实习记录--(海量数据如何判重?)--每天都要保持学习状态和专注的状态啊!!!---你的未来值得你去奋斗
海量数据如何判重?
判断一个值是否存在?解决方法:
1.使用哈希表:
可以将数据进行哈希操作,将数据存储在相应的桶中。
查询时,根据哈希值定位到对应的桶,然后在桶内进行查找。这种方法的时间复杂度为 O(1),但需要额外的存储空间来存储哈希表。如果桶中存在数据,则说明此值已存在,否则说明未存在。
2.使用布隆过滤器:
布隆过滤器是一种概率型数据结构,用于判断一个元素是否在集合中。它利用多个哈希函数映射数据到一个位数组,并将对应位置置为 1。
查询时,只需要对待查询的数据进行哈希,并判断对应的位是否都为 1。如果都为 1,则该数据可能存在;如果有一个位不为 1,则该数据一定不存在。布隆过滤器的查询时间复杂度为 O(k),其中 k 为哈希函数的个数。
相同点和不同点
相同点:
它们都存在误判的情况。
例如,使用哈希表时,不同元素的哈希值可能相同,所以这样就产生误判了;
而布隆过滤器的特征是,当布隆过滤器说,某个数据存在时,这个数据可能不存在;当布隆过滤器说,某个数据不存在时,那么这个数据一定不存在
不同点:
存储机制:
哈希表使用一个数组来存储键值对,通过哈希函数将键映射到数组的索引位置,然后将值存储在对应的位置上。
布隆过滤器则使用一个位数组(或位向量),通过多个哈希函数将元素映射到位数组的多个位上。
查询操作:
哈希表在进行查询时,通过计算哈希值来定位键值对的存储位置,然后直接获取对应的值。查询时间复杂度通常为 O(1)。
布隆过滤器在进行查询时,也通过多个哈希函数计算多个位,然后判断对应的位是否都为 1 来确定元素是否存在。查询时间复杂度为 O(k),其中 k 为哈希函数的个数。
内存占用:
哈希表需要根据数据规模来动态调整数组的大小,以保证存储效率。
布隆过滤器在预先设置位数组的大小后,不会随数据规模的增加而增长。因此布隆过滤器更适用于海量数据。
结论:
哈希表和布隆过滤器都能实现判重,但它们都会存在误判的情况,但布隆过滤器存储占用的空间更小,更适合海量数据的判重。
布隆过滤器实现原理:
布隆过滤器的实现:主要依靠的是它数据结构中的一个位数组,每次存储键值的时候,不是直接把数据存储在数据结构中,因为这样太占空间了,它是利用几个不同的无偏哈希函数,把此元素的 hash 值均匀的存储在位数组中,也就是说,每次添加时会通过几个无偏哈希函数算出它的位置,把这些位置设置成 1 就完成了添加操作。
当进行元素判断时,查询此元素的几个哈希位置上的值是否为 1,如果全部为 1,则表示此值存在,如果有一个值为 0,则表示不存在。因为此位置是通过 hash 计算得来的,所以即使这个位置是 1,并不能确定是那个元素把它标识为 1 的,因此布隆过滤器查询此值存在时,此值不一定存在,但查询此值不存在时,此值一定不存在。
