【论文阅读笔记】GLM-130B: AN OPEN BILINGUAL PRE-TRAINEDMODEL
Glm-130b:开放式双语预训练模型
摘要
我们介绍了GLM-130B,一个具有1300亿个参数的双语(英语和汉语)预训练语言模型。这是一个至少与GPT-3(达芬奇)一样好的100b规模模型的开源尝试,并揭示了如何成功地对这种规模的模型进行预训练。在这一过程中,我们面临着许多意想不到的技术和工程挑战,特别是在损失峰值和分歧方面。在本文中,我们介绍了GLM-130B的训练过程,包括它的设计选择,效率和稳定性的训练策略,以及工程努力。由此产生的GLM-130B模型在广泛的流行英语基准测试中提供了明显优于GPT-3 175B(达芬奇)的性能优势,而在OPT-175B和布鲁姆- 176b中没有观察到这种性能优势。在相关基准测试中,它也始终显著优于最大的中文模型ERNIE TITAN 3.0 260b。最后,我们利用GLM-130B的独特缩放特性,在没有后训练的情况下达到INT4量化,几乎没有性能损失,使其成为100b尺度模型中的第一个,更重要的是,允许其对4×RTX 3090 (24G)或8×RTX 2080 Ti (11G) gpu进行有效推理,这是使用100b尺度模型所需的最经济实惠的gpu。GLM-130B模型权重是公开访问的,其代码、训练日志、相关工具包和经验教训都是在https://github.com/THUDM/GLM-130B/上开源的。
1 INTRODUCTION
大型语言模型(llm),特别是那些参数超过1000亿个(100B)的模型(Brown et al, 2020;Thoppilan et al, 2022;Rae等,2021;Chowdhery等人,2022;Wang等人,2021)提出了有吸引力的缩放定律(Wei等人,2022b),其中突然出现了zero-shot和few-shot能力。其中,具有175B个参数的GPT-3 (Brown et al, 2020)开创了100b尺度llm的研究,在各种基准测试中,使用32个标记样例产生的性能明显优于完全监督的BERT-Large模型。然而,GPT-3(以及许多其他封闭的100b级规模的GPT-3)模型本身以及如何训练它,到目前为止对公众都是不透明的。培养出如此规模的高质量LLM,并将模型和培训过程分享给大家,具有至关重要的价值。
因此,我们的目标是预先训练一个开放和高度精确的100b级模型,并考虑到道德问题。在我们的尝试过程中,我们已经意识到,与训练10b规模的模型相比,在预训练效率、稳定性和收敛性方面,以这种规模预训练密集的LLM会带来许多意想不到的技术和工程挑战。在训练OPT-175B (Zhang et al ., 2022)和BLOOM176B (Scao et al ., 2022)中也同时发现了类似的困难,进一步证明了GPT-3作为先驱研究的重要性。

在这项工作中,我们从工程努力、模型设计选择、效率和稳定性的训练策略以及可负担推理的量化方面介绍了100b规模模型glm - 130b的预训练。由于人们普遍认识到,经验地列举训练100b级llm的所有可能设计在计算上是负担不起的,我们不仅介绍了训练GLM-130B的成功部分,还介绍了许多失败的选择和经验教训。
特别是训练的稳定性是如此规模的训练模式能否成功的决定性因素。与OPT-175B中手动调整学习率和BLOOM-176B中牺牲性能使用嵌入范数等做法不同,我们对各种选项进行了实验,发现嵌入梯度收缩策略可以显著稳定GLM-130B的训练。
具体来说,GLM-130B是一个双语(英语和中文)双向密集模型,具有1300亿个参数,在2022年5月6日至7月3日期间,在96个NVIDIA DGX-A100 (8×40G) GPU节点的集群上预训练了超过4000亿个令牌。我们没有使用gpt风格的架构,而是采用通用语言模型(General Language Model, GLM)算法(Du et al, 2022)来利用其双向注意力优势和自回归的空白填充目标。表1总结了GLM-130B、GPT-3与另外两个开源成果——opt - 175b和BLOOM-176B,以及PaLM 540B (Chowdhery et al, 2022)——一个4倍大的模型的比较,作为参考。
总之,概念上的独特性和工程上的努力使GLM-130B在广泛的基准测试(总共112个任务)中表现出超过GPT-3水平的性能,并且在许多情况下也优于PaLM 540B,而在OPT-175B和BLOOM-176B中尚未观察到优于GPT-3的性能(参见图1左)。对于零弹性能,GLM-130B在LAMBADA上优于GPT-3 175B(+5.0%)、OPT-175B(+6.5%)和BLOOM-176B (+13.0%) (Paperno et al, 2016),在Big-bench-lite上优于GPT-3 3 (Srivastava et al, 2022)。对于5发MMLU (Hendrycks et al, 2021)任务,它优于GPT-3 175B(+0.9%)和BLOOM-176B(+12.7%)。作为中文的双语 LLMs,它在7个zero-shot CLUE (Xu et al ., 2020)数据集(+24.26%)和5个zero-shot FewCLUE (Xu et al ., 2021)数据集(+12.75%)上的结果明显优于中文最大的 LLMs ERNIE TITAN 3.0 260B (Wang et al ., 2021)。重要的是,如图1所示,作为开放模型的GLM-130B与100b级模型相比,其偏置和生成毒性明显更小。
最后,我们设计了GLM-130B,使尽可能多的人能够进行100b规模的 LLMs研究。首先,决定130B的大小,而不是使用175B+参数作为OPT和BLOOM,因为这样的大小支持在单个A100 (8×40G)服务器上进行推理。其次,为了进一步降低对GPU的要求,我们将GLM-130B量化为不经过后训练的INT4精度,而OPT和BLOOM只能达到INT8精度。由于GLM架构的独特特性,GLM- 130b的INT4量化带来的性能下降可以忽略不计,例如,在LAMBADA上下降-0.74%,在MMLU上甚至下降+0.05%,使其仍然优于未压缩的GPT-3。这使得GLM130B在4×RTX 3090 (24G)或8×RTX 2080 Ti (11G)服务器上的快速推理性能得到保证,这是迄今为止使用100b级llm所需的最经济实惠的GPU。

