动手学深度学习——残差网络ResNet(原理解释+代码详解)
残差网络ResNet
- 1. 函数类
- 2. 残差块
- 3. ResNet模型
- 4. 训练模型
ResNet为了解决“新添加的层如何提升神经网络的性能”,它在2015年的ImageNet图像识别挑战赛夺魁
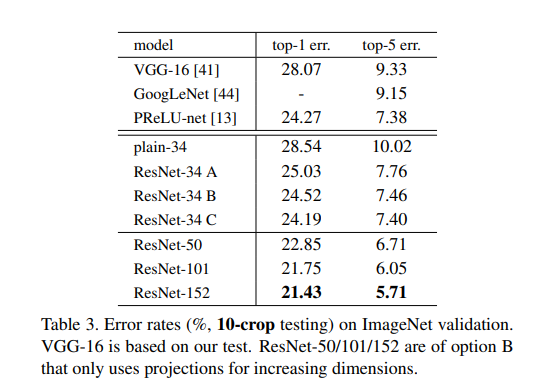
它深刻影响了后来的深度神经网络的设计,ResNet的被引用量更是达到了19万+。

1. 函数类
假设有一类特定的神经网络架构F,它包括学习速率和其他超参数设置。对于所有f∈F,存在一些参数集(例如权重和偏置),这些参数可以通过在合适的数据集上进行训练而获得。
现在假设 f* 是我们真正想要找到的函数,如果是 f*∈F,那可以轻而易举的训练得到它。
给定一个具有X特性和y标签的数据集
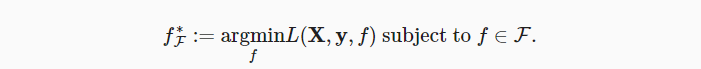
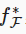 是我们要找的函数,为了使其更近似真正的 f* ,则需要更强的架构F’。
是我们要找的函数,为了使其更近似真正的 f* ,则需要更强的架构F’。
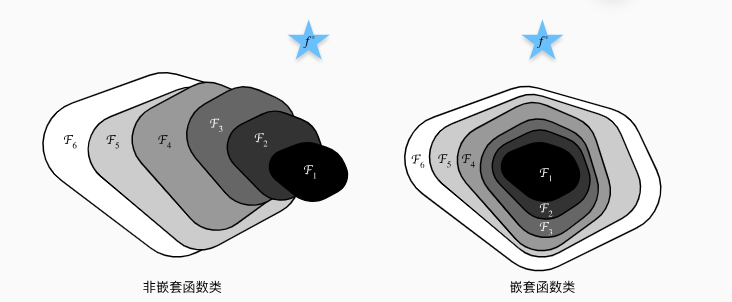
对于非嵌套函数类,较复杂的函数类并不总是向“真”函数 f* 靠拢(复杂度由F1向F6递增)。虽然F3比F1更接近 f*,但却离F6的更远了。
而右侧的嵌套函数可以避免上述问题。
2. 残差块
残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
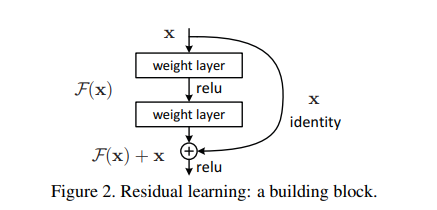
F(x) + x包含了原始元素。
ResNet沿用了VGG完整的3x3卷积层设计。
- 残差块里首先有2个有相同输出通道数的3x3卷积层。
- 每个卷积层后接一个批量规范化层和ReLU激活函数。
- 然后通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。
import torch
from torch import nn
from torch.nn import functional as F
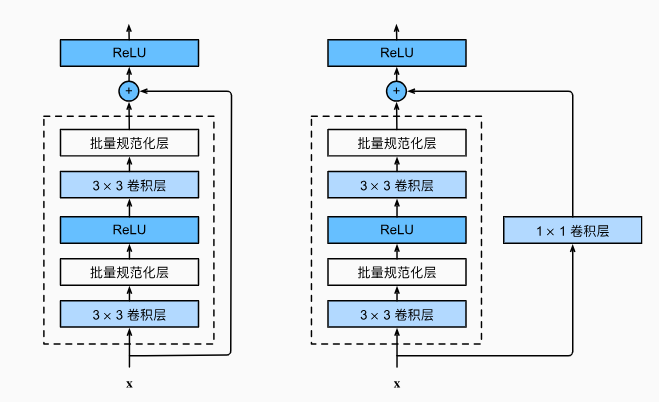
from d2l import torch as d2lclass Residual(nn.Module): #@save# use_ixiconv:残差连接是直接连接还是通过卷积层连接def __init__(self, input_channels, num_channels,use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += X return F.relu(Y)
此代码生成两种类型的网络:
- 一种是当use_1x1conv=False时,应用ReLU非线性函数之前,将输入添加到输出。
- 另一种是当use_1x1conv=True时,添加通过1x1卷积调整通道和分辨率。
 查看输入和输出形状一致的情况
查看输入和输出形状一致的情况
# 输入、输出的情况
blk = Residual(3, 3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape

在增加输出通道数的同时,减半输出的高和宽
# 增加输出通道的同时,减半输出的高度和宽度
blk = Residual(3, 6, use_1x1conv=True, strides=2)
blk(X).shape

3. ResNet模型
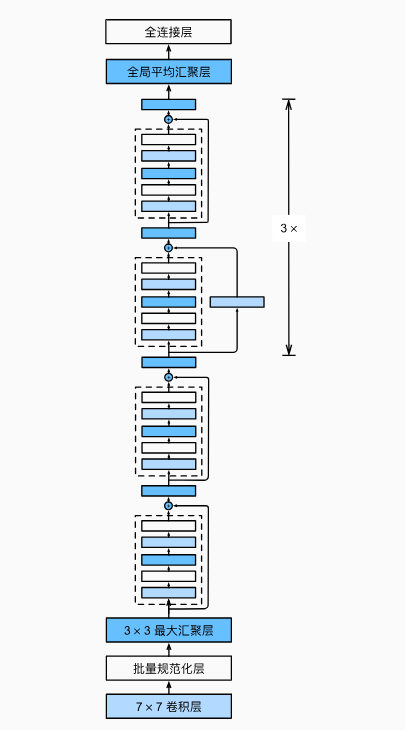
ResNet的前两层跟之前介绍的GoogLeNet中的一样: 在输出通道数为64、步幅为2的7x7卷积层后,接步幅为2的3x3的最大汇聚层。 不同之处在于ResNet每个卷积层后增加了批量规范化层。
# ResNet在每个卷积层后增加了批量规范层
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
ResNet使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。
第一个模块的通道数同输入通道数一致。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
# 实现残差连接模块:由4个残差连接块组成
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):# 定义空网络结构blk = []for i in range(num_residuals):# 第2,3,4个Inception块的第一个残差模块连接1x1卷积层if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blk
接着在ResNet加入所有残差块,这里每个模块使用2个残差块。
# 在ResNet加入所有残差块,每个模版使用2个残差块
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
最后在ResNet中加入全局平均汇聚层,以及全连接层输出。
# 在ResNet加入全局平均汇聚层以及全连接层输出
net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(), nn.Linear(512, 10))
每个模块有4个卷积层,加上第一个7x7卷积层和最后一个全连接层,共有18层,这种模型通常被称为ResNet-18。
观察一下ResNet中不同模块的输入形状是如何变化
# 每个模块有4个卷积层(不包括恒等映射的1x1卷积层)。
# 加上第一个7x7卷积层和最后一个全连接层,共有18层。
# 因此,这种模型通常被称为ResNet-18。
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:X = layer(X)print(layer.__class__.__name__, 'output_shape:\t', X.shape)