并且当位数组存储值比较稀疏的时候,查询的准确率越高,而当位数组存储的值越来越多时,误差也会增大。
位数组和 key 之间的关系,如下图
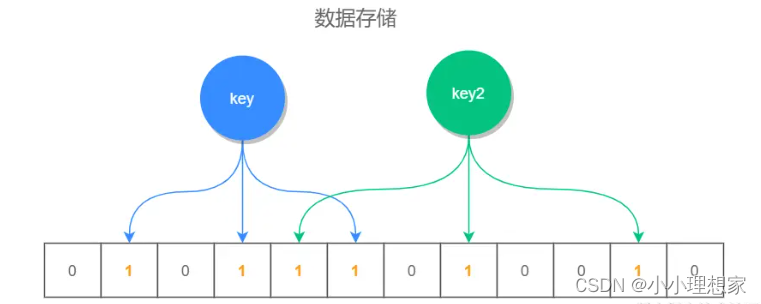
如何实现布隆过滤器?
1.通过程序实现(内存级别方案):使用 Google Guava 库实现布隆过滤器。
2.通过中间件实现(支持数据持久化):使用 Redis 4.0 之后提供的布隆过滤插件来实现,它的好处是支持持久化,数据不会丢失。
一、什么是Guava
1)Guava库是一个适合很多Java项目的通用工具库
2)Guava工具库中包含了:集合Collection、并发Concurrency、原语Primitive、反射Reflection、比较Comparison、I/O操作、哈希Hash、网络Networking、字符串String、数学函数Math、缓存Caching、内存中的发布/订阅……以及各种级别的数据类型
3)需要JDK 6以上版本
使用 Google Guava 库实现布隆过滤器总共分为以下两步:
- 引入 Guava 依赖
- 使用 Guava API 操作布隆过滤器
① 引入 Guava 依赖
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId>
</dependency>② 使用 Guava API
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;public class BloomFilterExample {public static void main(String[] args) {// 创建一个布隆过滤器,设置期望插入的数据量为10000,期望的误判率为0.01BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.unencodedCharsFunnel(), 10000, 0.01);// 向布隆过滤器中插入数据bloomFilter.put("data1");bloomFilter.put("data2");bloomFilter.put("data3");// 查询元素是否存在于布隆过滤器中System.out.println(bloomFilter.mightContain("data1")); // trueSystem.out.println(bloomFilter.mightContain("data4")); // false}
