基于【逻辑回归】的评分卡模型金融借贷风控项目实战
背景知识:
在银行借贷过程中,评分卡是一种以分数形式来衡量一个客户的信用风险大小的手段。今天我们来复现一个评分A卡的模型。完整的模型开发所需流程包括:获取数据,数据清洗和特征工程,模型开发,模型检验和评估,模型上线,模型检测和报告。
我们先来导入相关的模块:
'''获取数据——数据清洗——特征工程——模型训练和开发——模型检验和评估——模型上线和监控'''
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression先获取数据并查看数据的形状:
# 1.获取数据
data = pd.read_csv(r"E:\AI课程笔记\机器学习_2\05逻辑回归与评分卡\rankingcard.csv")
data.drop("Unnamed: 0", axis=1, inplace=True)
data.shape #(150000, 11)接着做数据清洗,包括重复值,缺失值和异常值。先去除重复值并重置索引:
# 2.1 去除重复值
data.drop_duplicates(inplace=True)
data.shape
data.index = range(data.shape[0]) # 重置索引查看有多少缺失值:
data.isnull().sum() # 查看缺失值
发现monthly Income和numberofdependents有缺失值。在这里,NumberOfDependents用所在列的平均值来填充
(注意:在具体业务中,算法工程师需要和业务人员具体了解每项业务指标的含义来筛选最合适的填充方式)
data["NumberOfDependents"].fillna(int(data["NumberOfDependents"].mean()), inplace=True) # 用平均值填补缺失值MonthlyIncome我们用随机森林回归(随机森林回归的原理是:基于用特征ABC去预测Z的思想,所以也可以用ABZ去预测C)来填充:
def fill_missing_rf(x, y, to_fill):"""使用随机森林填补一个特征的缺失值的函数参数:x:要填补的特征矩阵y:完整的,没有缺失值的标签to_fill:字符串,要填补的那一列的名称"""# 构建我们的新特征矩阵和新标签df = x.copy() # 复制特征矩阵fill = df.loc[:, to_fill] # 提取我们的标签df = pd.concat([df.loc[:, df.columns != to_fill], pd.DataFrame(y)], axis=1) # 构建新的特征矩阵# 找出我们的训练集和测试集Ytrain = fill[fill.notnull()]Ytest = fill[fill.isnull()]Xtrain = df.iloc[Ytrain.index, :]Xtest = df.iloc[Ytest.index, :]# 用随机森林回归来填补缺失值from sklearn.ensemble import RandomForestRegressor as rfrrfr = rfr(n_estimators=100).fit(Xtrain, Ytrain)Ypredict = rfr.predict(Xtest)return Ypredict
X = data.iloc[:, 1:]
Y = data["SeriousDlqin2yrs"]
y_pred = fill_missing_rf(X, Y, "MonthlyIncome")
data.loc[data.loc[:, "MonthlyIncome"].isnull(), "MonthlyIncome"] = y_pred
data.isnull().sum() # 查看缺失值将缺失值填充完毕后,查看数据信息:

