论文浅尝 | ChatKBQA:基于微调大语言模型的知识图谱问答框架

第一作者:罗浩然,北京邮电大学博士研究生,研究方向为知识图谱与大语言模型协同推理
OpenKG地址:http://openkg.cn/tool/bupt-chatkbqa
GitHub地址:https://github.com/LHRLAB/ChatKBQA
论文链接:https://arxiv.org/abs/2310.08975
动机
随着ChatGPT 的问世,属于大模型的时代就此开始。无可否认,大型语言模型(LLMs)如ChatGPT和GPT4在自然语言处理和人工智能领域中展现出了无与伦比的优势,它们凭借“大数据、大算力、强算法”的支持,不仅具有优越的文本生成能力,还拥有深度的语义理解能力。但是,尽管LLMs在这些领域中显示出强大的实力,其操作过程却如同一个不透明的黑箱,具体的决策逻辑难以被跟踪和解释。这就意味着在实际应用中,它可能无法完整、准确地呈现背后的知识体系,同时也有可能产生错误的答案。
另一方面,知识图谱(KGs),例如Wikidata、Freebase和DBpedia,通过图谱结构,显式地呈现了大量事实性知识及其间的关联。这种结构化的方式让人们能够更直观地看到知识的连贯性和丰富性,从而在推理和问答等任务中获得更高的可解释性。但知识图谱规模庞大,创建和维护需要付出巨大努力,并且天然无法使用自然语言进行问答和查询,这无疑增加了其在实际应用中的困难度。
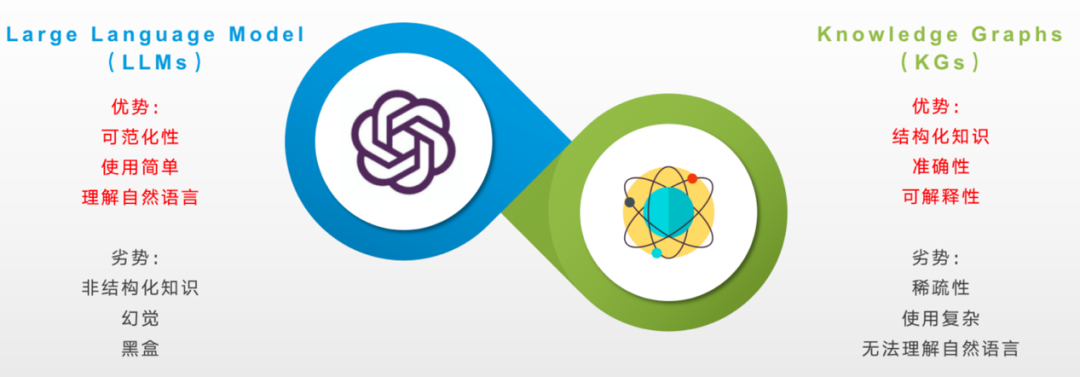
图1.大模型(LLMs)与知识图谱(KGs)优劣势对比
不难发现,大模型所缺少的可解释性以及推理过程和依据正是知识图谱的优势所在,而知识图谱的复杂性和对自然语言的陌生又是大模型旨在解决的问题,那么二者能否相结合从而达到完美互补的效果呢?在这种背景下,ChatKBQA应运而生。
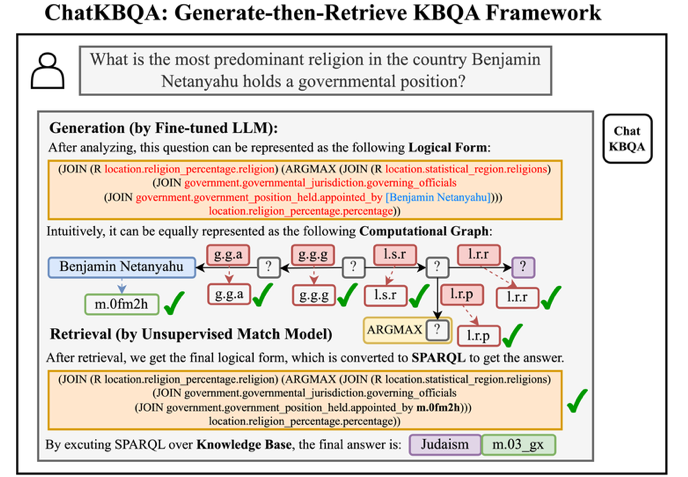
图2.ChatKBQA在给出最终答案以外还给出可解释KG推理路径
ChatKBQA在利用大模型强大的学习能力以及自然语言理解能力的同时,利用知识图谱的准确性和可解释性来弥补了大模型可能的幻觉现象以及本身的黑盒短板,将知识从大模型中解耦出来,实现可解释推理问答的LLM+KG新范式,对医疗、法律等专精垂域知识库上的可解释推理问答提供了新思路。
亮点
(1)通过提出基于大模型的生成-检索知识图谱问答框架ChatKBQA。利用生成再检索代替检索再生成的方式,解决了检索效率低、检索误导生成、KBQA任务解决方案复杂等痛点。
(2)在WebQSP和CWQ两个知识图谱问答基准benchmark上均达到目前的SOTA水平。
(3)首次利用微调大模型生成图数据库查询语言的方式,即GQoT(Graph Query of Thoughts),将图查询作为大模型思考的过程,实现LLM+KG协同驱动的可解释推理问答的新范式。
方法
ChatKBQA是一个使用经过微调的开源大模型的生成-然后检索的知识库问答(KBQA)框架。首先,ChatKBQA框架需要通过指令调整在KBQA数据集中的(自然语言问题,逻辑形式)对来高效微调开源大模型。微调后的大模型用于通过语义解析将新的自然语言问题转化为相应的候选逻辑形式。然后,ChatKBQA在短语级别检索这些逻辑形式中的实体和关系,并在将其转化为SPARQL后搜索可以针对知识库执行的逻辑形式。最后,通过转化获得的SPARQL用于获取最终的答案集,并实现对自然语言问题的可解释和需要知识的回答。下图给出了ChatKBQA 的整体框架描述。
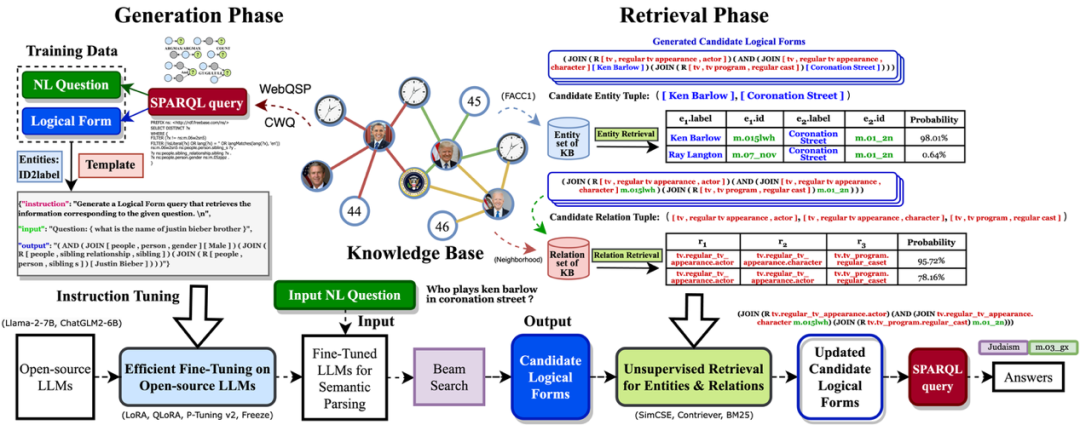
图3.ChatKBQA框架总览
(1)对大模型进行高效微调
为了构建指令微调的训练数据,ChatKBQA首先将KBQA数据集中测试集的自然语言问题对应的SPARQL查询转化为相应的逻辑形式,然后将这些逻辑形式中的实体ID(例如“m.06w2sn5”)替换为相应的实体标签(例如“[Justin Bieber]”),从而使大模型能够更好地理解实体标签,而不是无意义的实体ID。然后,我们将自然语言问题(例如“What is the name of justin bieber brother?”)和处理后的对应逻辑形式(例如“(AND (JOIN [people, person, gender] [Male]) (JOIN (R [people, sibling relationship, sibling]) (JOIN (R [people, person, siblings]) [Justin Bieber])))”)组合成“输入”和“输出”,并添加“指令”为“生成一个逻辑形式查询,检索与给定问题相对应的信息”,构成了针对开源大模型的指令微调训练数据。为了减小对具有大量参数的大模型进行微调的成本,ChatKBQA使用参数高效微调(PEFT)方法(如LoRA、QLoRA、P-tuning v2、Freeze等),仅微调少量模型参数,以实现与完全微调相当的性能。同时,ChatKBQA可以在所有上述高效微调方法以及大模型之间切换,如Llama-2-7B和ChatGLM2-6B。
(2)微调后的大模型进行逻辑形式的生成
经过微调,大模型已经拥有了一定的自然语言问题转化为逻辑形式的语义解析能力。因此,我们使用经过微调的大模型对测试集中的新问题进行语义解析,发现大约63%的样本已经与基准逻辑形式完全相同。当我们使用beam search时,大模型输出的候选逻辑形式列表C中,包含了约74%的样本与基准逻辑形式一致,这表明经过微调的大模型在语义解析任务的学习和解析能力方面表现出色。此外,如果我们将生成的候选逻辑形式中的实体和关系替换为“[]”(例如,“(AND (JOIN [] []) (JOIN (R []) (JOIN (R []) []))”),形成逻辑形式的骨架,那么基准逻辑形式的骨架中出现在候选骨架中的样本比例超过91%。这表明我们只需将逻辑形式中相应位置的实体和关系替换为KB中存在的实体和关系,就可以进一步提高性能。
(3)无监督的实体和关系检索
由于经过微调的LLMs对逻辑形式框架具有良好的生成能力,所以在检索阶段,我们采用一种无监督检索方法,将候选逻辑形式中的实体和关系经过短语级语义检索和替换,以获得最终的逻辑形式,可以转化为可在KB上执行的SPARQL查询。

