RLHF的替代算法之DPO原理解析:从Zephyr的DPO到Claude的RAILF
前言
本文的成就是一个点顺着一个点而来的,成文过程颇有意思
- 首先,如上文所说,我司正在做三大LLM项目,其中一个是论文审稿GPT第二版,在模型选型的时候,关注到了Mistral 7B(其背后的公司Mistral AI号称欧洲的OpenAI,当然 你权且一听,切勿过于当真)
- 而由Mistral 7B顺带关注到了基于其微调的Zephyr 7B,而一了解Zephyr 7B的论文,发现它还挺有意思的,即它和ChatGPT三阶段训练方式的不同在于:
在第二阶段训练奖励模型的时候,不是由人工去排序模型给出的多个答案,而是由AI比如GPT4去根据不同答案的好坏去排序
且在第三阶段的时候,用到了一个DPO的算法去迭代策略,而非ChatGPT本身用的PPO算法去迭代策略 - 考虑到ChatGPT三阶段训练方式我已经写得足够完整了(instructGPT论文有的细节我做了重点分析、解读,论文中没有的细节我更做了大量的扩展、深入、举例,具体可以参见《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》)
而有些朋友反馈到DPO比PPO好用(当然了,我也理解,毕竟PPO那套算法涉及到4个模型,一方面的策略的迭代,一方面是价值的迭代,理解透彻确实不容易) - 加之ChatGPT的最强竞品Claude也用到了一个RAILF的机制(和Zephyr 7B的AI奖励/DPO颇有异曲同工之妙),之前也曾想过写来着,但此前一直深究于ChatGPT背后的原理细节,现在也算有时间好好写一写了
综上,便拟定了本文的标题
第一部分 什么是DPO
今年5月份,斯坦福的一些研究者提出了RLHF的替代算法:直接偏好优化(Direct Preference Optimization,简称DPO),其对应论文为《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》
那其与ChatGPT所用的RLHF有何本质区别呢,简言之
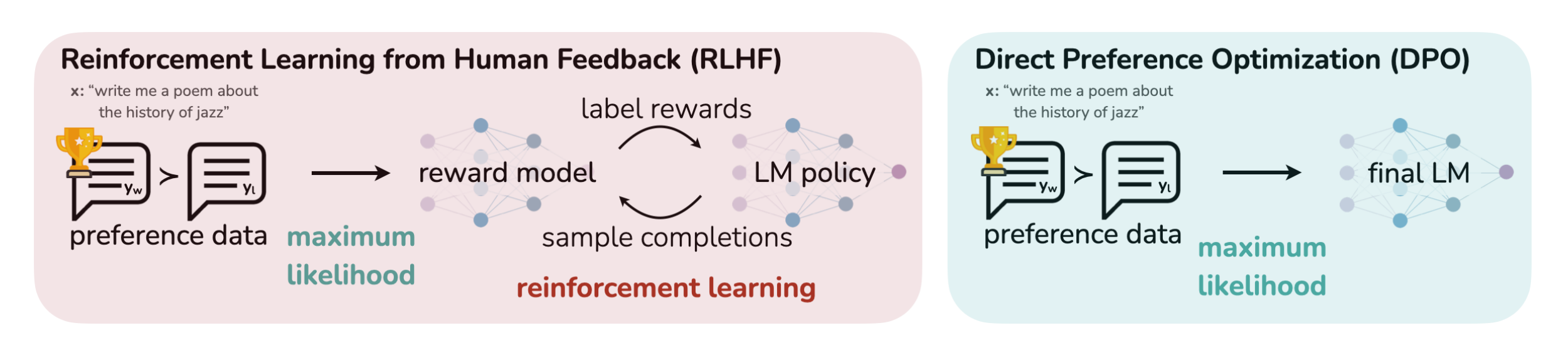
- RLHF将奖励模型拟合到人类偏好数据集上,然后使用RL方法比如PPO算法优化语言模型的策略,以输出可以获得高奖励的responses(同时不会偏离原始SFT模型太远)
RLHF methods fita reward model to a dataset of human preferences and then use RL to optimize a language model policy to produce responses assigned high reward without drifting excessively far from the original model.
虽然RLHF产生的模型具有令人印象深刻的会话和编码能力,但RLHF比监督学习复杂得多,其涉及训练多个LM和在训练循环中从LM策略中采样(4个模型,涉及到经验数据的采集,以及策略的迭代和价值的迭代,如果不太熟或忘了,请参见《ChatGPT技术原理解析》),从而产生大量的计算成本
While RLHF produces models with impressive conversational and coding abilities, the RLHFpipeline is considerably more complex than supervised learning, involving training multiple LMs andsampling from the LM policy in the loop of training, incurring significant computational costs. - 相比之下,DPO通过简单的分类目标直接优化最满足偏好的策略,而没有明确的奖励函数或RL
