数据分析过程中,发现数值缺失,怎么办?
按照数据缺失机制,数据分析过程中,我们可以将其分为以下几类:
(1)完全随机缺失(MCAR):所缺失的数据发生的概率既与已观察到的数据无关,也与未观察到的数据无关。
(2)随机缺失(MAR):假设缺失数据发生的概率与所观察到的变量是有关的,而与未观察到的数据的特征是无关的。MCAR与MAR均被称为是可忽略的缺失形式。
(3)不可忽略的缺失(NIM):亦称为非随机缺失,即如果不完全变量中,数据的缺失既依赖于完全变量又依赖于不完全变量本身,这种缺失即为不可忽略的缺失。
那么,对于缺失值,我们应该如何处理呢?
对于缺失值的处理,从总体上来说分为删除存在缺失值的个案和缺失值插补。对于主观数据,人将影响数据的真实性,存在缺失值的样本的其他属性的真实值不能保证,那么依赖于这些属性值的插补也是不可靠的,所以对于主观数据一般不推荐插补的方法。插补主要是针对客观数据,它的可靠性有保证。
1)删除含有缺失值的个案
有简单删除法和权重法。简单删除法是对缺失值进行处理的最原始方法。它将存在缺失值的个案删除。如果数据缺失问题可以通过简单的删除小部分样本来达到目标,那么这个方法是最有效的。
当缺失值的类型为非完全随机缺失的时候,可以通过对完整的数据加权来减小偏差。把数据不完全的个案标记后,将完整的数据个案赋予不同的权重,个案的权重可以通过logistic或probit回归求得。
如果解释变量中存在对权重估计起决定行因素的变量,那么这种方法可以有效减小偏差。如果解释变量和权重并不相关,它并不能减小偏差。对于存在多个属性缺失的情况,就需要对不同属性的缺失组合赋不同的权重,这将大大增加计算的难度,降低预测的准确性,这时权重法并不理想。
2)可能值插补缺失值
它的思想来源是以最可能的值来插补缺失值比全部删除不完全样本所产生的信息丢失要少。在数据挖掘中,面对的通常是大型的数据库,它的属性有几十个甚至几百个,因为一个属性值的缺失而放弃大量的其他属性值,这种删除是对信息的极大浪费,所以产生了以可能值对缺失值进行插补的思想与方法。常用的有如下几种方法。
(1)均值插补。数据的属性分为定距型和非定距型。如果缺失值是定距型的,就以该属性存在值的平均值来插补缺失的值;如果缺失值是非定距型的,就根据统计学中的众数原理,用该属性的众数(即出现频率最高的值)来补齐缺失的值。
(2)利用同类均值插补。同均值插补的方法都属于单值插补,不同的是,它用层次聚类模型预测缺失变量的类型,再以该类型的均值插补。假设X=(X1,X2…Xp)为信息完全的变量,Y为存在缺失值的变量,那么首先对X或其子集行聚类,然后按缺失个案所属类来插补不同类的均值。
如果在以后统计分析中还需以引入的解释变量和Y做分析,那么这种插补方法将在模型中引入自相关,给分析造成障碍。
(3)极大似然估计(ML)。在缺失类型为随机缺失的条件下,假设模型对于完整的样本是正确的,那么通过观测数据的边际分布可以对未知参数进行极大似然估计(Little and Rubin)。
这种方法也被称为忽略缺失值的极大似然估计,对于极大似然的参数估计实际中常采用的计算方法是期望值最大化(EM)。该方法比删除个案和单值插补更有吸引力,它一个重要前提:适用于大样本。有效样本的数量足够以保证ML估计值是渐近无偏的并服从正态分布。但是这种方法可能会陷入局部极值,收敛速度也不是很快,并且计算很复杂。
