ChatGPT是如何训练得到的?通俗讲解
首先声明喔,我是没有任何人工智能基础的小白,不会涉及算法和底层原理。
我依照我自己的简易理解,总结出了ChatGPT是怎么训练得到的,非计算机专业的同学也应该能看懂。看完后训练自己的min-ChatGPT应该没问题
希望大牛如果看到这篇文章后,就当图一乐。
文章目录
- ChatGPT名词解释(这里看看就行)
- ChatGPT是怎么训练得到的?
- InstructGTP训练流程
- Step1 以监督学习的方式对GPT3进行微调,得到监督学习模型
- Step2 训练出一个奖赏模型
- Step3 训练得到基于PPO算法的强化学习模型
- 总结
- 最后说一下我对ChatGPT的理解
ChatGPT名词解释(这里看看就行)
ChatGPT=GPT+人类反馈强化学习
GPT是Generative Pre-trained Transformer(生成预训练变换模型)
- Generative:生成的意思,因为这是个能生成文本的模型。
- Pre-trained:预训练的意思,这里代表无监督学习,是没有明确目的的训练方式,你无法提前知道结果是什么,生成文本比较发散。
- Transformer:变换的意思,代表是模型训练是网络架构,网络里面的各个参数不断变换嘛。
人类反馈强化学习是什么呢?
可以这样理解,模型的训练结果很大程度依赖人类的反馈,人类对其生成的结果进行打分。对打分的结果重新输入的模型中,来对模型进行调整。得分高相当于告诉它:”多生成这样的结果!“。得分低的相当于告诉它:”不要生成这样的结果!“。
ChatGPT是怎么训练得到的?
首先看一下ChatGPT发展时段:
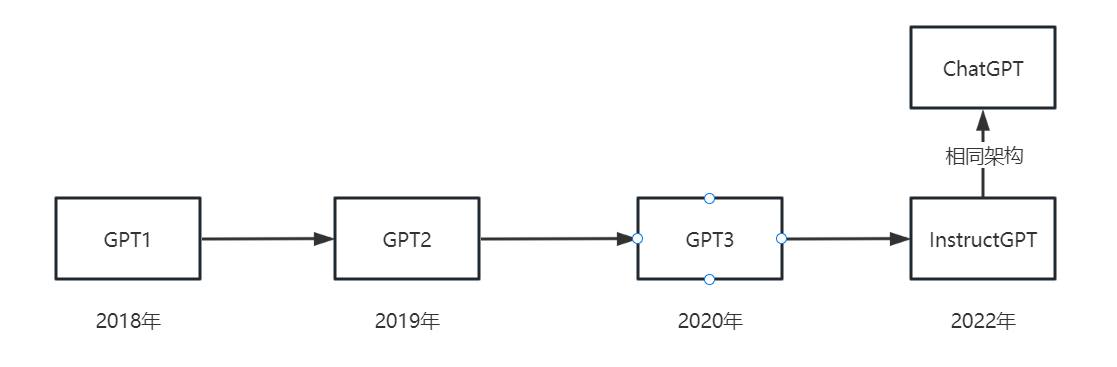
从GPT1到GPT3这个过程,GPT的三个模型几乎都是相同架构,只是有非常非常少量的改动。但一代比一代更大,,也更烧钱.。所以我对GPT系列的特点就是: 钞能力, 大就完事了。 其影响力和花费的成本是成正比的。
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
|---|---|---|---|
| GPT-1 | 2018年6月 | 1.17亿 | 约5GB |
| GPT-2 | 2019年2月 | 15亿 | 40G |
| GPT-3 | 2020年5月 | 1750亿 | 45TB |
从InstructGPT到ChatGPT没有很大的改动,ChatGPT采用的是InstructGPT的架构,本质上是一样的,只不过采用的训练的数据更多和人类聊天相关,所以变成了"ChatGPT"。
所以,最主要是看InstructGPT怎么通过GPT3来的。
InstructGTP训练流程
我参考了OpenAI发表关于InstructGPT论文:https://arxiv.org/pdf/2203.02155.pdf,分为如下的三步。
理论上讲,只要看懂了训练步骤的这三部分,就可以训练得到我们自己的 ChatGPT
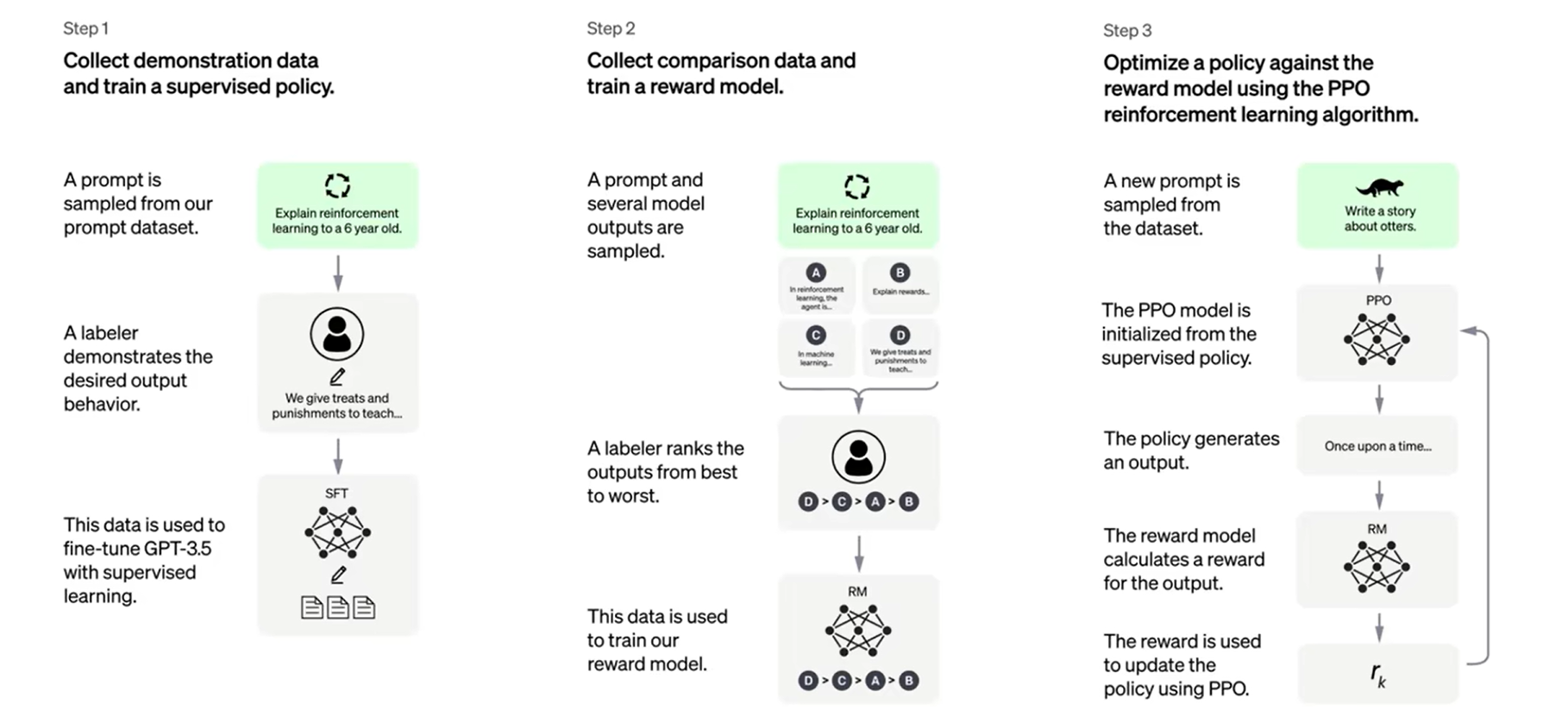
通俗化后如下…,下面我会详细解释每一步。
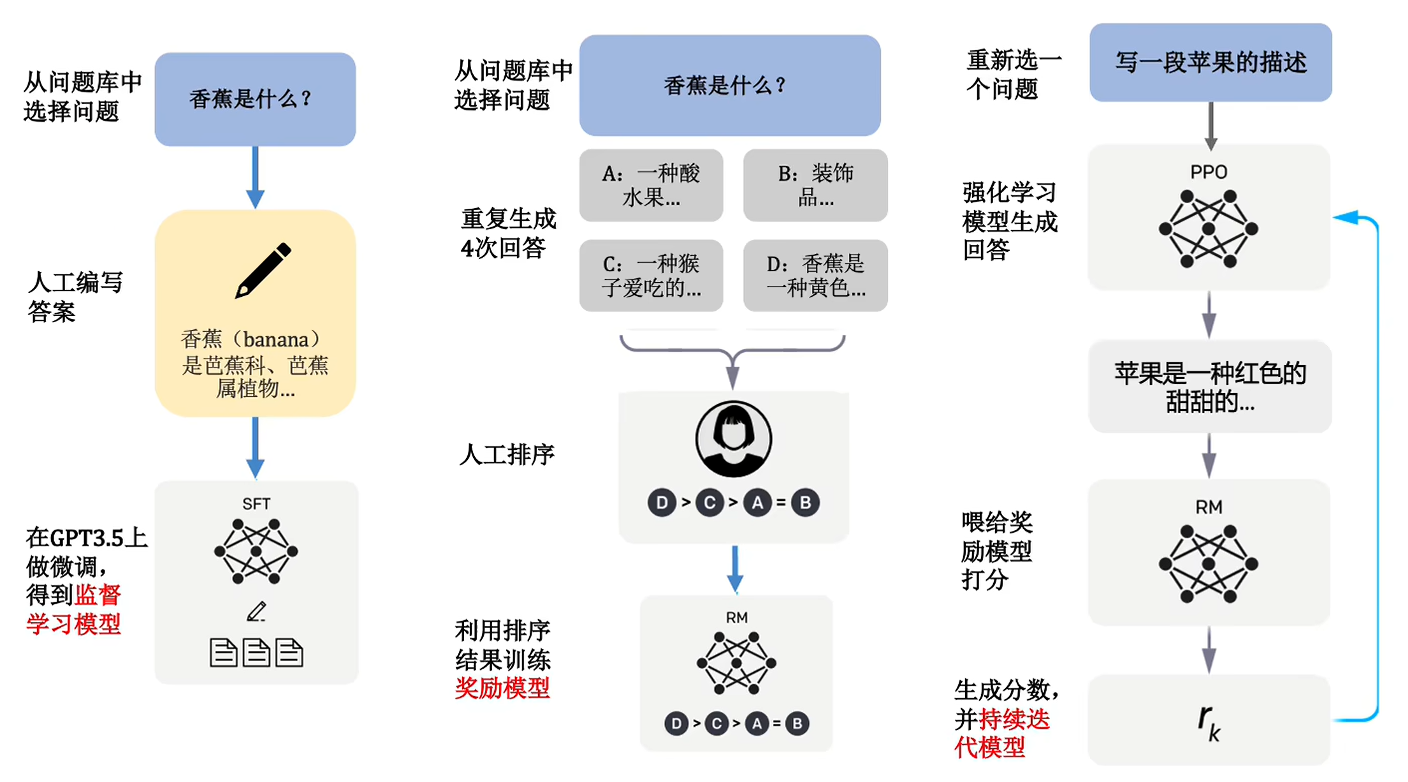
Step1 以监督学习的方式对GPT3进行微调,得到监督学习模型