图4.无监督的逻辑形式中实体关系检索算法
对于给定的查询,无监督检索方法(如SimCSE、Contriever、BM25)无需额外的训练,可以选择语义上与候选集最相似的前k个作为检索到的答案集。
(4)可解释的查询执行
在检索之后,我们获得了最终的候选逻辑形式列表 C′′,然后我们依次遍历 C′′ 中的逻辑形式 F 并将其转换为等效的 SPARQL 查询 q = Convert(F)。当找到可以对知识库 K 进行执行的第一个 q 时,我们执行它以获取最终的答案集 A = Execute(q|K)。通过这种方法,我们还可以基于 SPARQL 查询获得自然语言问题的完整推理路径,具有良好的可解释性。
综上,ChatKBQA提出了一种思考方式,既利用大模型执行自然语言语义解析以生成图查询,又通过调用外部知识库进行可解释的查询推理,我们将其称为“思考的图查询”(GQoT),这是一种有前途的LLM+KG组合范式,可更好地利用外部知识,提高问答的可解释性,避免LLM的幻觉。
实验
数据集:所有实验都在两个标准的KBQA数据集上进行:WebQuestionsSP (WebQSP) ,其中包含4,737个自然语言问题和SPARQL查询,以及ComplexWebQuestions (CWQ),其中包含34,689个自然语言问题和SPARQL查询。这两个数据集都基于Freebase知识库。
基线模型:我们将ChatKBQA与众多KBQA基线方法进行比较,包括KV-Mem ,STAGG,GRAFT-Net ,UHop,Topic Units,TextRay等KBQA方法。
评估指标:与以前的研究一样,我们使用F1分数、Hits@1和准确度(Acc)来表示所有答案和单个排名最高答案的覆盖率,以及精确匹配准确度。
超参数和环境:我们在WebQSP上对LLMs进行了100个epoch的微调,在CWQ上进行了10个epoch的微调,batch size为4,学习率为5e-5。所有实验都在一块NVIDIA A40 GPU(48GB)上完成,结果是从五次随机种子实验中取平均值得出的。
我们回答以下研究问题(RQs):
(RQ1)KBQA实验结果
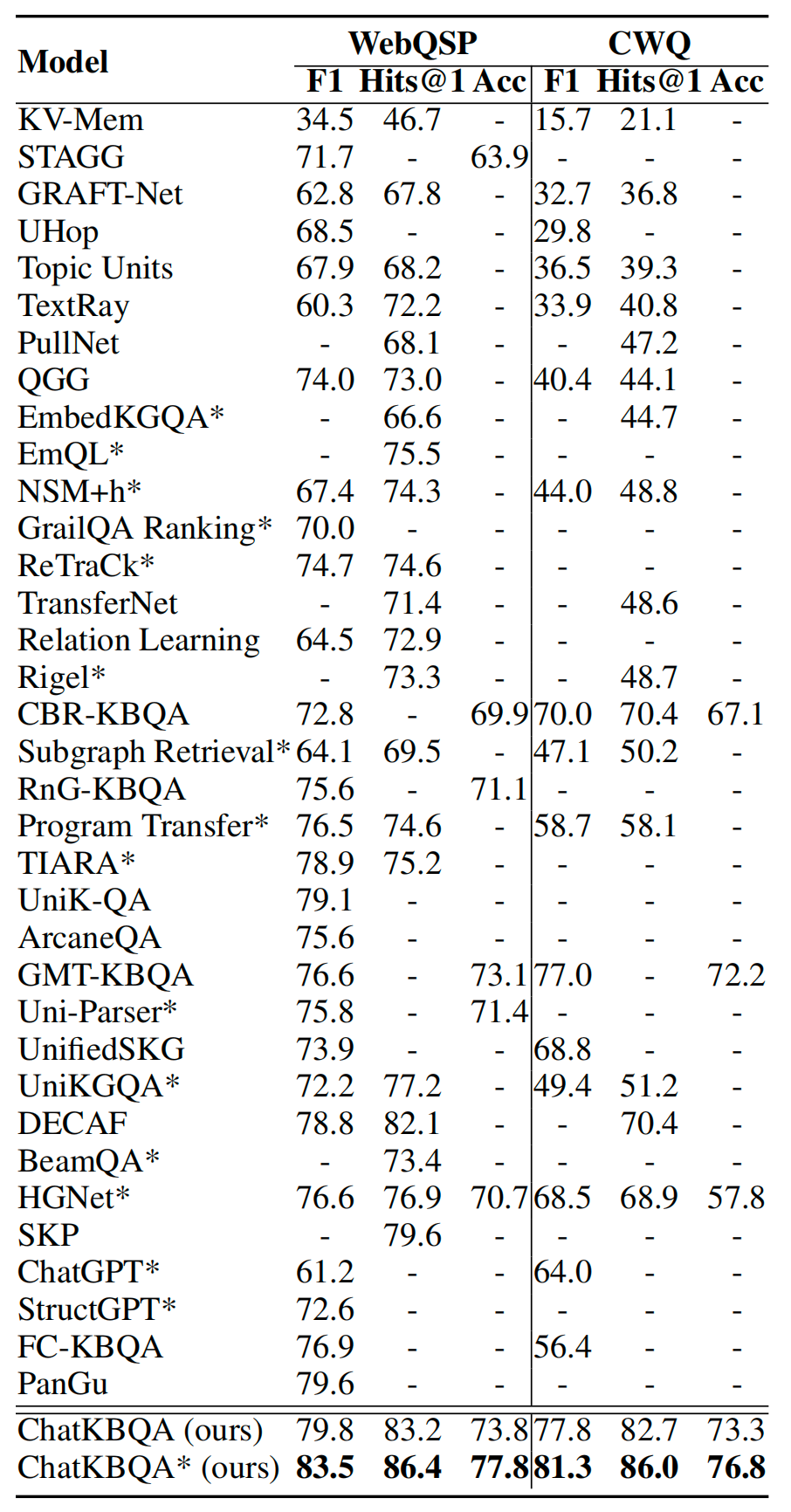
图5.ChatKBQA在CWQ数据集上与其他基线的KBQA结果比较,*表示使用oracle实体链接
