[Machine Learning] Learning with Noisy Labels
文章目录
- 随机分类噪声 (Random Classification Noise, RCN)
- 类别依赖的标签噪声 (Class-Dependent Noise, CCN)
- 二分类
- 多分类
- 实例和类别依赖的标签噪声 (Instance and Label-Dependent Noise, ILN)
标签噪声是指分类任务中的标签被错误地标记。这可能是由于各种原因,如数据收集错误、主观偏见或其他噪声源。
在有监督的机器学习中,标签噪声指的是数据集中的标签可能不准确或错误。这种噪声可以分为两种类型:
-
类别依赖标签噪声:这种噪声的特点是标签错误的概率仅依赖于真实的类别标签。举个例子,猫的图片可能被错误地标记为狗,而这种错误与图片的具体内容无关。
-
实例依赖标签噪声:在这种情况下,标签错误的概率依赖于每个具体的实例。比如,某些猫的图片可能由于其特定的特征(如颜色或姿态)更容易被错误地标记为狗。
风险度量了模型的预测与真实输出之间的差异。
-
期望的0-1风险 (Expected 0-1 Risk):
R D ( f ) = P ( sign ( f ( X ) ) ≠ Y ) = E ( X , Y ) ∼ D [ 1 ( sign ( f ( X ) ) ≠ Y ) ] R_D(f) = P(\text{sign}(f(X)) \neq Y) = \mathbb{E}_{(X,Y) \sim D}[1(\text{sign}(f(X)) \neq Y)] RD(f)=P(sign(f(X))=Y)=E(X,Y)∼D[1(sign(f(X))=Y)]
这度量了模型预测错误的概率。例如,对于二分类问题,这表示当模型的预测与真实标签不一致时的期望损失。
-
期望的L-风险 (Expected L-Risk):
R D , L ( f ) = E ( X , Y ) ∼ D [ L ( f ( X ) , Y ) ] R_{D,L}(f) = \mathbb{E}_{(X,Y) \sim D}[L(f(X),Y)] RD,L(f)=E(X,Y)∼D[L(f(X),Y)]
这是模型预测和实际标签之间损失函数L的期望值。L可以是任何度量预测错误的函数,例如均方误差、交叉熵等。
-
经验风险 (Empirical Risk):
R D , L , n ( f ) = 1 n ∑ i = 1 n L ( f ( X i ) , Y i ) R_{D,L,n}(f) = \frac{1}{n} \sum_{i=1}^{n} L(f(X_i),Y_i) RD,L,n(f)=n1i=1∑nL(f(Xi),Yi)
这代表了在训练集上模型的平均损失。
首先,考虑给定的训练样本集合:
{ ( X i , Y ~ i ) } 1 ≤ i ≤ n ∼ D ρ ( X , Y ~ ) n \{(X_i, \tilde Y_i )\}_{1 \leq i \leq n} \sim D_{\rho} (X, \tilde Y)^n {(Xi,Y~i)}1≤i≤n∼Dρ(X,Y~)n
这意味着我们有 n n n 个训练样本,每个样本 ( X i , Y ~ i ) (X_i, \tilde Y_i) (Xi,Y~i) 是从带噪声的分布 D ρ ( X , Y ~ ) D_{\rho} (X, \tilde Y) Dρ(X,Y~) 中抽取的。其中 X i X_i Xi 是特征或观察值,而 Y ~ i \tilde Y_i Y~i 是可能带有噪声的观察标签。
我们的目标是学习一个判别函数:
f n : X → R f_n: \mathcal{X} \rightarrow \mathbb{R} fn:X→R
对于标签噪声,我们引入以下概率模型:
ρ Y ( X ) = P ( Y ~ ∣ Y , X ) \rho_Y (X) = P(\tilde Y|Y, X) ρY(X)=P(Y~∣Y,X)
这里, ρ Y ( X ) \rho_Y (X) ρY(X) 描述了给定特征 X X X 和真实标签 Y Y Y 时观察到的噪声标签 Y ~ \tilde Y Y~ 的条件概率。
特别地:
ρ + 1 ( X ) = P ( Y ~ = − 1 ∣ Y = 1 , X ) \rho_{+1} (X) = P(\tilde Y = - 1|Y = 1, X) ρ+1(X)=P(Y~=−1∣Y=1,X)
ρ − 1 ( X ) = P ( Y ~ = 1 ∣ Y = − 1 , X ) \rho_{-1} (X) = P(\tilde Y = 1|Y = -1, X) ρ−1(X)=P(Y~=1∣Y=−1,X)
上面两个式子分别描述了当真实标签为 +1 和 -1 时,标签被错误观察(或翻转)的概率。
如果没有标签噪声,则我们可以很直接地说:
P ( Y ~ = 1 ∣ Y = 1 , X ) = P ( Y ~ = − 1 ∣ Y = − 1 , X ) = 1 P(\tilde Y = 1 |Y = 1, X) = P(\tilde Y = - 1|Y = -1, X) = 1 P(Y~=1∣Y=1,X)=P(Y~=−1∣Y=−1,X)=1
这意味着观察到的标签和真实标签总是相同的。
但是,如果存在标签噪声,观察到的标签可能与真实标签不同。这种情况下:
P ( Y ~ = 1 ∣ Y = − 1 , X ) , P ( Y ~ = − 1 ∣ Y = 1 , X ) ∈ ( 0 , 1 ) P(\tilde Y = 1|Y = -1, X), P(\tilde Y = - 1|Y = 1, X) \in (0,1) P(Y~=1∣Y=−1,X),P(Y~=−1∣Y=1,X)∈(0,1)
这表示,即使真实标签是 -1,观察到的标签为 1 的概率是非零的,并且在 (0,1) 范围内。同样,即使真实标签是 +1,观察到的标签为 -1 的概率也是非零的。
随机分类噪声 (Random Classification Noise, RCN)
这是最简单的噪声模型,其中噪声与观测值 X X X和真实标签 Y Y Y都无关。
ρ Y ( X ) = P ( Y ~ ∣ Y ) = ρ \rho_{Y} (X) = P(\tilde Y|Y) = \rho ρY(X)=P(Y~∣Y)=ρ
这意味着每个标签翻转的概率都是 ρ \rho ρ。
当我们使用线性分类器并且我们的目标是最小化一个凸损失函数时,如果我们的数据包含RCN,那么我们的分类性能可能会很差,类似于随机猜测。这是因为随机噪声可能会掩盖数据的真实模式,导致学习算法无法找到有意义的边界。因此,尽管我们成功地最小化了损失函数,但分类器可能仍然表现得像是在随机猜测。
首先,让我们再次明确什么是RCN。当我们得到一个样本的标签时,这个标签可能是正确的,也可能是错误的。在RCN的情况下,标签错误地翻转的概率是固定的,与特定的样本或样本的特征无关。
当我们训练机器学习模型时,我们使用损失函数来度量模型预测和真实标签之间的差异。在存在RCN的情况下,我们希望我们的损失函数能够抵抗这种噪声的影响,即它是鲁棒的。
对称损失函数是对RCN具有鲁棒性的一种损失函数。这意味着,对于给定的输入值x,损失函数在正类和负类上的损失之和是一个常数。
L ( f ( X ) , + 1 ) + L ( f ( X ) , − 1 ) = C L(f (X), +1) + L (f (X), -1) = C L(f(X),+1)+L(f(X),−1)=C
其中 C C C是一个常数, f ( X ) f(X) f(X)是我们的模型预测,而 + 1 +1 +1和 − 1 -1 −1代表类标签。
这种对称性确保了即使在标签翻转的情况下,损失函数的期望值仍然保持不变。也就是说,损失的期望值与是否存在RCN无关。
所以,我们有:
arg min f R D , L ( f ) = arg min f R D ρ , L ( f ) \arg\min_f R_{D,L}(f) = \arg\min_f R_{D_\rho,L}(f) argfminRD,L(f)=argfminRDρ,L(f)
这意味着,对于一个具有对称损失的模型,最小化噪声数据的期望风险与最小化干净数据的期望风险是等价的。
首先,让我们回顾一下风险函数的定义。对于任何函数 f f f,其与损失函数 L L L关联的期望风险可以表示为:
R D , L ( f ) = E ( X , Y ) ∼ D [ L ( f ( X ) , Y ) ] R_{D,L}(f) = \mathbb{E}_{(X,Y) \sim D}[L(f(X),Y)] RD,L(f)=E(X,Y)∼D[L(f(X),Y)]
对于噪声数据,期望风险是:
R D ρ , L ( f ) = E ( X , Y ~ ) ∼ D ρ [ L ( f ( X ) , Y ~ ) ] R_{D_\rho,L}(f) = \mathbb{E}_{(X,\tilde Y) \sim D_\rho}[L(f(X),\tilde Y)] RDρ,L(f)=E(X,Y~)∼Dρ[L(f(X),Y~)]
根据我们之前关于对称损失函数的定义,我们知道:
L ( f ( X ) , + 1 ) + L ( f ( X ) , − 1 ) = C L(f (X), +1) + L (f (X), -1) = C L(f(X),+1)+L(f(X),−1)=C
为了得到我们的关键等式,我们需要将损失函数与噪声模型结合起来。假设标签被随机翻转的概率是 ρ ρ ρ,那么标签保持不变的概率是 1 − ρ 1−ρ 1−ρ。
考虑两种情况:
- 当真实标签 Y = + 1 Y=+1 Y=+1,观测到的标签 Y ~ \tilde Y Y~可以是 + 1 +1 +1或 − 1 -1 −1。
- 当真实标签 Y = − 1 Y=-1 Y=−1,观测到的标签 Y ~ \tilde Y Y~可以是 − 1 -1 −1或 + 1 +1 +1。
将这些考虑到期望风险中,我们可以重写噪声风险为:
R D ρ , L ( f ) = ( 1 − ρ ) E ( X , Y ) ∼ D [ L ( f ( X ) , Y ) ] + ρ E ( X , Y ) ∼ D [ L ( f ( X ) , − Y ) ] R_{D_\rho,L}(f) = (1-\rho) \mathbb{E}_{(X,Y) \sim D}[L(f(X),Y)] + \rho \mathbb{E}_{(X,Y) \sim D}[L(f(X),-Y)] RDρ,L(f)=(1−ρ)E(X,Y)∼D[L(f(X),Y)]+ρE(X,Y)∼D[L(f(X),−Y)]
根据对称损失的定义:
E ( X , Y ) ∼ D [ L ( f ( X ) , − Y ) ] = C − E ( X , Y ) ∼ D [ L ( f ( X ) , Y ) ] = C − R D , L ( f ) \mathbb{E}_{(X,Y) \sim D}[L(f(X),-Y)] = C - \mathbb{E}_{(X,Y) \sim D}[L(f(X),Y)] = C - R_{D,L}(f) E(X,Y)∼D[L(f(X),−Y)]=C−E(X,Y)∼D[L(f(X),Y)]=C−RD,L(f)
根据对称损失的定义,最后一项可以进一步化简为:
R D ρ , L ( f ) = ( 1 − ρ ) R D , L ( f ) + ρ C − ρ R D , L ( f ) R_{D_\rho,L}(f) = (1-\rho) R_{D,L}(f) + \rho C - \rho R_{D,L}(f) RDρ,L(f)=(1−ρ)RD,L(f)+ρC−ρRD,L(f)
整理得:
R D ρ , L ( f ) = ( 1 − 2 ρ ) R D , L ( f ) + ρ C = E ( X , Y ~ ) ∼ D ρ [ L ( f ( X ) , Y ~ ) ] R_{D_\rho,L}(f) = (1-2\rho) R_{D,L}(f) + \rho C = \mathbb{E}_{(X,\tilde Y) \sim D_\rho}[L(f(X),\tilde Y)] RDρ,L(f)=(1−2ρ)RD,L(f)+ρC=E(X,Y~)∼Dρ[L(f(X),Y~)]
它表示了在RCN下,我们可以通过调整无噪声风险来预测噪声风险。这意味着如果我们选择了正确的损失函数,我们可以对噪声数据进行有效的学习,就好像我们正在使用无噪声数据一样。
现在,如果我们的目标是最小化风险,那么这两种情况下的最小化者应该是一样的,因为它们之间的关系是线性的,即 arg min f R D , L ( f ) = arg min f R D ρ , L ( f ) \arg\min_f R_{D,L}(f) = \arg\min_f R_{D_\rho,L}(f) argminfRD,L(f)=argminfRDρ,L(f)。
类别依赖的标签噪声 (Class-Dependent Noise, CCN)
在这种情况下,噪声仅与真实标签 Y Y Y有关。
ρ Y ( X ) = P ( Y ~ ∣ Y ) \rho_{Y} (X) = P(\tilde Y|Y) ρY(X)=P(Y~∣Y)
这意味着不同的类可能有不同的翻转概率。
二分类
在类别依赖的标签噪声中,某个类别的标签被错误地标记成另一个类别的概率是固定的,并且这个错误翻转概率可能对不同类别不同,即正类标签变为负类的概率 ρ + 1 \rho_{+1} ρ+1 和负类标签变为正类的概率 ρ − 1 \rho_{-1} ρ−1 是不同的, ρ + 1 ≠ ρ − 1 \rho_{+1} \neq \rho_{-1} ρ+1=ρ−1。
首先,我们定义翻转率:
ρ Y ( X ) = P ( Y ~ ∣ Y , X ) = P ( Y ~ ∣ Y ) ; ρ + 1 ( X ) = ρ + 1 ; ρ − 1 ( X ) = ρ − 1 \rho_{Y} (X) = P(\tilde Y|Y, X) = P(\tilde Y|Y); \quad \rho_{+1} (X) = \rho_{+1}; \quad \rho_{-1} (X) = \rho_{-1} ρY(X)=P(Y~∣Y,X)=P(Y~∣Y);ρ+1(X)=ρ+1;ρ−1(X)=ρ−1
这里的 ρ Y ( X ) ρ_Y (X) ρY(X) 表示在特征 X X X 和真实标签 Y Y Y 的条件下,观测标签 Y ~ \tilde Y Y~ 发生翻转的概率。在我们的假设中, ρ + 1 \rho_{+1} ρ+1 和 ρ − 1 \rho_{-1} ρ−1 是独立于 X X X的常数,代表正标签变成负标签和负标签变成正标签的概率。
为了处理这种噪声,我们需要调整损失函数 L L L为 L ~ \tilde L L~,以确保在干净数据 D D D和噪声数据 D ρ D_\rho Dρ上最小化损失函数的模型 f f f是一致的,即修改损失函数 L L L 为 L ~ \tilde L L~,使得 arg min f ∈ F R D , L ( f ) = arg min f ∈ F R D ρ , L ~ ( f ) \argmin\limits_{f \in \mathcal{F}} R_{D,L} (f) = \argmin\limits_{f \in \mathcal{F}} R_{D_\rho,\tilde L} (f) f∈FargminRD,L(f)=f∈FargminRDρ,L~(f)
处理这种噪声的方法包括:重要性重新加权(Importance reweighting)、无偏估计器(unbiased estimator)、成本敏感损失(cost-sensitive loss)和排名修剪(rank pruning)。
当我们把噪声数据和干净数据视为来自两个不同领域的样本时,可以应用重要性重新加权。这种方法的目的是通过赋予噪声数据中每个样本一个权重来模拟在无噪声数据上的训练效果。重要性权重 β ( X , Y ) \beta(X,Y) β(X,Y)是实现这一点的关键。
R D , L ( f ) = E ( X , Y ) ∼ D [ L ( f ( X ) , Y ) ] = ∫ P D ( X , Y ) L ( f ( X ) , Y ) d X d Y = ∫ P D ρ ( X , Y ) P D ( X , Y ) P D ρ ( X , Y ) L ( f ( X ) , Y ) d X d Y = E ( X , Y ) ∼ D ρ [ P D ( X , Y ) P D ρ ( X , Y ) L ( f ( X ) , Y ) ] = E ( X , Y ) ∼ D ρ [ β ( X , Y ) L ( f ( X ) , Y ) ] \begin{align*} R_{D,L}(f) &= \mathbb{E}_{(X,Y) \sim D}[L(f(X),Y)] \\ &= \int P_D(X,Y)L(f(X),Y)dXdY \\ &= \int P_{D_\rho}(X,Y) \frac{P_D(X,Y)}{P_{D_\rho}(X,Y)} L(f(X),Y)dXdY \\ &= \mathbb{E}_{(X,Y) \sim D_\rho}[\frac{P_D(X,Y)}{P_{D_\rho}(X,Y)} L(f(X),Y)] \\ &= \mathbb{E}_{(X,Y) \sim D_\rho}[\beta (X,Y) L(f(X),Y)] \\ \end{align*} RD,L(f)=E(X,Y)∼D[L(f(X),Y)]=∫PD(X,Y)L(f(X),Y)dXdY=∫PDρ(X,Y)PDρ(X,Y)PD(X,Y)L(f(X),Y)dXdY=E(X,Y)∼Dρ[PDρ(X,Y)PD(X,Y)L(f(X),Y)]=E(X,Y)∼Dρ[β(X,Y)L(f(X),Y)]
这里 β ( X , Y ) \beta(X,Y) β(X,Y)是一个重新加权因子,用于调整噪声数据的损失权重,使其反映在无噪声数据分布下的期望损失。
回想一下,我们有:
P D ρ ( Y ~ = y ∣ X ~ = x ) = ( 1 − ρ + 1 − ρ − 1 ) P D ( Y = y ∣ X = x ) + ρ − y P_{D_\rho}(\tilde Y = y | \tilde X = x) = (1 - \rho_{+1} - \rho_{-1}) P_{D} (Y = y | X = x) + \rho_{-y} PDρ(Y~=y∣X~=x)=(1−ρ+1−ρ−1)PD(Y=y∣X=x)+ρ−y
这个公式是描述在有噪声的数据分布 D ρ D_\rho Dρ中,给定特征 x x x,观察到标签 Y ~ \tilde Y Y~等于某个类别 y y y的条件概率。这里有两个部分组成:
-
( 1 − ρ + 1 − ρ − 1 ) P D ( Y = y ∣ X = x ) (1 - \rho_{+1} - \rho_{-1}) P_{D} (Y = y | X = x) (1−ρ+1−ρ−1)PD(Y=y∣X=x): 这是说,如果我们从干净的数据分布 D D D中取一个样本,它的真实标签是 y y y,并且这个标签没有被噪声影响,那么这个标签就会被正确观察到。这里的 ( 1 − ρ + 1 − ρ − 1 ) (1 - \rho_{+1} - \rho_{-1}) (1−ρ+1−ρ−1)是没有噪声影响的概率。
-
ρ − y \rho_{-y} ρ−y: 这表示当实际标签不是 y y y时,它被错误地翻转为 y y y的概率。对于二元分类来说,如果 y y y是+1,那么 − y -y −y就是-1,这表示 ρ − 1 \rho_{-1} ρ−1就是实际为-1的标签被错误翻转为+1的概率;同理,如果 y y y是-1,则 ρ + 1 \rho_{+1} ρ+1是实际为+1的标签被错误翻转为-1的概率。
然后我们可以得出重要性重新加权因子 β ( x , y ) \beta(x,y) β(x,y):
β ( x , y ) = P D ( X = x , Y = y ) P D ρ ( X = x , Y ~ = y ) = P D ( Y = y ∣ X = x ) P D ρ ( Y ~ = y ∣ X = x ) = P D ρ ( Y ~ = y ∣ X = x ) − ρ − y ( 1 − ρ + 1 − ρ − 1 ) P D ρ ( Y ~ = y ∣ X = x ) \beta(x,y) = \frac{P_D(X=x,Y=y)}{P_{D_\rho}(X=x,\tilde Y=y)} = \frac{P_D(Y=y | X=x)}{P_{D_\rho}(\tilde Y=y | X=x)} = \frac{P_{D_\rho}(\tilde Y=y | X=x) - \rho_{-y}}{(1 - \rho_{+1} - \rho_{-1}) P_{D_\rho}(\tilde Y=y | X=x)} β(x,y)=PDρ(X=x,Y~=y)PD(X=x,Y=y)=PDρ(Y~=y∣X=x)PD(Y=y∣X=x)=(1−ρ+1−ρ−1)PDρ(Y~=y∣X=x)PDρ(Y~=y∣X=x)−ρ−y
如果我们知道翻转率,我们就可以计算 β \beta β的值。
估计噪声率,我们有:
P ( Y ~ = − 1 ∣ X ~ = x + 1 ) = ( 1 − ρ + 1 − ρ − 1 ) P ( Y = − 1 ∣ X = x + 1 ) + ρ + 1 P(\tilde Y = -1 | \tilde X = x_{+1}) = (1 - \rho_{+1} - \rho_{-1}) P (Y = -1 | X = x_{+1}) + \rho_{+1} P(Y~=−1∣X~=x+1)=(1−ρ+1−ρ−1)P(Y=−1∣X=x+1)+ρ+1
P ( Y ~ = + 1 ∣ X ~ = x − 1 ) = ( 1 − ρ + 1 − ρ − 1 ) P ( Y = + 1 ∣ X = x − 1 ) + ρ − 1 P(\tilde Y = +1 | \tilde X = x_{-1}) = (1 - \rho_{+1} - \rho_{-1}) P (Y = +1 | X = x_{-1}) + \rho_{-1} P(Y~=+1∣X~=x−1)=(1−ρ+1−ρ−1)P(Y=+1∣X=x−1)+ρ−1
我们还假设翻转率很小,即 ρ + 1 + ρ − 1 ≤ 1 \rho_{+1} + \rho_{-1} \leq 1 ρ+1+ρ−1≤1。
这种情况下,我们可以得到两个不等式:
-
