机器学习 - 加油站数据分析
一、实验数据
数据集:“加油站数据.xls”
数据集介绍:该表记录了用户在11月和12月一天24小时内的加油信息,包括:持卡人标识(cardholder)、卡号(cardno)、加油站网点号(nodeno)、加油时间(opetime)、加油升数(liter)、金额(amount)
二、实验任务
a. 按照加油时间顺序对表0中的数据进行排序;
b. 统计加油站的站点数;统计用户总数(相同卡号按照同一人计算);统计17:30~18:30期间加油的人数和平均加油量,以及该时间段的加油总量在一天中的占比;
c. 按照月份可视化展示用户卡号为“1000113200000151566”的加油量;分析用户“1000113200000151566”常去的加油站点和通常的加油时间;根据加油时间、加油量、加油站点等因素分析该用户2007年是否有行为异常的时间,并进行解释说明。
d. 分析国庆节是否可以拉动加油站的经济增长(提示:可以跟整体和当月加油量的均值和方差进行对比);
e. 某用户周六9:00~19:00时间自由,你推荐他什么时间去哪个加油站加油,为什么;
f. 分析2007年期间,加油站点“32000966”的汽油价格波动情况;
三、前期工作
数据预处理
数据整合
import pandas as pd# 读取整个Excel文件
xls = pd.ExcelFile('D:/MecLearning/加油站数据.xls')# 创建一个空的DataFrame,用于存储所有表页的内容
combined_data = pd.DataFrame()# 遍历Excel文件的每个表页,并将其内容合并到combined_data中
for sheet_name in xls.sheet_names:df = pd.read_excel(xls, sheet_name)combined_data = pd.concat([combined_data, df], ignore_index=True)# 将合并后的数据写入一个新的Excel文件
combined_data.to_excel('D:/MecLearning/合并后的数据.xlsx', index=False)print("数据已整合并写入新的Excel文件 '合并后的数据.xlsx'")![]() 时间列分割
时间列分割
import pandas as pd# 读取原始Excel文件
df = pd.read_excel('D:/MecLearning/合并后的数据.xlsx')# 将opetime列分割成年月日和时间两列
df['Date'] = df['opetime'].str.split().str[0] # 提取年月日部分
df['Time'] = df['opetime'].str.split().str[1] # 提取时间部分# 将修改后的DataFrame保存到原始文件中
df.to_excel('D:/MecLearning/合并后的数据.xlsx', index=False)print("修改后的Date和Time列已保存到原始文件中")![]()