(4)多重插补(MI)。多值插补的思想来源于贝叶斯估计,认为待插补的值是随机的,它的值来自于已观测到的值。具体实践上通常是估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值。根据某种选择依据,选取最合适的插补值。多重插补方法分为三个步骤:
①为每个空值产生一套可能的插补值,这些值反映了无响应模型的不确定性;每个值都可以被用来插补数据集中的缺失值,产生若干个完整数据集合。
②每个插补数据集合都用针对完整数据集的统计方法进行统计分析;
③对来自各个插补数据集的结果,根据评分函数进行选择,产生最终的插补值。
假设一组数据,包括三个变量Y1,Y2,Y3,它们的联合分布为正态分布,将这组数据处理成三组,A组保持原始数据,B组仅缺失Y3,C组缺失Y1和Y2。在多值插补时,对A组将不进行任何处理,对B组产生Y3的一组估计值(作Y3关于Y1,Y2的回归),对C组作产生Y1和Y2的一组成对估计值(作Y1,Y2关于Y3的回归)。
当用多值插补时,对A组将不进行处理,对B、C组将完整的样本随机抽取形成为m组(m为可选择的m组插补值),每组个案数只要能够有效估计参数就可以了。对存在缺失值的属性的分布作出估计,然后基于这m组观测值,对于这m组样本分别产生关于参数的m组估计值,给出相应的预测即,这时采用的估计方法为极大似然法,在计算机中具体的实现算法为期望最大化法(EM)。对B组估计出一组Y3的值,对C将利用 Y1,Y2,Y3它们的联合分布为正态分布这一前提,估计出一组(Y1,Y2)。
上例中假定了Y1,Y2,Y3的联合分布为正态分布。这个假设是人为的,但是已经通过验证(Graham和Schafer于1999),非正态联合分布的变量,在这个假定下仍然可以估计到很接近真实值的结果。
多重插补和贝叶斯估计的思想是一致的,但是多重插补弥补了贝叶斯估计的几个不足。
(1)贝叶斯估计以极大似然的方法估计,极大似然的方法要求模型的形式必须准确,如果参数形式不正确,将得到错误得结论,即先验分布将影响后验分布的准确性。而多重插补所依据的是大样本渐近完整的数据的理论,在数据挖掘中的数据量都很大,先验分布将极小的影响结果,所以先验分布的对结果的影响不大。
(2)贝叶斯估计仅要求知道未知参数的先验分布,没有利用与参数的关系。而多重插补对参数的联合分布作出了估计,利用了参数间的相互关系。
以上四种插补方法,对于缺失值的类型为随机缺失的插补有很好的效果。两种均值插补方法是最容易实现的,也是以前人们经常使用的,但是它对样本存在极大的干扰,尤其是当插补后的值作为解释变量进行回归时,参数的估计值与真实值的偏差很大。
相比较而言,极大似然估计和多重插补是两种比较好的插补方法,与多重插补对比,极大似然缺少不确定成分,所以越来越多的人倾向于使用多重插补方法。
文章来源:网络 版权归原作者所有
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系小编,我们将立即处理
相关文章:

数据分析过程中,发现数值缺失,怎么办?
按照数据缺失机制,数据分析过程中,我们可以将其分为以下几类: (1)完全随机缺失(MCAR):所缺失的数据发生的概率既与已观察到的数据无关,也与未观察到的数据无关。 &#x…...
Vue3.0 toRef toRefs :VCA模式
简介 作用: 创建一个ref对象,其value值指向另一个对象中的某个属性 语法: const name toRef(person, name) 应用: 要将响应式对象中的某个属性单独供应给外部使用时 扩展: toRefs与toRef功能一致,但可…...

VS Code提取扩展时出错。XHR failed
需求:想要在扩展中心下载插件,发现报错 原因:vs code之前设置了代理,需要删除即可...

大模型需要哪类服务器
大模型需要高性能的服务器,以支持大规模的计算和存储需求。一般来说,大模型需要以下类型的服务器: 大型机:大型机可以提供强大的计算能力,适合处理大规模的数据和复杂的计算任务。 GPU服务器:GPU服务器可以…...
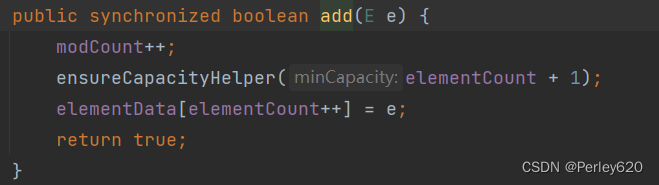
Java进阶(List)——面试时List常见问题解读 结合源码分析
前言 List、Set、HashMap作为Java中常用的集合,需要深入认识其原理和特性。 本篇博客介绍常见的关于Java中List集合的面试问题,结合源码分析题目背后的知识点。 关于的Set的博客文章如下: Java进阶(Set)——面试时…...
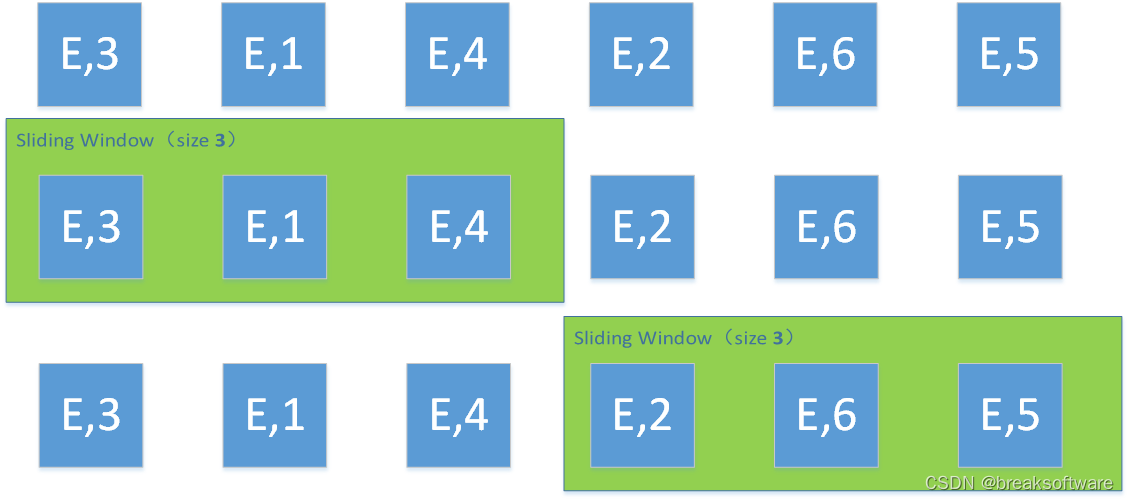
0基础学习PyFlink——个数滑动窗口(Sliding Count Windows)
大纲 滑动(Sliding)和滚动(Tumbling)的区别样例窗口为2,滑动距离为1窗口为3,滑动距离为1窗口为3,滑动距离为2窗口为3,滑动距离为3 完整代码参考资料 在 《0基础学习PyFlink——个数…...
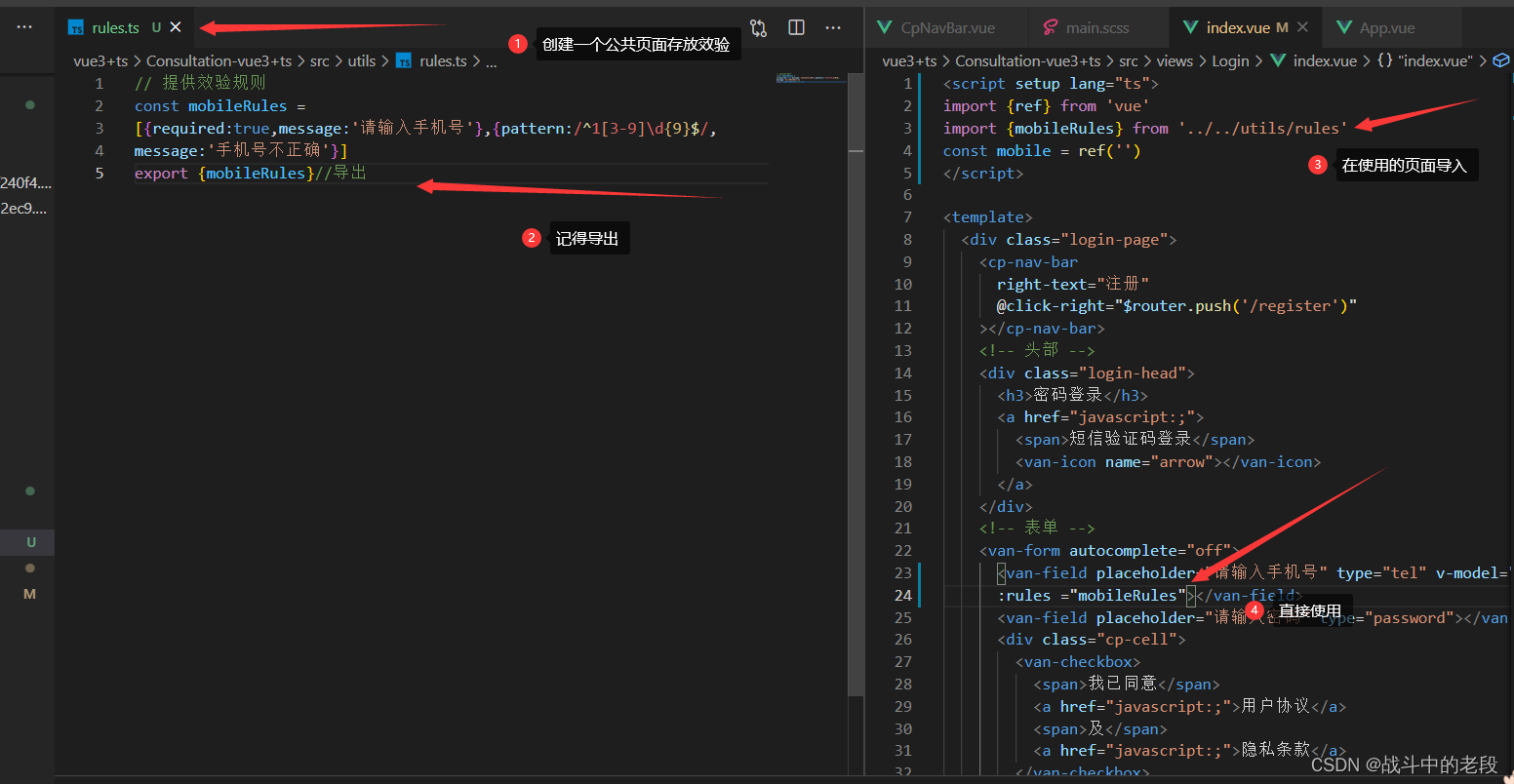
vue3+ts 提取公共方法
因为好多页面都会使用到这个效验规则,封装一个校检规则,方便维护 封装前 封装后...

