阿里面试:让代码不腐烂,DDD是怎么做的?
说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题:
谈谈你的高并发落地经验?
谈谈你对DDD的理解?
如何保证RPC代码不会腐烂,升级能力强?
最近有小伙伴在字节,又遇到了相关的面试题。小伙伴懵了, 他从来没有用过DDD,面挂了。关于DDD,尼恩之前给大家梳理过一篇很全的文章: 阿里一面:谈一下你对DDD的理解?2W字,帮你实现DDD自由
但是尼恩的文章, 太过理论化,不适合刚入门的人员。所以,尼恩也在不断的为大家找更好的学习资料。
前段时间,尼恩在阿里的技术公众号上看到了一篇文章《殷浩详解DDD:领域层设计规范》 作者是阿里 技术大佬殷浩,非常适合于初学者入门,同时也足够的有深度。
美中不足的是, 殷浩那篇文章的行文风格,对初学者不太友好, 尼恩刚开始看的时候,也比较晦涩。
于是,尼恩在读的过程中,把那些晦涩的内容,给大家用尼恩的语言, 浅化了一下, 这样大家更容易懂。
本着技术学习、技术交流的目的,这里,把尼恩修改过的 《殷浩详解DDD:领域层设计规范》,通过尼恩的公众号《技术自由圈》发布出来。
特别声明,由于没有殷浩同学的联系方式,这里没有找殷浩的授权,
如果殷浩同学或者阿里技术公众号不同意我的修改,不同意我的发布, 我即刻从《技术自由圈》公众号扯下来。
另外, 文章也特别长, 我也特别准备了PDF版本。如果需要尼恩修改过的PDF版本,也可以通过《技术自由圈》公众号找到尼恩来获取。
本文是 《从0到1,带大家精通DDD》系列的第3篇, 第1、2篇的链接地址是:
《阿里DDD大佬:从0到1,带大家精通DDD》
《阿里大佬:DDD 落地两大步骤,以及Repository核心模式》
大家可以先看第1篇、第2篇,再来看第3篇,效果更佳。
另外,尼恩会结合一个工业级的DDD实操项目,在第34章视频《DDD的顶奢面经》中,给大家彻底介绍一下DDD的实操、COLA 框架、DDD的面试题。
文章目录
- 说在前面
- 代码就变得腐败不堪,咋整?
- 9 个微服务设计模式
- 什么是防腐层
- Anti-corruption layer使用场景
- 防腐层的设计与实现
- 两个上下文相互依赖的简单例子
- 一个简单的防腐层的设计与实现
- 一个简单的防腐层的设计小结
- COLA框架中的防腐层
- 回顾COLA分层架构
- start层
- adapter层
- cilent层
- 什么是CQRS (Command 与 Query 分离)
- app层
- domain层
- infrastructure层
- COLA4.0分层总结
- COLA框架中的防腐层
- 对微服务中的远程调用进行防腐烂
- 设计gateway登录网关,防止rpc腐烂
- Feign的异常统一处理
- 未完待续,尼恩说在最后
- 推荐阅读
代码就变得腐败不堪,咋整?
一份业务代码,尤其是互联网业务代码,都有哪些特点? 大概有这几点:
- 互联网业务迭代快,工期紧,导致代码结构混乱,几乎没有代码注释和文档。
- 互联网人员变动频繁,很容易接手别人的老项目,新人根本没时间吃透代码结构,紧迫的工期又只能让屎山越堆越大。
- 多人一起开发,每个人的编码习惯不同,工具类代码各用个的,业务命名也经常冲突,影响效率。
- 大部分团队几乎没有时间做代码重构,任由代码腐烂。
每当我们新启动一个代码仓库,都是信心满满,结构整洁。但是时间越往后,代码就变得腐败不堪,技术债务越来越庞大。
这种情况有解决方案吗?也是有的:
- 小组内定期做代码重构,解决技术债务。
- 组内设计完善的应用架构,让代码的腐烂来得慢一些。(当然很难做到完全不腐烂)
- 设计尽量简单,让不同层级的开发都能快速看懂并上手开发,而不是在一堆复杂的没人看懂的代码上堆更多的屎山。
尼恩曾经见过一个极端的反面案例:
- 10年多时间, 衍生出 50多个不同的版本, 每个版本80%的功能相同,但是代码各种冲突,没有合并
- 10年多时间,经历过至少 5次推倒重来, 基本换一个领导,恨不得推导重来一次, 感觉老的版本都是不行,只有自己设计的才好
- 5次推倒重来,每次都是 风风火火/加班到进ICU, 投入了大量的人力/财力。其实大多是重复投入、重复建设
- 可谓, 一将不才累死三军,
- 所以,从项目角度来说,一个优秀的架构,对项目是多么重要;从人才角度来说, 一个优秀的架构师,对一个团队来说是多么的重要
如何让你的代码腐烂的尽可能慢一些,让团队的开发效率尽可能快一些。这里有一个核心的设计模式:放腐层(Anti-corruption layer)模式。
9 个微服务设计模式
2017年,微软 AzureCAT 模式和实践团队在 Azure 架构中心发布了 9 个新的微服务设计模式,文中提到的9 个模式包括:
- 外交官模式(Ambassador)
- 放腐层(Anti-corruption layer)
- 后端服务前端(Backends for Frontends)
- 舱壁模式(Bulkhead)
- 网关聚合(Gateway Aggregation)
- 网关卸载(Gateway Offloading)
- 网关路由(Gateway Routing)
- 边车模式(Sidecar)
- 绞杀者模式(Strangler)。
微软团队在 Azure 架构中心文章,也给出了这些模式解决的问题、方案、使用场景、实现考量等。
微软团队称这 9 个模式有助于更好的设计和实现微服务,同时看到业界对微服务的兴趣日渐增长,所以也特意将这些模式记录并发布。
下图是微软团队建议如何在微服务架构中使用这些模式:
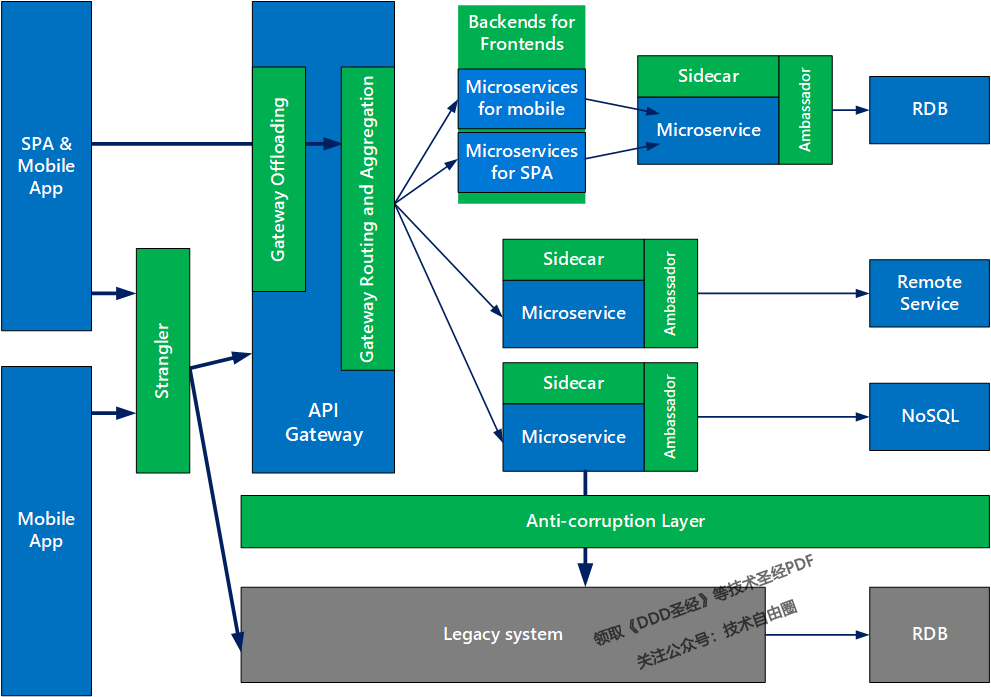
微软:微服务设计模式
注意:请点击图像以查看清晰的视图!
这些模式绝大多数也是目前业界比较常用的模式,如:
- 外交官模式(Ambassador)可以用与语言无关的方式处理常见的客户端连接任务,如监视,日志记录,路由和安全性(如 TLS)。
- 防腐层(Anti-corruption layer)介于新应用和遗留应用之间,用于确保新应用的设计不受遗留应用的限制。
- 后端服务前端(Backends for Frontends)为不同类型的客户端(如桌面和移动设备)创建单独的后端服务。这样,单个后端服务就不需要处理各种客户端类型的冲突请求。这种模式可以通过分离客户端特定的关注来帮助保持每个微服务的简单性。
- 舱壁模式(Bulkhead)隔离了每个工作负载或服务的关键资源,如连接池、内存和 CPU。使用舱壁避免了单个工作负载(或服务)消耗掉所有资源,从而导致其他服务出现故障的场景。这种模式主要是通过防止由一个服务引起的级联故障来增加系统的弹性。
- 网关聚合(Gateway Aggregation)将对多个单独微服务的请求聚合成单个请求,从而减少消费者和服务之间过多的请求。
- 边车模式(Sidecar)将应用程序的辅助组件部署为单独的容器或进程以提供隔离和封装。
设计模式是对针对某一问题域的解决方案,它的出现也代表了工程化的可能。
随着微服务在业界的广泛实践,相信这个领域将会走向成熟和稳定。
这里,主要介绍反腐层(Anti-corruption layer)模式
什么是防腐层
**反腐层(Anti-corruption layer)**模式最先由 **Eric Evans 在 Domain-Driven Design(域驱动的设计)**中描述。
在许多情况下,我们的系统需要依赖其他系统,但被依赖的系统可能具有不合理的数据结构、API、协议或技术实现。如果我们强烈依赖外部系统,就会导致我们的系统受到**“腐蚀”**。
在这种情况下,通过引入防腐层,可以有效地隔离外部依赖和内部逻辑,无论外部如何变化,内部代码尽可能保持不变。
反腐层(Anti-corruption layer,简称 ACL)介于新应用和旧应用之间,用于确保新应用的设计不受老应用的限制。是一种在不同应用间转换的机制。
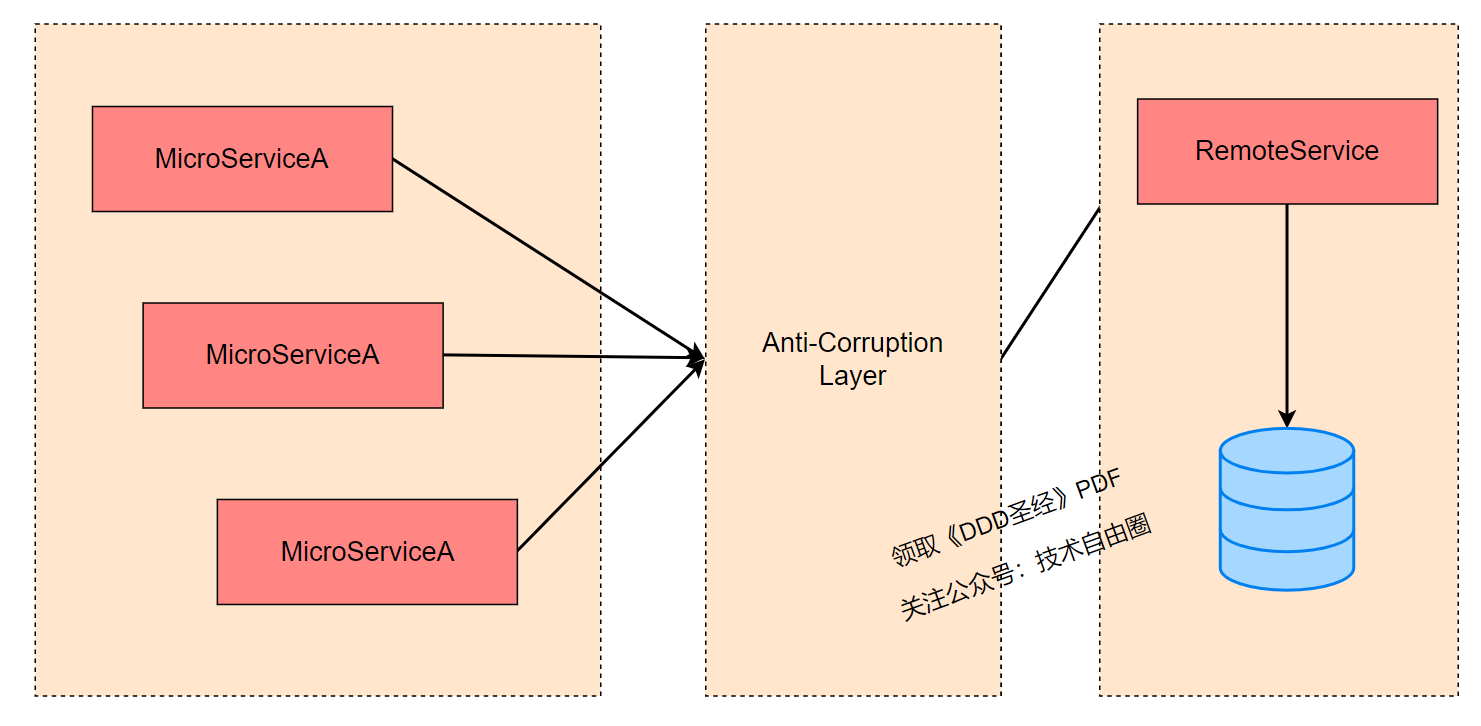
注意:请点击图像以查看清晰的视图!
创建一个反腐层,以根据客户端自己的域模型为客户提供功能。
反腐层通过其现有接口与另一个系统进行通信,几乎不需要对其进行任何修改。
反腐层是将一个域映射到另一个域,这样使用第二个域的服务就不必被第一个域的概念“破坏”。因此,反腐层隔离不仅是为了保护你的系统免受异常代码的侵害,还在于分离不同的域并确保它们在将来保持分离。
该层可作为应用程序内的组件或作为独立服务实现。
防腐层不仅仅是一层简单的调用封装,在实际开发中,ACL可以提供更多强大的功能:
-
适配器:
很多时候外部依赖的数据、接口和协议并不符合内部规范,通过适配器模式,可以将数据转化逻辑封装到ACL内部,降低对业务代码的侵入。
-
缓存:
对于频繁调用且数据变更不频繁的外部依赖,通过在ACL里嵌入缓存逻辑,能够有效的降低对于外部依赖的请求压力。同时,很多时候缓存逻辑是写在业务代码里的,通过将缓存逻辑嵌入ACL,能够降低业务代码的复杂度。
-
兜底:
如果外部依赖的稳定性较差,提高系统稳定性的策略之一是通过ACL充当兜底,例如在外部依赖出问题时,返回最近一次成功的缓存或业务兜底数据。这种兜底逻辑通常复杂,如果散布在核心业务代码中,会难以维护。通过集中在ACL中,更容易进行测试和修改。
-
易于测试:
ACL的接口类能够很容易的实现Mock或Stub,以便于单元测试。
-
功能开关:
有时候,我们希望在某些场景下启用或禁用某个接口的功能,或者让某个接口返回特定值。
我们可以在ACL中配置功能开关,而不会影响真实的业务代码。
Anti-corruption layer使用场景
在以下情况下使用此模式:
迁移计划为发生在多个阶段,但是新旧系统之间的集成需要维护
很多人一看到旧系统就想要赶快替换掉他,但是请不要急著想著去替换旧系统,因为这条路充满困难与失败,而且 旧系统通常反而是系统目前最赚钱的部分。更好的做法是在使用旧系统时包上一层 ACL,让你的开发不受影响,甚至可以一点一滴的替换旧系统的功能,达到即使不影响目前功能下也能开发新功能,达到重构的效果!
两个或更多个子系统具有不同的语义,需要对外部上下文的访问进行一次转义
例如:对接第三方系統。缴费软件中的收银台系统,需要对接不同的支付方式(支付宝、各个银行、信用卡等),这是就需要收银台系统充当一个Anti-corruption layer,将用户的缴费支付信息,转换成各个三方支付系统需要的数据格式。
如果内部多个组件对外部系统需要访问,那么可以考虑将其放到通用上下文中。
例如:我们有一个抽奖平台,包含有现金券、折扣券、外卖券、出行券等组件,但他们都需要对接用户信息服务,这时就需要在抽奖平台中,搭建一个Anti-corruption layer,作为抽奖平台对接用户信息的通用适配层。
如果新旧系统之间没有重要的语义差异,则此模式可能不适合。
防腐层的设计与实现
在应用服务中,经常需要调用外部服务接口来实现某些业务功能,这就在代码层面引入了对外部系统的依赖。这里就需要用到防腐层,隔离 外部变化。
两个上下文相互依赖的简单例子
举个例子,有 A 和 B 两个上下文,
其中 B 通过开放主机服务提供对外访问,A 上下文请求 B 上下文的 RPC 接口时,B 将会返回一个模型BView,如果 A 直接在领域模型中引用 B 返回的模型BView,将会早上 A 上下文被污染。
B 上下文对外提供的 RPC 接口:
/*** B上下文对外暴露的查询服务,查询*/
public interface BRpcQueryService{Response<BView> query(Query query);
}
public class BView{private Integer property1;private String property2;//省略其他属性以及get/set方法
}
当 A 调用ContextBQueryService 的query方法,将会得到BView这个类。
如果 A 的领域模型直接引用了 BView,将会导致 A 自己的上下文被污染,容易引发很多问题:
-
类级别的改变:随着 B 上下文的迭代,可能 BView 这个类路径、名称、属性名等都会改变。
举个例子,B 上下文可能会进行系统重构,重构时会重新发布一个新的 jar 包,要求调用方切换到的新的 jar 包上,这个情况在我实际工作中遇到的不少。如果直接将 BView 引入到本地上下文中,A 将需要进行大量的改动,并且需要大量回归测试才能确保切换无风险。
-
属性级别的:BView 中的某个属性的类型与 A 上下文中对应的属性类型并不一致,因而使用时必须进行强转;BView 中某个字段的名称与本地上下文某个字段的名称相同,调用时容易引起歧义,例如我在工作中遇到过外部接口返回的模型中有个
source字段,本地领域模型中也有一个source字段,但是两者的含义并不一致。
当有多个服务依赖此外部接口时,全部的被依赖服务,都需要迁移和改造,这种的成本将会巨大。
同时,外部依赖的兜底、限流和熔断策略也会受到影响。
在复杂系统中,我们应该尽量避免自己的代码因为外部系统的变化而修改。
那么如何实现对外部系统的隔离呢?答案就是引入防腐层(Anti-Corruption Layer,简称ACL)。
一个简单的防腐层的设计与实现
防腐层的设计和实现并不难,主要注意一下要点:
- 要点1:防腐层方法返回值必须是本地上下文的值对象或者基本数据类型,不得返回外部上下文的模型
伪代码如下:
public class BContextGateway{private BRpcQueryService bRpc;public SomeValue queryFromBContext(Prams params){//封装查询报文Query query=this.fromPrams(params);//执行查询Response<BView> bResponse=bRpc.query(query);//忽略判空、查询失败等逻辑BView bView=bResponse.getData();//重点:封装本地上下文的值对象进行返回return new SomeValue(bView.getProperty1());}
}
另外,防腐层方法要捕获外部异常,并抛出的本地上下文自定义的异常, 伪代码如下:
public class BContextGateway{private BRpcQueryService bRpc;public SomeValue queryFromBContext(Prams params){//封转查询报文Query query=this.fromPrams(params);Response<BView> bResponse;try{//查询结果bResponse=bRpc.query(query);}catch(Exception e){//重点:捕获异常,并抛出本地自定义的异常throw new QueryContextBException();}//省略其他逻辑}
}
-
要点2:外部上下文返回的错误码,应该转化成本地异常进行抛出,不应该将错误码返回给上层,
要点2伪代码如下:
public class BContextGateway{private BRpcQueryService bRpc;public SomeValue queryFromBContext(Prams params){//封转查询报文Query query=this.fromPrams(params);//执行查询Response<BView> bResponse=bRpc.query(query);//重点:根据错误码时抛出本地自定义的异常if("1".equals(bResponse.getCode())){throw new QueryContextBException();}//忽略其他逻辑}
}
-
要点3:按需返回,只返回需要的字段或者数据类型。
只返回需要的字段,这个很好理解不用过多解释;只返回需要的数据类型。
举个例子,外部上下文可能返回字符串的 0 和 1 代表 false 和 true,但是我们本地是使用布尔类型的,因此要在防腐层转换好再返回。伪代码如下:
public class BContextGateway{private BRpcQueryService bRpc;public Boolean checkFromBContext(Prams params){//封转查询报文Query query=this.fromPrams(params);//执行查询Response<Integer> bResponse=bRpc.check(query);//重点:查询失败,根据错误码时抛出本地自定义的异常if("ERROR".equals(bResponse.getCode())){throw new QueryContextBException();}//转换成需要的布尔类型进行返回return "1".equals(bResponse.getData());}
}
这样,经过ACL改造后,ApplicationService的代码已不再直接依赖外部的类和方法,而是依赖我们自己内部定义的值类和接口。
如果未来外部服务发生任何变化,只需修改Facade类和数据转换逻辑,而不需要修改ApplicationService的逻辑。
一个简单的防腐层的设计小结
在没有防腐层ACL的情况下,系统需要直接依赖外部对象和外部调用接口,调用逻辑如下:
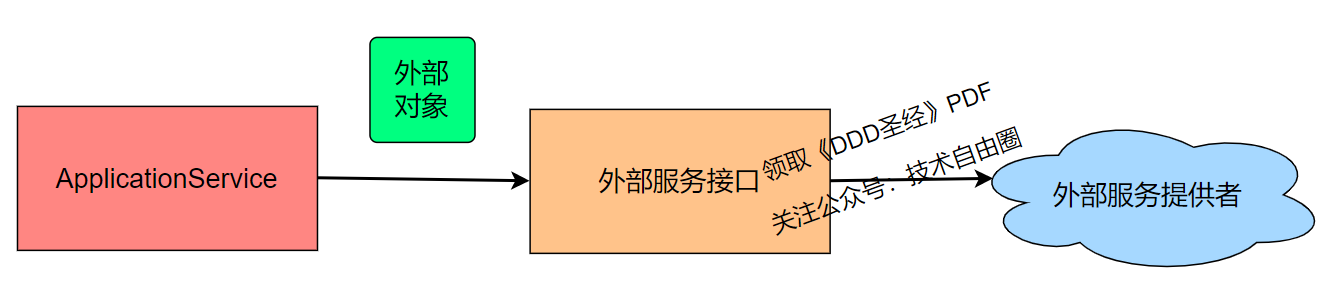
注意:请点击图像以查看清晰的视图!
而有了防腐层ACL后,系统只需要依赖内部的值类和接口,调用逻辑如下:

