【ElasticSearch系列-03】ElasticSearch的高级句法查询Query DSL
ElasticSearch系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】ElasticSearch下载和安装 | https://zhenghuisheng.blog.csdn.net/article/details/129260827 |
| 【二】ElasticSearch概念和基本操作 | https://blog.csdn.net/zhenghuishengq/article/details/134121631 |
| 【二】ElasticSearch的高级查询Query DSL | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
ElasticSearch的高级句法查询Query DSL
- 一,ElasticSearch高级查询语法Query DSL
- 一,Query DSL的基本使用
- 1.1,深分页查询Scroll
- 1.2,match条件查询
- 1.3,match_phrase短语查询
- 1.4,multi_match多字段查询
- 1.5,query_string 查询
- 1.6,term精确匹配
- 1.7,prefix前缀查询
- 1.8,通配符查询wildcard
- 1.9,范围查询range
- 1.10,fuzzy模糊查询
- 1.11,highlight查询
- 2,Query DSL多条件查询(高级查询)
- 2.1,Bool Query布尔查询
- 2.2,Boosting Query权重查询
- 2.3,Dis max query 最佳匹配
- 2.4,Cross Field跨字段匹配
一,ElasticSearch高级查询语法Query DSL
前面两篇主要讲解了es的安装以及一些基本的概念,接下来这篇讲解的是es的高阶语法,QueryDSL。在这里主要是用ik分词器讲解,暂不使用默认的分词器。
一,Query DSL的基本使用
在安装了kibana之后,内部会有一个search的语句,用来查询数据
GET _search
{"query": {"match_all": {}}
}
其结果如下,默认是返回前10条数据,类似于做了分页,默认加了一个from0和一个size10,并且在es中,size默认是小于或者等于10000,如果超过这个值,就会直接抛异常

