【Spark分布式内存计算框架——Spark Streaming】5. DStream(上)
3. DStream
SparkStreaming模块将流式数据封装的数据结构:DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种Spark算子操作后的结果数据流。
3.1 DStream 是什么
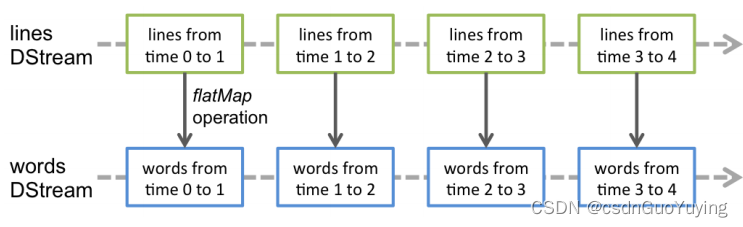
离散数据流(DStream)是Spark Streaming最基本的抽象。它代表了一种连续的数据流,要么从某种数据源提取数据,要么从其他数据流映射转换而来。DStream内部是由一系列连续的RDD组成的,每个RDD都包含了特定时间间隔内的一批数据,如下图所示:

DStream本质上是一个:一系列时间上连续的RDD(Seq[RDD]),DStream = Seq[RDD]。
DStream = Seq[RDD]
DStream相当于一个序列(集合),里面存储的数据类型为RDD(Streaming按照时间间隔划分流式数据)
对DStream的数据进行操作也是按照RDD为单位进行的。
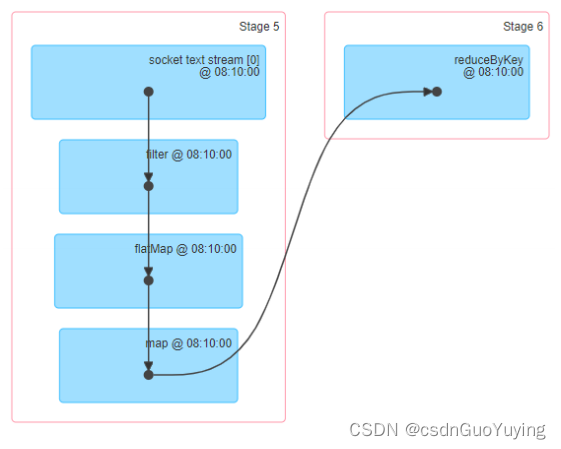
通过WEB UI界面可知,对DStream调用函数操作,底层就是对RDD进行操作,发现很多时候DStream中函数与RDD中函数一样的。
DStream中每批次数据RDD在处理时,各个RDD之间存在依赖关系,DStream直接也有依赖关系,RDD具有容错性,那么DStream也具有容错性。
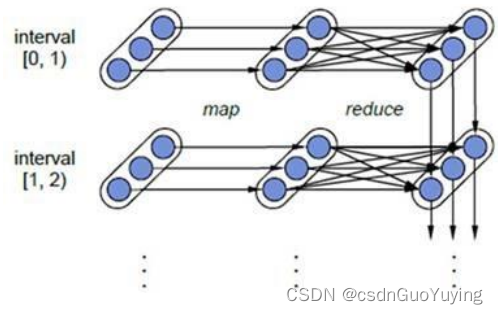
上图相关说明:
1)、每一个椭圆形表示一个RDD
2)、椭圆形中的每个圆形代表一个RDD中的一个Partition分区
3)、每一列的多个RDD表示一个DStream(图中有三列所以有三个DStream)
4)、每一行最后一个RDD则表示每一个Batch Size所产生的中间结果RDD
Spark Streaming将流式计算分解成多个Spark Job,对于每一时间段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程。