注意:请点击图像以查看清晰的视图!
COLA框架中的防腐层
**COLA提供了一整套代码架构,拿来即用。**COLA 架构是阿里发布的一套DDD脚手架,是一个整洁的,面向对象的,分层的,可扩展的应用架构,可以帮助降低复杂应用场景的系统熵值,提升系统开发和运维效率。
不管是传统的分层架构、六边形架构、还是洋葱架构,都提倡以业务为核心,解耦外部依赖,分离业务复杂度和技术复杂度等,COLA 架构在此基础上融合了 CQRS、DDD、SOLID 等设计思想,形成一套可落地的应用架构。
COLA中包含了很多架构设计思想,包括讨论度很高的领域驱动设计DDD等。
首先主要谈谈COLA架构,COLA的官方博文中是这么介绍的:
在平时我们的业务开发中,大部分的系统都需要:
- 接收request,响应response;
- 做业务逻辑处理,像校验参数,状态流转,业务计算等等;
- 和外部系统有联动,像数据库,微服务,搜索引擎等;
正是有这样的共性存在,才会有很多普适的架构思想出现,比如分层架构、六边形架构、洋葱圈架构、整洁架构(Clean Architecture)、DDD架构等等。
这些应用架构思想虽然很好,但我们很多同学还是“不讲Co德,明白了很多道理,可还是过不好这一生”。问题就在于缺乏实践和指导。COLA的意义就在于,他不仅是思想,还提供了可落地的实践。应该是为数不多的应用架构层面的开源软件。
尼恩会结合一个工业级的DDD实操项目,在第34章视频中,给大家彻底介绍一个 COLA 框架。