DPO directly optimizes for the policy best satisfying the preferences with a simple classification objective, without an explicit reward function or RL
更具体而言,DPO的本质在于
- 增加了被首选的response相对不被首选的response的对数概率,但它包含了一个动态的、每个示例的重要性权重,以防止我们发现的简单概率比目标发生的模型退化
与现有算法一样,DPO依赖于理论偏好模型,衡量给定的奖励函数与经验偏好数据的一致性
the DPO update increases the relative log probability of preferred to dispreferred responses, but it incorporates a dynamic, per-example importance weight that preventsthe model degeneration that we find occurs with a naive probability ratio objective
Like existingalgorithms, DPO relies on a the oretical preference model that measures how well a given reward function aligns with empirical preference data. - 然而,虽然现有方法比如ChatGPT通过定义偏好损失来训练奖励模型,然后在奖励模型的指引下训练策略,但DPO使用变量的变化来直接将偏好损失定义为策略的函数,给定人类对模型响应的偏好数据集,DPO因此可以使用简单的二元交叉熵目标优化策略,而无需在训练期间明确学习奖励函数或从策略中采样
However, while existing methods use the preference model to define a preference loss to train a reward model and then train a policy that optimizes the learned reward model, DPO uses a change of variables to definethe preference loss as a function of the policy directly. Given a dataset of human preferences overmodel responses, DPO can therefore optimize a policy using a simple binary cross entropy objective,without explicitly learning a reward function or sampling from the policy during training.
第二部分 Zephyr 7B的训练模式:从AI奖励到DPO
// 待更
第三部分 Claude的RAILF
// 待更
相关文章:
RLHF的替代算法之DPO原理解析:从Zephyr的DPO到Claude的RAILF
前言 本文的成就是一个点顺着一个点而来的,成文过程颇有意思 首先,如上文所说,我司正在做三大LLM项目,其中一个是论文审稿GPT第二版,在模型选型的时候,关注到了Mistral 7B(其背后的公司Mistral AI号称欧洲…...
U盘显示无媒体怎么办?方法很简单
当出现U盘无媒体情况时,您可以在磁盘管理工具中看到一个空白的磁盘框,并且在文件资源管理器中不会显示出来。那么,导致这种问题的原因是什么呢?我们又该怎么解决呢? 导致U盘无媒体的原因是什么? 当您遇到上…...
进销存管理系统如何提高供应链效率?
供应链和进销存系统之间有着密切的联系。进销存系统是供应链管理的一部分,用于跟踪和管理产品的采购、库存和销售。进销存管理是供应链管理的核心流程之一,它有助于提高效率、降低成本、增加盈利,同时确保客户满意度,这对于企业的…...

