不一样的编程方式 —— 协程(设计原理与汇编实现)
主要通过以下9个方面来了解协程的原理:
目录
1、为什么使用协程
1.3、协程的适用场景
2、协程的原语操作
3、协程的切换
3.1、汇编实现
4.协程的运行流程
5.协程的结构体定义(我们其实可以参照线程或者进程的状态来设计)
5.1、多状态集合设计
6.协程的调度策略
7.协程调度器如何定义
8、多核模式
9、性能测试
为什么要有协程?协程解决了什么问题?
关于协程,我们经常看到这样的话:同步的编程方式,异步的性能。那么什么是同步,什么是异步呢?
同步与异步
同步和异步,是形容两者之间的关系。两者在一个流程内,就是同步;两者不在一个流程内,就是异步。
我们这里说的同步和异步,是指io同步操作和io异步操作。
还有一个容易与io异步操作混淆的概念,异步io,就是指有io数据的时候,直接callback,AIO, 比如boost的asio;
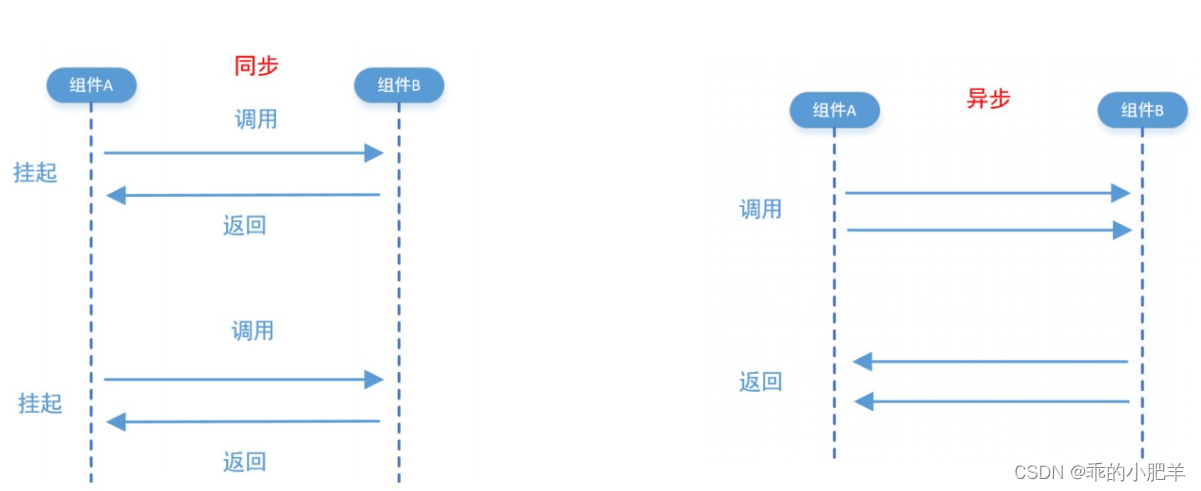
主要差别是在IO事件是否就绪的两种处理方式的区别
方法一:io 同步操作
- 发起请求:等待响应
- 接受响应
对 io 的操作和 epoll_wait 放在同一流程里,需要等待 io 的响应。
优点:sockfd 管理方便,操作逻辑清晰缺点:依赖 io 响应速度,性能差
int handle(int sockfd) {recv(sockfd, rbuffer, length, 0);parser_proto(rbuffer, length);send(sockfd, sbuffer, length, 0);
}
方法二:io 异步操作
handle 函数内部将 sockfd 的操作,push 到线程池中,在 io 数据拷贝阶段可以做其他事。
int thread_cb(int sockfd) {// 此函数是在线程池创建的线程中运行,与 handle 不在一个线程上下文中运行recv(sockfd, rbuffer, length, 0);parser_proto(rbuffer, length);send(sockfd, sbuffer, length, 0);
}
int handle(int sockfd) {//此函数在主线程 main_thread 中运行,在此处之前,确保线程池已经启动。push_thread(sockfd, thread_cb); //将 sockfd 放到其他线程中运行。
}
1、为什么使用协程
从性能方面来看,对于使用异步 io 的线程,存在三个问题:
系统线程占用大量的内存空间
线程切换占用大量的系统时间
为了线程安全,线程间需要加锁保护资源,降低执行的效率
从编程角度来看,无论同步还是异步编程方式,都是基于事件驱动的。事件驱动流程包括注册事件,绑定回调,触发回调,提高了系统的并发。但是由于回调的多层嵌套,使得编程复杂,降低了代码的可维护性。
在资源有限的前提下,高性能服务需要解决的问题有:
减少线程的重复高频创建:线程池
尽量避免线程的阻塞
Reactor + 非阻塞回调:解决问题的能力有限
响应式编程:容易陷入回调地狱,割裂业务逻辑
协程:将同 io 转成异步 io
提升代码的可维护与可理解性:减少回调函数,减少回调链深度
而协程的出现,可以很好地解决上述问题。
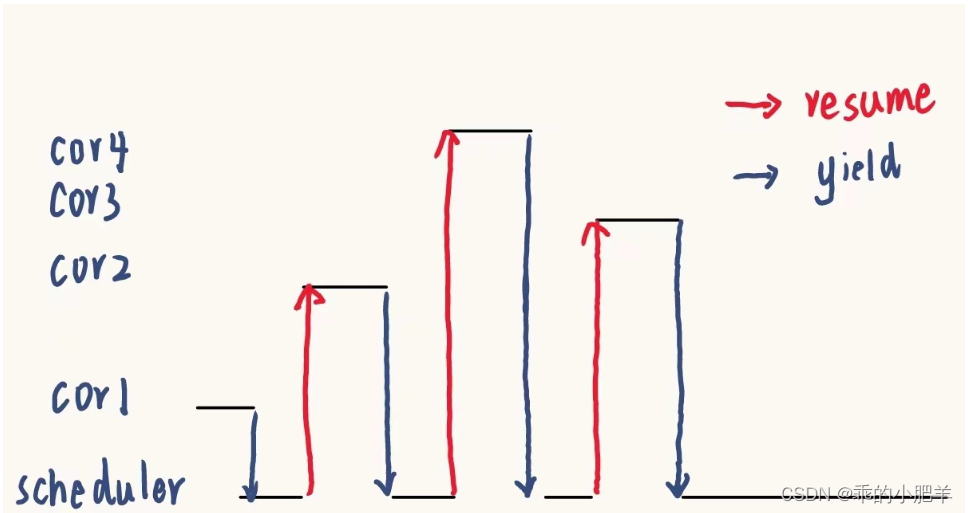
协程运行在线程之上。当一个协程调用阻塞 io,主动让出 cpu ( yield 原语) ,让另一个协程运行在当前线程之上( resume 原语)。协程没有增加线程数量,只是在线程的基础上通过分时复用的方式运行多个协程,降低了系统内存。而且协程的切换在用户态完成,减少了系统切换开销。
综上所述,协程的优势体现在:
消耗系统资源和切换代价更小
协程可以实现无锁编程
简化了异步编程,可以达到以同步的编程方式实现异步的性能。
1.3、协程的适用场景
协程适用于 I/O 密集型业务,线程切换频繁。其他情况,性能不会有太大的提升。
2、协程的原语操作
yield: 协程主动让出CPU给调度器。时机:业务提交 -> epoll_wait
resume: 调度器恢复协程的运行权。时机:epoll_wait -> 业务处理
resume 和 yield 是两个可逆的原子操作。
io 异步操作函数执行流程如下:
将 sockfd 添加到 epoll 管理
由协程上下文 yield 到调度器的上下文
调度器获取下一个协程上下文,resume 新的协程