3.2 DStream Operations
DStream类似RDD,里面包含很多函数,进行数据处理和输出操作,主要分为两大类:
- DStream#Transformations:将一个DStream转换为另一个DStream
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#transformations-on-dstreams - DStream#Output Operations:将DStream中每批次RDD处理结果resultRDD输出
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#output-operations-on-dstreams
函数概述
DStream中包含很多函数,大多数与RDD中函数类似,主要分为两种类型:
其一:转换函数【Transformation函数】
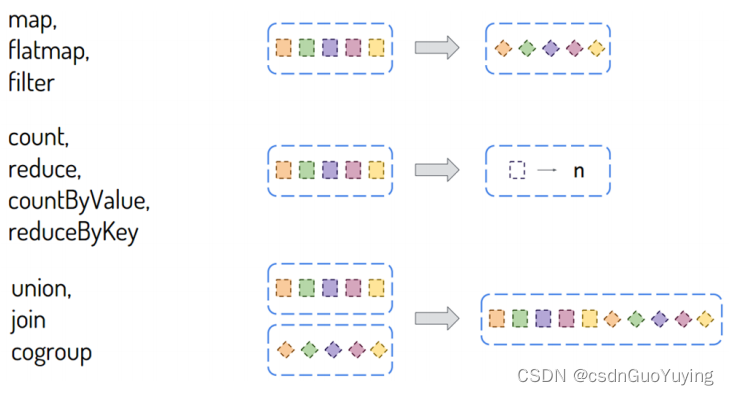
DStream中还有一些特殊函数,针对特定类型应用使用的函数,比如updateStateByKey状态函数、window窗口函数等,后续具体结合案例讲解。
其二:输出函数【Output函数】
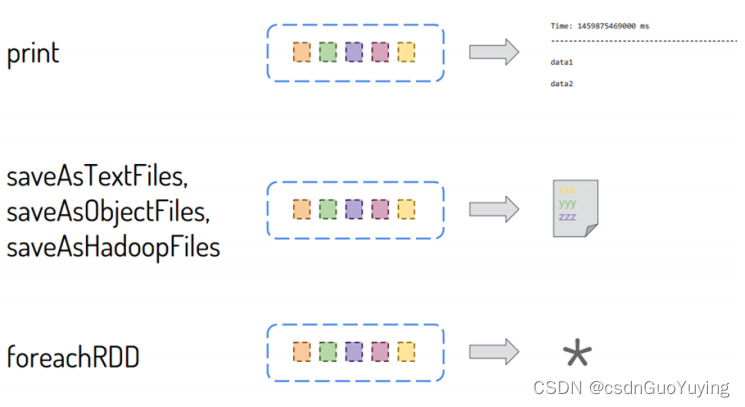
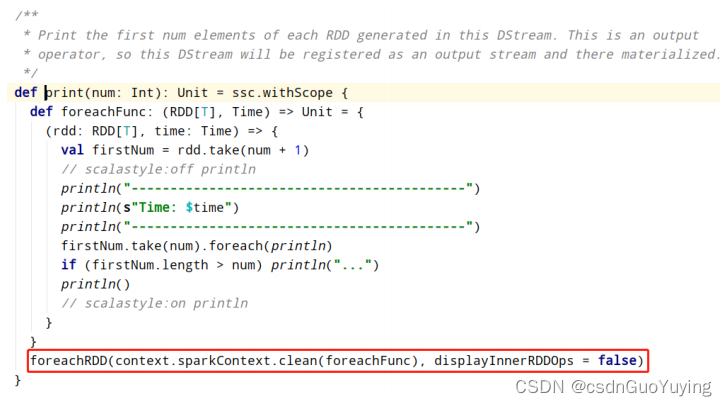
DStream中每批次结果RDD输出使用foreachRDD函数,前面使用的print函数底层也是调用foreachRDD函数,截图如下所示:
在DStream中有两个重要的函数,都是针对每批次数据RDD进行操作的,更加接近底层,性能更好,强烈推荐使用:
- 转换函数transform:将一个DStream转换为另外一个DStream;
- 输出函数foreachRDD:将一个DStream输出到外部存储系统;
在SparkStreaming企业实际开发中,建议:能对RDD操作的就不要对DStream操作,当调用DStream中某个函数在RDD中也存在,使用针对RDD操作。
转换函数:transform
通过源码认识transform函数,有两个方法重载,声明如下:

接下来使用transform函数,修改词频统计程序,具体代码如下:
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 基于IDEA集成开发环境,编程实现从TCP Socket实时读取流式数据,对每批次中数据进行词频统计。
*/
object StreamingTransformRDD {
def main(args: Array[String]): Unit = {
// 1. 构建StreamingContext流式上下文实例对象
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// b.创建流式上下文对象, 传递SparkConf对象,TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回
context
}
// 2. 从数据源端读取数据,此处是TCP Socket读取数据
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream(
"node1.itcast.cn", //
9999, //
// TODO: 设置Block存储级别为先内存,不足磁盘,副本为1
storageLevel = StorageLevel.MEMORY_AND_DISK
)
// TODO: 3. 对每批次的数据进行词频统计
/*
transform表示对DStream中每批次数据RDD进行操作
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// TODO: 在DStream中,能对RDD操作的不要对DStream操作。
val resultDStream: DStream[(String, Int)] = inputDStream.transform(rdd => {
val resultRDD: RDD[(String, Int)] = rdd
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
resultRDD
})
// 4. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.print(10)
// 5. 对于流式应用来说,需要启动应用
ssc.start()
// 流式应用启动以后,正常情况一直运行(接收数据、处理数据和输出数据),除非人为终止程序或者程序异常停止
ssc.awaitTermination()
// 关闭流式应用(参数一:是否关闭SparkContext,参数二:是否优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
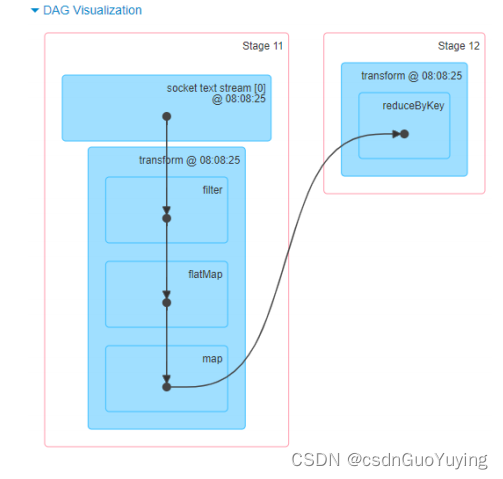
查看WEB UI监控中每批次Batch数据执行Job的DAG图,直接显示针对RDD进行操作。
输出函数:foreachRDD
foreachRDD函数属于将DStream中结果数据RDD输出的操作,类似transform函数,针对每批次RDD数据操作,源码声明如下:

继续修改词频统计代码,自定义输出数据,具体代码如下:
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
/**
* 基于IDEA集成开发环境,编程实现从TCP Socket实时读取流式数据,对每批次中数据进行词频统计。
*/
object StreamingOutputRDD {
def main(args: Array[String]): Unit = {
// 1. 构建StreamingContext流式上下文实例对象
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// TODO:设置数据输出文件系统的算法版本为2
.set("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2")
// b.创建流式上下文对象, 传递SparkConf对象,TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回
context
}
// 2. 从数据源端读取数据,此处是TCP Socket读取数据
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream(
"node1.itcast.cn", //
9999, //
// TODO: 设置Block存储级别为先内存,不足磁盘,副本为1
storageLevel = StorageLevel.MEMORY_AND_DISK
)
// 3. 对每批次的数据进行词频统计
/*
transform表示对DStream中每批次数据RDD进行操作
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// TODO: 在DStream中,能对RDD操作的不要对DStream操作。
val resultDStream: DStream[(String, Int)] = inputDStream.transform(rdd => {
val resultRDD: RDD[(String, Int)] = rdd
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
resultRDD
})
// TODO: 4. 将结果数据输出 -> 将每批次的数据处理以后输出
/*
对DStream中每批次结果RDD数据进行输出操作
def foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit
其中Time就是每批次BatchTime,Long类型数据, 转换格式:2020/05/10 16:53:25
*/
resultDStream.foreachRDD{ (rdd, time) =>
// 使用lang3包下FastDateFormat日期格式类,属于线程安全的
val batchTime: String = FastDateFormat.getInstance("yyyyMMddHHmmss")
.format(new Date(time.milliseconds))
println("-------------------------------------------")
println(s"Time: $batchTime")
println("-------------------------------------------")
// TODO: 先判断RDD是否有数据,有数据在输出
if(!rdd.isEmpty()){
// 对于结果RDD输出,需要考虑降低分区数目
val resultRDD = rdd.coalesce(1)
// 对分区数据操作
resultRDD.foreachPartition{iter =>iter.foreach(item => println(item))}
// 保存数据至HDFS文件
resultRDD.saveAsTextFile(s"datas/streaming/wc-output-${batchTime}")
}
}
// 5. 对于流式应用来说,需要启动应用
ssc.start()
// 流式应用启动以后,正常情况一直运行(接收数据、处理数据和输出数据),除非人为终止程序或者程序异常停止
ssc.awaitTermination()
// 关闭流式应用(参数一:是否关闭SparkContext,参数二:是否优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
将SparkStreaming处理结果RDD数据保存到MySQL数据库或者HBase表中,代码该如何编写呢?
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#design-patterns-for-using-foreachrdd
伪代码如下所示:
// 数据输出,将分析处理结果数据输出到MySQL表
resultDStream.foreachRDD{(rdd, time) =>
// 将BatchTime转换:2019/10/10 14:59:35
val batchTime = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss").format(time.milliseconds)
println("-------------------------------------------")
println(s"Time: $batchTime")
println("-------------------------------------------")
// TODO:首先判断每批次结果RDD是否有值,有值才输出, 必须判断,提升性能
if(!rdd.isEmpty()){
rdd.foreachPartition{iter =>
// 第一步、获取连接:从数据库连接池中获取连接
val conn: Connection = null
// 第二步、保存分区数据到MySQL表
iter.foreach{item =>// TODO: 使用conn将数据保存到MySQL表中
}
// 第三步、关闭连接:将连接放入到连接池中
if(null != conn) conn.close()
}
}
}
将每批次数据统计结果RDD保存到HDFS文件中,代码如下:
resultDStream.foreachRDD{(rdd, time) =>
// 将BatchTime转换:2019/10/10 14:59:35
val batchTime = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss").format(time.milliseconds)
println("-------------------------------------------")
println(s"Time: $batchTime")
println("-------------------------------------------")
// TODO:首先判断每批次结果RDD是否有值,有值才输出, 必须判断,提升性能
if(!rdd.isEmpty()){
// 注意:将Streaming结果数据RDD保存文件中时,最好考虑降低分区数目
rdd.coalesce(1).saveAsTextFile(s"datas/spark/streaming/wc-${time.milliseconds}")
}
}
相关文章:
【Spark分布式内存计算框架——Spark Streaming】5. DStream(上)
3. DStream SparkStreaming模块将流式数据封装的数据结构:DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种Spark算子操作后的结果数据流。 3.1 DStream 是什么…...
Spring系列-9 Async注解使用与原理
背景: 本文作为Spring系列的第九篇,介绍Async注解的使用、注意事项和实现原理,原理部分会结合Spring框架代码进行。 本文可以和Spring系列-8 AOP原理进行比较阅读 1.使用方式 Async一般注解在方法上,用于实现方法的异步…...

Python自动化测试实战篇(6)用PO分层模式及思想,优化unittest+ddt+yaml+request登录接口自动化测试
这些是之前的文章,里面有一些基础的知识点在前面由于前面已经有写过,所以这一篇就不再详细对之前的内容进行描述 Python自动化测试实战篇(1)读取xlsx中账户密码,unittest框架实现通过requests接口post登录网站请求&…...