C++ ->
C -> 是访问类或结构体对象的成员的运算符 注意这里不是直接的访问.是用于访问指向对象的指针的成员 下面的代码可以很好的理解如下: #include<iostream>using namespace std;class Func{public:int i,j;void myFunc(){cout<<"i"<&l…...

VR全景在医院的应用:缓和医患矛盾、提升医院形象
医患关系一直以来都是较为激烈的,包括制度的不完善、医疗资源紧张等问题也时有存在,为了缓解医患矛盾,不仅要提升患者以及家属对于医院的认知,还需要完善医疗制度,提高医疗资源的配置效率,提高服务质量。 因…...

【python基础】format格式化函数的使用
文章目录 前言一、format()内容匹配替换1、序号索引2、关键字3、列表索引4、字典索引5、通过类的属性6、通过魔法参数 二、format()数字格式化 前言 语法:str.format() 说明:一种格式化字符串的函数。 一、format()内容匹配替换 1、序号索引 在没有参…...
Java web(三):Http、Tomcat、Servlet
文章目录 一、Java web技术栈二、Http1.1 Http请求数据格式1.2 Http响应数据格式1.3 状态码 二、Tomcat2.1 介绍2.2 web项目结构2.3 IDEA中使用Tomcat 三、Servlet3.1 Servlet使用3.2 Servlet生命周期3.3 Servlet方法和体系结构3.4 urlPattern配置 四、Request4.1 获取请求数据…...
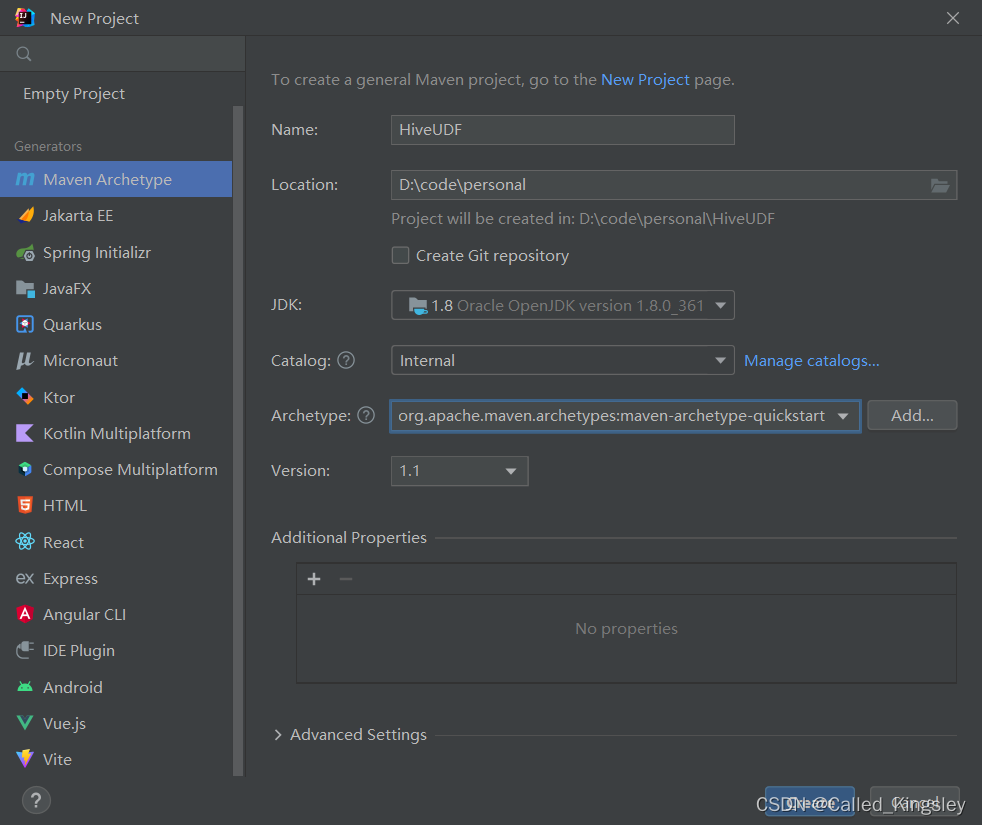
Java实现Hive UDF详细步骤 (Hive 3.x版本,IDEA开发)
这里写目录标题 前言1. 新建项目2.配置maven依赖3.编写代码4.打jar包5.上传服务器6.代码中引用 前言 老版本编写UDF时,需要继承 org.apache.hadoop.hive.ql.exec.UDF类,然后直接实现evaluate()方法即可。 由于公司hive版本比较高(3.x&#x…...
Apache的Access.log分析总结)
Vue进阶(幺陆肆)Apache的Access.log分析总结
文章目录 一、前言二、常用指令 一、前言 前端项目排错阶段,可借助apache的Access.log进行请求日志查看。 二、常用指令 #查看80端口的tcp连接 #netstat -tan | grep "ESTABLISHED" | grep ":80" | wc -l #当前WEB服务器中联接次数最多的ip地…...

Apple 苹果发布 M3、M3 Pro 和 M3 Max 芯片
本心、输入输出、结果 文章目录 Apple 苹果发布 M3、M3 Pro 和 M3 Max 芯片前言M3、M3 Pro 和 M3 Max 芯片的性能相关资料图M3 Pro规格M3 Max规格弘扬爱国精神 Apple 苹果发布 M3、M3 Pro 和 M3 Max 芯片 编辑:简简单单 Online zuozuo 地址:https://blog…...

Linux常用命令及主流服务部署大全
目录 Linux 系统目录 一、常用操作命令 1、目录操作 2、文件内容操作(查看日志,更改配置文件) 3、压缩和解压缩 4、更改文件权限 二、各服务部署命令 1、增加虚拟内存 2、JDK 2.1 删除系统自带的openjdk 2.2 安装jdk 2.3 删除jd…...

list-watch集群调度
调度约束 Kubernetes 是通过 List-Watch **** 的机制进行每个组件的协作,保持数据同步的,每个组件之间的设计实现了解耦。 用户是通过 kubectl 根据配置文件,向 APIServer 发送命令,在 Node 节点上面建立 Pod 和 Container。…...

深度强化学习中的神经网络部分的作用是什么?一般如何选择合适的神经网络呢?
在深度强化学习中,神经网络部分通常用于实现值函数近似或策略近似,以帮助智能体学习如何在一个环境中做出决策以获得最大的累积奖励。这些神经网络在深度强化学习中扮演着重要的角色,具体作用如下: 1.值函数近似(Valu…...