1.commit完后,switch --> epoll_wait 是 yield (让出(将当前协程从寄存器里让出)操作到wait下等待io就绪,如果IO就绪那么使用resume操作,在将当前协程让出后,把新的协程交换到cpu上运行(寄存器上))
2.epoll_wait --> io处理流程 是 resume (恢复操作)
yield 与 resume 是一个switch操作(三种实现方式):
1.longjump/setjump
2.ucontext
3.汇编实现
3、协程的切换
协程的上下文如何进行切换?现有的 C++ 协程库均基于两种方案
汇编实现:libco,Boost.context
OS 提供的 API :
phxrpc:基于 ucontext / Boost.context 的上下文切换
libmill:基于 setjump/longjump 的协程切换
一般来说,基于汇编的上下文切换要比采用系统调用的切换更加高效
3.1、汇编实现
x86-64有16个64位寄存器,分别是:%rax,%rbx,%rcx,%rdx,%rdi,%rsi,%rbp,%rsp,%r8,%r9,%r10,%r11,%r12,%r13,%r14,%r15。
%rax: Return value, 作为函数返回值使用。
%rsp: Stack pointer,栈指针,栈顶指针,指向栈顶
%rbp: Base pointer,基址指针,栈桢(栈底)指针 Frame pointer,指向栈的底部
%rdi,%rsi,%rdx,%rcx,%r8,%r9: 用作函数参数,依次对应第1, …, 6参数
%rbx,%r12,%r13,%r14,%r15: Caller saved,被调用者保护寄存器(易失性寄存器),程序调用过程中寄存器的值不需要保存。如果要保存,则调用者负责压栈。
%r10,%r11: Callee-owned,调用者保护寄存器(非易失性寄存器)。程序调用过程中,需要保存,不能覆盖。被调用寄存器先保存值然后再调用,调用结束后恢复调用前的值。
%rip: Instruction pointer, 相当于PC指针指向当前的指令地址,指向下一条要执行的指令
协程上下文切换,就是先将 cpu 寄存器的值暂时保存到 cur_ctx,再将即将运行的协程的上下文 new_ctx 的值 mov 到相对应的 cpu 寄存器上,完成切换。
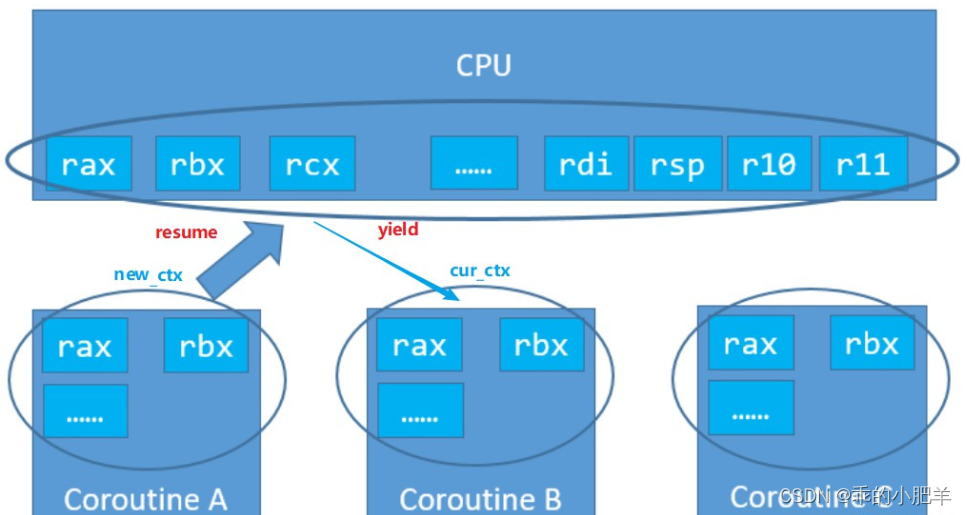
切换函数 _switch 的定义
/*** @brief switch实现协程切换,保存cpu寄存器的值到cur_ctx,加载new_ctx上下文到cpu寄存器* @param new_ctx: 对应寄存器rdi,即将运行协程的上下文,加载它的上下文到cpu寄存器* @param cur_ctx: 对应寄存器rsi,正在运行协程的上下文,保存cpu寄存器到它的上下文 * @return int */
int _switch(nty_cpu_ctx *new_ctx, nty_cpu_ctx *cur_ctx);
//
__asm__ (
" .text \n"
" .p2align 4,,15 \n"
".globl _switch \n"
".globl __switch \n"
"_switch: \n"
"__switch: \n"
" movq %rsp, 0(%rsi) # save stack_pointer \n"
" movq %rbp, 8(%rsi) # save frame_pointer \n"
" movq (%rsp), %rax # save insn_pointer \n"
" movq %rax, 16(%rsi) \n"
" movq %rbx, 24(%rsi) # save rbx,r12-r15 \n"
" movq %r12, 32(%rsi) \n"
" movq %r13, 40(%rsi) \n"
" movq %r14, 48(%rsi) \n"
" movq %r15, 56(%rsi) \n"
" movq 56(%rdi), %r15 \n"
" movq 48(%rdi), %r14 \n"
" movq 40(%rdi), %r13 # restore rbx,r12-r15 \n"
" movq 32(%rdi), %r12 \n"
" movq 24(%rdi), %rbx \n"
" movq 8(%rdi), %rbp # restore frame_pointer \n"
" movq 0(%rdi), %rsp # restore stack_pointer \n"
" movq 16(%rdi), %rax # restore insn_pointer \n"
" movq %rax, (%rsp) \n"
" ret \n"
);
nty_cpu_ctx 结构体,存储寄存器的值
// x86 寄存器列表,每个寄存器8字节
typedef struct _nty_cpu_ctx {void *esp; void *ebp;void *eip;void *edi;void *esi;void *ebx;void *r1;void *r2;void *r3;void *r4;void *r5;
} nty_cpu_ctx;
4.协程的运行流程

