计算机毕设 基于大数据的抖音短视频数据分析与可视化 - python 大数据 可视化
文章目录
- 0 前言
- 1 课题背景
- 2 数据清洗
- 3 数据可视化
- 地区-用户
- 观看时间
- 分界线
- 每周观看
- 观看路径
- 发布地点
- 视频时长
- 整体点赞、完播
- 4 进阶分析
- 相关性分析
- 留存率
- 5 深度分析
- 客户价值判断
- 5 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 基于大数据的抖音短视频数据分析与可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
1 课题背景
本项目是大数据—基于抖音用户数据集的可视化分析。抖音作为当下非常热门的短视频软件,其背后的数据有极高的探索价值。本项目根据1737312条用户行为数据,利用python工具进行由浅入深的内容分析,目的是挖掘其中各类信息,更好地进行内容优化、产品运营。
2 数据清洗
数据信息查看
简单看一下前5行数据,确定需要进一步预处理的内容:数据去重、删除没有意义的第一列,部分列格式转换、异常值检测。
# 读取数据
df = pd.read_csv('data.csv')
df.head()

df.info()

数据去重
无重复数据
print('去重前:',df.shape[0],'行数据')
print('去重后:',df.drop_duplicates().shape[0],'行数据')
缺失值查看
print(np.sum(df.isnull()))

变量类型转换
real_time 和 date 转为时间变量,id、城市编码转为字符串,并把小数点去掉
df['date'] = df['date'].astype('datetime64[ns]')
df['real_time'] = df['real_time'].astype('datetime64[ns]')
df['uid'] = df['uid'].astype('str')
df['user_city'] = df['user_city'].astype('str')
df['user_city'] = df['user_city'].apply(lambda x:x[:-2])
df['item_id'] = df['item_id'].astype('str')
df['author_id'] = df['author_id'].astype('str')
df['item_city'] = df['item_city'].astype('str')
df['item_city'] = df['item_city'].apply(lambda x:x[:-2])
df['music_id'] = df['music_id'].astype('str')
df['music_id'] = df['music_id'].apply(lambda x:x[:-2])
df.info()