正式解题
a.按照加油时间顺序对数据进行排序:
import pandas as pd# 读取Excel文件
df = pd.read_excel('D:/MecLearning/加油站数据.xls')# 按照加油时间排序
df.sort_values(by='opetime', inplace=True)# 打印排序后的数据
print(df)
b.统计加油站的站点数,统计用户总数,统计17:30~18:30期间加油的人数和平均加油量,以及该时间段的加油总量在一天中的占比:
# 统计加油站站点数
station_count = df['nodeno'].nunique()# 统计用户总数
user_count = df['cardno'].nunique()# 过滤出17:30~18:30期间的数据
filtered_data = df[(df['opetime'] >= '17:30:00') & (df['opetime'] <= '18:30:00')]# 统计该时间段加油的人数和平均加油量
people_count = filtered_data['cardholder'].nunique()
average_liter = filtered_data['liter'].mean()# 计算该时间段的加油总量占比
total_liter = filtered_data['liter'].sum()
total_day_liter = df['liter'].sum()
percentage = (total_liter / total_day_liter) * 100print(f"加油站站点数:{station_count}")
print(f"用户总数:{user_count}")
print(f"17:30~18:30期间加油的人数:{people_count}")
print(f"平均加油量:{average_liter:.2f}升")
print(f"该时间段的加油总量占比:{percentage:.2f}%")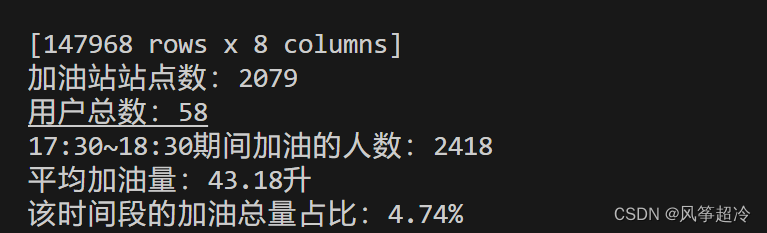
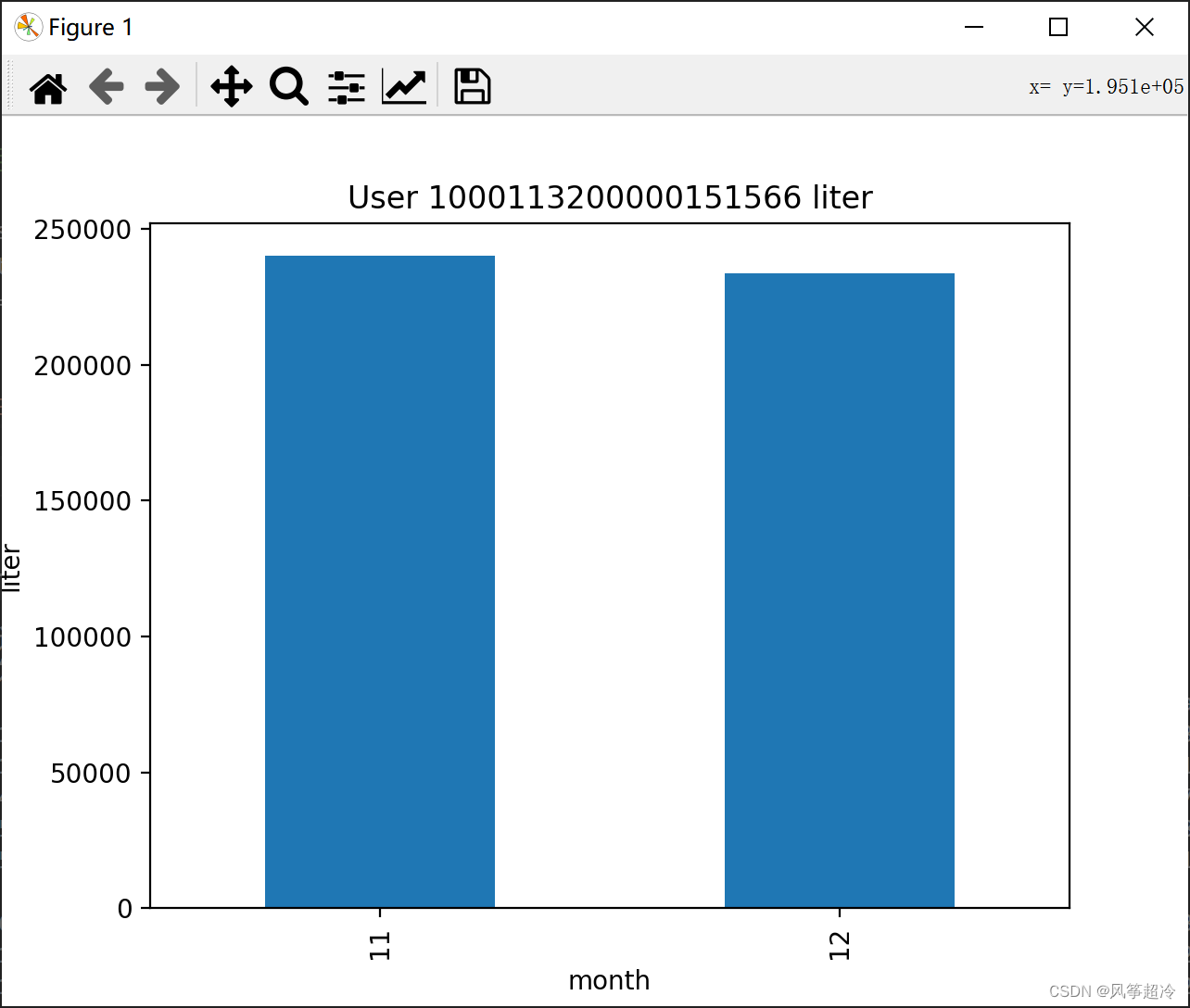
c.可视化展示用户卡号为“1000113200000151566”的加油量,分析用户常去的加油站点和通常的加油时间,并分析是否有异常时间段:
import pandas as pd
import matplotlib.pyplot as plt
import warnings# 忽略特定警告
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")# 读取Excel文件
df = pd.read_excel('D:/MecLearning/合并后的数据.xlsx')# 按照加油时间排序
df.sort_values(by='opetime', inplace=True)# 过滤出指定用户的数据,并明确创建一个副本
user_data = df[df['cardno'] == 1000113200000160000].copy()import matplotlib.pyplot as plt
import matplotlib.font_manager as fm# 查找支持的中文字体
font_path = fm.findSystemFonts(fontpaths=None, fontext="ttf")
for font in font_path:if "SimHei" in font:plt.rcParams['font.sans-serif'] = [fm.FontProperties(fname=font).get_name()]plt.rcParams['axes.unicode_minus'] = Falsebreak# 绘图代码
