论文阅读:One Embedder, Any Task: Instruction-Finetuned Text Embeddings
1. 优势
现存的emmbedding应用在新的task或者domain上时表现会有明显下降,甚至在相同task的不同domian上的效果也不行。这篇文章的重点就是提升embedding在不同任务和领域上的效果,特点是不需要用特定领域的数据进行finetune而是使用instuction finetuning就可以在不同的任务和领域上表现得很好。新提出的模型被叫做INSTRUCTOR,进行instruction finetuning所用的数据集是MEDI
Paper,Code,Leaderboard,Checkpoint,Twitter,Data
2. INSTRUCTOR结构
- 基于single encoder architecture,参考:Leveraging Passage Retrieval with Generative Models
for Open Domain Question Answering - 使用GTR模型(Generalizable T5-based dense Retrievers)作为encoder骨架。GTR模型是用T5模型初始化的,在web corpus上做预训练,在information search datasets上做finetune。
- GTR模型用的是Large Dual Encoders Are Generalizable Retrievers这篇文章里面的,T5模型是这篇文章里面的Exploring the Limits of Transfer Learning with a Unified
Text-to-Text Transformer,由于T5模型的文章过长,可以参考T5 模型:NLP Text-to-Text 预训练模型超大规模探索,找到自己的目标实验之后再看对应的论文片段。
3. 训练数据
- 这个方法的核心是instruction-base finetuning,如下图所示,一个输入经过INSTRUCTOR会根据不同的目标改写成不同的输入形式:
- instructioninstruction-based finetun
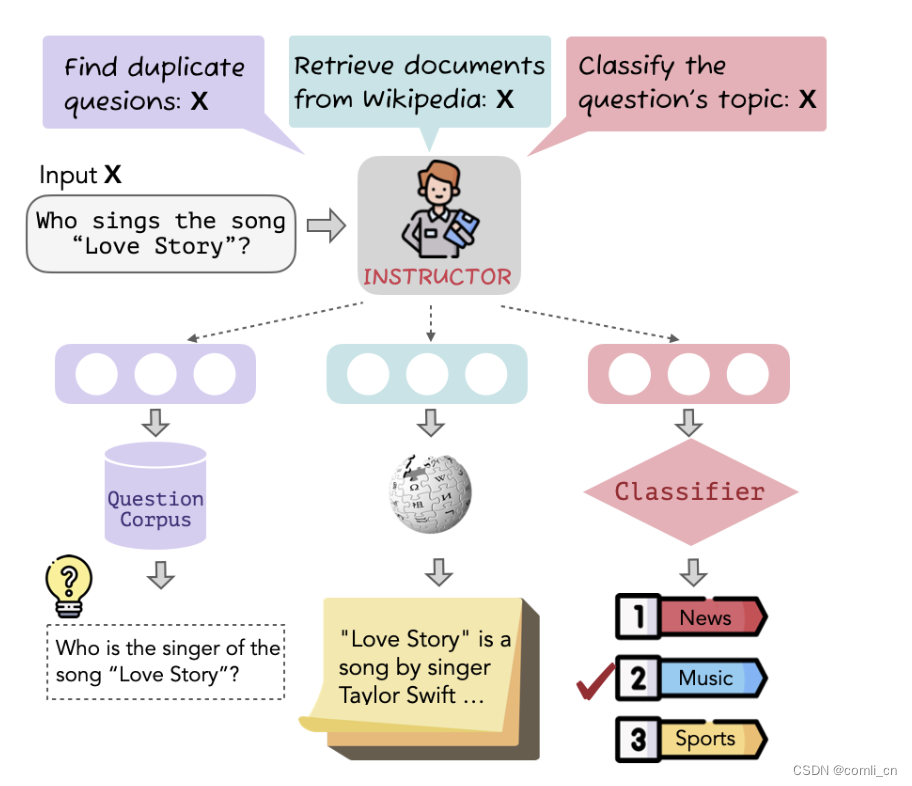
input:Who sings the song "Love Story"?INSTRUCOR:input1:Find duplicate quesions:Who sings the song "Love Story"?input2:Retrieve documents from wikipedia:Who sings the song "Love Story"?input3:Classify question's topic:Who sings the song "Love Story"?