协程中遇到io操作,就加入到epoll里面,yield,将CPU让出,回到调度器,调度器进行调度,决定哪个协程运行。
一个fd对应一个协程的设计方法,是不是最优的?能不能设计成多分fd对应一个协程?
对于网络框架,一个fd对应一个协程是一个很好的方案;
如果是对界面刷新或者磁盘文件操作,就不是很合适。
比如A协程 recv,如果该fd io已经准备就绪了,这时候yield,调度器会调度其他协程运行,可能调度几百几千个其他协程,最后再回到A协程进行recv,它的实时性有没有意义?
对于大量io,所有io一起看的话,单个io的实时性是没有意义的。
5.协程的结构体定义(我们其实可以参照线程或者进程的状态来设计)
//这里我们就采用比较简单的方式来实现
协程数据结构设计分为两部分
- 运行体 R:包含运行状态(就绪,睡眠,等待),运行体回调函数,回调参数,栈指针,栈大小,当前运行体
- 调度器 S:包含执行集合(就绪,睡眠,等待)
5.1、多状态集合设计
新创建的协程,创建完成后,加入到就绪集合,等待调度器的调度;协程在运行完成后,进行 IO 操作,此时 IO 并未准备好,进入等待状态集合;IO 准备就绪,协程开始运行,后续进行 sleep 操作,此时进入到睡眠状态集合。
那么,运行体如何在多状态集合高效切换?三种集合如何设置合理的数据结构?
就绪 (ready) 集合:不设置优先级,所有协程优先级一致,使用队列存储就绪的协程,简称就绪队列 (ready_queue)
睡眠 (sleep) 集合:需要对睡眠时长排序,采用红黑树来存储,简称睡眠树 (sleep_tree)。key 为睡眠时长,value 为对应的协程结点。
等待 (wait) 集合:需要对 IO 等待时间排序,采用红黑树来存储,简称等待树 (wait_tree)。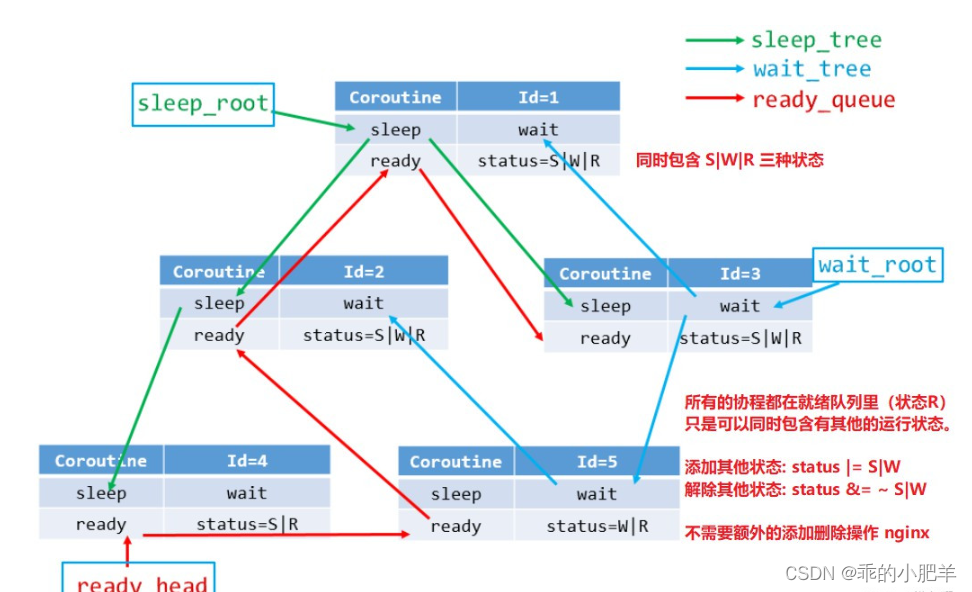
struct coroutine {nty_cpu_ctx ctx; //上下文环境,保存CPU寄存器proc_coroutine func; // 子过程的回调函数void *arg; // 子过程回调函数的参数void *ret; // 子过程回调函数的返回值nty_coroutine_status status; // 运行状态:ready, wait, sleepnty_schedule *sched; // 调度器uint64_t birth; // 创建时间uint64_t id; // 协程 idvoid *stack; // 栈空间size_t stack_size; // 栈空间大小RB_ENTRY(_nty_coroutine) sleep_node; // 睡眠 sleep 树RB_ENTRY(_nty_coroutine) wait_node; // 等待 wait 树TAILQ_ENTRY(_nty_coroutine) ready_next; // 就绪 ready 队列
};
我们每个协程有自己独立的栈空间比较好,共享栈的话在编程和处理方面比较麻烦
6.协程的调度策略
协程如何被调度,有两种方案,生产者消费者模式和多状态运行。

