2-爬虫-代理池搭建、代理池使用(搭建django后端测试)、爬取某视频网站、爬取某视频网站、bs4介绍和遍历文档树
1 代理池搭建
2 代理池使用
2.1 搭建django后端测试
3 爬取某视频网站
4爬取某视频网站
5 bs4介绍和遍历文档树
1 代理池搭建
# ip代理-每个设备都会有自己的IP地址-电脑有ip地址---》访问一个网站---》访问太频繁---》封ip-收费:靠谱稳定--提供api-免费:不稳定--自己写api用-开源的:https://github.com/jhao104/proxy_pool免费代理---》爬取免费代理---》验证---》存到redis中flask搭建web---》访问某个接口,随机获取ip# 搭建步骤:1 git clone git@github.com:jhao104/proxy_pool.git2 pycharm中打开3 安装依赖:创建虚拟环境 pip install -r requirements.txt4 修改配置文件: DB_CONN = 'redis://127.0.0.1:6379/0'5 运行调度程序和web程序# 启动调度程序python proxyPool.py schedule# 启动webApi服务python proxyPool.py server6 api介绍/ GET api介绍 None/get GET 随机获取一个代理 可选参数: ?type=https 过滤支持https的代理/pop GET 获取并删除一个代理 可选参数: ?type=https 过滤支持https的代理/all GET 获取所有代理 可选参数: ?type=https 过滤支持https的代理/count GET 查看代理数量 None/delete GET 删除代理 ?proxy=host:ip# http和https代理-以后使用http代理访问http的地址-使用https的代理访问https的地址
2 代理池使用
"公网" 和 "内网" 是网络术语,用于描述不同的网络范围和可访问性。以下是它们的定义和示例:**公网 (Internet)**:- **定义:** 公网是指全球范围的互联网,连接了世界各地的计算机、服务器和设备,允许它们通过因特网协议(IP)进行通信。- **示例:** - 当您使用浏览器访问网站,例如 Google、Facebook 或 Twitter,您是通过公网与这些网站的服务器通信。- 电子邮件发送和接收也是通过公网进行的,例如使用 Gmail 或 Outlook 邮箱。- 在社交媒体上与全球范围内的朋友互动,如发布推文、分享照片或发布视频。**内网 (Intranet)**:- **定义:** 内网是指一个私有网络,通常在组织、公司或机构内部使用,用于内部通信、数据共享和资源管理。它通常不直接连接到公网。- **示例:** - 企业内部网络:大多数组织都有内部网络,用于员工之间的通信和共享内部资源。这些网络可以包括内部网站、文件共享和内部电子邮件系统。- 家庭网络:在家庭网络中,您可以有多个设备(例如台式电脑、笔记本电脑、智能手机、智能家居设备等)连接到一个本地路由器,形成一个内部网络。这个内部网络允许这些设备共享文件、打印机和互联网连接,但通常不会直接暴露给公网。在这两个示例中,公网是全球范围的互联网,而内网是限定在特定组织或家庭的私有网络。
内网通常需要特定的访问权限才能连接到公网,并且通常通过防火墙或路由器进行保护,以确保安全性和隐私。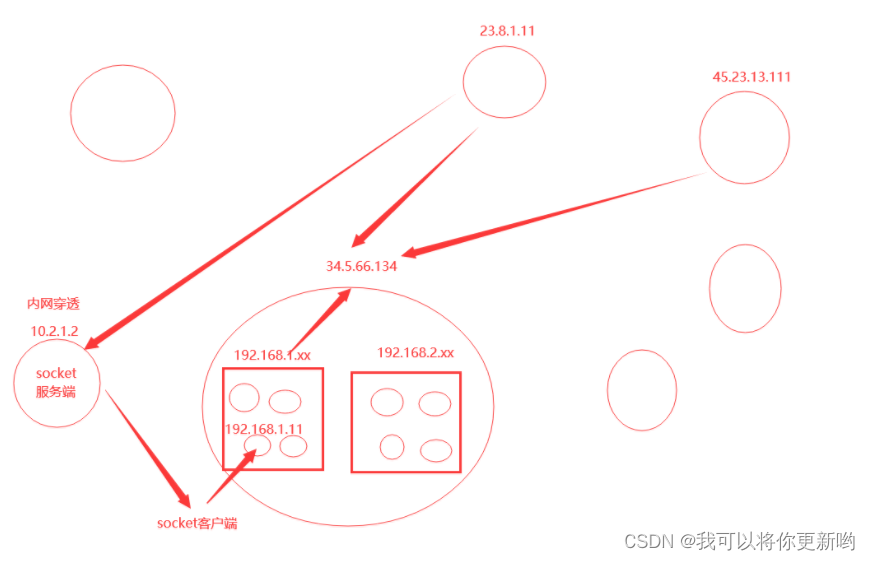
2.1 搭建django后端测试
import requests
res = requests.get('http://192.168.1.252:5010/get/?type=http').json()['proxy']
proxies = {'http': res,
}
print(proxies)
# 我们是http 要使用http的代理
respone = requests.get('http://139.155.203.196:8080/', proxies=proxies)
print(respone.text)
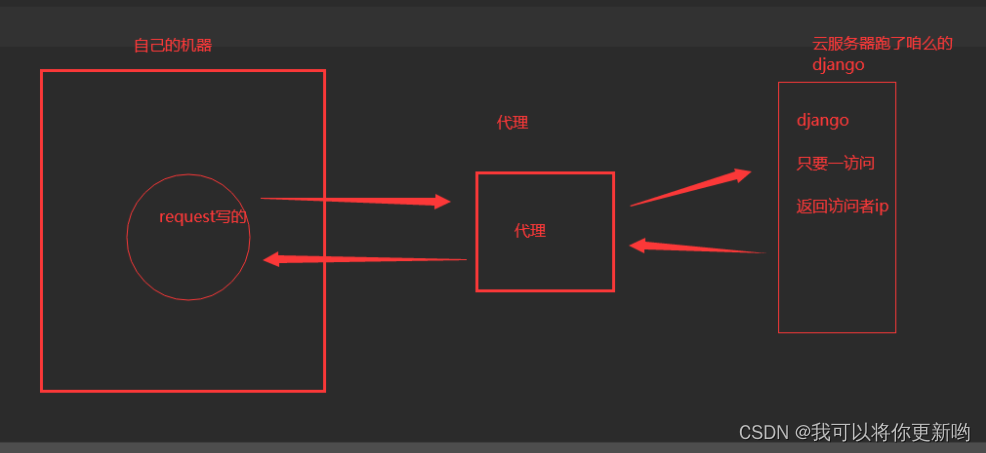
# 步骤:1 写个django,只要访问,就返回访问者ip2 部署在公网上---》python manage.py runserver 0.0.0.0:80003 本机使用代理测试import requestsres1 = requests.get('http://192.168.1.63:5010/get/?type=http').json()dic = {'http': res1['proxy']}print(dic)res = requests.get('http://47.93.190.59:8000/', proxies=dic)print(res.text)# 补充:代理有 透明和高匿透明的意思:使用者最终的ip是能看到的高匿:隐藏访问者真实ip,服务端看不到
3 爬取某视频网站
# 目标:爬取该网站的视频,保存到本地 https://www.pearvideo.com/ import requests
import re# 请求地址是:
# https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0
res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0')
# print(res.text)
# 解析出视频地址---》正则
video_list = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">', res.text)
# print(video_list)
for video in video_list:video_id = video.split('_')[-1]url = 'https://www.pearvideo.com/' + videoprint(url) # 向视频详情发送请求---》解析出页面中mp4视频地址---》直接下载即可header = {'Referer': url}res_json = requests.get(f'https://www.pearvideo.com/videoStatus.jsp?contId={video_id}&mrd=0.14435938848299434',headers=header).json()mp4_url = res_json['videoInfo']['videos']['srcUrl']real_mp4_url = mp4_url.replace(mp4_url.split('/')[-1].split('-')[0], 'cont-%s' % video_id)print(real_mp4_url)# 把视频保存到本地res_video = requests.get(real_mp4_url)with open('./video/%s.mp4' % video_id, 'wb') as f:for line in res_video.iter_content(1024):f.write(line)# res=requests.get('https://www.pearvideo.com/video_1526860')
# print(res.text)# 第一层反扒:需要携带referfer
# header = {'Referer': 'https://www.pearvideo.com/video_1527879'}
# res = requests.get('https://www.pearvideo.com/videoStatus.jsp?contId=1527879&mrd=0.14435938848299434', headers=header)
# print(res.text)# 反扒二:
# https://video.pearvideo.com/mp4/adshort/20190311/ 1698982998222 -13675354_adpkg-ad_hd.mp4 返回的
# https://video.pearvideo.com/mp4/adshort/20190311/ cont-1527879 -13675354_adpkg-ad_hd.mp4 能播的
# s = 'https://video.pearvideo.com/mp4/adshort/20190311/1698982998222-13675354_adpkg-ad_hd.mp4'
# print(s.replace(s.split('/')[-1].split('-')[0], 'cont-1527879'))4 爬取新闻
# 没有一个解析库---》用正则---》解析库--》html/xml
import requests
# pip install BeautifulSoup4
from bs4 import BeautifulSoupres = requests.get('https://www.autohome.com.cn/news/1/#liststart')
# print(res.text)
# 找到页面中所有的类名叫article ul标签
soup = BeautifulSoup(res.text, 'html.parser')
# bs4的查找
ul_list = soup.find_all(class_='article', name='ul') # 所有的类名叫article ul标签
print(len(ul_list))
# 循环再去没一个中,找出所有li
for ul in ul_list:li_list = ul.find_all(name='li')for li in li_list:h3 = li.find(name='h3')if h3:title = h3.texturl = 'https:' + li.find(name='a')['href']if url.startswith('//'):url = 'https:' + urldesc = li.find(name='p').textreade_count = li.find(name='em').textimg = li.find(name='img')['src']print(f'''文章标题:{title}文章地址:{url}文章摘要:{desc}文章阅读数:{reade_count}文章图片:{img}''')# 爬5页--->把图片保存到本地--->把打印的数据存储到mysql中--》建个表5 bs4介绍和遍历文档树
# BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库,解析库
# pip install beautifulsoup4
from bs4 import BeautifulSouphtml_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b><span>lqz</span></p><p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p><p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser') # 解析库可以使用 lxml,速度快(必须安装) 可以使用python内置的 html.parser# print(soup.prettify())-----重点:遍历文档树----------
#遍历文档树:即直接通过标签名字选择,特点是选择速度快,但如果存在多个相同的标签则只返回第一个
#1、用法 通过 . 遍历
# res=soup.html.head.title
# res=soup.p
# print(res)
#2、获取标签的名称
# res=soup.html.head.title.name
# res=soup.p.name
# print(res)
#3、获取标签的属性
# res=soup.body.a.attrs # 所有属性放到字典中 :{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
# res=soup.body.a.attrs.get('href')
# res=soup.body.a.attrs['href']
# res=soup.body.a['href']
# print(res)#4、获取标签的内容
# res=soup.body.a.text #子子孙孙文本内容拼到一起
# res=soup.p.text
# res=soup.a.string # 这个标签有且只有文本,才取出来,如果有子孙,就是None
# res=soup.p.strings
# print(list(res))#5、嵌套选择# 下面了解
#6、子节点、子孙节点
# print(soup.p.contents) #p下所有子节点
# print(list(soup.p.children)) #得到一个迭代器,包含p下所有子节点
# print(list(soup.p.descendants)) #获取子子孙节点,p下所有的标签都会选择出来#7、父节点、祖先节点
# print(soup.a.parent) #获取a标签的父节点
# print(list(soup.a.parents) )#找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲...
#8、兄弟节点
# print(soup.a.next_sibling) #下一个兄弟
# print(soup.a.previous_sibling) #上一个兄弟
#
print(list(soup.a.next_siblings)) #下面的兄弟们=>生成器对象
# print(soup.a.previous_siblings) #上面的兄弟们=>生成器对象
相关文章:
2-爬虫-代理池搭建、代理池使用(搭建django后端测试)、爬取某视频网站、爬取某视频网站、bs4介绍和遍历文档树
1 代理池搭建 2 代理池使用 2.1 搭建django后端测试 3 爬取某视频网站 4爬取某视频网站 5 bs4介绍和遍历文档树 1 代理池搭建 # ip代理-每个设备都会有自己的IP地址-电脑有ip地址---》访问一个网站---》访问太频繁---》封ip-收费:靠谱稳定--提供api-免费ÿ…...
动手学深度学习——残差网络ResNet(原理解释+代码详解)
残差网络ResNet 1. 函数类2. 残差块3. ResNet模型4. 训练模型 ResNet为了解决“新添加的层如何提升神经网络的性能”,它在2015年的ImageNet图像识别挑战赛夺魁 它深刻影响了后来的深度神经网络的设计,ResNet的被引用量更是达到了19万。 1. 函数类 假…...
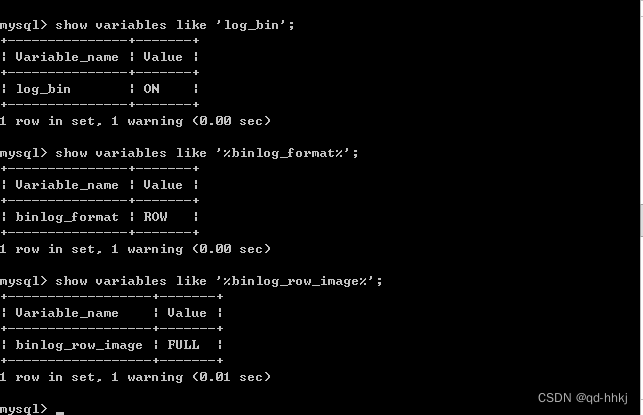
MYSQL 8.0 配置CDC(binlog)
CDC(Change Data Capture)即数据变更抓取,通过源端数据源开启CDC,ROMA Connect 可实现数据源的实时数据同步以及物理表的物理删除同步。这里介绍通过开启Binlog模式CDC功能。 注意:1、使用MYSQL8.0及以上版本。 2、不…...
软件测试/测试开发丨ChatGPT能否成为PPT最佳伴侣
点此获取更多相关资料 简介 PPT 已经渗透到我们的日常工作中,无论是工作汇报、商务报告、学术演讲、培训材料都常常要求编写一个正式的 PPT,协助完成一次汇报或一次演讲。PPT相比于传统文本的就是有布局、图片、动画效果等,可以给到观众更好…...

