据加载器,指定批处理大小和其他参数。
定义CNN模型:
My_CNN:自定义的卷积神经网络模型,包括卷积层、池化层和全连接层。
创建CNN模型、损失函数和优化器:
model:创建My_CNN模型的实例。
nn.CrossEntropyLoss():定义用于多分类问题的交叉熵损失函数。
optim.SGD:使用随机梯度下降优化器,指定学习率和动量。
训练模型:
epochs:指定训练轮数。
循环中的嵌套循环:迭代训练数据批次,进行前向传播、反向传播和参数优化。
保存模型:
model_path:指定模型保存的路径。
torch.save:保存训练后的模型。
在测试集上评估模型性能:
计算模型在测试集上的准确率。
计算每个类别的准确率。
具体代码来说:
transform = transforms.Compose(
[transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
解释:
transforms.Compose:这是一个用于组合多个数据预处理步骤的函数。它允许你按顺序应用多个转换,以便将原始数据转换为最终的形式。
transforms.ToTensor():这是一个数据预处理步骤,将图像数据转换为张量(tensor)的格式。在深度学习中,张量是常用的数据表示方式,因此需要将图像数据从常见的图像格式(如JPEG或PNG)转换为张量。
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)):这是另一个数据预处理步骤,用于对图像进行归一化处理。归一化的目的是将图像的像素值缩放到一个特定的范围,以便神经网络更容易学习。在这里,均值和标准差都被设置为0.5,这将使图像像素值在-1到1之间。
batch_size = 4trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,shuffle=True, num_workers=0)testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,shuffle=False, num_workers=0)
解释:
batch_size = 4:定义了每个训练和测试批次中包含的图像数量。在深度学习中,通常将数据分成小批次进行训练,以便更有效地使用计算资源。
trainset 和 testset 的定义:这两行代码加载了CIFAR-10数据集的训练集和测试集,并进行了如下操作:
torchvision.datasets.CIFAR10:使用CIFAR-10数据集,它包括一组包含10个不同类别的图像数据,适用于图像分类任务。
root=‘./data’:指定数据集的存储目录,可以根据需要更改。
train=True 和 train=False:这两个参数分别用于加载训练集和测试集。
download=True:如果数据集尚未下载,会自动下载。
transform=transform:指定了前面定义的数据预处理管道,将在加载数据时应用。
trainloader 和 testloader 的定义:这两行代码创建了数据加载器,将数据集划分为批次以进行训练和测试。
torch.utils.data.DataLoader:这是PyTorch提供的用于加载数据的工具,可以自动处理数据的分批和洗牌等任务。
batch_size=batch_size:指定了每个批次的大小,即每次加载多少图像数据。
shuffle=True 和 shuffle=False:shuffle参数指定是否在每个epoch(训练轮次)之前对数据进行洗牌,以增加数据的随机性。通常在训练时进行洗牌,而在测试时不进行洗牌。
num_workers=0:这个参数指定用于数据加载的线程数。在此代码中,设置为0表示不使用多线程加载数据。如果有多个CPU核心可用,可以将其设置为大于0的值以加速数据加载。
class My_CNN(nn.Module):
def __init__(self):super().__init__()
省略部分代码
def forward(self, x):
省略部分代码
return x
model = My_CNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
解释:
这部分代码定义了一个卷积神经网络(CNN)模型,并创建了用于训练该模型的损失函数和优化器。让我们逐步解释每一部分:
class My_CNN(nn.Module)::这是一个自定义的CNN模型类的定义。这个类继承自nn.Module,这是PyTorch中构建神经网络模型的基本方式。
def init(self)::这是构造函数,用于初始化CNN模型的各个层。
super().init():调用父类nn.Module的构造函数以确保正确初始化模型。
self.conv1 和 self.conv2:这是两个卷积层的定义,分别具有不同数量的输入和输出通道以及卷积核的大小。
self.pool:这是最大池化层的定义,用于减小特征图的空间尺寸。
self.fc1、self.fc2 和 self.fc3:这是三个全连接层(也称为线性层),用于将卷积层的输出转换为最终的分类结果。
def forward(self, x)::这是前向传播函数,定义了模型的前向传播过程。
在前向传播中,输入x经过卷积层、激活函数(F.relu)、池化层以及全连接层,最终输出分类结果。
torch.flatten(x, 1):这一步将卷积层的输出扁平化,以便将其输入到全连接层。
返回值是模型的输出,表示对输入数据的分类预测。
model = My_CNN():创建了My_CNN类的一个实例,即CNN模型。
criterion = nn.CrossEntropyLoss():定义了损失函数,这里使用的是交叉熵损失函数。它用于衡量模型的预测与实际标签之间的差距,是一个用于监督学习任务的常见损失函数。
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9):定义了优化器,这里使用的是随机梯度下降(SGD)。优化器负责更新模型的参数,以减小损失函数的值。学习率(lr)和动量(momentum)是优化算法的超参数,影响了参数更新的速度和方向。
