性能优于BERT的FLAIR:一篇文章入门Flair模型
文章目录
- What is FLAIR?
- FLAIR Model
- Contextual String Embedding for Sequence Labeling
- example
- FLAIR Application Area
- Sentiment Analysis
- Named Entity Recognition
- Text Classification
- FLAIR
- 一、什么是FLAIR?
- 二、FLAIR Library的优势是什么?
- 三、用于Sequence Labeling的Contextual String Embedding
- FLAIR算法实现
- Embedding Words with Transformers
- Embedding Documents with Transformers
- How to Stack Embedding
- Transformer Embedding
- Embedding Words
- Embedding Sentences
- Arguments
- Layers
- Pooling Operation
- Layer Mean
- Fine-Tunealbe
- Flair Embedding
- Recommended Flair Usage
- Classic Word Embedding
- 参考文献
What is FLAIR?
FLAIR是一个NLP的综合框架,旨在为研究人员提供用于各种文本分析任务的灵活高效的工具集
FLAIR的特点是强调尖端的序列标记(cutting-edge sequence labeling)、文本分类(text categorization)和语言建模(language modeling)
FLAIR由两个主要部分组成:FLAIR Library和FLAIR Embedding
- FLAIR Library包含几种用于常见NLP任务的预配置模型和应用程序
- FLAIR Embedding提供了一个在巨大数据集上训练的Word Embedding和Contextual String Embedding
FLAIR Model
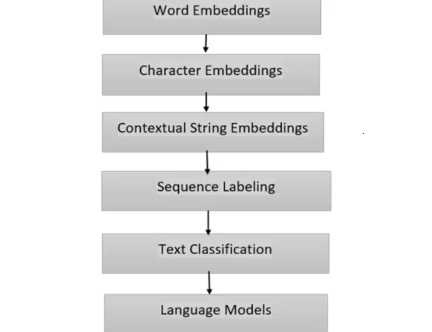
FLAIR模型图说明了通过FLAIR不同组件的信息流,提供了如何处理和分析文本的可视化表示,该图显示了以下组件:
- Word Embedding:使用Word2Vec和GloVe捕获给定文本中各个单词的语义和句法信息
- Character Embedding:结合Character Embedding来捕获单词的形态信息
- Contextual String Embedding:FLAIR利用Contextual String Embedding根据周围的上下文对单词的含义进行编码
- Sequence Labeling:FLAIR使用Sequence Labeling(例如LSTM)为文本中的各个token分配label,该组件对命名实体识别和词性标记等任务至关重要
- Text Classification:FLAIR使用卷积神经网络(CNN)和Self-Attention支持文本分类任务,该组件使模型能够将文档分类为不同的类别或预测情感
- Language Models:FLAIR结合了捕捉文本全局上下文的语言模型,这些模型(Transformer)是在大型语料库上进行训练的,并且可以生成上下文化的单词表示
Contextual String Embedding for Sequence Labeling
FLAIR 中的Contextual String Embedding是文本中word或token的表示,它们根据周围的上下文捕获其含义。这些embedding通过考虑整个句子或单词出现的标记序列来编码单个单词的语义和句法信息。这种上下文信息对于 NLP 中的序列标记任务至关重要,例如命名实体识别 (NER) 和词性 (POS) 标记。
example
"The cat sat on the mat."例如,单词"mat"可以指代地板覆盖物,而单词"cat"可能指代猫科哺乳动物。
在FLAIR中,Contextual String Embedding通常基于BERT或RoBERTa,它会考虑句子中每个单词的上下文,并为该单词生成对应的向量表示或Embedding
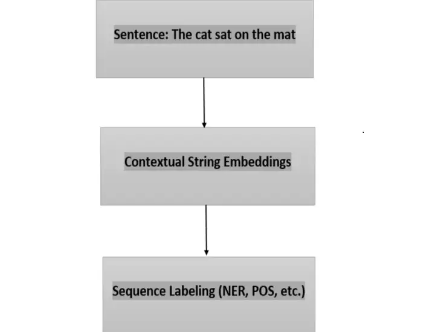
在图中,输入句子 "The cat sat on the mat"被输入到Contextual String Embedding组件中,该组件将句子作为一个整体进行处理,Contextual String Embedding为句子中的每个单词生成对应的向量表示,捕获它们的上下文含义
然后,这些Contextual String Embedding将用作Sequence Labeling的输入,例如命名实体识别 (NER) 或词性 (POS) 标记。Sequence Labeling组件根据上下文和手头的任务将特定标签应用于句子中的每个单词
例如,在命名实体识别任务中,Sequence Labeling组件可以将"cat"识别和分类为 "ANIMAL"类型的实体,将"mat"识别为"OBJECT"类型的实体。
Contextual String Embedding通过利用句子中单词的上下文信息,在提高Sequence Labeling任务的性能方面发挥着至关重要的作用。它们使模型能够根据周围的单词做出更准确的预测,从而提高准确性和对文本的理解。
FLAIR Application Area
Sentiment Analysis
情感分析涉及确定一段文本中表达的情感,无论是积极的、消极的还是中性的。 FLAIR 的模型可以准确分析社交媒体帖子、客户评论和在线讨论中的情绪。
Named Entity Recognition
命名实体识别(NER)旨在识别和分类文本中的命名实体,例如人名、组织名称、位置和日期。 FLAIR 的Sequence Labeling模型在 NER 任务中表现出色,可为信息提取提供准确的结果。
Text Classification
文本分类涉及将文档分类为预定义的类别或主题。 FLAIR 提供了强大的文本分类模型,支持垃圾邮件检测、主题建模和文档组织等任务
FLAIR
对语境的了解打破了阻碍NLP技术进步的障碍
至今为止,单词要么表示为稀疏矩阵,要么表示为嵌入式词语,如GLoVe,Bert和ELMo
一、什么是FLAIR?