3 数据可视化
基本信息的可视化,面向用户、创作者以及内容这三个维度进行,构建成分画像,便于更好地针对用户、创作者进行策略投放、内容推广与营销。
地区-用户
user_city_count = user_info.groupby(['user_city']).count().sort_values(by=['uid'],ascending=False)
x1 = list(user_city_count.index)
y1 = user_city_count['uid'].tolist()
len(y1)
不同地区用户数量分布图
#柱形图代码
chart = Bar()
chart.add_xaxis(x1)
chart.add_yaxis('地区使用人数', y1, color='#F6325A',itemstyle_opts={'barBorderRadius':[60, 60, 20, 20]},label_opts=opts.LabelOpts(position='top'))
chart.set_global_opts(datazoom_opts=opts.DataZoomOpts(range_start=0,range_end=5,orient='horizontal',type_='slider',is_zoom_lock=False, pos_left='1%' ),visualmap_opts=opts.VisualMapOpts(is_show = False,type_='opacity',range_opacity=[0.2, 1]),title_opts=opts.TitleOpts(title="不同地区用户数量分布图",pos_left='40%'),legend_opts=opts.LegendOpts(pos_right='10%',pos_top='2%'))
chart.render_notebook()
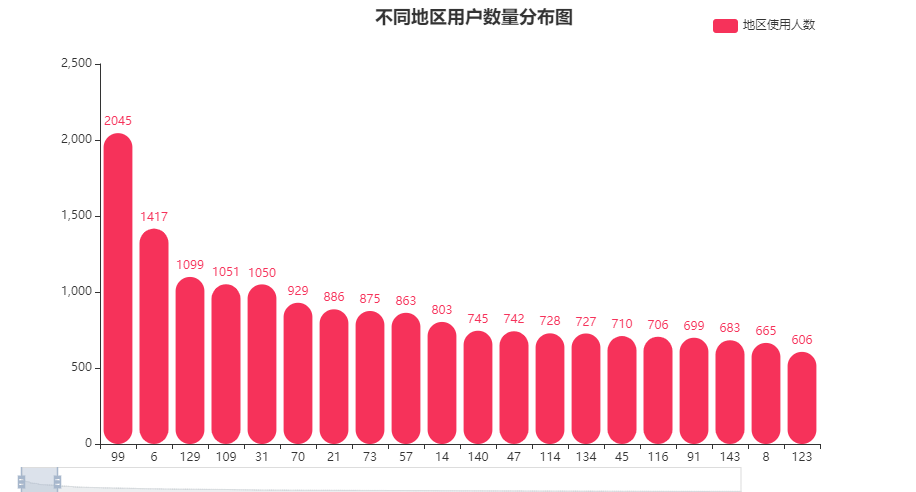
覆盖到了387个城市,其中编号为99的城市用户比较多超过2000人,6、129、109、31这几个城市的使用人数也超过了1000。
- 可以关注用户较多城市的特点,对产品受众有进一步的把握。
- 用户较少的城市可以视作流量洼地,考虑进行地推/用户-用户的推广,增加地区使用人数。
观看时间
h_num = round((df.groupby(['H']).count()['uid']/10000),1).to_list()
h = list(df.groupby(['H']).count().index)
不同时间观看数量分布图
chart = Line()
chart.add_xaxis(h)
chart.add_yaxis('观看数/(万)',h_num, areastyle_opts=opts.AreaStyleOpts(color = '#1AF5EF',opacity=0.3),itemstyle_opts=opts.ItemStyleOpts(color='black'),label_opts=opts.LabelOpts(font_size=12))
chart.set_global_opts(legend_opts=opts.LegendOpts(pos_right='10%',pos_top='2%'),title_opts=opts.TitleOpts(title="不时间观看数量分布图",pos_left='40%'),)
chart.render_notebook()
去掉时差后
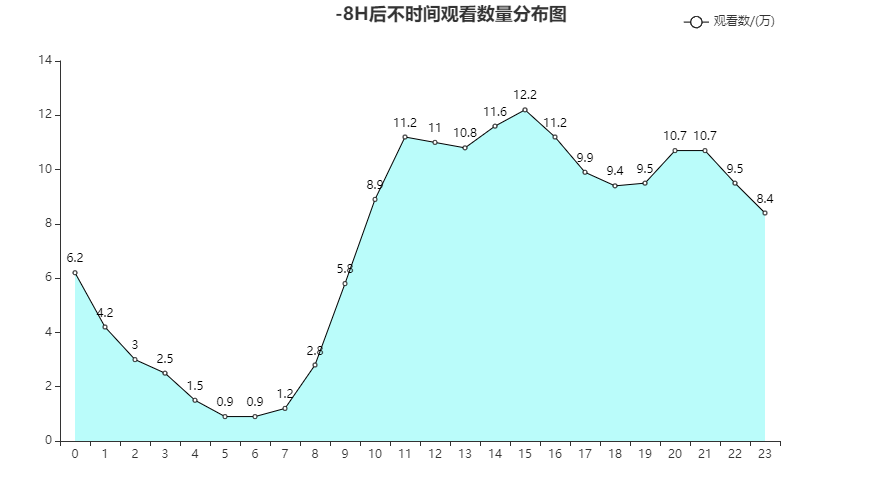
根据不同时间的观看视频数量来看,11-18,20-21,尤其是13-16是用户使用的高峰期
- 在用户高浏览的时段进行广告的投放,曝光量更高
- 在高峰段进行优质内容的推荐,效果会更好
分界线
点赞/完播率分布图
left = df.groupby(['H']).sum()[['finish','like']]
right = df.groupby(['H']).count()['uid']
per = pd.concat([left,right],axis=1)
per['finish_radio'] = round(per['finish']*100/per['uid'],2)
per['like_radio'] = round(per['like']*100/per['uid'],2)
x = list(df.groupby(['H']).count().index)
y1 = per['finish_radio'].to_list()
y2 = per['like_radio'].to_list()
#建立一个基础的图形
chart1 = Line()
chart1.add_xaxis(x)
chart1.add_yaxis('完播率/%',y1,is_smooth=True,label_opts=opts.LabelOpts(is_show=False),is_symbol_show = False,linestyle_opts=opts.LineStyleOpts(color='#F6325A',opacity=.7,curve=0,width=2,type_= 'solid' ))
chart1.set_global_opts(yaxis_opts = opts.AxisOpts(min_=25,max_=45))
chart1.extend_axis(yaxis=opts.AxisOpts(min_=0.4,max_=3))
#叠加折线图
chart2 = Line()
chart2.add_xaxis(x)
chart2.add_yaxis('点赞率/%',y2,yaxis_index=1,is_smooth=True,label_opts=opts.LabelOpts(is_show=False),is_symbol_show = False,linestyle_opts=opts.LineStyleOpts(color='#1AF5EF',opacity=.7,curve=0,width=2,type_= 'solid' ))
chart1.overlap(chart2)
chart1.set_global_opts(legend_opts=opts.LegendOpts(pos_right='10%',pos_top='2%'),title_opts=opts.TitleOpts(title="点赞/完播率分布图",pos_left='40%'),)chart1.render_notebook()
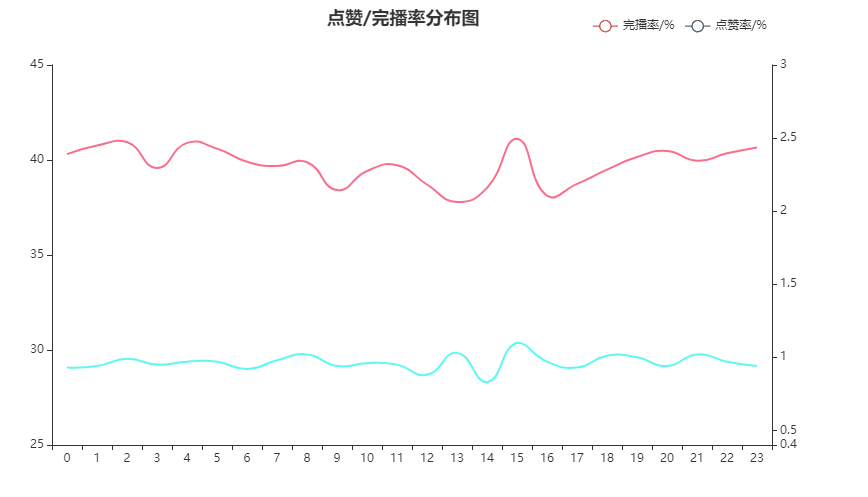
关注到点赞率和完播率,这两个与用户粘性、创作者收益有一定关系的指标。可以看到15点是两个指标的小高峰,2、4、20、23完播较高,8、13、18、20点赞率较高。但结合观看数量与时间段的分布图,大致猜测15点深度用户较多。
- 关注深度用户特点,思考如何增加普通用户的完播、点赞
每周观看
df['weekday'] = df['date'].dt.weekday
week = df.groupby(['weekday']).count()['uid'].to_list()
df_pair = [['周一', week[0]], ['周二', week[1]], ['周三', week[2]], ['周四', week[3]], ['周五', week[4]], ['周六', week[5]], ['周日', week[6]]]
chart = Pie()
chart.add('', df_pair,radius=['40%', '70%'],rosetype='radius',center=['45%', '50%'],label_opts=opts.LabelOpts(is_show=True,formatter = '{b}:{c}次'))
chart.set_global_opts(visualmap_opts=[opts.VisualMapOpts(min_=200000,max_=300000,type_='color', range_color=['#1AF5EF', '#F6325A', '#000000'],is_show=True,pos_top='65%')],legend_opts=opts.LegendOpts(pos_right='10%',pos_top='2%',orient='vertical'),title_opts=opts.TitleOpts(title="一周内播放分布图",pos_left='35%'),)chart.render_notebook()
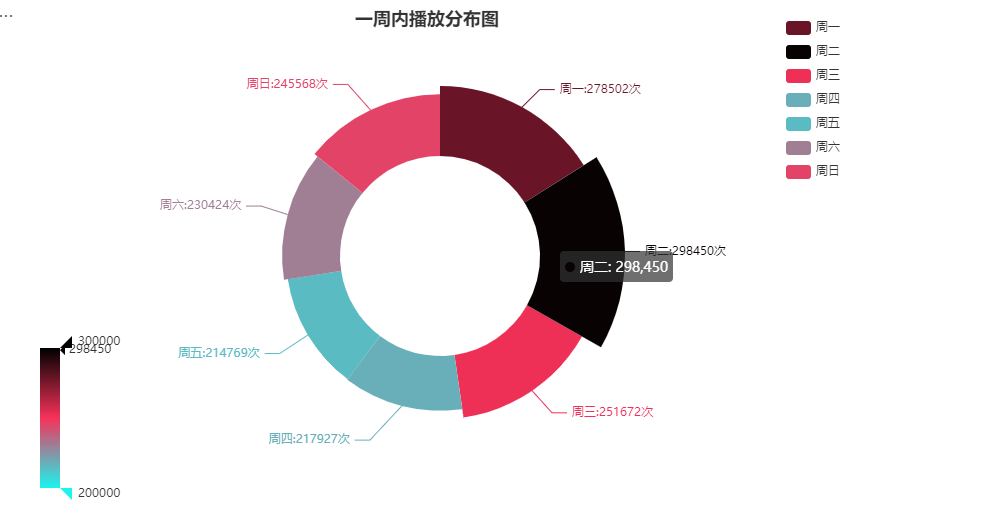
在统计的时间内周一到周三观看人数较多,但总体观看次数基本在20-30w之间。
- 创作者选择在周一-三这几天分布可能会收获更多的观看数量
观看路径
df.groupby(['channel']).count()['uid']