epochs=5
for epoch in range(epochs): # loop over the dataset multiple times
running_loss = 0.0for i, data in enumerate(trainloader, 0):# get the inputs; data is a list of [inputs, labels]inputs, labels = data# zero the parameter gradientsoptimizer.zero_grad()# forward + backward + optimizeoutputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()if i % 2000 == 1999: # print every 2000 mini-batchesprint(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')running_loss = 0.0
print('Finished Training')
name_path = './cnn_model_model.pth'
torch.save(model,name_path)
解释:
epochs=5:定义了训练的轮次(epochs),也就是模型将遍历整个训练数据集的次数。
for epoch in range(epochs)::这是一个循环,遍历每个训练轮次。
running_loss = 0.0:用于追踪每个训练轮次的累积损失。
for i, data in enumerate(trainloader, 0)::这个嵌套循环遍历训练数据集的小批次。
i 表示当前批次的索引。
data 包含了当前批次的输入数据和标签。
optimizer.zero_grad():在每个批次开始时,将优化器的梯度清零,以便准备计算新的梯度。
outputs = model(inputs):进行前向传播,将输入数据传递给模型,得到模型的输出。
loss = criterion(outputs, labels):计算损失,衡量模型的预测与实际标签之间的差距。使用了前面定义的交叉熵损失函数。
loss.backward():进行反向传播,计算模型参数相对于损失的梯度。
optimizer.step():根据计算得到的梯度,更新模型的参数,以减小损失函数的值。
running_loss += loss.item():累积当前批次的损失值,用于后续打印统计信息。
if i % 2000 == 1999::每经过2000个小批次,打印一次统计信息。这是为了跟踪训练进度,查看损失是否在逐渐减小。
print(f’[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}'):打印当前训练轮次和批次的损失值。
running_loss = 0.0:重置累积损失值,以便下一个统计周期。
print(‘Finished Training’):当所有轮次的训练完成后,打印 “Finished Training” 以指示训练结束。
name_path = ‘./cnn_model_model.pth’:指定模型的保存路径。
torch.save(model, name_path):将训练好的模型保存到指定路径。这样可以在之后的任务中加载和使用该模型,而不需要重新训练。
这段代码执行了模型的训练过程,循环遍历多个轮次,每轮次内遍历训练数据的小批次。在每个小批次中,进行前向传播、计算损失、反向传播以及参数更新。训练的目标是通过调整模型参数,减小损失函数的值,从而提高模型的性能。同时,每隔一定数量的小批次,打印训练统计信息以监视训练进度。最后,训练完成后,模型被保存到文件以备将来使用。
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
prepare to count predictions for each class
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
again no gradients needed
with torch.no_grad():
for data in testloader:images, labels = dataoutputs = model(images)_, predictions = torch.max(outputs, 1)# collect the correct predictions for each classfor label, prediction in zip(labels, predictions):if label == prediction:correct_pred[classes[label]] += 1total_pred[classes[label]] += 1
print accuracy for each class
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')
解释:
classes = (‘plane’, ‘car’, ‘bird’, ‘cat’,‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’):这是数据集中的类别标签,它们代表CIFAR-10数据集中的10个不同类别,分别是飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车。
correct_pred 和 total_pred:这两个字典用于跟踪每个类别的正确预测数量和总预测数量,初始化为零。
with torch.no_grad()::这个语句块指示在此之后的计算不需要梯度信息。这是因为在测试阶段,我们不需要计算梯度,只是进行前向传播和计算准确度。
for data in testloader::遍历测试数据集的小批次。