# 检查用户数据是否为空
if not user_data.empty:# a. 可视化用户加油量按月份user_data['opetime'] = pd.to_datetime(user_data['opetime']) # 转换为日期时间类型user_data['month'] = user_data['opetime'].dt.month # 提取月份monthly_data = user_data.groupby('month')['liter'].sum() # 按月份统计加油量monthly_data.plot(kind='bar')plt.xlabel('month')plt.ylabel('liter')plt.title('User 1000113200000151566 liter')plt.show()# b. 分析用户常去的加油站点和通常的加油时间frequent_station = user_data['nodeno'].mode().values[0]frequent_time = user_data['opetime'].mode().values[0]print(f"常去的加油站点:{frequent_station}")print(f"通常的加油时间:{frequent_time}")# c. 根据因素分析异常时间段# 这部分需要进一步的数据分析和领域知识,以确定异常时间段# 查找超出正常范围的加油量mean_liter = user_data['liter'].mean()std_liter = user_data['liter'].std()threshold = mean_liter + 2 * std_liter # 将2倍标准差作为异常阈值abnormal_periods = user_data[user_data['liter'] > threshold]if not abnormal_periods.empty:print("发现异常时间段:")print(abnormal_periods)else:print("未找到用户1000113200000151566的加油记录")
d. 分析国庆节是否可以拉动加油站的经济增长,可以比较国庆节期间的加油量与整体和当月加油量的均值和方差:
import pandas as pd
import matplotlib.pyplot as plt
import warnings# 忽略特定警告
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")# 读取Excel文件
df = pd.read_excel('D:/MecLearning/合并后的数据.xlsx')# 假设国庆节日期范围为 '2007-10-01' 到 '2007-10-07'
national_day_data = df[(df['Date'] >= '2007-11-01') & (df['Date'] <= '2007-11-07')]# 计算国庆节期间的加油量均值和方差
national_day_mean = national_day_data['liter'].mean()
national_day_var = national_day_data['liter'].var()# 计算整体加油量均值和方差
overall_mean = df['liter'].mean()
overall_var = df['liter'].var()# 计算当月加油量均值和方差
current_month_data = df[df['Date'].str.startswith('2007-11')]
current_month_mean = current_month_data['liter'].mean()
current_month_var = current_month_data['liter'].var()# 打印比较结果
print(f"国庆节期间的加油量均值:{national_day_mean:.2f}升")
print(f"国庆节期间的加油量方差:{national_day_var:.2f}")
print(f"整体加油量均值:{overall_mean:.2f}升")
print(f"整体加油量方差:{overall_var:.2f}")
print(f"当月加油量均值:{current_month_mean:.2f}升")
print(f"当月加油量方差:{current_month_var:.2f}")
e. 推荐某用户周六9:00~19:00时间自由的加油时间和加油站点:
# 过滤出周六的数据
saturday_data = df[df['opetime'].dt.weekday == 5]# 过滤出9:00~19:00的数据
saturday_data = saturday_data[(saturday_data['opetime'] >= '09:00:00') & (saturday_data['opetime'] <= '19:00:00')]# 找出用户最常去的加油站点