-
构建了MEDI,一个多样化的数据集,用于微调INSTRUCTOR。这个数据集包含了330种不同的文本embedding任务,并就这种具有对比损失的多任务组合对INSTRUCTOR进行训练
-
其中300个数据集来自super-NI,还有30个来自现有集合
-
super-NI带有Instructions但是没有提供正负样本对,这里用Sentence-T5 embedding来帮助构成pairs。数据下载:natural-instructions
-
对于分类任务,如果 x i x_i xi和 x j x_j xj的label均为正且 x i x_i xi和 x j x_j xj的embedding相似度高,则 x i x_i xi和 x j x_j xj就会被归为positive-pair,如果 x i x_i xi和 x j x_j xj的label不同,则归为negative-pair。
下图是super-NI数据集的标准格式
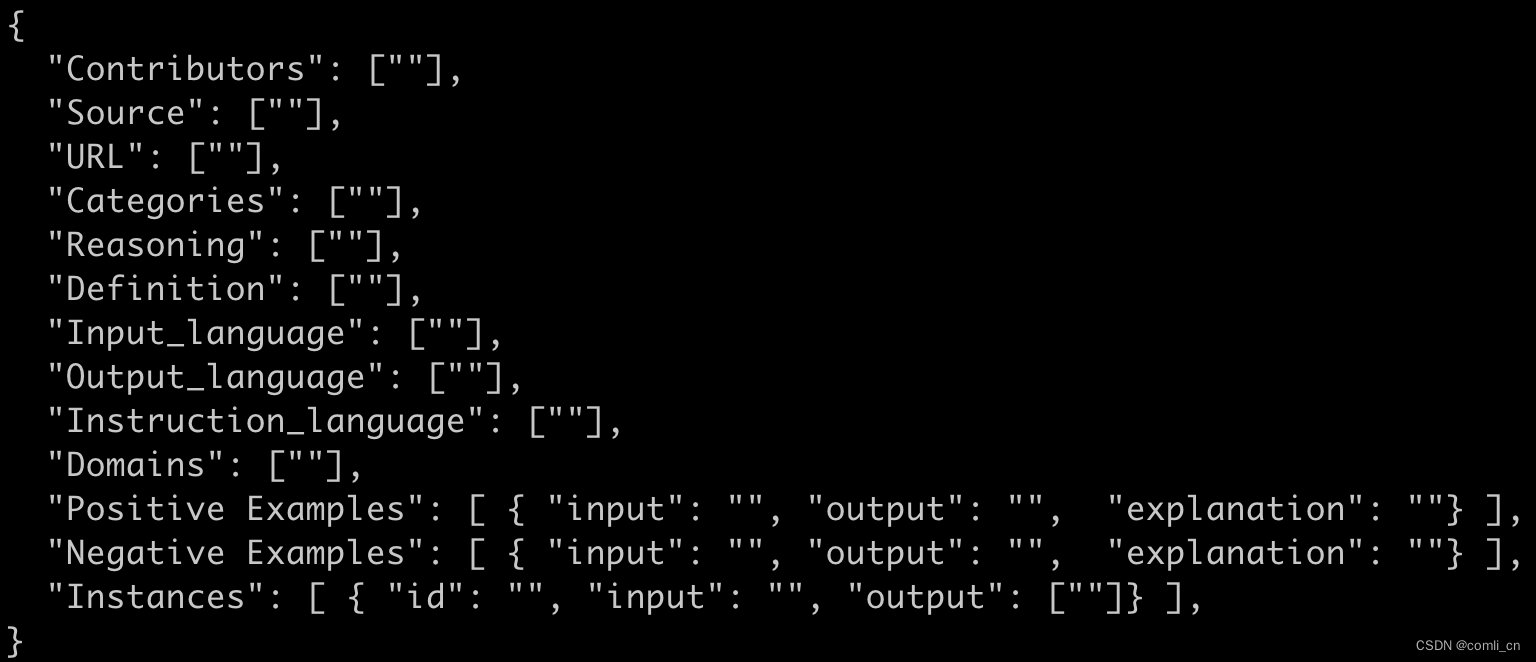
如下图是super-NI里面一个分类任务的数据集,如果都属于Positive Examples且embedding相似度高则为positive-pair,如果一个属于Positive Examples,一个属于Negative Examples则为negative-pair
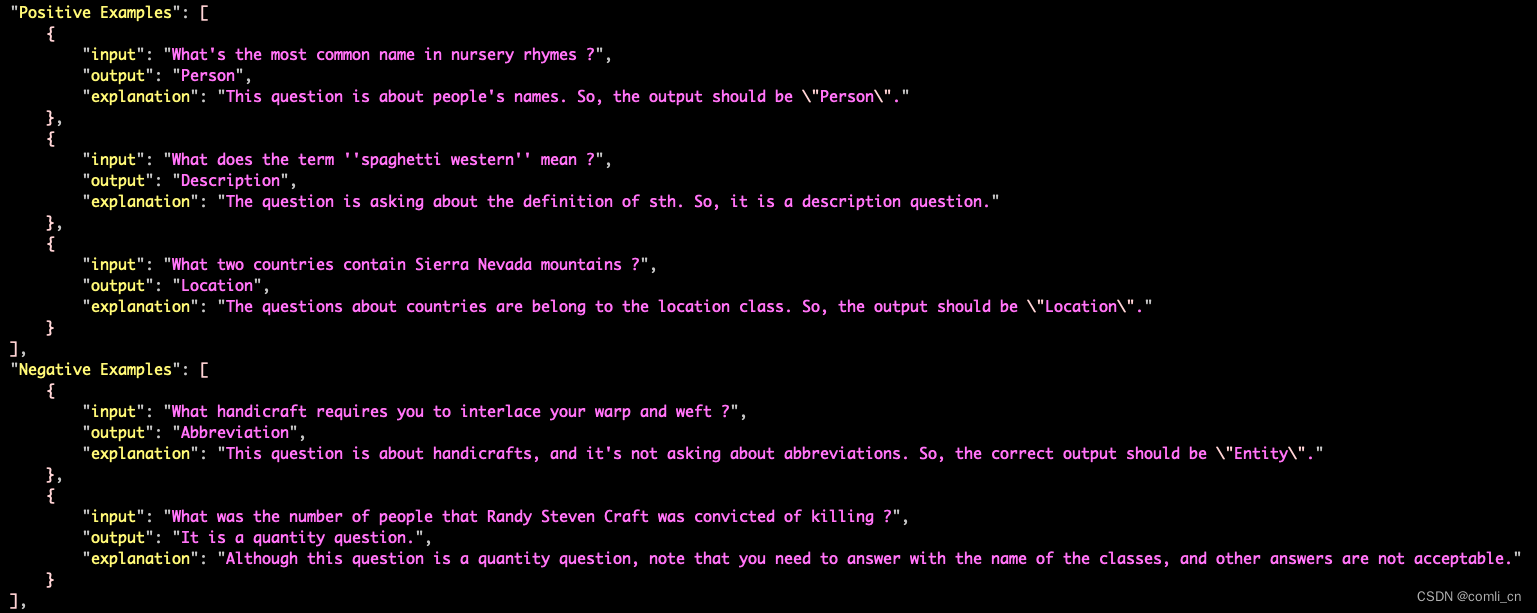
-
对于其他任务,要先按照下面的式子计算score,然后选择s_pos最高的作为positive-pair,选择s_neg最高的作为hard negative-pair(一个反例对有一个更大的余弦相似对意味着从不同的类别中区分两对样例是更困难的,这样的对被视为硬反例对hard negative pairs,他们有更多的信息并且更有意义去学习一个可区分的特征)
-
在训练的时候将每个batch里面放入一个hard negative,一个batch里面除了一个positive之外其余的都作为negtive(inbatch sampled negatives)
-
-
另外30个数据集来自Sentence Transformers embedding data
- 这30个数据集已经有了positive pairs,其中的一小部分比如说MSMARCO和Natural Questions包含有hard negative pairs
- 在模型finetune时使用4个negative pairs(参考一下这篇文章:Large Dual Encoders Are Generalizable Retrievers)Large Dual Enco
- 因为这些数据集缺乏instructions,做了一个instruction模版,并且人工为每个数据集写prompt
- 数据集的几种格式:

4. 训练目标
最大化输入与正样本的相似度,最小化输入与负样本的相似度;用instruction和query拼接后的embedding与instruction和doc拼接后的embedding计算相似度
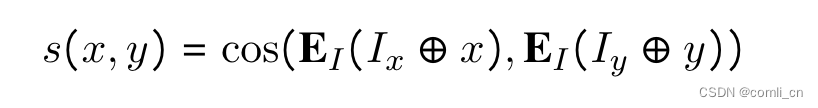
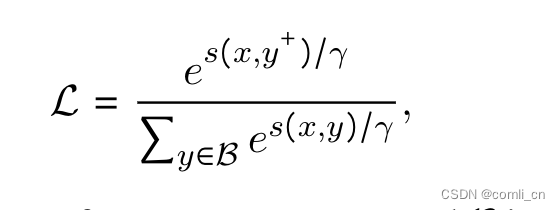
5. 训练细节
- 因为MEDI里面datasets的大小差别很大,所以要对比较大的dataset做降采样
- 在每一步,首先随机选择一个dataset,然后从这个dataset里构建一个minibatch。这样我们可以确定in-batch negatives是从同一个dataset里面采样的,从而防止模型使用任务差异来预测负标签
- 用GTR-Large模型初始化INSTRUCTOR,并使用AdamW优化器在学习率为2*10(-5),warmup ratio为0.1的条件下在MEDI上进行finetune
6. 评估
- 在70项embedding评估任务(其中66项在训练期间看不到)上进行评估,涵盖了从分类,信息检索到语义文本相似性,文本生成评估和上下文学习中的prompt检索
7. 效果
- 在70项评估任务中获得了平均3.4%的提升
- INSTRUCTOR的表现优于使用同样结构但是没有task instructions的变体,通过这个实验证明了instructions对task-aware embedding的重要性
- 分析表明,INSTRUCTOR对指令的变化很鲁棒,指令微调减轻了在不同数据集上训练单个模型的挑战
8. 分析
-
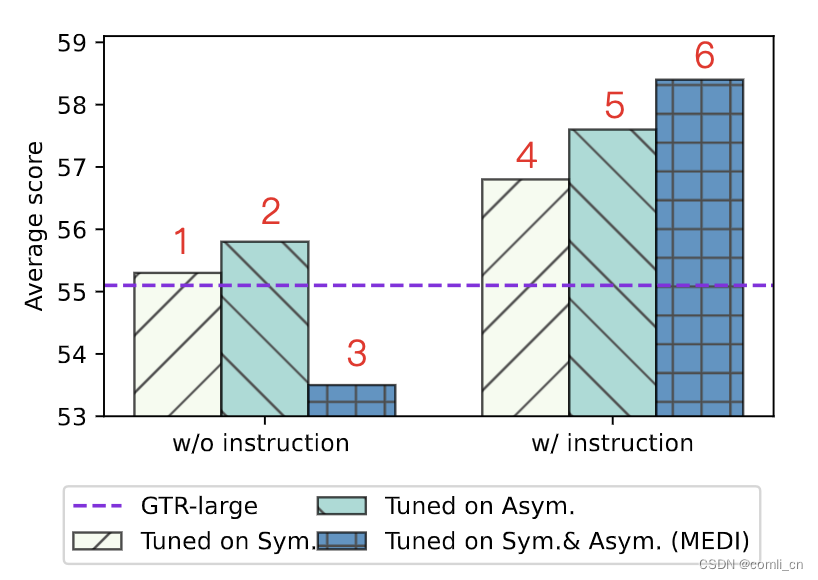