Flair是由Zalando Research开发的一个简单的自然语言处理(NLP)库。 Flair的框架直接构建在PyTorch上,PyTorch是最好的深度学习框架之一。 Zalando Research团队还为以下NLP任务发布了几个预先训练的模型:
- 名称-实体识别(NER):它可以识别单词是代表文本中的人,位置还是名称。
- 词性标注(PoS):将给定文本中的所有单词标记为它们所属的“词性”。
- 文本分类:根据标准对文本进行分类(标签)。
二、FLAIR Library的优势是什么?
Flair库中包含了许多强大的功能,以下是最突出的一些方面:
- 它包括了最通用和最先进的单词嵌入方式,如GloVe,BERT,ELMo,字符嵌入等。凭借Flair API技术,使用起来非常容易
- Flair的界面允许我们组合不同的word embedding并使用词向量表示文档,显著优化了结果
三、用于Sequence Labeling的Contextual String Embedding
在处理NLP任务时,上下文语境非常重要。通过先前字符预测下一个字符,这一学习过程构成了序列建模的基础。
Contextual String Embedding是通过熟练利用字符语言模型的内部状态,来产生一种新的嵌入类型。简单来说,它通过字符模型中的某些内部原则,使单词在不同的句子中可以具有不同的含义
注意:语言和字符模型是单词/字符的概率分布,因此每个新单词或新字符都取决于前面的单词或字符。
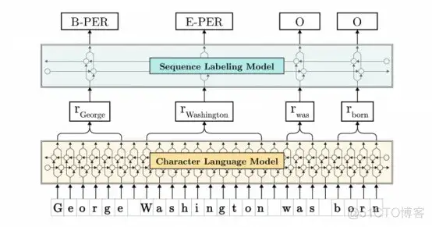
有两个主要因素驱动了Contextual String Embedding:
- 这些单词被理解为字符(没有任何单词的概念)。也就是说,它的工作原理类似于字符嵌入
- Embedding是通过其周围文本进行语境化的。这意味着根据上下文,相同的单词可以有不同的Embedding意义。很像自然的人类语言,不是吗?在不同的情况下,同一个词可能有不同的含义。
让我们看个例子来理解这个意思:
- 案例1:读一本书(Reading a book)
- 案例2:请预订火车票(Please book a train ticket)
说明:
- 在案例1中,book是一个名词
- 在案例2中,book是动词
FLAIR算法实现
Embedding Words with Transformers
使用flair中的TransformerWordEmbeddings来实现将文本映射到向量空间中:
from flair.data import Sentence
from flair.embeddings import TransformerWordEmbeddings# init embedding
embedding = TransformerWordEmbeddings("./model/bert-base-chinese")# create a sentence
sentence = Sentence("今天天气真好")# embed words in sentence
embedding.embed(sentence)
for token in sentence:print(f"{token}: {token.embedding}")
Embedding Documents with Transformers
from flair.data import Sentence
from flair.embeddings import TransformerDocumentEmbeddings# init embedding
document_embedding=TransformerDocumentEmbeddings("./model/bert-base-chinese")# create a sentence
document_sentence=Sentence("今天天气真好")# embed words in sentence
document_embedding.embed(document_sentence)
print(f"{document_sentence}: {document_sentence.embedding}")
How to Stack Embedding
我们可以使用Flair将embedding组合成"embedding stacks",当不进行微调时,使用embedding组合通常会给出最佳结果
使用StackedEmbedding类并通过传递希望组合的embedding列表来实例化它
Transformer Embedding
Flair 支持各种基于 Transformer 的架构,例如 HuggingFace 的 BERT 或 XLNet,有两个类 TransformerWordEmbeddings(用于嵌入单词)和 TransformerDocumentEmbeddings(用于嵌入文档)。
Embedding Words
加载BERT模型:
from flair.embeddings import TransformerWordEmbeddings# init embedding
embedding = TransformerWordEmbeddings('bert-base-uncased')# create a sentence
sentence = Sentence('The grass is green .')# embed words in sentence
embedding.embed(sentence)
加载RoBERTa模型:
from flair.embeddings import TransformerWordEmbeddings# init embedding
embedding = TransformerWordEmbeddings('roberta-base')# create a sentence
sentence = Sentence('The grass is green .')# embed words in sentence
embedding.embed(sentence)
Embedding Sentences
要将整个句子作为一个整体(而不是句子中的每个单词),只需要使用TransformerDocumentEmbedding即可:
from flair.embeddings import TransformerDocumentEmbeddings# init embedding
embedding = TransformerDocumentEmbeddings('roberta-base')# create a sentence
sentence = Sentence('The grass is green .')# embed words in sentence
embedding.embed(sentence)
Arguments
初始化 TransformerWordEmbeddings 和 TransformerDocumentEmbeddings 类时可以设置多个选项:
| Argument | Default |
|---|---|
| model | bert-base-uncased |
| layers | all |
| subtoken_pooling | first |
| layer_mean | True |
| fine_tune | False |
Layers