在KBQA任务中,上表列出了我们提出的generate-then-retrieve ChatKBQA框架的实验结果,采用了最佳设置,使用Llama-2-7B进行LoRA微调,beam search大小设置为15,以及SimCSE用于无监督检索,以及其他基线模型。我们可以看到,ChatKBQA在WebQSP和CWQ数据集上都明显优于所有现有的KBQA方法。与先前的最佳结果相比,ChatKBQA的F1分数、Hits@1和准确率分别提高了约4个百分点、4个百分点和4个百分点在WebQSP上,CWQ上分别提高了约3个百分点、15个百分点和4个百分点,这反映出ChatKBQA在KBQA任务上具有出色的性能,达到了最新的SOTA性能水平。
(RQ2)消融实验
为了验证ChatKBQA的生成和检索阶段的有效性,我们分别对这两个阶段进行了分离的消融分析。在生成阶段,我们使用了训练数据的20%、40%、60%和80%与完整训练集进行的模型微调相比的效果。如下图(左)所示,随着训练数据量的增加,KBQA的效果也越来越好,证明了微调的有效性。在检索阶段,为了分别验证实体检索(ER)和关系检索(RR),我们从框架中分别去除了ER或RR,并得到了三个简化的变体(ChatKBQA w/o ER,ChatKBQA w/o RR和ChatKBQA w/o ER, RR),然后以不同的beam size进行比较。如下图(右)所示,增加beam size显著提高了效果,ER和RR都对结果有贡献,其中ER的贡献高于RR,因为ChatKBQA w/o RR比ChatKBQA w/o ER要好。
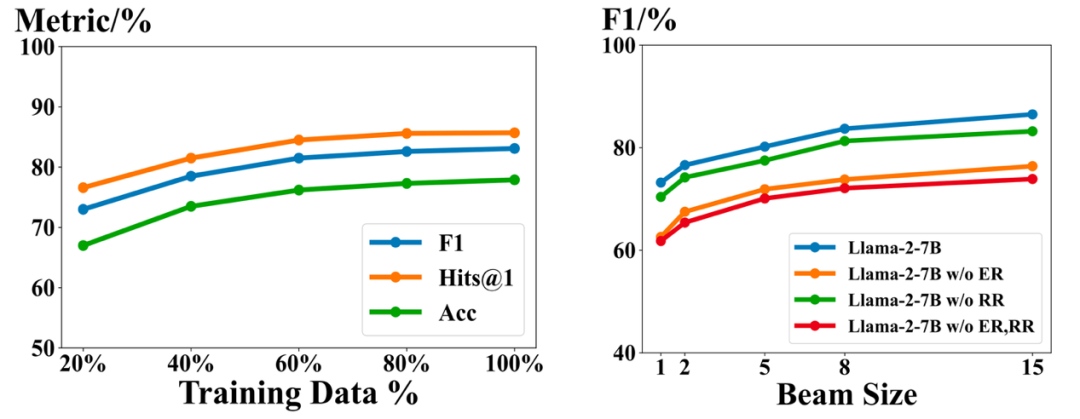
图6.ChatKBQA生成阶段的消融研究(左),ChatKBQA检索阶段的消融研究(右)
(RQ3)生成-检索还是检索-生成
为了验证我们提出的基于大模型的生成然后检索方法是否优于以前的检索然后生成方法,我们采用了在DECAF中设计的指令获取的知识片段,并分别将Top1、Top2、Top5和Top10的检索结果添加到指令中,然后与不进行检索的Llama-2-7B的微调进行比较。如下表所示,我们发现在逻辑形式生成方面,不进行检索优于进行检索,这体现在提取匹配比率(EM)、经过束搜索后的匹配比率(BM)和骨架匹配比率(SM)方面。这是因为检索得到的信息会包含错误的干扰信息,增加指令的最大标记数量,从而导致大模型对原始问题的灾难性遗忘,增加了训练的难度。同时,我们观察到,没有进行检索的Llama-2-7B微调实现了74.7%的BM和91.1%的SM,表现出色,这是因为大模型已经学到了实体和关系的良好模式,为生成后的检索提供了基础。