1.1,深分页查询Scroll
上面说了默认采用的是from加size的方式来解决分页数据返回的问题,但是size的数据是有大小的限制的,当然也可以通过以下命令来调节size的大小
PUT /zhs/_settings
{ "index.max_result_window" :"20000"
}
虽然这种方式可以暂时调节size大小,但是治标不治本,因为依旧是会存在限制,并且由于数据量太大,还可能将内存撑爆。因此后面引入了这种Scroll游标的方式来查询全量数据
GET /zhs_db/_search?scroll=1m //1m表示查询时间窗口保持1分钟
{"query": {"match_all": {}},"size": 10 //批量查询10条数据
}
在将查询的值返回中可以看出,会生成一个_scroll_id,以及返回一些分片数,查询的总条数等
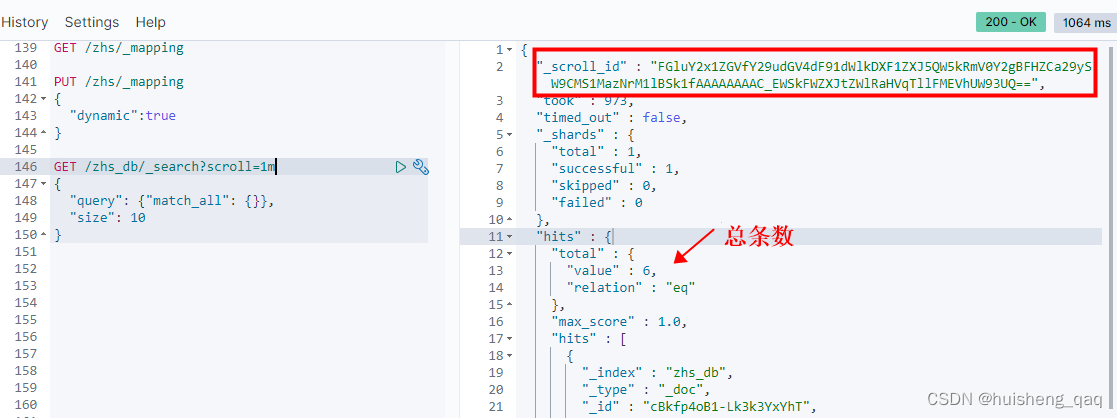
就是比如说第一次查询10条数据,随后记录最后一条数据的id,然后在这个时间窗口期内,携带这个id再去库中拉取后十条数据,往复如此。不管是关系系数据库还是非关系型数据库,其设计思想都是这样
拉取的数据会存储在快照里面,后面的操作都是操作这个快照中缓存的数据。因此为了保证性能问题,会牺牲一些精准度,因为后面写进来的数据不在这个快照里面。
1.2,match条件查询
在使用这个match之前,先创建一个索引,并设置分词器为ik分词器
DELETE /zhs_db
PUT /zhs_db
{"settings" : {"index" : {"analysis.analyzer.default.type": "ik_max_word"}}
}
先插入几条数据,先用最基础的Put的方式插入五条数据
PUT /zhs_db/_doc/1
{
"address":"东岳泰山"
}
PUT /zhs_db/_doc/2
{
"address":"西岳华山"
}
PUT /zhs_db/_doc/3
{
"address":"南岳衡山"
}
PUT /zhs_db/_doc/4
{
"address":"北岳恒山"
}
PUT /zhs_db/_doc/5
{
"address":"中岳嵩山"
}
在确定要查询某一条数据时,可以先通过这个分词分析看看是如何进行分词的
POST _analyze
{"analyzer": "ik_max_word","text": "中岳嵩山"
}
那么可以直接通过这个match的方式批量查询数据
GET /zhs_db/_search
{"query": {"match": {"address": "中岳"}}
}
如果是要查询特定的某个值,可以直接再加一个operator属性,并且value设置成and,如果没有设置这个属性,那么默认值就是的or
GET /zhs_db/_search
{"query": {"match": {"address": {"query": "中岳嵩山","operator": "and"}}}
}
除了上面的operator之外,还可以使用 minimum_should_match ,用于最小分词匹配。就是说分词器默认分为中岳和嵩山两个,只需要满足其中一个就能被查出来
address:{"query":"中岳嵩山","minimum_should_match": 1
}
1.3,match_phrase短语查询
在使用这个短语查询时,需要通过分词器分析,判断两个词的下标是否连续
GET /zhs_db/_search
{"query": {"match_phrase": {"address": "中岳嵩山"}}
}
如通过这个ik分词器分析,可以得知这两个分开的词的position是连续的,分别为0和1,如果不连续,则不能将值查询出
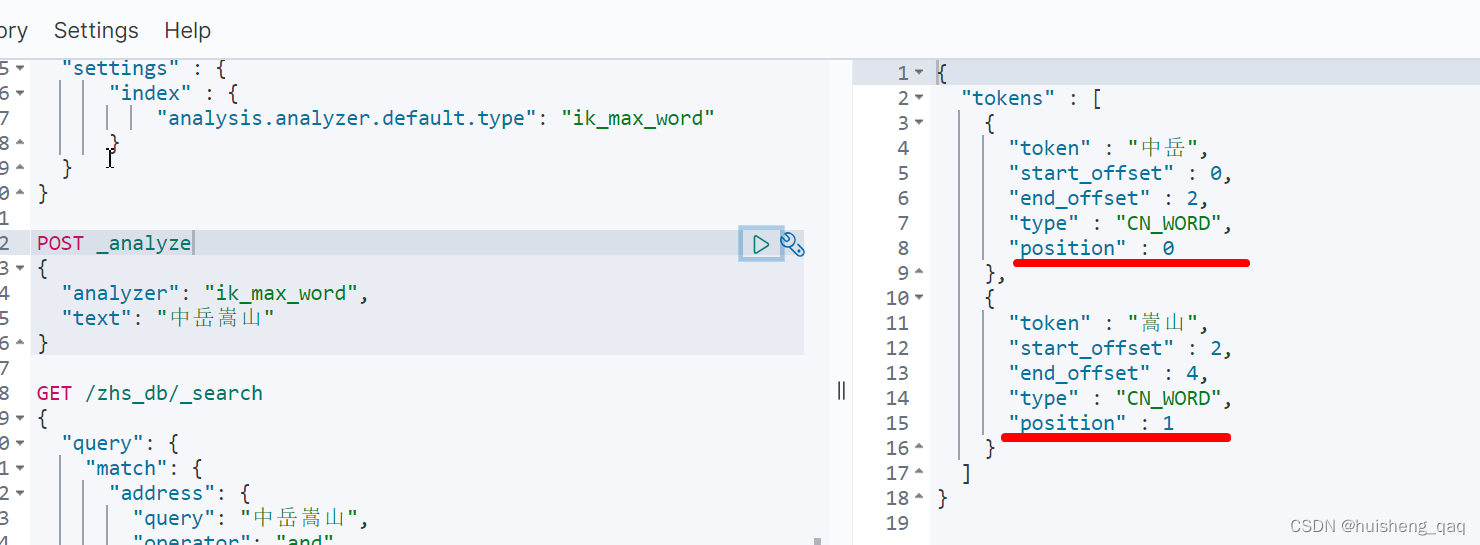
当然为了解决这个间隔问题,可以直接通过设置 slop 属性来设置允许多少个空格进行匹配
address:{"query":"中岳嵩山","slop": 1
}
1.4,multi_match多字段查询
上面主要讲解的是单字段查询,但是在实际开发中一般都是多字段查询,其语句如下
GET /zhs_db/_search
{"query": {"multi_match": {"query": "中岳嵩山","fields": ["address","name"]}}
}
1.5,query_string 查询
queryString相当于是一个multi_match的一个综合版,如果没有指定具体的字段,则会在全字段中查询
GET /zhs_db/_search
{"query": {"query_string": {"query": "中岳"}}
}
可以设置默认的字段,也可以指定多个字段
"query_string": {//"default_field": "address","fields": ["name","address"],"query": "中岳"