layers参数控制Transformer层用于嵌入,如果将此值设置为 “-1、-2、-3、-4”,则使用前 4 层进行嵌入。如果将其设置为 “-1”,则仅使用最后一层。如果将其设置为"all",则使用所有图层。
这会影响embedding的长度,因为层只是连接起来的
from flair.data import Sentence
from flair.embeddings import TransformerWordEmbeddingssentence = Sentence('The grass is green.')# use only last layers
embeddings = TransformerWordEmbeddings('bert-base-uncased', layers='-1', layer_mean=False)
embeddings.embed(sentence)
print(sentence[0].embedding.size())sentence.clear_embeddings()# use last two layers
embeddings = TransformerWordEmbeddings('bert-base-uncased', layers='-1,-2', layer_mean=False)
embeddings.embed(sentence)
print(sentence[0].embedding.size())sentence.clear_embeddings()# use ALL layers
embeddings = TransformerWordEmbeddings('bert-base-uncased', layers='all', layer_mean=False)
embeddings.embed(sentence)
print(sentence[0].embedding.size())"""
torch.Size([768])
torch.Size([1536])
torch.Size([9984])
"""
Pooling Operation
大多数基于Transformer的模型(Transformer-XL除外)都使用subword tokenization。例如,以下token puppeteer可以标记(tokenization)为subwords:pupp、##ete 和 ##er。
我们对这些subwords实现不同的池化操作来生成最终的token表示:
- first:仅使用第一个subword的embedding
- last:仅使用最后一个subword的embedding
- first_last:第一个和最后一个subword的embedding被连接并使用
- mean:计算并使用所有subword embedding的 torch.mean
# use first and last subtoken for each word
embeddings = TransformerWordEmbeddings('bert-base-uncased', subtoken_pooling='first_last')
embeddings.embed(sentence)
print(sentence[0].embedding.size())
Layer Mean
基于 Transformer 的模型具有一定数量的层,可以设置 layer_mean=True 对所有选定图层进行平均,所得向量将始终具有与单层相同的维度:
from flair.embeddings import TransformerWordEmbeddings# init embedding
embedding = TransformerWordEmbeddings("roberta-base", layers="all", layer_mean=True)# create a sentence
sentence = Sentence("The Oktoberfest is the world's largest Volksfest .")# embed words in sentence
embedding.embed(sentence)"""
tensor([-0.0323, -0.3904, -1.1946, ..., 0.1305, -0.1365, -0.4323],device='cuda:0', grad_fn=<CatBackward>)
Fine-Tunealbe
对embedding进行微调时,在TransformerWordEmbedding中设置卡fine_tune=True。微调时,也应该只使用最顶层,所以最好设置layers=“-1”
# use first and last subtoken for each word
embeddings = TransformerWordEmbeddings('bert-base-uncased', fine_tune=True, layers='-1')
embeddings.embed(sentence)
print(sentence[0].embedding)
Flair Embedding
Contextual String Embedding是一种强大的嵌入,可以捕获超出标准Word Embedding的潜在语义信息。主要区别是:
- 它们在没有任何明确的单词概念下进行训练,因此从根本上将单词建模为字符序列
- 它们通过周围的文本进行语境化,这意味着同一个单词将根据其上下文使用而具有不同的embedding
使用Flair只需要实例化适当的embedding类即可使用:
from flair.embeddings import FlairEmbeddings# init embedding
flair_embedding_forward = FlairEmbeddings('news-forward')# create a sentence
sentence = Sentence('The grass is green .')# embed words in sentence
flair_embedding_forward.embed(sentence)
Recommended Flair Usage
建议结合前向和后向Flair embedding,根据任务,还建议在组合中添加标准word embedding。因此,对于大多数英语任务,我们推荐的StackedEmbedding是:
from flair.embeddings import WordEmbeddings, FlairEmbeddings, StackedEmbeddings# create a StackedEmbedding object that combines glove and forward/backward flair embeddings
stacked_embeddings = StackedEmbeddings([WordEmbeddings('glove'),FlairEmbeddings('news-forward'),FlairEmbeddings('news-backward'),])sentence = Sentence('The grass is green .')# just embed a sentence using the StackedEmbedding as you would with any single embedding.
stacked_embeddings.embed(sentence)# now check out the embedded tokens.