P ( Y ~ = − 1 ∣ X = x ) ≥ ρ + 1 P(\tilde Y = -1 | X = x) \geq \rho_{+1} P(Y~=−1∣X=x)≥ρ+1:在所有标签为-1的噪声数据中,至少有 ρ + 1 \rho_{+1} ρ+1 的比例是由于正类标签被错误地翻转为负类造成的。因此,噪声负类的概率至少包括了所有被错误翻转的正类标签的比例。
-
P ( Y ~ = + 1 ∣ X = x ) ≥ ρ − 1 P(\tilde Y = +1 | X = x) \geq \rho_{-1} P(Y~=+1∣X=x)≥ρ−1:在所有标签为+1的噪声数据中,至少有 ρ − 1 \rho_{-1} ρ−1 的比例是因为负类标签被错误地翻转为正类。
这里, ρ + 1 \rho_{+1} ρ+1 是真实标签为+1(正类)但被观测为-1(负类)的条件概率,而 ρ − 1 \rho_{-1} ρ−1 是真实标签为-1但被观测为+1的条件概率。
至少意味着实际上翻转的概率可能更高,但不会低于我们预设的噪声率( ρ + 1 \rho_{+1} ρ+1和 ρ − 1 \rho_{-1} ρ−1)。所以当我们观测到一个翻转的标签时,我们可以确定,这个翻转的事件发生的概率不会低于预先设定的噪声率阈值。
举一个具体的例子来说明这一点:
假设我们观察一个正类的样本( Y = + 1 Y=+1 Y=+1),它有 ρ + 1 \rho_{+1} ρ+1 的概率被错误地标记为负类( Y ~ = − 1 \tilde Y=-1 Y~=−1)。因此,在所有观察到的负类标签中( Y ~ = − 1 \tilde Y=-1 Y~=−1),至少有 ρ + 1 \rho_{+1} ρ+1 的比例原本应该是正类。所以,这就解释了为什么 P ( Y ~ = − 1 ∣ X = x ) ≥ ρ + 1 P(\tilde Y = -1 | X = x) \geq \rho_{+1} P(Y~=−1∣X=x)≥ρ+1。
而 ρ + 1 + ρ − 1 ≤ 1 \rho_{+1} + \rho_{-1} \leq 1 ρ+1+ρ−1≤1 这个条件则是确保翻转率的合理性,即错误翻转的概率之和不能超过1,这是因为一个标签要么保持不变,要么翻转一次,不可能出现两次翻转(这在二元分类中意味着标签回到了原来的类别)。这个条件帮助保证了噪声模型的一致性和逻辑上的合理性。
这样的假设允许我们为最小化学习算法的损失函数时设置一个下限,确保模型在面对标签噪声时的鲁棒性。
为了估计翻转率,我们设计如下估计器:
ρ − y = min X ∈ X P ( Y ~ = y ∣ X ) \rho_{-y} = \min\limits_{X \in \mathcal{X}} P(\tilde Y = y | X) ρ−y=X∈XminP(Y~=y∣X)
在这个估计器中,我们对于所有的特征空间 X \mathcal{X} X,找到在 X X X下观测到标签 y y y的最小概率,作为翻转率 ρ − y \rho_{-y} ρ−y的估计。
有了噪声数据,我们可以学习翻转率和噪声类后验概率。其中 β ( x , y ) \beta(x,y) β(x,y)定义为:
β ( x , y ) = P D ( X = x , Y = y ) P D ρ ( X = x , Y ~ = y ) = P D ρ ( Y ~ = y ∣ X = x ) − ρ − y ( 1 − ρ + 1 − ρ − 1 ) P D ρ ( Y ~ = y ∣ X = x ) \beta(x,y) = \frac{P_D(X=x,Y=y)}{P_{D_\rho}(X=x,\tilde Y=y)} = \frac{P_{D_\rho}(\tilde Y=y | X=x) - \rho_{-y}} {(1 - \rho_{+1} - \rho_{-1}) P_{D_\rho}(\tilde Y=y | X=x)} β(x,y)=PDρ(X=x,Y~=y)PD(X=x,Y=y)=(1−ρ+1−ρ−1)PDρ(Y~=y∣X=x)PDρ(Y~=y∣X=x)−ρ−y
β ( x , y ) \beta(x,y) β(x,y)是一个调整因子,用于从噪声数据分布调整回干净数据分布。
最后,我们结合原始损失函数,利用大数定律(LLN)来估计噪声数据的期望,从而学习关于干净数据的期望风险:
R D , L ( f ) = E ( X , Y ) ∼ D ρ [ β ( X , Y ) L ( f ( X ) , Y ) ] R_{D,L}(f) = \mathbb{E}_{(X,Y) \sim D_\rho}[\beta (X,Y) L(f(X),Y)] RD,L(f)=E(X,Y)∼Dρ[β(X,Y)L(f(X),Y)]
这里,我们通过期望风险表达式,将噪声数据下的学习问题转换为在干净数据下的风险最小化问题。因此,尽管我们只能观察到噪声数据,但通过合理估计和调整,我们可以构建一个在干净数据上表现良好的模型。
多分类
在多类分类问题中,每个类别的标签可能以不同的概率被错误地标注为其他类别。这种现象可以通过一个称为转移矩阵(Transition Matrix)的概念来建模,记作 T T T。例如,假设我们有 C C C个类别,转移矩阵 T T T如下所示:
T = [ P ( Y ~ = 1 ∣ Y = 1 ) P ( Y ~ = 1 ∣ Y = 2 ) ⋯ P ( Y ~ = 1 ∣ Y = C ) P ( Y ~ = 2 ∣ Y = 1 ) P ( Y ~ = 2 ∣ Y = 2 ) ⋯ P ( Y ~ = 2 ∣ Y = C ) ⋮ ⋮ ⋱ ⋮ P ( Y ~ = C ∣ Y = 1 ) P ( Y ~ = C ∣ Y = 2 ) ⋯ P ( Y ~ = C ∣ Y = C ) ] T = \begin{bmatrix} P(\tilde Y = 1|Y = 1) & P(\tilde Y = 1|Y = 2) & \cdots & P(\tilde Y = 1|Y = C) \\ P(\tilde Y = 2|Y = 1) & P(\tilde Y = 2|Y = 2) & \cdots & P(\tilde Y = 2|Y = C) \\ \vdots & \vdots & \ddots & \vdots \\ P(\tilde Y = C|Y = 1) & P(\tilde Y = C|Y = 2) & \cdots & P(\tilde Y = C|Y = C) \end{bmatrix} T= P(Y~=1∣Y=1)P(Y~=2∣Y=1)⋮P(Y~=C∣Y=1)P(Y~=1∣Y=2)P(Y~=2∣Y=2)⋮P(Y~=C∣Y=2)⋯⋯⋱⋯P(Y~=1∣Y=C)P(Y~=2∣Y=C)⋮P(Y~=C∣Y=C)
在这个矩阵中,每个元素 P ( Y ~ = j ∣ Y = i ) P(\tilde Y = j|Y = i) P(Y~=j∣Y=i)代表真实类别为 i i i时,被误标为类别 j j j的概率。如果假设矩阵 T T T是已知的,那么可以利用它来从噪声标签中恢复出真实的类别概率。
如果我们假定给定真实标签后,噪声标签独立于实例,即 P ( Y ~ ∣ Y ) = P ( Y ~ ∣ Y , X ) P(\tilde Y|Y) = P(\tilde Y|Y,X) P(Y~∣Y)=P(Y~∣Y,X),那么可以通过以下前向变换得到噪声标签的概率分布:
[ P ( Y ~ = 1 ∣ X ) , . . . , P ( Y ~ = C ∣ X ) ] T = T [ P ( Y = 1 ∣ X ) , . . . , P ( Y = C ∣ X ) ] T [P(\tilde Y = 1|X),... , P(\tilde Y = C|X)]^T = T[P(Y = 1|X),... , P(Y = C|X)]^T [P(Y~=1∣X),...,P(Y~=C∣X)]T=T[P(Y=1∣X),...,P(Y=C∣X)]T
或者,可以通过以下后向变换从噪声标签的概率分布恢复出真实标签的概率分布:
[ P ( Y = 1 ∣ X ) , . . . , P ( Y = C ∣ X ) ] T = T − 1 [ P ( Y ~ = 1 ∣ X ) , . . . , P ( Y ~ = C ∣ X ) ] T [P(Y = 1|X),... , P(Y = C|X)]^T = T^{-1}[P(\tilde Y = 1|X),... , P(\tilde Y = C|X)]^T [P(Y=1∣X),...,P(Y=C∣X)]T=T−1[P(Y~=1∣X),...,P(Y~=C∣X)]T
上述等式意味着,我们可以通过使用噪声类后验概率和逆转移矩阵来推断干净的类后验概率。
假设我们使用深度学习来处理分类任务:
在这个情境下,我们通常会有一个深度神经网络来估计 [ P ( Y ~ = 1 ∣ X ) , . . . , P ( Y ~ = C ∣ X ) ] T [P(\tilde Y = 1|X),... , P(\tilde Y = C|X)]^T [P(Y~=1∣X),...,P(Y~=C∣X)]T,即给定输入 X X X时,每个类别的噪声标签的概率。然后,我们可以应用转移矩阵的逆矩阵 T − 1 来估计 [ P ( Y = 1 ∣ X ) , . . . , P ( Y = C ∣ X ) ] T T^{-1}来估计[P(Y = 1|X),... , P(Y = C|X)]^T T−1来估计[P(Y=1∣X),...,P(Y=C∣X)]T,即真实的类后验概率。
这种方法使得我们可以在噪声标签的存在下,仍然有效地训练深度学习模型,并且能够在推理时更准确地预测真实的类别。这是通过校正模型输出,以反映从噪声数据中学习到的真实类别概率分布,而非直接观察到的噪声分布。
实例和类别依赖的标签噪声 (Instance and Label-Dependent Noise, ILN)
这是最复杂的模型,噪声取决于观测值 X X X和真实标签 Y Y Y。
ρ Y ( X ) = P ( Y ~ ∣ Y , X ) \rho_{Y} (X) = P(\tilde Y|Y, X) ρY(X)=P(Y~∣Y,X)
这意味着噪声可能随观测值的变化而变化。
对于实例和类别依赖的标签噪声,估计每个实例的标签翻转率(即标签从正确变为错误的概率)是一个非常困难的问题:
-
数据的复杂性:当噪声不仅仅依赖于类别,而且依赖于实例的特定特征时,需要对每个实例的噪声水平进行建模。这意味着需要估计一个可能与实例的所有特征相关的复杂函数。
-
标识问题(Identifiability problem):如果不对噪声过程有一定的先验知识,那么从有噪声的数据中区分出实例的影响和随机噪声的影响是不可能的。换句话说,很难确定是实例的哪些特征导致了标签错误。
-
缺乏足够信息:在没有关于噪声过程的额外信息(例如噪声率的上下界或噪声的特定模式)的情况下,仅仅从有噪声的数据中估计每个实例的噪声是不可行的。
因此,对于实例和类别依赖的标签噪声,直接估计翻转率通常是不适定的(ill-posed),因为问题的解可能不存在,可能不唯一,或者解对于数据的微小变化可能极其敏感。为了解决这个问题,研究者们通常会:
-
采用强假设:比如假设实例依赖的噪声可以通过观察到的数据的一些简单函数来建模。
-
使用半监督学习或无监督学习的方法:这些方法不完全依赖于标签信息,从而在一定程度上能够抵抗标签噪声的影响。
-
利用小部分清洗数据:如果有一小部分标签是准确的,那么可以利用这部分数据来校准或估计噪声水平。
-
设计鲁棒的模型和学习算法:例如,通过修改损失函数或正则化策略来减轻噪声标签的不良影响。
相关文章:

[Machine Learning] Learning with Noisy Labels
文章目录 随机分类噪声 (Random Classification Noise, RCN)类别依赖的标签噪声 (Class-Dependent Noise, CCN)二分类多分类 实例和类别依赖的标签噪声 (Instance and Label-Dependent Noise, ILN) 标签噪声是指分类任务中的标签被错误地标记。这可能是由于各种原因,…...
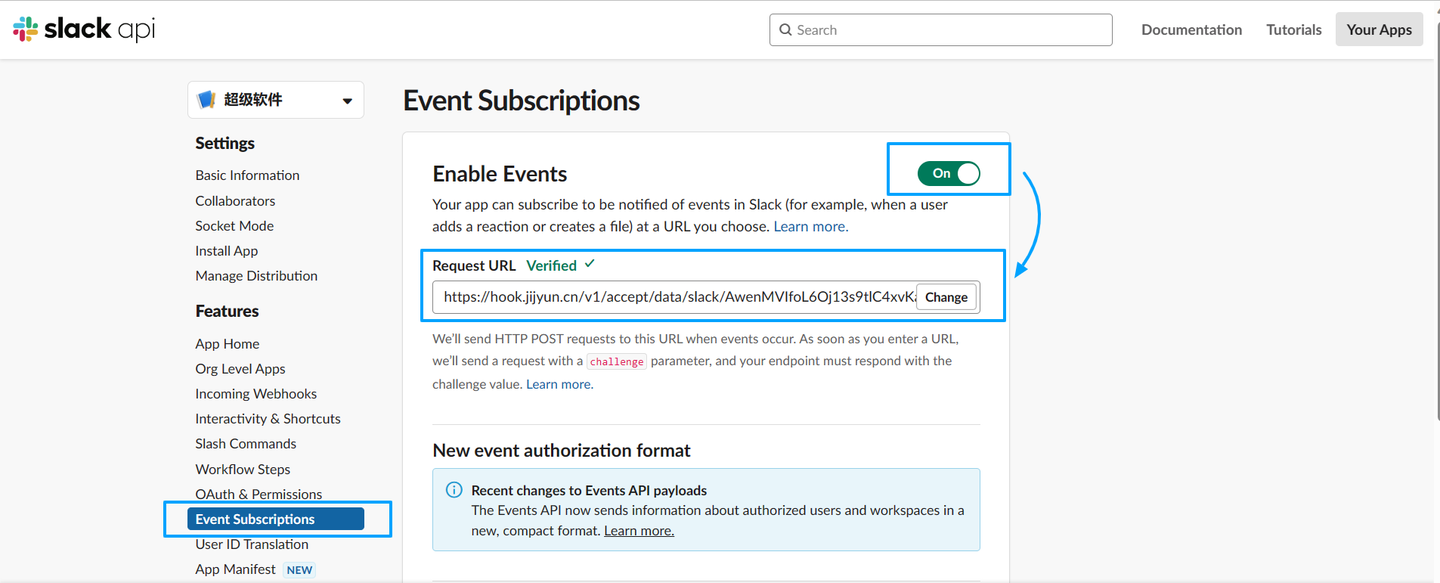
集简云slack(自建)无需API开发轻松连接OA、电商、营销、CRM、用户运营、推广、客服等近千款系统
slack是一个工作效率管理平台,让每个人都能够使用无代码自动化和 AI 功能,还可以无缝连接搜索和知识共享,并确保团队保持联系和参与。在世界各地,Slack 不仅受到公司的信任,同时也是人们偏好使用的平台。 官网&#x…...