java对象的创建过程
一.类的加载与检查 当我们new了一个对象的时候,首先会去检查一下这个指令是否在常量池中存在符号引用,并且检查这个符号引用代表的对象是否被加载,解析初始化过,如果没有就要先去进行类加载过程 二.分配内存 我们通过第一步的检…...

Salesforce创建一个页面,能够配置各种提示语,而不需要修改代码
在Salesforce中创建一个页面,并使其能够配置各种提示语,可以使用自定义设置、自定义对象或自定义标签等方法来实现。以下是一种常见的方法: 自定义对象或自定义设置:您可以创建一个自定义对象或自定义设置来存储各种提示语的信息。…...

轻松管理MySQL权限:Python脚本带你飞
数据库管理是 IT 专家和开发者日常工作中的重要组成部分。一个合适的用户权限管理系统不仅确保了数据的安全性,还能确保数据能够按照预期的方式被正确地访问和修改。在本文中,我们将探讨如何使用 Python 脚本来管理和查询 MySQL 数据库中的用户权限。 用户权限管理:创建或修…...
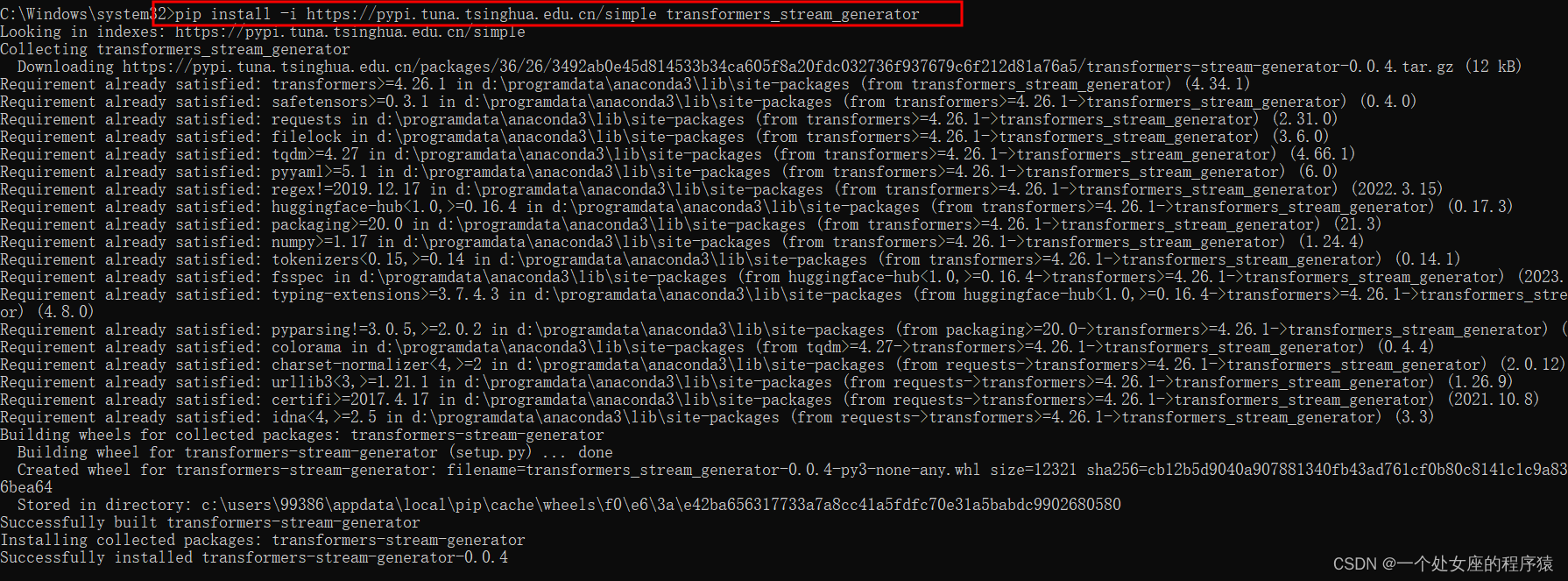
Py之transformers_stream_generator:transformers_stream_generator的简介、安装、使用方法之详细攻略
Py之transformers_stream_generator:transformers_stream_generator的简介、安装、使用方法之详细攻略 目录 transformers_stream_generator的简介 1、Web Demo T1、original T2、stream transformers_stream_generator的安装 transformers_stream_generator的…...
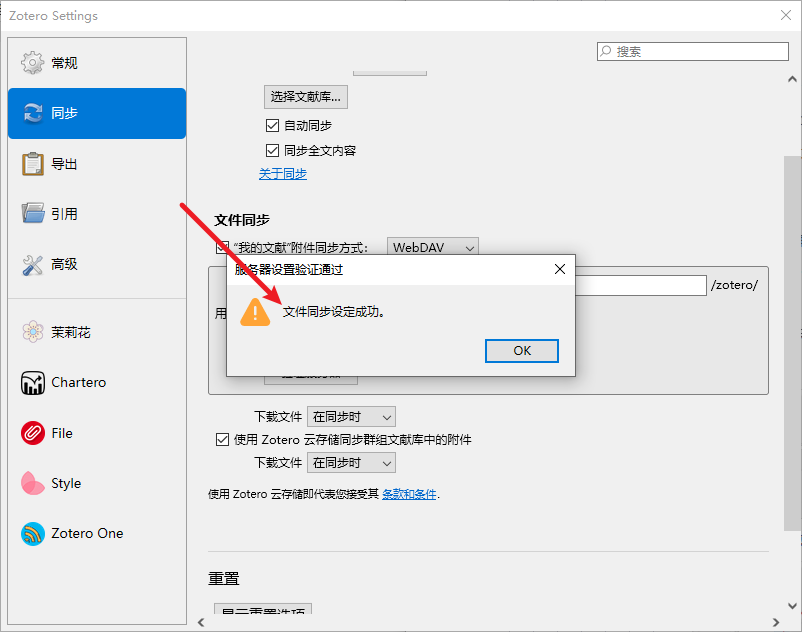
2023年Zotero最新同步教程-使用TeraCloud的25G免费空间实时跨设备同步文献