4. 训练模型
在Fashion-MNIST数据集上训练ResNet
定义精度评估函数
"""定义精度评估函数:1、将数据集复制到显存中2、通过调用accuracy计算数据集的精度
"""
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save# 判断net是否属于torch.nn.Module类if isinstance(net, nn.Module):net.eval()# 如果不在参数选定的设备,将其传输到设备中if not device:device = next(iter(net.parameters())).device# Accumulator是累加器,定义两个变量:正确预测的数量,总预测的数量。metric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:# 将X, y复制到设备中if isinstance(X, list):# BERT微调所需的(之后将介绍)X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)# 计算正确预测的数量,总预测的数量,并存储到metric中metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1]
定义GPU训练函数
"""定义GPU训练函数:1、为了使用gpu,首先需要将每一小批量数据移动到指定的设备(例如GPU)上;2、使用Xavier随机初始化模型参数;3、使用交叉熵损失函数和小批量随机梯度下降。
"""
#@save
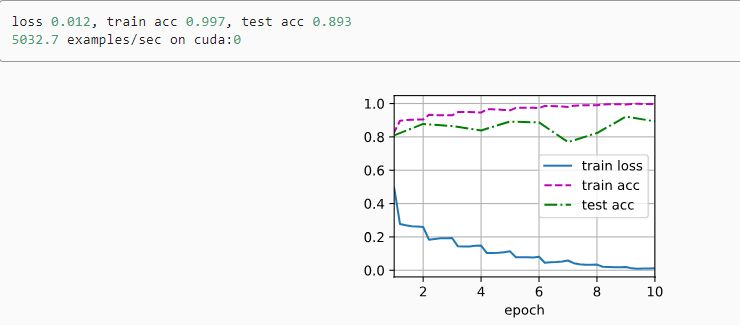
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU训练模型(在第六章定义)"""# 定义初始化参数,对线性层和卷积层生效def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)# 在设备device上进行训练print('training on', device)net.to(device)# 优化器:随机梯度下降optimizer = torch.optim.SGD(net.parameters(), lr=lr)# 损失函数:交叉熵损失函数loss = nn.CrossEntropyLoss()# Animator为绘图函数animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])# 调用Timer函数统计时间timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):# Accumulator(3)定义3个变量:损失值,正确预测的数量,总预测的数量metric = d2l.Accumulator(3)net.train()# enumerate() 函数用于将一个可遍历的数据对象for i, (X, y) in enumerate(train_iter):timer.start() # 进行计时optimizer.zero_grad() # 梯度清零X, y = X.to(device), y.to(device) # 将特征和标签转移到devicey_hat = net(X)l = loss(y_hat, y) # 交叉熵损失l.backward() # 进行梯度传递返回optimizer.step()with torch.no_grad():# 统计损失、预测正确数和样本数metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop() # 计时结束train_l = metric[0] / metric[2] # 计算损失train_acc = metric[1] / metric[2] # 计算精度# 进行绘图if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))# 测试精度test_acc = evaluate_accuracy_gpu(net, test_iter) animator.add(epoch + 1, (None, None, test_acc))# 输出损失值、训练精度、测试精度print(f'loss {train_l:.3f}, train acc {train_acc:.3f},'f'test acc {test_acc:.3f}')# 设备的计算能力print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec'f'on {str(device)}')

训练模型
# 训练模型
lr, num_epochs, batch_size = 0.05, 10 ,256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
相关文章:
动手学深度学习——残差网络ResNet(原理解释+代码详解)
残差网络ResNet 1. 函数类2. 残差块3. ResNet模型4. 训练模型 ResNet为了解决“新添加的层如何提升神经网络的性能”,它在2015年的ImageNet图像识别挑战赛夺魁 它深刻影响了后来的深度神经网络的设计,ResNet的被引用量更是达到了19万。 1. 函数类 假…...
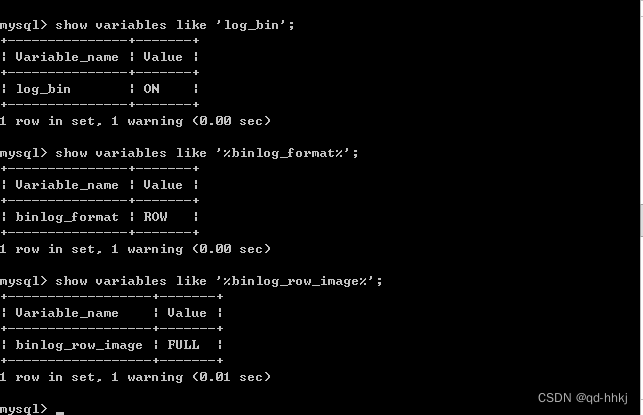
MYSQL 8.0 配置CDC(binlog)
CDC(Change Data Capture)即数据变更抓取,通过源端数据源开启CDC,ROMA Connect 可实现数据源的实时数据同步以及物理表的物理删除同步。这里介绍通过开启Binlog模式CDC功能。 注意:1、使用MYSQL8.0及以上版本。 2、不…...
软件测试/测试开发丨ChatGPT能否成为PPT最佳伴侣
点此获取更多相关资料 简介 PPT 已经渗透到我们的日常工作中,无论是工作汇报、商务报告、学术演讲、培训材料都常常要求编写一个正式的 PPT,协助完成一次汇报或一次演讲。PPT相比于传统文本的就是有布局、图片、动画效果等,可以给到观众更好…...

java对象的创建过程
一.类的加载与检查 当我们new了一个对象的时候,首先会去检查一下这个指令是否在常量池中存在符号引用,并且检查这个符号引用代表的对象是否被加载,解析初始化过,如果没有就要先去进行类加载过程 二.分配内存 我们通过第一步的检…...