回顾COLA分层架构
先来看两张官方介绍图
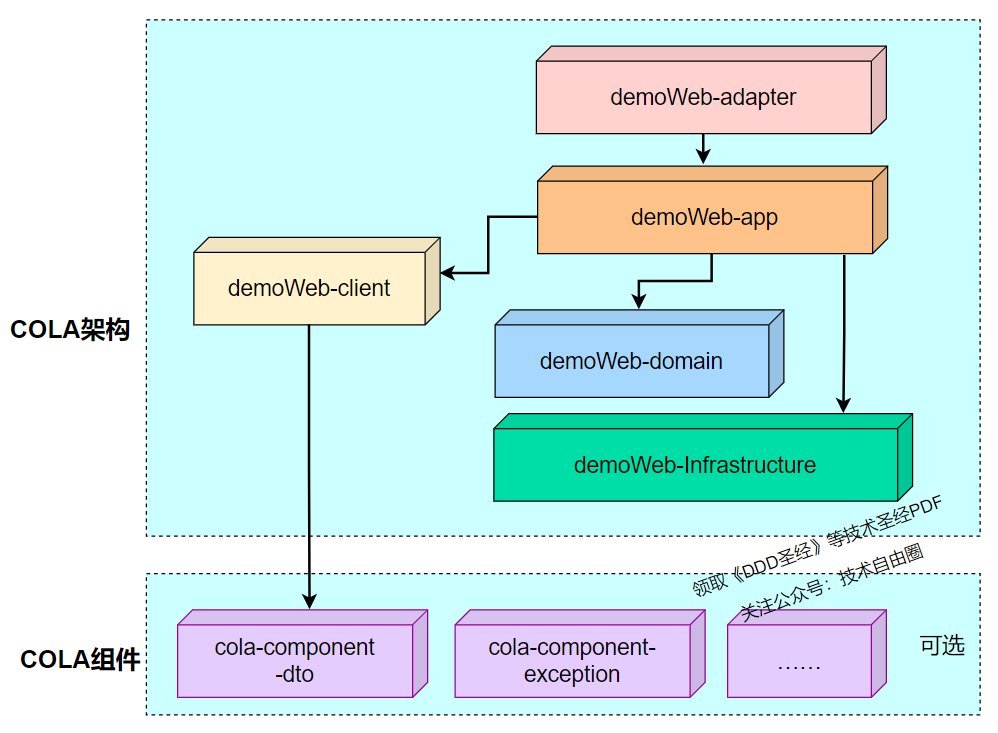
注意:请点击图像以查看清晰的视图!
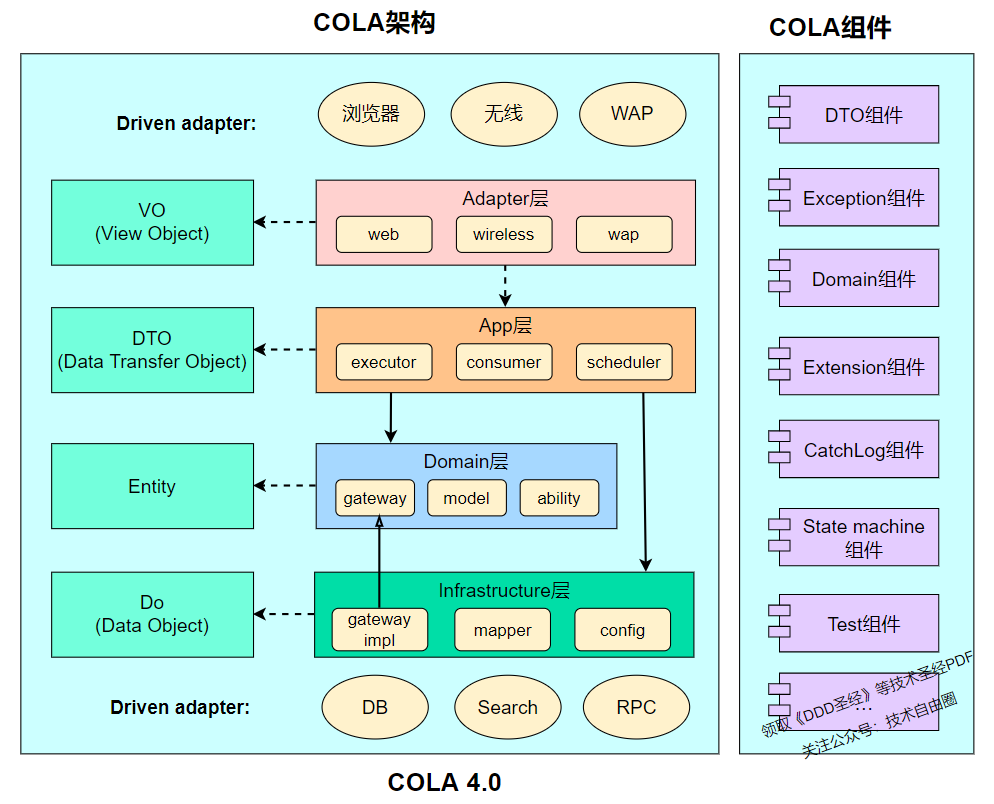
注意:请点击图像以查看清晰的视图!
其次,还有一个官方的表格,介绍了COLA中每个层的命名和含义:
| 层次 | 包名 | 功能 | 必选 |
|---|---|---|---|
| Adapter层 | web | 处理页面请求的Controller | 否 |
| Adapter层 | wireless | 处理无线端的适配 | 否 |
| Adapter层 | wap | 处理wap端的适配 | 否 |
| App层 | executor | 处理request,包括command和query | 是 |
| App层 | consumer | 处理外部message | 否 |
| App层 | scheduler | 处理定时任务 | 否 |
| Domain层 | model | 领域模型 | 否 |
| Domain层 | ability | 领域能力,包括DomainService | 否 |
| Domain层 | gateway | 领域网关,解耦利器 | 是 |
| Infra层 | gatewayimpl | 领域网关实现 | 是 |
| Infra层 | mapper | ibatis数据库映射 | 否 |
| Infra层 | config | 配置信息 | 否 |
| Client SDK | api | 服务对外透出的API | 是 |
| Client SDK | dto | 服务对外的DTO | 是 |
这两张图和一个表格已经把整个COLA架构的绝大部分内容展现给了大家,但是一下子这么多信息量可能很难消化。
COLA整个示例架构项目是一个Maven父子结构,那我们就从父模块一个个好好过一遍。
首先父模块的pom.xml包含了如下子模块:
<modules><module>demo-web-client</module><module>demo-web-adapter</module><module>demo-web-app</module><module>demo-web-domain</module><module>demo-web-infrastructure</module><module>start</module>
</modules>
start层
COLA 的start模块作为整个应用的启动模块(通常是一个SpringBoot应用),只承担启动项目和全局相关配置项的存放职责。
COLA 的start模块代码目录如下:
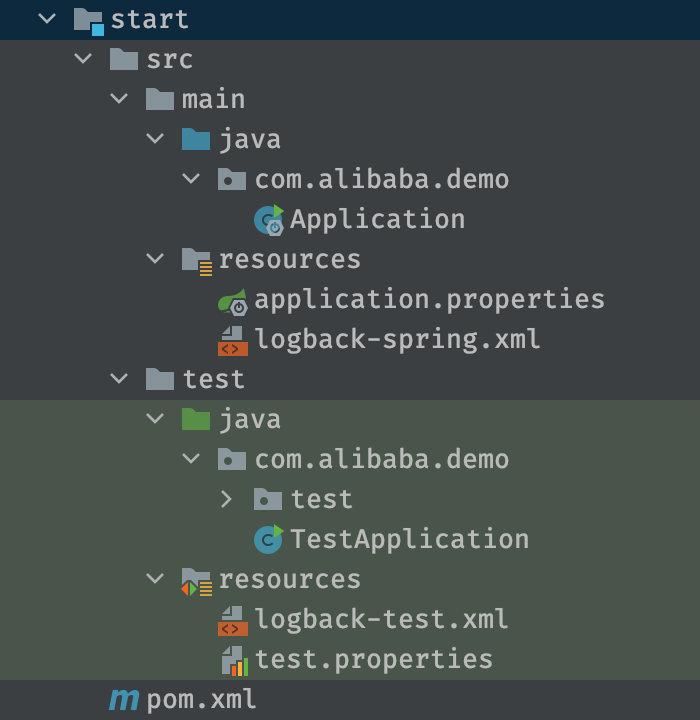
将启动独立出来,好处是清晰简洁,也能让新人一眼就看出如何运行项目,以及项目的一些基础依赖。
adapter层
接下来就是 demo-web-adapter模块,这里包括平时我们用的controller层(对于Web应用来说),换汤不换药。
只是在定位上,比 web controller 的 层次更高,包括 web 的接口,还包括 mobile (for APP),wap (for mobile html)等等
为啥不叫 Controller?
Controller这个名字主要是来自于MVC,因为是MVC,所以自带了Web应用的烙印。
然而,随着mobile的兴起,现在很少有应用仅仅只支持Web端,通常的标配是Web,Mobile,WAP三端都要支持。