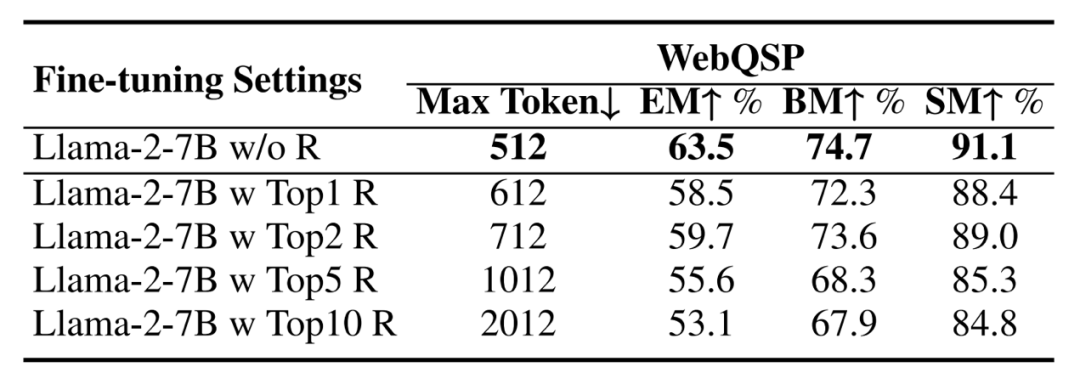
图7.比较在ChatKBQA中微调Llama-2-7B进行逻辑形式生成之前是否使用检索结果
(RQ4)在生成阶段与ChatGPT以及T5的比较
为了说明为什么ChatKBQA选择对开源的生成型大模型进行微调,例如Llama-27B和ChatGLM2-6B,我们分别将生成逻辑形式的大模型替换为ChatGPT、GPT-4、T5和Flan-T5,观察它们的提取匹配(EM)和不使用束搜索的骨架匹配(SM)结果。如下图所示,尽管ChatGPT和GPT-4具有大量的参数,但由于它们不是开源的,无法进行良好的逻辑形式生成。而T5和Flan-T5在经过微调后可以很好地捕获骨架,但EM仅约为10%,远不如Llama-2-7B的63%,因此不能保证后续的无监督实体和关系检索。经过微调的开源大模型,如Llama-2-7B和ChatGLM2-6B,展现出比T5和ChatGPT更强的语义解析能力,可以在EM和SM方面生成质量更高的逻辑形式。
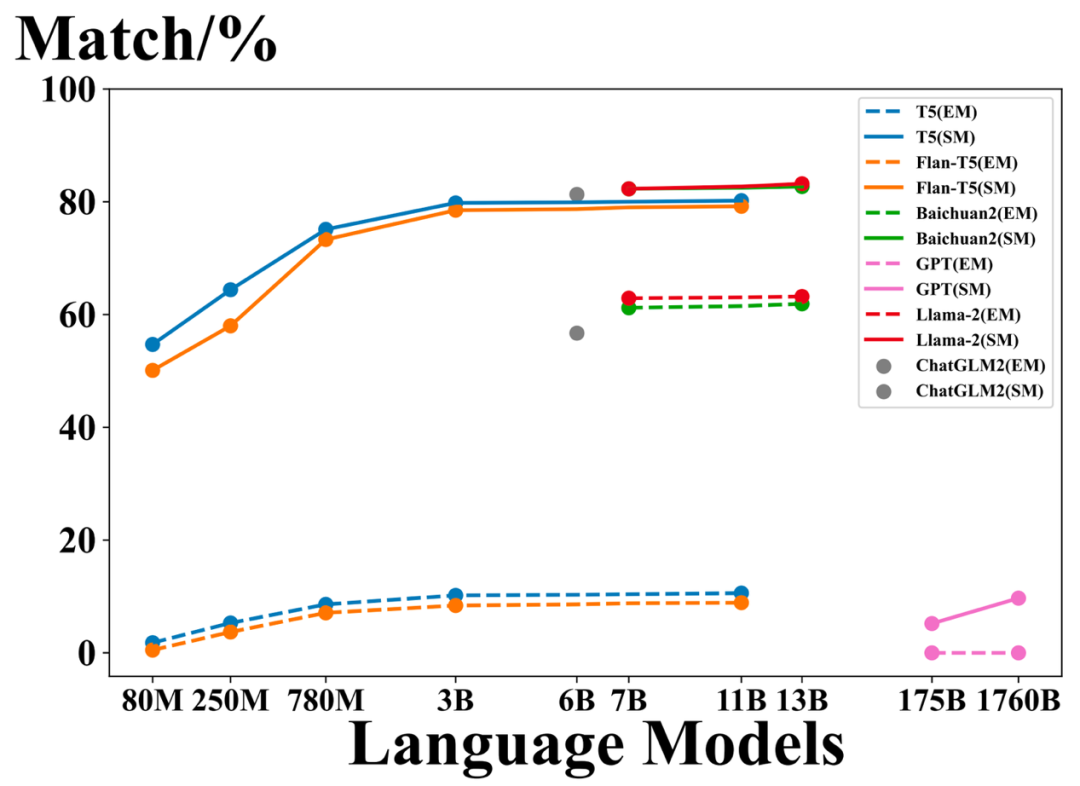
图8.ChatKBQA生成阶段与其他语言模型的比较
(RQ5)检索阶段的效率分析
为了体现生成-然后检索方法如何提高检索效率,我们将逻辑形式生成(AG-R)后的实体检索(ER)和关系检索(RR)与传统从自然语言问题中的检索(NL-R)进行了比较。我们将检索的效率定义为要检索的文本与一组检索答案之间的平均相似度,该相似度范围在[0,1]之间,由不同的检索模型进行评分。需要注意的是,BM25需要进行评分,然后通过映射函数映射到[0,1]范围的相似度。
如下图所示,所有三种检索方法(SimCSE,Contriever和BM25)都认为AG-R比NL-R更有效,对ER和RR来说差距更为显著。这是因为NL-R仍然需要确定实体或关系的位置,而在AG-R中,LLM生成了逻辑形式后,这一步骤已经完成。此外,通常来说,生成的逻辑形式中的关系种类比实体少,而逻辑形式通常可以被直接且准确地预测,而在自然语言问题中,关系通常以隐式方式表示,这使得AG-R在RR上相对于NL-R的效率情况完全不同,这加强了生成-然后检索方法的优势。
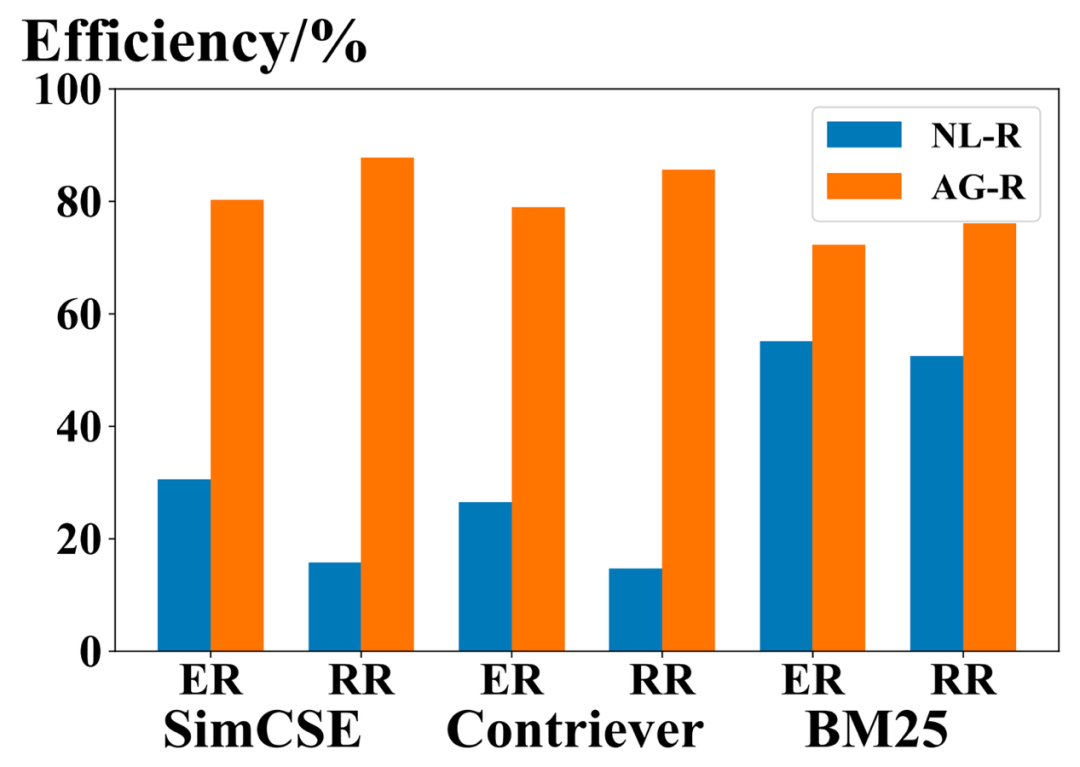