Salesforce创建一个页面,能够配置各种提示语,而不需要修改代码
在Salesforce中创建一个页面,并使其能够配置各种提示语,可以使用自定义设置、自定义对象或自定义标签等方法来实现。以下是一种常见的方法: 自定义对象或自定义设置:您可以创建一个自定义对象或自定义设置来存储各种提示语的信息。…...

轻松管理MySQL权限:Python脚本带你飞
数据库管理是 IT 专家和开发者日常工作中的重要组成部分。一个合适的用户权限管理系统不仅确保了数据的安全性,还能确保数据能够按照预期的方式被正确地访问和修改。在本文中,我们将探讨如何使用 Python 脚本来管理和查询 MySQL 数据库中的用户权限。 用户权限管理:创建或修…...
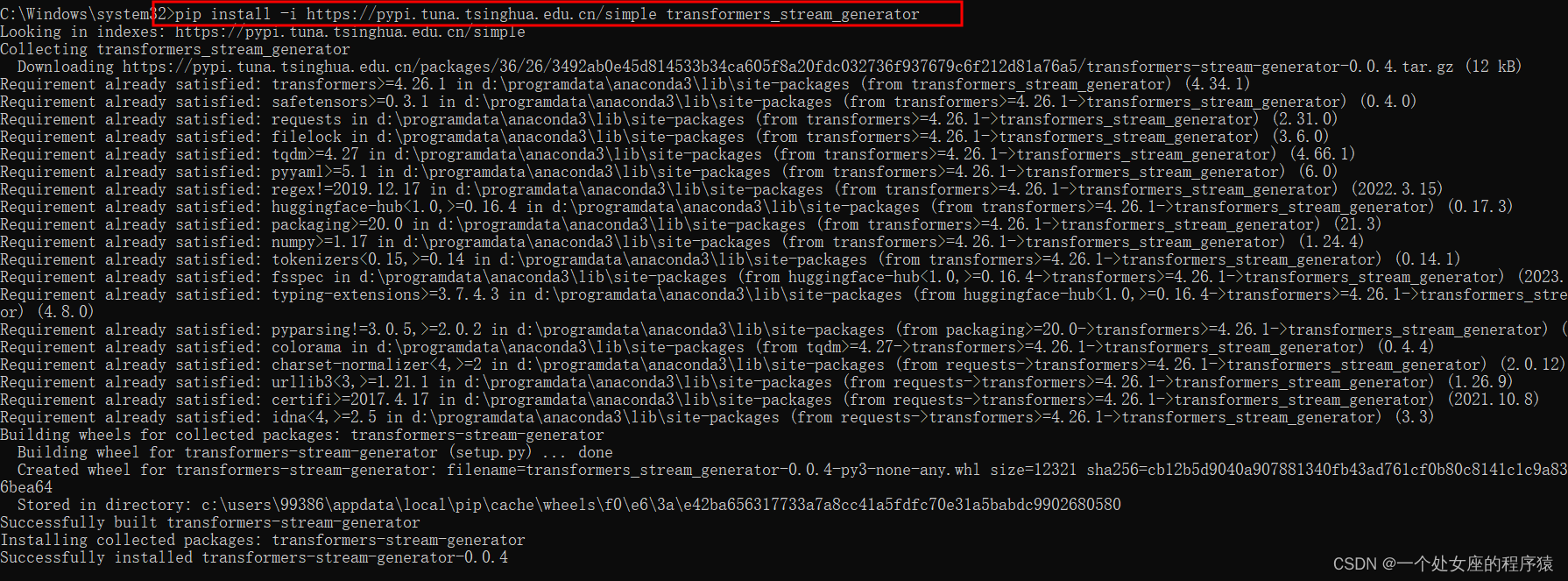
Py之transformers_stream_generator:transformers_stream_generator的简介、安装、使用方法之详细攻略
Py之transformers_stream_generator:transformers_stream_generator的简介、安装、使用方法之详细攻略 目录 transformers_stream_generator的简介 1、Web Demo T1、original T2、stream transformers_stream_generator的安装 transformers_stream_generator的…...