for token in sentence:print(token)print(token.embedding)
使用三种不同embedding的组合来实现word embedding,这样的组合往往可以实现最先进的精度
Classic Word Embedding
经典的Word Embedding是静态的、单词级的,这意味着每个不同的单词都会得到一个预先计算的embedding。
只要实例化WordEmbeddings类并传入相应的模型名称即可:
from flair.embeddings import WordEmbeddings# init embedding
glove_embedding = WordEmbeddings('glove')# create sentence.
sentence = Sentence('The grass is green .')# embed a sentence using glove.
glove_embedding.embed(sentence)# now check out the embedded tokens.
for token in sentence:print(token)print(token.embedding)
将适当的 id 字符串传递给 WordEmbeddings 类的构造函数来选择加载那些预训练的embedding。
如果要加载自定义embedding,需要确保自定义embedding的格式为gensim
可以使用以下代码片段经FastText embedding转换为gensim
import gensim
word_vectors = gensim.models.KeyedVectors.load_word2vec_format('/path/to/fasttext/embeddings.txt', binary=False)
参考文献
1、Hugging Face-FLAIR
2、Flair:一款简单但技术先进的NLP库
3、Everything about FLAIR: A Framework for NLP
4、Transformer embeddings
5、Embeddings
6、Flair embeddings
相关文章:
性能优于BERT的FLAIR:一篇文章入门Flair模型
文章目录 What is FLAIR?FLAIR ModelContextual String Embedding for Sequence Labelingexample FLAIR Application AreaSentiment AnalysisNamed Entity RecognitionText Classification FLAIR一、什么是FLAIR?二、FLAIR Library的优势是什么ÿ…...
Weblogic ssrf漏洞复现
文章目录 一、漏洞描述二、漏洞特征1.查看uddiexplorer应用2.漏洞点 三、漏洞复现1.获取容器内网ip2.VULHUB Weblogic SSRF漏洞 docker中 centos6 无法启动的解决办法3.准备payload4.反弹shell 一、漏洞描述 SSRF 服务端请求伪造(Server-Side Request Forgery),是一种由攻击者…...
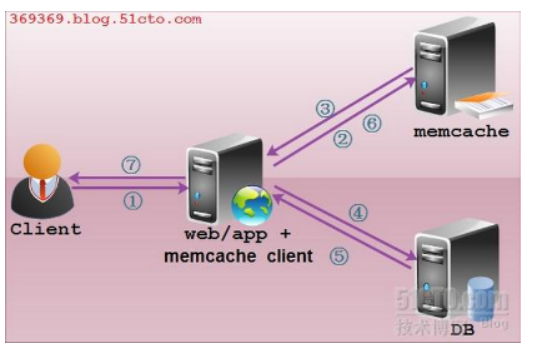
Memcached构建缓存服务器
Memcache介绍 1、特点 内置存储方式----------为了提高性能,memcached中保存的数据都存储在memcache内置的内存存储空间中。由于数据仅存在于内存中,重启操作系统会导致全部数据消失 简单key/value存储--------------服务器不关心数据本身的意义及结构&…...
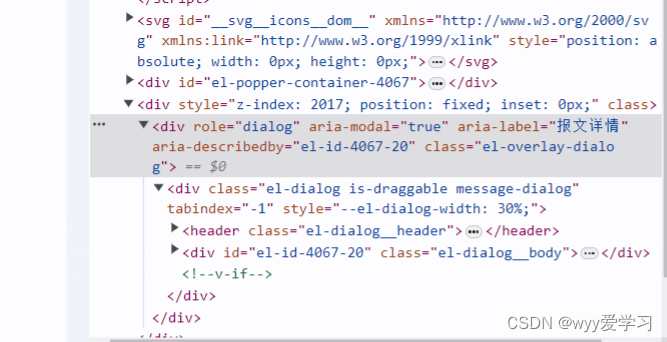
vue3+element Plus实现弹框的拖拽、可点击底层页面功能
1、template部分 <el-dialog:modal"false"v-model"dialogVisible"title""width"30%"draggable:close-on-click-modal"false"class"message-dialog"> </el-dialog> 必须加的属性 modal:是否去掉遮罩层…...
)
Vue+elementui 纯前端实现Excel导入导出功能(区分表头标题)
引入插件 import * as XLSX from "xlsx/xlsx.mjs"; import { read, utils } from xlsx/xlsx.mjs; 上传文件方法 // 上传文件状态改变时的钩子,添加文件、上传成功和上传失败时都会被调用async handle(ev) {//改变表格key值this.$refs.cpkTable.loading…...

使用Scrapy的调试工具和日志系统定位并解决爬虫问题
目录 摘要 一、Scrapy简介 二、Scrapy的调试工具 1、Shell调试工具 2、断点调试 三、Scrapy的日志系统 四、实例解析 1、启用详细日志 2、断点调试 3、分析日志 4、解决问题 五、代码示例 总结 摘要 本文详细介绍了如何使用Scrapy的调试工具和日志系统来定位并解…...