发现数据已经没有缺失值了。最后我们来处理异常值。显示数据永远都会有异常值,我们需要去根据业务性质去捕捉。在这里,我们发现有一条年龄为0的数据,这显然是异常值,因此我们将它删除,并返回删除后的原数据(还有更多的异常值需要银行业务方面的知识,和算法无关,这里就不赘述了):
data = data[data["age"] != 0]到这里,重复值,缺失值和异常值我们都处理完毕了。再考虑是否需要做标准化,答案是不需要。因为对业务人员来说,他们无法理解标准化后的数据是什么意思。
接下来我们查看一下好客户和坏客户分别有多少:
Y.value_counts()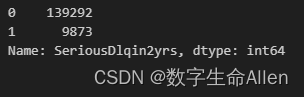
我们发现标签值0有13w+的数据,1只有不到1w的数据,这说明数据有严重的样本不均衡问题。在这里我们可以使用上采样法去平衡样本:
# 样本不均衡,用上采样算法生成新的样本
import imblearn # imblearn是专门用来处理样本不均衡问题的库
from imblearn.over_sampling import SMOTE # SMOTE是上采样算法
sm = SMOTE(random_state=42) # 实例化
X = data.iloc[:, 1:]
Y = data["SeriousDlqin2yrs"]
X, Y = sm.fit_resample(X, Y) # 返回上采样过后的特征矩阵和标签
X = pd.DataFrame(X) # 将X转换为DataFrame格式
Y = pd.DataFrame(Y) # 将Y转换为DataFrame格式
data2 = pd.concat([Y, X], axis=1) # 将X和Y合并
data2.columns = data.columns # 将data2的列名改为data的列名
data2.head(5)
data2.shape
Y.value_counts()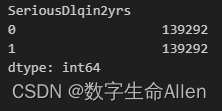
这个时候我们发现样本就均衡了。
到这里,我们就完成了数据预处理的全部工作。接下来我们将数据切片成特征矩阵和标签矩阵,在其基础上划分为训练集和测试集后,将特征训练集和标签训练集合并,特征测试集和标签测试集合并,并将他们保存至本地:
# 数据集划分
X = data2.iloc[:, 1:]
Y = data2.iloc[:, 0]
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X, Y, test_size=0.3, random_state=420)# 训练集和测试集分别存储至本地
train = pd.concat([Ytrain, Xtrain], axis=1)
train.index = range(train.shape[0])
train.columns = data.columnstest = pd.concat([Ytest, Xtest], axis=1)
test.index = range(test.shape[0])
test.columns = data.columnstrain.to_csv(r"E:\AI课程笔记\机器学习_2\05逻辑回归与评分卡\train.csv")
test.to_csv(r"E:\AI课程笔记\机器学习_2\05逻辑回归与评分卡\test.csv")接下来我们对各个特征进行分档,我们使用分箱来离散化连续变量,好让拥有不同属性的人,根据不同的特征被分成不同的类别,打上不同的分数,类似于聚类。分箱最好在4-5个为佳。
分箱有几个重要的原因:
- 简化模型:将连续数据分成箱子后,可以将其视为离散数据,更容易建立和理解模型。
- 处理异常值:分箱可以帮助识别和处理异常值,将其归入适当的箱子中,减少异常值对模型的影响。
- 解决非线性关系:某些情况下,变量与目标之间的关系可能是非线性的,分箱可以捕捉到这种非线性关系。
在这里还要介绍两个概念,IV和WOE。