while (1) {//遍历睡眠集合,将满足条件的加入到 readynty_coroutine *expired = NULL;while ((expired = sleep_tree_expired(sched)) != NULL) {TAILQ_ADD(&sched->ready, expired);}//遍历等待集合,将满足添加的加入到 readynty_coroutine *wait = NULL;int nready = epoll_wait(sched->epfd, events, EVENT_MAX, 1);for (i = 0;i < nready;i ++) {wait = wait_tree_search(events[i].data.fd);TAILQ_ADD(&sched->ready, wait);}// 使用 resume 恢复 ready 的协程运行权while (!TAILQ_EMPTY(&sched->ready)) {nty_coroutine *ready = TAILQ_POP(sched->ready);resume(ready);}
}
多状态运行
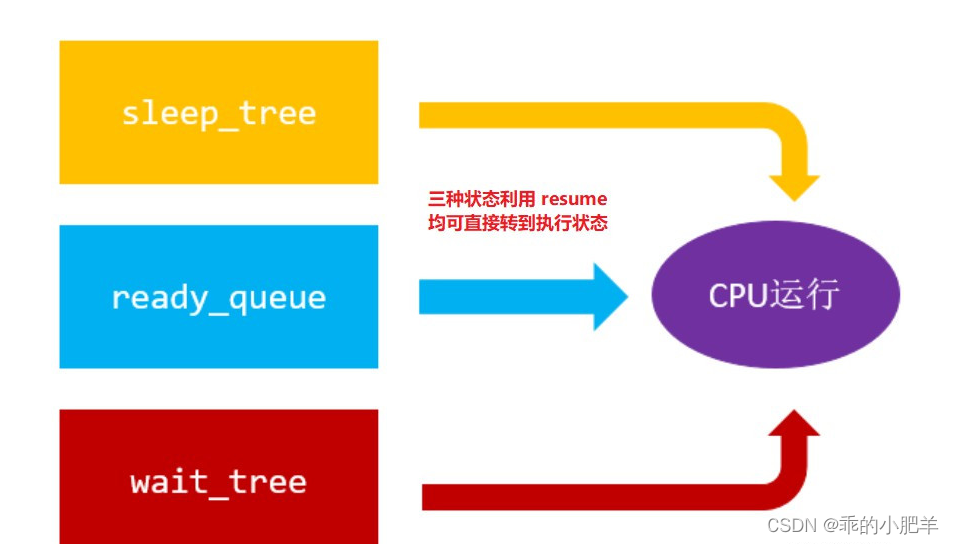
while (1) {//遍历睡眠集合,使用 resume 恢复 expired 的协程运行权nty_coroutine *expired = NULL;while ((expired = sleep_tree_expired(sched)) != NULL) {resume(expired);}//遍历等待集合,使用 resume 恢复 wait 的协程运行权nty_coroutine *wait = NULL;int nready = epoll_wait(sched->epfd, events, EVENT_MAX, 1);for (i = 0;i < nready;i ++) {wait = wait_tree_search(events[i].data.fd);resume(wait);}// 使用 resume 恢复 ready 的协程运行权while (!TAILQ_EMPTY(sched->ready)) {nty_coroutine *ready = TAILQ_POP(sched->ready);resume(ready);}
}
其实我认为是第一种比较好,因为参照线程和进程的状态来实现会更加贴合操作系统运行
7.协程调度器如何定义
每一协程都需要使用的而且可能会不同属性的,就是协程属性(私有)。每一协程都需要的而且数据一致的,就是调度器的属性(公共)。调度器是管理所有协程运行的组件。
// 调度策略
struct scheduler_op {remove_wait();remove_sleep();
};// 调度器,用来管理所有的协程
struct scheduler {int epfd; struct epoll_event events[]; struct coroutine *cur; // 当前运行的协程queue_tail(, struct coroutine) ready; // 指向就绪队列rbtree_root(, struct coroutine) wait; // 指向等待树rbtree_root(, struct coroutine) sleep; // 指向睡眠树struct scheduler_op *sch_op; //调度策略
};
这么定义好了之后,调度器就可以遍历各个状态的数据结构,然后加一个定时器,将要超时的
协程调度上来,设置当前运行协程是因为调度器需要运行一个协程,如果来新的协程,再把老的协程执行让出操作,新的协程resume操作,交给调度器进行调度
调度器与协程(每个协程对应一个客户端)的运行关系
if (io 是否可写) {connect();
}
else {epoll_ctl(epfd, fd);yield();
}
8、多核模式
一个线程一个调度器,简单,不需要加锁
一个进程一个调度器,简单,不需要加锁
多个线程共用一个调度器,复杂,入队需要加锁
9、性能测试
测试标准
并发量:fd数量、协程的数量,fd数量 == 协程数量
为什么这么说呢,是因为我们当一个客户端连接的是否,事件就绪,如果是读事件中的监听套接字,那么还需要创建一个新的协程将新的fd加入到epoll中,所以每个客户端连接过来,我们都需要创建一个协程来管理当前客户端的fd
所以说fd数量 == 协程数量
每秒接入量:fd -> coroutine_create
断开连接:coroutine_destory
相关文章:
不一样的编程方式 —— 协程(设计原理与汇编实现)
主要通过以下9个方面来了解协程的原理: 目录 1、为什么使用协程 1.3、协程的适用场景 2、协程的原语操作 3、协程的切换 3.1、汇编实现 4.协程的运行流程 5.协程的结构体定义(我们其实可以参照线程或者进程的状态来设计) 5.1、多状态集合设计 6.协程的调度…...