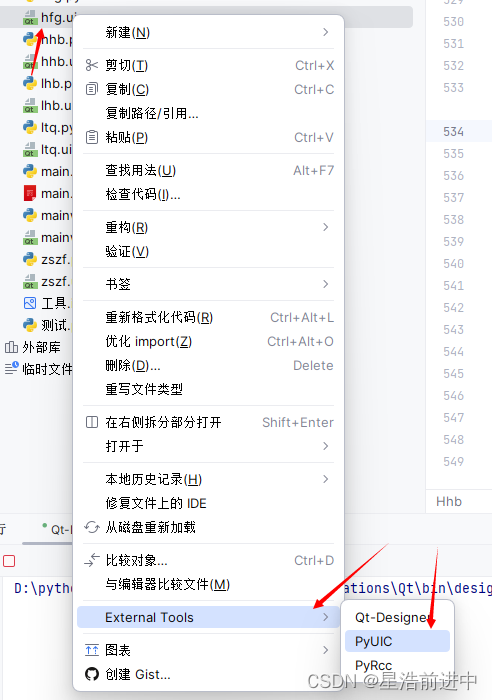
Pycharm安装配置Pyqt5教程(保姆级)
目录 一、前言 1、依赖包 2、工具 二、安装依赖包 三、配置环境 四、配置设计工具 1、Qt Designer 2、PyRcc 3、PyUIC 五、使用 1、界面设计 2、ui文件转化为py文件 一、前言 很多情况下需要为程序设计一个GUI界面,在Python中使用较多的用户界面设计工具…...
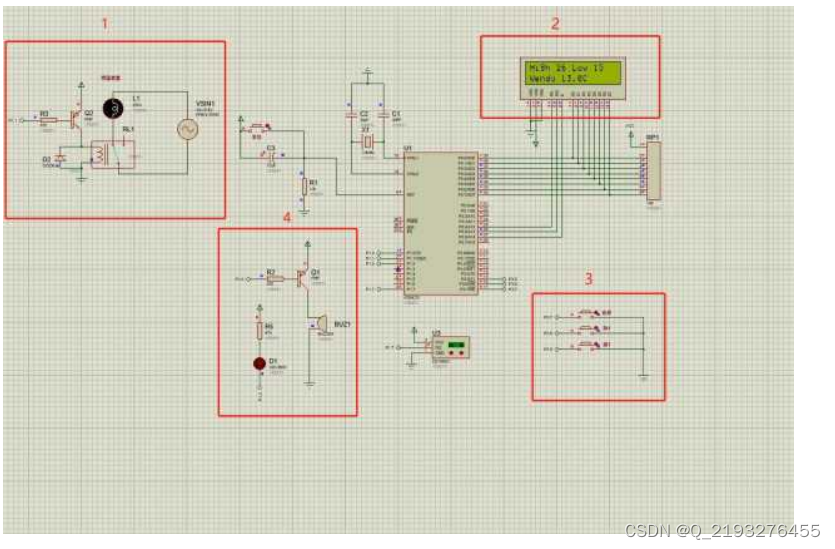
基于单片机的养殖场温度控制系统设计
博主主页:单片机辅导设计 博主简介:专注单片机技术领域和毕业设计项目。 主要内容:毕业设计、简历模板、学习资料、技术咨询。 文章目录 主要介绍一、控制系统设计二、系统方案设计2.1 系统运行方案设计2.1.1 羊舍环境温度的确定 三、 系统仿…...
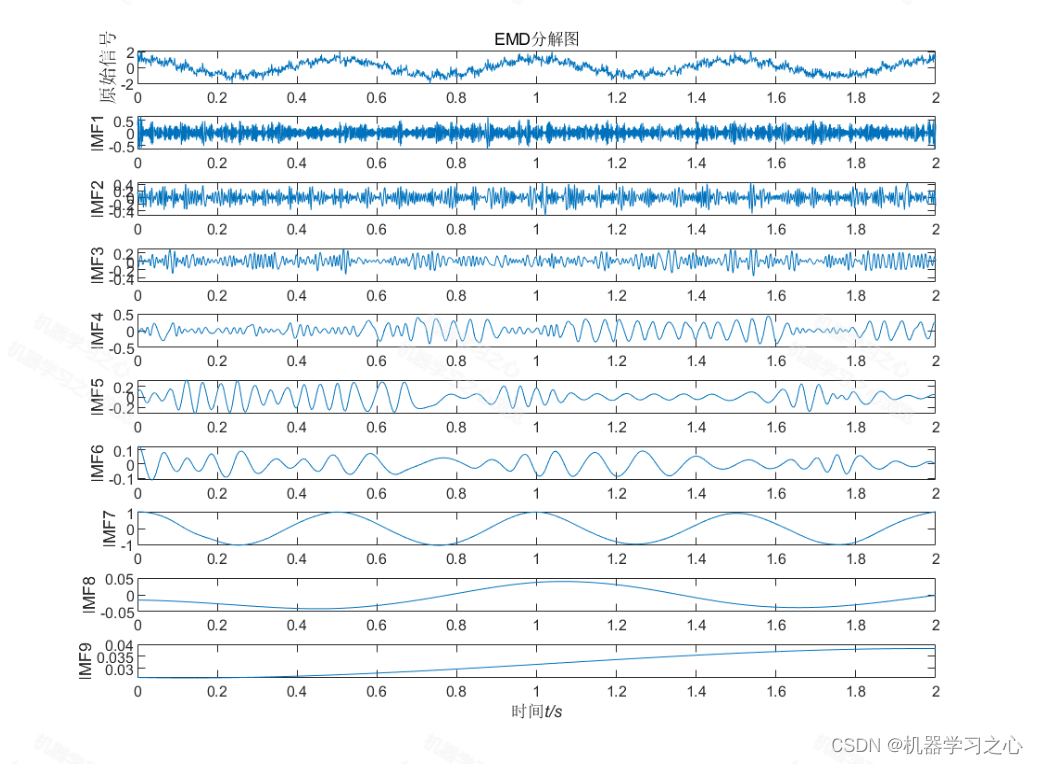
时序分解 | Matlab实现EMD经验模态分解时间序列信号分解
时序分解 | Matlab实现EMD经验模态分解时间序列信号分解 目录 时序分解 | Matlab实现EMD经验模态分解时间序列信号分解效果一览基本介绍程序设计参考资料 效果一览 基本介绍 Matlab实现EMD经验模态分解时间序列信号分解 Matlab语言 算法新颖小众,用的人很少…...