}
1.6,term精确匹配
上面的match属于是模糊匹配,而使用精确匹配的,就是这个term。
在ES的Mapping Type 中 keyword , date ,integer, long , double , boolean or ip 这些类型不分词,只有text类型分词。因此term在对这些数据进行查询时,就是精确匹配
GET /zhs_db/_search
{"query": {"term": {"address": "中岳"}}
}
如果想要对全字段进行精确匹配,可以添加一个keyword 关键字
"address.keyword": "中岳嵩山"
在es中,查询会有算分操作,而算分操作会影响到性能问题,而精确匹配是不需要算分的,可以将query转成filter,从而忽略算分所带来的影响
"query":{"constant_score":{"filter":{}}
}
如果短时间内存在多次term的查询,那么就会将这部分数据缓存起来
1.7,prefix前缀查询
前缀查询就是查询以某个字段开头的数据,因此用不上底层的倒排字典,而是将所有的数据遍历一遍,将符合的数据返回。由于用不上倒排索引,因此对性能是有一定的影响的
PUT /zhs_db/_search
{"query":{"prefix":{"address":{"value":"嵩山"}}}
}
1.8,通配符查询wildcard
通配符查询就和这个前缀查询一样,都是利用不上这个倒排索引,而是将所有的数据遍历查询一遍,符合的数据返回。
GET /zhs_db/_search
{"query": {"wildcard": {"address": {"value": "*山*"}}}
}
1.9,范围查询range
可以直接通过这个range关键字实现范围查询,
- gte 大于等于
- lte 小于等于
- gt 大于
- lt 小于
- now 当前时间
POST /zhs_db/_search
{"query": {"range": {"age": {"gte": 25,"lte": 28}}}
}
1.10,fuzzy模糊查询
fuzzy表示允许在打错字的情况下,将想要查询的数据查询出来。
GET /zhs_db/_search
{"query": {"fuzzy": {"address": {"value": "松山","fuzziness": 1 //表示允许错一个字}}}
}
除了使用上面这种方式,还能用match的方式实现这种错别字的模糊查询
GET /zhs_db/_search
{"query": {"match": {"address": {"query": "松山","fuzziness": 1}}}
}
1.11,highlight查询
就是将query查询出来的结果,通过highlight的方式实现高亮
GET /products/_search
{"query": {"term": {"name": {"value": "牛仔"}}},"highlight": {"fields": {"*":{}}}
}
2,Query DSL多条件查询(高级查询)
2.1,Bool Query布尔查询
在一个bool查询中,可以是一个或者多个查询字句的组合,字句总共有四种,分别是 must、should、must_not、filter,前两者使用时内部会进行算分的操作,后二者不会
must相当于是and操作,即所有几句中的查询条件都要满足。如下must中是一个数组,每个子查询中就是一个正常的query dsl查询,如必须满足中地址字段中带有公园,remark字段中带有北的数据
GET /zhs_db/_search
{"query": {"bool": {"must": [{"match": {"address": "公园"}},{"match": {"remark": "北"}}]}}
}
shouuld 表示的就是一个or的应用,表示只需要满足其中的一个查询字句就能将结果返回
GET /zhs_db/_search
{"query": {"bool": {"should": []}}
}
2.2,Boosting Query权重查询
权重查询是一种控制手段,通过设置boost权重的值来影响最终的查询结果,权重的设置如下
- 当设置的boost大于1时,查询的的相关性会提高
- 当设置的boost大于0而小于1时,查询的相关性会降低
- 当设置的boost的值为负数时,贡献负分
举一个例子,查询一篇文章时,将会员的文章显示在普通用户文章的前面,如下面的代码,先创建一个文章索引,随后插入两条数据,一条是vip用户的,一条是普通用户的,文章标题一样
PUT /article_db
POST /article_db/_bulk
{"index": {"_id": "1"}}
{"title":"java入门","comment":"精通java","type":"vip"}