Thinkphp6项目在虚拟机无法指向pulic的目录访问的方法
以阿里云虚拟主机为例,服务器环境为 LAMP,Apache2.4 php7.2 mysql5.7 1.根目录新建 index.php 文件,将以下内容放入文件中 <?php include ./public/index.php;2.将 public 目录下的 admin.php、backend 文件夹、static 文件夹、tinymc…...

数据结构(超详细讲解!!)第十八节 串(堆串)
1.定义 假设以一维数组heap [MAXSIZE] 表示可供字符串进行动态分配的存储空间,并设 int start 指向heap 中未分配区域的开始地址(初始化时start 0) 。在程序执行过程中,当生成一个新串时,就从start指示的位置起&#…...
idea集成测试插件替代postman
idea集成测试插件替代postman 兄弟萌,你再测试接口是否无bug是否流畅的时候是否还在使用“postman”来回切换进行测试呢? 页面切换进行测试,有没有感觉很麻烦呢? 打开postman,输入接口地址,有没有感觉很麻烦…...

clusterprolifer go kegg msigdbr 富集分析应该使用哪个数据集,GO?KEGG?Hallmark?
关注微信:生信小博士 5 Overview of enrichment analysis Chapter 5 Overview of enrichment analysis | Biomedical Knowledge Mining using GOSemSim and clusterProfiler 5.1.2 Gene Ontology (GO) Gene Ontology defines concepts/classes used to describ…...