}在上述示例中,我们通过 BloomFilter.create() 方法创建一个布隆过滤器,指定了元素序列化方式、期望插入的数据量和期望的误判率。然后,我们可以使用 put() 方法向布隆过滤器中插入数据,使用 mightContain() 方法来判断元素是否存在于布隆过滤器中。
相关文章:
实习记录--(海量数据如何判重?)--每天都要保持学习状态和专注的状态啊!!!---你的未来值得你去奋斗
海量数据如何判重? 判断一个值是否存在?解决方法: 1.使用哈希表: 可以将数据进行哈希操作,将数据存储在相应的桶中。 查询时,根据哈希值定位到对应的桶,然后在桶内进行查找。这种方法的时间复…...
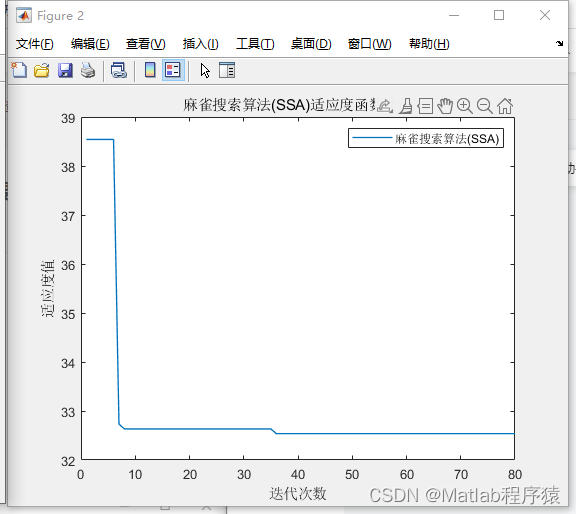
【MATLAB源码-第67期】基于麻雀搜索算法(SSA)的无人机三维地图路径规划,输出最短路径和适应度曲线。
操作环境: MATLAB 2022a 1、算法描述 麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新颖的元启发式优化算法,它受到麻雀社会行为的启发。这种算法通过模拟麻雀的食物搜索行为和逃避天敌的策略来解决优化问题。SSA通过模…...
Promise的并发控制 - 从普通并发池到动态并发池
一、场景 给你一个有200个URL的数组,通过这些URL来发送请求,要求并发请求数不能超过五个。 这是一道很常考的面试题,接下来让我们来学习一下Promise并发控制 二、普通并发池的实现 主要思路就是,判断当前队列是否满,…...
Java类加载机制(类加载器,双亲委派模型,热部署示例)
Java类加载机制 类加载器类加载器的执行流程类加载器的种类加载器之间的关系ClassLoader 的主要方法Class.forName()与ClassLoader.loadClass()区别 双亲委派模型双亲委派 类加载流程优缺点 热部署简单示例 类加载器 类加载器的执行流程 类加载器的种类 AppClassLoader 应用类…...
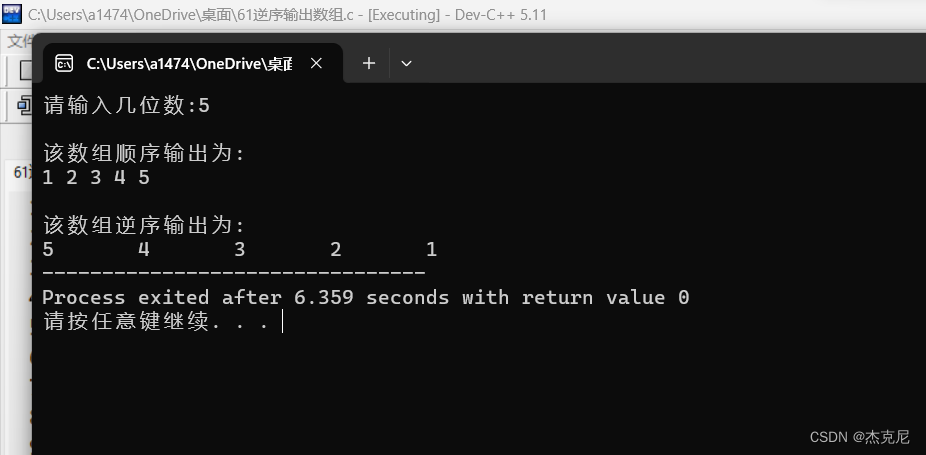
【C语言初学者周冲刺计划】3.2将一个数组中的值逆序重新存放
目录 1解题思路: 2代码 3运行代码如图: 4总结: 1解题思路: 首先学会如何利用循环输入位数和输入数值,然后再利用循环逆序即可 2代码 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> int main() { int…...
【C++心愿便利店】No.11---C++之string语法指南
文章目录 前言一、 为什么学习string类二、标准库中的string类 前言 👧个人主页:小沈YO. 😚小编介绍:欢迎来到我的乱七八糟小星球🌝 📋专栏:C 心愿便利店 🔑本章内容:str…...