首先收集人们在对话中更感兴趣的问题,形成一个问题库,然后不断从数据库中提取一个问题(称为prompt),给到现实生活中的人,让它来做出回答。原论文图片里面的例子是给6岁的儿童解释强化学习,让人工回答完后将问题和回答一起放入到GPT-3.5中进行监督学习,来得到一个生成模型。
每次往模型中输入一个文本,它就是按照训练的数据,给我们输出一个文本。
补充:问题库的来源:
GPT3面世后,OpenAI提供了api,可集成到自己的项目中,用户使用的时候直接采用 prompt的方法做0样本或小样本的预测
下面的代码就是调用OpenAI提供的api,使用的同时,OpenAI会收集prompt数据,研究人员从这些问题(prompt)中采样一部分,人工对这些问题(prompt)做回答,得到的结果称为demonstration即有标签数据,再用这些demonstration继续微调GPT3
import openai
openai.api_key="**********************"
response = openai.Completion.create(model="text-davinci-003",prompt=prompt,temperature=0,max_tokens=100,top_p=1,frequency_penalty=0.0,presence_penalty=0.0,
)
message = response.choices[0].text
print(message)
毫无疑问,第一步通过大量监督学习的方式其实是比较困难的,它消耗很多的资源。**很难找到足够多的人来回答问题很多不同领域的问题,并且有些回答不好评价它的好坏。**因此有了接下来的两步。
Step2 训练出一个奖赏模型