cilent层
有了我们说的“controller”层,接下来有的小伙伴肯定就会想,是不是service层啦。
是,也不是。
传统的MVC应用中,一个service层给controller层调用。
service层分为 service interface + service implement , controller 依赖的是 mvc service interface , mvc service implement 的实例,由 spring 容器完成注入。
所以在COLA中,你的adapter层 (/mvc controller层),调用了client层,client层中就是你服务接口的定义,也就是mvc service interface。

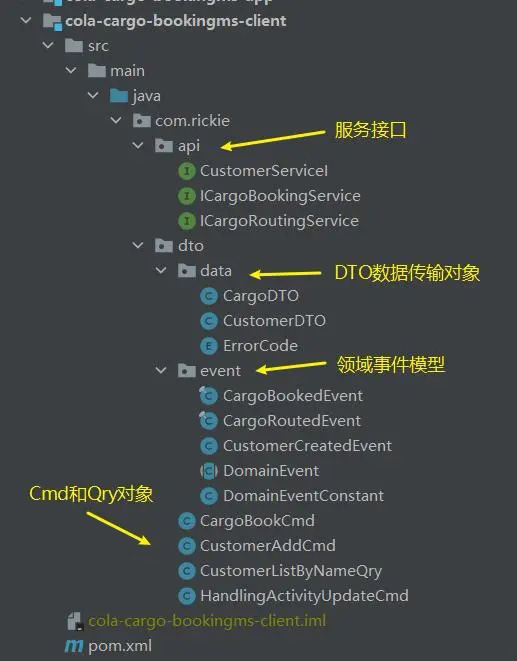
从上图中可以看到,client包里有:
- api文件夹:存放服务接口定义
- dto文件夹:存放传输实体
注意,这里只是服务接口定义,而不是服务层的具体实现,所以在adapter层中,调用的其实是client层的接口:
@RestController
public class CustomerController {@Autowiredprivate CustomerServiceI customerService;@GetMapping(value = "/customer")public MultiResponse<CustomerDTO> listCustomerByName(@RequestParam(required = false) String name){CustomerListByNameQry customerListByNameQry = new CustomerListByNameQry();customerListByNameQry.setName(name);return customerService.listByName(customerListByNameQry);}}
而最终接口的具体实现逻辑( mvc service implement 的实例)放到了app层。
@Service
@CatchAndLog
public class CustomerServiceImpl implements CustomerServiceI {@Resourceprivate CustomerListByNameQryExe customerListByNameQryExe;@Overridepublic MultiResponse<CustomerDTO> listByName(CustomerListByNameQry customerListByNameQry) {return customerListByNameQryExe.execute(customerListByNameQry);}
}
总之, Client层:包含的代码应该是常见的服务接口Facade和DTO数据传输对象,如API、DTO、领域事件、Command和Query对象等等。
一个更加复杂的例子如下:
什么是CQRS (Command 与 Query 分离)
CQRS(Command Query Responsibility Segregation)是一种简单的设计模式。
CQRS衍生与CQS,即命令和查询分离,CQS是由Bertrand Meyer所设计。
按照这一设计概念,系统中的方法应该分为两种:改变状态的命令和返回值的查询。‘
Greg young将引入了这个设计概念,并将其应用于对象或者组件当中,这就是今天所要将的CQRS。
CQRS背后的主要思想是应用程序更改对象或组件状态(Command)应该与获取对象或者组件信息(Query)分开。
具体来说:CQRS(Command Query Responsibility Segregation),Command 与 Query 分离的一种模式。
-
Command:命令则是对会引起数据发生变化操作的总称,即新增,更新,删除这些操作,都是命令
-
Query:查询则不会对数据产生变化的操作,只是按照某些条件查找数据
CQRS 的核心思想是将这两类不同的操作进行分离,可以是两个独立的应用,两个不同的数据源,也可以是同一个应用内的不同接口上。
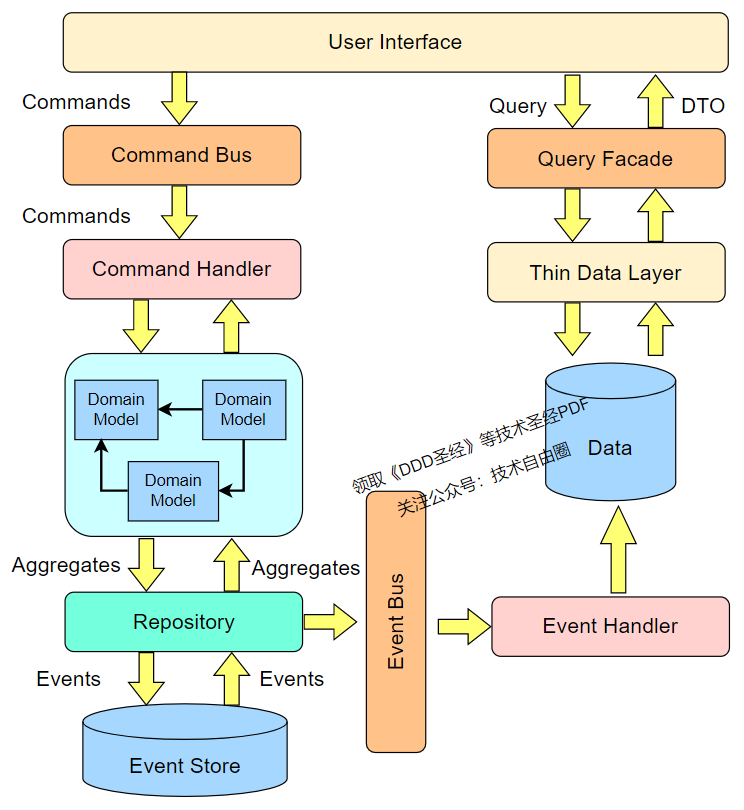
注意:请点击图像以查看清晰的视图!
从上图可看出,把数据的变更通过数据同步到另一个库用来查询数据,其实就是数据异构。
但这不是我们现在需要做的,我们是要利用CQRS的思想解决领域驱动中查询功能实现复杂的问题
CQRS 说白了,就是“数据查询”和“业务操作”分离。
在COLA 4.0之前,还有Command Bus和Query Bus 。Command Bus(命令总线):是一种接收命令并将命令传递给命令处理程序的队列。Query Bus(查询总线):是一种查询命令并将查询传递给查询处理程序的队列。
在COLA 4.0中,已经移除了Command Bus和Query Bus的处理,进一步简化了COLA架构。
app层
接着上面说的,我们的app模块作为服务的实现,存放了各个业务的实现类( mvc service implement ),并且严格按照业务分包,
这里划重点,是先按照业务分包,再按照功能分包的,为何要这么做,后面还会多说两句,先看图:

customer和order分别对应了消费着和订单两个业务子领域。
里面是COLA定义app层下面三种功能:
| App层 | executor | 处理request,包括command和query | 是 |
|---|---|---|---|
| App层 | consumer | 处理外部message | 否 |
| App层 | scheduler | 处理定时任务 | 否 |
可以看到,消息队列的消费者和定时任务,这类平时我们业务开发经常会遇到的场景,也放在app层。
应用层(Application Layer):主要负责获取输入,组装上下文,参数校验,调用领域层做业务处理,如果需要的话,发送消息通知等。
一个更加复杂的(Application Layer)代码结构,大致如下:

domain层
接下来便是domain,也就是领域层,先看一下领域层整体结构:

可以看到,首先是按照不同的领域(customer和order)分包,里面则是三种主要的文件类型:
- 领域实体:实体模型是充血模型,例如官方示例里的Customer.java如下:
@Data
@Entity
public class Customer{private String customerId;private String memberId;private String globalId;private long registeredCapital;private String companyName;private SourceType sourceType;private CompanyType companyType;public Customer() {}public boolean isBigCompany() {return registeredCapital > 10000000; //注册资金大于1000万的是大企业}public boolean isSME() {return registeredCapital > 10000 && registeredCapital < 1000000; //注册资金大于10万小于100万的为中小企业}public void checkConfilict(){//Per different biz, the check policy could be different, if so, use ExtensionPointif("ConflictCompanyName".equals(this.companyName)){throw new BizException(this.companyName+" has already existed, you can not add it");}}
}
- 领域能力:domainservice文件夹下,是领域对外暴露的服务能力,如上图中的CreditChecker
- 领域网关:gateway文件夹下的接口定义,这里的接口你可以粗略的理解成一种SPI,也就是交给infrastructure层去实现的接口。
例如CustomerGateway里定义了接口getByById,要求infrastructure的实现类必须定义如何通过消费者Id获取消费者实体信息,而infrastructure层可以实现任何数据源逻辑,比如,从MySQL获取,从Redis获取,还是从外部API获取等等。
public interface CustomerGateway {public Customer getByById(String customerId);
}
在示例代码的CustomerGatewayImpl(位于infrastructure层)中,CustomerDO(数据库实体)经过MyBatis的查询,转换为了Customer领域实体,进行返回。完成了依赖倒置。
@Component
public class CustomerGatewayImpl implements CustomerGateway {@Autowiredprivate CustomerMapper customerMapper;public Customer getByById(String customerId){CustomerDO customerDO = customerMapper.getById(customerId);//Convert to Customerreturn null;}
}