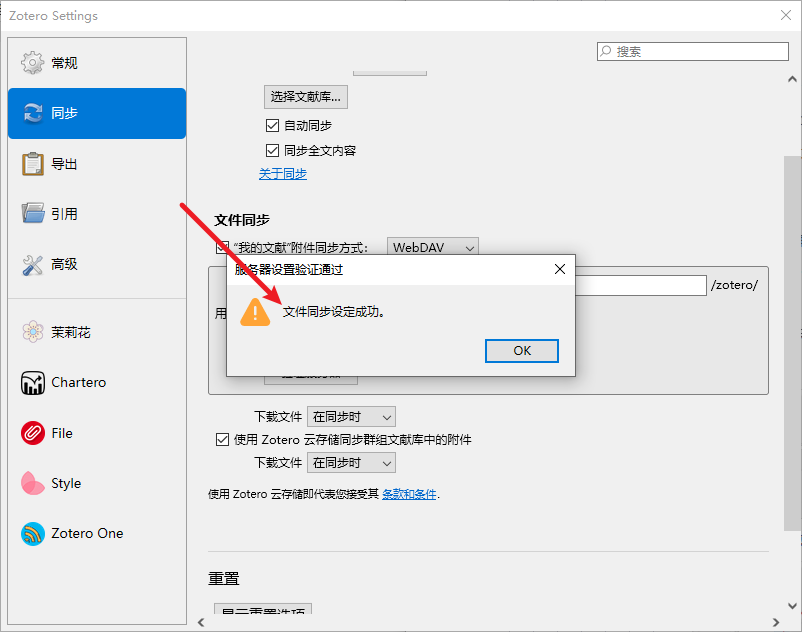
2023年Zotero最新同步教程-使用TeraCloud的25G免费空间实时跨设备同步文献
文章目录 1. 前言2.1. 注册账号2.1.1. 填写注册信息2.1.2. 创建账号成功2.1.3. 注意2.2. 扩容空间2.3. 打开WebDAV 3. Zotero配置WebDAV同步3.1. 设置网址3.2. 验证服务器3.3. 文件同步成功 4. 结语 1. 前言 Zotero免费版的存储空间是300m,一个图文PDF动辄两三M&am…...
,即交换两数。)
面试题:用宏定义写出swap(x,y),即交换两数。
鼠标选中查看答案↓: #define swap(x,y) do{(x)(x)(y);(y)(x)-(y);(x)(x)-(y);}while(0) 这个题考查宏定义的语法,尤其是多行代码的宏定义,加上do{}while(),,可以保证这些语句只执行一次。...
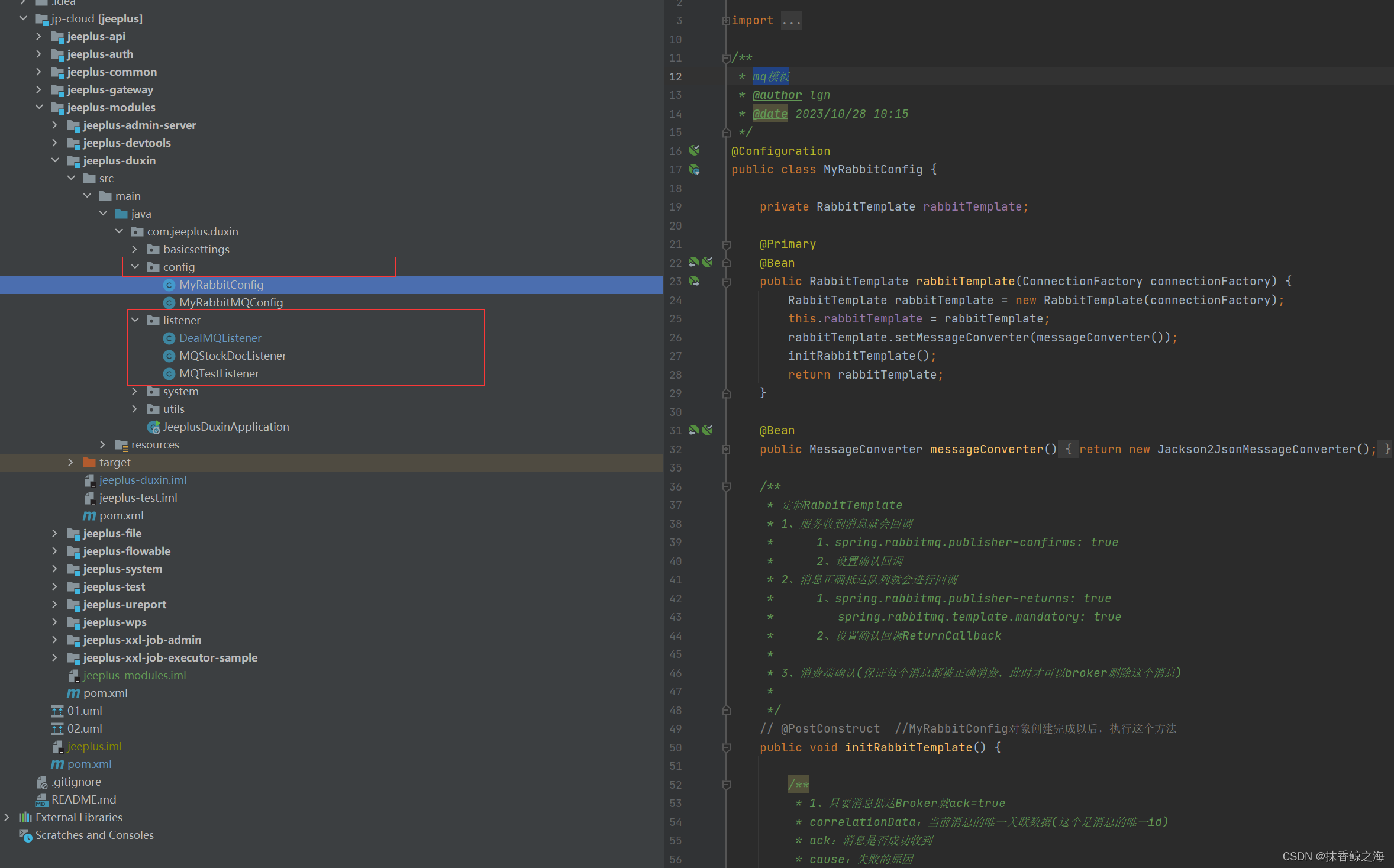
微服务框架SpringcloudAlibaba+Nacos集成RabbitMQ
目前公司使用jeepluscloud版本,这个版本没有集成消息队列,这里记录一下,集成的过程;这个框架跟ruoyi的那个微服务版本结构一模一样,所以也可以快速上手。 1.项目结构图: 配置类的东西做成一个公共的模块 …...