图3:GLM-130B训练中不同layernorm的试验。结果表明,DeepNorm是最稳定的,因为它具有较小的梯度范数,并且在早期训练中不会出现峰值。
2 THE DESIGN CHOICES OF GLM-130B
机器学习模型的架构定义了它的归纳偏差。然而,人们已经意识到,探索llm的各种架构设计在计算上是负担不起的。介绍和解释GLM-130B独特的设计选择。
2.1 GLM-130B’S ARCHITECTURE
GLM作为主干。最近的 100B-scale LLMs,如GPT-3、PaLM、OPT和BLOOM,都遵循传统的gpt风格(Radford等人,2019)的解码器自回归语言建模架构。在GLM-130B中,我们尝试探索双向glm -通用语言模型(Du et al, 2022)作为其主干的潜力。
GLM是一种基于变换的语言模型,利用自回归填充空白作为其训练目标。简而言之,对于文本序列x = [x1,···,xn],从中采样文本跨度{s1,···,sm},其中每个si表示一个连续标记[si,1,···,si,li]的跨度,并用单个掩码标记替换(即损坏)以形成xcorrupt。要求模型自回归地恢复它们。为了允许损坏跨度之间的交互,它们对彼此的可见性是由它们顺序的随机抽样排列决定的。
GLM在未屏蔽(即未损坏)上下文上的双向注意将GLM- 130b与使用单向注意的GPT-style LLMs区分开来。为了支持理解和生成,它混合了两个corruption目标,每个目标都由一个特殊的mask token表示:
•[MASK]:句子中的短空格,其长度加起来相当于输入的某一部分。
•[gMASK]:在提供前缀上下文的句子末尾随机长度的长空白。
从概念上讲,具有双向注意的空白填充目标能够比gpt风格的模型更有效地理解上下文:当使用[MASK]时,GLM-130B表现为BERT (Devlin等人,2019)和T5 (rafael等人,2020);当使用[gMASK]时,GLM-130B的行为与PrefixLM相似(Liu et al, 2018;Dong et al, 2019)。
根据经验,GLM-130B在zero-shot LAMBADA上提供了创纪录的80.2%的精度,优于GPT-3和PaLM 540B(图2)。通过设置注意罩,GLM-130B的单向改型可与GPT-3和OPT-175B相媲美。我们的观察结果与现有研究结果一致(Liu et al ., 2018;Dong et al, 2019)。

