【ElasticSearch系列-06】Es集群架构的搭建以及集群的核心概念
ElasticSearch系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】ElasticSearch下载和安装 | https://zhenghuisheng.blog.csdn.net/article/details/129260827 |
| 【二】ElasticSearch概念和基本操作 | https://blog.csdn.net/zhenghuishengq/article/details/134121631 |
| 【三】ElasticSearch的高级查询Query DSL | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【四】ElasticSearch的聚合查询操作 | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【五】SpringBoot整合elasticSearch | https://blog.csdn.net/zhenghuishengq/article/details/134212200 |
| 【六】Es集群架构的搭建以及集群的核心概念 | https://blog.csdn.net/zhenghuishengq/article/details/134258577 |
Es集群架构的搭建以及集群的核心概念
- 一,深入理解es集群架构的底层原理
- 1,集群的核心概念
- 1.1,节点以及节点类型
- 1.2,请求和响应流程
- 1.3,分片
- 2,集群搭建
- 2.1,es集群搭建
- 2.2,kibana安装
- 3,X-pack安全认证
- 4,Node结点类型
- 4.1,不同结点的配置
- 4.2,单一职责的好处
一,深入理解es集群架构的底层原理
前面讲解了es的安装,基本使用等,接下来这篇主要讲解es的集群架构的底层原理,es的索引分片,副本等基本知识
1,集群的核心概念
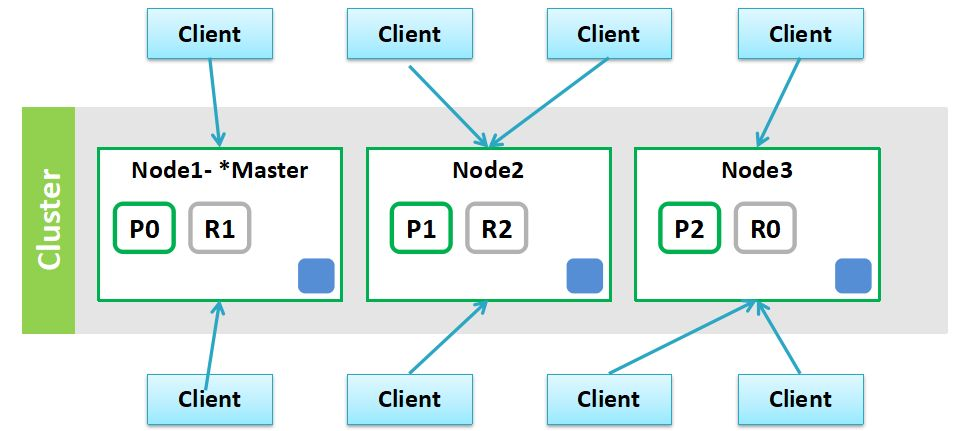
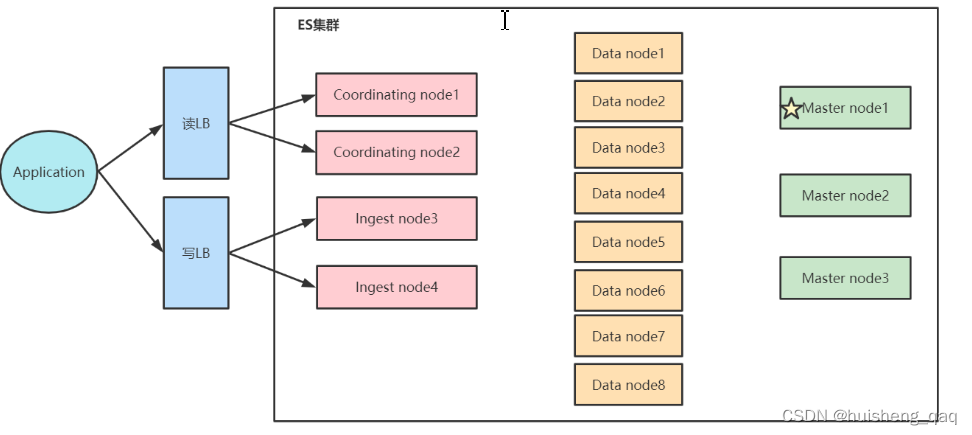
在安装集群之前,先了解一下集群的几个概念。如下图 ,就是一个三个节点组成的es集群,p0、p1、p2表示一个节点中的分片,R0、R1、R2表示分片对应的副本
1.1,节点以及节点类型
一个集群中可以有一个或者多个节点,每一个节点就是一个Es的实例,其本质就是一个java进程。一般在一台机器上,建议运行一个ElasticSearch的实例。在Es集群中,存在多种节点类型,主要有以下几种节点,在搭建es集群时,需要根据不同的结点类型设置不同的参数。每个结点在启动之后,默认就是一个可以参与选举的 Master eligible 结点