低代码开发,一场深度的IT效率革命
目录 一、前言 二、低代码迅速流行的理由 三、稳定性和生产率的最佳实践 四、程序员用低代码开发应用有哪些益处? 1、提升开发价值 2、利于团队升级 五、总结 一、前言 尽管IT技术支撑了全球的信息化浪潮,然而困扰行业已久的软件开发效率并未像摩尔定律那…...
虚拟串口软件使用介绍
对于上位机开发来说(特别是串口通信应用),上机位软件的调试尤为重要,但是上机位软件的调试并不关心硬件,只需要关注验证发送的数据帧的接收情况,为了便于调试,可以将上机位软件与串口软件互通,实现数据的交互,但由于互通需要串口,可以借助串口虚拟软件(VSPD),虚拟出…...
如何编写一份完整的软件测试报告?(进阶版)百分之90不知道
背景 作为测试从业者,编写测试用例,测试计划,测试报告都是必经之路,最近完成了年终述职以及版本准出,感觉测试报告或者各类报告真是职场人不可或缺的一项技能,趁着热乎劲🔥,写下一些…...

python企业微信小程序发送信息
python企业微信小程序发送信息 在使用下面代码之前先配置webhook 教程如下: https://www.bilibili.com/video/BV1oH4y1S7pN/?vd_sourcebee29ac3f59b719e046019f637738769 然后使用如下代码就可以发消息了: 代码如下: #codinggbk import r…...

Java入门篇 之 逻辑控制(练习题篇)
博主碎碎念: 练习题是需要大家自己打的请在自己尝试后再看答案哦; 个人认为,只要自己努力在将来的某一天一定会看到回报,在看这篇博客的你,不就是在努力吗,所以啊,不要放弃,路上必定坎坷&#x…...
)
Android Google登录并获取token(亲测有效)
背景: Android 需要用到Google的登录授权,用去token给到服务器,服务器再通过token去获取用户信息,实现第三方登录。 我们通过登录之后的email来获取token,不需要server_clientId;如果用server_clientId还…...