使用instructions对INSTRUCTOR进行finetune可以让模型在多个任务上表现出色。对比实验,将MEDI分为对称group和非对称group,在inetune时没有instructions的情况下INSTRUCTOR单独在对称group或非对称group里的表现与原始的GTR模型相似,但是如果将两个group混合的话inetune时没有instructions表现就会变差。如下图所示,w/o表示without,左右相比可以看到蓝色的网格条有很明显的提升,绿色和黄色的也有提升,证明了instructions的重要性。
-
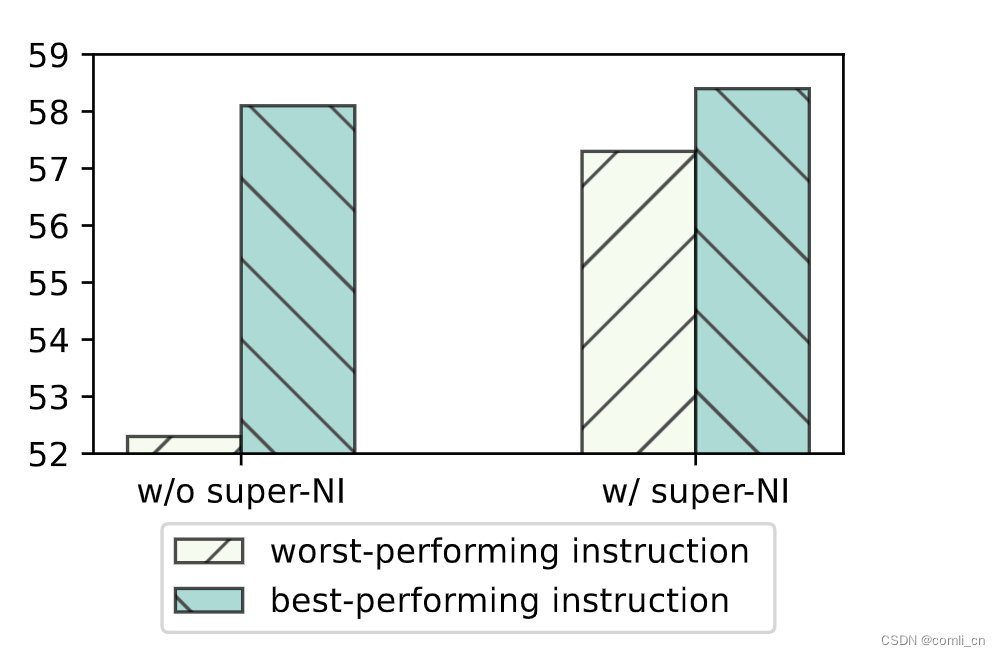
使用instructions对INSTRUCTOR进行finetune可以让模型的鲁棒性增加,如下图所示,加入instructions之后在super-NI上最好的表现与最差表现之间的差距明显变小了,模型比较稳定了。
-
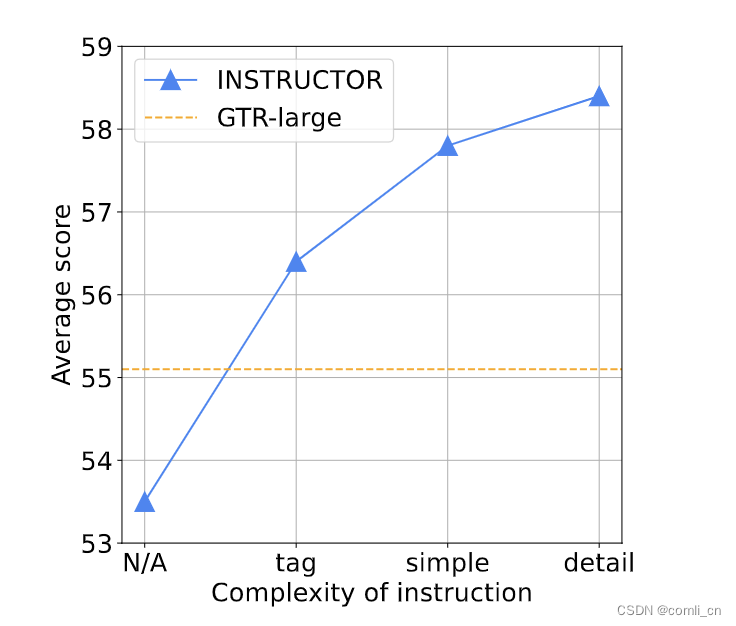
instructions越复杂模型表现越好,如下图所示,N/A表示没有instructions,tag表示提供了数据集的名字,simple表示给任务领域提供了一两个词的描述,detail表示instructions提供全了
-
model size越大表现越好
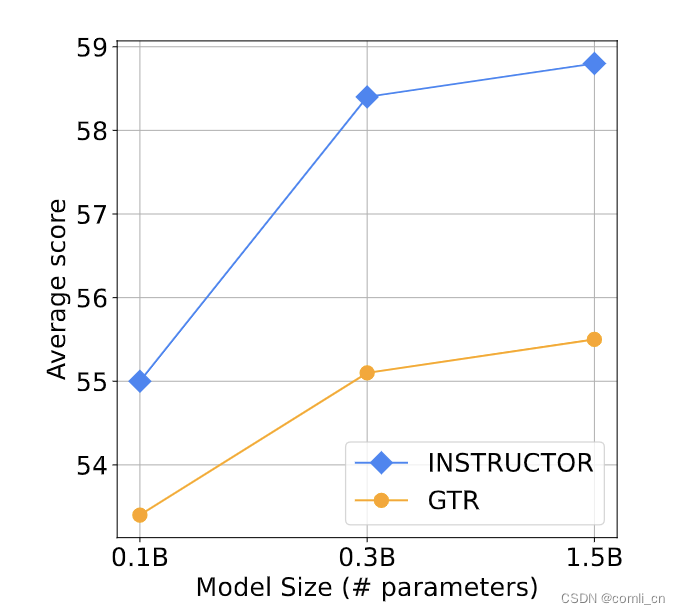
-
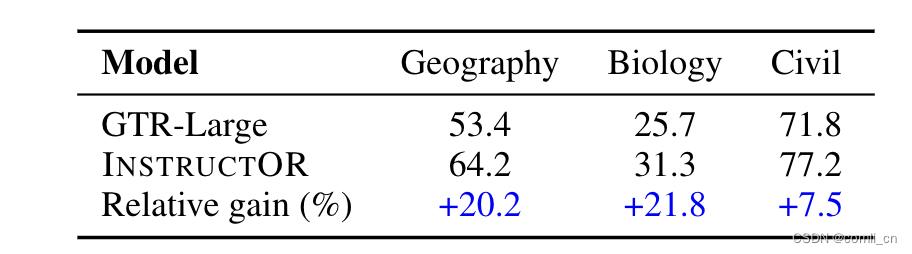
在没有见过的领域表现更好,如下表所示,在没有学习过的三个领域INSTRUCTOR相较于GTR-Large都有明显的优势
-
语义相似的vector距离更近,语义不同的vector距离更远,如下图所示,红色圈圈是语义相似的,绿色圆圈是语义不同的,圆圈带实框的是有instructions的,圆圈没有带实框的是没有instructions的