奖赏模型的训练方式,针对同一个问题,让第一步得到监督学习模型给出四个答案。让现实中的人对这四个回答进行排序,对这个排序来进行训练奖赏模型。
虽然我造不出冰箱,但我可以评价一个冰箱的好坏。意思是说,我没有办法像监督学习这样的方式,告诉你冰箱是怎么造的,但是我是冰箱实际上的使用者,我是可以评估冰箱是好还是坏的。就像我没有办法向6岁儿童解释深度学习,但是我可以对生成回答判断是好是坏,就能很轻易的对它们进行排序。
很显然,排序的成本是比直接回答的成本更低的。
补充:为什么需要奖赏模型?
我们需要不断对生成的结果进行排序,来得到人们最满意的回答。人能够对生成的结果进行满意度排序,那我们也希望有模型来对结果排序。
Step3 训练得到基于PPO算法的强化学习模型

PPO算法不用管,只用知道这是人工智能领域一个很厉害的强化学习的算法就行了。深入不讨论。
首先我们还是从数据集里面取出一条问题(prompt),然后放入到强化学习模型里面,得到了一条输出文本。我们对输出的文本进行打分,把打分的结果反馈到强化学习模型中。
这个强化学习模型是基于第一步得到的监督模型得到的,打分的话,是用到第二部得到的奖励模型。
总结
InstructGPT比GPT3有哪些方面的改进?
- InstructGPT使用的训练数据,是人们更加经常使用到的,比如:日常的对话,常见的数学、物理知识等等。因此我们使用ChatGPT才能更像对话。****
- 引入了强化学习
ChatGPT这次能破圈引起全球讨论,原因是采用了对话形式,让每个普通人都能感受到人工智能技术的强大
最后说一下我对ChatGPT的理解
-
ChatGPT的出现并不是说OpenAI有多厉害,他们用的技术并不都是原创的技术,甚至很多模型都是行业内开源的,但是他们巧妙地把这些模型融合到了一起。更为关键的是,ChatGPT将模型参数扩大到了1750亿,模型框架没有改变,但是参数有了十倍、百倍的增长,最终量变引发了质变
-
ChatGPT更准确的定位是个人助手
它在办公场景里很好用,比如写大纲、写报告、写文章,还有做题,甚至写代码,就算是编程的初学者也能在其帮助下写出高质量的代码。现在,ChatGPT已经具备了一定的逻辑推理能力,未来,在客服、营销、医疗等诸多场景下,只要是重复性的人脑劳动都有可能被ChatGPT取代
参考:
何小枝:https://www.zhihu.com/people/who-u
周总:https://mp.weixin.qq.com/s/h2IOP3XDJ_RicqiV4l00GQ
相关文章:
ChatGPT是如何训练得到的?通俗讲解
首先声明喔,我是没有任何人工智能基础的小白,不会涉及算法和底层原理。 我依照我自己的简易理解,总结出了ChatGPT是怎么训练得到的,非计算机专业的同学也应该能看懂。看完后训练自己的min-ChatGPT应该没问题 希望大牛如果看到这…...