观看途径主要以1为主,初步猜测为App。3途径也有部分用户使用,可能为浏览器。
- 考虑拓宽各个观看渠道,增加总体播放量和产品使用度
- 非主渠道观看,制定策略提升转化,将流量引入主渠道
- 针对主要渠道内容进行商业化策略投放,效率更高
发布地点
author_info = df.drop_duplicates(['author_id','item_city'])[['author_id','item_city']]
author_info.info()
author_city_count = author_info.groupby(['item_city']).count().sort_values(by=['author_id'],ascending=False)
x1 = list(author_city_count.index)
y1 = author_city_count['author_id'].tolist()
df.drop_duplicates(['author_id']).shape[0]
不同城市创作者分布图
chart = Bar()
chart.add_xaxis(x1)
chart.add_yaxis('地区创作者人数', y1, color='#F6325A',itemstyle_opts={'barBorderRadius':[60, 60, 20, 20]})
chart.set_global_opts(datazoom_opts=opts.DataZoomOpts(range_start=0,range_end=5,orient='horizontal',type_='slider',is_zoom_lock=False, pos_left='1%' ),visualmap_opts=opts.VisualMapOpts(is_show = False,type_='opacity',range_opacity=[0.2, 1]),legend_opts=opts.LegendOpts(pos_right='10%',pos_top='2%'),title_opts=opts.TitleOpts(title="不同城市创作者分布图",pos_left='40%'))
chart.render_notebook()
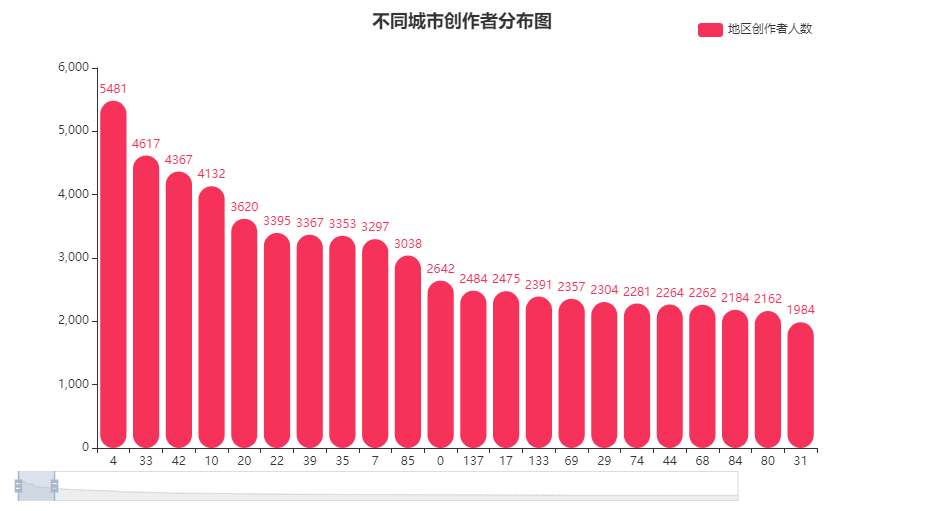
观看用户地区分布和创作者分布其实存在不对等的情况。4地区创作者最多,超5k人,33、42、10地区创作者也较多。
- 创作者与地区的联系也值得关注,尤其是创作内容如果和当地风俗环境人文有关
- 相邻近地区的优质的创作者之间互动,可以更好的引流
视频时长
time = df.drop_duplicates(['item_id'])[['item_id','duration_time']]
time = time.groupby(['duration_time']).count()
x1 = list(time.index)
y1 = time['item_id'].tolist()
不同时长作品分布图
chart = Bar()
chart.add_xaxis(x1)
chart.add_yaxis('视频时长对应视频数', y1, color='#1AF5EF',itemstyle_opts={'barBorderRadius':[60, 60, 20, 20]},label_opts=opts.LabelOpts(font_size=12, color='black'))
chart.set_global_opts(datazoom_opts=opts.DataZoomOpts(range_start=0,range_end=50,orient='horizontal',type_='slider'),visualmap_opts=opts.VisualMapOpts(max_=100000,min_=200,is_show = False,type_='opacity',range_opacity=[0.4, 1]),legend_opts=opts.LegendOpts(pos_right='10%',pos_top='2%'),title_opts=opts.TitleOpts(title="不同时长作品分布图",pos_left='40%'))chart.render_notebook()
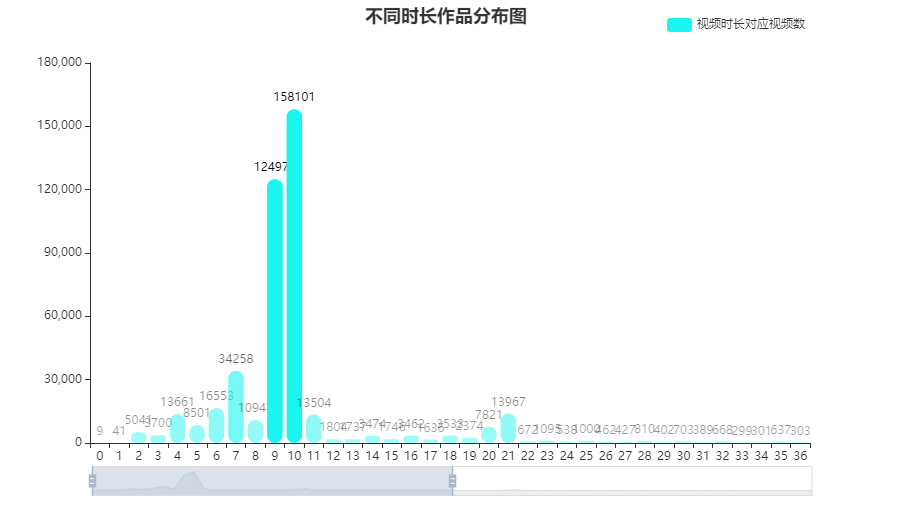
视频时长主要集中在9-10秒,符合抖音“短”视频的特点。
- 官方提供9/10秒专用剪视频模板,提高创作效率
- 创作者关注创意浓缩和内容提炼
- 视频分布在这两个时间点的爆发也能侧面反映用户刷视频的行为特征
整体点赞、完播
like_per = 100*np.sum(df['like'])/len(df['like'])
finish_per = 100*np.sum(df['finish'])/len(df['finish'])
gauge = Gauge()
gauge.add("",[("视频互动率", like_per),['完播率',finish_per]],detail_label_opts=opts.LabelOpts(is_show=False,font_size=18),axisline_opts=opts.AxisLineOpts(linestyle_opts=opts.LineStyleOpts(color=[(0.3, "#1AF5EF"), (0.7, "#F6325A"), (1, "#000000")],width=20)))