OpenCV检测圆(Python版本)
文章目录 示例代码示例结果调参 示例代码 import cv2 import numpy as np# 加载图像 image_path DistanceComparison/test_image/1.png image cv2.imread(image_path, cv2.IMREAD_COLOR)# 将图像转换为灰度 gray cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)# 使用高斯模糊消除…...

轻量封装WebGPU渲染系统示例<15>- DrawInstance批量绘制(源码)
当前示例源码github地址: https://github.com/vilyLei/voxwebgpu/blob/main/src/voxgpu/sample/DrawInstanceTest.ts 此示例渲染系统实现的特性: 1. 用户态与系统态隔离。 细节请见:引擎系统设计思路 - 用户态与系统态隔离-CSDN博客 2. 高频调用与低频调用隔离。…...

E: 仓库 “http://cn.archive.ubuntu.com/ubuntu kinetic Release” 没有 Release 文件。
sudo apt-get update时报以下错误: E: 仓库 “http://cn.archive.ubuntu.com/ubuntu kinetic Release” 没有 Release 文件。 N: 无法安全地用该源进行更新,所以默认禁用该源。 N: 参见 apt-secure(8) 手册以了解仓库创建和用户配置方面的细节。 E: 仓库…...

【VR开发】【Unity】【VRTK】3-VR项目设置
任何VR避不开的步骤 如何设置VR项目,无论是PC VR还是安卓VR,我在不同的系列教程中都说过了,不过作为任何一个VR开发教程都难以避免的一环,本篇作为VRTK的开发教程还是对VR项目设置交代一下。 准备好你的硬件 头盔必须是6DoF的,推荐Oculus Quest系列,Rift系列,HTC和Pi…...

git log 用法
git log --format"%s" -n 1在 Git 中,您可以使用 git log 命令来查看提交历史,其中包含每个提交的详细信息,包括提交消息。如果您只想提取提交信息而不是完整的 git log 输出,可以使用 git log 命令的 --format 选项来指…...

Linux学习---有关监控系统zabbix的感悟
监控系统 监控系统就像咱们日常生活中小区监控(Monitor),用于及时发现问题(PROBLEM),根据相应的规则可以触发警告(Media),在后台显示屏(Dashboard)上以某种方面显示出来,高级的报警系统也许还能实现电话通知等功能,目的是为及时发…...

apollo云实验:定速巡航场景仿真调试
定速巡航场景仿真调试 概述启动仿真环境仿真系统修改默认巡航速度 实验目的福利活动 主页传送门:📀 传送 概述 自动驾驶汽车在实现落地应用前,需要经历大量的道路测试来验证算法的可行性和系统的稳定性,但道路测试存在成本高昂、…...

基于RK3568的新能源储能能量管理系统ems
新能源储能能量管理系统(EMS)是一种基于现代化技术的系统,旨在管理并优化新能源储能设备的能量使用。 该系统通过监测、调度和控制新能源储能设备来确保能源的高效利用和可持续发展。 本文将从不同的角度介绍新能源储能能量管理系统的原理、…...
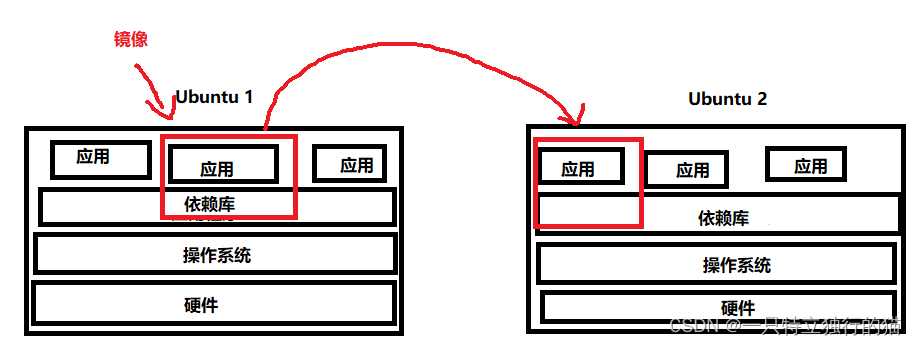
dockerfile避坑笔记(VMWare下使用Ubuntu在Ubuntu20.04基础镜像下docker打包多个go项目)
一、docker简介 docker是一种方便跨平台迁移应用的程序,通过docker可以实现在同一类操作系统中,如Ubuntu和RedHat两个linux操作系统中,实现程序的跨平台部署。比如我在Ubuntu中打包了一个go项目的docker镜像(镜像为二进制文件&am…...

Qt 使用QtXlsx操作Excel表
1.环境搭建 QtXlsx是一个用于读写Microsoft Excel文件(.xlsx)的Qt库。它提供了一组简单易用的API,可以方便地处理电子表格数据。 Github下载:GitHub - dbzhang800/QtXlsxWriter: .xlsx file reader and writer for Qt5 官方文档…...

canal+es+kibana+springboot
1、环境准备 服务器:Centos7 Jdk版本:1.8 Mysql版本:5.7.44 Canal版本:1.17 Es版本:7.12.1 kibana版本:7.12.1 软件包下载地址:链接:https://pan.baidu.com/s/1jRpCJP0-hr9aI…...