Linux学习笔记1-入门
前言:之前的基于单片机的闭环控制步进电机项目其实已经完成了,但很多时间都花在调试和生产上,实在没时间去做总结笔记,现在又开始做新项目了,从单片机到了Linux,想用这个平台来督促自己继续学习,…...

怎样更有效的运营Etsy店铺?
大家都知道,Etsy作为一个重要的电商平台,给很多人提供了不少机会。但是如何取得etsy店铺运营的成功呢?第一步就是选好辅助工具。 什么是指纹浏览器? VMLogin指纹浏览器(www.vmlogin.com.cn) 是一种工具,通过伪装用户…...

Vue 项目中如何使用Bootstrap5(简单易懂)
Vue 项目中如何使用Bootstrap5(简单易懂) 安装在 src/main.js 文件下引入包在vue文件中使用 Bootstrap官网(中文):https://www.bootcss.com/ Bootstrap5文档:https://v5.bootcss.com/docs/getting-started/…...

k8s 资源预留
KUBERNETES资源管理之–资源预留 Kubernetes 的节点可以按照 Capacity 调度。node节点本身除了运行不少驱动 OS 和 Kubernetes 的系统守护进程,默认情况下 pod 能够使用节点全部可用容量, 除非为这些系统守护进程留出资源,否则它们将与 pod 争…...
微信小程序自定义弹窗阻止滑动冒泡catchtouchmove之后弹窗内部内容无法滑动
自定义弹窗 如图所示: 自定义弹窗内部有带滚动条的盒子区域 问题: 在盒子上滑动,页面如果超出一屏的话,也会跟着一起上下滚动 解决方案:给自定义弹窗 添加 catchtouchmove 事件,阻止冒泡即可 网上不少…...

Linux 命令速查
Network ping ping -c 3 -i 0.01 127.0.0.1 # -c 指定次数 # -i 指定时间间隔 日志 一般存放位置: /var/log,包含:系统连接日志 进程统计 错误日志 常见日志文件说明 日志功能access-logweb服务访问日志acct/pacct用户命令btmp记录失…...

第22期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练 Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以…...

JavaScript前端 console 控制台详细解析与代码实例
JavaScript Console(控制台)是一个重要的工具,可以用于调试和测试 JavaScript 代码。在浏览器中,你可以使用控制台来查看 JavaScript 输出、测试代码、调试错误等。在本文中,我们将详细介绍控制台的常用功能和代码实例…...
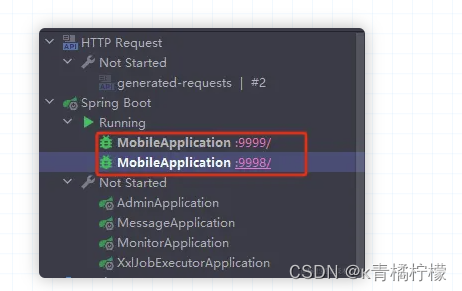
idea中启动多例项目配置
多实例启动 日常本地开发微服务项目时,博主想要验证一下网关的负载均衡以及感知服务上下线能力时,需要用到多实例启动。 那么什么是多实例启动嘞?简单说就是能在本地同时启动多个同一服务。打个比方项目中有一个 MobileApplication 服务&…...

Activiti7流程结束监听事件中,抛出的异常无法被spring全局异常捕捉
ProcessRuntimeEventListener activiti7中,提供了ProcessRuntimeEventListener监听器,用于监听流程实例的结束事件 /*** 流程完成监听器*/ Slf4j Component public class ProcessCompleteListener implements ProcessRuntimeEventListener<ProcessC…...

Android 默认关闭自动旋转屏幕功能
Android 默认关闭自动旋转屏幕功能 接到客户邮件想要默认关闭设备的自动旋转屏幕功能,具体修改参照如下: /vendor/mediatek/proprietary/packages/apps/SettingsProvider/res/values/defaults.xml - <bool name"def_accelerometer_rotati…...
软文推广方案,媒介盒子分享
作为企业宣传的手段,它能用较低的成本获得较好的宣传效果,但有许多企业在进行软文推广时并不起效,这是因为没掌握好方法。今天媒介盒子就来告诉大家,通用的软文推广方案。 一、 明确推广目标以及受众 明确软文推广的目标有助于明…...