gauge.render_notebook()
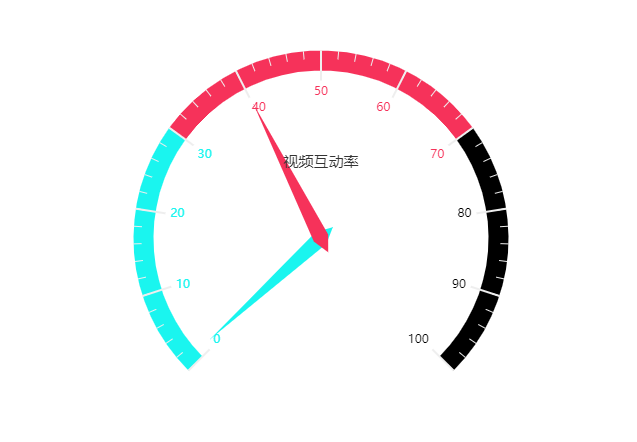
内容整体完播率非常接近40%,点赞率在1%左右
- 用户更多是“刷”视频,挖掘吸引力和作品连贯性,能更好留住用户
- 点赞功能挖掘不够,可尝试进行ABtest,对点赞按钮增加动画,测试是否会提升点赞率
4 进阶分析
相关性分析
df_cor = df[['finish','like','duration_time','H']] # 只选取部分
cor_table = df_cor.corr(method='spearman')
cor_array = np.array(cor_table)
cor_name = list(cor_table.columns)
value = [[i, j, cor_array[i,j]] for i in [3,2,1,0] for j in [0,1,2,3]]
heat = HeatMap()
heat.add_xaxis(cor_name)
heat.add_yaxis("",cor_name,value,label_opts=opts.LabelOpts(is_show=True, position="inside"))
heat.set_global_opts(visualmap_opts=opts.VisualMapOpts(is_show=False, max_=0.08, range_color=["#1AF5EF", "#F6325A", "#000000"]))
heat.render_notebook()
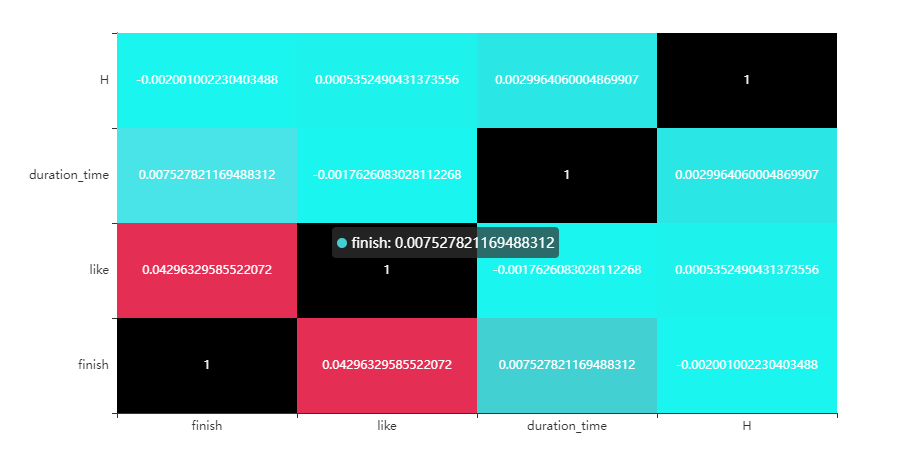
因为变量非连续,采取spearman相关系数,制作相关性热力图。由于数据量比较大的缘故,几个数量性变量之间的相关性都比较小,其中看到finish和点赞之间的相关系数稍微大一些,可以一致反映用户对该视频的偏好。
留存率
pv/uv
temp = df['date'].to_list()
puv = df.groupby(['date']).agg({'uid':'nunique','item_id':'count'})
uv = puv['uid'].to_list()
pv = puv['item_id'].to_list()
time = puv.index.to_list()
chart1 = Line()
chart1.add_xaxis(time)
chart1.add_yaxis('uv',uv,is_smooth=True,label_opts=opts.LabelOpts(is_show=False),is_symbol_show = False,linestyle_opts=opts.LineStyleOpts(color='#1AF5EF',opacity=.7,curve=0,width=2,type_= 'solid' ))
chart1.add_yaxis('pv',pv,is_smooth=True,label_opts=opts.LabelOpts(is_show=False),is_symbol_show = False,linestyle_opts=opts.LineStyleOpts(color='#F6325A',opacity=.7,curve=0,width=2,type_= 'solid' ))
chart1.render_notebook()
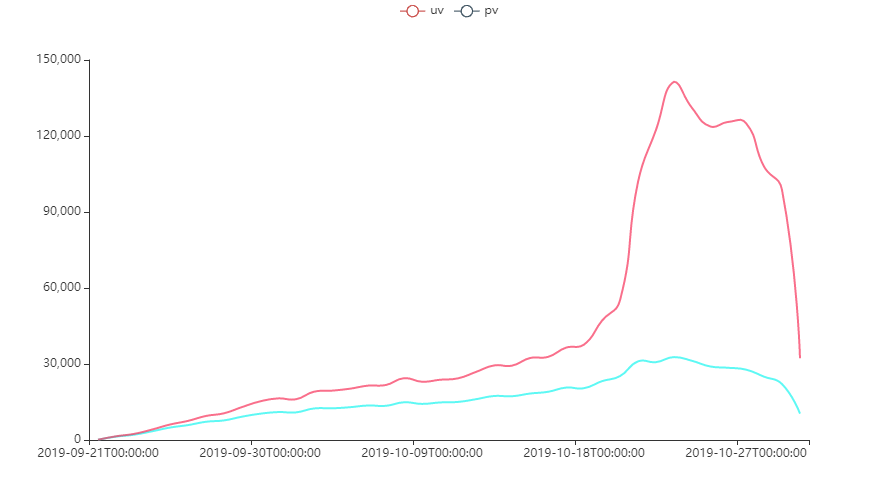
在2019.10.18进入用户使用高峰阶段,目标用户单人每天浏览多个视频。
- 关注高峰时间段,是否是当下推荐算法起作用了
7/10 留存率
lc = []
for i in range(len(time)-7):bef = set(list(df[df['date']==time[i]]['uid']))aft = set(list(df[df['date']==time[i+7]]['uid']))stay = bef&aftper = round(100*len(stay)/len(bef),2)lc.append(per)lc1 = []
for i in range(len(time)-1):bef = set(list(df[df['date']==time[i]]['uid']))aft = set(list(df[df['date']==time[i+1]]['uid']))stay = bef&aftper = round(100*len(stay)/len(bef),2)lc1.append(per)
x7 = time[0:-7]
chart1 = Line()
chart1.add_xaxis(x7)
chart1.add_yaxis('七日留存率/%',lc,is_smooth=True,label_opts=opts.LabelOpts(is_show=False),is_symbol_show = False,linestyle_opts=opts.LineStyleOpts(color='#F6325A',opacity=.7,curve=0,width=2,type_= 'solid' ))