刷题28-有效的变位词
32-有效的变位词 解题思路: 注意变位词的条件,当两个字符串完全相等或者长度不等时,就不是变位词。 把字符串中的字符映射成整型数组,统计每个字符出现的次数 注意数组怎么初始化: int [] s1new int[26]代码如下&a…...

JavaWeb中异步交互的关键——Ajax
文章目录1,Ajax 概述1.1 作用1.2 同步和异步1.3 案例1.3.1 分析1.3.2 后端实现1.3.3 前端实现2,axios2.1 基本使用2.2 快速入门2.2.1 后端实现2.2.2 前端实现2.3 请求方法别名3,JSON3.1 概述3.2 JSON 基础语法3.2.1 定义格式3.2.2 代码演示3.2.3 发送异步…...
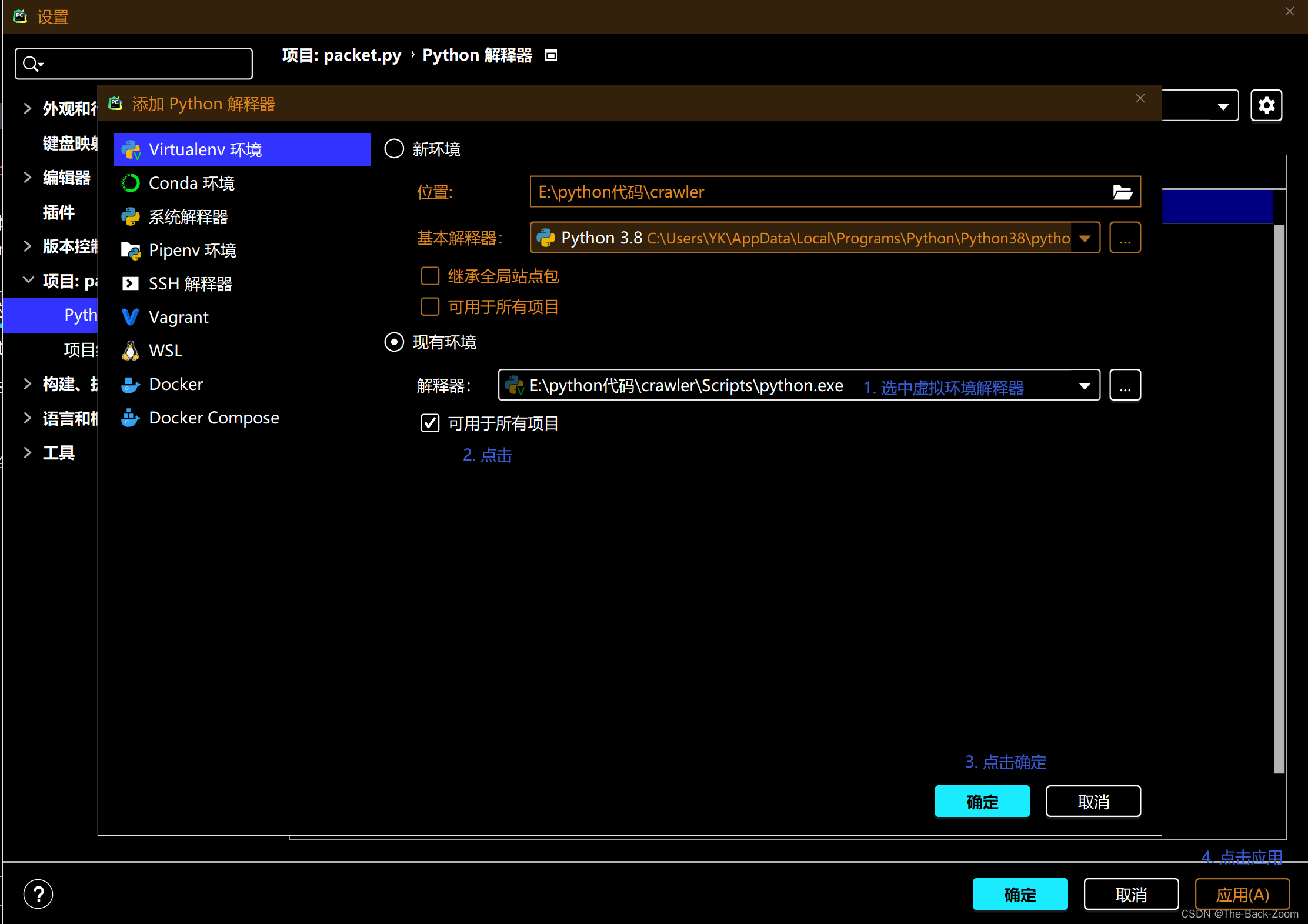
python爬虫常见错误
python爬虫常见错误前言python常见错误1. AttributeError: WebDriver object has no attribute find_element_by_id1. 问题描述2. 解决办法2. selenium:DeprecationWarning: executable_path has been deprecated, please pass in1. 问题描述2. 解决办法3. 下载了包…...