用AI魔法打败AI魔法
全文均为AI创作。 此为内容创作模板,在发布之前请将不必要的内容删除当前,AI技术的广泛应用为社会公众提供了个性化智能化的信息服务,也给网络诈骗带来可乘之机,如不法分子通过面部替换语音合成等方式制作虚假图像、音频、视频仿…...

Java 中的final:不可变性的魔法之旅
🎏:你只管努力,剩下的交给时间 🏠 :小破站 Java 中的final:不可变性的魔法之旅 前言第一:了解final变量第二:final方法第三:final类第四:final参数第五&#…...

Alfred 5 for mac(最好用的苹果mac效率软件)中文最新版
Alfred 5 Mac是一款非常实用的工具,它可以帮助用户更加高效地使用Mac电脑。用户可以学会使用快捷键、全局搜索、快速启动应用程序、使用系统维护工具、快速复制粘贴文本以及自定义设置等功能,以提高工作效率。 Alfred for Mac 的一些主要功能包括&#…...

常见的Python解释器,你了解多少?
Python,作为一种解释型编程语言,它的运行过程也遵循“程序源码—>解释器(字节码)—>虚拟机(可执行文件)”的流程。 在编写Python程序时,是在扩展名为.py的文件中进行编写,.py…...
在 Python 中使用 Selenium 按文本查找元素
我们将通过示例介绍在Python中使用selenium通过文本查找元素的方法。 在 Python 中使用 Selenium 按文本查找元素 软件测试是检查应用程序是否满足用户需求的技术。 该技术有助于使应用程序成为无错误的应用程序。 软件测试可以手动完成,也可以通过某些软件完成。…...
被隐藏或遮挡如何恢复?)
【Notepad++】搜索返回窗口(find result)被隐藏或遮挡如何恢复?
Notepad 搜索返回窗口被隐藏或遮挡如何恢复 1:F72:F12恢复之后可以多看一些Notepad中快捷键的使用,以备不时之需。 1:F7 打开任意文件,搜索任意内容,按F7,焦点切换到Find result。 按AltSpace,出现小窗口点击"移动…...

应用软件安全编程--05预防 XML 注入
如果用户有能力使用结构化XML 文档作为输入,那么他能够通过在数据字段中插入 XML 标签来 重写这个 XML 文档的内容。 XML 解析器会将这些标签按照正常标签进行解析。下面是一段在线商 店的 XML 代码,主要用于查询后台数据库。 <item)<descri…...

JavaEE-博客系统3(功能设计)
本部分内容为:实现登录功能;强制要求用户登录;实现显示用户信息;退出登录;发布博客 该部分的后端代码如下: Overrideprotected void doPost(HttpServletRequest req, HttpServletResponse resp) throws Ser…...
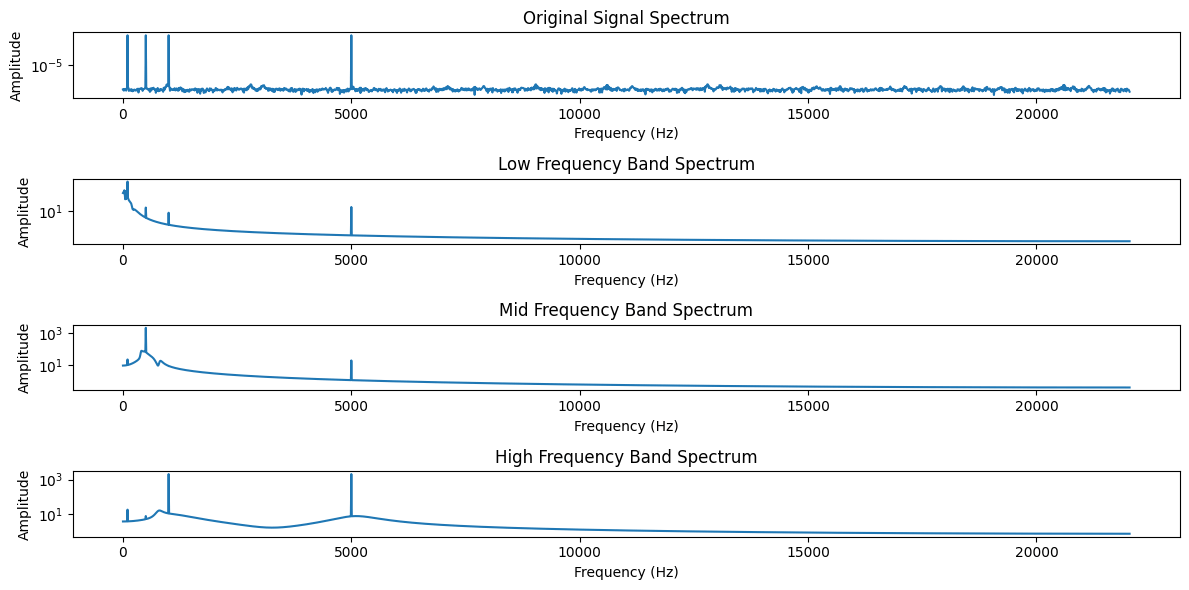
椭圆滤波器
之前的文章 信号去噪 中列出了7种常用的信号去噪算法,对于后两种算法——深度学习和奇异值分解(SVD),我现在也不太理解,就先不写了。 很多朋友留言又提了一些算法,今天一起来聊聊椭圆滤波器。 椭圆滤波器(Elliptic F…...
Mac 下安装golang环境
一、下载安装包 安装包下载地址 下载完成,直接继续----->下一步到结束即可安装成功; 安装成功之后,验证一下; go version二、配置环境变量 终端输入vim ~/.zshrc进入配置文件,输入i进行编辑 打开的不管是空文本…...