chart1.set_global_opts(legend_opts=opts.LegendOpts(pos_right='10%',pos_top='2%'),title_opts=opts.TitleOpts(title="用户留存率分布图",pos_left='40%'),)chart1.render_notebook()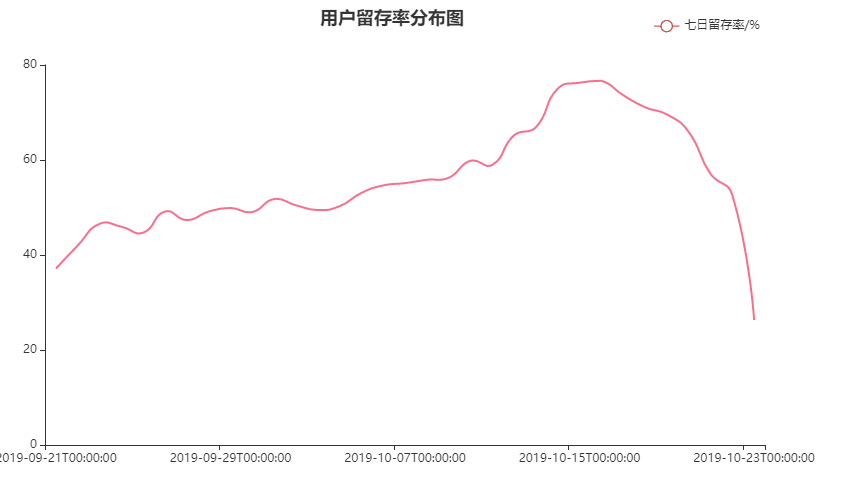
用户留存率保持在40%+,且没有跌破30%,说明获取到的数据中忠实用户较多。
- 存在一定可能性是因为数据只爬取了特定用户群体的行为数据,结合创作者数量>用户数量可得到验证
- 但一定程度可以反映软件留存这块做的不错
5 深度分析
客户价值判断
通过已观看数、完播率、点赞率进行用户聚类,价值判断
df1 = df.groupby(['uid']).agg({'item_id':'count','like':'sum','finish':'sum'})
df1['like_per'] = df1['like']/df1['item_id']
df1['finish_per'] = df1['finish']/df1['item_id']
ndf1 = np.array(df1[['item_id','like_per','finish_per']])#.shape
kmeans_per_k = [KMeans(n_clusters=k).fit(ndf1) for k in range(1,8)]
inertias = [model.inertia_ for model in kmeans_per_k]
chart = Line(init_opts=opts.InitOpts(width='560px',height='300px'))
chart.add_xaxis(range(1,8))
chart.add_yaxis("",inertias,label_opts=opts.LabelOpts(is_show=False),linestyle_opts=opts.LineStyleOpts(color='#F6325A',opacity=.7,curve=0,width=3,type_= 'solid' ))
chart.render_notebook()
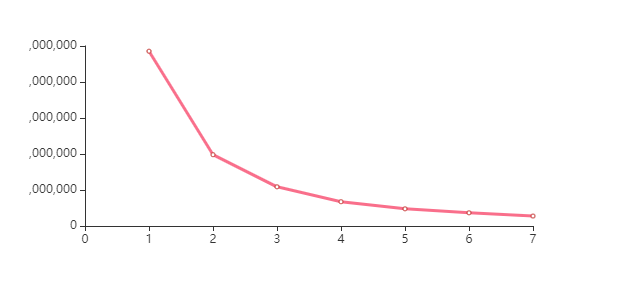
n_cluster = 4
cluster = KMeans(n_clusters=n_cluster,random_state=0).fit(ndf1)
y_pre = cluster.labels_ # 查看聚好的类
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
silhouette_score(ndf1,y_pre)
n_cluster = 3
cluster = KMeans(n_clusters=n_cluster,random_state=0).fit(ndf1)
y_pre = cluster.labels_ # 查看聚好的类
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
silhouette_score(ndf1,y_pre)
比较三类、四类的轮廓系数,确定聚为3类
c_ = [[],[],[]]
c_[0] = [87.998,9.1615,39.92]
c_[1] = [13.292,12.077,50.012]
c_[2] = [275.011,8.125,28.751]
bar = Bar(init_opts=opts.InitOpts(theme='macarons',width='1000px',height='400px')) # 添加分类(x轴)的数据
bar.add_xaxis(['播放数','点赞率(千分之)','完播率(百分之)'])
bar.add_yaxis('0', [round(i,2) for i in c_[0]], stack='stack0')
bar.add_yaxis('1',[round(i,2) for i in c_[1]], stack='stack1')
bar.add_yaxis('2',[round(i,2) for i in c_[2]], stack='stack2')
bar.render_notebook()
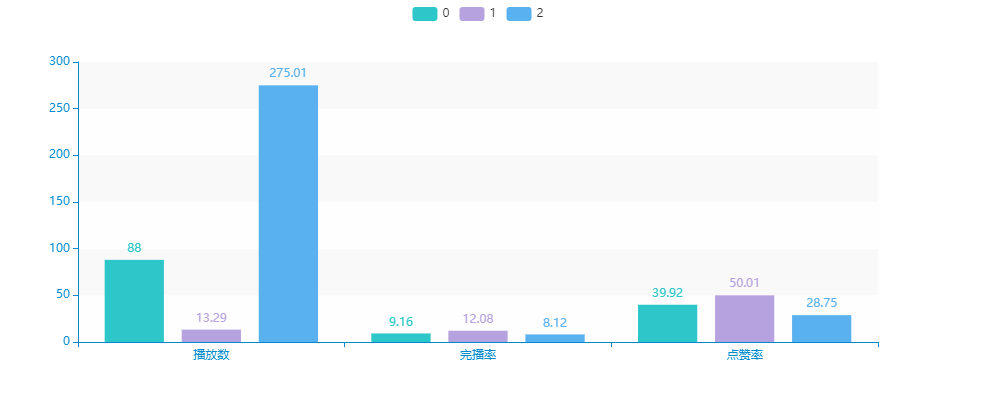
可以大致对三类的内容做一个描述。
- 紫色 - 观看数量较少,但点赞完播率都非常高的:对内容观看有耐心,愿意产生额外性行为。因此通过观看兴趣内容打散、可以刺激用户观看更多视频。e.g.多推荐有悬念、连续性的短视频
- 绿色 - 观看数量适中,点赞率、完播率有所下滑,对这类用户的策略可以中和先后两种。
- 蓝色 - 观看数量非常多,点赞、完播率教室,这类用户更多会关注到视频前半段的内容,兴趣点可通过停留时间进行判断,但使用时间相对较长,反映产品依赖性,一定程度上来说算是核心用户。e.g.利用停留时间判断喜好,优化推荐算法,重点推荐前半段内容吸引力大的。
5 最后
相关文章:
计算机毕设 基于大数据的抖音短视频数据分析与可视化 - python 大数据 可视化
文章目录 0 前言1 课题背景2 数据清洗3 数据可视化地区-用户观看时间分界线每周观看观看路径发布地点视频时长整体点赞、完播 4 进阶分析相关性分析留存率 5 深度分析客户价值判断 5 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,…...