Linux 进程:父子进程
目录一、了解子进程二、创建子进程1.创建子进程2.区分父子进程三、理解子进程四、创建子进程的意义进程就是运行中的应用程序,如果一个程序较为庞大,我们可以给这个程序创建多个进程,每个进程负责一部分代码的运行。 A进程如果创建了B进程&am…...
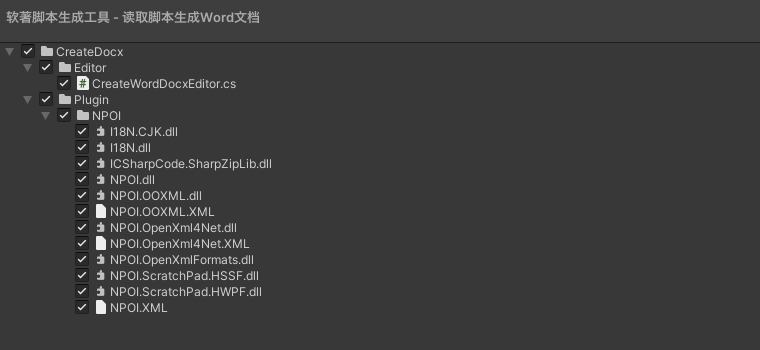
Unity 之 实现读取代码写进Word文档功能实现 -- 软著脚本生成工具
Unity 之 实现读取代码写进Word文档功能前言一,实现步骤1.1 逻辑梳理1.2 用到工具二,实现读写文件2.1 读取目录相关2.2 读写文件三,编辑器拓展3.1 编辑器拓展介绍3.2 实现界面可视化四,源码分享4.1 工具目录4.2 完整代码前言 之所…...
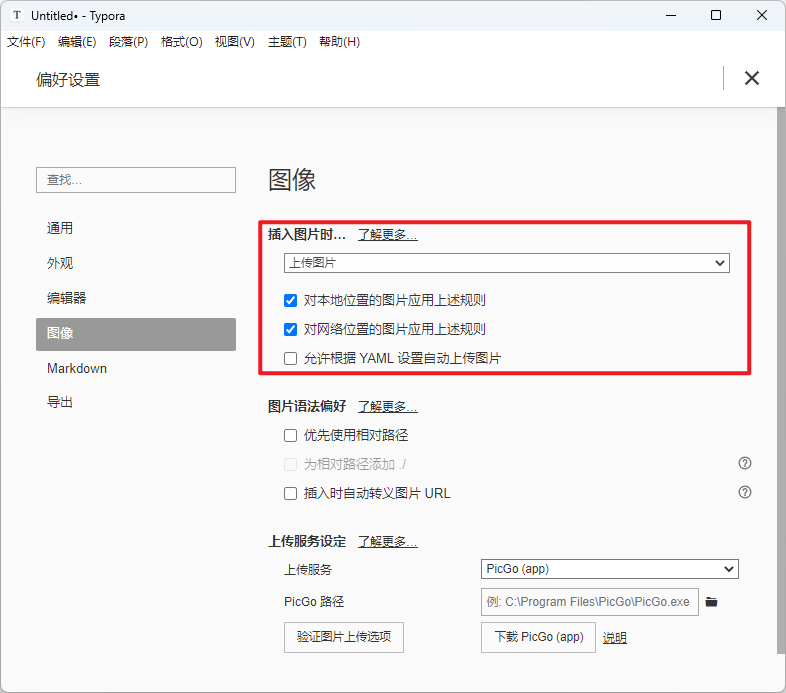
Typora图床配置:Typora + PicGo + 阿里云OSS
文章目录一、前景提要二、相关链接三、搭建步骤1. 购买阿里云对象存储OSS2. 对象存储OSS:创建Bucket3. 阿里云:添加OSS访问用户及权限4. 安装Typora5. 配置PicGo方法一:使用PicGo-Core (Command line)方法二:使用PicGo(app)6. 最后…...