CSDN热榜分析6:将实时爬取的热榜数据导入sqlite
文章目录 初始化数据库接口更改数据库写入 初始化数据库 引入数据库的目的不止是为了存储,更多地也是为了便于查询,否则也没必要用一个Text控件来展示信息了。 所以一个正常的工作逻辑是,一打开热榜分析系统,也就同步打开数据库…...
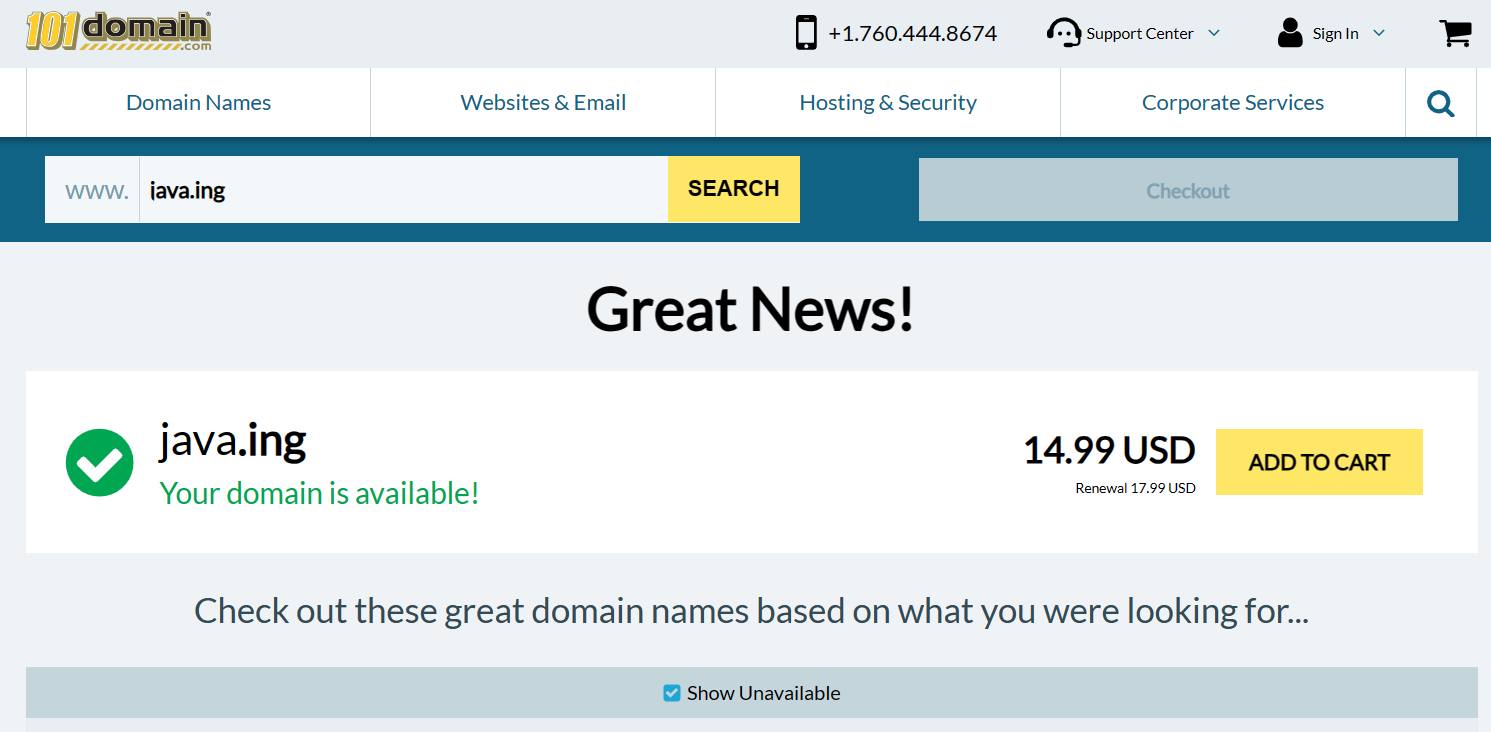
2023年11月1日,Google全新域名来袭:.ing域名现已问世!
2023年11月1日(Oct31,2023美国与中国时差)Google宣布,正式推出.ing域名,这是一种新的顶级域名,旨在为用户提供更多的选择和创意。.ing域名是由Google和国际互联网名称与数字地址分配机构(ICANN)合作开发的,…...
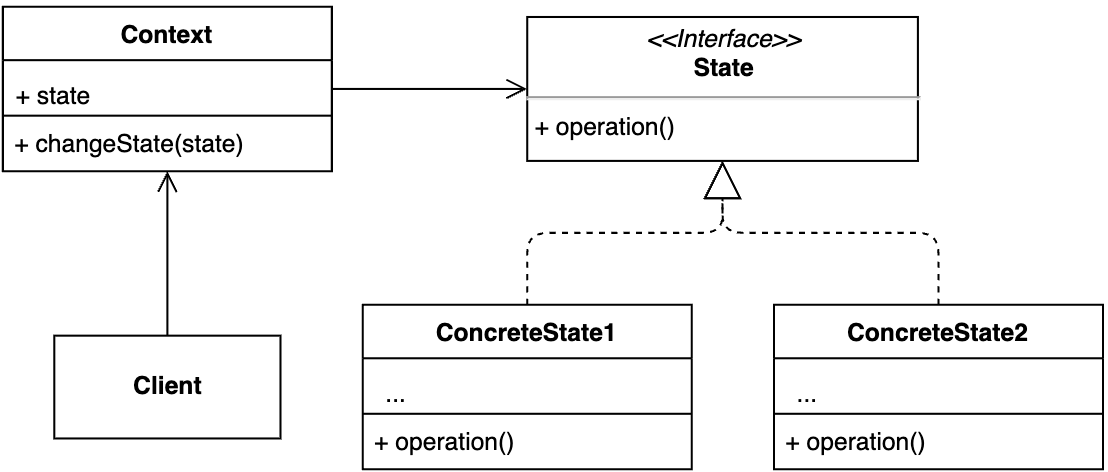
【设计模式】第22节:行为型模式之“状态模式”
一、简介 状态模式一般用来实现状态机,而状态机常用在游戏、工作流引擎等系统开发中。不过,状态机的实现方式有多种,除了状态模式,比较常用的还有分支逻辑法和查表法。该模式允许对象内部状态改变使改变它的行为。 二、适用场景…...