1.OpenResty系列之入门简介
OpenResty(也称为ngx_openresty)是一个基于Nginx的全功能Web应用服务器,它将Nginx与一组附加模块和Lua脚本语言集成在一起,以提供高性能的Web应用程序开发和扩展性。 Nginx是一个轻量级的、高性能的HTTP服务器和反向代理服务器&a…...
)
Trie树(字典树)
原理: 1. ch[p][j]:p是每个单词存到的idx索引,j是存入字符映射的数字 2. cnt[p] 存这个单词个数 【模板】字典树 - 洛谷 #include <iostream> #include <cstring> using namespace std;const int N 3e6 10; int ch[N][100], idx; int cnt…...

华为政企网络安全产品集
产品类型产品型号产品说明 防火墙及应用安全网关ASG5505ASG5000系列上网行为管理产品(以下简称“ASG5000”)是华为面向各类企业、政府、大中型数据中心以及各类无线非经营性场所推出的业界领先的综合上网行为管理产品。 该系列产品可深度识别、管控和…...

02-Sping事务实现之声明式事务基于XML的实现方式
声明式事务之XML实现方式 开发步骤 第一步: 引入AOP相关的aspectj依赖 <!--aspectj依赖--> <dependency><groupId>org.springframework</groupId><artifactId>spring-aspects</artifactId><version>6.0.0-M2</version> <…...
桶装水订水系统水厂送水小程序开发;
桶装水小程序正式上线,支持多种商品展示形式,会员卡、积分、分销等功能; 开发订水送水小程序系统,基于用户、员工、商品、订单、配送站和售后管理模块,对每个模块进行统计分析,简化了分配过程,提…...