图9.ChatKBQA检索阶段在自然语言问题上(NL-R)与在生成逻辑形式上(AG-R)做检索的效率比较
(RQ6)即插即用的特性
ChatKBQA是一个基于LLMs的KBQA框架,具有即插即用特性,可以灵活替换三个部分:大模型、高效微调方法和无监督检索方法。我们选择Llama-2-13B作为大模型,LoRA作为调整方法,以及SimCSE作为检索方法的基本变种,并将所有变种的beam size设置为8,以在单个A40 GPU上进行比较。我们测试了多种大模型例如Baichuan2-7B、Baichuan2-13B、ChatGLM2-6B、Llama-2-7B,微调方法部分的QLoRA、P-Tuning v2、Freeze,以及检索方法部分的Contriever和BM25。由于ChatKBQA具有即插即用的特性,随着大模型和调整以及检索方法的升级,KBQA任务将变得更好地解决,具有良好的灵活性和可扩展性。
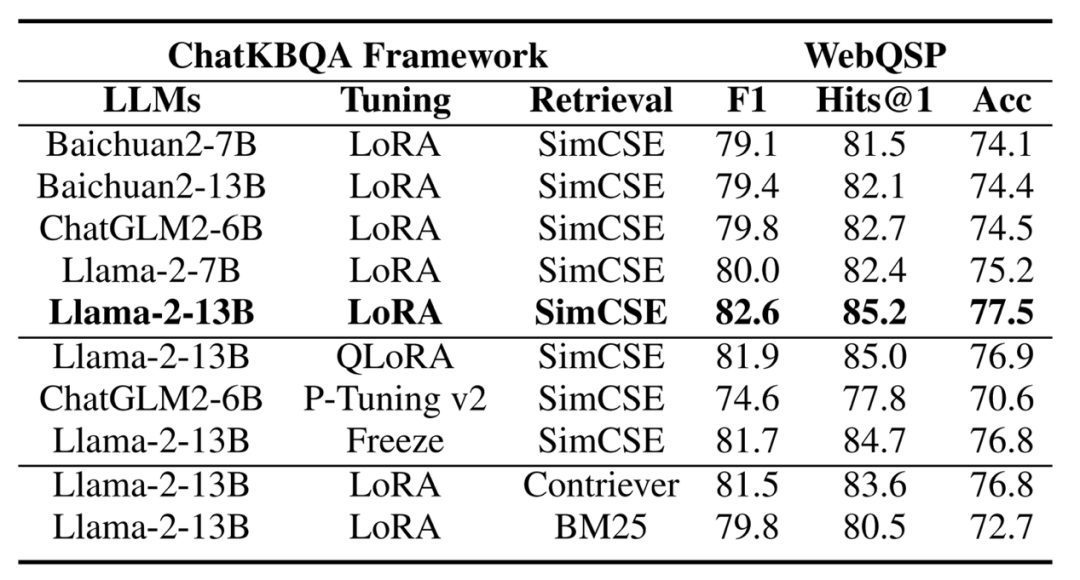
图10.ChatKBQA框架分别替换llm、调优方法和无监督检索方法的即插即用性能比较,beam大小均设为8
总结
在这项工作中,我们提出了ChatKBQA,这是一个基于生成-检索的框架,用于知识库问答(KBQA),充分利用了现代经过微调的大型语言模型(LLMs)的强大能力。通过将重点放在检索之前的逻辑形式生成上,我们的方法与传统方法有了显著的不同,解决了检索效率低和检索错误对经过微调的开源大模型和无监督检索方法的语义解析的误导性影响等固有挑战。我们的实验结果基于两个标准的KBQA基准数据集,WebQSP和CWQ,证实ChatKBQA在KBQA领域取得了新的最佳表现。此外,我们的框架的简单性和灵活性,特别是其即插即用的特性,使其成为将大模型与知识图集成以进行更具解释性和知识要求的问答任务的有前途的方向。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
相关文章:
论文浅尝 | ChatKBQA:基于微调大语言模型的知识图谱问答框架
第一作者:罗浩然,北京邮电大学博士研究生,研究方向为知识图谱与大语言模型协同推理 OpenKG地址:http://openkg.cn/tool/bupt-chatkbqa GitHub地址:https://github.com/LHRLAB/ChatKBQA 论文链接:https://ar…...