图2:相似规模的GLM-130B和LLMs 在zero-shot LAMBADA语言建模。Du等人(2022)提供了GLM双向注意的详细信息。
Layer Normalization层规范化(LN, Ba等人(2016))。训练不稳定性对LLMs是一个主要挑战(Zhang et al ., 2022;Scao等,2022;Chowdhery等人,2022)(参见附录中的图10,用于训练几个100b尺度模型中的崩溃)。选择合适的LNs,可以稳定训练LLMs。我们对现有的实践进行了实验,例如Pre-LN (Xiong et al, 2020);
我们的研究后来集中在Post-LN上,因为它在初步实验中具有良好的下游结果,尽管它不能稳定GLM-130B。幸运的是,用新提出的DeepNorm (Wang et al ., 2022b)初始化后ln的一次尝试产生了很好的训练稳定性。具体而言,给定GLM-130B的层数N,我们采用DeepNorm(x) = LayerNorm(α·x + Network(x)),其中α = (2N) 1 2,并对ffn, v_proj和out_proj应用缩放因子为(2N)−1 2的Xavier法线初始化。此外,所有偏置项初始化为零。从图3可以看出,这对GLM-130B的训练稳定性有明显的好处。
Positional Encoding and FFNs位置编码和ffn。我们在训练稳定性和下游性能方面对位置编码(PE)和FFN改进的不同选项进行了实证测试(详见附录B.3)。对于GLM-130B中的pe,我们采用旋转位置编码(RoPE, Su等人(2021))而不是ALiBi (Press等人,2021)。为了改善Transformer中的ffn,我们选择GLU和GeLU (Hendrycks & Gimpel, 2016)激活作为替代品。
2.2 GLM-130B’S PRE-TRAINING SETUP
受到近期作品的启发(Aribandi et al, 2022;魏等,2022a;Sanh et al, 2022), GLM- 130b预训练目标不仅包括自监督GLM自回归空白填充,还包括对一小部分token的多任务学习。预计这将有助于提高其下游零次学习性能。
零次学习 Zero-shot定义:学习一个新类的的视觉分类器,这个新类没有提供任何的图像数据,仅仅给出了这个类的word embedding。zero-shot基本概念
首先通过一个例子来引入zero-shot的概念。假设我们已知驴子和马的形态特征,又已知老虎和鬣狗都是又相间条纹的动物,熊猫和企鹅是黑白相间的动物,再次的基础上,我们定义斑马是黑白条纹相间的马科动物。不看任何斑马的照片,仅仅凭借推理,在动物园一众动物中,我们也能够找到斑马。
上述例子中包含了一个推理过程,就是利用过去的知识(已知动物的描述),在脑海中推理出新对象的具体形态,从而能对新对象进行辨认。(如下图所示)ZSL就是希望能够模仿人类的这个推理过程,使得计算机具有识别新事物的能力。
原文链接:https://blog.csdn.net/gary101818/article/details/129108491
Self-Supervised Blank Infilling (95% tokens).自我监督空白填充(95%tokens)。回想一下,GLM-130B在此任务中同时使用[MASK]和[gMASK]。每个训练序列一次独立地应用其中一个。
具体来说,[MASK]用于屏蔽30%的训练序列中的连续跨度进行空白填充。跨度的长度遵循泊松分布(λ = 3),加起来是输入的15%。
对于其他70%的序列,每个序列的前缀被保留为上下文,并使用[gMASK]来掩盖其余部分。掩码长度从均匀分布中采样。
预训练数据包括1.2T Pile (train split) (Gao et al ., 2020) English, 1.0T Chinese wuaoorpora (Yuan et al ., 2021),以及我们从网络上抓取的250G Chinese语料库(包括在线论坛、百科全书、QA),形成了中英文内容的均衡构成。
Multi-Task Instruction Pre-Training (MIP, 5% tokens).多任务指令预训练(MIP, 5%tokens)。T5 (rafael et al, 2020)和ExT5 (Aribandi et al, 2022)表明,预训练中的多任务学习可能比微调更有帮助,因此我们建议在GLM-130B的预训练中包含各种指令提示数据集,包括语言理解、生成和信息提取。
与最近的作品相比(Wei et al ., 2022a;Sanh等人,2022)利用多任务提示微调来改善zero-shot任务转移,MIP仅占5%的tokens,并且在预训练阶段设置,以防止破坏llms的其他一般能力,例如无条件自由生成。
具体来说,我们包括74个提示数据集,来自(Sanh等,2022;Wang et al ., 2022a),列于附录C和表12。建议GLM-130B用户避免根据第5节中说明的标准在这些数据集上评估其 zero-shot和 zero-shot能力。
2.3 PLATFORM-AWARE PARALLEL STRATEGIES AND MODEL CONFIGURATIONS
2.3平台感知并行策略和模型配置
GLM-130B在96个DGX-A100 GPU (8×40G)服务器集群上进行训练,为期60天。
目标是通过尽可能多的代币,正如最近的一项研究(Hoffmann et al, 2022)表明的那样,大多数现有的LLMs在很大程度上训练不足。
The 3D Parallel Strategy.三维并行策略。数据并行性(Valiant, 1990)和张量模型并行性(Shoeybi等人,2019)是训练十亿尺度模型的实际实践(Wang & Komatsuzaki, 2021;Du et al, 2022)。为了进一步解决由于在节点间应用张量并行而导致的巨大GPU内存需求和GPU整体利用率下降的问题,我们使用40G而不是80G a100来训练GLM-130B,我们将管道模型并行与其他两种策略结合起来,形成了一种3D并行策略。
管道并行性将模型划分为每个并行组的顺序阶段,为了进一步减少管道引入的气泡(bubbles),我们利用DeepSpeed (Rasley等人,2020)的PipeDream-Flush (Narayanan等人,2021)实现以相对较大的全局批大小(4,224)训练GLM-130B,以减少时间和GPU内存浪费。通过数值和实证检验,我们采用了4路张量并行和8路管道并行(详见附录B.4)。根据(Chowdhery等人,2022)的计算,我们报告了由于重新物化,硬件FLOPs利用率(HFU)为43.3%,模型FLOPs利用率(MFU)为32.5%。
GLM-130B Configurations。我们的目标是使我们的100B-scale LLM能够以FP16精度运行单个DGX-A100 (40G)节点。基于我们从GPT-3中采用的12288隐藏状态维,得到的模型尺寸必须不超过130B个参数,即GLM-130B。为了最大限度地提高GPU利用率,我们根据平台及其相应的并行策略配置模型。为了避免由于两端额外嵌入单词而导致中间阶段内存利用率不足,我们通过从中移除一层来平衡管道分区,使GLM-130B中的9×8-2=70个transformer层。
在对集群的60天访问期间,我们成功地训练了GLM-130B 4000亿个令牌(中文和英文各约2000亿个),每个样本的固定序列长度为2048。
对于[gMASK]训练目标,我们使用2,048个令牌的上下文窗口。对于[MASK]和多任务目标,我们使用512个上下文窗口并将四个样本连接在一起以满足2,048个序列长度。在第一个2.5%的样本中,我们将批量大小从192预热到4224。我们使用AdamW (Loshchilov & Hutter, 2019)作为优化器,将β1和β2设置为0.9和0.95,权重衰减值为0.1。在前0.5%的样本中,我们将学习率从10−7预热到8 × 10−5,然后通过10×cosine schedule 将其衰减。我们使用0.1的(dropout rate)和使用1.0的clipping value的clip gradients(参见表11的完整配置)。
3 THE TRAINING STABILITY OF GLM-130B
glm-130b的训练稳定性
训练稳定性是GLM-130B质量的决定性因素,它也在很大程度上受到其通过tokens数量的影响(Hoffmann et al, 2022)。因此,考虑到计算使用约束,必须在浮点(FP)格式的效率和稳定性之间进行权衡:低精度FP格式(例如16位精度- fp16)提高了计算效率,但容易出overflow and underflow errors,导致训练崩溃。
Mixed-Precision。我们遵循混合精度(micicikevicius等人,2018)策略(Apex O2)的常见做法,即FP16用于向前和向后,FP32用于优化器状态和主权重,以减少GPU内存使用并提高训练效率。与OPT-175B和BLOOM-176B类似(参见附录图10),GLM-130B的训练也会因为这种选择而面临频繁的损耗峰值,并且随着训练的进行,损耗峰值会越来越频繁。与精度相关的峰值往往没有明确的原因:有些会自行恢复;另一些则预示着梯度标准突然飙升,最终出现峰值甚至NaN损失。OPT-175B试图通过手动跳过数据和调整超参数来修复;BLOOM176B通过嵌入规范技术做到了这一点(Dettmers等人,2021)。我们花了几个月的时间对峰值进行实证调查,并意识到当transformers规模扩大时出现了一些问题:
首先,如果使用Pre-LN,transformer主支路的值尺度在较深的层中可能非常大。这在GLM130B中通过使用基于DeepNorm的Post-LN(参见第2.1节)来解决,这使得值尺度始终是有界的
其次,随着模型的扩大,注意力得分变得如此之大,以至于超过了FP16的范围。在LLMs中,有几个选项可以克服这个问题。在CogView (Ding et al, 2021)中,提出了PB-Relax来去除偏差项并在注意力计算中扣除极值以避免该问题,不幸的是,这并不能帮助避免GLM-130B中的解收敛。在BLOOM-176B中,使用BF16格式代替FP16,因为它在NVIDIA Ampere gpu(即A100)上的值范围很广。然而,在我们的实验中,由于它在梯度积累中转换为FP32, BF16消耗的运行时GPU内存比FP16多15%,更重要的是它不支持其他GPU平台(例如NVIDIA Tesla V100),限制了生成的LLMs的可访问性。BLOOM-176B的另一个选择是将嵌入范数应用于BF16,但牺牲了对模型性能的重大惩罚,因为他们注意到嵌入范数会损害模型的zero-shot学习(Cf.章节4.3 in (Scao et al, 2022))。
Embedding Layer Gradient Shrink 嵌入层梯度收缩(EGS)。我们的实证研究表明,梯度范数可以作为训练崩溃的信息指标。具体地说,我们发现训练崩溃通常落后于梯度范数的“峰值”几个训练步骤。这种尖峰通常是由嵌入层的异常梯度引起的,因为我们观察到,在GLM-130B的早期训练中,其梯度范数往往比其他层的梯度范数大几个数量级(Cf。图4 (a))。此外,在早期训练中,它往往波动很大。在视觉模型(Chen et al, 2021)中,通过冻结patch投影层来处理这个问题。不幸的是,我们不能冻结语言模型中嵌入层的训练。
最后,我们发现嵌入层上的梯度收缩可以克服损失峰值,从而稳定GLM-130B的训练。它首先用于多模态变压器CogView (Ding et al, 2021)。设α为收缩因子,该策略可以通过word_embedding = word_embedding∗α+word_embedding.detach()∗(1−α)来实现。根据经验,图4 (b)表明,设置α = 0.1可以消除我们可能遇到的大多数峰值,延迟可以忽略不计。
事实上,最后的GLM-130B训练运行只经历了三次后期损失偏离情况,尽管由于硬件故障多次失败。对于三个意想不到的峰值,进一步缩小嵌入梯度仍然可以帮助稳定GLM-130B训练。有关详细信息,请参阅代码库中的训练笔记和Tensorboard日志。
4 GLM-130B INFERENCE ON RTX 2080 TI
GLM-130B的主要目标之一是降低访问 100B-scale LLMs的硬件要求,同时不存在效率和有效性方面的缺点。
如前所述,130B的模型大小是为在单个A100 (40G×8)服务器上运行完整的GLM-130B模型而确定的,而不是OPT-175B和BLOOM-176B所需的高端A100 (80G×8)机器。为了加速GLM-130B推理,我们还利用FasterTransformer (Timonin et al, 2022)在c++中实现GLM-130B。与Huggingface中BLOOM-176B的PyTorch实现相比,在同一台A100服务器上,GLM-130B的解码推理速度快了7-8.4倍。(详情见附录B.5)。
RTX 3090 /2080的INT4量化。为了进一步支持普及的gpu,我们尝试在保持性能优势的同时尽可能压缩GLM-130B,特别是通过量化(Zafrir等人,2019;沈等,2020;Tao等人,2022),它为生成语言模型引入了很少的任务不可知性能下降。
通常,实践是将模型权重和激活量化到INT8。然而,我们在附录B.6中的分析表明,t LLMs’ 的激活可能包含极端的异常值。同时,还发现了OPT-175B和BLOOM-176B中的突发性异常值(Dettmers等人,2022),这些异常值仅影响约0.1%的特征维度,因此可以通过矩阵乘法分解对这些异常维度进行求解。不同的是,在GLM-130B的激活中存在大约30%的异常值,这使得上述技术的效率低得多。因此,我们决定专注于模型权重的量化(即,主要是线性层),同时保持FP16的激活精度。量化模型在运行时动态转换为FP16精度,引入了较小的计算开销,但大大减少了用于存储模型权重的GPU内存使用。