文章目录 1. 前言2.1. 注册账号2.1.1. 填写注册信息2.1.2. 创建账号成功2.1.3. 注意2.2. 扩容空间2.3. 打开WebDAV 3. Zotero配置WebDAV同步3.1. 设置网址3.2. 验证服务器3.3. 文件同步成功 4. 结语 1. 前言 Zotero免费版的存储空间是300m,一个图文PDF动辄两三M&am…...
,即交换两数。)
面试题:用宏定义写出swap(x,y),即交换两数。
鼠标选中查看答案↓: #define swap(x,y) do{(x)(x)(y);(y)(x)-(y);(x)(x)-(y);}while(0) 这个题考查宏定义的语法,尤其是多行代码的宏定义,加上do{}while(),,可以保证这些语句只执行一次。...
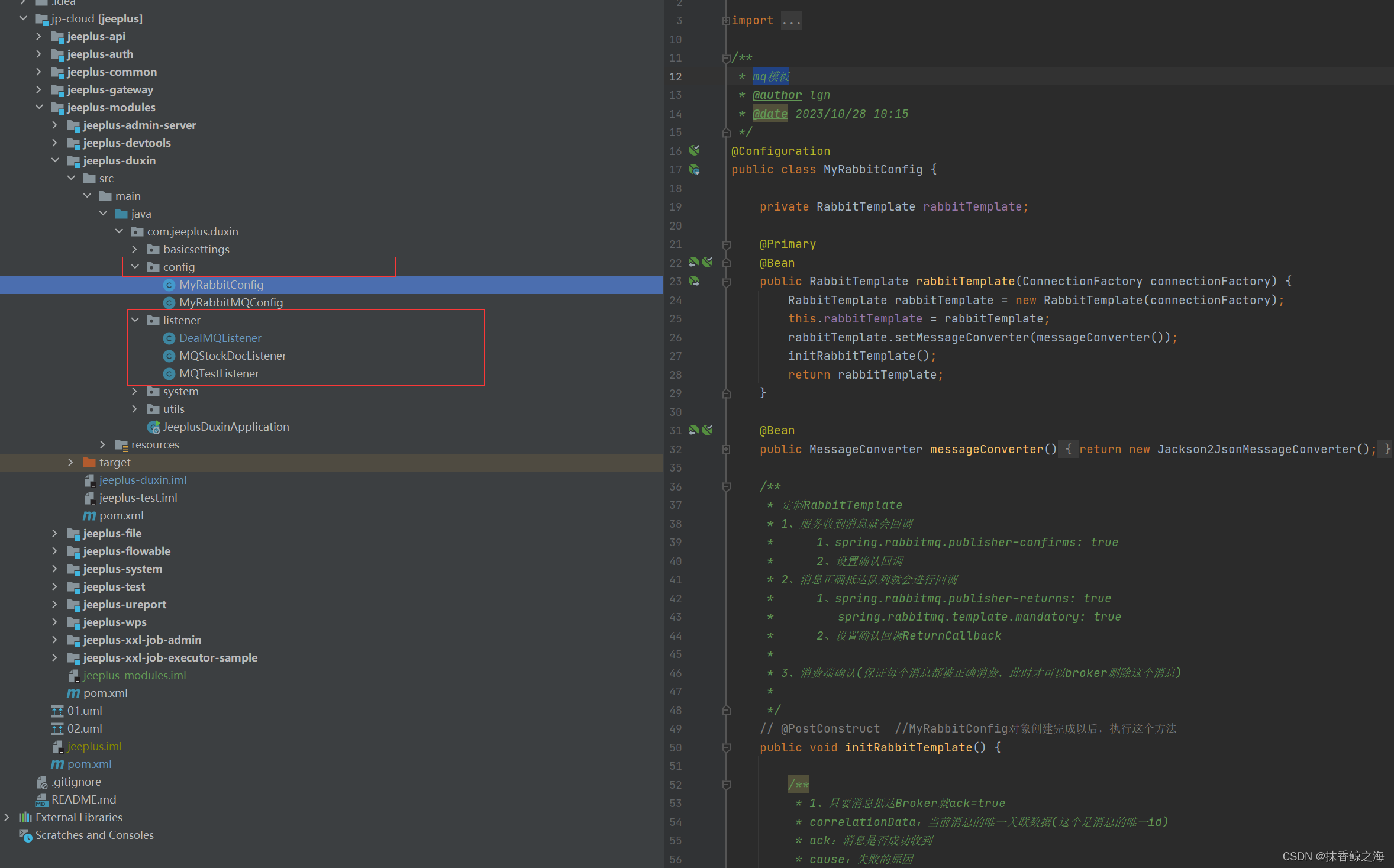
微服务框架SpringcloudAlibaba+Nacos集成RabbitMQ
目前公司使用jeepluscloud版本,这个版本没有集成消息队列,这里记录一下,集成的过程;这个框架跟ruoyi的那个微服务版本结构一模一样,所以也可以快速上手。 1.项目结构图: 配置类的东西做成一个公共的模块 …...