AI_Papers周刊:第三期
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 2023.02.20—2023.02.26 文摘词云 Top Papers Subjects: cs.CL 1.LLaMA: Open and Efficient Foundation Language Models 标题:LLaMA:开放高效的基础语言模型 作者&#…...

在win7上用VS2008编译skysip工程
在win7上用VS2008编译skysip工程 1. 安装vs2008及相应的补丁包,主要包含以下安装包: 1.1 VS2008TeamSuite90DayTrialCHSX1429243.iso 1.2 VS2008SP1CHSX1512981.iso 1.3 VS90sp1-KB945140-CHS.exe 2. 安装Windows SDK: 6.0.6001.18000.367-KRMSDK_EN.zip 例如安装路径为…...

python 数据结构习题
旋转图像给定一个nn的二维矩阵表示一个图像。将图像顺时针旋转90度。你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。例如,给定matrix[[1,2,3],[4,5&#x…...
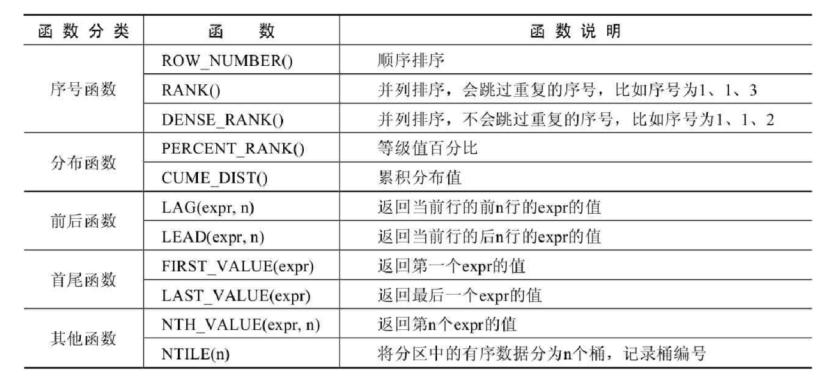
18、MySQL8其它新特性
文章目录1 MySQL8新特性概述1.1 MySQL8.0 新增特性1.2 MySQL8.0移除的旧特性2 新特性1:窗口函数2.1 使用窗口函数前后对比2.2 窗口函数分类2.3 语法结构2.4 分类讲解1 序号函数2 分布函数3 前后函数4 首尾函数5 其他函数2.5 小 结3 新特性2:公用表表达式…...