每个箱子的WOE越大,代表这个箱子的优质客户越多;IV值衡量的是某一个变量的信息量,可用来表示一个变量的预测能力,用来做特征选择。箱子越多IV会越小,因为信息损失会很多;IV越小说明特征几乎不带有有效信息,对模型没有贡献,可以被删除,但IV越大,有效信息非常多,对模型的贡献率超高并且可疑。所以我们需要找到V的大小和箱子个数的平衡点。
在分箱的过程中,箱子的数量是一个重要的参数。箱子的数量越多,每个箱子的区间就越小,模型对数据的拟合程度就越高,但是也会导致信息损失更多。因为当箱子的数量增加时,每个箱子中的样本数量就会减少,从而导致每个箱子中的样本分布更加不均匀,可能会出现某些箱子中只有少数样本,或者某些箱子中只有一种样本。这些情况都会导致模型的泛化能力下降,从而影响模型的预测效果。所以我们需要画出IV值的学习曲线。
分箱的步骤是:①先把连续性变量分成分类型变量②确保每一组都包含两种类型的样本③对相邻的组进行卡方检验,如果P值很大则进行合并,直到少于N箱。④让一个特征分成(2,3,4,20)箱,观察每个特征的IV值如何变化,找出最适合的分箱个数。⑤计算每个分箱的WOE值,观察分箱效果。
接下来以[age]特征为例,来对数据进行分箱,在这里我们用pandas库的qcut函数来分箱(假设先分成20箱,q = 20),并生成一个“qcut新列”:
# qcut等频分箱
train1 = train.copy()
train1["qcut"], updown = pd.qcut(train1["age"], retbins=True, q=20) # 等频分箱
train1["qcut"].value_counts() # 查看每个分箱中的样本量
updown # 查看每个分箱的上限和下限新生成的列如下图所示:
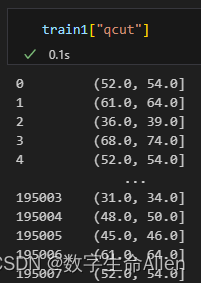
可以清晰的看到每个样本所在的分箱情况,我们再来看看每个箱子里面包含的样本数:
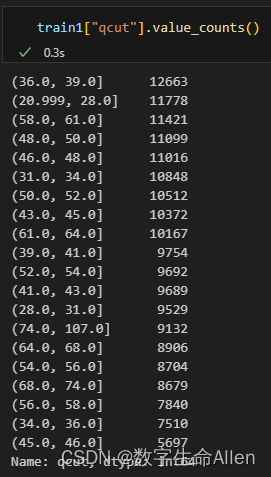
接下来我们再来看看每个箱子中0和1的个数:
# 查看每个分箱中0和1的数量
coount_y0 = train1[train1["SeriousDlqin2yrs"] == 0].groupby(by="qcut").count()["SeriousDlqin2yrs"] # 每个箱子中0的个数
coount_y1 = train1[train1["SeriousDlqin2yrs"] == 1].groupby(by="qcut").count()["SeriousDlqin2yrs"] # 每个箱子中1的个数
上图所示的是每个箱子中0的个数。为了将数据信息统一展示,我们运行如下代码将数据合并:-
num_bins = [*zip(updown, updown[1:], coount_y0, coount_y1)] # 将每个分箱的上限、下限、0的个数、1的个数放在一起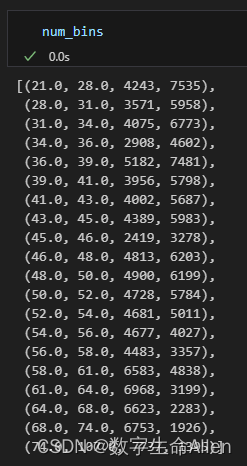
为了让数据可读性更强,我们重新生成表头:
columns = ["min", "max", "count_0", "count_1"]df = pd.DataFrame(num_bins, columns=columns)
每个箱子的上限和下限以及0的数量,1的数量都清晰可见了。接下来我们构造两个函数,分别计算WOE和IV值:
# 计算WOE和iv值
def get_woe(num_bins):# 通过num_bins数据计算woecolumns = ["min", "max", "count_0", "count_1"]df = pd.DataFrame(num_bins, columns=columns) # 将num_bins转换为DataFramedf["total"] = df.count_0 + df.count_1 # 每个箱子的总数df["percentage"] = df.total / df.total.sum() # 每个箱子的占比df["bad_rate"] = df.count_1 / df.total # 每个箱子中1的占比df["good%"] = df.count_0 / df.count_0.sum() # 每个箱子中0的占比df["bad%"] = df.count_1 / df.count_1.sum() # 每个箱子中1的占比df["woe"] = np.log(df["good%"] / df["bad%"]) # 计算每个箱子的woe值return df# 计算IV值