二进制搭建以太坊2.0节点-2023最新详细版文档
文章目录 一、配置 JWT 认证二、部署执行节点geth2.1 下载geth二进制文件2.2 geth节点启动三、部署共识节点Prysm3.1 下载Prysm脚本3.2 Prysm容器生成四、检查节点是否同步完成4.1 检查geth执行节点4.2 检查prysm共识节点4.3 geth常用命令五、节点同步详细说明5.1 启动时日志5.…...
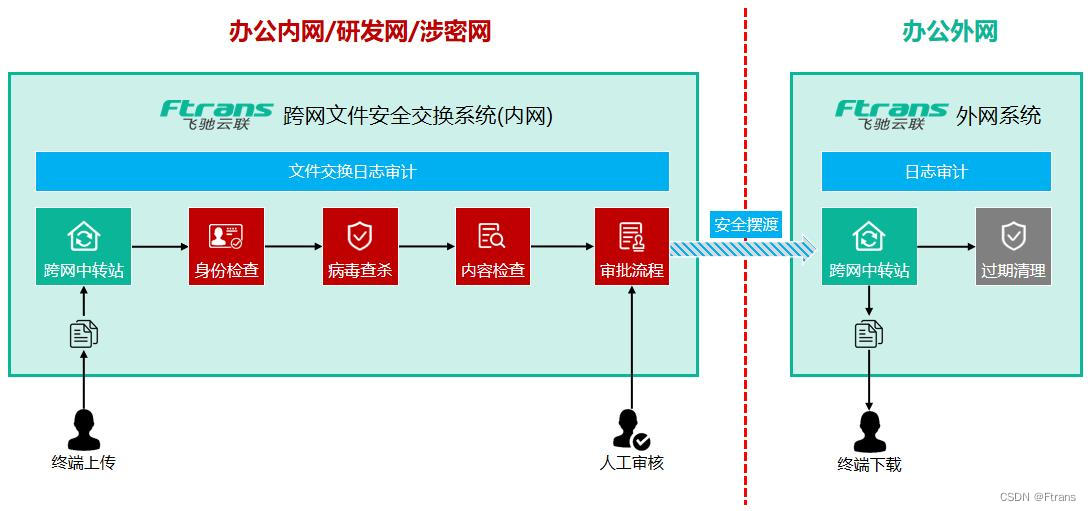
如何简化跨网络安全域的文件发送流程,大幅降低IT人员工作量?
为什么要做安全域的隔离? 随着企业数字化转型的逐步深入,企业投入了大量资源进行信息系统建设,信息化程度日益提升。在这一过程中,企业也越来越重视核心数据资产的保护,数据资产的安全防护成为企业面临的重大挑战。 …...

带你深入了解c语言指针后续
前言 🎈个人主页:🎈 :✨✨✨初阶牛✨✨✨ 🐻推荐专栏: 🍔🍟🌯 c语言进阶 🔑个人信条: 🌵知行合一 🍉本篇简介:>:介绍c语言中有关指针更深层的知识. 金句分享: ✨在该…...
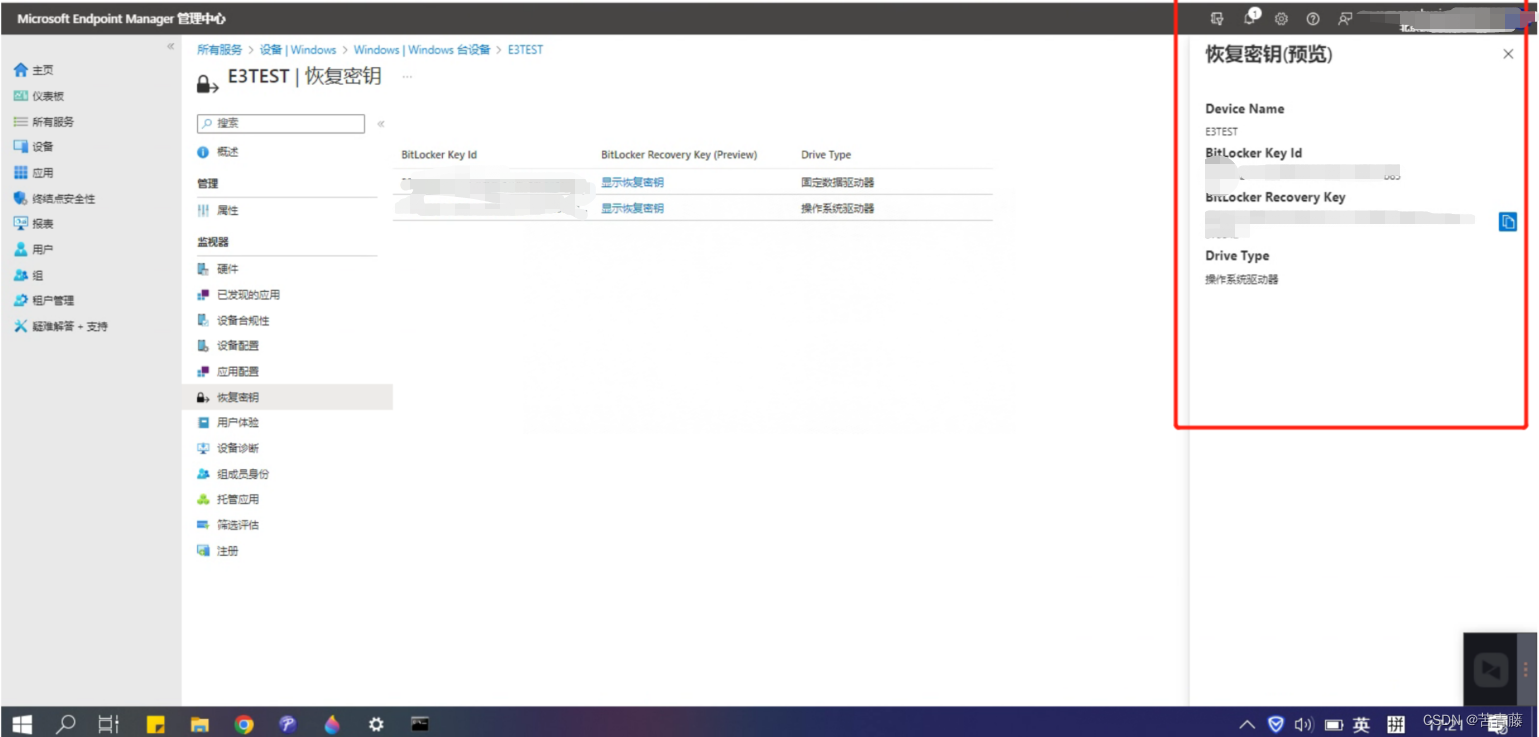
借助Intune无感知开启Bitlocker
希望使用 Intune 部署 BitLocker,但不知道从哪里开始?这是人们最开始使用 Intune 时最常见的问题之一。在本博客中,你将了解有关使用 Intune 管理 BitLocker 的所有信息,包括建议的设置、BitLocker CSP 在客户端上的工作方式&…...