images, labels = data:将小批次数据分成图像和对应的标签。
outputs = model(images):使用训练好的模型对图像进行预测,得到模型的输出。
_, predictions = torch.max(outputs, 1):通过 torch.max 函数找到每个样本预测的类别,即具有最高预测分数的类别。
for label, prediction in zip(labels, predictions)::通过 zip 函数,将实际标签和预测标签一一对应起来,以便比较它们。
if label == prediction::比较实际标签和预测标签,如果它们相等,表示模型做出了正确的预测。
correct_pred[classes[label]] += 1:对应类别的正确预测数量加一。
total_pred[classes[label]] += 1:对应类别的总预测数量加一。
for classname, correct_count in correct_pred.items()::遍历每个类别和其正确预测数量。
accuracy = 100 * float(correct_count) / total_pred[classname]:计算每个类别的准确度,即正确预测数量除以总预测数量,以百分比表示。
print(f’Accuracy for class: {classname:5s} is {accuracy:.1f} %'):打印每个类别的准确度,格式化输出。
总结:这段代码的目标是计算并打印出每个类别的分类准确度,以便评估模型在不同类别上的性能。这是在测试阶段对模型性能进行评估的一种方式。
测试模型的代码:
import torch
from PIL import Image
from torch import nn
import torch
import torchvision
import torch.nn.functional as F
device = torch.device('cuda')
image_path=“plane.png”
image =Image.open(image_path)
print(image)
image=image.convert('RGB')
transform=torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
image=transform(image)
print(image.shape)
class My_CNN(nn.Module):
def __init__(self):super().__init__()省略部分代码 return x
#加载模型
model = torch.load(“cnn_net_model.pth”,map_location=torch.device(‘cuda’))#加载完成网络模型,映射
print(model)#维数不够
image = torch.reshape(image,(1,3,32,32))#这一个很重要,要满足四个通道
image=image.to(device)#做cuda变换,不然报错
model.eval()
with torch.no_grad():#节约内存性能
output=model(image)
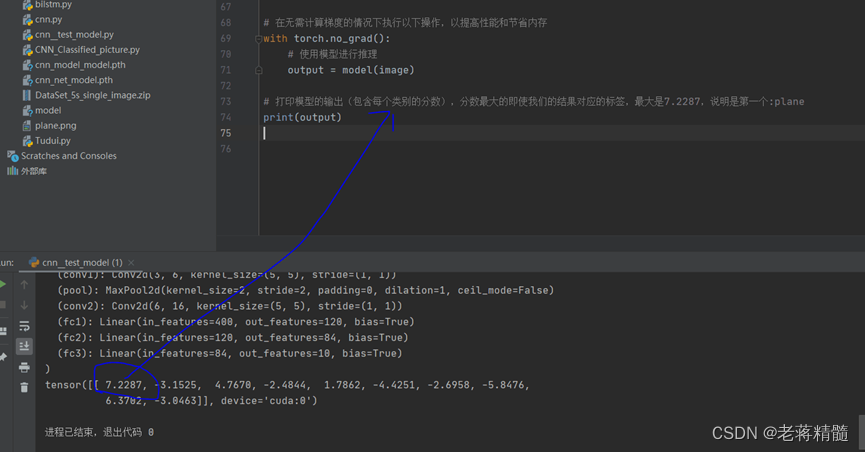
#识别类别,数字最大的就是我们的结果
print(output)
解释:
导入必要的库和模块:
torch:PyTorch库,用于构建和运行深度学习模型。
PIL:Python Imaging Library,用于处理图像。
nn:PyTorch的神经网络模块。
F:PyTorch的函数模块。
device:将模型加载到GPU设备。
image_path:待分类的图像文件路径。
Image.open(image_path):使用PIL库打开图像文件。
图像的预处理:
image.convert(‘RGB’):将图像转换为RGB模式,以确保图像通道数为3。
transform:定义了一系列的图像预处理操作,包括将图像缩放到32x32像素大小并将其转换为PyTorch的Tensor数据类型。
image = transform(image):应用上述的预处理操作,将图像准备好以供模型处理。
定义神经网络模型:
My_CNN 类:这是一个自定义的卷积神经网络模型,包括两个卷积层,两个池化层,以及三个全连接层。这个模型与之前训练的CNN模型相似,用于图像分类任务。
加载预训练模型:
model = torch.load(“cnn_net_model.pth”, map_location=torch.device(‘cuda’)):加载之前训练并保存的CNN模型。map_location 参数指定了模型的加载位置,这里指定为CUDA/GPU。
调整输入图像的维度和数据类型:
image = torch.reshape(image, (1, 3, 32, 32)):将输入的图像数据调整为适合模型的维度(1个样本,3个通道,32x32像素大小)。
image = image.to(device):将图像数据移动到GPU设备,以便进行GPU上的推理。
模型推理和分类:
model.eval():将模型切换到推理模式,这意味着模型不再更新梯度。
with torch.no_grad()::在这个块中,不会计算或保存梯度信息,以提高性能和节省内存。
output = model(image):对输入的图像进行前向传播,得到模型的输出。
print(output):打印模型的输出,这是一个包含了不同类别的分数的张量。
测试结果:
相关文章:
自定义的卷积神经网络模型CNN,对图片进行分类并使用图片进行测试模型-适合入门,从模型到训练再到测试,开源项目
自定义的卷积神经网络模型CNN,对图片进行分类并使用图片进行测试模型-适合入门,从模型到训练再到测试:开源项目 开源项目完整代码及基础教程: https://mbd.pub/o/bread/ZZWclp5x CNN模型: 1.导入必要的库和模块&…...