{"index": {"_id": "2"}}
{"title":"java入门","comment":"精通java","type":"ordinary"}
那么在查询时,想将vip用户的文章排在前面,就可以直接通过设置这个boost权重进行设置,将vip用户的权重值设置为大于1,这样在算分时,算的分值就更大
GET /article_db/_search
{"query": {"bool": {"should": [{"match": {"title": "java入门"}},{"match": {"type": {"query": "vip","boost": 3}}},{"match": {"type": {"query": "ordinary","boost": 1}}}]}}
}
如下图所示,vip的算分为2.6,而普通用户的算分在1.2。如果算分值一样,谁id小谁在前面
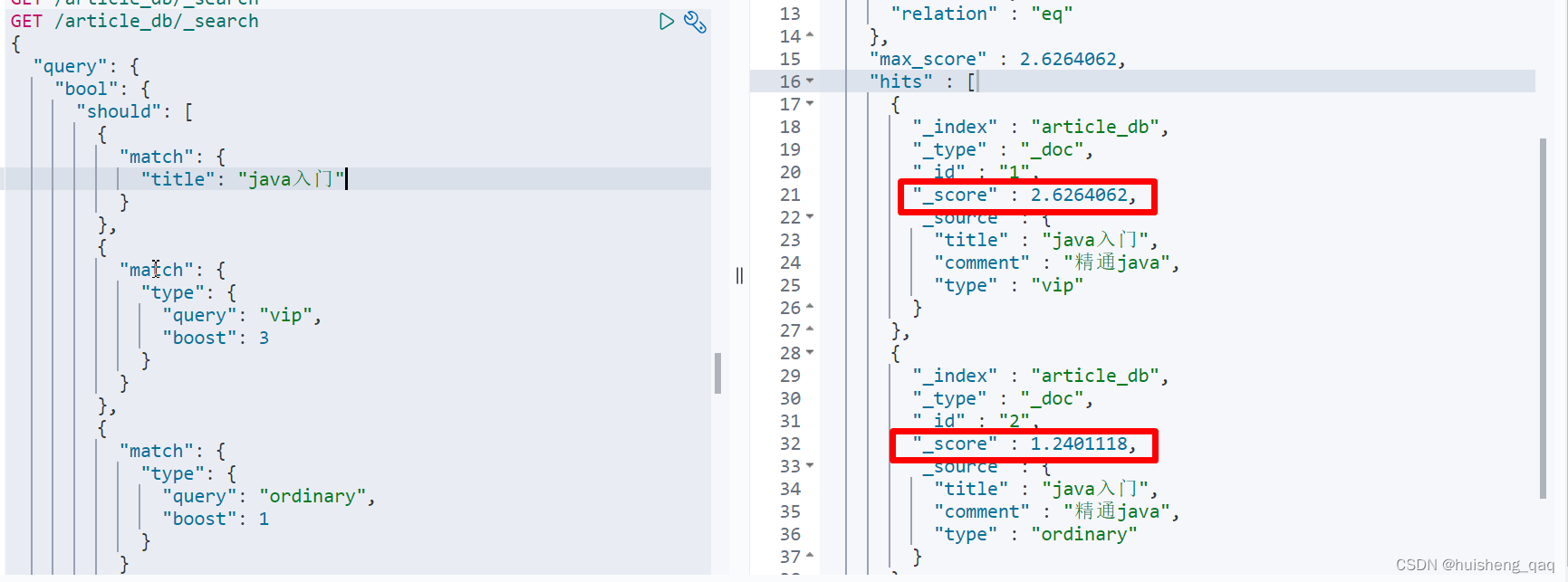
当然如果查询出了不需要的数据,优先考虑通过过滤去掉数据,再考虑降低其权重
2.3,Dis max query 最佳匹配
通过dis_max以及结合queries进行使用,并且可以通过设置这个tie_breaker来确人是最佳匹配,还是所有的字段的值同等重要
POST /article_db/_search
{"query": {"dis_max": {"queries": [{ "match": { "title": "java" }},{ "match": { "comment": "java" }}],"tie_breaker": 0.5 //0代表使用最佳匹配;1代表所有语句同等重要。}}
}
但是在实际开发中,更加的推荐通过这个multi_match这个方式来实现这个最佳字段匹配,并且设置这个type类型为 best_fields
POST /article_db/_search
{"query": {"multi_match": {"type": "best_fields","query": "java","fields": ["title","comment"],"tie_breaker": 0.2 //0代表使用最佳匹配;1代表所有语句同等重要。}}
}
除了实现最佳匹配之外,multi_match还实现了最多字段匹配,就是将type的类型设置成 most_fields
GET /titles/_search
{"query": {"multi_match": {"query": "java,"type": "most_fields","fields": ["title","comment"]}}
}
2.4,Cross Field跨字段匹配
如在遇到某些场景,需要结合多个字段的值进行匹配,如省市区,在上面讲了一种copy_to的方式解决这种跨字段匹配的方式,也可以使用这个 Cross Field 实现多字段匹配
如先创建一个address_db的地址索引,随后批量的插入一些数据
PUT /address_db
PUT /address_db/_bulk
{ "index": { "_id": "1"} }
{"province": "广东","city": "深圳","region":"南山"}
{ "index": { "_id": "2"} }
{"province": "广东","city": "深圳","region":"福田"}
{ "index": { "_id": "3"} }
{"province": "广东","city": "深圳","region":"宝安"}
{ "index": { "_id": "4"} }
{"province": "广东","city": "深圳","region":"龙岗"}
}
随后通过这个multi_match多字段查询,并且设置type类型为 cross_fields
GET /address_db/_search
{"query": {"multi_match": {"query": "广东深圳宝安","type": "cross_fields","operator": "and", "fields": ["province","city","region"]}}
}
相关文章:
【ElasticSearch系列-03】ElasticSearch的高级句法查询Query DSL
ElasticSearch系列整体栏目 内容链接地址【一】ElasticSearch下载和安装https://zhenghuisheng.blog.csdn.net/article/details/129260827【二】ElasticSearch概念和基本操作https://blog.csdn.net/zhenghuishengq/article/details/134121631【二】ElasticSearch的高级查询Quer…...