前端面试大纲
一、CSS 1.说一下CSS的盒模型。 在HTML页面中的所有元素都可以看成是一个盒子 盒子的组成:内容content、内边距padding、边框border、外边距margin 盒模型的类型: 标准盒模型 margin border padding content IE盒模型 margin content(border padd…...
是一种用于在汽车和工业领域中进行通信的串行总线系统(附加案例))
CAN(Controller Area Network)是一种用于在汽车和工业领域中进行通信的串行总线系统(附加案例)
CAN(Controller Area Network)是一种用于在汽车和工业领域中进行通信的串行总线系统。它是一种高可靠性、多主机、多节点通信协议,主要用于实时控制和数据传输。 CAN数据是指在CAN总线上通过CAN协议进行通信传输的数据。CAN总线上的数据被分…...

代码随想录day53|1143.最长公共子序列、 1035.不相交的线、 53. 最大子序和
1143.最长公共子序列 dp[i][j]:长度为[0, i - 1]的字符串text1与长度为[0, j - 1]的字符串text2的最长公共子序列为dp[i][j] 因此是if(nums1[i-1] nums2[j-1]) 1035.不相交的线 和上一题一样 53. 最大子序和 int result dp[0]; 不是0,因为dp[i]有…...
xilinx fpga ddr mig axi
硬件 参考: https://zhuanlan.zhihu.com/p/97491454 https://blog.csdn.net/qq_22222449/article/details/106492469 https://zhuanlan.zhihu.com/p/26327347 https://zhuanlan.zhihu.com/p/582524766 包括野火、正点原子的资料 一片内存是 1Gbit 128MByte 16bit …...

《golang设计模式》第三部分·行为型模式-04-迭代器模式(Iterator)
文章目录 1. 概念1.1 角色1.2 类图 2. 代码示例2.1 需求2.2 代码2.3 类图 1. 概念 迭代器(Iterator)能够在不暴露聚合体内部表示的情况下,向客户端提供遍历聚合元素的方法。 1.1 角色 InterfaceAggregate(抽象聚合)…...

python加上ffmpeg实现音频分割
前言: 这是一个系列的文章,主要是使用python加上ffmpeg来对音视频文件进行处理,包括音频播放、音频格式转换、音频文件分割、视频播放等。 系列文章链接: 链接1: python使用ffmpeg来制作音频格式转换工具(优化版) 链接2:<Python>PyQt5+ffmpeg,简单视频播放器的编写(…...

LLM之Prompt(一):5个Prompt高效方法在文心一言3.5的测试对比
在Effective Prompt: 编写高质量Prompt的14个有效方法文中我们了解了14个编写Prompt的方法(非常感谢原作者),那么这些Prompt在具体大模型中的效果如何呢?本文以百度文心一言3.5版本大模型在其中5个方法上做个测试对比。 第1条&am…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

别再盲调temperature=0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单
更多请点击: https://intelliparadigm.com 第一章:别再盲调temperature0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单 DeepSeek-R1/VL 等开源大模型在实际部署中,仅靠调节 temperature 往往收效甚…...
运营管理与服务保障平台建设方案)
低空旅游观光与低空通勤(eVTOL)运营管理与服务保障平台建设方案
本方案旨在为eVTOL载具构建集运营管理、空中交通管制、安全保障与乘客服务于一体的数字化平台。通过微服务架构、5G-A融合感知、空域网格化与零信任安全等核心技术,解决高密度飞行中的资源调度与安全冲突问题。目标实现毫秒级冲突解算与15分钟内快速周转,…...
)
DeepSeek代码审查能力白皮书(2024企业级实测报告)
更多请点击: https://kaifayun.com 第一章:DeepSeek代码审查能力白皮书(2024企业级实测报告)概述 本报告基于2024年Q1至Q3期间,面向金融、电信与云原生三大垂直行业的17家头部企业客户开展的深度实测,覆盖…...

浏览器端音频解密技术:如何让加密音乐在本地重获新生?
浏览器端音频解密技术:如何让加密音乐在本地重获新生? 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目…...

机器学习在宇宙中微子快味转换检测中的实践:从逻辑回归到天体物理模拟集成
1. 项目概述:当机器学习遇见宇宙深处的“幽灵粒子” 在宇宙最狂暴的舞台——核心坍缩超新星(CCSN)和双中子星并合(NSM)事件的中心,上演着一场肉眼无法观测的微观物理盛宴。这里的主角是中微子,这…...