frequent_station = saturday_data['nodeno'].mode().values[0]# 找出平均加油量最高的时间段
best_time = saturday_data.groupby('opetime')['liter'].mean().idxmax()print(f"推荐加油时间:{best_time}")
print(f"推荐加油站点:{frequent_station}")
f. 分析加油站点“32000966”的汽油价格波动情况:
计算price
import pandas as pd
import matplotlib.pyplot as plt
import warnings# 忽略特定警告
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")# 读取Excel文件
df = pd.read_excel('D:/MecLearning/合并后的数据.xlsx')# 检查是否包含 'amount' 和 'liter' 列
if 'amount' in df.columns and 'liter' in df.columns:# 新增 'price' 列df['price'] = df['amount'] / df['liter']# 保存带有 'price' 列的新数据框到Excel文件df.to_excel('D:/MecLearning/合并后的数据_with_price.xlsx', index=False)
else:print("数据中缺少 'amount' 或 'liter' 列。")分析加油站点“32000966”的汽油价格波动
import pandas as pd
import matplotlib.pyplot as plt
import warnings# 忽略特定警告
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")# 读取Excel文件
df = pd.read_excel('D:/MecLearning/合并后的数据_with_price.xlsx')# 假设数据集包含汽油价格字段为'price'
station_data = df[df['nodeno'] == '32000966']
station_data['Date'] = pd.to_datetime(station_data['Date']) # 转换为日期时间类型
station_data.sort_values(by='Date', inplace=True) # 按照加油时间排序import matplotlib.pyplot as plt
import matplotlib.dates as mdates# 设置日期时间刻度格式
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
plt.gca().xaxis.set_major_locator(mdates.MonthLocator(interval=1)) # 设置刻度间隔为一个月# 绘制汽油价格的折线图
plt.plot(station_data['Date'], station_data['price'])
plt.xlabel('日期')
plt.ylabel('汽油价格')
plt.title('2007年加油站点32000966汽油价格波动情况')
plt.xticks(rotation=45) # 旋转x轴标签,以防止重叠
plt.grid() # 添加网格线
plt.show()相关文章:
机器学习 - 加油站数据分析
一、实验数据 数据集:“加油站数据.xls” 数据集介绍:该表记录了用户在11月和12月一天24小时内的加油信息,包括:持卡人标识(cardholder)、卡号(cardno)、加油站网点号(n…...
基于CMFB余弦调制滤波器组的频谱响应matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1、CMFB余弦调制滤波器组原理 4.2、CMFB调制过程 4.3、CMFB特点 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 ......................…...