【C++ 系列文章 -- 程序员考试 201811 下午场 C++ 专题 】
1.1 C 题目六 阅读下列说明和C代码,填写程序中的空(1) ~(5),将解答写入答题纸的对应栏内。 【说明】 以下C代码实现一个简单乐器系统,音乐类(Music)可以使用…...
javaEE -15( 13000字 JavaScript入门 - 2)
一:JavaScript(WebAPI) JS 分成三个大的部分 ECMAScript: 基础语法部分DOM API: 操作页面结构BOM API: 操作浏览器 WebAPI 就包含了 DOM BOM,这个是 W3C 组织规定的. (和制定 ECMAScript 标准的大佬们不是一伙人). 前面学的 JS 基础语法主要学的是 …...
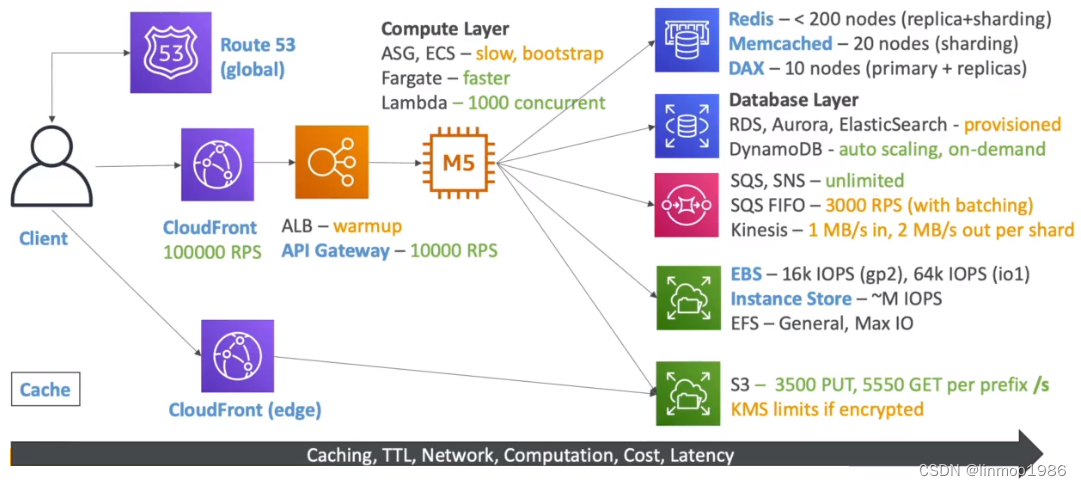
AWS SAP-C02教程11-解决方案
本章中,会根据一些常见场景的解决方案或者AWS的某一方面的总结,带你了解AWS各个组件之间的配合使用、如何在解决方案中选择组件以及如何避开其本身限制实现需求。 目录 1 处理高并发解决方案(Handing Extreme Rates)2 日志管理(AWS Managed Logs)3 部署解决方案(Deploy…...