Idea 对容器中的 Java 程序断点远程调试
第一种:简单粗暴型 直接在java程序中添加log.info(),根据需要打印信息然后打包覆盖,根据日志查看相关信息 第二种:远程调试 在IDEA右上角点击编辑配置设置相关参数在Dockerfile中加入 "-jar", "-agentlib:jdwp…...

vscode设置保存后,自动格式化代码
第一步:打开setting.json文件 第二步:在setting.json中加入以下代码 "editor.formatOnType": true, "editor.formatOnSave": true, "editor.formatOnPaste": true...

datagrip出现 java.net.ConnectException: Connection refused: connect.
出现这样的情况要看一下hadoop有没有启动 start-all.sh nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 & scp -r /export/server/apache-hive-3.1.2-bin/ node3:/export/server/ /export/server/apache-hive-3.1.2-bin/bin/hive show databa…...
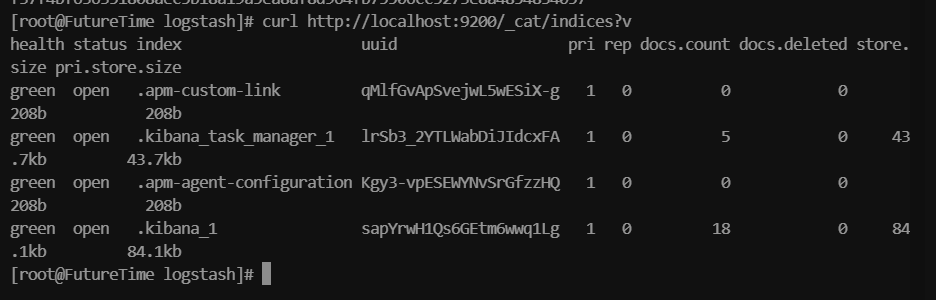
Docker 安装ELK7.7.1
(在安装之前,本方法必须安装jdk1.8以上版本) 一、安装elasticsearch 1、下载elasticsearch7镜像:docker pull elasticsearch:7.7.1 2、创建挂载目录:mkdir -p /data/elk/es/{config,data,logs} 3、赋予权限:chown -R 1000:100…...