若依系统的数据导入功能设置
一、后端 Log(title "公交站牌", businessType BusinessType.IMPORT)PreAuthorize("ss.hasPermi(busStop:busStop:import)")PostMapping("/importData")public AjaxResult importData(MultipartFile file, boolean updateSupport) throws Exce…...

vue页面父组件与子组件相互调用方法和传递参数值
vue页面父组件与子组件相互调用方法和传递参数值 父组件页面定义 <el-button type"text" icon"el-icon-refresh" click"refreshClick" slot"label"></el-button> <leftList leftClick"loadModelClick" r…...
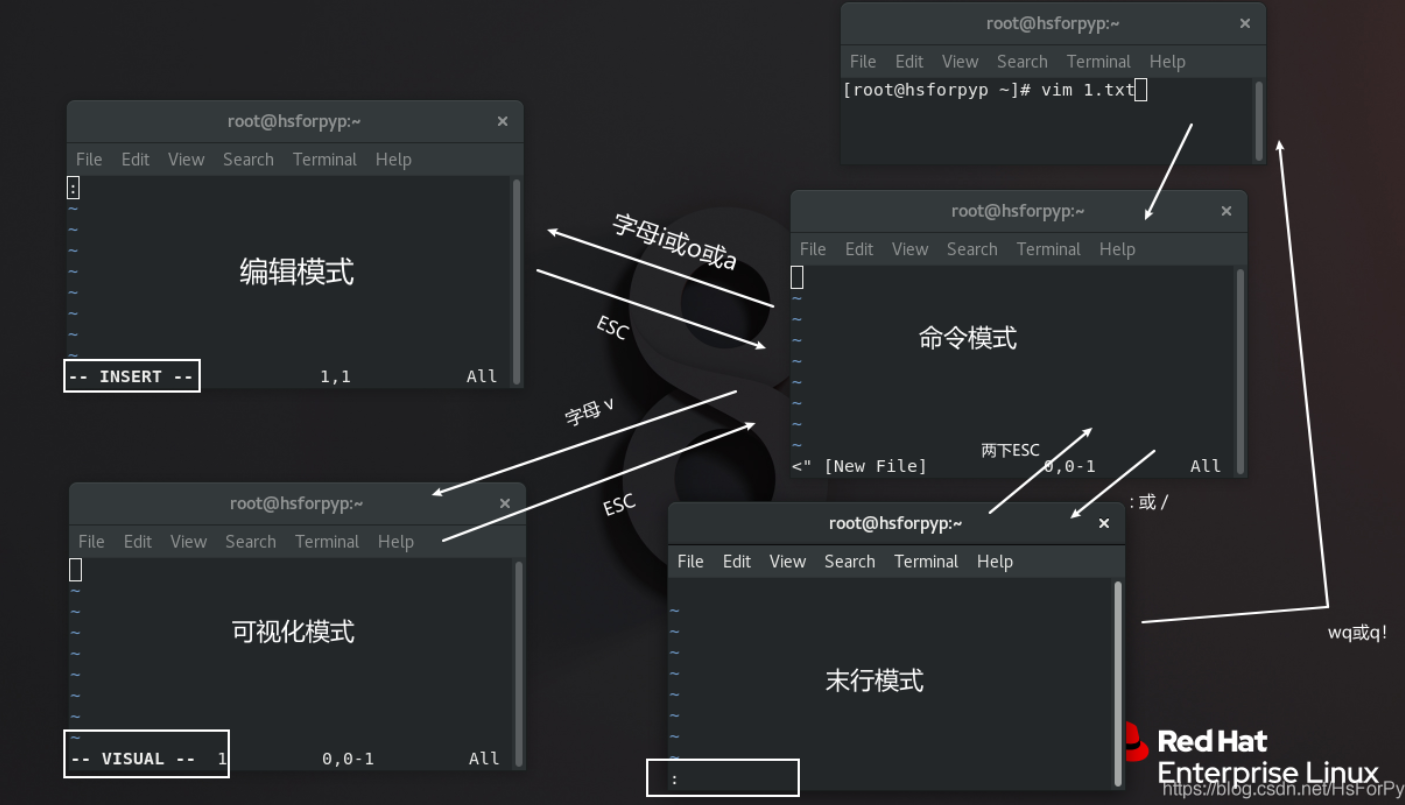
vim使用
概述 vi(visual editor)是Unix/Linux编辑器的一种。类似于win中notepad。vim(vi improved)加强版 安装vim: $ yum install vim -y四种模式 命令模式:快速进行复制、粘贴、删除等操作,还可以…...