【Android笔记79】Android之接口请求库Retrofit的介绍及使用
这篇文章,主要介绍Android之接口请求库Retrofit的介绍及使用。 目录 一、Retrofit接口请求库 1.1、什么是Retrofit 1.2、Retrofit的使用 (1)引入依赖...
蓝桥杯 考勤打卡
问题描述 小蓝负责一个公司的考勤系统, 他每天都需要根据员工刷卡的情况来确定 每个员工是否到岗。 当员工刷卡时, 会在后台留下一条记录, 包括刷卡的时间和员工编号, 只 要在一天中员工刷过一次卡, 就认为他到岗了。 现在小蓝导出了一天中所有员工的刷卡记录, 请将所有到岗…...
逻辑回归
逻辑回归 在分类问题中,要预测的变量y为离散值(y0~1),逻辑回归模型的输出变量范围始终在 0 和 1 之间。 训练集为 {(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}\{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})\} {…...
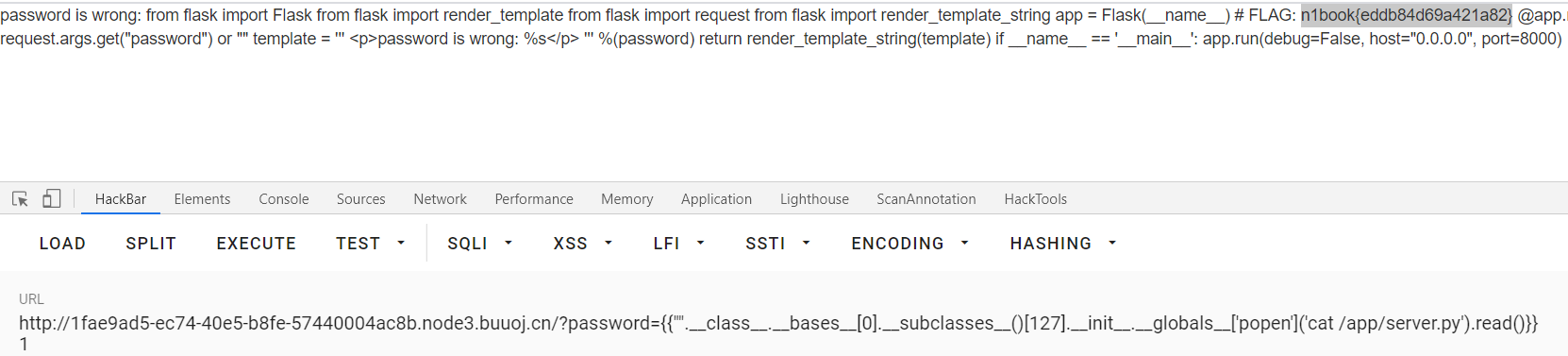
CTFer成长之路之Python中的安全问题
Python中的安全问题CTF 1.Python里的SSRF 题目提示 尝试访问到容器内部的 8000 端口和 url path /api/internal/secret 即可获取 flag 访问url: http://f5704bb3-5869-4ecb-9bdc-58b022589224.node3.buuoj.cn/ 回显如下: 通过提示构造payload&…...
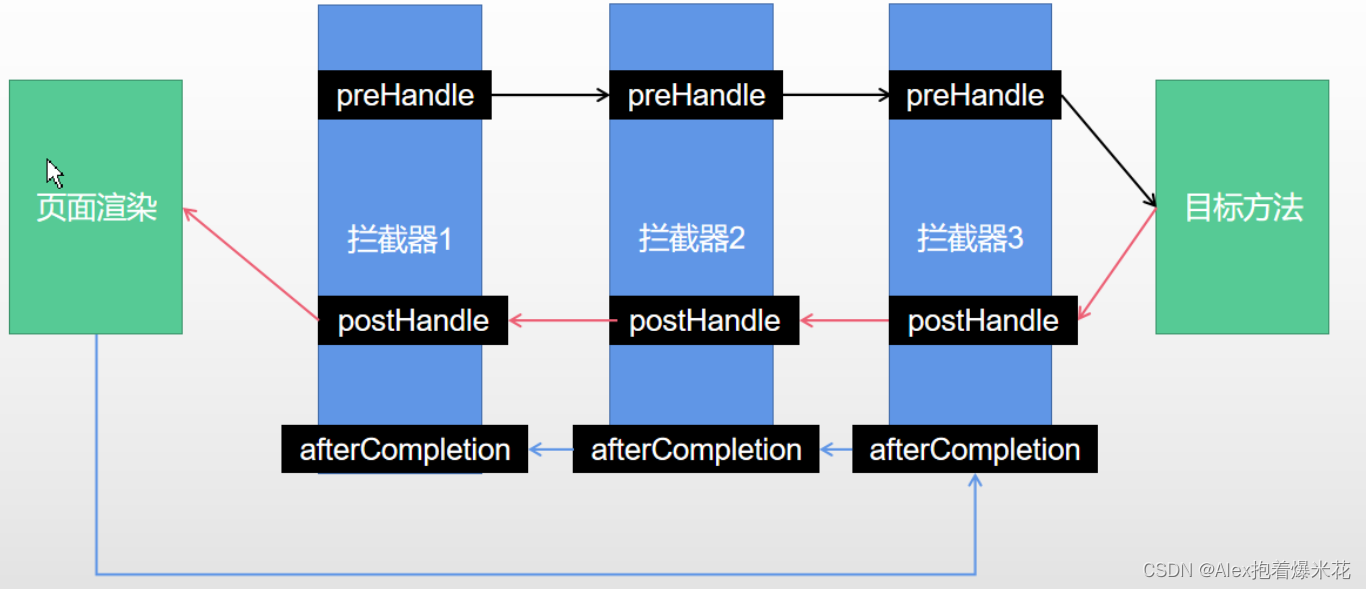
SpringBoot知识快速复习
Spring知识快速复习启动器自动装配ConfigurationImport导入组件Conditional条件装配ImportResource导入Spring配置文件ConfigurationProperties配置绑定Lombok简化开发dev-toolsyaml请求和响应处理静态资源规则与定制化请求处理-Rest映射请求处理-常用参数注解使用请求处理-Ser…...
SpringBoot+React博客论坛系统 附带详细运行指导视频
文章目录一、项目演示二、项目介绍三、项目运行截图四、主要代码一、项目演示 项目演示地址: 视频地址 二、项目介绍 项目描述:这是一个基于SpringBootReact框架开发的博客论坛系统。首先,这是一个前后端分离的项目,文章编辑器…...