决策树算法
决策树算法是一种用于分类和回归问题的机器学习算法。它通过构建树形结构来进行决策,每个内部节点代表一个特征或属性,每个叶子节点代表一个类别或值。 下面是决策树算法的一般步骤: 数据准备:收集相关的训练数据,并对…...

maven之pom文件详解
一、maven官网 maven官网 maven官网pom文件详解链接 二、maven之pom 1、maven项目的目录结构 pom文件定于了一个maven项目的maven配置,一般pom文件的放在项目或者模块的根目录下。 maven的遵循约定大于配置,约定了如下的目录结构: 目录目…...

深度学习之基于Python+OpenCV+dlib的考生信息人脸识别系统(GUI界面)
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 深度学习在人脸识别领域的应用已经取得了显著的进展。Python是一种常用的编程语言,它提供了许多强大的库…...
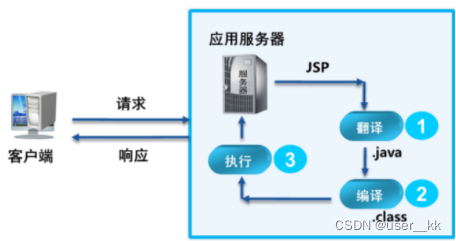
创建javaEE项目(无maven),JSP(九大内置对象)、Servlet(生命周期)了解
一、Servlet和jsp 0.创建web项目(无maven): 1.创建一个普通的java项目 2.项目根目录右键,添加模板 3.配置tomcat服务器 4.配置项目tomcat依赖 1.Servlet(Server Applet)服务端小程序 用户通过浏览器发送一个请求,服务器tomcat接收到后&…...
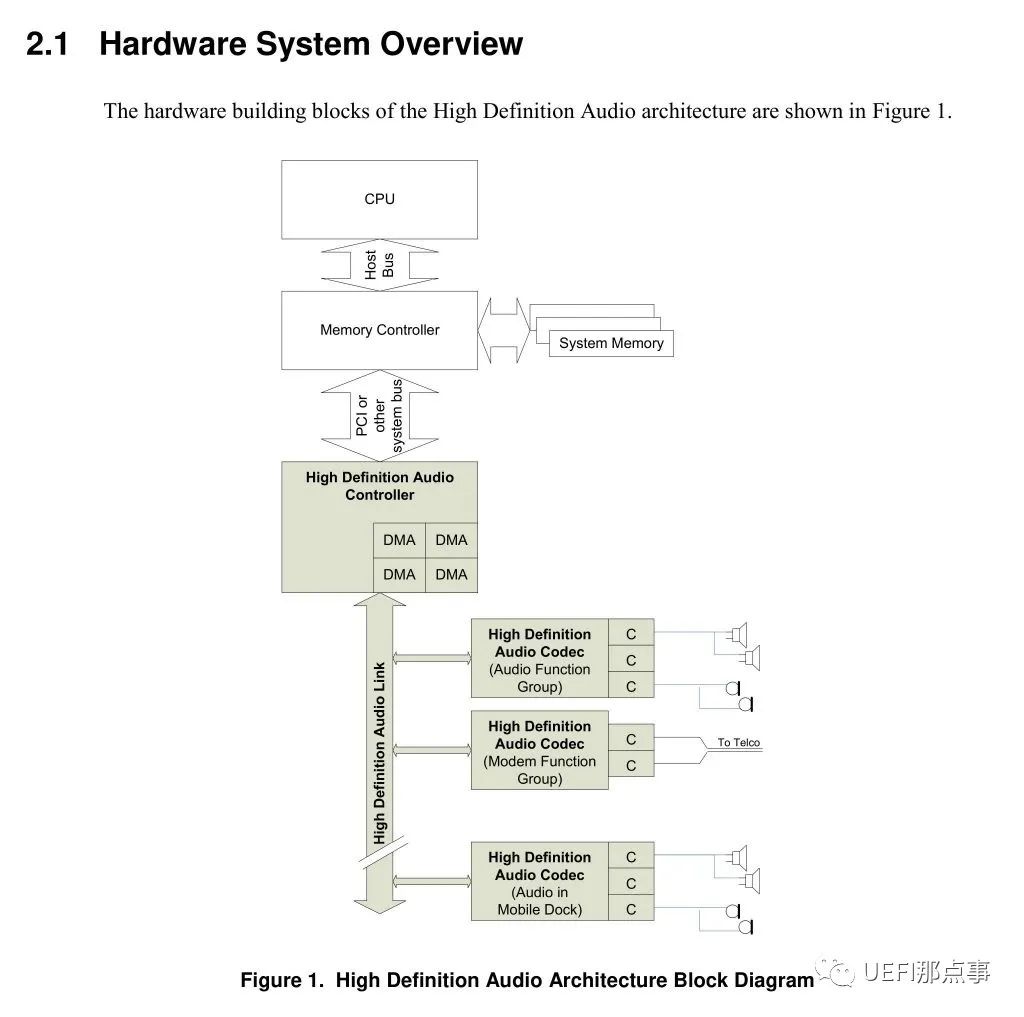
BIOS开发笔记 - HDA Audio
在PC中,音频输出是一个重要的功能之一,目前大多数采用的是英特尔高清晰音效(英语:Intel High Definition Audio,简称为HD Audio或IHD)方案,它是由Intel于2004年所提出的音效技术,能够展现高清晰度的音质效果,且能进行多声道的播放,在音质(音效质量)上超越过去的其他…...
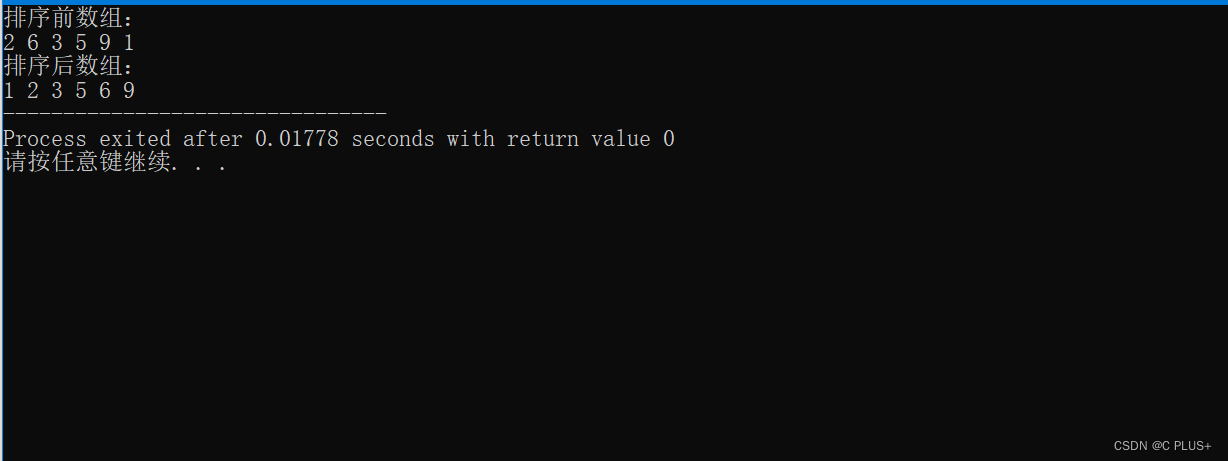
C语言——选择排序
完整代码: //选择排序 // 选择排序是一种简单直观的排序算法。它的工作原理如下:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大&am…...
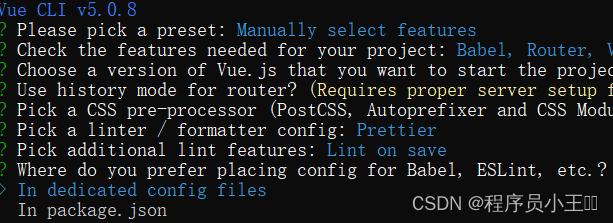
vue详细安装教程
这里写目录标题 一、下载和安装node二、创建全局安装目录和缓存日志目录三、安装vue四、创建一个应用程序五、3x版本创建六、创建一个案例 一、下载和安装node 官网下载地址:https://nodejs.org/en/download 选择适合自己的版本,推荐LTS,长久…...