软件测试的目的---防范项目风险
软件测试的目的到底是什么一直是困扰开发人员和测试人员的一个问题, 项目管理人员希望测试能够保证软件项目的成功 开发人员希望希望测试可以让他们理直气壮的说,他们的软件是没有问题的,从而证明他们的工作成果 软件测试经典理论说,测试无法证明软件是没有问题,而只能证明软…...

自己动手写编译器:创建由 C 语言编译而成的语法解析器
在上一章节,我们完成了由 c 语言设计的输入系统,本节我们看看如何在前一节的基础上完成一个由 c 语言设计并编译出来的词法解析器。整个解析器的基本设计思路是: 1,由我们上一节设计的输入系统将字符串从文件中读入。 2࿰…...

接口设计-增删改查
关于增删改查的 接口设计,比较简单,有一些固定的做法可以使用。 查询列表 查询列表的接口,带上分页的入参: pageNo,pageSize,非必选,并设置默认值。 入参为 dto,根据 dto 从数据库…...

持续持续集成部署-k8s-配置与存储-配置管理:Secret 的应用
持续持续集成部署-k8s-配置与存储-配置管理:Secret 的应用 1. 简介2. 创建 Secret3. docker-registry 的使用1. 简介 与 ConfigMap 类似,用于存储配置信息,但是主要用于存储敏感信息、需要加密的信息,Secret 可以提供数据加密、解密功能。 在创建 Secret 时,要注意如果要…...
:开发环境搭建)
ZYNQ7020开发(一):开发环境搭建
文章目录 一、配置Ubuntu 编译环境二、安装Petalinux三、安装JTAG驱动四、安装Vitis一、配置Ubuntu 编译环境 虚拟机环境:VMware Workstation 16 Pro 16.1.0 build-17198959Ubuntu 版本:No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04.6 L…...