图5:(左)注意力密度和w2的权重分布;(右)GLM-130B的INT4权重量化标度律。
令人兴奋的是,我们成功地达到了GLM-130B的INT4权重量化,而现有的成功迄今只达到了INT8。内存方面,与INT8相比,INT4版本有助于额外节省所需GPU内存的一半至70GB,从而允许GLM-130B在4 × RTX 3090 Ti (24G)或8 × RTX 2080 Ti (11G)上进行推理。在性能方面,表2表明,在没有任何训练的情况下,int4版本的GLM-130B几乎没有性能下降,因此在普通基准测试中保持了比GPT-3更好的性能优势。

表2:左:量化的GLM-130B在几个基准上的性能;右图:INT4用FasterTransformer量化GLM-130B的推理速度(编码和解码)。
GLM’s INT4 Weight Quantization Scaling Law. GLM的INT4权值量化标度律。我们研究了图5中所示的这种独特的INT4权重量化缩放规律的潜在机制。我们在图5中绘制了权重值分布,结果证明它直接影响量化质量。具体来说,一个分布更广的线性层需要用更大的箱子进行量化,这会导致更大的精度损失。
因此,广泛分布的注意力密集矩阵和w2矩阵解释了GPT-style BLOOM的INT4量化失败。相反,与类似大小的gpt相比,GLM的分布往往要窄得多,并且INT4和FP16版本之间的差距随着GLM模型尺寸的扩大而进一步缩小(详见附录中的图15)。
5 THE RESULTS
我们按照LLMs(如GPT-3和PaLM)的常用设置来评估GLM-130B的英语1。作为中英文双语LLM, GLM-130B也以中文为基准进行评估。
GLM-130B Zero-Shot学习范围的探讨。由于GLM-130B已与MIP训练,在这里我们澄清其Zero-Shot评估的范围。事实上,“zero-shot”的解释似乎存在争议,在社会上没有达成共识。我们遵循了一项有影响力的相关调查(Xian等人,2018),该调查称“在测试时,在Zero-Shot学习环境中,目标是将测试图像分配给看不见的类标签”,其中涉及看不见的类标签是关键。因此,我们推导出选择GLM-130B的Zero-Shot(和few-shot)数据集的标准:
•英语:1)对于具有固定标签的任务(例如,自然语言推理):这些任务中的数据集不应该被评估;2)对于没有固定标签的任务(例如,(选择题)QA,主题分类):只考虑与MIP中的数据集有明显领域转移的数据集。
•中文:所有数据集都可以评估,因为存在zero-shot跨语言迁移。
过滤测试数据集。遵循先前的做法(Brown et al, 2020;Rae et al .2021)和我们的上述标准,我们过滤并避免报告潜在污染数据集的评估结果。对于LAMBADA和CLUE,我们发现在13-gram的设置下重叠最小。Pile、MMLU和BIG-bench要么held-out,要么晚于语料库的爬取。 Pile,
MMLU, and BIG-bench are either held-out or released later than the crawling of corpora.
5.1 LANGUAGE MODELING
LAMBADA (Paperno et al ., 2016)是一个测试最后一个单词语言建模能力的数据集。先前图2所示的结果表明,GLM-130B在双向关注的情况下实现了80.2的zero-shot精度,在LAMBADA上创造了新的记录。
Pile测试集(Gao et al ., 2020)包括一系列语言建模的基准。平均而言,与GPT-3和Jurassic1 (Lieber et al, 2021)相比,GLM130B在其18个共享测试集上的加权BPB表现最好,后者的结果直接采用后者,显示其强大的语言能力(详见附录C.4)。

表3:GLM-130B在Pile评价上的平均BPB(18个子数据集)