png或jpg等图片文件转ico图标文件,格式在线转换
图片文件转ico图标文件在线转换:在线转换图片格式-在线图片转换器-100% 免费 (jinaconvert.com)...
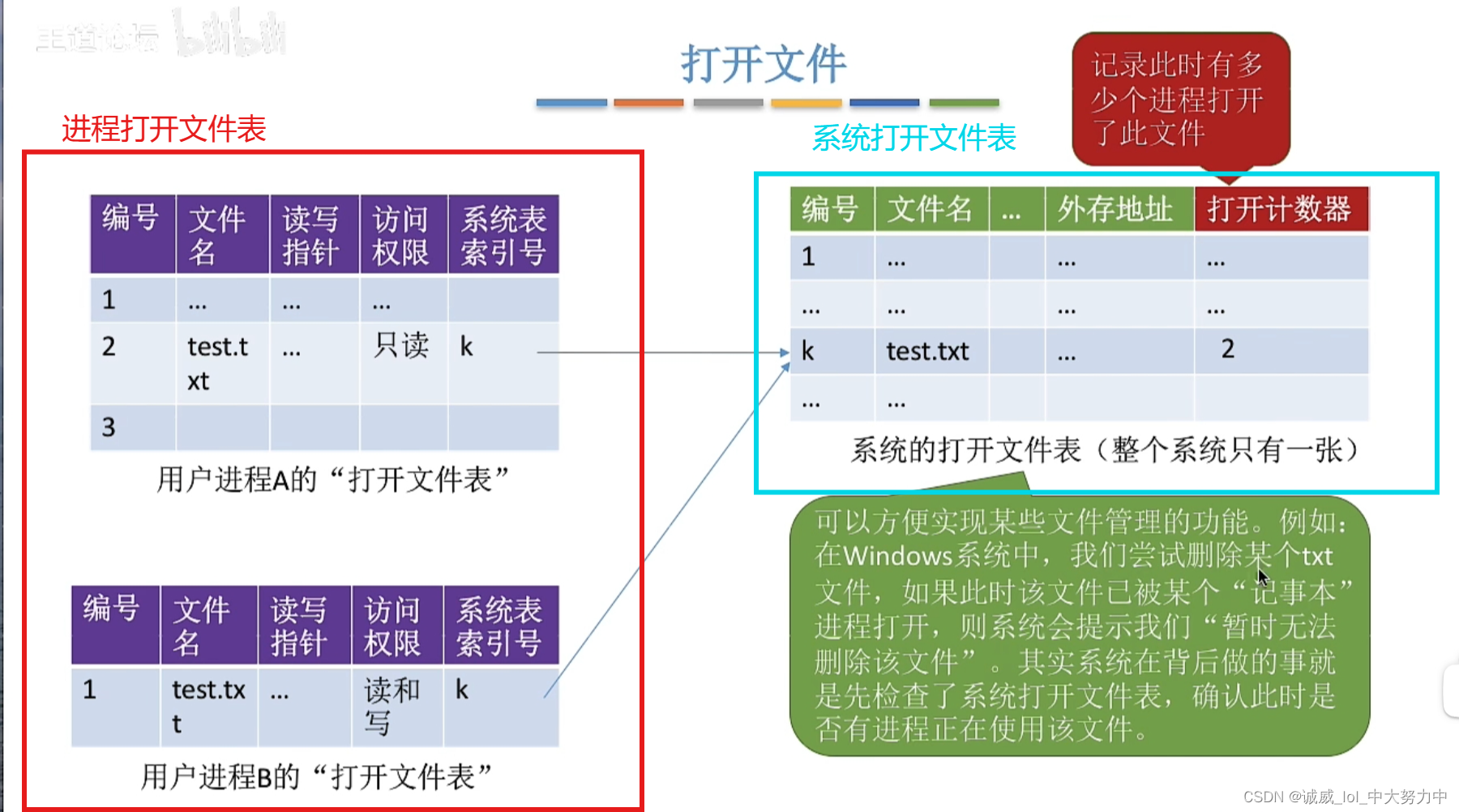
操作系统——对文件的 基本操作(王道视频p65)
1.总体概述: 2.进程打开文件表 和 系统打开文件表:...

中海达守护电力人员作业安全
近日,中海达为电网某换流站作业人员提供的160余套北斗高精度定位产品顺利完成交付。通过使用北斗高精度定位技术,帮助换流站实现了人员(车辆)位置实时定位、电子围栏实时预警、远程作业指导等应用效果,用高科技保障电网…...
想学计算机编程从什么学起?零基础如何自学计算机编程?中文编程开发语言工具箱之渐变标签组构件
想学计算机编程从什么学起?零基础如何自学计算机编程? 给大家分享一款中文编程工具,零基础轻松学编程,不需英语基础,编程工具可下载。 这款工具不但可以连接部分硬件,而且可以开发大型的软件,…...

中国人民大学与加拿大女王大学金融硕士——一把开启未来金融世界的金钥匙
在这个日新月异、竞争激烈的时代,每个人都渴望不断提升自我,以应对不断变化的世界。在当今的金融领域,国际化的视野和多元化的知识结构变得越来越重要。如何才能掌握未来世界的金钥匙呢?其实,这把金钥匙并非遥不可及&a…...
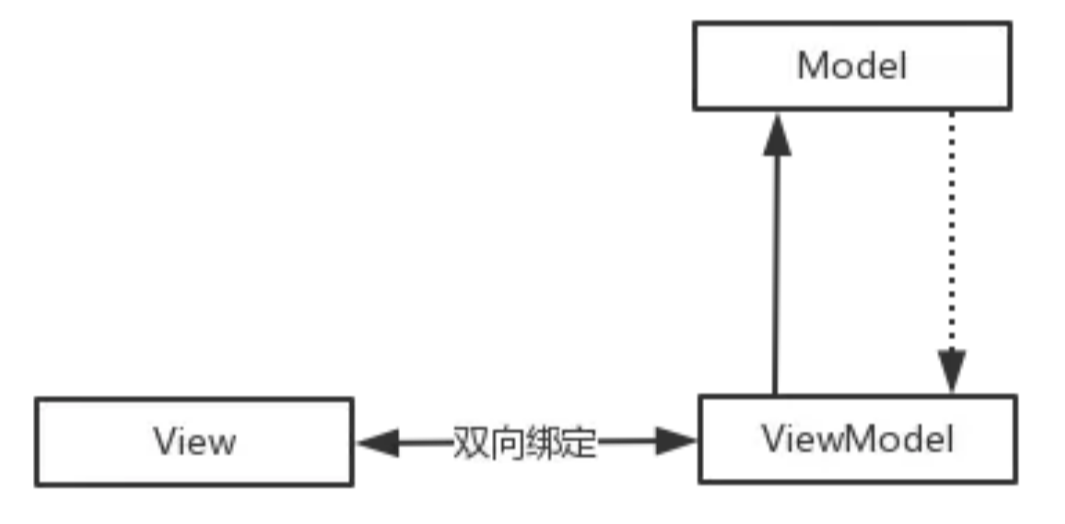
MVC、MVP、MVVM区别
MVC、MVP、MVVM区别 MVC(Model-View-Controller) 。是一种设计模式,通常用于组织与应用程序的数据流。它通常包括三个组件:模型(Model)、视图(View)和控制器(Controller&…...
【Kotlin精简】第7章 泛型
1 泛型 泛型即 “参数化类型”,将类型参数化,可以用在类,接口,函数上。与 Java 一样,Kotlin 也提供泛型,为类型安全提供保证,消除类型强转的烦恼。 1.1 泛型优点 类型安全:通用允许…...
ElasticSearch与Lucene是什么关系?Lucene又是什么?
一. ElasticSearch 与 Lucene 的关系 Elasticsearch(ES)和Apache Lucene之间有密切的关系,可以总结如下: Elasticsearch构建于Lucene之上:Elasticsearch实际上是一个分布式的、实时的搜索和分析引擎,它构建…...