ClickHouse Java多参UDF
一、环境版本 环境版本docker clickhouse22.3.10.22 docker pull clickhouse/clickhouse-server:22.3.10.22二、XML配置 2.1 配置文件 # 创建udf配置文件 vim /etc/clickhouse-server/demo_function.xml<functions><function><type>executable</type&…...
修改Typora默认微软雅黑字体
修改Typora字体 写在前面 我最近在折腾windows电脑,从macos转像windows不容易啊,因为键盘快捷键经常弄错,这篇文章就是修改Typora中字体显示的问题。 正文内容 我发现在windows中,字体非常的难看,微软雅黑也太丑了…...

ESP32网络开发实例-Web服务器显示LM35传感器数据
Web服务器显示LM35传感器数据 文章目录 Web服务器显示LM35传感器数据1、LM35介绍2、软件准备3、硬件准备4、代码实现4.1 LM35与ADS1115驱动4.2 Web服务器显示LM35传感器数据本文将介绍有关如何在ESP32的Web服务器中显示LM35 温度传感器数据。 1、LM35介绍 LM35 用于测量物体或…...

ATFX汇市:美联储11月利率决议再暂停加息,紧缩货币政策或已接近尾声
ATFX汇市:11月美联储利率决议结果在今日2:00公布,其中提到:美联储寻求以2%的速度实现最大的就业和通胀率,为了达成这些目标,美联储决定将联邦基金利率的目标区间维持在5.25%~5.5%;委员会将会考虑货币政策的…...
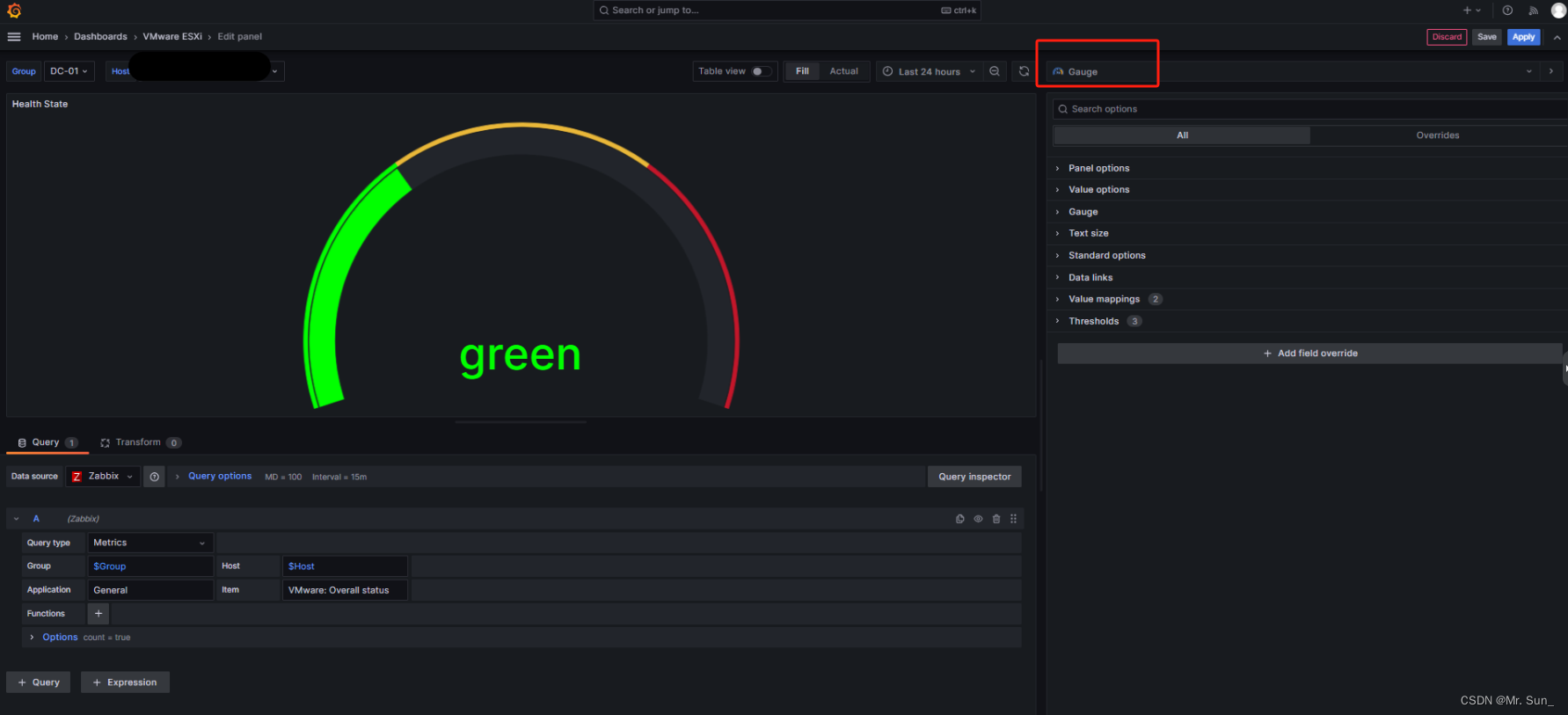
g.Grafana之Gauge的图形说明
直接上操作截图 1. 创建一个新的Dashboard 2.为Dashboard创建变量 【General】下的Name与Label的名称自定义 【Query options】 下的Group可以填写Zabbix内的所有组/.*/ , 然后通过Regex正则过滤需要的组名 3.设置Dashboard的图形 我使用文字来描述下这个图 1.我们在dash…...