C++ primer 之 extern
C primer 之 extern什么是声明什么是定义两者有什么区别ertern的作用什么是声明 就是使得名字为程序所知,一个文件如果想使用别处定义的名字就必须包含对那个名字的声明。 什么是定义 负责创建与名字关联的实体。 两者有什么区别 变量声明和声明都规定了变量的…...
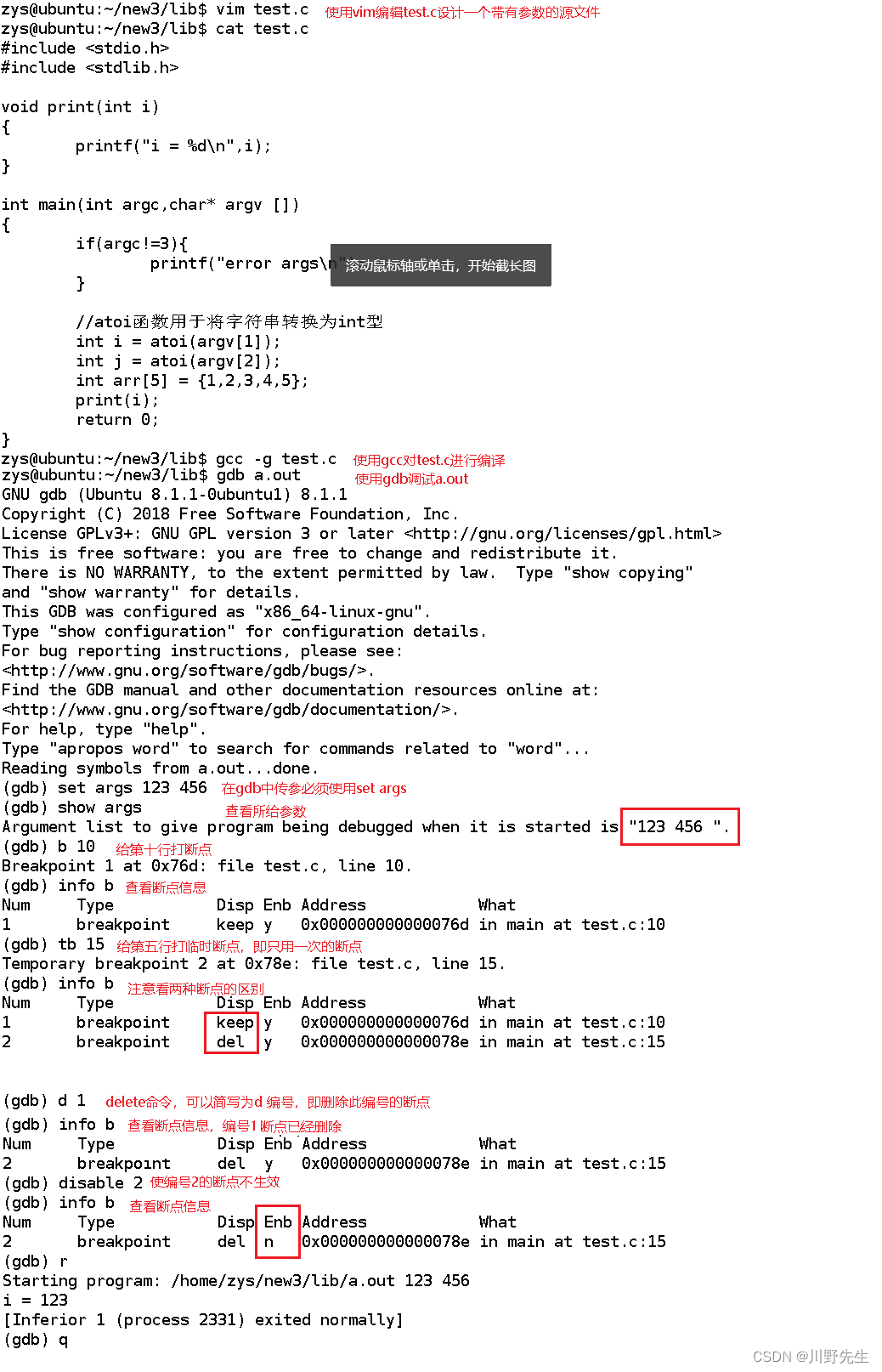
Linux 练习二 (VIM编辑器 + GCC编译器 + GDB调试)
文章目录VIM命令思维导图GCC编译器1、GCC编译文件练习2、静态库动态库制作练习将此函数编译成动态库将此函数编译成静态库GCC优化选项 -OnGDB调试命令练习练习一:编写一个程序,通过gdb调试,使用到gdb的b,n,s࿰…...