图6:沿着训练步骤在MMLU(57个任务)上的GLM-130B。
图7:跨尺度的BIG-bench-lite评估(24个任务)
表4:BIGbench-lite的详细信息(24个任务)。
5.2 MASSIVE MULTITASK LANGUAGE UNDERSTANDING (MMLU)
大规模多任务语言理解(mmlu)
MMLU (Hendrycks等人,2021)是一个多样化的基准,包括57个选择题回答任务,涉及从高中水平到专家水平的人类知识。它是在Pile爬取之后发布的,是LLMs几次学习的理想试验台。GPT-3结果采用MMLU, BLOOM-176B测试使用与GLM-130B相同的提示符(详见附录C.6和表15)。
在图6中查看了大约300B个tokens后,GLM-130B在MMLU上的few-shot (5-shot) p性能接近GPT-3(43.9)。随着训练的进行,它继续向上移动,当训练必须结束时达到44.8的准确率(即总共查看400B个tokens)。这与观察结果(Hoffmann et al, 2022)一致,即大多数现有LLMs远未得到充分训练。
5.3 BEYOND THE IMITATION GAME BENCHMARK (BIG-BENCH)
5.3超越模仿游戏基准(BIG-BENCH)
BIG-bench (Srivastava et al, 2022)对涉及模型推理、知识和常识能力的挑战性任务进行基准测试。考虑到llm评估它的150个任务非常耗时,我们暂时报告了big -bench寿命——一个官方的24个任务子集合。从图7和表4可以看出,在zero-shot设置中,GLM-130B优于GPT-3 175B,甚至优于PaLM 540B(比GPT-3 175B大4倍)。这可能是由于GLM-130B的双向上下文注意和MIP,这已被证明可以改善看不见的任务中的zero-shot结果(Wei等人,2022a;Sanh et al, 2022)。随着shot的增加,GLM-130B的性能不断提高,保持了其优于GPT-3的性能(各型号和任务的详细信息参见附录C.5和表14)。
限制和讨论。在上述实验中,我们观察到GLM-130B随着少弹样本数量的增加,其性能的增长(13.31 ~ 15.12)不如GPT-3(4.35 ~ 13.18)显著。下面是我们对这一现象的直观理解。
首先,GLM-130B的双向特性可能导致较强的zero-shot性能(如zero-shot语言建模所示),从而比单向LLMs更接近相似规模(即 100B-scale)模型的few-shot“上限”。其次,这也可能归因于现有MIP范式的缺失(Wei et al ., 2022a;Sanh et al ., 2022),它只涉及训练中的zero-shot预测,并且可能会偏向GLM-130B,以获得更强的zero-shot学习,但相对较弱的上下文few-shot性能。为了纠正偏差,我们提出的一个潜在解决方案是使用带有不同上下文样本的MIP,而不仅仅是零样本。
最后,尽管与GPT-3几乎相同的GPT架构,PaLM 540B在使用少量上下文学习的情况下的相对增长要比GPT-3显著得多。我们推测,这种性能增长的进一步加速是PaLM高质量和多样化的私人收集的培训语料库的来源。通过将我们的经验与(Hoffmann et al, 2022)的见解相结合,我们意识到应该进一步投入更好的架构、更好的数据和更多的算力FLOPS。
5.4 CHINESE LANGUAGE UNDERSTANDING EVALUATION (CLUE)
我们评估了GLM-130B在既定的中国自然语言处理基准CLUE (Xu et al ., 2020)和FewCLUE (Xu et al ., 2021)上的中国zero-shot性能。请注意,我们在MIP中不包括任何中国下游任务。到目前为止,我们已经完成了两个基准的部分测试,包括7个CLUE和5个FewCLUE数据集(详见附录C.7)。我们将GLM-130B与现有最大的中文单语语言模型260B ERNIE Titan 3.0 (Wang et al, 2021)进行了比较。我们遵循它的设置来报告开发数据集上的zero-shot结果。GLM-130B在12个任务中始终优于ERNIE Titan 3.0(参见图8)。有趣的是,GLM-130B在两个抽象MRC数据集(DRCD和CMRC2018)上的表现至少比ERNIE好260%,这可能是由于GLM-130B的预训练目标自然地与抽象MRC的形式产生共鸣。
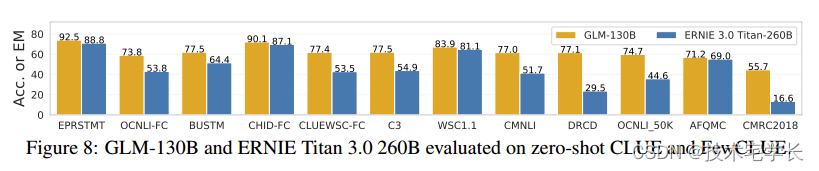
Figure 8: GLM-130B and ERNIE Titan 3.0 260B evaluated on zero-shot CLUE and FewCLUE.
图8:GLM-130B和ERNIE Titan 3.0 260B在zero-shot CLUE和FewCLUE上的评估。
6 RELATED WORK
在本节中,我们回顾了GLM-130B在预训练 LLMs的预训练、迁移和推理方面的相关工作(Qiu et al ., 2020;Bommasani et al, 2021)。
训练。香草语言建模指的是仅解码器的自回归模型(例如,GPT (Radford等人,2018)),但它也识别文本上任何形式的自我监督目标。
最近,基于变压器的语言模型(Vaswani等人,2017)呈现出一种迷人的缩放规律:随着模型的扩展,新能力(Wei等人,2022b)从1.5B (Radford等人,2019),10b尺度的语言模型(rafael等人,2020;Shoeybi等人,2019;Black等人,2022),到100Bscale GPT-3 (Brown等人,2020)。后来,尽管有许多百万级的 LLMs(Lieber et al, 2021;Thoppilan et al, 2022;Rae等,2021;Smith等人,2022;Chowdhery等人,2022;Wu等,2021;Zeng等,2021;Wang et al ., 2021)的中英文版本,它们不向公众开放,或者只能通过有限的api访问。 LLMs之间的紧密关系严重阻碍了其发展。GLM-130B的努力,以及最近的ElutherAI, OPT-175B (Zhang等人,2022)和BLOOM-176B (Scao等人,2022),旨在为我们的社区提供高质量的开源 LLMs。
转移。虽然微调实际上是迁移学习的一种方式,但由于 LLMs的规模巨大,对 LLMs的评估一直集中在提示和情境学习上(Brown等人,2020;Liu et al ., 2021a)。然而,最近的一些尝试是关于语言模型的参数有效学习(Houlsby等人,2019)和提示调谐(即p调谐,Li & Liang (2021);Liu等(2021b);Lester et al (2021);Liu et al(2022))。目前我们暂不关注这些,将把它们在GLM-130B上的综合测试留到以后的研究中。
推理。如今,大多数公众可访问的 LLMs都通过有限的api提供服务。在这项工作中,我们努力的一个重要部分是LLMs的高效和快速推理。相关工作可能包括蒸馏(Sanh等人,2019;Jiao等,2020;Wang et al, 2020),量化(Zafrir et al, 2019;沈等,2020;Tao et al ., 2022)和修剪(Michel et al ., 2019;Fan et al, 2019)。最近的研究(Dettmers等人,2022)表明,由于异常维数的特殊分布,OPT-175B和BLOOM-176B等LLMs可以量化为8位。在这项工作中,我们展示了GLM的INT4权重量化缩放定律,该定律允许GLM- 130b在最少4×RTX 3090 (24G) gpu或8×RTX 2080 Ti (11G) gpu上进行推理。
7 CONCLUSION AND LESSONS
我们介绍GLM-130B,一种双语预训练语言模型,旨在促进开放和包容的法学硕士研究。GLM-130B的技术和工程事业为LLMs的架构、预训练目标、训练稳定性和效率以及可负担的推理提供了见解。总之,它有助于GLM-130B在112项任务的语言表现和偏见和毒性基准的道德结果方面的高质量。我们成功和失败的经验都被浓缩成 100B-scale LLMs 训练的经验教训,附在附录B.10中。
相关文章:
【论文阅读笔记】GLM-130B: AN OPEN BILINGUAL PRE-TRAINEDMODEL
Glm-130b:开放式双语预训练模型 摘要 我们介绍了GLM-130B,一个具有1300亿个参数的双语(英语和汉语)预训练语言模型。这是一个至少与GPT-3(达芬奇)一样好的100b规模模型的开源尝试,并揭示了如何成功地对这种规模的模型进行预训练。在这一过程中࿰…...

Object常用方法
Object常用方法目录 1. equals(Object obj): 2. toString(): 3. hashCode(): 4. getClass(): 5. notify() 和 notifyAll(): 6. wait() 和 wait(long timeout): 7. clone(): 8. fina…...