【力扣】面试经典150题——双指针
文章目录 125. 验证回文串392. 判断子序列167. 两数之和 II - 输入有序数组11. 盛最多水的容器15. 三数之和 125. 验证回文串 如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。 字…...
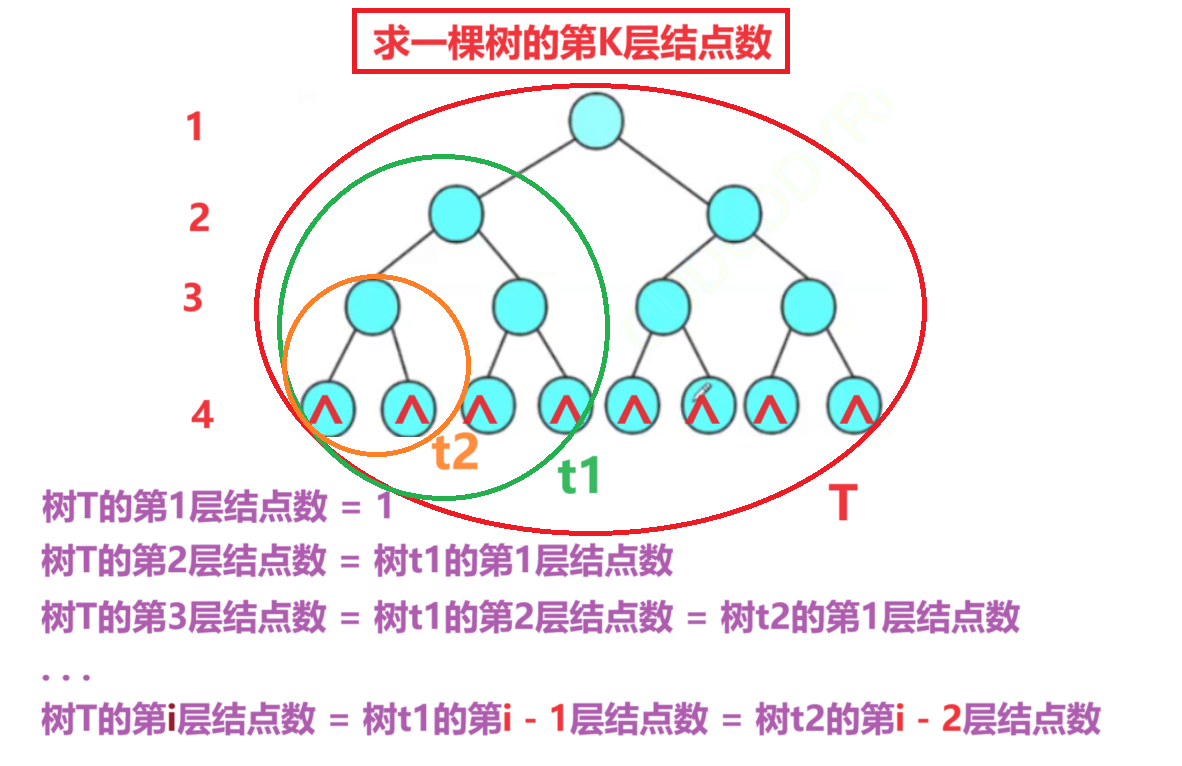
6-8 最宽层次结点数 分数 10
文章目录 1.题目描述2.本题ac答案2.1法一: 代码复用2.2法二: 顺序队列实现层序遍历 3.C层序遍历求最大宽度3.1层序遍历代码3.2求最大宽度 1.题目描述 2.本题ac答案 2.1法一: 代码复用 //二叉树第i层结点个数 int LevelNodeCount(BiTree T, int i) {if (T NULL || i < 1)re…...