helm一键部署grafana
一键部署命令 helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo update helm install prometheus prometheus-community/kube-prometheus-stack暴露服务 kubectl port-forward --address 0.0.0.0 deployment/prometheus-gr…...

pytorch复现_NMS
NMS(非极大值抑制)阈值是用于控制在一组重叠的边界框中保留哪些边界框的参数。当检测或识别算法生成多个边界框可能涵盖相同物体时,NMS用于筛选出最相关的边界框,通常是根据它们的置信度分数。 具体来说,NMS的工作原理…...
备份doris数据到minio
1、MINIO 设置 创建服务账户,记住ACCESS_KEY和SECRET_KEY 创建Buckets doris 设置region 在首页查看服务ip和端口号 2、创建S3备份库 因为minio是兼容S3协议的,所以可以通过s3协议链接minio。 CREATE REPOSITORY minio WITH S3 ON LOCATION "s3://…...

Linux中正则表达式等
grep命令:主要作用就是过滤查找文本内容 常用的选项有: -m 数字:匹配几次之后停止,按行匹配,不是按字符个数,例如 -v:取反 例如: -n:显示匹配的行号 例如: -c:仅显示匹配的行数,不显示匹配内…...

记一次并发问题 Synchronized 失效
记一次并发问题 Synchronized 失效 场景:为避免信息提交重复,给事务方法增加了synchronized修饰符,实际场景中仍然无法完全避免重复,原因是因为在第一个线程执行完synchronized代码段后,此时spring还未完成事务提交&a…...
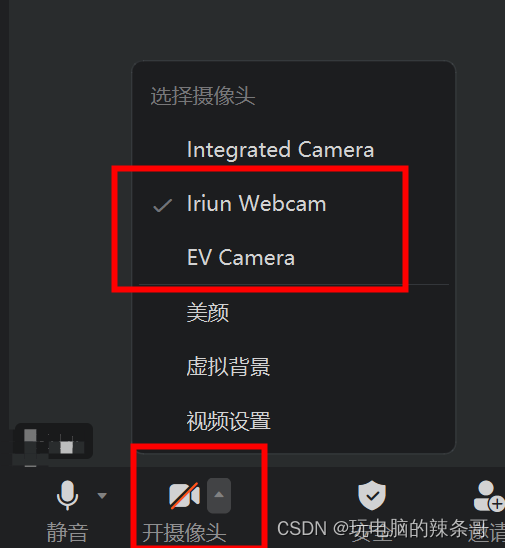
手机平板摄像头如何给电脑用来开视频会议
环境: Iriun Webcam EV虚拟摄像头 钉钉会议 问题描述: 手机平板摄像头如何给电脑用来开视频会议 解决方案: 1.下载软件 手机端和电脑端都下载这个软件,连接同一局域网打开软件连接好 另外一款软件Iriun 也是一样操作 2.打…...
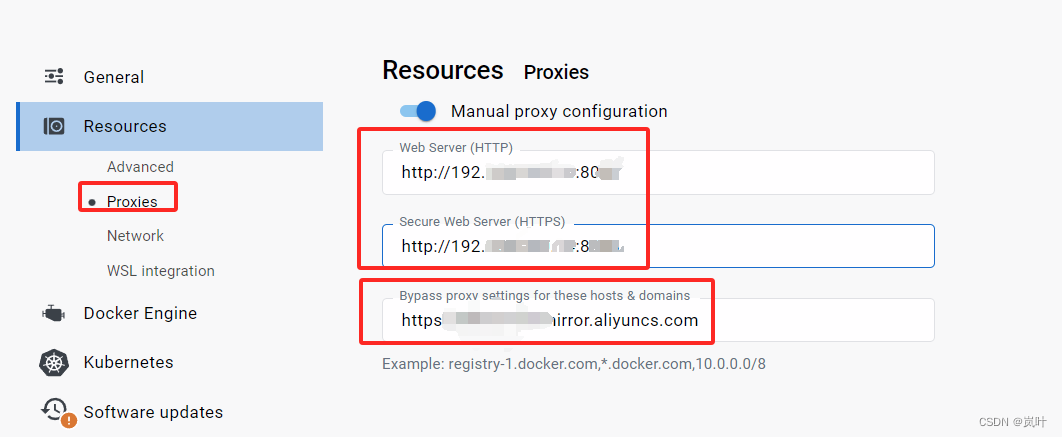
windows docker desktop 更换镜像 加速
最近 docker hub 访问不了; 经过研究 可以通过添加 代理镜像网址 添加代理服务器的方式 实现完美访问 1添加镜像网站 修改成国内镜像地址就能享受到飞一般的速度,但有一个问题,部分站点镜像不全或者镜像比较老,建议使用多个镜像站。 https…...