def get_iv(df): # 通过df计算IV值rate = df["good%"] - df["bad%"] # 计算每个箱子中好人和坏人的占比差iv = np.sum(rate * df.woe) # 计算IV值return iv接下来我们通过卡方检验,判断箱子之间的相似性:
# 卡方检验 用来检验两个变量之间是否独立
num_bins_ = num_bins.copy()
import scipy.stats
IV = []
axisx = []
while len(num_bins_) > 2:pvs = []# 获取num_bins_两两之间的卡方检验的置信度(或卡方值)for i in range(len(num_bins_) - 1):x1 = num_bins_[i][2:]x2 = num_bins_[i + 1][2:]# 0返回卡方值,1返回p值pv = scipy.stats.chi2_contingency([x1, x2])[1] # p值pvs.append(pv)# 通过p值进行处理,合并p值最大的两组i = pvs.index(max(pvs))num_bins_[i:i + 2] = [(num_bins_[i][0],num_bins_[i + 1][1],num_bins_[i][2] + num_bins_[i + 1][2],num_bins_[i][3] + num_bins_[i + 1][3])] # 将卡方值最大的两组合并bins_df = get_woe(num_bins_)axisx.append(len(num_bins_))IV.append(get_iv(bins_df))
plt.figure()
plt.plot(axisx, IV)
plt.xticks(axisx)
plt.xlabel("number of box")
plt.ylabel("IV")
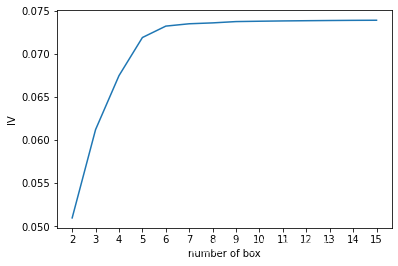
plt.show()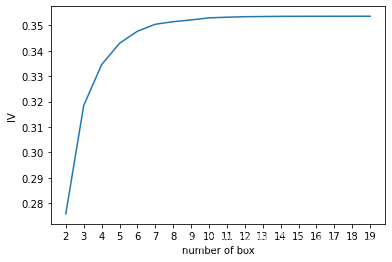
由图可知,我们要找到转折点,也就是当箱体等于6时,可以得到最优的IV。因为当箱体从6开始,IV值的增长速率由快转慢。
接下来我们把分箱过程包装成1个函数:
# 将合并箱体的过程包装成函数,实现分箱
def get_bin(num_bins,n):while len(num_bins) > n:pvs = []# 获取num_bins_两两之间的卡方检验的置信度(或卡方值)for i in range(len(num_bins) - 1):x1 = num_bins[i][2:]x2 = num_bins[i + 1][2:]# 0返回卡方值,1返回p值pv = scipy.stats.chi2_contingency([x1, x2])[1] # p值pvs.append(pv)# 通过p值进行处理,合并p值最大的两组i = pvs.index(max(pvs))num_bins[i:i + 2] = [(num_bins[i][0],num_bins[i + 1][1],num_bins[i][2] + num_bins[i + 1][2],num_bins[i][3] + num_bins[i + 1][3])] # 将卡方值最大的两组合并return num_binsafterbins = get_bin(num_bins, 6)
afterbins