9. T5模型
- 所谓的 T5 模型其实就是个 Transformer 的 Encoder-Decoder 模型,BERT只用了Encoder,GPT只用了Decoder
- T5训练数据的清洗工作
- 只保留结尾是正常符号的行;
- 删除任何包含不好的词的页面,具体词表参考List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words库,里面中文列表有319个词
- 包含 Javascript 词的行全去掉
- 包含编程语言中常用大括号的页面
- 任何包含”lorem ipsum(用于排版测试)“的页面
- 连续三句话重复出现情况,保留一个
- T5模型的训练方法
- Transformer Encoder-Decoder 模型
- BERT-style 式的破坏方法
- Replace Span 的破坏策略
- 15 %的破坏比
- 3 的破坏时小段长度
- T5的不同尺寸模型
- Small,Encoder 和 Decoder 都只有 6 层,隐维度 512,8 头
- Base,相当于 Encoder 和 Decoder 都用 BERT-base
- Large,Encoder 和 Decoder 都用 BERT-large 设置,除了层数只用 12 层
- 3B(Billion)和11B,层数都用 24 层,不同的是其中头数量和前向层的维度
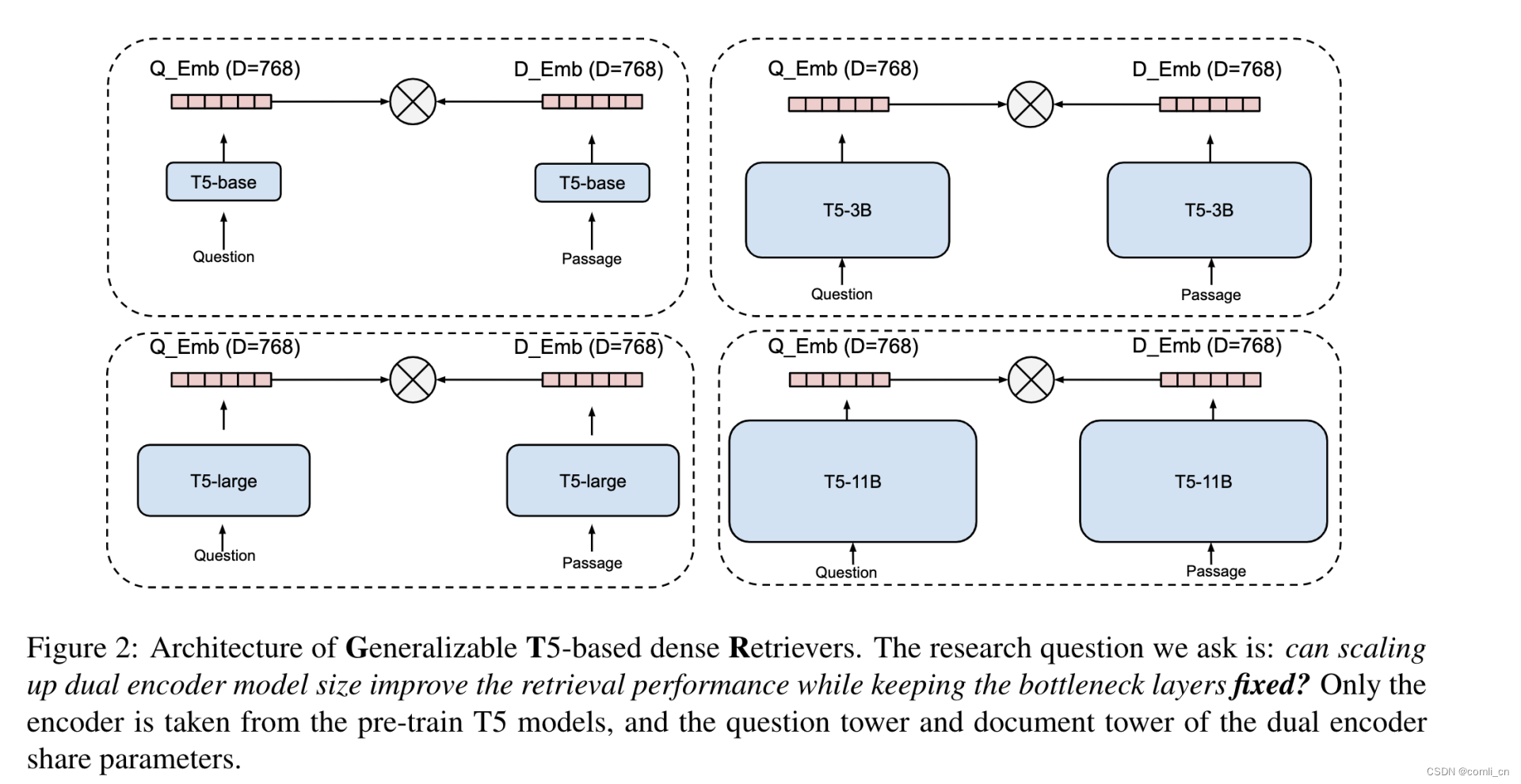
10. GTR模型
-
提出的思路:在bottleneck embedding固定不变的情况下(768)增加双塔编码器的尺寸(用T5模型进行编码)可以获取表现更好的embeddingbottleneck embedding
-
模型结构:
-
训练数据:pretrain使用的是2B的query-answer对,finetune用的是MS Marco
-
结论:
- 尽管bottleneck embedding的尺寸是固定的,但是增加编码器的尺寸会使的模型拥有更好的泛化性
- 是用问答数据进行预训练和用人类标注的数据进行finetune对用充分利用大模型优秀的能力是很重要的
- GTR在利用人类标注数据上表现出了很高的效率,只需要用10%的MS Marco就可以提神模型在领域外的泛化能力
参考:
- 代码:instructor-embedding
相关文章:
论文阅读:One Embedder, Any Task: Instruction-Finetuned Text Embeddings
1. 优势 现存的emmbedding应用在新的task或者domain上时表现会有明显下降,甚至在相同task的不同domian上的效果也不行。这篇文章的重点就是提升embedding在不同任务和领域上的效果,特点是不需要用特定领域的数据进行finetune而是使用instuction finetun…...