【VR开发】【Unity】【VRTK】2-关于VR的基础知识
【概述】 在VRTK的实操讲解之前,本篇先介绍几个重要的VR认识。 【VR对各个行业的颠覆】 如果互联网几乎把所有行业都重做了一遍,VR在接下来的几年很可能再把现有的行业都重做一遍,包括但不限于教育,房地产,零售&…...
jeecg-uniapp 转成小程序的过程 以及报错 uniapp点击事件
uniapp 点击事件 tap: 单击事件 confirm: 回车事件 blur:失去焦点事件 touchstart: 触摸开始事件 touchmove: 触摸移动事件。 touchend: 触摸结束事件。 longpress: 长按事件。 input: 输入框内容变化事件。 change: 表单元素值变化事件。 submit: 表单提交事件。 scroll: 滚动…...
如何配置?)
Django的静态文件目录(路径)如何配置?
通常用下面的三条语句配置Django的静态文件目录 STATICFILES_DIRS [os.path.join(BASE_DIR, static)] STATIC_URL /static/ STATIC_ROOT os.path.join(BASE_DIR, /static)那么这三条语句分别的作用是什么呢? 请参考博文 https://blog.csdn.net/wenhao_ir/articl…...
)
函数应用(MySQL)
--数值类函数 --绝对值 select abs(-1) --seiling ceil 向上取整 select ceil(1.1) --floor 向下取整 select floor(1.9); --四舍五入 select round(1.17, 1); --rand 随机数 select rand(rand()*1000); --字符串函数 utf8mb3 utfmb4 select length(小三) --查找字符数…...

数据分析过程中,发现数值缺失,怎么办?
按照数据缺失机制,数据分析过程中,我们可以将其分为以下几类: (1)完全随机缺失(MCAR):所缺失的数据发生的概率既与已观察到的数据无关,也与未观察到的数据无关。 &#x…...
Vue3.0 toRef toRefs :VCA模式
简介 作用: 创建一个ref对象,其value值指向另一个对象中的某个属性 语法: const name toRef(person, name) 应用: 要将响应式对象中的某个属性单独供应给外部使用时 扩展: toRefs与toRef功能一致,但可…...

VS Code提取扩展时出错。XHR failed
需求:想要在扩展中心下载插件,发现报错 原因:vs code之前设置了代理,需要删除即可...

大模型需要哪类服务器
大模型需要高性能的服务器,以支持大规模的计算和存储需求。一般来说,大模型需要以下类型的服务器: 大型机:大型机可以提供强大的计算能力,适合处理大规模的数据和复杂的计算任务。 GPU服务器:GPU服务器可以…...
Java进阶(List)——面试时List常见问题解读 结合源码分析
前言 List、Set、HashMap作为Java中常用的集合,需要深入认识其原理和特性。 本篇博客介绍常见的关于Java中List集合的面试问题,结合源码分析题目背后的知识点。 关于的Set的博客文章如下: Java进阶(Set)——面试时…...
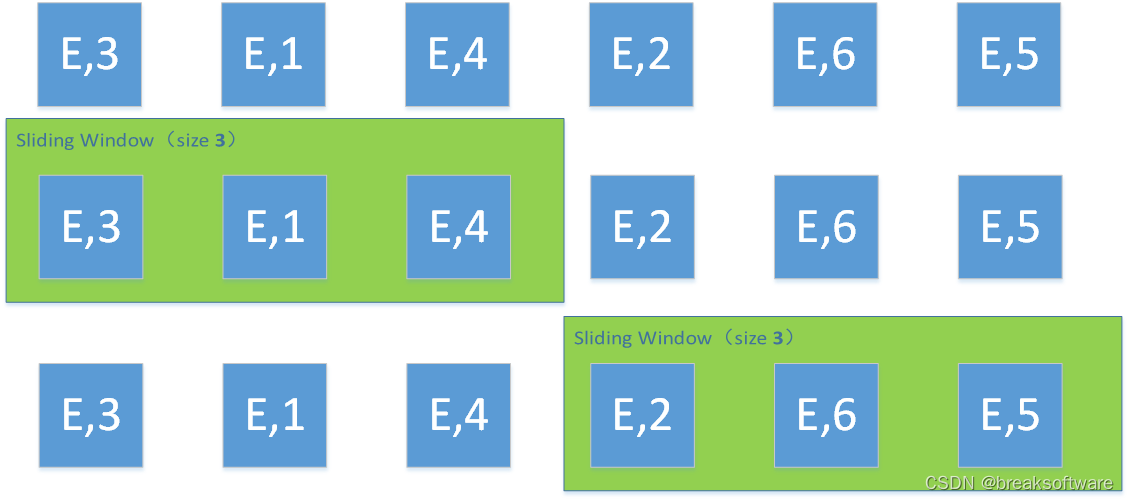
0基础学习PyFlink——个数滑动窗口(Sliding Count Windows)
大纲 滑动(Sliding)和滚动(Tumbling)的区别样例窗口为2,滑动距离为1窗口为3,滑动距离为1窗口为3,滑动距离为2窗口为3,滑动距离为3 完整代码参考资料 在 《0基础学习PyFlink——个数…...
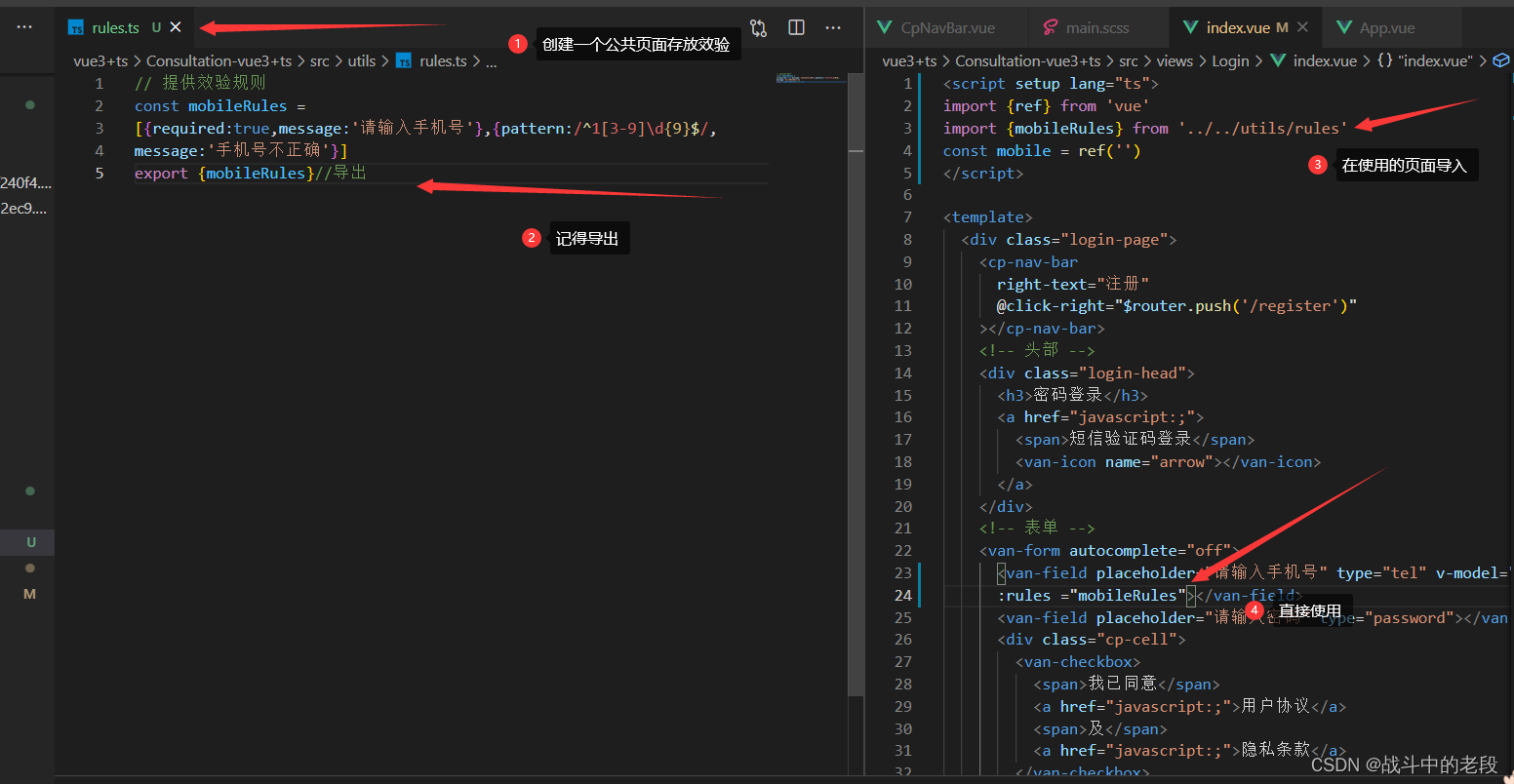
vue3+ts 提取公共方法
因为好多页面都会使用到这个效验规则,封装一个校检规则,方便维护 封装前 封装后...