C# 使用.NET的SocketAsyncEventArgs实现高效能多并发TCPSocket通信
简介: SocketAsyncEventArgs是一个套接字操作得类,主要作用是实现socket消息的异步接收和发送,跟Socket的BeginSend和BeginReceive方法异步处理没有多大区别,它的优势在于完成端口的实现来处理大数据的并发情况。 BufferManager类…...
+ Spring相关源码)
设计模式——观察者模式(Observer Pattern)+ Spring相关源码
文章目录 一、观察者模式定义二、例子2.1 菜鸟教程例子2.1.1 定义观察者2.1.2 定义被观察对象2.1.3 使用 2.2 JDK源码 —— Observable2.2.1 观察者接口Observer2.2.1 被观察者对象Observable 2.3 Spring源码 —— AbstractApplicationContext2.3.1 观察者2.3.2 被观察者 2.3 G…...
openpnp - code review - 开机对话框历史记录和贡献者名单
文章目录 openpnp - code review - 开机对话框历史记录和贡献者名单概述笔记D:\my_openpnp\openpnp_dev_2022_0801\src\main\java\org\openpnp\gui\AboutDialog.javaEND openpnp - code review - 开机对话框历史记录和贡献者名单 概述 偶然发现, 自己打包后的openpnp, 开机后…...