linux下多机器ssh免密码登录配置
20,21,22,23等4台机器配置ssh免密登陆 确认sshd配置 查看/etc/ssh/sshd_config文件,确认如下配置没有被注释掉: AuthorizedKeysFile .ssh/authorized_keys每一台机器修改hosts配置主机名(可选) 执行ssh命令,如…...
【IDEA使用maven package时,出现依赖不存在以及无法从仓库获取本地依赖的问题】
Install Parent project C:\Users\lxh\.jdks\corretto-1.8.0_362\bin\java.exe -Dmaven.multiModuleProjectDirectoryD:\学习\projectFile\study\study_example_service "-Dmaven.homeD:\Program Files\JetBrains\IntelliJ IDEA2021\plugins\maven\lib\maven3" "…...

Flink 统计接入的数据量-滚动窗口和状态的使用
1、概述 在生产场景值,经常需要和上游、下游对数,离线场景可以直接 group by 再 count ,但是实时场景中,如果使用 kafka 作为中间件,中间经过几个 job 的过滤转化后,再对照像 Doris 或 Clickhouse 中最终层…...
)
SpringBoot快速整合canal1.1.5(TCP模式)
SpringBoot快速整合canal1.1.5(TCP模式) 安装并配置MySQL主从⭐ 1:Docker安装MySQL8.0.28 docker pull mysql:8.0.282:创建目录: mkdir -p /usr/local/mysql8/data mkdir -p /usr/local/mysql8/log mkdir -p /usr/…...