注意:请点击图像以查看清晰的视图!
infrastructure层
最后是我们的infrastructure也就是基础设施层,
infrastructure层有我们刚才提到的gatewayimpl网关实现,当然,infrastructure层有MyBatis的mapper等数据源的映射和config配置文件。
| Infra层 | gatewayimpl | 网关实现 | 是 |
|---|---|---|---|
| Infra层 | mapper | ibatis数据库映射 | 否 |
| Infra层 | config | 配置信息 | 否 |
COLA4.0分层总结
了解了这个6层,COLA4.0很简单明了,然后,用一段官方介绍博客原文来总结COLA的层级:
1)适配层(Adapter Layer):
负责对前端展示(web,wireless,wap)的路由和适配,对于传统B/S系统而言,adapter就相当于MVC中的controller;
2)应用层(Application Layer):
主要负责获取输入,组装上下文,参数校验,调用领域层做业务处理,如果需要的话,发送消息通知等。层次是开放的,应用层也可以绕过领域层,直接访问基础实施层;
3)领域层(Domain Layer):
主要是封装了核心业务逻辑,并通过领域服务(Domain Service)和领域对象(Domain Entity)的方法对App层提供业务实体和业务逻辑计算。领域是应用的核心,不依赖任何其他层次;
4)基础实施层(Infrastructure Layer):
主要负责技术细节问题的处理,比如数据库的CRUD、搜索引擎、文件系统、分布式服务的RPC等。
COLA框架中的防腐层
领域防腐的重任也落在Infrastructure Layer (基础实施层),外部依赖需要通过gateway的代理和转义,才能被上面的App层和Domain层使用。
对微服务中的远程调用进行防腐烂
在构建微服务时,我们经常需要跨服务调用,比如 登录的时候,需要调用系统服务以获取用户详细信息。
以下是在微服务中使用OpenFeign实现跨服务调用的过程。
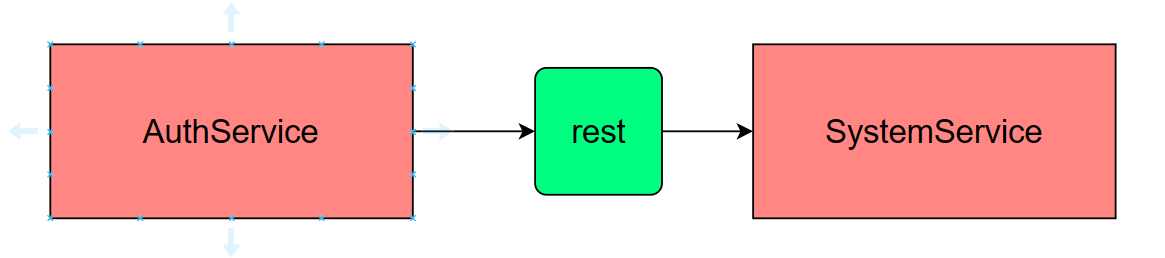
以登录为例,authservice 需要调用 SystemService ,获取用户信息, 两个微服务之间的关系如下:
在咱们的工程代码中,调用的核心链路,大致如下:
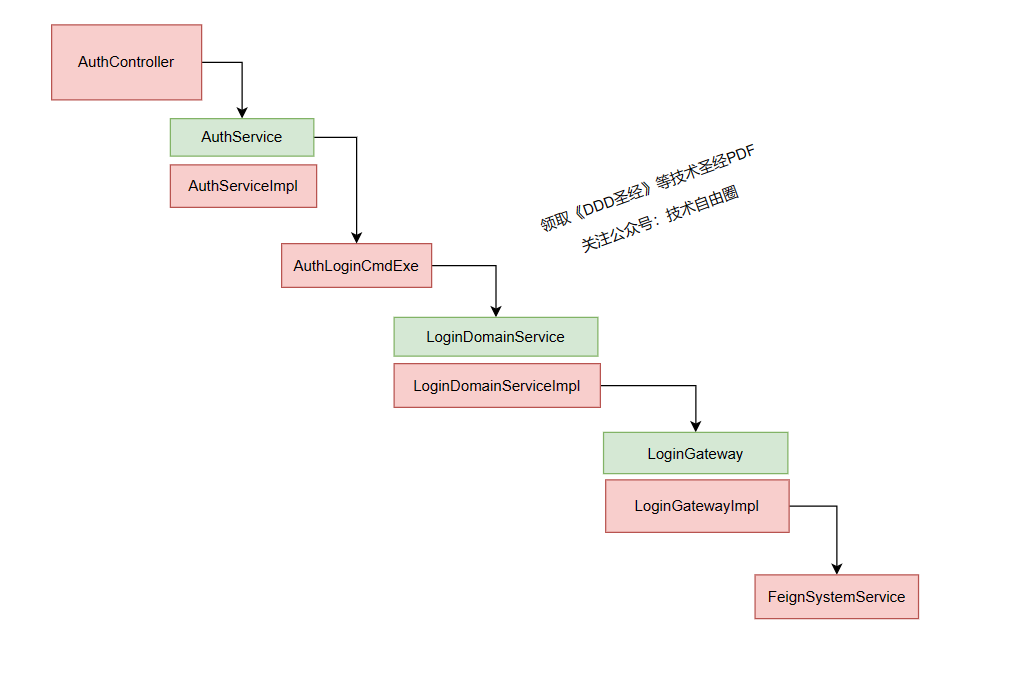
以上链路,是尼恩打断点,通过调用链路,画出来的。
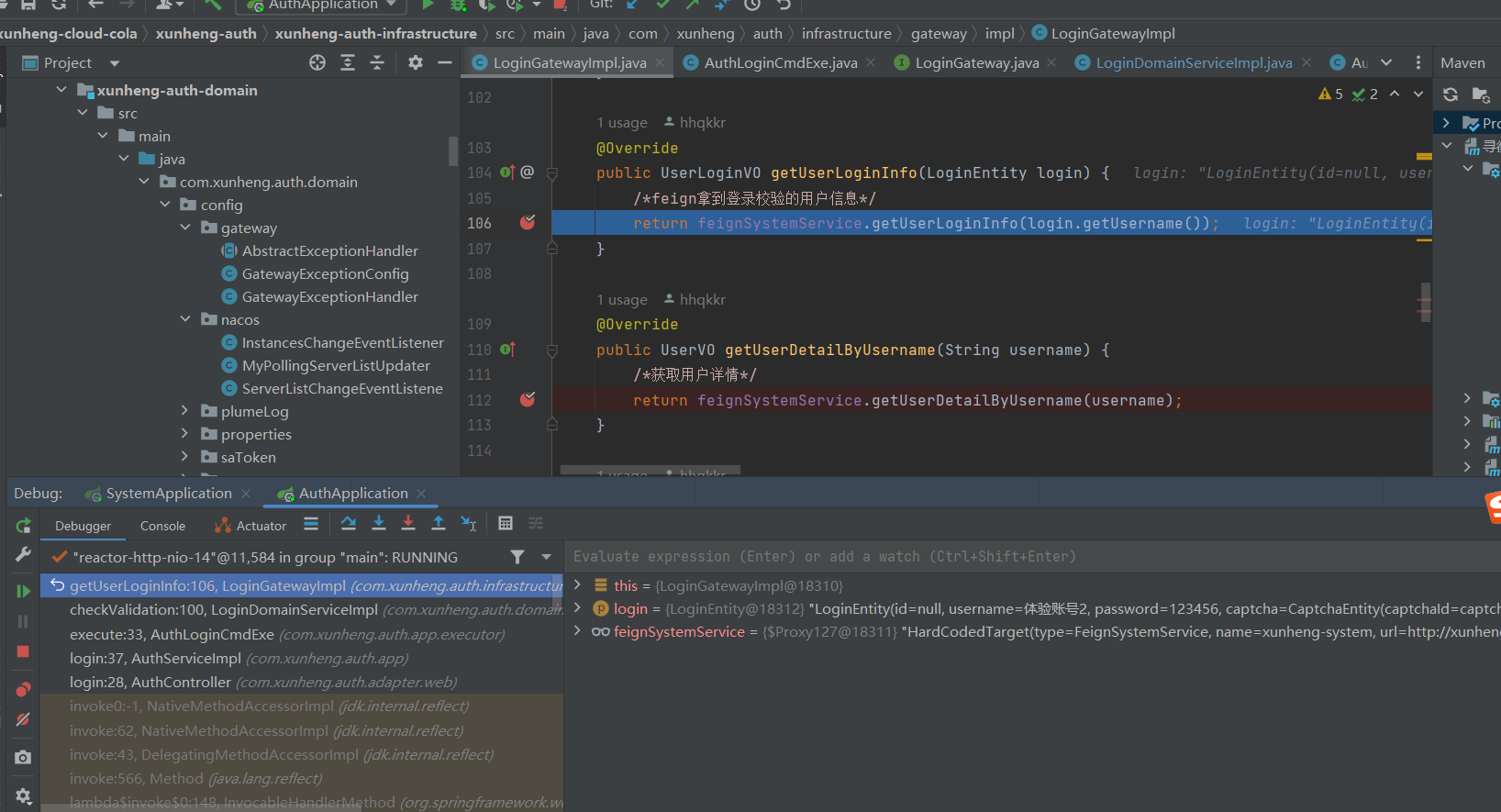
设计gateway登录网关,防止rpc腐烂
在mvc 架构中, 登录服务 LoginDomainServiceImpl ,如果需要通过rpc获取用户信息, 直接注入 Feign的代理客户端stub 对象, 完成RPC远程调用就可以了。
大致的流程如下所示:
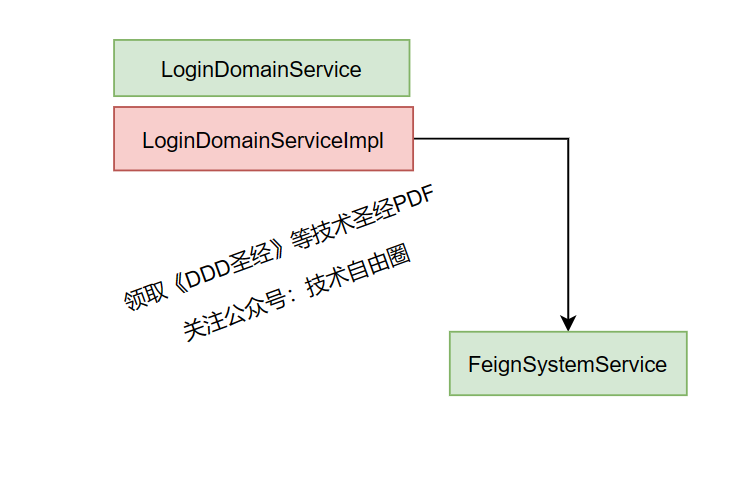
这样就会导致 LoginDomainServiceImpl 领域服务,两个问题:
(1)对 Feign RPC 框架进行强依赖,使得 领域服务 LoginDomainServiceImpl 的代码不利于复用和扩展。
LoginDomainServiceImpl 的代码不是纯业务的, 如果要拿到其他地方复用,发现和现有的 cache、rpc等技术组件强耦合。
(2)也不利于底层技术组件的换代和升级
在尼恩的视频中,介绍过使用Dubbo 替代Feign 进行性能调优的实操, 进行性能10倍以上的调优。
但是,这样就需要去修改 领域服务LoginDomainServiceImpl 的代码, 可能会修改引入, 带来一些潜在问题, 带来很多的不确定性。
两种现象,我们这里统称为RPC腐烂。
解决的措施是: 设计gateway登录网关,封装 RPC组件 , 隔离特定的RPC 框架, 防止rpc腐烂。
大致的流程如下所示:
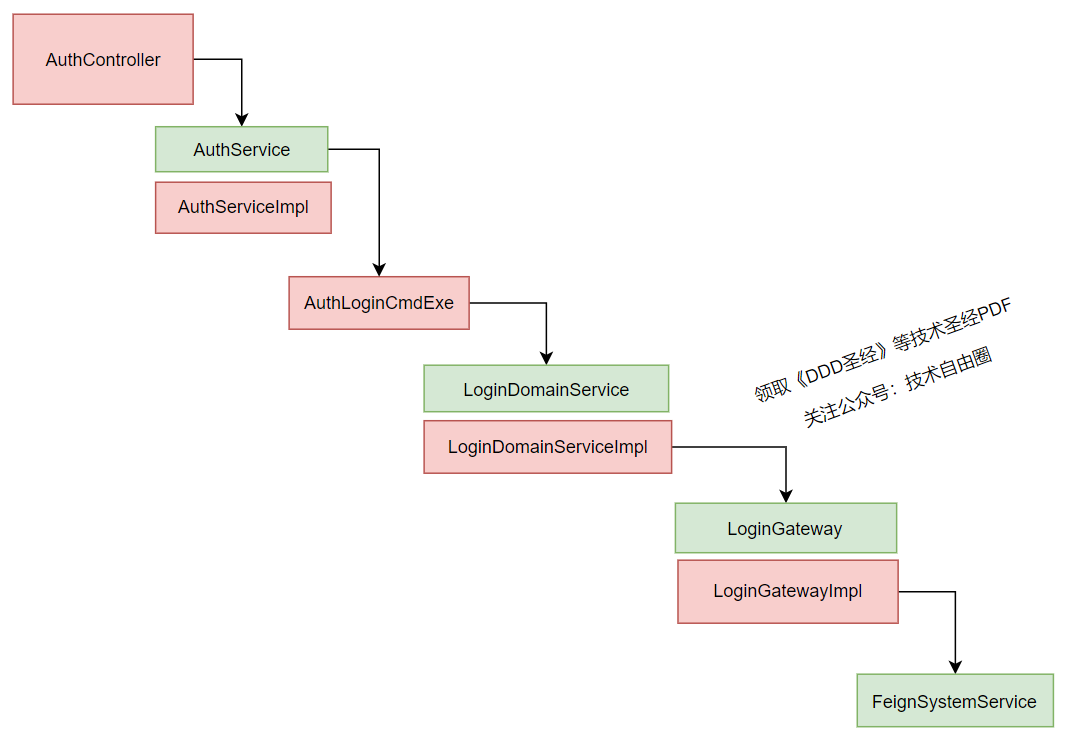
在代码维度, 是 服务层依赖 领域 网关
在代码维度, 领域 网关 依赖 Feign 组件

理论上,为了彻底解耦, 我们需要遵循上述ACL的实现逻辑,gateway 内部 进行 数据的转换。
然而,在实际开发中,由于是内部系统,差异性不太明显,通常可以直接使用OpenFeign进行远程调用,忽略Facade定义和内部类转换的过程。
Feign的异常统一处理
在使用OpenFeign进行远程调用时,如果HTTP状态码为非200,OpenFeign会触发异常解析并进入默认的异常解码器feign.codec.ErrorDecoder,将业务异常包装成FeignException。
此时,如果不做任何处理,调用时可以返回的消息会变成FeignException的消息体,如下所示:

显然,这个包装后的异常我们不需要,应该直接将捕获到的生产者的业务异常抛给前端。
那么,如何解决这个问题呢?
可以通过重写OpenFeign的默认异常解码器来实现,代码如下:
@Slf4j
public class FeignClientErrorDecoder implements ErrorDecoder {@Overridepublic Exception decode(String s, Response response) {log.error("捕获到fegin服务端内部异常");if(response.status() != HttpStatus.OK.value()){if(response.status() == HttpStatus.SERVICE_UNAVAILABLE.value()){String errContent;GlobalException exception = new GlobalException("内部请求异常");try {errContent = Util.toString(response.body().asReader());if(!StringUtils.isEmpty(errContent)){errContent = errContent.replaceAll("\t","").replaceAll("\n","");JSONObject errResp = JSONObject.parseObject(errContent);String errMessage = errResp.getString("message");exception = new GlobalException(errMessage);}}catch (Exception e){log.error("feign处理异常错误",e);}return exception;}}return new GlobalException("未知错误!");}
}
此异常解码器直接将异常转化为自定义的GlobalException,表示远程调用异常。
当然,还需要在配置类中注入此异常解码器。
@Slf4j
@Configuration
public class FeignConfig {@Beanpublic Request.Options options(){return new Request.Options(5000,10000);}@Beanpublic Logger.Level feignLoggerLevel(){return Logger.Level.FULL;}@Beanpublic ErrorDecoder errorDecoder() {return new FeignClientErrorDecoder();}@Beanpublic FeignAuthInterceptor feignAuthRequestInterceptor(){return new FeignAuthInterceptor();}
}
当然,可能有许多模块都需要远程调用,我们可以将上述内容构建成一个通用的Starter模块,以便其他业务模块共享。
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\com.xunheng.feign.config.FeignConfig,\com.xunheng.feign.config.FeignClientErrorDecoder,\com.xunheng.feign.interceptor.FeignAuthInterceptor
未完待续,尼恩说在最后
DDD 面试题,是非常常见的面试题。
DDD的学习材料, 汗牛塞屋,又缺乏经典。
《殷浩详解DDD:领域层设计规范》做到从0到1带大家精通DDD,非常难得。
这里,把尼恩修改过的 《殷浩详解DDD:领域层设计规范》,通过尼恩的公众号《技术自由圈》发布出来。
大家面试的时候, 可以参考以上的内容去组织答案,如果大家能做到对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。
另外在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,并且在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
当然,关于DDD,尼恩即将给大家发布一波视频 《第34章:DDD的顶奢面经》。
推荐阅读
《百亿级访问量,如何做缓存架构设计》
《多级缓存 架构设计》
《消息推送 架构设计》
《阿里2面:你们部署多少节点?1000W并发,当如何部署?》
《美团2面:5个9高可用99.999%,如何实现?》
《网易一面:单节点2000Wtps,Kafka怎么做的?》
《字节一面:事务补偿和事务重试,关系是什么?》
《网易一面:25Wqps高吞吐写Mysql,100W数据4秒写完,如何实现?》
《亿级短视频,如何架构?》
《炸裂,靠“吹牛”过京东一面,月薪40K》
《太猛了,靠“吹牛”过顺丰一面,月薪30K》
《炸裂了…京东一面索命40问,过了就50W+》
《问麻了…阿里一面索命27问,过了就60W+》
《百度狂问3小时,大厂offer到手,小伙真狠!》
《饿了么太狠:面个高级Java,抖这多硬活、狠活》
《字节狂问一小时,小伙offer到手,太狠了!》
《收个滴滴Offer:从小伙三面经历,看看需要学点啥?》
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓
相关文章:
阿里面试:让代码不腐烂,DDD是怎么做的?
说在前面 在40岁老架构师 尼恩的读者交流群(50)中,最近有小伙伴拿到了一线互联网企业如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题: 谈谈你的高并发落地经验? 谈谈你对DDD的理解…...