C++ ->
C -> 是访问类或结构体对象的成员的运算符 注意这里不是直接的访问.是用于访问指向对象的指针的成员 下面的代码可以很好的理解如下: #include<iostream>using namespace std;class Func{public:int i,j;void myFunc(){cout<<"i"<&l…...

VR全景在医院的应用:缓和医患矛盾、提升医院形象
医患关系一直以来都是较为激烈的,包括制度的不完善、医疗资源紧张等问题也时有存在,为了缓解医患矛盾,不仅要提升患者以及家属对于医院的认知,还需要完善医疗制度,提高医疗资源的配置效率,提高服务质量。 因…...

【python基础】format格式化函数的使用
文章目录 前言一、format()内容匹配替换1、序号索引2、关键字3、列表索引4、字典索引5、通过类的属性6、通过魔法参数 二、format()数字格式化 前言 语法:str.format() 说明:一种格式化字符串的函数。 一、format()内容匹配替换 1、序号索引 在没有参…...
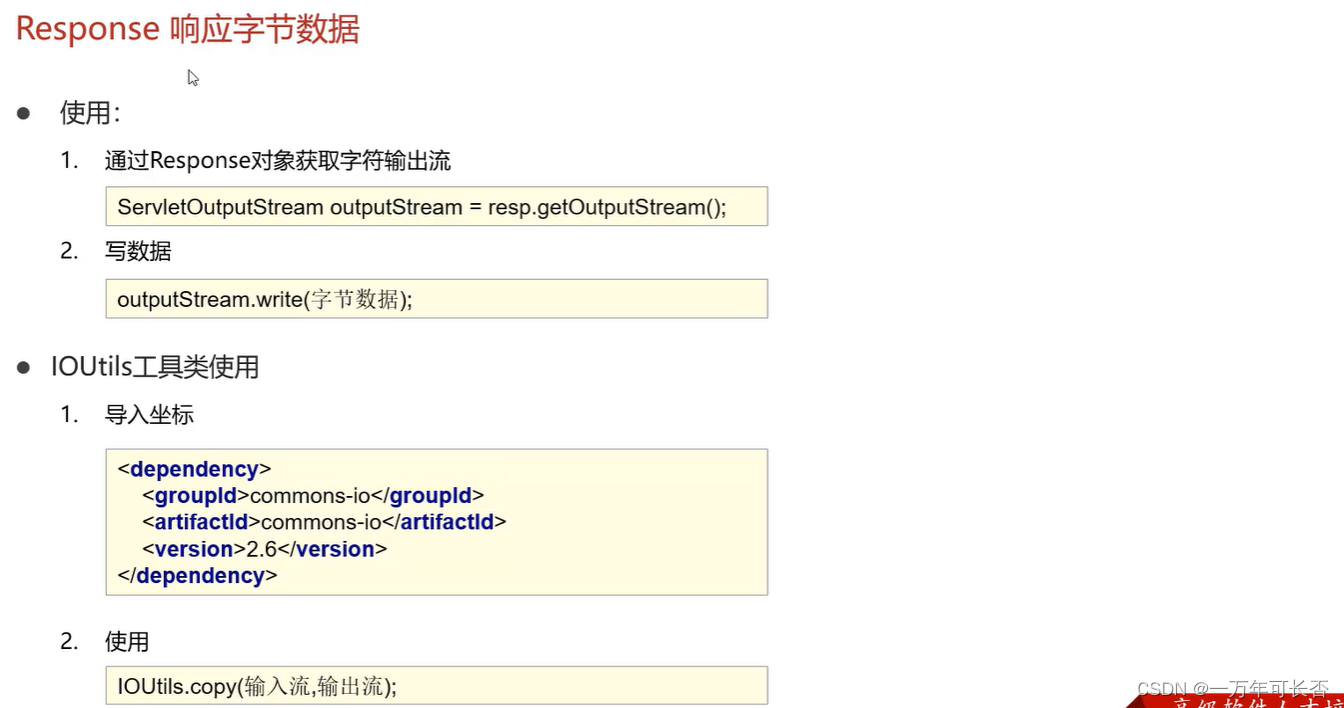
Java web(三):Http、Tomcat、Servlet
文章目录 一、Java web技术栈二、Http1.1 Http请求数据格式1.2 Http响应数据格式1.3 状态码 二、Tomcat2.1 介绍2.2 web项目结构2.3 IDEA中使用Tomcat 三、Servlet3.1 Servlet使用3.2 Servlet生命周期3.3 Servlet方法和体系结构3.4 urlPattern配置 四、Request4.1 获取请求数据…...
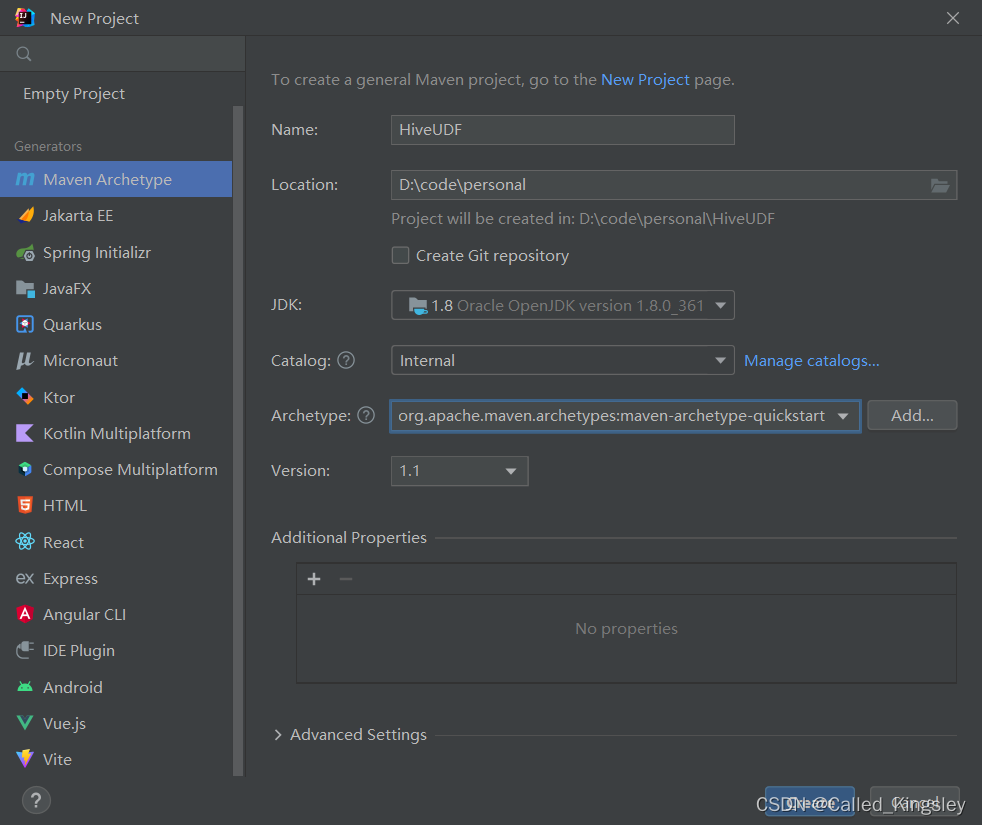
Java实现Hive UDF详细步骤 (Hive 3.x版本,IDEA开发)
这里写目录标题 前言1. 新建项目2.配置maven依赖3.编写代码4.打jar包5.上传服务器6.代码中引用 前言 老版本编写UDF时,需要继承 org.apache.hadoop.hive.ql.exec.UDF类,然后直接实现evaluate()方法即可。 由于公司hive版本比较高(3.x&#x…...
Apache的Access.log分析总结)
Vue进阶(幺陆肆)Apache的Access.log分析总结
文章目录 一、前言二、常用指令 一、前言 前端项目排错阶段,可借助apache的Access.log进行请求日志查看。 二、常用指令 #查看80端口的tcp连接 #netstat -tan | grep "ESTABLISHED" | grep ":80" | wc -l #当前WEB服务器中联接次数最多的ip地…...