低代码开发,一场深度的IT效率革命
目录 一、前言 二、低代码迅速流行的理由 三、稳定性和生产率的最佳实践 四、程序员用低代码开发应用有哪些益处? 1、提升开发价值 2、利于团队升级 五、总结 一、前言 尽管IT技术支撑了全球的信息化浪潮,然而困扰行业已久的软件开发效率并未像摩尔定律那…...
虚拟串口软件使用介绍
对于上位机开发来说(特别是串口通信应用),上机位软件的调试尤为重要,但是上机位软件的调试并不关心硬件,只需要关注验证发送的数据帧的接收情况,为了便于调试,可以将上机位软件与串口软件互通,实现数据的交互,但由于互通需要串口,可以借助串口虚拟软件(VSPD),虚拟出…...
如何编写一份完整的软件测试报告?(进阶版)百分之90不知道
背景 作为测试从业者,编写测试用例,测试计划,测试报告都是必经之路,最近完成了年终述职以及版本准出,感觉测试报告或者各类报告真是职场人不可或缺的一项技能,趁着热乎劲🔥,写下一些…...

python企业微信小程序发送信息
python企业微信小程序发送信息 在使用下面代码之前先配置webhook 教程如下: https://www.bilibili.com/video/BV1oH4y1S7pN/?vd_sourcebee29ac3f59b719e046019f637738769 然后使用如下代码就可以发消息了: 代码如下: #codinggbk import r…...