可以看到,原先20箱的数据,现在变成了6箱。查看一下每组的WOE值:
bins_df = get_woe(afterbins)
bins_df
可以看到,WOE的组间差距很大,并且WOE单调递增(如果WOE有超过两个转折点,说明分箱过程有问题)。接下来我们将上述的全部分箱过程,打包成一个函数:
# 接下来我们将选取最佳分箱个数的过程包装成函数,对所有特征进行分箱
def graphforbestbin(DF, X, Y, n=5, q=20, graph=True):"""自动最优分箱函数,基于卡方检验的分箱参数:DF: 需要输入的数据X: 需要分箱的列名Y: 分箱数据对应的标签 Y 列名n: 保留分箱个数q: 初始分箱的个数graph: 是否要画出IV图像区间为前开后闭 (]"""DF = DF[[X, Y]].copy()DF["qcut"], bins = pd.qcut(DF[X], retbins=True, q=q, duplicates="drop")coount_y0 = DF.loc[DF[Y] == 0].groupby(by="qcut").count()[Y] # 每个箱子中0的个数coount_y1 = DF.loc[DF[Y] == 1].groupby(by="qcut").count()[Y] # 每个箱子中1的个数num_bins = [*zip(bins, bins[1:], coount_y0, coount_y1)] # 将每个分箱的上限、下限、0的个数、1的个数放在一起for i in range(q):if 0 in num_bins[0][2:]:num_bins[0:2] = [(num_bins[0][0],num_bins[1][1],num_bins[0][2] + num_bins[1][2],num_bins[0][3] + num_bins[1][3])]continuefor i in range(len(num_bins)):if 0 in num_bins[i][2:]:num_bins[i - 1:i + 1] = [(num_bins[i - 1][0],num_bins[i][1],num_bins[i - 1][2] + num_bins[i][2],num_bins[i - 1][3] + num_bins[i][3])]breakelse:breakdef get_woe(num_bins):# 通过num_bins数据计算woecolumns = ["min", "max", "count_0", "count_1"]df = pd.DataFrame(num_bins, columns=columns) # 将num_bins转换为DataFramedf["total"] = df.count_0 + df.count_1 # 每个箱子的总数df["percentage"] = df.total / df.total.sum() # 每个箱子的占比df["bad_rate"] = df.count_1 / df.total # 每个箱子中1的占比df["good%"] = df.count_0 / df.count_0.sum() # 每个箱子中0的占比df["bad%"] = df.count_1 / df.count_1.sum() # 每个箱子中1的占比df["woe"] = np.log(df["good%"] / df["bad%"]) # 计算每个箱子的woe值return dfdef get_iv(df): # 通过df计算IV值rate = df["good%"] - df["bad%"] # 计算每个箱子中好人和坏人的占比差iv = np.sum(rate * df.woe) # 计算IV值return ivIV = []axisx = []while len(num_bins) > n:pvs = []# 获取num_bins_两两之间的卡方检验的置信度(或卡方值)for i in range(len(num_bins) - 1):x1 = num_bins[i][2:]x2 = num_bins[i + 1][2:]# 0返回卡方值,1返回p值pv = scipy.stats.chi2_contingency([x1, x2])[1]pvs.append(pv)# 通过p值进行处理,合并p值最大的两组i = pvs.index(max(pvs))num_bins[i:i + 2] = [(num_bins[i][0],num_bins[i + 1][1],num_bins[i][2] + num_bins[i + 1][2],num_bins[i][3] + num_bins[i + 1][3])]bins_df = pd.DataFrame(get_woe(num_bins))axisx.append(len(num_bins))IV.append(get_iv(bins_df))if graph:plt.figure()plt.plot(axisx, IV)plt.xticks(axisx)plt.xlabel("number of box")plt.ylabel("IV")plt.show()return bins_dffor i in train.columns[1:-1]:print(i)graphforbestbin(train, i, "SeriousDlqin2yrs", n=2, q=20, graph=True)运行一下看看结果:

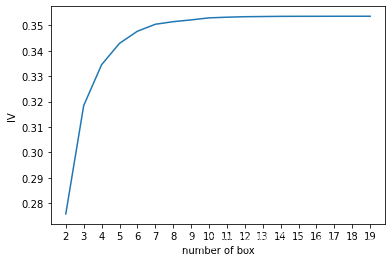

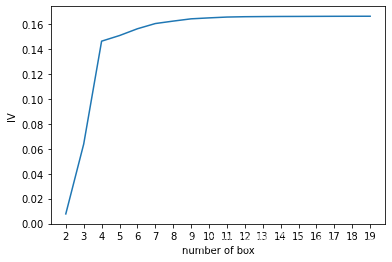




可以发现有的可以自动分箱,有的无法自动分箱。无法自动分箱的原因是该特征本身就是分类特征,不是连续特征,因此系统无法绘制出分箱图像。对于无法自动分箱的特征,我们用负无穷和正无穷替换原有的最小值和最大值,这是为了可以覆盖所有情况
# 可以自动分箱的变量
auto_col_bins = {"RevolvingUtilizationOfUnsecuredLines": 6,"age": 5,"DebtRatio": 4,"MonthlyIncome": 3,"NumberOfOpenCreditLinesAndLoans": 5}# 不能自动分箱的变量
hand_bins = {"NumberOfTime30-59DaysPastDueNotWorse": [0, 1, 2, 13],"NumberOfTimes90DaysLate": [0, 1, 2, 17],"NumberRealEstateLoansOrLines": [0, 1, 2, 4, 54],"NumberOfTime60-89DaysPastDueNotWorse": [0, 1, 2, 8],"NumberOfDependents": [0, 1, 2, 3]}
# 保证区间覆盖使用np.inf替换最大值,使用-np.inf替换最小值
hand_bins = {k: [-np.inf, *v[:-1], np.inf] for k, v in hand_bins.items()}相关文章:
基于【逻辑回归】的评分卡模型金融借贷风控项目实战
背景知识: 在银行借贷过程中,评分卡是一种以分数形式来衡量一个客户的信用风险大小的手段。今天我们来复现一个评分A卡的模型。完整的模型开发所需流程包括:获取数据,数据清洗和特征工程,模型开发,…...

企业拉美跨境出海面对时延情况怎么办?
随着全球化不断发展,中国企业也不断向海外拓展业务,开拓市场,增加收入来源,扩大自身品牌影响力。然而出海企业面临不同以往的困难和挑战,在其中不可避免面临的跨境网络时延问题,如何选择区域进行部署企业业…...

【vector题解】只出现一次的数字 | 电话号码的数字组合
只出现一次的数字 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给你一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。你可以按 任意顺序 返回答案。 你必须设计并…...
VS2022 开发方式
使用 C# 在VS 2022 上开发时,发现有多种项目类型可以创建。这些类型放一起容易搞混,于是记录一下各种类型的区别。 这里主要介绍windows控制台程序、MFC程序、WPF程序、WinForm程序的特点。 创建哪种应用? 创建控制台应用 Windows控制台程序…...

【Python语言速回顾】——数据可视化基础
目录 引入 一、Matplotlib模块(常用) 1、绘图流程&常用图 编辑 2、绘制子图&添加标注 编辑 3、面向对象画图 4、Pylab模块应用 二、Seaborn模块(常用) 1、常用图 2、代码示例 编辑 编辑 编辑 …...
java实现pdf文件添加水印,下载到浏览器
java实现pdf文件添加水印,下载到浏览器 添加itextpdf依赖 <dependency><groupId>com.itextpdf</groupId><artifactId>itextpdf</artifactId><version>5.5.8</version> </dependency>文件下载到浏览器和指定路径 …...
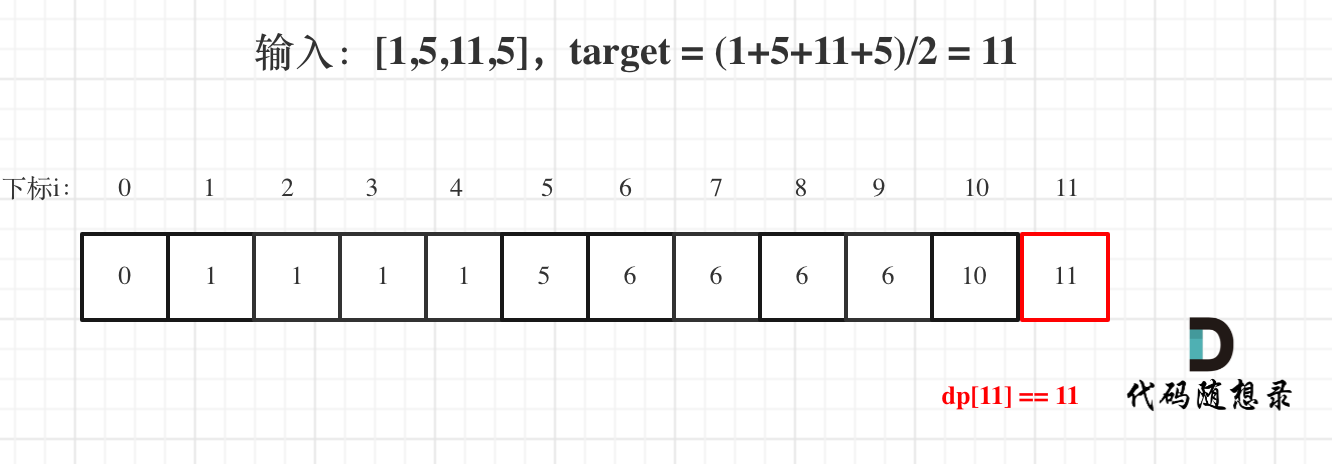
代码随想录算法训练营第四十一天丨 动态规划part04
01背包理论基础 见连接:代码随想录 416. 分割等和子集 思路 01背包问题 背包问题,大家都知道,有N件物品和一个最多能背重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解…...