MySQL笔记--Ubuntu安装MySQL并基于C++测试API
目录 1--安装MySQL 2--MySQL连接 3--代码案例 1--安装MySQL # 安装MySQL-Server sudo apt install mysql-server# 设置系统启动时自动开启 sudo systemctl start mysql # sudo systemctl enable mysql# 检查MySQL运行状态 sudo systemctl status mysql# 进入MySQL终端 sudo…...

与AI对话的艺术:如何优化Prompt以获得更好的响应反馈
前言 在当今数字化时代,人工智能系统已经成为我们生活的一部分。我们可以在智能助手、聊天机器人、搜索引擎等各种场合与AI进行对话。然而,要获得有益的回应,我们需要学会与AI进行有效的沟通,这就涉及到如何编写好的Prompt。 与…...
outlook是什么软件outlook邮箱撤回邮件方法
Outlook是微软公司开发的一款邮件客户端,也是Office办公套件的一部分。它可以与多个电子邮件服务提供商(如Outlook.com、Exchange、Gmail等)集成,用户可以使用Outlook来发送、接收和管理电子邮件、日历、联系人、任务等信息。本篇…...
电脑如何录制小视频
如果你想在你的电脑上录制视频分享给你的朋友或者亲人,无论你的电脑是win还是mac,都可以在本篇文章中找到电脑录制视频的详细教程。小编为你们整理了2种不同系统电脑的录制详细流程,继续阅读查看吧! 第一部分:windows…...

vue使用百度富文本
🔥博客主页: 破浪前进 🔖系列专栏: Vue、React、PHP ❤️感谢大家点赞👍收藏⭐评论✍️ 1、下载UEditor 链接已放到文章中了 2、上传到项目目录中 一般上传到public下,方便到时候打包进去,以免…...
【Springboot】集成Swagger
引入依赖 <dependency><groupId>io.springfox</groupId><artifactId>springfox-boot-starter</artifactId><version>3.0.0</version> </dependency> 浏览器 启动项目后 在浏览器中输入地址 localhost:端口号/swagger-ui/ 使…...
[SpringCloud | Linux] CentOS7 部署 SpringCloud 微服务
目录 一、环境准备 1、工具准备 2、虚拟机环境 3、Docker 环境 二、项目准备 1、配置各个模块(微服务)的 Dockerfile 2、配置 docker-compose.yml 文件 3、Maven 打包 4、文件整合并传输 三、微服务部署 1、部署至 Docker 2、访问微服务 四…...

阿里面试:让代码不腐烂,DDD是怎么做的?
说在前面 在40岁老架构师 尼恩的读者交流群(50)中,最近有小伙伴拿到了一线互联网企业如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题: 谈谈你的高并发落地经验? 谈谈你对DDD的理解…...

NoSQL数据库使用场景以及架构介绍
文章目录 一. 什么是NoSQL?二. NoSQL分类三. NoSQL与关系数据库有什么区别四. NoSQL主要优势和缺点五. NoSQL体系框架 其它相关推荐: 系统架构之微服务架构 系统架构设计之微内核架构 鸿蒙操作系统架构 架构设计之大数据架构(Lambda架构、Kap…...