解决无法进入MERCURY路由器管理界面的问题 水星网络路由器
问题:今天家里停电了,来电过后,路由器有信号,但是手机连上WiFi后无法正常上网。尝试过给路由器断电开电,拔插网线。试了这两种方法后手机依然无法正常上网。最后想到了重启路由器,也就是将路由器恢复出厂设…...
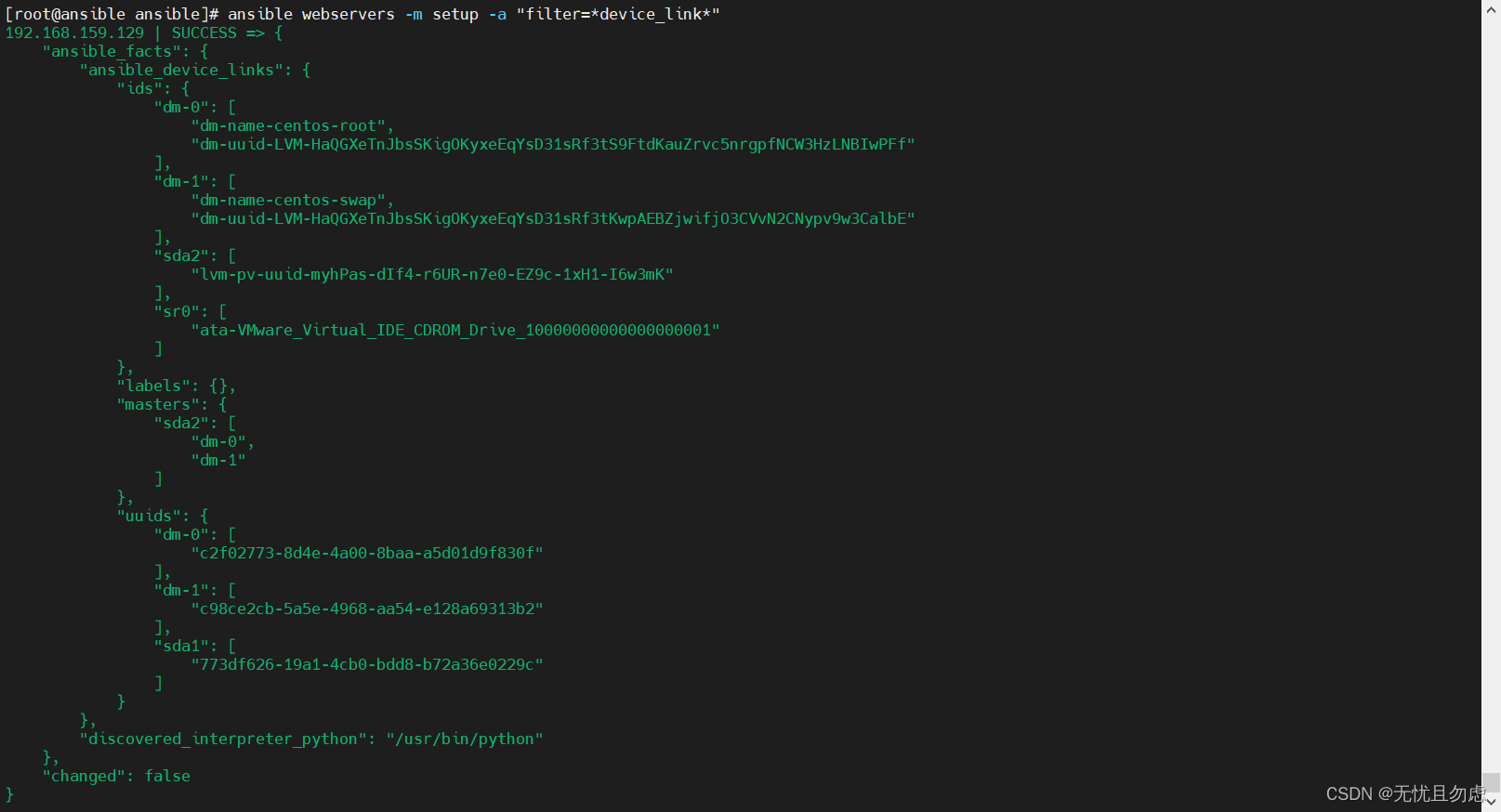
Ansible自动化安装部署及使用
目录 前言 一、环境概况 修改主机名(可选项) 二、安装部署 1.安装epel扩展源 2.安装Ansible 3.修改Ansible的hosts文件 4.生成密钥 三、Ansible模块使用介绍 Command模块 Shell模块 User模块 Copy模块 File模块 Hostname模块 Yum模块 Ser…...