PyCharm免费安装和新手使用教程
简介 PyCharm是一款由JetBrains公司开发的Python集成开发环境(IDE)。它提供了一系列强大的功能,包括自动代码完成、语法高亮、自动缩进、代码重构、调试器、测试工具、版本控制工具等,使开发者可以更加高效地开发Python应用程序。…...

使用Python的Scikit-Learn进行决策树建模和可视化:以隐形眼镜数据集为例
决策树是一种强大的机器学习算法,它在数据挖掘和模式识别中被广泛应用。决策树模型可以帮助我们理解数据中的模式和规则,并做出预测。在本文中,我们将介绍如何使用Python的Scikit-Learn库构建决策树模型,并使用Graphviz进行可视化…...

开源软件:释放创新的力量,改变数字世界的游戏规则
在充满活力的技术领域,创新是至高无上的,有一种方法已获得显著的吸引力——开源软件。开源软件凭借其透明、协作和无限可能性的精神,彻底改变了我们开发、共享和定制应用程序的方式。从操作系统到数据分析工具,其影响跨越了多个领…...
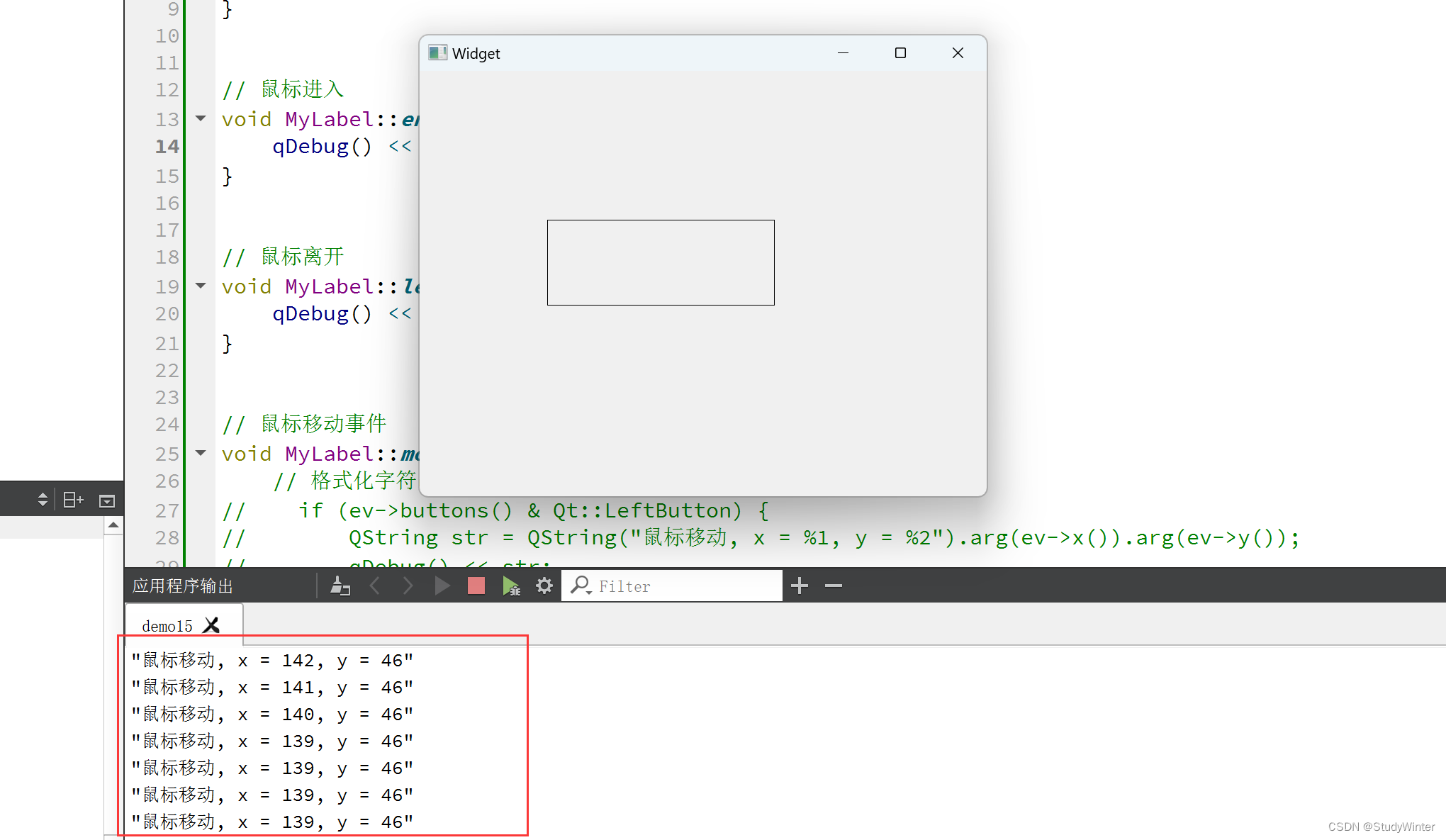
【QT】鼠标常用事件
新建项目 加标签控件 当鼠标进去,显示【鼠标进入】,离开时显示【鼠标离开】 将QLable提升成自己的控件,然后再去捕获 添加文件 改继承的类名 提升类 同一个父类,可以提升 效果 现在代码就和Qlabel对应起来了。 在.h中声明&…...
--mlx90640 - 红外测温(MLX90640))
LuatOS-SOC接口文档(air780E)--mlx90640 - 红外测温(MLX90640)
常量# 常量 类型 解释 mlx90640.FPS1HZ number FPS1HZ mlx90640.FPS2HZ number FPS2HZ mlx90640.FPS4HZ number FPS4HZ mlx90640.FPS8HZ number FPS8HZ mlx90640.FPS16HZ number FPS16HZ mlx90640.FPS32HZ number FPS32HZ mlx90640.FPS64HZ number FPS6…...

java连接本地数据库可以简写为///
java连接数据库配置文件写为: server:port: 8091 spring:application:name: user-managerdatasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/user?serverTimezoneAsia/Shanghai&characterEncodingutf-8username: root…...

基于springboot漫画动漫网站
基于springbootvue漫画动漫网站 摘要 基于Spring Boot的漫画动漫网站是一个精彩的项目,它结合了现代Web开发技术和漫画爱好者的热情。这个网站的目标是为用户提供一个便捷的平台,让他们能够欣赏各种漫画和动漫作品,与其他爱好者分享他们的兴趣…...

autoFac 生命周期 试验
1.概述 autoFac的生命周期 序号名称说明1InstancePerDependency每次请求都创建一个新的对象2InstancePerLifetimeScope同一个Lifetime生成的对象是同一个实例3SingleInstance每次都用同一个对象 2.注 InstancePerLifetimeScope 同一个Lifetime生成的对象是同一个实例&#x…...

foreach、for in 和for of的区别?
forEach,for...in 和 for...of 是 JavaScript 中用于遍历数据的三种不同的结构。它们在遍历数组、对象和可迭代对象(如 Set 和 Map)时非常有用。尽管它们都可以用于循环遍历,但它们之间存在一些重要的区别: forEach&a…...

【Effective C++】条款45: 运用成员函数模板接受所有兼容的类型
假设有如下继承结构: class Top{}; class Middle: public Top{}; class Bottom: public Middle{};public继承意味着is-a关系,所有的基类都是派生类,但反之则不是,例如所有的学生都是人,但不是所有的人都是学生. 派生类到基类的指针可以直接隐式转换 Top* pt1 new Middle; T…...