JavaSE22——HashMap
集合框架_HashMap 一、概述 HashMap 是用于存储 Key-Value 键值对的集合。 (1)HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,所以具有很快的访问速度,但遍历顺序不确定。 (2&…...

「图像 merge」无中生有制造数据
在进行一个新项目的时候,往往缺少一些真实数据,导致没办法进行模型训练,这时候就需要算法工程师自行制作一些数据了,比如这篇文章分享的 bag 目标检测,在检测区域没有真实的 bag数据 此时,就可以采用图像拼…...

RK3588之ArmSoM-W3 + MPP实现多路硬解码拉流
简介 学习完MPP的解码Demo之后,想必大家都想通过一个项目来进行RK3588-MPP的解码实战。本篇文章就基于ArmSoM-W3开发板,开发一个多路硬解码项目,实现四路MPP硬解码拉流显示实现的效果如下: RK3588四路MPP硬解码拉流 环境介绍 硬件…...

【Rust日报】2023-10-29 隆重推出 Rerun 0.10!
Lapce代码编辑器发布v0.3.0 Lapce代码编辑器新发布v0.3.0! https://lapce.dev/ 距离我们上次发布已经过去很长一段时间了。我们正忙着在自己的 UI 工具包Floem中重写 Lapce ,这将使我们以后对 UI 部分代码的开发变得更容易、更快。 另一件值得注意的事情…...
AI智能识别如何助力PDF,轻松实现文档处理?
AI智能识别如何助力PDF,轻松实现文档处理? 随着科技的不断发展,人工智能(AI)在各个领域都发挥着重要的作用。其中,文档智能( Document AI )在金融、医疗、教育、保险、能源、物流等…...

【SA8295P 源码分析】114 - 将Android GVM userdata文件系统从 EXT4 修改为 F2FS
【SA8295P 源码分析】114 - 将Android GVM userdata文件系统从 EXT4 修改为 F2FS 一、代码修改方法1. BoardConfig.mk2. 修改 fstab二、开机进入 adb 验证2.1 验证 userdata 修改 f2fs 文件系统格式成功2.2 测试 f2fs 文件系统性能:androbench.apk系列文章汇总见:《【SA8295P…...

LeetCode 387 字符串中的第一个唯一字符 简单
题目 - 点击直达 1. 387 字符串中的第一个唯一字符1. 题目详情1. 原题链接2. 题目要求3. 基础框架 2. 解题思路1. 思路分析2. 时间复杂度3. 代码实现 1. 387 字符串中的第一个唯一字符 1. 题目详情 给定一个字符串 s ,找到 它的第一个不重复的字符,并返…...
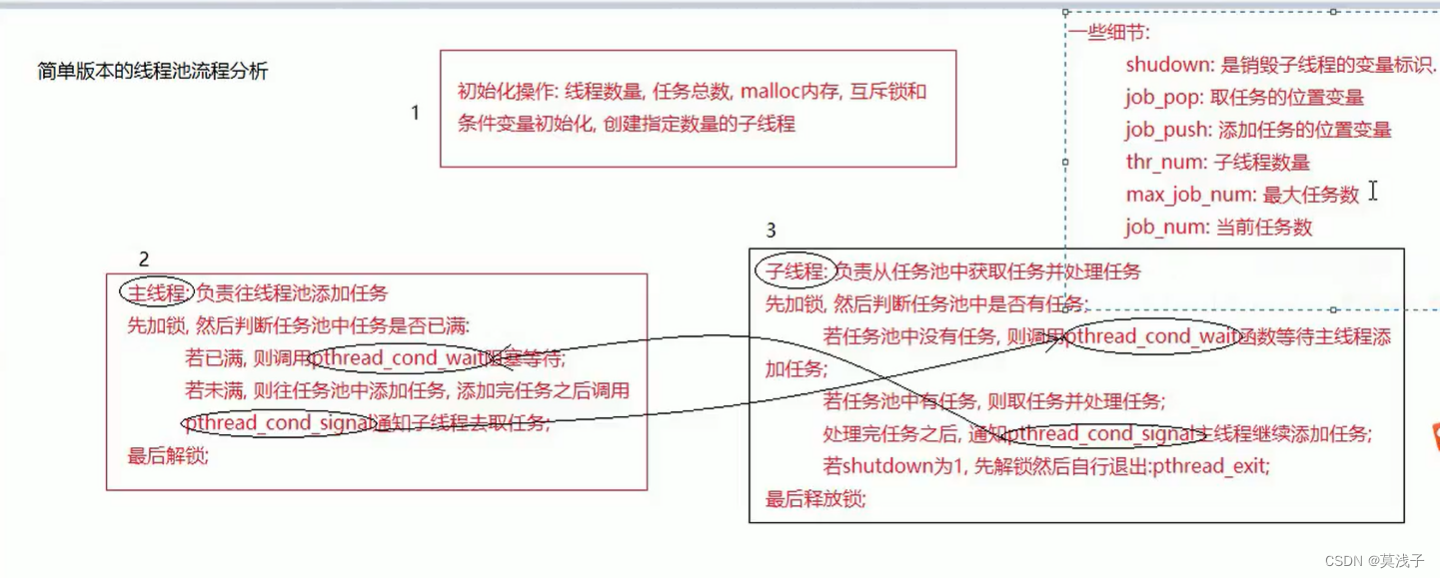
线程池--简单版本和复杂版本
目录 一、引言 二、线程池头文件介绍 三、简单版本线程池 1.创建线程池 2.添加任务到线程池 3.子线程执行回调函数 4.摧毁线程池 5.简单版线程池流程分析 四、复杂版本线程池 1.结构体介绍 2.主线程 3.子线程 4.管理线程 一、引言 多线程版服务器一个客户端就需要…...