NoSQL数据库使用场景以及架构介绍
文章目录 一. 什么是NoSQL?二. NoSQL分类三. NoSQL与关系数据库有什么区别四. NoSQL主要优势和缺点五. NoSQL体系框架 其它相关推荐: 系统架构之微服务架构 系统架构设计之微内核架构 鸿蒙操作系统架构 架构设计之大数据架构(Lambda架构、Kap…...

RFID系统提升物流信息管理效率应用解决方案
一、物流仓储管理方法 1、在仓库的进出口处安装RFID读写器,当粘贴RFID标签的电动叉车和货物进入装载区时,RFID读写器会自动检索并记录信息,当它们离开物流配送中心时,入口处的RFID读写器会读取标签信息,并生成出货单&…...
ONNX的结构与转换
ONNX的结构与转换 1. 背景2. ONNX结构分析与修改工具2.1. ONNX结构分析2.2. ONNX的兼容性问题2.3. 修改ONNX模型 3. 各大深度学习框架如何转换到ONNX?3.1. MXNet转换ONNX3.2. TensorFlow模型转ONNX3.3. PyTorch模型转ONNX3.4. PaddlePaddle模型转ONNX3.4.1. 简介3.4…...

vue3中,使用html2canvas截图包含视频、图片、文字的区域
需求:将页面中指定区域进行截图,区域中包含了图片、文字、视频。 第一步,先安装 npm install html2canvas第二步,在页面引入: import html2canvas from html2canvas;第三步,页面使用: 1&…...
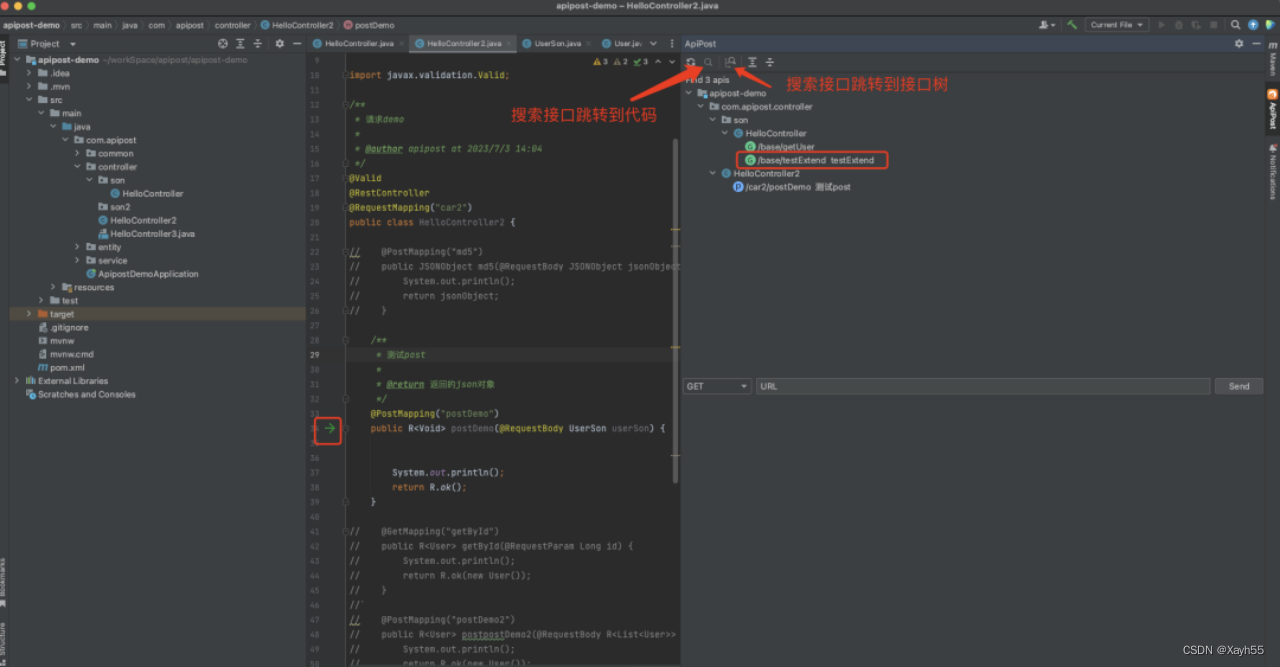
后端神器!代码写完直接调试!
Apipost推出IDEA插件非常省时高效,写完代码直接可以进行调试,而且支持生成接口文档,真是后端神器啊! 可以点击下方链接安装更新或在插件商店中搜索安装 下载链接:https://plugins.jetbrains.com/plugin/22676-apipos…...

MATLAB | 万圣节来画个简单的可爱鬼叭!
万圣节要到啦一起来画个可爱鬼吧~ 代码比较的短: 完整代码 figure(Units,normalized,Position,[.2,.1,.52,.72]); axgca;hold on;axis off; ax.DataAspectRatio[1,1,1]; ax.YDirreverse; ax.XLim[0,100]; ax.YLim[0,100]; [X,Y]meshgrid(linspace(0,1,200)); Zsq…...

贪心算法学习------优势洗牌
目录 一,题目 二,题目接口 三,解题思路和代码 全部代码: 一,题目 给定两个数组nums1和nums2,nums1相对于nums2的优势可以用满足nums1[i]>nums2[i]的索引i的数目来描述。 返回nums1的任意排序,使其优…...
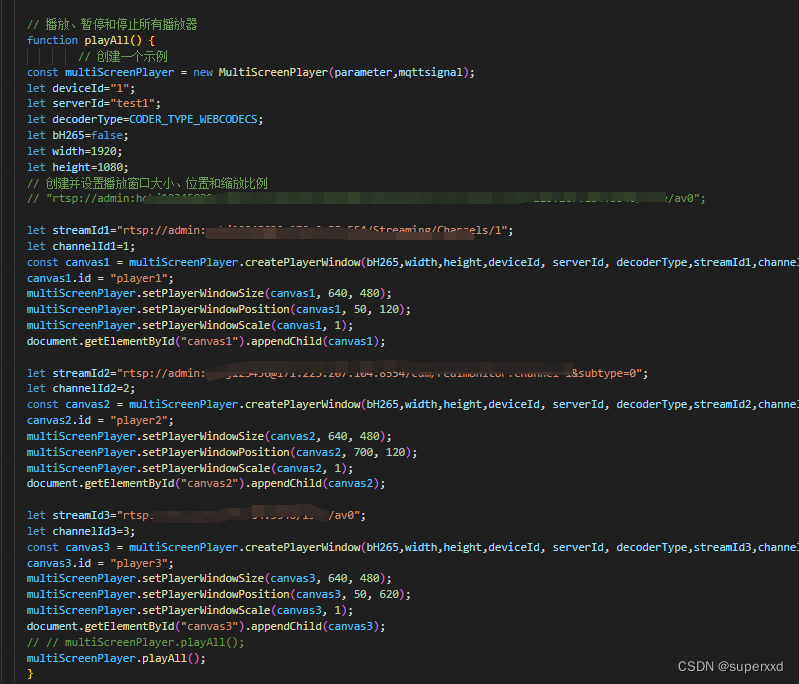
音视频rtsp rtmp gb28181在浏览器上的按需拉流
按需拉流是从客户视角来看待音视频的产品功能,直观,好用,为啥hls flv大行其道也是这个原因,不过上述存在的问题是延迟没法降到实时毫秒级延迟,也不能随心所欲的控制。通过一段时间的努力,结合自己闭环技术栈…...
Java 算法篇-深入了解二分查找法
🔥博客主页: 小扳_-CSDN博客 ❤感谢大家点赞👍收藏⭐评论✍ 目录 1.0 二分查找法的说明 2.0 二分查找实现的多种版本 2.1 二分查找的基础版本 2.2 二分查找的改动版本 2.3 二分查找的平衡版本 2.4 二分查找的官方版本 3.0 二分查找的应用 1…...