Spring Boot插件化开发概念原理及实现
Spring Boot 是一个开源的Java框架,它简化了基于Spring框架的应用程序的开发和部署过程。它提供了一种快速、简单的方式来构建独立的、可执行的Spring应用程序。在Spring Boot中,插件化开发是一种强大的开发模式,它允许开发人员将应用程序的不…...

Ps:PSDT 模板文件
自 Photoshop CC 2015.5 版以后,Ps 中新增了一种文件格式:.PSDT。 说明: PSD、PDD、PSDT 都是 Ps 的专用文件格式,需要继续在 Ps 中进行编辑的文件可存为此类格式。 PSD Photoshop document Photoshop 默认文档格式,支…...
Linux-----nginx的简介,nginx搭载负载均衡以及nginx部署前后端分离项目
目录 nginx的简介 是什么 nginx的特点以及功能 Nginx负载均衡 下载 安装 负载均衡 nginx的简介 是什么 Nginx是一个高性能的开源Web服务器和反向代理服务器。它的设计目标是为了解决C10k问题,即在同一时间内支持上万个并发连接。 Nginx采用事件驱动的异…...
presto插件机制揭秘:探索无限可能的数据处理舞台
文章目录 1. 前言2. Presto插件架构3. Plugin接口3.1 插件协议3.2 插件实现类 4. 插件加载过程4.1 PluginManager 5. 插件应用6. 总结 关键词:Presto Plugin 1. 前言 本文源码环境: presto: prestoDb 0.275版本 在Presto框架中插件机制设计是一种非常常见…...

acwing算法基础之数据结构--并查集算法
目录 1 基础知识2 模板3 工程化 1 基础知识 并查集支持O(1)时间复杂度实现: 将两个集合合并。询问两个元素是否在一个集合中。 基本原理:每个集合用一颗树来表示。树根的编号就是整个集合的编号。每个结点存储它的父结点,p[x]表示x的父结点…...
k8s:二进制搭建 Kubernetes v1.20
目录 1 操作系统初始化配置 2 部署 etcd 集群 2.1 准备签发证书环境 2.2 生成Etcd证书 3 部署 docker引擎 4 部署 Master 组件 5 部署 Worker Node 组件 k8s集群master01:192.168.30.105 kube-apiserver kube-controller-manager kube-scheduler etcd k8s集…...

SpringBoot系列-1启动流程
背景 本文作为SpringBoot系列的开篇,介绍SpringBoot的启动流程,包括Spring容器和Tomcat启动过程。SpringBoot作为流行的微服务框架,其是基于约定和自动装配机制对Spring的封装和增强。 由于前面的Spring系列对Spring容器已经进行了较为细致的…...
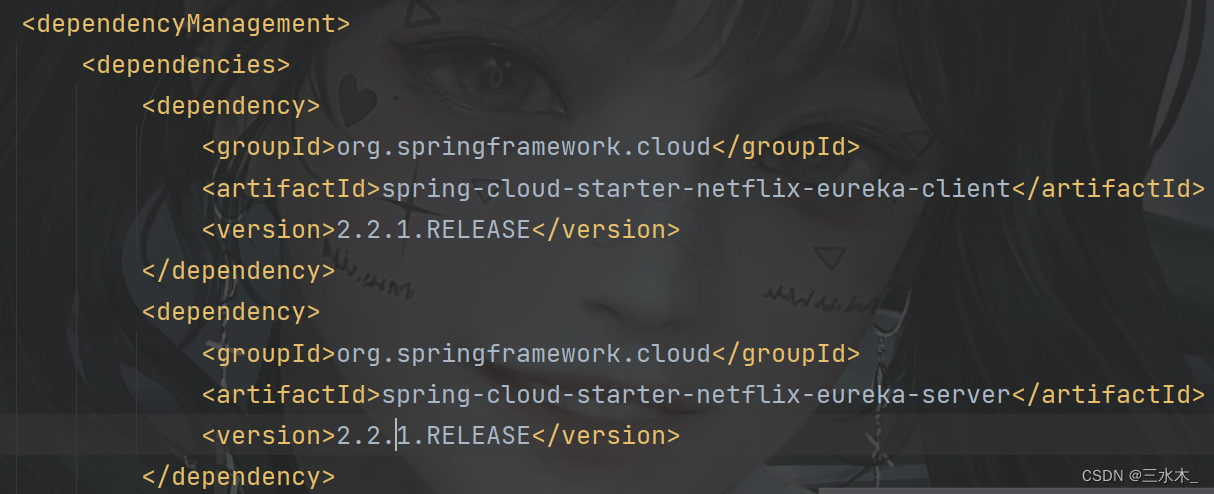
【记】一次common模块导入无效的bug
首先Maven clean install无用 然后idea清除缓存重启无用 pom.xml文件重载无效 正确解决路径: 1.检查common模块的父工程导入和自身模块的声明是否正确 默认是继承父工程的groupid,可以不用再声明 2.检查子工程是否引入正确的common,org不要…...
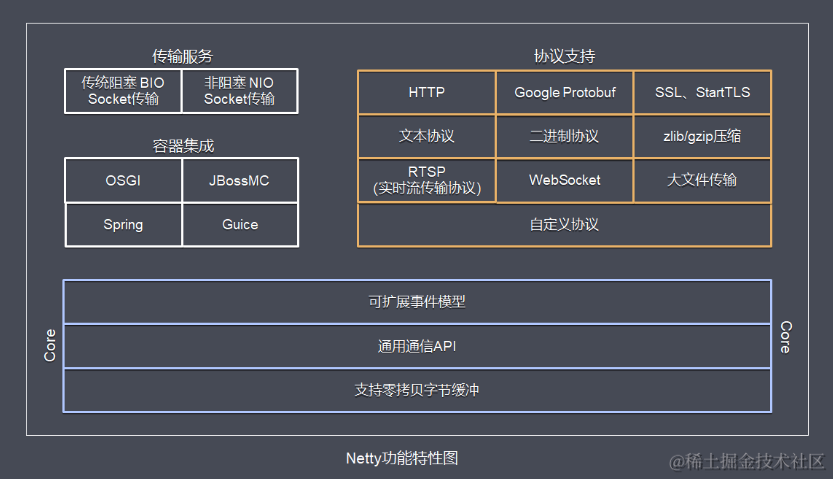
1.Netty概述
原生NIO存在的问题(Netty要解决的问题) 虽然JAVA NIO 和 JAVA AIO框架提供了多路复用IO/异步IO的支持,但是并没有提供给上层“信息格式”的良好封装。JAVA NIO 的 API 使用麻烦,需要熟练掌握 ByteBuffer、Channel、Selector等 , 所以用这些API实现一款真正的网络应…...