森林The Forest - 服务器开服
对于想要自建游戏服务器的玩家,云鸢互联是一个不错的专业联机平台选择。它提供稳定、低延迟且724小时在线的服务器环境,助你轻松打造专属游戏世界。平台主打极致的新手友好——全图形化控制面板,无需编写代码,也无需掌握Linux命令…...
)
Linux】2026 年 13 款最强视频播放器(含安装命令 + 优缺点)
Linux视频播放器选择多样,如榛名、MPlayer、VLC等,功能强大、支持多格式,满足各类用户需求 一、榛名视频播放器 榛名视频播放器是一款基于Qt的开源视频播放器,提供了许多基本功能。其特点包括支持Youtube-dl、控制播放速度、丰富…...

【Sora 2批量视频生成黄金工作流】:实测吞吐提升4.8倍的关键配置——NVIDIA A100集群下每小时稳定输出217段1080p视频
更多请点击: https://codechina.net 第一章:Sora 2批量视频生成工作流全景概览 Sora 2作为新一代多模态视频生成模型,其批量处理能力依托于模块化、可编排的端到端工作流设计。该工作流融合提示工程、时空 latent 编码、分块并行解码与后处理…...

【OpenClaw 进阶配置】如何让 MiniMax 搜索替代 SearXNG 作为 Web Search provider
【OpenClaw 进阶配置】如何让 MiniMax 搜索替代 SearXNG 作为 Web Search provider 标签: OpenClaw / MiniMax / 配置教程 / AI工具 踩坑记录 + 完整配置方案 前言 最近在配置 OpenClaw 的 web_search 工具,遇到了一个有意思的问题:明明已经在 tools.web.search.provider …...

利亚德沙特LED视效工厂预计7月投产,Micro LED本地交付进入中东
今天讲的出海案例是利亚德,这家 1995 年成立、从 LED 显示产品研发生产销售起步,并做到小间距和 Micro LED 的视效科技公司,沙特工厂预计 2026 年 7 月投产。在 2026 年 5 月的投资者关系活动记录表中,利亚德光电股份有限公司回应…...

RoboMaster电调通信协议逆向解析:如何用逻辑分析仪抓包调试CAN总线数据
RoboMaster电调通信协议逆向解析:如何用逻辑分析仪抓包调试CAN总线数据 当电机突然停止响应,或是反馈数据出现异常时,大多数开发者会陷入反复检查代码的循环。但真正的解决方案往往隐藏在那些肉眼不可见的CAN总线数据流中。本文将带你用逻辑…...

Go语言模板引擎与前端渲染实战
Go语言模板引擎与前端渲染实战 引言 模板引擎是Web开发中连接后端数据与前端展示的关键组件。Go语言标准库提供了强大的模板引擎,本文将深入探讨其使用方法和最佳实践。 一、Go模板引擎基础 1.1 text/template与html/template // text/template - 纯文本模板 import…...
 ;CLQTRLELYKQGLRGSLTKLKGPLT)
GM-CSF (54-78) ;CLQTRLELYKQGLRGSLTKLKGPLT
一、基础信息中文名称:粒细胞 - 巨噬细胞集落刺激因子片段 (54-78)英文名称:Granulocyte-Macrophage Colony-Stimulating Factor (54-78)三字母序列:Cys-Leu-Gln-Thr-Arg-Leu-Glu-Leu-Tyr-Lys-Gln-Gly-Leu-Arg-Gly-Ser-Leu-Thr-Lys-Leu-Lys-G…...

3步解决游戏手柄兼容性问题:XOutput完全指南
3步解决游戏手柄兼容性问题:XOutput完全指南 【免费下载链接】XOutput DirectInput to XInput wrapper 项目地址: https://gitcode.com/gh_mirrors/xo/XOutput 你是否遇到过这样的尴尬时刻?心爱的旧手柄在最新游戏里毫无反应,或者新买…...

突破语言壁垒:AI驱动视频学习工具LLPlayer完全指南
突破语言壁垒:AI驱动视频学习工具LLPlayer完全指南 【免费下载链接】LLPlayer The media player for language learning, with dual subtitles, AI-generated subtitles, real-time translation, and more! 项目地址: https://gitcode.com/gh_mirrors/ll/LLPlayer…...