docker进阶
文章目录 docker 进阶Part1 常用命令总结docker version 查看docker客户端和服务端信息docker info 查看更加详细信息docker images 列出所有镜像基本用法常用选项 docker search 搜索镜像基本用法示例用法 docker pull 拉取镜像基本用法示例用法 docker rmi 删除镜像基本用法示…...
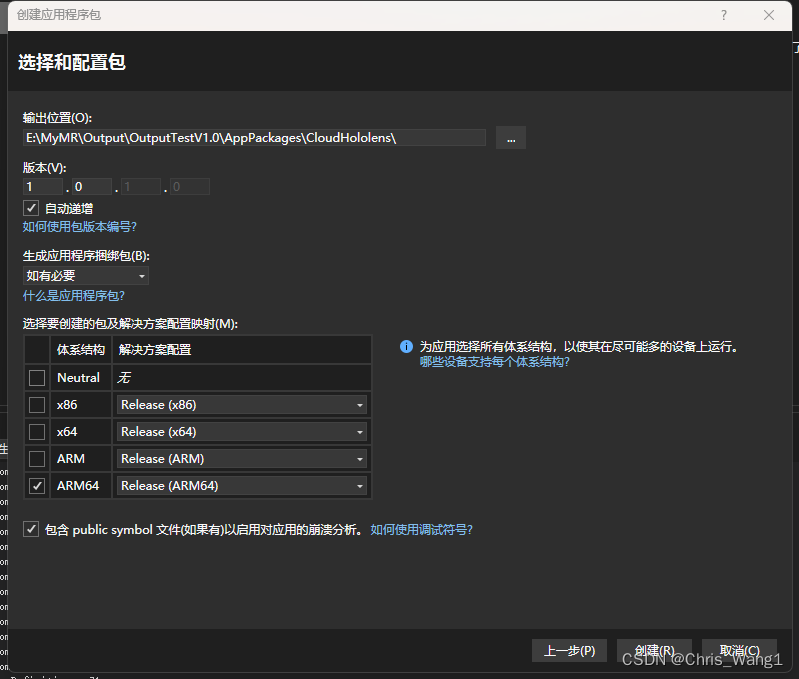
Unity HoloLens 2 应用程序发布
设置3D 启动器画面,glb格式的模型 VS中可以直接生成所有大小的图标...
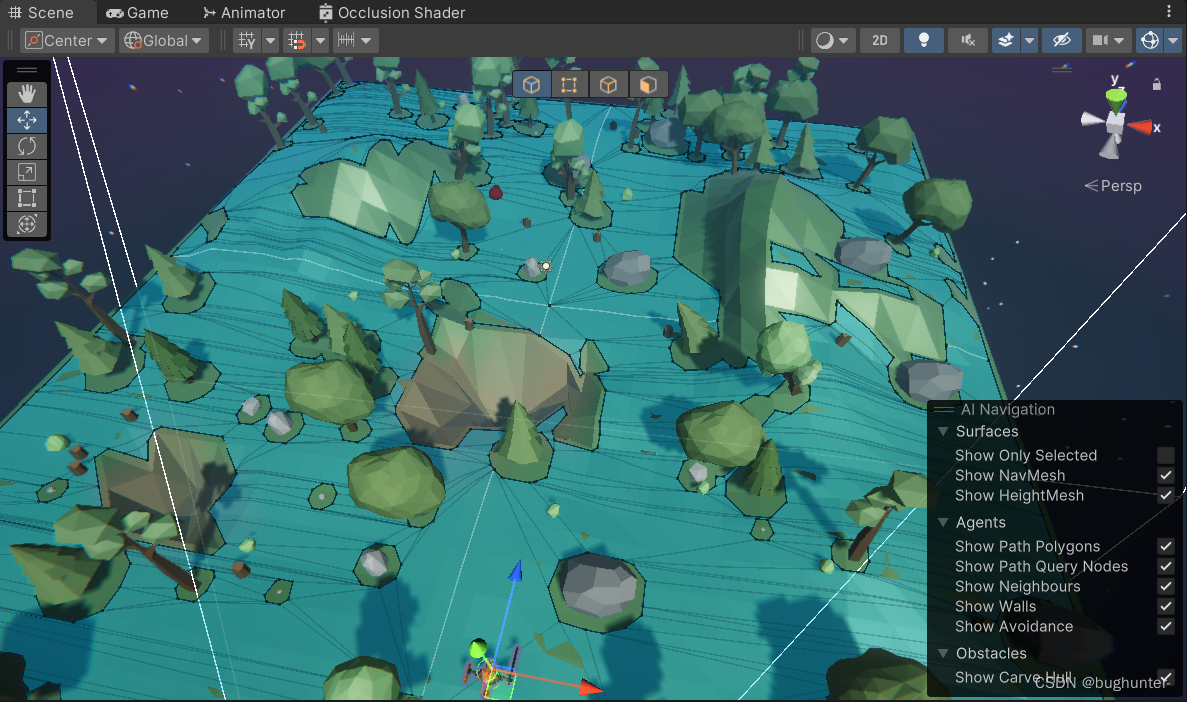
3D RPG Course | Core 学习日记三:Navigation智能导航地图烘焙
前言 前面我们已经绘制好了一个简单的地图场景,现在我们需要使用Navigation给地图做智能导航,以实现AI自动寻路,以及设置地图的可行走区域以及不可行走区域,Navigation的基础知识、原理、用法在Unity的官方文档,以及网…...