WSL1 安装 debian xfce 用xrdp 导入远程桌面
凑合能用 晃晃行 晃晃不行 而且比较卡 还经常报崩溃 sudo apt install xfce4 xfce4-goodies xorg dbus-x11 x11-xserver-utils apt install locales -y 安装过完应该会提示设置locales,如果安装完之后想要更改相关设置,可以使用如下命令重新设置loca…...
WPF RelativeSource属性-目标对象类型易错
上一篇转载了RelativeSource的三种用法,其中第二种用法较常见,这里记录一下项目中曾经发生错误的地方,以防自己哪天忘记了,又犯了同样错误—WPF RelativeSource属性-CSDN博客 先回顾一下: 控件关联其父级容器的属性—…...

Java while 和do while 循环
循环是程序中的重要流程结构之一。循环语句能够使程序代码重复执行,适用于需要重复一段代码直到满足特定条件为止的情况。 所有流行的编程语言中都有循环语句。Java 中采用的循环语句与C语言中的循环语句相似,主要有 while、do-while 和 for。 另外 Ja…...

知识图谱与大语言模型协同:构建材料科学精准智能问答系统
1. 项目概述:当知识图谱遇见大语言模型“想象一下,未来有这样一个设备……个人可以存储他所有的书籍、记录和通信,并且它被机械化,可以以极高的速度和灵活性进行查阅。它是他记忆的一个放大的、亲密的补充。”——范内瓦布什&…...

Web渗透测试全流程实战指南:从侦察到报告的结构化方法
1. 这不是“黑客速成班”,而是一张能真正带你进渗透测试实战现场的路线图很多人点开“Web渗透测试学习流程图”时,心里想的是:学完这个,我是不是就能黑进某个网站?能不能接单赚钱?甚至幻想自己坐在咖啡馆里…...
,实测涨点还省显存)
别再只用MaxPool了!试试在YOLOv9里集成Haar小波下采样(HWD),实测涨点还省显存
突破传统下采样瓶颈:YOLOv9集成Haar小波下采样的实战指南当你在训练YOLOv9模型时,是否遇到过这样的困境——为了提升检测精度而增加模型复杂度,却发现显存迅速耗尽;或是采用激进的下采样策略后,小目标检测性能明显下降…...

Windows 11系统下,Fiddler代理端口不是8888?这份Mumu模拟器网络调试避坑指南请收好
Windows 11系统下Fiddler与Mumu模拟器网络调试实战指南在移动应用开发和测试过程中,网络调试工具与模拟器的配合使用是必不可少的环节。许多开发者习惯性地认为Fiddler的默认代理端口就是8888,但在实际配置中,这个假设往往会导致一系列难以排…...
资源包的5步极速法)
紧急预警:新课标实施倒计时90天!用PlayAI快速构建跨学科项目式学习(PBL)资源包的5步极速法
更多请点击: https://kaifayun.com 第一章:紧急预警:新课标实施倒计时90天!用PlayAI快速构建跨学科项目式学习(PBL)资源包的5步极速法 距离《义务教育课程方案(2022年版)》全面落地…...

大白话拆解AI黑话!从LLM到Agent,一篇扫盲无压力
前言:别再被AI名词劝退了 有没有一种感觉:现在刷技术文章、看AI项目、聊行业趋势,满屏都是 LLM、Token、上下文、RAG、Agent、幻觉…… 每个词都似懂非懂,搜完解释看完就忘,想用的时候依旧一头雾水。 其实所有AI名词&a…...

数据科学实践案例与项目管理
数据科学实践案例与项目管理 1. 技术分析 1.1 数据科学项目管理概述 数据科学项目管理是确保项目成功的关键: 项目生命周期问题定义: 明确目标数据收集: 获取数据数据处理: 清洗转换模型开发: 构建模型评估验证: 评估效果部署上线: 生产环境项目管理要素:目标设定进…...

proj-agones:知识点:helm
helm install之后的log be like:(base) savilahaobogon ~ % helm install prometheus prometheus-community/kube-prometheus-stack -n monitoring --create-namespace NAME: prometheus LAST DEPLOYED: Wed May 20 14:54:39 2026 NAMESPACE: monitoring STATUS: de…...

观察Taotoken按Token计费模式如何帮助项目控制预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken按Token计费模式如何帮助项目控制预算 对于依赖大模型API进行开发的团队和个人而言,成本控制是一个贯穿项…...

XZ63C,18V输入,CMOS输出电压检测芯片
产品概述这系列芯片是使用 CMOS 技术开发的高精度、低功耗、小封装电压检测芯片。检测电压在小温度漂移的情况下保持极高的精度。输出配置是 CMOS 输出。产品特点● 封装:SOT23-3,TO92● 输出配置:CMOS● 工作电压:1.5V-18V …...