npm ERR! code ELIFECYCLE
问题: 一个老项目,现在想运行下,打不开了 npm install 也出错 尝试1 、使用cnpm npm install -g cnpm --registryhttps://registry.npm.taobao.org cnpm install 还是不行 尝试2、 package.json 文件,去掉 那个插件 chorm…...
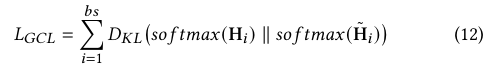
Mgeo:multi-modalgeographic language model pre-training
文章目录 question5.1 Geographic Encoder5.1.1 Encoding5.1.2 5.2 multi-modal pre-training 7 conclusionGeo-Encoder: A Chunk-Argument Bi-Encoder Framework for Chinese Geographic Re-Rankingabs ERNIE-GeoL: A Geography-and-Language Pre-trained Model and its Appli…...
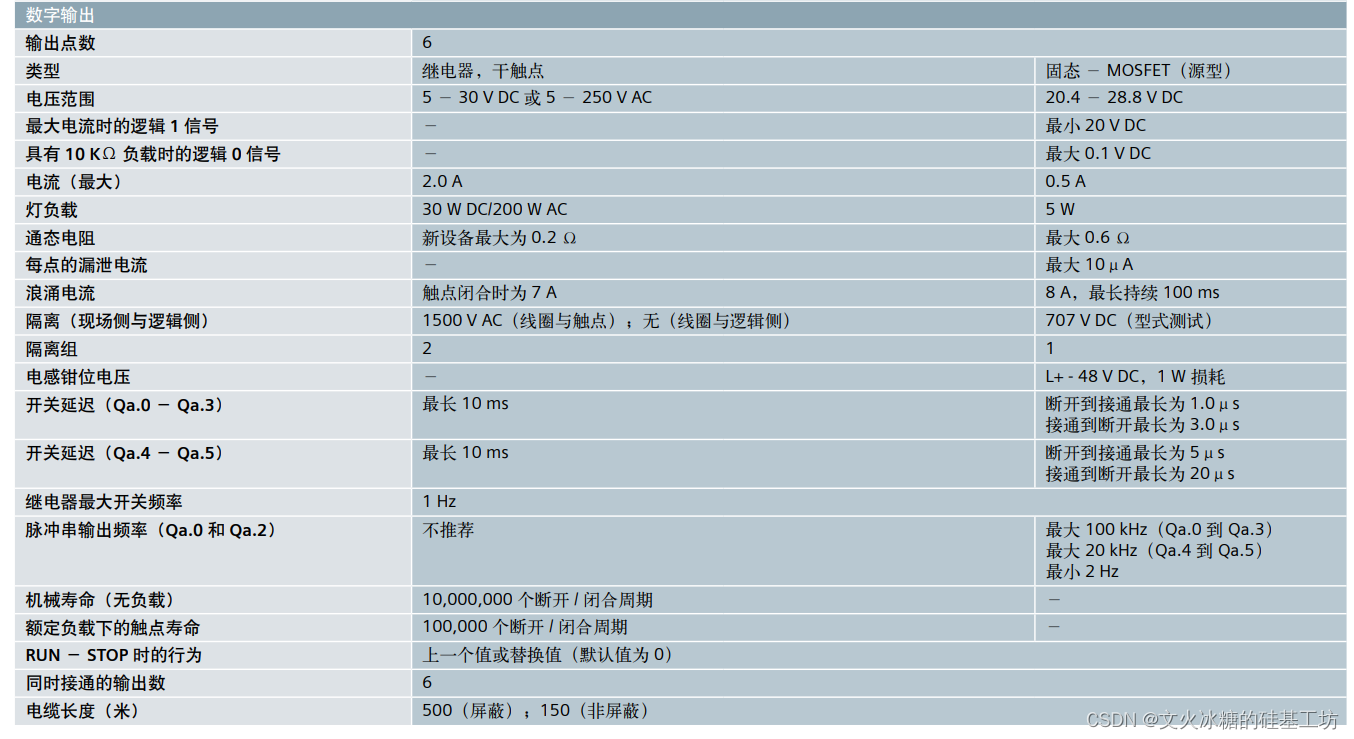
[激光原理与应用-75]:西门子PLC系列选型
目录 一、西门子PLC PLC系列 二、西门子PLC S7 1200系列 2.1 概述 2.2 12xx系列比较 三、西门子 PLC 1212C系列 四、主要类别比较 4.1 AC/DC/RLY的含义 4.2 AC/DC/RLY与DC/DC/DC 4.3 直流输入与交流输入比较 4.4 继电器输出与DC输出的区别 一、西门子PLC PLC系列 …...