[BUUCTF NewStarCTF 2023 公开赛道] week3 crypto/pwn
居然把第3周忘了写笔记了. 后边难度上来了,还是很有意思的 Crypto Rabins RSA rsa一般要求e与phi互质,但rabin一般用2,都是板子题也没什么好解释的 from Crypto.Util.number import * from secret import flag p getPrime(64) q getPrime(64) assert p % 4 3 assert q %…...

软件测试---边界值分析(功能测试)
能对限定边界规则设计测试点---边界值分析 选取正好等于、刚好大于、刚好小于边界的值作为测试数据 上点: 边界上的点 (正好等于);必选(不考虑区开闭) 内点: 范围内的点 (区间范围内的数据);必选(建议选择中间范围) 离点: 距离上点最近的点 (刚好…...
使用pytorch处理自己的数据集
目录 1 返回本地文件中的数据集 2 根据当前已有的数据集创建每一个样本数据对应的标签 3 tensorboard的使用 4 transforms处理数据 tranfroms.Totensor的使用 transforms.Normalize的使用 transforms.Resize的使用 transforms.Compose使用 5 dataset_transforms使用 1 返回本地…...

http进一步认识
好久不见各位,今天为大家带来http协议的进一步认识 文章目录 👀http协议的认识👀新的改变 👀http协议的认识 http协议经历了三个版本的演化,HTTP0.9是第一个版本的协议,它的组成极其简单,只涉…...

grafana docker安装
grafana docker安装 Grafana是一款用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。目前使用grafana的公司有很多,如paypal、ebay、intel等。 Grafana 是 Graphite 和 InfluxDB 仪表盘和图形编辑器。Grafana 是开…...
【Kubernetes】初识k8s--扫盲阶段
文章目录 1、k8s概述2、为什么要有k8s2.1 回顾以往的应用部署方式2.2 容器具有的优势 3、k8s能带来什么 1、k8s概述 kubernetes是一个可移植、可扩展的开源平台,用于管理 容器化 的工作负载和服务,可促进申明式配置和自动化。kubernetes拥有一个庞大且快…...

“01”滴答“摩尔斯电码”加密解密单个字符
“01”替换滴嗒“.-”“摩尔斯电码”字符,加密解密键盘输入的单个字符。 (本笔记适合熟悉循环和列表的 coder 翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free:大咖免费“圣经”教程《 python 完全自学教程》&a…...

P3817 小A的糖果
Portal. 贪心。 注意到这里的盒子不会被删除,只会改变盒子的值。问题立刻简单化了。对于一组相邻的糖果个数和大于 x x x 的盒子组,优先吃掉靠后的盒子。 证明正确性也很显然,因为减少后面的盒子的糖果数可以使得后面的情况更优。 #incl…...
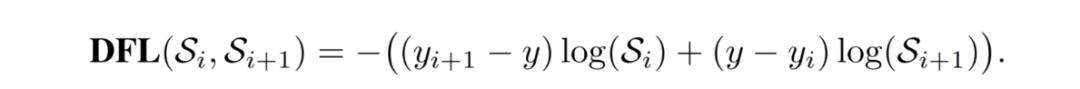
Yolov8目标识别与实例分割——算法原理详细解析
前言 YOLO是一种基于图像全局信息进行预测并且它是一种端到端的目标检测系统,最初的YOLO模型由Joseph Redmon和Ali Farhadi于2015年提出,并随后进行了多次改进和迭代,产生了一系列不同版本的YOLO模型,如YOLOv2、YOLOv3、YOLOv4&a…...

HandlerMethodArgumentResolver方法参数解析器支持多用户
1、概述 HandlerMethodArgumentResolver,中文称为方法参数解析器,是Spring Web(SpringMVC)组件中的众多解析器之一,主要用来对Controller中方法的参数进行处理。 使用场景 在一般的接口调用场景下,每次调用Controller都需要检查请求中的token信息,并根据token还原用户信息…...

【Linux】 man命令使用
介绍 man命令是Linux下最核心的命令之一。而man命令也并不是英文单词“man”的意思,它是单词manual的缩写,即使用手册的意思。 man命令会列出一份完整的说明。 其内容包括命令语法、各选项的意义及相关命令 。更为强大的是,不仅可以查看Lin…...

同一个数据库服务器进行数据表间的数据迁移-MySQL
同一个数据库服务器进行数据表间的数据迁移 一、相同结构的表数据迁移/备份/导入到同一MySQL的某个库的某张表 实验目标:将t1.table_one的数据备份到migration_one.table_11(提醒:这两个表结构一致) 同一个MySQL中有很多库&…...