YOLO目标检测——真实道路车辆检测数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:自动驾驶技术研发、交通安全监控数据集说明:真实道路车辆检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(j…...
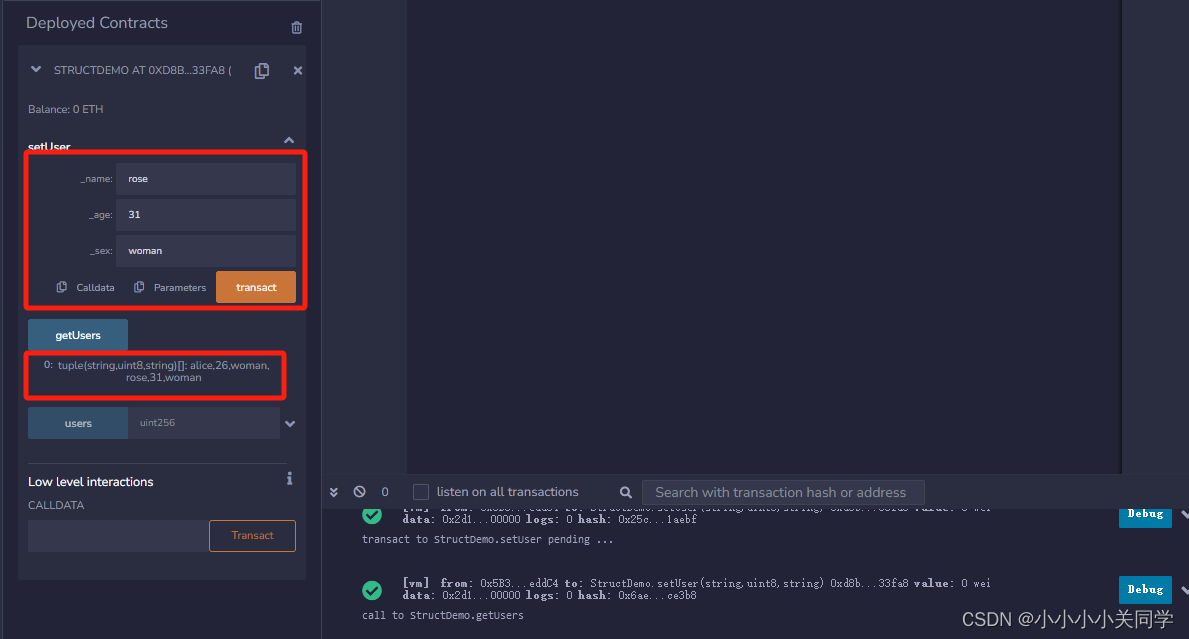
【Solidity】Solidity中的基本数据类型和复合数据类型
1. 基本数据类型 1.1 整数类型 Solidity支持有符号整数和无符号整数,可以指定位数和范围。以下是一些整数类型的示例: int:有符号整数,可以是正数或负数。2,-45,2023 uint:无符号整数&#x…...

Flutter Set存储自定义对象时 如何保证唯一
在Flutter中,Set和List是两种不同的集合类型,List中存储的元素可以重复,Set中存储的元素不可重复。 如果你想在Set中存储自定义对象,你需要确保对象的唯一性。 这可以通过在自定义类中实现hashCode方法和equals方法来实现。 has…...

Docker容器中执行throttle.sh显示权限报错:RTNETLINK answers: Operation not permitted
在模拟通信环境时,我执行了一下命令: bash ./throttle.sh wan但是,出现了权限的报错:RTNETLINK answers: Operation not permitted 解决方案说简单也挺简单,只需要两步完成。但是其实又蛮繁琐,因为需要将…...

【Linux】jdk、tomcat、MySQL环境搭建的配置安装,Linux更改后端端口
一、作用 工具的组合为开发者和系统管理员提供了构建和运行Java应用程序以及存储和管理数据的完整环境。 JDK(Java Development Kit):JDK是Java开发工具包,它提供了开发和运行Java应用程序所需的工具和库。通过安装JDK,…...

AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了
AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了2026年真正值得重视的AI底层能力,是让模型知道该信谁 你有没有发现一个很扎心的变化。 以前我们用AI,最怕它不会。 现在我们用AI,最怕它太会了。 它能写…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...
原理与ScalableHD架构优化实践)
超维计算(HDC)原理与ScalableHD架构优化实践
1. 超维计算(HDC)基础解析超维计算(Hyperdimensional Computing, HDC)是一种受大脑信息处理机制启发的计算范式,其核心思想是用高维随机向量(通常称为超向量或HV)来表示和处理信息。与传统神经网…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

Jetson Orin上TVA模型DLA精准卸载配置
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

想深耕网络安全行业,这些必备条件缺一不可
网络空间的攻防对抗日益激烈,网络安全已成为企业生存和国家安全的命脉,它负责构筑数字世界的坚固防线,保护核心资产与用户隐私免受侵害。 想要成为一名优秀的网络安全专家,除了敏锐的安全意识和高度的责任感,更需要锤…...

告别依赖冲突:在Debian12上为特定项目搭建Python2.7.18独立运行环境
告别依赖冲突:在Debian12上为特定项目搭建Python2.7.18独立运行环境 当现代Linux系统已全面拥抱Python3的时代,突然需要维护一个仅支持Python2.7的遗留项目,这种场景对开发者而言无异于一场噩梦。本文将带你用工程化的思维,在Deb…...