Data-Centric Financial Large Language Models
本文是LLM系列文章,针对《Data-Centric Financial Large Language Models》的翻译。 以数据为中心的大语言金融模型 摘要1 引言2 背景3 方法4 实验5 结论和未来工作 摘要 大型语言模型(LLM)有望用于自然语言任务,但在直接应用于…...
【HarmonyOS】服务卡片 API6 JSUI跳转不同页面并携带参数
【关键字】 服务卡片、卡片跳转不同页面、卡片跳转页面携带参数 【写在前面】 本篇文章主要介绍开发服务卡片时,如何实现卡片点击跳转不同页面,并携带动态参数到js页面。在此篇文章“服务卡片 API6 JSUI跳转不同页面”中说明了如果跳转不同页面…...
SQL server数据库端口访问法
最近数据库连接,也是无意中发现了这个问题,数据库可根据端口来连接 网址:yii666.com< 我用的是sql2014测试的,在安装其他程序是默认安装了sql(sql的tcp/ip端口为xxx),服务也不相同,但是由于比较不全,我…...

深孔枪钻厂家,科研管理系统思路
序号 名称 参数及技术指标 (一)系统性能要求 1.系统界面:支持中英文界面自由切换。 2. 系统兼容性:支持主流浏览器,如:IE11 以上、 360 安全浏览器、Firefox、Google Ch…...
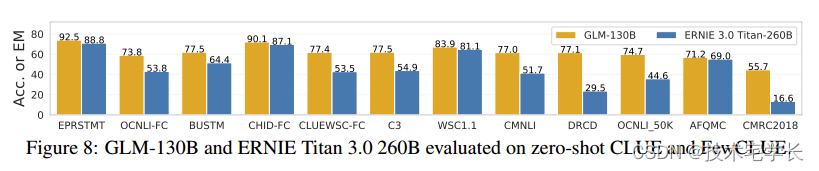
【论文阅读笔记】GLM-130B: AN OPEN BILINGUAL PRE-TRAINEDMODEL
Glm-130b:开放式双语预训练模型 摘要 我们介绍了GLM-130B,一个具有1300亿个参数的双语(英语和汉语)预训练语言模型。这是一个至少与GPT-3(达芬奇)一样好的100b规模模型的开源尝试,并揭示了如何成功地对这种规模的模型进行预训练。在这一过程中࿰…...

Object常用方法
Object常用方法目录 1. equals(Object obj): 2. toString(): 3. hashCode(): 4. getClass(): 5. notify() 和 notifyAll(): 6. wait() 和 wait(long timeout): 7. clone(): 8. fina…...

【VR开发】【Unity】【VRTK】2-关于VR的基础知识
【概述】 在VRTK的实操讲解之前,本篇先介绍几个重要的VR认识。 【VR对各个行业的颠覆】 如果互联网几乎把所有行业都重做了一遍,VR在接下来的几年很可能再把现有的行业都重做一遍,包括但不限于教育,房地产,零售&…...
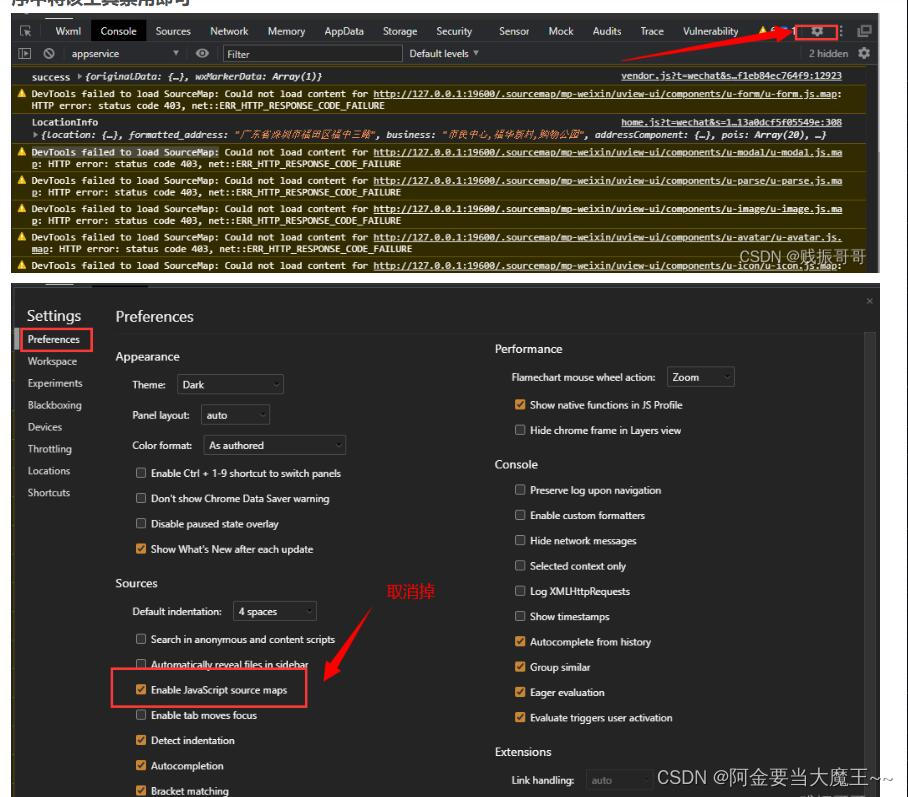
jeecg-uniapp 转成小程序的过程 以及报错 uniapp点击事件
uniapp 点击事件 tap: 单击事件 confirm: 回车事件 blur:失去焦点事件 touchstart: 触摸开始事件 touchmove: 触摸移动事件。 touchend: 触摸结束事件。 longpress: 长按事件。 input: 输入框内容变化事件。 change: 表单元素值变化事件。 submit: 表单提交事件。 scroll: 滚动…...
如何配置?)
Django的静态文件目录(路径)如何配置?
通常用下面的三条语句配置Django的静态文件目录 STATICFILES_DIRS [os.path.join(BASE_DIR, static)] STATIC_URL /static/ STATIC_ROOT os.path.join(BASE_DIR, /static)那么这三条语句分别的作用是什么呢? 请参考博文 https://blog.csdn.net/wenhao_ir/articl…...
)
函数应用(MySQL)
--数值类函数 --绝对值 select abs(-1) --seiling ceil 向上取整 select ceil(1.1) --floor 向下取整 select floor(1.9); --四舍五入 select round(1.17, 1); --rand 随机数 select rand(rand()*1000); --字符串函数 utf8mb3 utfmb4 select length(小三) --查找字符数…...

从开发者视角感受Taotoken官方价折扣带来的实际成本节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从开发者视角感受Taotoken官方价折扣带来的实际成本节省 对于独立开发者和小型团队而言,在构建和迭代AI应用时…...
)
AI生成镜头如何通过DIT审核?——Netflix《The Last Frame》技术白皮书首度公开(附VFX合规性检查清单PDF)
更多请点击: https://kaifayun.com 第一章:AI视频生成在电影制作中的应用 AI视频生成技术正深刻重构电影工业的工作流,从前期预演到后期特效,再到个性化内容分发,其渗透已覆盖创作全生命周期。传统依赖高成本实拍与手…...

【Sora 2批量视频生成黄金工作流】:实测吞吐提升4.8倍的关键配置——NVIDIA A100集群下每小时稳定输出217段1080p视频
更多请点击: https://codechina.net 第一章:Sora 2批量视频生成工作流全景概览 Sora 2作为新一代多模态视频生成模型,其批量处理能力依托于模块化、可编排的端到端工作流设计。该工作流融合提示工程、时空 latent 编码、分块并行解码与后处理…...

app应用接入广告的完整流程和方法:从零搭建可持续变现体系
随着移动互联网进入存量竞争阶段,用户流量增长趋于饱和,单纯依靠用户新增实现产品增值的模式已然失效。对于绝大多数免费工具、社交、资讯、游戏类 APP 而言,合规、稳定、可持续的广告变现,已经成为补齐产品商业闭环、维持产品长期…...

Rust-Bio 生物信息学库入门指南:5个简单步骤快速上手
Rust-Bio 生物信息学库入门指南:5个简单步骤快速上手 【免费下载链接】rust-bio This library provides implementations of many algorithms and data structures that are useful for bioinformatics. All provided implementations are rigorously tested via co…...
亲测好用的AI写作辅助平台,毕业生收藏备用)
(良心整理)亲测好用的AI写作辅助平台,毕业生收藏备用
毕业季论文写作真的这么难吗?选题方向模糊、文献资料繁杂、写作进度缓慢、查重修改头疼、格式规范混乱…… 这份亲测好用的AI论文工具清单,涵盖中英文写作、全流程支持、专项功能、免费与高性价比选项,从开题构思到最终定稿全程护航ÿ…...

为什么92%的CRM项目在6个月内失去用户喜爱?揭秘Lovable CRM的3层情感化设计模型
更多请点击: https://intelliparadigm.com 第一章:Lovable CRM系统搭建 Lovable CRM 是一个轻量、可扩展、开发者友好的客户关系管理系统,专为中小团队设计,强调易用性与可定制性的平衡。它基于 Go 语言后端与 Vue 3 前端构建&am…...
3PEAK思瑞浦 TP321-DF0R DFN1X1-4 运算放大器
特性 通用型,低成本: 增益带宽积:1MHz 低静态电流:45A/放大器 偏移电压:最大5.0毫伏 偏移电压温度漂移:2uV/C 输入偏置电流:10pA 共模抑制比/电源抑制比:90dB 单位增益稳定 轨到轨输入和输出 过驱动输入无相位反转 供电电压范围: TP321-DFOR: 2.1V 至 5.5V 其他部分…...

Unity接入海康UMP流全流程:签名认证、HTTP长连接与自定义渲染
1. 这不是简单的“拉流”,而是一场跨协议、跨权限、跨引擎的精准对接你有没有试过在Unity里直接填一个RTSP地址,比如rtsp://admin:123456192.168.1.64:554/Streaming/Channels/101,然后点播放——结果黑屏、报错、卡死,或者更糟&a…...

软件工程方法论与敏捷开发
软件工程方法论与敏捷开发 1. 技术分析 1.1 软件工程概述 软件工程是系统化的软件开发方法: 软件工程要素过程: 开发流程方法: 技术手段工具: 辅助工具核心目标:高质量软件按时交付可控成本1.2 软件开发方法论 方法论分类传统方法: 瀑布模型敏捷方法: Scrum、Kanban…...