Linux学习第28天:Platform设备驱动开发(二): 专注与分散
Linux版本号4.1.15 芯片I.MX6ULL 大叔学Linux 品人间百味 思文短情长 三、硬件原理图分析 四、驱动开发 1、platform设备与驱动程序开发 53 /* 54 * 设备资源信息,也就是 LED0 所使用的所有寄存器 55 */ 56 static str…...

探索中医数字化:基于深度学习的舌苔检测项目推荐
探索中医数字化:基于深度学习的舌苔检测项目推荐 【下载地址】基于深度学习的舌苔检测毕设留档 本项目是针对中医领域中舌象分析的一项研究,通过应用深度学习技术来实现自动的舌苔检测。随着人工智能在医疗健康领域的深入发展,利用计算机视觉…...

医疗设备晶振精度:从ppm偏差到诊断治疗安全的关键影响
1. 项目概述:从一颗“心跳”说起在医疗设备这个对可靠性要求近乎苛刻的领域,我们常常关注传感器精度、算法鲁棒性、材料生物相容性这些显性指标。然而,有一个看似不起眼、却如同设备“心跳”般至关重要的基础元件——晶体振荡器,也…...

Perplexity实时新闻查询效率翻倍:从API调用到结果过滤的7个隐藏技巧
更多请点击: https://codechina.net 第一章:Perplexity实时新闻查询效率翻倍:从API调用到结果过滤的7个隐藏技巧 Perplexity 的实时新闻 API(如 /search/news 端点)在默认配置下常因冗余字段、未压缩响应和同步阻塞而…...

LLMs 的新前沿:挑战、解决方案与工具
原文:towardsdatascience.com/the-new-frontiers-of-llms-challenges-solutions-and-tools-b1d48c34cf8e?sourcecollection_archive---------2-----------------------#2024-01-25 https://towardsdatascience.medium.com/?sourcepost_page---byline--b1d48c34cf8…...

基于Next.js与Shadcn/ui的现代Web仪表盘开发实战指南
1. 项目概述与核心价值 最近在折腾一个开源项目,叫 openclaw-dashboard ,是 anis-marrouchi 大佬在 GitHub 上开源的一个仪表盘项目。光看名字,你可能会觉得这又是一个平平无奇的“又一个仪表盘”,但实际深入把玩之后&#x…...

Wireshark 和 tcpdump 到底怎么选?一线排障中抓包工具的适用场景、边界与判断标准
Wireshark 和 tcpdump 到底怎么选?一线排障中抓包工具的适用场景、边界与判断标准 很多团队一遇到网络慢、连接断续、接口超时,第一反应就是“先抓包”。问题是:抓包不是答案,抓什么、在哪抓、用什么工具抓,才决定你能…...

Win11家庭版隐藏功能解锁:除了gpedit.msc,这些高级设置你也能用了
Win11家庭版隐藏功能深度解锁:从组策略到系统优化的高阶玩法 当你第一次在Win11家庭版中成功唤出组策略编辑器(gpedit.msc)时,面对密密麻麻的策略项是否感到无从下手?这就像拿到了一把万能钥匙,却不知道哪些…...

3步快速上手Univer:从零构建企业级办公套件的完整指南
3步快速上手Univer:从零构建企业级办公套件的完整指南 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsheets is d…...

用STM32G431RBT6复刻一个简易示波器+信号发生器:蓝桥杯嵌入式外设综合应用实战
基于STM32G431RBT6的嵌入式示波器与信号发生器开发实战 在嵌入式系统开发领域,将理论知识转化为实际应用能力是每个工程师成长的必经之路。本文将带你使用STM32G431RBT6开发板,从零开始构建一个兼具示波器和信号发生器功能的综合系统。这个项目不仅能够…...

单片机代码优化实战:从数据类型到算法与数据结构的效率提升
1. 项目概述:为什么单片机代码需要“斤斤计较”?如果你是从PC端或者服务器端开发转过来的朋友,第一次接触单片机编程,可能会觉得处处掣肘。在PC上,我们习惯了动辄几个G的内存,上百G的硬盘,CPU频…...