idea中配置spring boot单项目多端口启动
参照文章 https://zhuanlan.zhihu.com/p/610767685 项目配置如下 下面为 idea 2023,不同版本的设置有区别,但是没那么大,idea 2023默认使用新布局,切换为经典布局即可。 在项目根目录的.idea/workspace.xml文件里添加如下配置 &l…...
MP4视频文件损坏怎么修复?
3-2 作为摄影师,或者在平时有拍摄工作的事情的,比如搞婚庆、搞航拍什么的,有一定的概率会遇到损坏的视频文件,比如相机突然断电、无人机炸机等,有可能会导致保存的MP4文件损坏。 这种文件使用播放器播放的话…...

使用electron ipcRenderer接收通信消息多次触发
使用electron ipcRenderer接收通信消息多次触发 在使用electron ipcRenderer.on接收ipcRenderer.send的返回值时,ipcRenderer.send发送一次信息, ipcRenderer.on会打印多个日志, renderer.once(get-file-path, (event: any, paths: any) &g…...

Spring事务最佳应用指南(包含:事务传播类型、事务失效场景、使用建议、事务源码分析)
前言 本文主要介绍的是在Spring框架中有关事务的应用方式,以及一些生产中常见的与事务相关的问题、使用建议等。同时,为了让读者能够更容易理解,本文在讲解过程中也会通过源码以及案例等方式进行辅助说明,通过阅读本文不但能够解…...

Go语言的Http包及冒泡排序解读
目录标题 Http一.Get二、Post三、Http服务器 BubbleSort冒泡排序 Http 一.Get package mainimport ("fmt""io/ioutil""net/http")func main() {response, err : http.Get("http://www.baidu.com")if err ! nil {fmt.Println("Ht…...
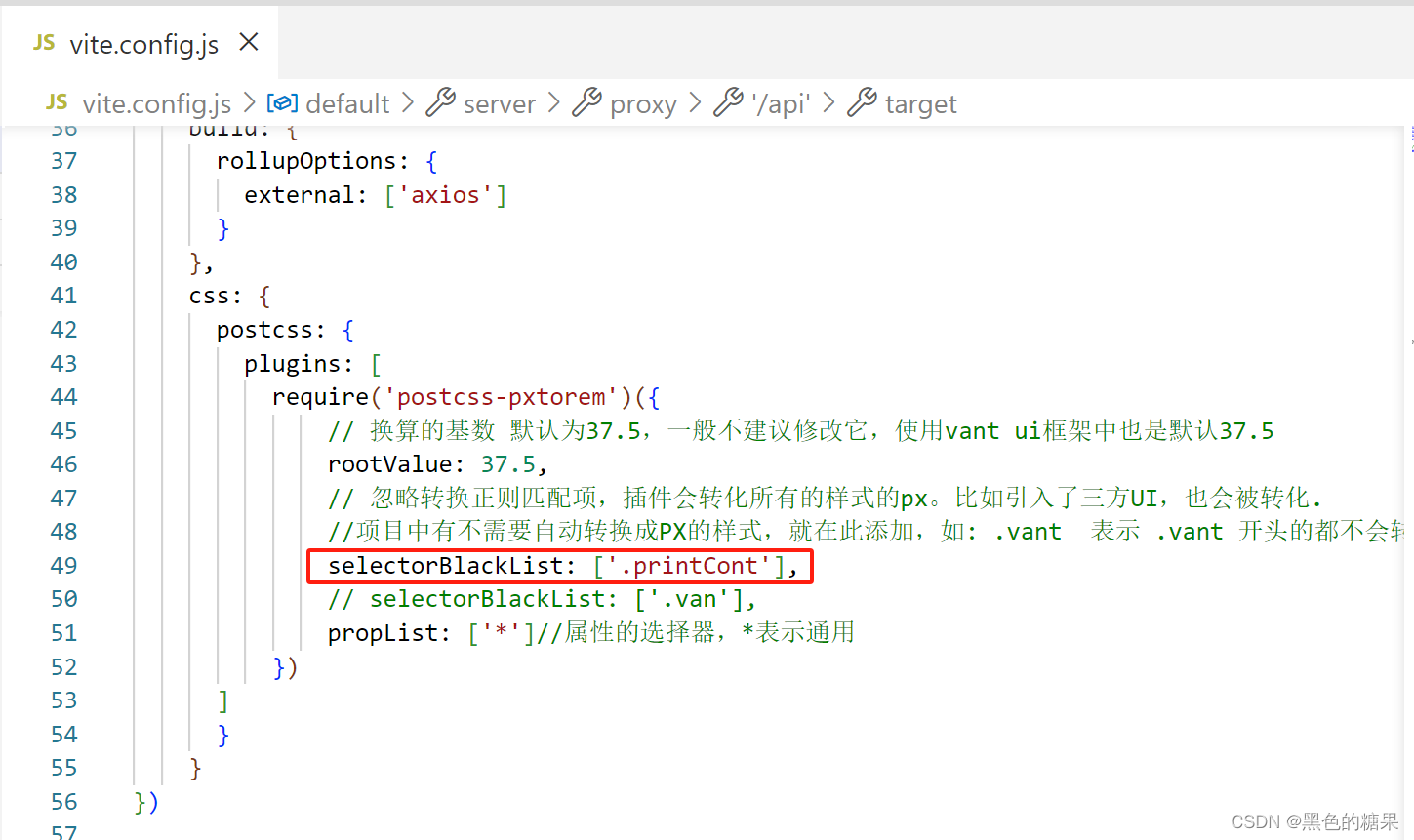
vue二维码生成插件qrcodejs2-fix、html生成图片插件html2canvas、自定义打印内容插件print-js的使用及问题总结
一、二维码生成插件qrcodejs2-fix 1.安装命令 npm i qrcodejs2-fix --save2.页面使用 import { nextTick } from vue; import QRCode from qrcodejs2-fix; nextTick(() > {let codeView document.querySelector("#codeView");codeView.innerHTML ""…...