Java 正则表达式字符篇
精确匹配一个字符 精确匹配字符串 abc , //精确匹配字符串 "abc"String regexabc "abc";System.out.println("abc".matches(regexabc));// trueSystem.out.println("ABC".matches(regexabc));// falseSystem.out.println…...
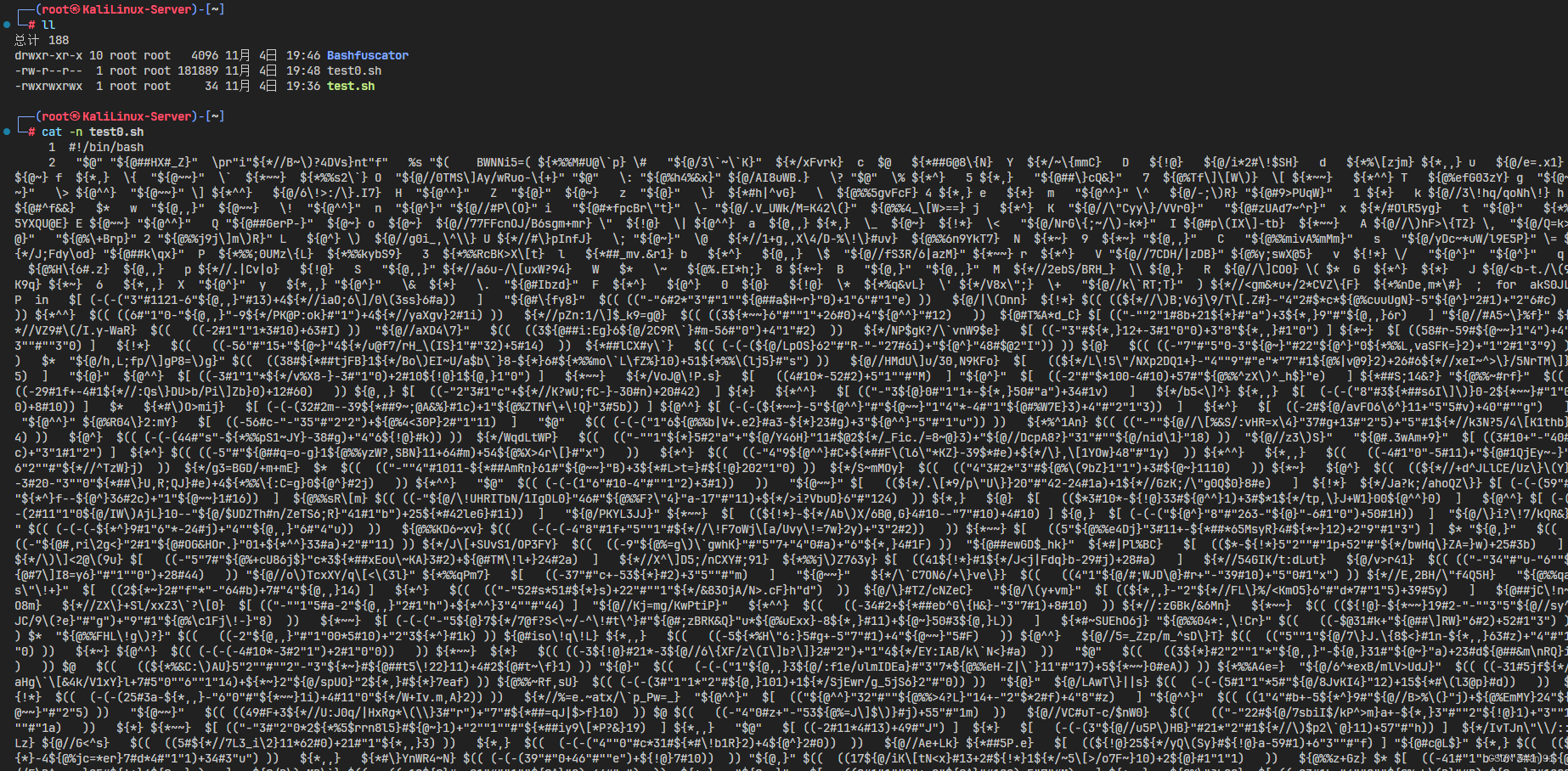
shell脚本代码混淆
文章目录 起因安装 Bashfuscator安装BashfuscatorBashfuscator的使用 起因 很多时候我并不希望自己的shell脚本被别人看到,于是我在想有没有什么玩意可以把代码加密而又正常执行,于是我想到了代码混淆,简单来看一下: 现在我的目…...