零基础该如何转行Python工程师?学习路线是什么?
最近1年的主要学习时间,都投资到了 python 数据分析和数据挖掘上面来了,虽然经验并不是十分丰富,但希望也能把自己的经验分享下,最近也好多朋友给我留言,和我聊天,问我python该如何学习,才能少走…...
Go项目(商品微服务-1)
文章目录简介建表protohandler商品小结简介 商品微服务主要在于表的设计,建哪些表?表之间的关系是怎样的? 主要代码就是 CURD表和字段的设计是一个比较有挑战性的工作,比较难说清楚,也需要经验的积累,这里…...

机器学习——集成学习
引言 集成学习:让机器学习效果更好,单个不行,群殴走起。 分类 1. Bagging:训练多个分类器取平均(m代表树的个数)。 2.Boosting(提升算法):从弱学习器开始加,通过加权来进行训练。…...
VS编译系统 实用调试技巧
目录什么是bug?调试是什么?有多重要?debug和release的介绍windows环境调试介绍、一些调试实例如何写出(易于调试)的代码编程常见的错误什么是bug?其实bug在英文翻译中有表示臭虫的含义,因为第一次被发现的导致计算机…...

【华为OD机试模拟题】用 C++ 实现 - GPU 调度(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 去重求和(2023.Q1) 文章目录 最近更新的博客使用说明GPU 调度题目输入输出示例一输入输出说明示例二输入输出说明Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。...

腾讯前端必会react面试题合集
React-Router的路由有几种模式? React-Router 支持使用 hash(对应 HashRouter)和 browser(对应 BrowserRouter) 两种路由规则, react-router-dom 提供了 BrowserRouter 和 HashRouter 两个组件来实现应用的…...
Linux搭建SVN服务器,并内网穿透实现公网远程访问
文章目录1. Ubuntu安装SVN服务2. 修改配置文件2.1 修改svnserve.conf文件2.2 修改passwd文件2.3 修改authz文件3. 启动svn服务4. 内网穿透4.1 安装cpolar内网穿透4.2 创建隧道映射本地端口5. 测试公网访问6. 配置固定公网TCP端口地址6.1 保留一个固定的公网TCP端口地址6.2 配置…...

C++STL之list的模拟实现
目录 一.list准备 二. iterator迭代器 1._list_iterator 2.begin()、end() 3.const_begin()、const_end() 4.!&& 5. && -- 6.operator* 7.operator-> 三.Modify(修改) 1.insert() 2.erase() 3.push_back() && push_front() 4.pop_bac…...