Linux 启用本地ISO作为软件源
环境:sle12sp5 (open SUSE) 1、禁用现有的源 查看源:sle12sp5 zypper lr -u ➜ sle12sp5 zypper lr -u Repository priorities are without effect. All enabled repositories share the same prior…...

SpringCloud-Alibaba-Nacos2.0.4
SpringCloud-Alibaba-Nacos2.0.4 SpringCloud Alibaba版本选择(截止到2023年3月12日) Spring Cloud Alibaba VersionSpring Cloud VersionSpring Boot Version2021.0.4.0*Spring Cloud 2021.0.42.6.11 SpringCloud Alibaba-2021.0.4.0组件版本关系 S…...

docker运行镜像相关配置文件
Dockerfile 文件配置 FROM anapsix/alpine-java:8_server-jre_unlimitedMAINTAINER Lion LiRUN mkdir -p /data/sydatasource/logs \/data/sydatasource/temp \/data/skywalking/agentWORKDIR /data/sydatasourceENV SERVER_PORT8220EXPOSE ${SERVER_PORT}ENV TZAsia/Shanghai …...

引擎系统设计思路 - 用户态与系统态隔离
用户态与系统态隔离: a. 外部用户侧的对象或者逻辑,在外部创建使用。内部系统侧的对象或者逻辑,在内部创建使用。 b. 用户状态下对内部系统的操作要立即响应,但是具体如何实际执行系统内部的机制,则是异步并行的。因为…...