适用于 Linux 的 WPF:Avalonia
许多年前,在 WPF 成为“Windows Presentation Foundation”并将 XAML 作为 .NET、Windows 等的 UI 标记语言引入之前,有一个代号为“Avalon”的项目。Avalon 是 WPF 的代号。XAML 现在无处不在,XAML 标准是一个词汇规范。 Avalonia 是一个开…...

【教3妹学编程-算法题】数组中两个数的最大异或值
3妹:“太阳当空照,花儿对我笑,小鸟说早早早,你为什么背上炸药包” 2哥 :3妹,什么事呀这么开心呀。 3妹:2哥你看今天的天气多好啊,阳光明媚、万里无云、秋高气爽,适合秋游。 2哥&…...

STM32-RTC实时时钟
目录 RTC实时时钟 功能框图 UNIX时间戳 初始化结构体 RTC时间结构体 RTC日期结构体 RTC闹钟结构体 进入和退出配置函数 实验环节1:显示日历 常规配置 RTC配置 测试环节 实验现象 实验环节2:闹钟 常规配置 RTC配置 测试环节 实验现象 R…...

初学Flutter,实现底部导航切换
效果展示 flutter bottomNavBar 主要实现代码 入口文件:main.dart import package:flutter/material.dart; import package:flutter_demo/components/bottomNavBar.dart; import package:flutter_demo/views/cart.dart; import package:flutter_demo/views/cata.d…...
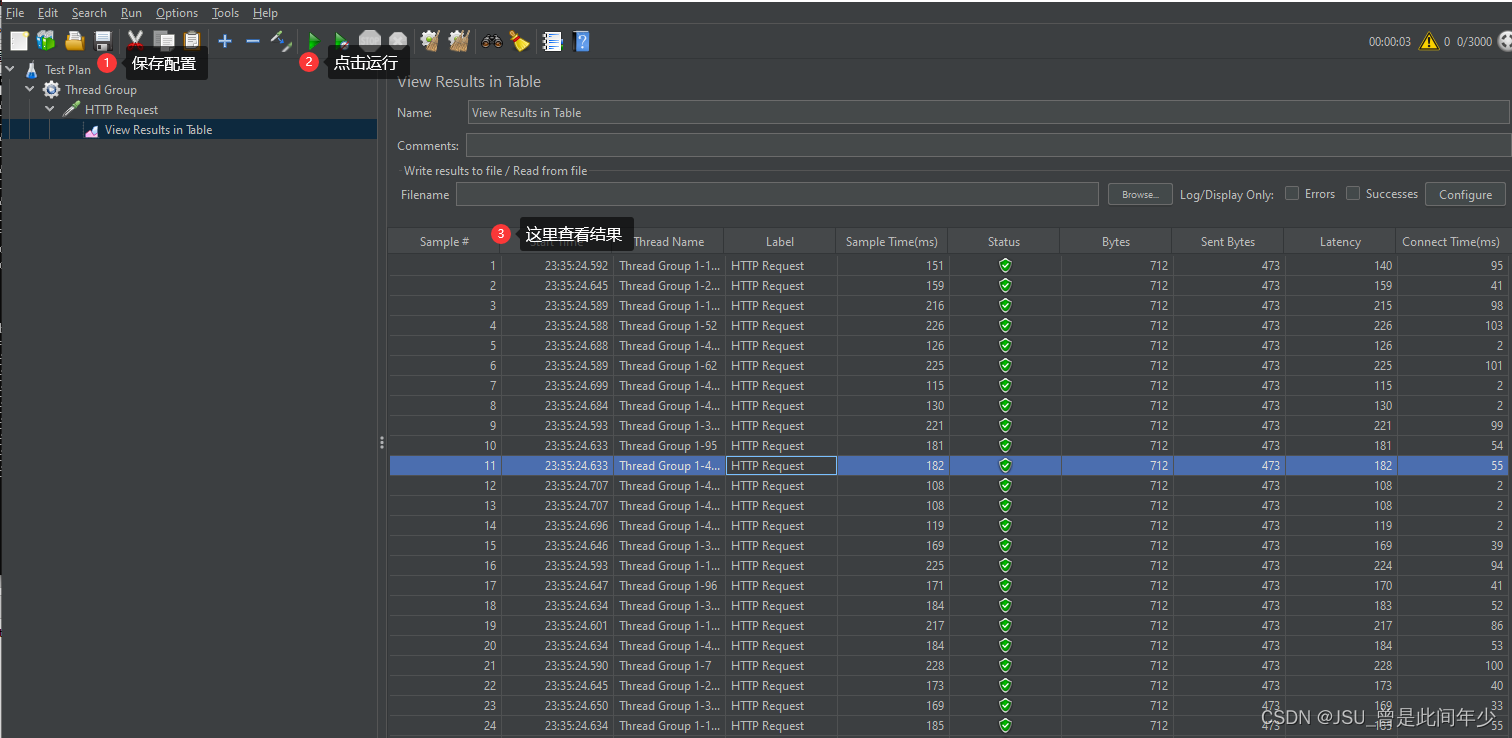
使用JMeter进行接口压力测试
1.我首先创建一个线程组 2.创建好之后如图所示 3. 进行配置 4. 然后添加一个https请求 5.创建好之后设置请求方法和对应参数 6.设置表格监听器 7.创建好之后如图所示 8.保存jmx文件后点击运行进行测试,结果反馈如下图...
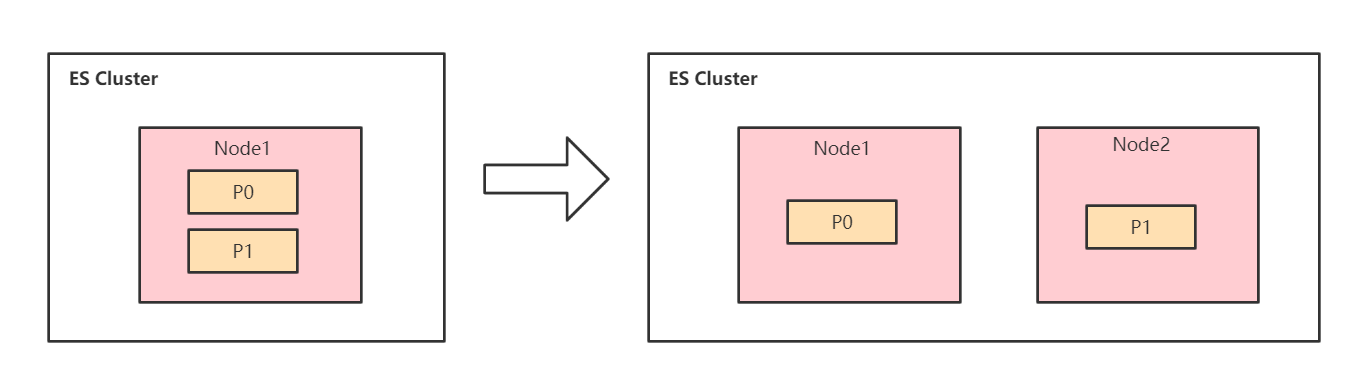
ElasticSearch集群架构实战及其原理剖析
ES集群架构 为什么要使用ES集群架构 分布式系统的可用性与扩展性: 高可用性 服务可用性:允许有节点停止服务;数据可用性:部分节点丢失,不会丢失数据; 可扩展性 请求量提升/数据的不断增长(将数据分布…...