MySQL 子查询优化:从慢查询到飞起的实战之路
开场白 说起 MySQL 子查询优化,这事儿我还真踩过大坑。有一次上线一个报表功能,SQL 里套了两层子查询,测试环境跑得挺快,上了生产直接把数据库干到 CPU 100%,整个系统卡了十分钟。后来 DBA 找过来,一看执行…...

Win10下ENSP USG6000镜像加载卡在###?别慌,VirtualBox网卡桥接这个设置是关键
Win10下ENSP USG6000镜像加载卡在###的终极解决方案 当你满怀期待地在Windows 10上启动ENSP模拟器,拖入USG6000防火墙设备,却只看到一串无情的 ### 符号时,那种挫败感我深有体会。作为一名曾经被这个问题折磨数小时的网络工程师,…...

不只是open-vm-tools:让ArchLinux与VMware无缝协作的完整服务清单
不只是open-vm-tools:让ArchLinux与VMware无缝协作的完整服务清单在虚拟化环境中,ArchLinux以其极简和高度可定制的特性吸引着技术爱好者。然而,与VMware的深度集成往往被简化为"安装open-vm-tools"的单一操作,忽略了完…...
)
从零搭建流媒体服务器:用ZLMediaKit + FFmpeg在CentOS上实现直播推拉流(完整配置与测试)
从零搭建流媒体服务器:用ZLMediaKit FFmpeg在CentOS上实现直播推拉流(完整配置与测试) 流媒体技术正在重塑现代内容分发的格局。想象一下,你正在开发一个在线教育平台,需要实时传输讲师的高清视频;或者运营…...

云服务器Nginx静态网站首屏慢的四层根因与优化方案
1. 为什么明明用了Nginx,静态网站首屏加载却要3秒以上?你有没有遇到过这种情况:在云服务器上用Nginx部署了一个纯HTMLCSSJS的静态站点,连数据库都不用,理论上应该毫秒级响应——结果打开首页,F12 Network面…...
截图工具终极指南:从内置工具到第三方替代方案全解析)
国产系统(UOS/麒麟/方德)截图工具终极指南:从内置工具到第三方替代方案全解析
国产操作系统截图工具全攻略:从基础操作到高阶玩法在数字化办公时代,截图功能已成为日常工作中不可或缺的生产力工具。对于统信UOS、麒麟KOS、方德NFS等国产操作系统的用户而言,掌握系统内置截图工具的各项功能,并了解当内置工具无…...

proj-agones:知识点:helm
helm install之后的log be like:(base) savilahaobogon ~ % helm install prometheus prometheus-community/kube-prometheus-stack -n monitoring --create-namespace NAME: prometheus LAST DEPLOYED: Wed May 20 14:54:39 2026 NAMESPACE: monitoring STATUS: de…...

HTML 零基础入门:从概念到常用标签详解,前端入门超详细版
一、HTML介绍HTML 全称超文本标记语言(HyperText Markup Language),是搭建网页的基础骨架语言,也是前端开发最入门、最核心的语言。它不属于编程语言,没有逻辑运算、没有变量,只是一套标记标签,…...

pycryptodome导入失败的四大底层原因与诊断方案
1. 这不是pycryptodome的问题,而是你没看清它真正依赖的底层逻辑“ImportError: No module named Crypto”、“AttributeError: module Crypto.Cipher has no attribute AES”、“ModuleNotFoundError: No module named Cryptography_cffi...”——这些报错我过去三…...

ARM嵌入式C#开发实战:基于SkiaSharp的低延迟GUI实现
1. 这不是玩具,是ARM嵌入式系统能力的“压力测试仪”很多人第一次听说“在ARM开发板上跑C#游戏”,第一反应是:这能行?C#不是Windows桌面和服务器的语言吗?Mono?.NET Core?ARM板子连图形驱动都配…...