RFID系统提升物流信息管理效率应用解决方案
一、物流仓储管理方法 1、在仓库的进出口处安装RFID读写器,当粘贴RFID标签的电动叉车和货物进入装载区时,RFID读写器会自动检索并记录信息,当它们离开物流配送中心时,入口处的RFID读写器会读取标签信息,并生成出货单&…...
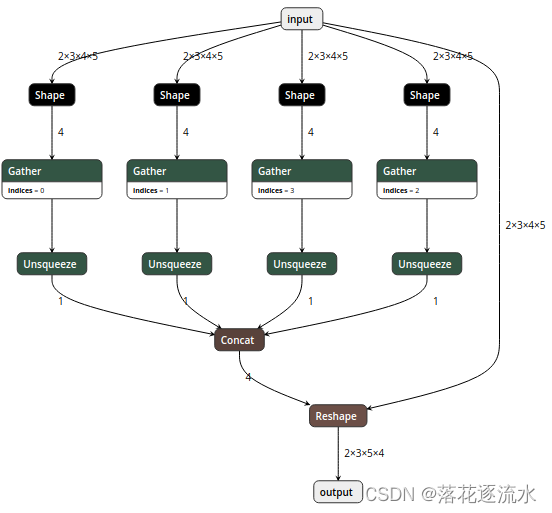
ONNX的结构与转换
ONNX的结构与转换 1. 背景2. ONNX结构分析与修改工具2.1. ONNX结构分析2.2. ONNX的兼容性问题2.3. 修改ONNX模型 3. 各大深度学习框架如何转换到ONNX?3.1. MXNet转换ONNX3.2. TensorFlow模型转ONNX3.3. PyTorch模型转ONNX3.4. PaddlePaddle模型转ONNX3.4.1. 简介3.4…...

G-Helper终极指南:如何用免费开源工具彻底替代Armoury Crate
G-Helper终极指南:如何用免费开源工具彻底替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbo…...

DOM 基础全面解析
系列文章目录 《JavaScript 基础与进阶笔记》(前期偏基础巩固与常见面试点,后续进入闭包、异步、工程化等进阶主题) 第 01 篇:数据类型与类型判断第 02 篇:变量声明与作用域第 03 篇:闭包与高阶函数第 04…...

OpenClaw:本地AI协作者,让大模型真正动手执行
1. 项目概述:当AI不再“请指示”,而是直接“已执行”你有没有过这种体验:深夜改完最后一行代码,顺手让AI助手帮忙检查下Git提交记录里有没有漏掉敏感信息——结果它只回你一句“建议使用git log -p查看”,然后就安静了…...

ChatGPT写代码总出错?揭秘92%开发者忽略的3层提示工程校验机制
更多请点击: https://intelliparadigm.com 第一章:ChatGPT写代码总出错?揭秘92%开发者忽略的3层提示工程校验机制 当ChatGPT生成的代码在本地运行失败、逻辑错位或依赖缺失时,问题往往不在模型本身,而在于提示&#x…...

CANN/asc-devkit:UB到GM数据拷贝函数
asc_copy_ub2gm 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode…...

Wot Design Uni 文件上传组件:如何实现异步上传的强大功能
Wot Design Uni 文件上传组件:如何实现异步上传的强大功能 【免费下载链接】wot-design-uni 一个基于Vue3TS开发的uni-app组件库,提供70高质量组件,支持暗黑模式、国际化和自定义主题。 项目地址: https://gitcode.com/gh_mirrors/wo/wot-d…...
)
Java 面向对象 - 触发类的初始化,执行其中的 static 块(包含不会触发初始化的情况)
触发类的初始化,执行其中的 static 块 访问 static 字段 public class SomeClass {static {System.out.println("static block executed");}public static int num 100; }int num SomeClass.num;访问 static 方法,可以使用空方法(…...

Java学习笔记——DAY3
目录 1、Java方法 2、方法的定义 3、方法调用 4、方法的重载 5、命令行传参 6、可变参数 7、递归 1、Java方法 Java方法是语句的集合,它们在一块执行一个功能。 方法是解决一类问题的步骤的有序集合方法包含与类或对象中方法在程序中被创建,在其…...

G-Helper:华硕笔记本性能控制的终极轻量级替代方案
G-Helper:华硕笔记本性能控制的终极轻量级替代方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exper…...

C++ 重载与重写的区别与实现
1 . 前言在面向对象语言中,经常提到重载与重写,以下内容直观描述两者差异成员函数被重载的特征: (1)相同的范围(在同一个类中); (2)函数名字相同;…...