Apple 苹果发布 M3、M3 Pro 和 M3 Max 芯片
本心、输入输出、结果 文章目录 Apple 苹果发布 M3、M3 Pro 和 M3 Max 芯片前言M3、M3 Pro 和 M3 Max 芯片的性能相关资料图M3 Pro规格M3 Max规格弘扬爱国精神 Apple 苹果发布 M3、M3 Pro 和 M3 Max 芯片 编辑:简简单单 Online zuozuo 地址:https://blog…...

React Starter Kit 团队协作:如何建立统一的开发规范
React Starter Kit 团队协作:如何建立统一的开发规范 【免费下载链接】react-starter-kit Start your first React App. By using React, Redux, and React-Router. 项目地址: https://gitcode.com/gh_mirrors/reac/react-starter-kit React Starter Kit 是一…...

Claude 3.5架构升级:请求编排器层的零成本蒸发
1. 项目概述:这不是一次普通更新,而是一次架构级“蒸发”“Anthropic Just Shipped the Layer That’s Already Going to Zero”——这个标题乍看像科技媒体的夸张头条,但作为连续跟踪Claude模型演进三年、亲手部署过从Haiku到Sonnet再到Opus…...

具身智能赋能:无感定位打破 UWB 传统空间交互局限
具身智能赋能:无感定位打破 UWB 传统空间交互局限人工智能技术向实体空间深度渗透,具身智能成为空间计算领域进阶发展的核心方向。区别于传统算法仅停留在数据层面分析决策,具身智能依托空间感知能力让智能体系拥有环境理解、自主交互、动态适…...

书匠策AI降重降AIGC:论文党的“隐身斗篷“真有那么神?
各位被论文折磨到头秃的同学们,先别急着划走!今天咱不讲那些干巴巴的"论文写作技巧",咱聊点真正能救命的黑科技——书匠策AI的降重和降AIGC功能。 你可能会问:市面上降重工具一抓一大把,书匠策AI凭什么让我…...

UE4SS终极指南:掌握虚幻引擎游戏修改的核心技术
UE4SS终极指南:掌握虚幻引擎游戏修改的核心技术 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE…...

避坑指南:在Xilinx ZYNQ上调试Linux DMA驱动时常见的5个问题与解决方法
避坑指南:在Xilinx ZYNQ上调试Linux DMA驱动时常见的5个问题与解决方法 当工程师在Xilinx ZYNQ平台上开发Linux DMA驱动时,往往会遇到一些看似简单却极具迷惑性的问题。这些问题轻则导致数据传输失败,重则引发系统崩溃。本文将聚焦五个最具代…...

AI绘画的三重危机:颜料、像素与剽窃
1. 这不是技术讨论,而是一场正在发生的行业地震“Paint, Pixels, and Plagiarism”——光看这个标题,你就能闻到火药味。它没说“AI绘画工具使用指南”,也没写“Stable Diffusion参数调优手册”,而是把颜料(Paint&…...

从外包到正式编再到技术合伙人,我的10年职业三级跳
2003年的夏天,我从一家三本院校的计算机专业毕业,带着一份勉强过关的成绩单和两个用硬纸板打印的简历,走进了北京上地的一家软件外包公司。我的第一份职位,是连合同甲方都叫不全的“外派测试员”。坐在我旁边的,是和我…...

2026年吃油腻重口后的脾虚湿热腹泻辨证用药与中成药选购参考
日常饮食中,若长期或一次性摄入过多油腻、辛辣、重口味食物,可能会引发肠胃不适的一种常见类型。这类情况的相关知识、公开产品信息整理如下,本文仅做日常健康科普,不构成诊断、治疗或用药建议。一、公开提到的该类型肠胃不适的常…...

java篇12-Java中的异常
java中的异常是一个类,处理异常就是创建一个异常类对象并抛出这个对象,java处理异常的机制是中断,异常不是语法错了,语法错了编译不通过,不会产生字节码文件,不会运行,而异常是在运行过程中导致…...