python3 连接数据库 mysql PyMysql
python3PyMysql PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库 , 遵循 Python 数据库 API v2.0 规范 。 PyMySQL 安装 pip install PyMySQLPyMySQL 连接数据库 import pymysql pymysql.Connect(hostlocalhost,port 3306,user root,password **…...
昇腾AI新技能,还能预防猪生病?
国药集团动物保健股份有限公司(简称“国药动保”)是专业从事动物保健产品研发、生产和销售的国家高新技术企业,是国内少数几家具备新产品原创能力的动物保健企业。其中,猪圆环病毒灭活疫苗等市场份额位居行业前列。 “猪圆环病毒…...
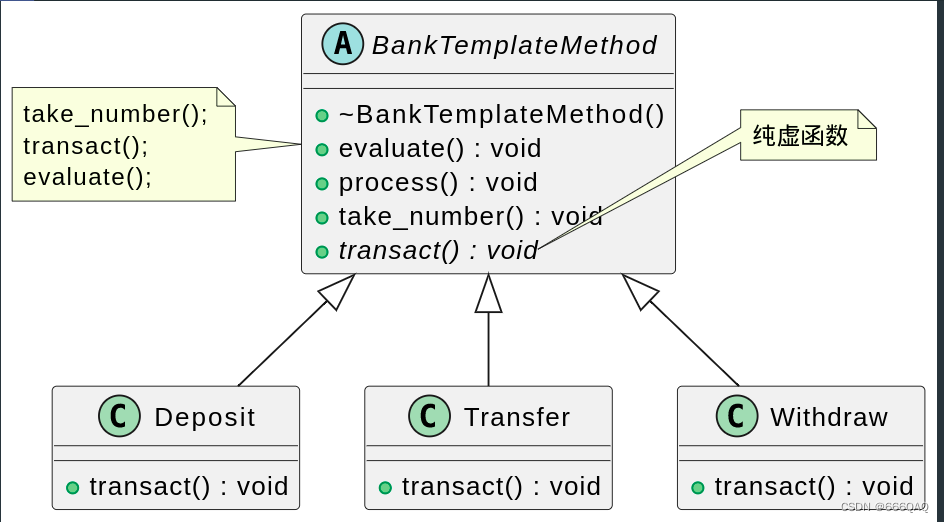
模板方法模式(Template Method)
模式结构图 说明 基本方法是模板方法的组成部分。基本方法分为一下三种: 抽象方法 由抽象类声明,由其具体子类实现。C中就是纯虚函数。 具体方法 由抽象类或具体类声明并实现,子类可以进行覆盖也可以继承。C中是虚函数。 钩子方法 由抽象类…...

C C++ typedef的使用
一、为基本数据类型起别名 typedef int myint; myint x 5; "myint"是"int"的别名,可以使用"myint"来代替"int"声明变量,这个很好理解,但是也很少有人这么用吧。 二、为结构体起别名 …...

imFile下载管理器:从入门到精通的免费全能下载解决方案
imFile下载管理器:从入门到精通的免费全能下载解决方案 【免费下载链接】imfile-desktop A full-featured download manager. 项目地址: https://gitcode.com/gh_mirrors/im/imfile-desktop imFile是一款功能全面的免费下载管理器,支持HTTP、FTP、…...

掌握高效窗口管理:专业级分辨率调整工具完全指南
掌握高效窗口管理:专业级分辨率调整工具完全指南 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 在当今多任务处理和多屏工作环境中,你是否经常遇到窗口大小不合适、分辨率限制或游戏画面…...

暗黑2存档编辑器:免费开源工具助你轻松修改角色与装备
暗黑2存档编辑器:免费开源工具助你轻松修改角色与装备 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 暗黑2存档编辑器是一款专门为《暗黑破坏神2》玩家设计的免费开源工具,让你能够轻松修改游戏存档&…...

xhs签名验证机制详解:如何绕过小红书反爬虫系统的终极指南
xhs签名验证机制详解:如何绕过小红书反爬虫系统的终极指南 【免费下载链接】xhs 基于小红书 Web 端进行的请求封装。https://reajason.github.io/xhs/ 项目地址: https://gitcode.com/gh_mirrors/xh/xhs 在小红书数据爬取领域,xhs签名验证机制是开…...

C#项目实战:用StackExchange.Redis+RedisDesktopManager构建一个简易用户会话缓存系统
C#实战:基于StackExchange.Redis构建高可用会话缓存系统 在分布式系统架构中,会话管理始终是开发者需要解决的核心问题之一。传统ASP.NET的InProc会话模式在Web Farm环境下会面临一致性挑战,而SQL Server会话状态又难以满足高并发场景的性能…...

毕业季救星:Word 2016域代码终极指南,让你的参考文献列表和文内引用完美同步
学术写作效率革命:用Word域代码构建智能参考文献系统 每到毕业季,总有一群人在深夜里对着电脑屏幕抓狂——他们的论文参考文献编号像多米诺骨牌一样,因为中间插入了一个新引用而全部错乱。手动调整几十处引用编号不仅耗时,还容易出…...
)
别再死记硬背了!用这三个二极管等效模型,轻松搞定电路分析(附典型例题)
二极管电路分析的三大黄金法则:从理论到实战的思维跃迁 在电子工程领域,二极管就像电路世界里的"单向阀门",看似简单却暗藏玄机。许多初学者面对复杂二极管电路时,往往陷入盲目试错的困境——要么死记硬背公式ÿ…...

性价比高可代理的油烟分离油烟机的厂家
最近跟10多个开厨电店的老板喝茶,一半人唉声叹气:去年赚的钱全压库存里了,3个做了十几年的老老板说,再找不到好产品,今年打算把店转了。为啥好好的店做成这样?说白了就是选品选错了,风口变了&am…...

从Claude Code到nanocode:轻量级AI编程助手核心架构与工程实践
1. 项目概述:从Claude Code到nanocode的轻量化之路 如果你是一名开发者,尤其是对AI编程助手(AI Agent)的内部工作原理充满好奇,那么你很可能听说过Anthropic的Claude Code。它是一个功能强大的命令行AI代理࿰…...

如何快速实现NCM文件批量转换:ncmdumpGUI完整使用指南
如何快速实现NCM文件批量转换:ncmdumpGUI完整使用指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否下载了网易云音乐却发现文件是NCM格式…...