)
[SSD综述1.8] 固态存储市场发展分析与预测_固态存储技术发展方向(2022to2023)
依公知及经验整理,原创保护,禁止转载。 专栏 《SSD入门到精通系列》 <<<< 返回总目录 <<<< 前言 自2020年疫情爆发以来,远程办公、网上教育、流媒体等等应用引爆对消费电子及云服务的需求增长,全球数字化转型加速,带来了两年的闪存风光时…...

【Linux】多路IO复用技术③——epoll详解如何使用epoll模型实现简易的一对多服务器(附图解与代码实现)
在正式阅读本篇博客之前,建议大家先按顺序把下面这两篇博客看一下,否则直接来看这篇博客的话估计很难搞懂 多路IO复用技术①——select详解&如何使用select模型在本地主机实现简易的一对多服务器http://t.csdnimg.cn/BiBib多路IO复用技术②——poll…...

【unity实战】实现类似英雄联盟的buff系统(附项目源码)
文章目录 先来看看最终效果前言开始BUFF系统加几个BUFF测试1. 逐层消失,升级不重置剩余时间的BUFF2. 一次性全部消失,升级重置剩余时间的BUFF3. 永久BUFF,类似被动BUFF4. 负面BUFF,根据当前BUFF等级计算每秒收到伤害值,…...
 —— SPI相关概念)
STM32单片机学习(27) —— SPI相关概念
文章目录概述SPI通信的核心特性I2C和SPI的简单对比SPI学习的补充说明SPI硬件电路设计SPI的四条通信线SPI通信的片选线低电平选中不支持广播通信SPI通信的时序结构(重点)SPI通信的比特序通信空闲状态,SPI时钟极性采样时机,SPI时钟相…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

2026这6款神级降AIGC平台大公开,一键让AIGC率直逼绝对安全线!
步入 2026 年,学术圈的风向早已不是从前的模样。曾经大家还在为查重率发愁,如今却陷入了更棘手的困境——如何在不破坏论文专业性的前提下,彻底消除 AI 痕迹?随着 AIGC 检测技术不断进化,高校对论文的审核标准也愈发严…...

约束感知图缩减算法在量子优化中的应用
1. 约束感知图缩减算法概述在量子计算领域,资源受限一直是制约算法实际应用的主要瓶颈。以当前主流的超导量子计算机为例,其量子比特数通常在50-100个之间,且存在显著的噪声干扰。这种硬件限制使得许多经典优化问题难以直接映射到量子设备上求…...

NHSE终极教程:5分钟掌握动物森友会存档编辑技巧
NHSE终极教程:5分钟掌握动物森友会存档编辑技巧 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》的收集烦恼吗?想快速打造梦想岛屿却…...

Linux 负载均衡的 cache_nice_tries:缓存友好的迁移尝试
简介现如今服务器、嵌入式设备、工控主板普遍采用多核、NUMA 架构 CPU,多进程多线程并发运行模式成为常态。Linux 内核依靠调度域分层负载均衡机制,分散 CPU 运行压力,避免单核心负载过高、其余核心空闲浪费硬件算力。但任务跨核心迁移是一把…...

ESP32搭建TFT_LCD中文字库,附常用字库
(一)简介 在使用ESP32的时候,我们知道OLED屏幕是有中文库的,里面有非常多的常用字,但是LCD屏幕只有取模才能得到中文字体,那我们本期教程就来教大家如何搭建自己的字体库,使用中文字体更加方便快…...

如何永久保存微信聊天记录?WeChatMsg终极数据导出指南
如何永久保存微信聊天记录?WeChatMsg终极数据导出指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...