docker打包container成image,然后将image上传到docker hub
第一步:停止正在运行的容器 docker stop <container_name> eg: docker stop xuanjie_mlir 第二步:将对应的container打包成image docker commit <container_id> <镜像名:版本> eg:docker commit 005672e6d97a…...
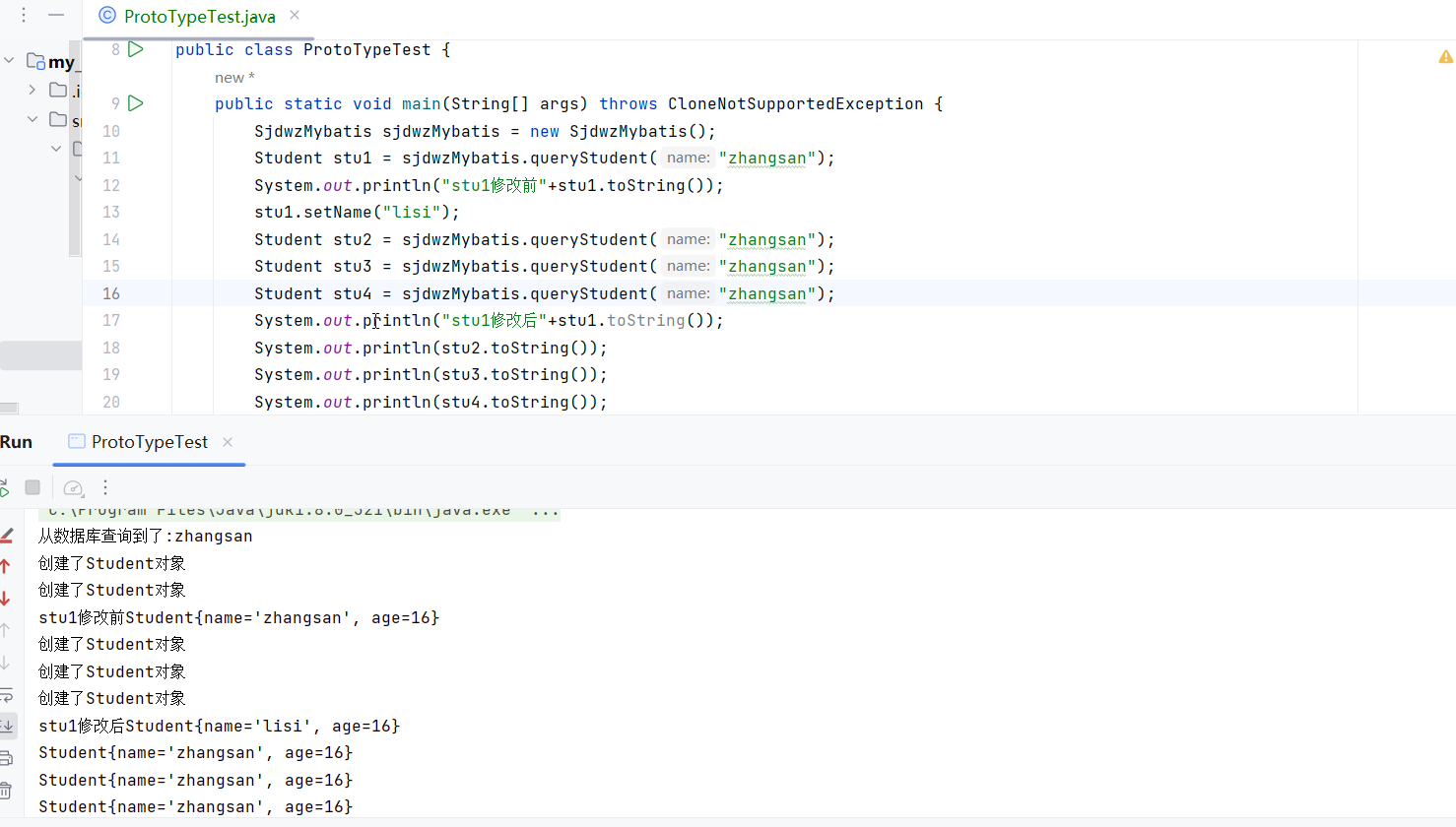
设计模式—创建型模式之原型模式
设计模式—创建型模式之原型模式 原型模式(Prototype Pattern)用于创建重复的对象,同时又能保证性能。 本体给外部提供一个克隆体进行使用。 比如我们做一个SjdwzMybatis,用来操作数据库,从数据库里面查出很多记录&…...
Zygote进程通信为什么用Socket而不是Binder?
Zygote进程是Android系统中的一个特殊进程,它在系统启动时被创建,并负责孵化其他应用进程。它的主要作用是预加载和共享应用进程的资源,以提高应用启动的速度。 在Android系统中,常用的进程通信方式有以下几种: Intent…...

API接口加密,解决自动化中登录问题
一、加密方式 AES:对称加密,快RAS:非对称加密,慢AESRAS:安全高效 加密过程:字符串》字节流》加密的字节流(算法),解密有可能出现乱码,所以不能直接转成字符…...
COCOS2DX3.17.2 Android升级targetSDK30问题解决方案
一、luajit不兼容问题 不兼容版本:【2.1.0-bate2、2.1.0-bate3都存在异常】 出问题系统:Android11;Android10的系统部分机型有问题,部分机型正常 异常点1:c调用lua接口,pushObjiect的时候crash 异常点2…...

HarmonyOS鸿蒙原生应用开发设计- 隐私声明
HarmonyOS设计文档中,为大家提供了独特的隐私声明,开发者可以根据需要直接引用。 开发者直接使用官方提供的隐私声明内容,既可以符合HarmonyOS原生应用的开发上架运营规范,又可以防止使用别人的内容产生的侵权意外情况等ÿ…...