致远OA wpsAssistServlet任意文件读取漏洞复现 [附POC]
文章目录 致远OA wpsAssistServlet任意文件读取漏洞复现 [附POC]0x01 前言0x02 漏洞描述0x03 影响版本0x04 漏洞环境0x05 漏洞复现1.访问漏洞环境2.构造POC3.复现 0x06 修复建议 致远OA wpsAssistServlet任意文件读取漏洞复现 [附POC] 0x01 前言 免责声明:请勿利用…...

Unpaywall:5分钟快速安装,轻松解锁付费学术论文的实用指南
Unpaywall:5分钟快速安装,轻松解锁付费学术论文的实用指南 【免费下载链接】unpaywall-extension Firefox/Chrome extension that gives you a link to a free PDF when you view scholarly articles 项目地址: https://gitcode.com/gh_mirrors/un/unp…...

DeepSeek审计日志全链路解析:从日志采集、脱敏、存储到SOC对接的7步生产级落地手册
更多请点击: https://codechina.net 第一章:DeepSeek审计日志的核心价值与架构全景 DeepSeek审计日志是企业级AI平台安全治理的关键基础设施,它不仅记录模型调用、数据访问、权限变更等关键操作事件,更通过结构化、可追溯、防篡改…...

AI智能体:从概念到现实的技术演进与应用前景
AI智能体正渐渐从科幻概念转变成现实应用里的关键角色,这是随着人工智能技术的快速发展而出现的情况。按照2024年发布的报告来看,全球已经存在超过67%的企业其正在规划或者早已经部署了和AI智能体相关的项目,预计到2026年的时候,这…...

Playwright安装失败排障指南:五种生产级部署方式
1. 为什么“mcp-playwright”安装总卡在第一步?——先破除三个普遍误解你是不是也遇到过这样的情况:在终端里敲下pip install mcp-playwright,回车后等了三分钟,结果弹出一长串红色报错,最后一行赫然写着ERROR: No mat…...

终极免费指南:如何用Whisky在Mac上运行Windows游戏与应用
终极免费指南:如何用Whisky在Mac上运行Windows游戏与应用 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 还在为Mac无法畅玩Windows游戏、运行专业软件而烦恼吗ÿ…...

MATLAB XFOIL翼型分析终极指南:快速上手专业气动计算
MATLAB XFOIL翼型分析终极指南:快速上手专业气动计算 【免费下载链接】XFOILinterface 项目地址: https://gitcode.com/gh_mirrors/xf/XFOILinterface 想要在MATLAB环境中轻松进行专业的翼型气动性能分析吗?🚀 XFOILinterface为您提供…...
)
ChatGPT可视化输出总失真?深度解析其底层渲染引擎限制(基于OpenAI v4.12.3源码逆向分析)
更多请点击: https://kaifayun.com 第一章:ChatGPT可视化输出失真现象的实证观察 在实际工程调试与教学演示中,开发者频繁反馈 ChatGPT(尤其是通过 API 或网页界面返回 Markdown 渲染结果)对代码块、数学公式、表格及…...
)
ChatGPT提示工程进阶实战(故事化表达失效的7大隐形陷阱)
更多请点击: https://kaifayun.com 第一章:故事化表达失效的底层认知重构 当工程师在技术文档中反复使用“用户点击按钮后,系统就像一位耐心的向导,带他走过三步旅程”这类修辞时,信息熵并未降低——反而因隐喻失准而…...

终极OneNote Markdown插件:3步让你的笔记焕然一新
终极OneNote Markdown插件:3步让你的笔记焕然一新 【免费下载链接】NoteWidget Markdown add-in for Microsoft Office OneNote 项目地址: https://gitcode.com/gh_mirrors/no/NoteWidget 还在为OneNote中繁琐的格式调整而烦恼吗?OneNote Markdow…...

BooruDatasetTagManager:10倍提升AI训练数据标注效率的智能解决方案
BooruDatasetTagManager:10倍提升AI训练数据标注效率的智能解决方案 【免费下载链接】BooruDatasetTagManager 项目地址: https://gitcode.com/gh_mirrors/bo/BooruDatasetTagManager 面对数千张AI训练图像的繁琐标注工作,你是否感到力不从心&am…...