【算法练习Day40】打家劫舍打家劫舍 II打家劫舍 III
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:练题 🎯长路漫漫浩浩,万事皆有期待 文章目录 打家劫舍打家劫舍 II打家劫…...

双十一运动健身好物推荐,这几款健身好物一定不要错过!
双十一购物狂欢节又要到了,又要到买买买的时候了!相信有很多想健身的小白还在发愁不知道买啥装备?别急,三年健身达人这就给你们分享我的年度健身好物! 第一款:南卡Runner Pro4s骨传导耳机 推荐理由&#…...

Angular异步数据流编程
1 目前常见的异步编程的几种方法 首先给出一个异步请求的实例: import {Injectable} from angular/core;Injectable({providedIn: root }) export class RequestServiceService {constructor() {}getData() {setTimeout(() > {let res zhaoshuai-lcreturn res…...

古典舞学习的独舞与群舞,古典舞的成品舞蹈教学大全
一、教程描述 本套教程的古典舞是很全面的,不仅有舞蹈动作分解教学,而且有成品舞的完整教学,同时提供独立的背景音乐文件,可以让你更快地学会古典舞。本套教程,大小30.54G,共有276个文件。 二、教程目录 …...

听GPT 讲Rust源代码--library/std(16)
题图来自 EVALUATION OF RUST USAGE IN SPACE APPLICATIONS BY DEVELOPING BSP AND RTOS TARGETING SAMV71[1] File: rust/library/std/src/sync/mpmc/select.rs 在Rust标准库中,rust/library/std/src/sync/mpmc/select.rs文件的作用是实现一个多生产者多消费者的选…...

计算机编程软件编程基础知识,中文编程工具下载分享
计算机编程软件编程基础知识,中文编程工具下载分享 给大家分享一款中文编程工具,零基础轻松学编程,不需英语基础,编程工具可下载。 这款工具不但可以连接部分硬件,而且可以开发大型的软件,象如图这个实例…...
模块?)
OpenClaw 的模型架构中,是否使用了非自回归生成(NAR)模块?
关于OpenClaw模型架构中是否使用了非自回归生成模块,这其实是一个挺有意思的问题。在讨论具体细节之前,或许可以先聊聊非自回归生成本身在技术演进中的位置。 非自回归生成,也就是NAR,和常见的自回归生成方式不太一样。自回归生成…...

JTAG接口原理、故障诊断与安全操作指南
1. JTAG接口基础解析作为一名从事FPGA开发多年的工程师,我经常需要与JTAG接口打交道。这个看似简单的四线接口,在实际工作中却经常给我们带来各种"惊喜"。今天我就结合自己踩过的坑,系统地讲讲JTAG那些事儿。JTAG(Joint Test Actio…...

OpenClaw快速接入QQ教程
OpenClaw快速接入QQ教程 OpenClaw是一个强大的开源AI Agent,支持通过多种聊天软件进行交互。下面将详细介绍如何在OpenClaw中接入QQ,实现QQ与AI的对话操作。 前置准备工作 在开始配置之前,请确保完成以下准备工作: QQ账号部署好Op…...

低空经济落地第一站:工业无人机巡检的格局重构、技术革命与黄金增长期
在海拔4500米的青藏高原特高压输电线路上,一架全自主工业无人机沿着预设航线平稳飞行,以厘米级精度悬停在绝缘子旁,红外热成像镜头精准捕捉到导线的微小发热点,端侧AI大模型实时完成缺陷识别与风险分级,数据同步回传至…...

IUV5G数字室分酒店项目实战:从勘察到验收的避坑指南
1. 站点勘察:这些细节不注意会让你返工 第一次做酒店5G室分项目时,我在勘察环节踩过不少坑。记得有次因为没注意电梯井的测量方式,导致后期设计方案全部推翻重做。下面这些实战经验,能帮你省去至少50%的返工时间。 经纬度记录有个…...

不止System.Memory!OpenCVSharp依赖的这几个DLL报错,一个方法全搞定
深度解析OpenCVSharp依赖冲突:从System.Memory到通用解决方案 当你兴致勃勃地准备运行一个基于OpenCVSharp的计算机视觉项目时,突然弹出的"DLL加载失败"或"版本不匹配"错误信息就像一盆冷水浇灭了热情。System.Memory只是众多潜在问…...

RTX 3090上跑Isaac Lab强化学习:从克隆仓库到训练蚂蚁机器人保姆级避坑指南
RTX 3090上的Isaac Lab强化学习实战:从零训练蚂蚁机器人的完整指南 在机器人强化学习领域,NVIDIA Isaac Lab正迅速成为研究者和开发者的首选工具链。当RTX 3090的24GB显存遇上Ubuntu 22.04的稳定环境,这套组合能为复杂RL任务提供令人惊喜的训…...
Pixel Aurora Engine效果展示:‘进化像素’设计哲学下的10组对比作品集
Pixel Aurora Engine效果展示:‘进化像素’设计哲学下的10组对比作品集 1. 像素极光引擎概览 Pixel Aurora Engine是一款基于AI扩散模型的高端像素艺术生成工具。它采用独特的复古像素游戏风格界面设计,将现代AI技术与经典8-bit美学完美融合。这款工具…...

灵活创建Windows安装介质:MediaCreationTool.bat的实用指南
灵活创建Windows安装介质:MediaCreationTool.bat的实用指南 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

BiliTools:解决B站资源离线访问难题的跨平台技术方案
BiliTools:解决B站资源离线访问难题的跨平台技术方案 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools 在…...