【MATLAB第81期】基于MATLAB的LSTM长短期记忆网络预测模型时间滞后解决思路(更新中)
【MATLAB第81期】基于MATLAB的LSTM长短期记忆网络预测模型时间滞后解决思路(更新中) 在LSTM预测过程中,极易出现时间滞后,类似于下图,与一个以上的样本点结果错位,产生滞后的效果。 在建模过程中…...
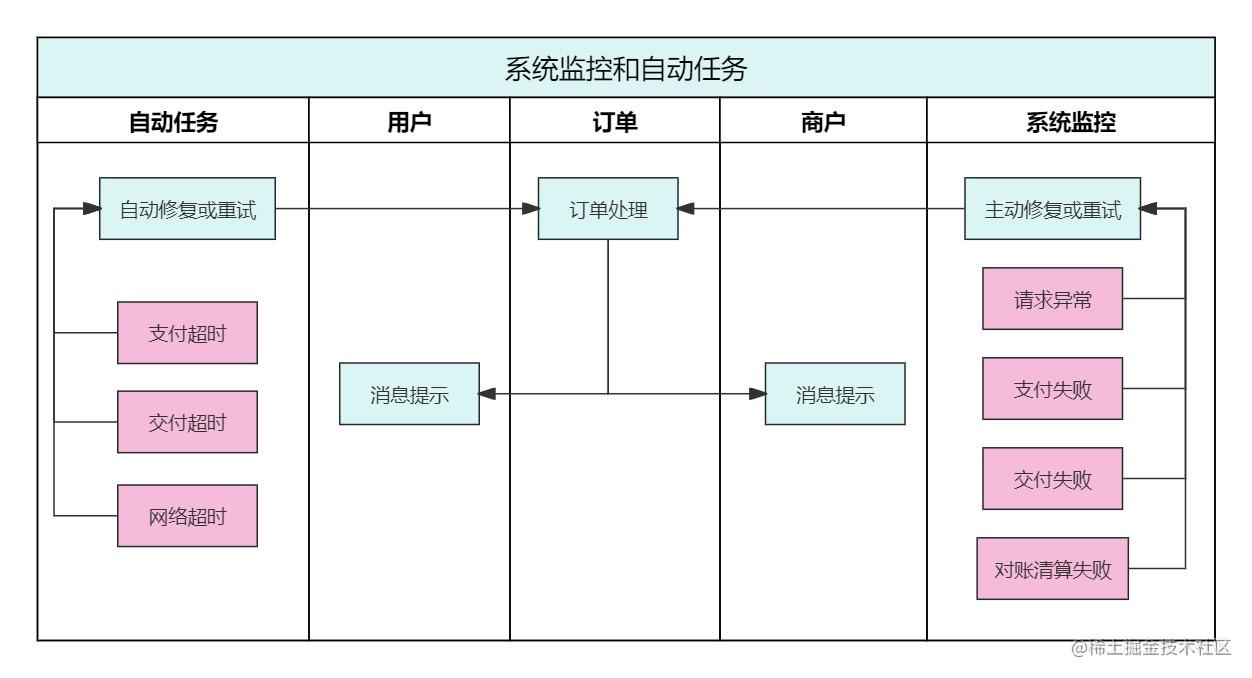
订单业务和系统设计(一)
一、背景简介 订单其实很常见,在电商购物、外卖点餐、手机话费充值等生活场景中,都能见到它的影子。那么,一笔订单的交易过程是什么样子的呢?文章尝试从订单业务架构和产品功能流程,描述对订单的理解。 二、订单业务…...

安全模型的分类与模型介绍
安全模型的分类 基本模型:HRU机密性模型:BLP、Chinese Wall完整性模型:Biba、Clark-Wilson BLP模型 全称(Bell-LaPadula)模型,是符合军事安全策略的计算机安全模型。 BLP模型的安全规则: 简…...

I/O多路转接之select
承接上文:I/O模型之非阻塞IO-CSDN博客 简介 select函数原型介绍使用 一个select简单的服务器的代码书写 select的缺点 初识select 系统提供select函数来实现多路复用输入/输出模型 select系统调用是用来让我们的程序监视多个文件描述符的状态变化的; 程序会停在s…...
“如何对TXT文件的内容进行连续行删除?实现一键文件整理!
如果你有一个TXT文件,需要删除其中的连续行,这可能是为了整理文件、去除重复信息或清除不需要的文本。尽管手动删除每一行可能很耗时,但幸运的是,有一个简单而高效的方法可以帮助你实现这个目标。 首先,在首助编辑高手…...

数字孪生+高斯泼溅+CIMPro孪大师,打造申报“硬通货”
当前,2026年全国智能工厂梯度培育申报窗口期正在密集推进中。从四川、江苏到福建、安徽,各地工信部门纷纷下发《关于做好2026年度智能工厂梯度培育有关工作的通知》,2025年至2027年是基础级、卓越级、领航级智能工厂建设的三年关键窗口期。你…...

Unity VR开发选无线还是有线?Oculus Quest 2串流实战对比与效率工具推荐
Unity VR开发无线与有线串流深度对比:Oculus Quest 2高效开发全指南 当你沉浸在Unity VR开发的世界中,Oculus Quest 2无疑是目前最受欢迎的测试平台之一。但每次修改代码后漫长的打包安装过程,是否让你在无线自由与有线稳定之间反复纠结&…...

抖音视频收藏革命:从水印困扰到纯净收藏的完美蜕变
抖音视频收藏革命:从水印困扰到纯净收藏的完美蜕变 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader 你是否曾经在抖…...

G-Helper深度解析:华硕笔记本的终极轻量级控制方案
G-Helper深度解析:华硕笔记本的终极轻量级控制方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exper…...

3DMAX建模救星实测:SmoothBoolean插件处理复杂布尔运算,到底有多稳多快?
3DMAX建模革命:SmoothBoolean插件深度测评与实战指南 在数字建模的世界里,布尔运算一直是把双刃剑——它既能快速实现复杂形状的切割与组合,又常常成为模型崩溃的导火索。对于专业建模师而言,面对机械零件、建筑构件或影视道具中那…...

NotebookLM共享协作安全红线:GDPR/等保2.0合规下的4类高危操作与自动审计方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM共享协作安全红线:GDPR/等保2.0合规下的4类高危操作与自动审计方案 NotebookLM 作为 Google 推出的 AI 增强型笔记工具,其“共享链接即协作”的默认机制在提升效率的同…...

BG3 Mod Manager终极指南:如何轻松管理《博德之门3》模组
BG3 Mod Manager终极指南:如何轻松管理《博德之门3》模组 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 你是否曾经因为《博德之门3》模…...

数据分析师简历封神指南:数据可视化 + 业务洞察双重点
引言:别让你的简历,死在6秒筛选期 “熟练使用Python、SQL、Tableau,擅长数据分析与可视化”——当HR第101次看到这句千篇一律的技能描述时,手指已经悬在“删除”键上。2026年数据分析师岗位竞争有多卷?某招聘平台数据显示,平均每个岗位收到250份简历,HR平均花6秒扫描一…...

【NotebookLM评论反馈功能深度解析】:20年AI产品专家揭秘谷歌最新协作黑科技如何重塑知识管理流程?
更多请点击: https://intelliparadigm.com 第一章:NotebookLM评论反馈功能的诞生背景与战略定位 NotebookLM 作为 Google 推出的面向研究者与知识工作者的 AI 笔记工具,其核心价值在于“基于可信来源的深度理解”——而非泛化生成。在早期用…...

从官方例程到实战:剖析lwip+FreeRTOS在Zynq7020上的TCP热拔插实现与任务调度优化
1. 官方例程热拔插实现机制拆解 第一次在Zynq7020上看到TCP热拔插功能时,确实让我这个老嵌入式工程师也眼前一亮。官方例程里那个看似简单的link_detect_thread任务,实际上藏着不少精妙设计。我们先从PHY芯片的状态检测说起——这个看似基础的操作&#…...