【面试精选】00后卷王带你三天刷完软件测试面试八股文
前言 本人普通本科计算机专业,做测试也有3年的时间了,讲下我的经历,我刚毕业就进了一个小自研薪资还不错,有10.5k(个人觉得我很优秀),在里面呆了两年,积累了一些的经验和技能&#…...
:使用指南)
One API 部署教程(下):使用指南
导读:前面两篇讲了本地和线上部署,现在 One API 已经跑起来了,接下来就是真正的使用环节! 理解核心概念 在开始之前,咱们先搞清楚几个关键概念,不然后面容易晕。 渠道(Channel):就是你的各个 AI 平台的 API Key。比如你有 DeepSeek 的 Key、OpenAI 的 Key、通义千问…...

别再傻傻分不清!PECL、CML、LVDS三种高速差分接口,硬件工程师选型避坑指南
高速差分接口选型实战:PECL、CML、LVDS的工程化决策指南 当PCB布线密度突破8层板、信号速率迈入Gbps时代,差分接口的选择直接决定系统稳定性。某通信设备厂商曾因误用LVPECL接口导致整批产品EMC测试失败,损失超百万——这类故事在硬件圈屡见不…...

DDR2 / DDR3 / DDR4 颗粒信号差异对照表
DDR2 与 DDR3 颗粒引脚信号一一对应对照表信号组别DDR2 信号名DDR3 对应信号名功能一致差异说明差分时钟CK、CK#CK、CK#✅ 完全一致功能、时序定义相同,仅电平不同时钟使能CKECKE✅ 完全一致高低电平逻辑、工作模式控制相同硬件复位无RESET#❌ DDR2 无DDR3 新增&…...

工业作业火花识别 工业作业安全监测 工业安全火灾识别 火灾烟雾识别
火灾、烟雾及火花检测数据集 数据集概述 本数据集面向计算机视觉目标检测场景构建,聚焦火情风险要素识别,为烟火火花类智能监测模型训练提供标准化图像数据支撑,整体适配深度学习目标检测算法训练、验证与测试流程,可有效支撑安防…...

PNetLab-vs-EVE-NG安全性分析
1 PNetLab vs EVE-NG社区版:从一次CVE看"免费fork"的安全代价 1.1 痛点引入 2025年11月,CVE-2025-63749被公开披露——PNetLab 5.3.11存在命令注入漏洞,攻击者通过qemu_options参数注入$(/bin/bash -c reverse_shell),…...

Windows安卓驱动安装终极解决方案:一键自动化ADB Fastboot工具
Windows安卓驱动安装终极解决方案:一键自动化ADB Fastboot工具 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirro…...

2026年照片去水印免费软件App推荐|主流工具优缺点对比与实测评价
处理照片时遇到水印,通常有两条路:要么花钱买专业软件,要么找个免费方案凑合着用。但2026年的现在,免费去水印工具已经相当能打了。无论是手机App、桌面软件还是在线网站,都能找到效果不错的免费选项。本文将详细介绍目…...
)
用Python搞定常微分方程:从经典RK4到隐式IRK6的保姆级代码对比(附避坑指南)
Python数值解微分方程实战:从RK4到IRK6的算法选择与避坑指南 微分方程数值解法是工程计算中的核心技能,但面对十几种龙格库塔方法时,很多开发者会陷入选择困难。本文将用可复用的Python代码,带你穿透显式RK4与隐式IRK6的迷雾。 1.…...

3步实现B站缓存视频智能转换:高效保存珍贵学习资源
3步实现B站缓存视频智能转换:高效保存珍贵学习资源 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他…...
)
告别GitHub!手把手教你用Gitblit在Windows 10上搭建私人局域网Git服务器(附SourceTree配置)
告别GitHub!手把手教你用Gitblit在Windows 10上搭建私人局域网Git服务器(附SourceTree配置) 在当今代码托管平台高度集中的环境下,越来越多的开发者开始关注数据主权和隐私保护。特别是对于金融、医疗等敏感行业的开发团队&#x…...