Linux上编译sqlite3库出现undefined reference to `sqlite3_column_table_name‘
作者:朱金灿 来源:clever101的专栏 为什么大多数人学不会人工智能编程?>>> 在Ubuntu 18上编译sqlite3库后在运行程序时出现undefined reference to sqlite3_column_table_name’的错误。网上的说法是说缺少SQLITE_ENABLE_COLUMN_M…...

GitHub中文插件终极指南:3分钟让英文GitHub变母语界面
GitHub中文插件终极指南:3分钟让英文GitHub变母语界面 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 还在为GitHub的英文…...
)
手把手复现:用GCC编译选项关闭栈保护,一步步演示缓冲区溢出攻击(附完整代码)
从零构建缓冲区溢出攻击实验:GCC编译选项与漏洞利用实战指南 缓冲区溢出攻击作为系统安全领域的经典课题,至今仍在各类CTF竞赛和实际渗透测试中频繁出现。对于刚接触底层安全的研究者而言,亲手复现一次完整的溢出攻击过程,远比阅读…...

告别轮询!手把手教你用S32K3的FlexCAN Enhanced FIFO+DMA实现高效CAN FD数据接收
告别轮询!手把手教你用S32K3的FlexCAN Enhanced FIFODMA实现高效CAN FD数据接收 在汽车电子和工业控制领域,CAN FD总线的高负载场景对MCU的实时性提出了严苛挑战。当波特率飙升至5Mbps、单帧数据扩展到64字节时,传统的中断接收模式会让CPU陷入…...
:解锁摄像头与雷达融合的3D感知新范式)
跨域空间匹配(CDSM):解锁摄像头与雷达融合的3D感知新范式
1. 为什么自动驾驶需要跨域空间匹配技术 当你坐在一辆自动驾驶汽车里,最不希望看到的就是系统把前方停着的卡车误判成广告牌。这种错误在单一传感器系统中其实很常见——摄像头可能因为逆光看不清物体轮廓,雷达又难以识别物体的具体形状。这就是为什么我…...

从Caffeine源码到实战:手把手教你用Checker Framework给Java代码做‘体检’
从Caffeine源码到实战:手把手教你用Checker Framework给Java代码做‘体检’ 在阅读Caffeine这样的高质量开源项目时,细心的开发者常会注意到一些独特的编译注解——比如Nullable、GuardedBy这类标记。这些看似简单的注解背后,其实隐藏着一个强…...

UCCL:GPU网络传输的性能优化与创新
1. UCCL:GPU网络传输的革命性创新在分布式机器学习训练场景中,GPU集群间的通信效率往往成为制约系统整体性能的关键瓶颈。传统基于TCP/IP的传输协议由于内核协议栈处理和多次数据拷贝等问题,难以满足现代AI训练任务对低延迟和高带宽的严苛要求…...

【YOLOv5 v6.1】从零到一:手把手实战自定义数据集训练与部署避坑指南
1. 环境准备:从零搭建YOLOv5训练环境 第一次接触YOLOv5时,我最头疼的就是环境配置。这里分享一个经过多次验证的稳定方案,适用于大多数NVIDIA显卡设备。首先需要安装Anaconda,这是管理Python环境的利器。我习惯用Miniconda&#x…...

不止于安装:用Docker在5分钟内快速搭建可复用的ROS Noetic开发环境
5分钟构建可移植ROS开发环境:Docker容器化实战指南 在机器人开发领域,环境配置一直是令人头疼的问题。不同项目依赖的ROS版本冲突、系统库不兼容、团队协作时环境不一致…这些痛点消耗着开发者宝贵的时间。传统安装方式就像在主机上直接"装修"…...

Grounding DINO:从零解析跨模态开放集检测的架构革新与实战
1. 开放集检测的革命:为什么需要Grounding DINO? 当你在手机相册里搜索"海边日落"时,传统视觉模型只能匹配预设的"沙滩""太阳"等标签,而Grounding DINO却能真正理解语义——这就是开放集检测的魅力…...
)
Windows 10/11下,手把手教你用Python2和Git搞定GitHack(附常见错误解决)
Windows 10/11下Python2与Git环境搭建及GitHack实战指南 在网络安全和CTF竞赛领域,.git文件夹泄露是一个常见但危险的漏洞。GitHack作为一款专门针对此类漏洞的利用工具,能够帮助安全研究人员快速还原网站源代码。本文将详细介绍在Windows 10/11系统上配…...