Java入门篇 之 逻辑控制(练习题篇)
博主碎碎念: 练习题是需要大家自己打的请在自己尝试后再看答案哦; 个人认为,只要自己努力在将来的某一天一定会看到回报,在看这篇博客的你,不就是在努力吗,所以啊,不要放弃,路上必定坎坷&#x…...
)
Android Google登录并获取token(亲测有效)
背景: Android 需要用到Google的登录授权,用去token给到服务器,服务器再通过token去获取用户信息,实现第三方登录。 我们通过登录之后的email来获取token,不需要server_clientId;如果用server_clientId还…...

npm ERR! code ELIFECYCLE
问题: 一个老项目,现在想运行下,打不开了 npm install 也出错 尝试1 、使用cnpm npm install -g cnpm --registryhttps://registry.npm.taobao.org cnpm install 还是不行 尝试2、 package.json 文件,去掉 那个插件 chorm…...
Mgeo:multi-modalgeographic language model pre-training
文章目录 question5.1 Geographic Encoder5.1.1 Encoding5.1.2 5.2 multi-modal pre-training 7 conclusionGeo-Encoder: A Chunk-Argument Bi-Encoder Framework for Chinese Geographic Re-Rankingabs ERNIE-GeoL: A Geography-and-Language Pre-trained Model and its Appli…...
[激光原理与应用-75]:西门子PLC系列选型
目录 一、西门子PLC PLC系列 二、西门子PLC S7 1200系列 2.1 概述 2.2 12xx系列比较 三、西门子 PLC 1212C系列 四、主要类别比较 4.1 AC/DC/RLY的含义 4.2 AC/DC/RLY与DC/DC/DC 4.3 直流输入与交流输入比较 4.4 继电器输出与DC输出的区别 一、西门子PLC PLC系列 …...

量子化学计算中的自旋适应算符与费米子激发算符
1. 量子化学计算中的自旋适应算符基础在量子化学模拟领域,保持电子波函数的自旋对称性是一个根本性挑战。传统计算方法中,我们使用Slater行列式来表示多电子波函数,这种方法虽然直观,但无法保证波函数是总自旋算符Ŝ的本征态。自旋…...

LinkSwift:九大网盘直链下载的终极解决方案,快速获取真实下载地址
LinkSwift:九大网盘直链下载的终极解决方案,快速获取真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘…...

态是相关,势是因果,感是具身,知是离身
态是相关,势是因果,感是具身,知是离身,用四个高度概括的词,切中了“人机环境系统智能”中态势感知四个核心维度的本质属性。我们可以结合之前的探讨,来深入拆解一下这句“十六字真言”:态是相关…...
)
Perplexity健康科普查询深度拆解(临床医生都在用的7个隐藏技巧)
更多请点击: https://codechina.net 第一章:Perplexity健康科普查询的底层逻辑与临床价值 Perplexity 健康科普查询并非传统关键词匹配式搜索引擎,其核心依托于实时检索增强生成(RAG)架构与权威医学知识图谱的深度融合…...

Perplexity学校信息检索终极手册:覆盖K12/高职/高校的12类典型场景+27个可复用Prompt模板
更多请点击: https://codechina.net 第一章:Perplexity学校信息检索终极手册导论 在教育数字化加速演进的今天,高校师生亟需一种高效、可信且语义精准的信息获取方式。Perplexity 作为融合实时网络检索与大语言模型推理能力的智能问答平台&…...

如何用智能去重工具高效清理重复图片:AntiDupl.NET完整使用指南
如何用智能去重工具高效清理重复图片:AntiDupl.NET完整使用指南 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾面对电脑里杂乱无章的图片库感到束…...

大模型注意力机制深度解析:从Dot-Product到Flash Attention的演进之路
引言如果让你用一句话概括过去七年人工智能领域最重要的技术突破,答案几乎毫无悬念——注意力机制(Attention Mechanism) 。2017年,Google团队在论文《Attention Is All You Need》中首次提出Transformer架构,彻底摒弃…...

The import xxx.xxx.xxx is never used
The import xxx.xxx.xxx is never used List is a raw type. References to generic type List<E> should be parameterized Dead code The value of the local variable d is not used代码洁癖啊,为啥这些这么多黄色警告都不处理呢。 没有用的代码࿰…...

别再被0.1+0.2≠0.3搞懵了!用Python和Java代码手把手拆解IEEE-754浮点数存储
浮点数精度之谜:用代码揭开0.10.2≠0.3的真相 当你在Python控制台输入0.1 0.2时,得到的不是预期的0.3,而是0.30000000000000004。这个看似简单的数学运算为何会出现如此"诡异"的结果?本文将带你用Python和Java代码深入…...

Windows HEIC缩略图终极解决方案:3步解锁苹果照片完美预览
Windows HEIC缩略图终极解决方案:3步解锁苹果照片完美预览 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 还在为iPh…...