为什么硬件性能监控很重要
当今的混合网络环境平衡了分布式网络和现代技术的实施。但它们并不缺少一个核心组件:服务器。保持网络正常运行时间归结为监控和管理导致网络停机的因素。极有可能导致性能异常的此类因素之一是硬件。使用硬件监控器监控网络硬件已成为一项关键需求。 硬件监视器是…...

HTTP缓存
HTTP缓存HTTP缓存引发的一个问题HTTP缓存的作用HTTP缓存的分类强制缓存协商缓存(解决强缓存下资源不更新问题)缓存策略HTTP缓存引发的一个问题 有一次在开发移动端H5项目,UI提了几个UI问题,经过样式调试,android上没有…...

量子退火在锂离子电池材料优化中的应用与原理
1. 量子退火技术原理与材料优化应用概述量子退火(Quantum Annealing)是一种基于量子力学原理的优化算法,它通过模拟量子系统的绝热演化过程来寻找复杂问题的全局最优解。与传统模拟退火算法相比,量子退火利用量子隧穿效应而非热涨…...

ARM内存访问指令LDRB与LDREX详解及应用
1. ARM内存访问指令概述在嵌入式系统开发中,对内存的高效访问是保证程序性能的关键。ARM架构提供了丰富的内存访问指令集,其中LDRB和LDREX是两种具有代表性的指令。LDRB(Load Register Byte)用于从内存加载字节数据,而…...

ModTheSpire终极指南:为《杀戮尖塔》构建安全高效的模组生态
ModTheSpire终极指南:为《杀戮尖塔》构建安全高效的模组生态 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire 在游戏模组开发领域,安全性与扩展性往往难以兼得。…...

大恒相机USB3驱动冲突排查:设备管理器可见但软件无法识别的深度解析
1. 问题现象与初步排查 最近在调试大恒USB3相机时遇到了一个典型问题:设备管理器里能正常识别相机设备,但打开配套软件GalaxyView却死活找不到相机。这种"看得见摸不着"的情况在工业视觉开发中特别常见,尤其是当你同时安装了多个视…...

信息时代个人知识管理:从碎片化信息到结构化洞察的实践指南
1. 信息海洋中的航行:从碎片到洞察我们正漂浮在一片前所未有的信息海洋里。每天,无数的邮件、通知、文章、帖子像潮水般涌来,我们则像一个个拾贝者,快乐地捡拾着那些零碎的趣闻和知识的金块。这种感觉很奇妙,不是吗&am…...

从锡疫到无铅焊料失效:材料环境可靠性设计实战解析
1. 从拿破仑的纽扣说起:材料失效背后的工程警示在电子工程领域,我们每天都在与材料打交道。从PCB上的焊点,到芯片内部的金属互连,再到外壳的塑料,材料的可靠性直接决定了产品的成败。几年前,当整个行业因Ro…...

设计器模版底图,一直渲染错误,是因为第一张图变形后内存中图片数据被改了,其他尺码一直错误
这其实是你们现在更需要的组合:不是只看 decode(),而是再确认“这次 decode 对应的还是当前这张图”。再确认“这次 decode 对应的还是当前这张图” 是怎么做到的,详细列举代码我直接从现在这次改动的代码里,把"确认图片身份…...

如何让老旧安卓电视焕发新生:mytv-android实现流畅播放体验的完整指南
如何让老旧安卓电视焕发新生:mytv-android实现流畅播放体验的完整指南 【免费下载链接】mytv-android 使用Android原生开发的视频播放软件 项目地址: https://gitcode.com/gh_mirrors/my/mytv-android 你是否还在为家中那台反应迟钝、启动缓慢的旧电视而烦恼…...

Altium Designer 系统偏好设置全解析:从新手到高手的效率跃迁
1. Altium Designer系统偏好设置的重要性 刚接触Altium Designer时,我和大多数新手一样,只关注画原理图、布局布线这些核心功能。直到有次看到同事操作,同样的操作他只用我三分之一的时间完成,我才意识到系统偏好设置的重要性。这…...
深度探秘:以一次文件打开操作为例)
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例 当我们在终端输入cat /etc/shadow时,系统背后究竟发生了什么?这个看似简单的操作,实际上触发了一系列精妙的安全检查机制。本文将带您深入Linux内…...