选择适合你的办公桌:提高工作效率的关键
在如今的数字时代,越来越多的人将办公桌移到家里或办公室。但是,如何选择适合你的办公桌可能是个挑战。不同的工作需要和工作空间大小会影响你的选择。下面是一些简单的建议,帮助你找到适合你的办公桌,提高工作效率。 首先&…...

国产手机涨价,苹果却开启了降价模式,618可能还要降,怎么打?
苹果的iPhone17可能是苹果史上降价最慢的手机了,这款手机上市以来降价速度非常缓慢,但是昨晚苹果CEO库克还中国的时候,苹果就官宣iPhone17Pro系列降价1000元,与国产手机因存储芯片涨价而涨价形成鲜明对比。值得注意的是当下iPhone…...

MCP服务器构建指南:安全连接AI与外部工具的核心架构与实战
1. 项目概述:MCP服务器生态的构建者如果你最近在关注AI智能体开发,尤其是围绕Claude、Cursor这类工具的生态,那么“MCP”这个词大概率已经在你耳边出现了无数次。ViswaSrimaan/mcp_servers这个项目,正是这个新兴浪潮中的一个关键基…...
)
告别默认视图:5个CloudCompare点云可视化高级技巧(颜色映射、尺寸分级、OpenGL优化)
告别默认视图:5个CloudCompare点云可视化高级技巧(颜色映射、尺寸分级、OpenGL优化) 在三维点云处理领域,可视化效果直接影响数据分析的深度与决策效率。CloudCompare作为开源点云处理利器,其默认视图设置往往难以满足…...

从零构建C语言静态库:工程实践与避坑指南
1. 项目概述:为什么我们需要亲手打造一个静态库?在C语言的开发世界里,尤其是当你从编写单个文件的小程序,过渡到管理一个包含数十上百个源文件的中大型项目时,一个绕不开的话题就是代码的组织与复用。你可能有过这样的…...

2026春招AI人才争夺战白热化!小白程序员如何抓住13万高薪机遇?速收藏!
2026年春招显示AI领域岗位量同比增长8.7倍,成为职场新风口。具身智能岗位薪资暴增,AI科学家月薪高达13.2万元。高薪AI岗位紧缺,程序员需拥抱AI工具提升竞争力,否则面临被替代风险。AI能力已成为职场基础设施,不学AI可能…...

如何在5分钟内免费创建4K虚拟显示器:ParsecVDisplay终极指南
如何在5分钟内免费创建4K虚拟显示器:ParsecVDisplay终极指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 想要在Windows电脑上快速扩展工作空间,享受4K…...

掌握高效B站会员购抢票技巧:biliTickerBuy实战指南
掌握高效B站会员购抢票技巧:biliTickerBuy实战指南 【免费下载链接】biliTickerBuy b站会员购购票辅助工具 项目地址: https://gitcode.com/GitHub_Trending/bi/biliTickerBuy biliTickerBuy是一款专为B站会员购平台设计的开源抢票辅助工具,通过P…...

Agnix:构建AI原生操作系统,实现智能体即应用新范式
1. 项目概述:从“智能体”到“操作系统”的范式跃迁最近在开源社区里,一个名为agent-sh/agnix的项目引起了我的注意。乍一看这个名字,很容易联想到当下火热的“AI智能体”(Agent),但深入研究后你会发现&…...

在Windows上安装APK的终极指南:5步掌握APK Installer工具
在Windows上安装APK的终极指南:5步掌握APK Installer工具 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上直接安装Android应用…...

Unity问题记录
一个物体在Scene窗口看不见,Game窗口能看见。选中它时,打开Gizmos也看不见身上碰撞体的线框。也无法被射线检测到。换成其他Mesh:Open Asset In Context正常显示:把它Revert回预制体,还是不显示。Ctrl D复制一个&#…...