- Master Node:主节点,如上图中的Node1就是master主节点,主要是负责一些索引的创建、删除、决定分片要分配到哪个结点、维护整个集群的更新等
- Master eligible nodes:可以参与选举的合格节点,当主节点挂了该节点就可以参与选举,该节点也是Master主结点的一个从结点
- Data Node:专门用于存放数据的节点,如索引插入的数据就是存放在这个节点中。由master主结点负责如何将分片分发到数据节点上,通过数据节点解决数据的水平扩展和解决数据的单点问题。
- Coordinating Node:协调节点,用于接收和响应请求,完成数据的接收和分发
1.2,请求和响应流程
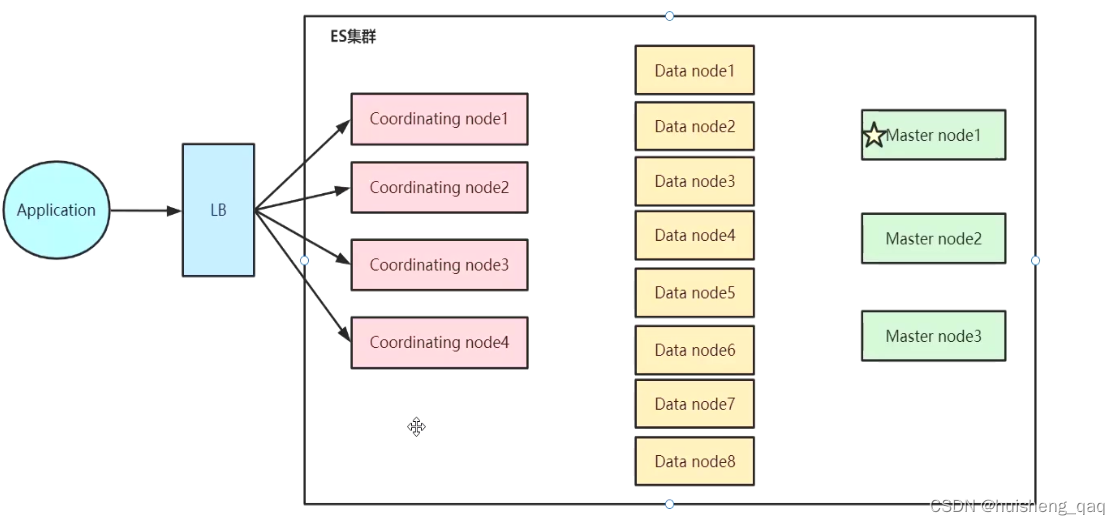
一个简单的es的集群架构如下,在一个客户端的请求下,首先会经过这个协调结点的接收和分发,让请求具体落实到Data Node数据节点,或者是Master主结点。如果是查询数据,可以直接分发到Data数据节点,如果是增删改,需要涉及到集群,分片或者副本的变化,那么可以直接分发到这个Master主结点上面。
在将数据从结点的分片中查询之后,又会将数据汇总到这个Coordinating 协调结点上面,经过一些统计计算等,最后将结果返回
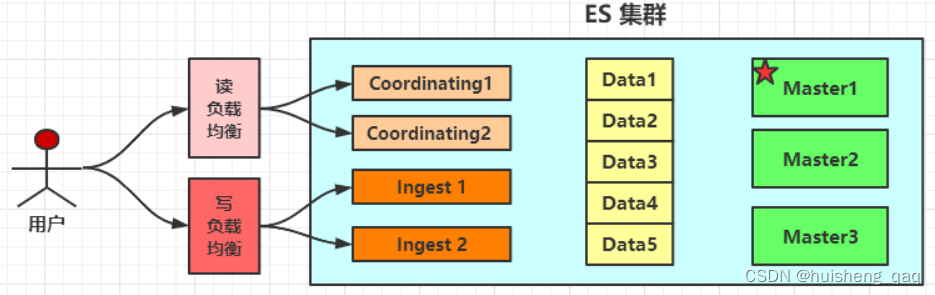
如果es要做读写分离来增加高性能的话,可以增加这个Ingest Node结点,该节点名为前置处理转换结点,支持pipeline管道设置,可以使用这个Ingest节点对数据进行过滤以及转换操作
1.3,分片
在创建索引时,可以指定索引分片的个数,副本的个数等。分片又可以分为主分片和副本分片。
主分片 :Primary Shard,主要是用于解决数据水平扩展的问题,通过主分片,可以将数据分发到集群的所有结点上面,每一个分片是一个Lucene的一个实例,分片在创建之后,不允许被修改,因为获取数据需要通过hash取模运算,改了数量就会直接影响结果
副本分片 : Replica Shard,用于解决数据高可用的问题,就是主分片的一个拷贝,主分片数在创建之后不允许被修改,副本分片数是允许被修改的,并且在一定程度上,可以通过增加副本数来提高服务读取数据的性能。但是副本分片最好是设置成0或者1,如果是日志数据,可以直接设置为0,如果是商品信息这种检索数据,那么可以直接设置成为1。
如下面在创建索引的时候,可以设置分片的数量以及设置副本的数量。
PUT /zhs_db
{"settings": {"number_of_shards": 3, //设置分片数"number_of_replicas": 1 //设置副本数}
}
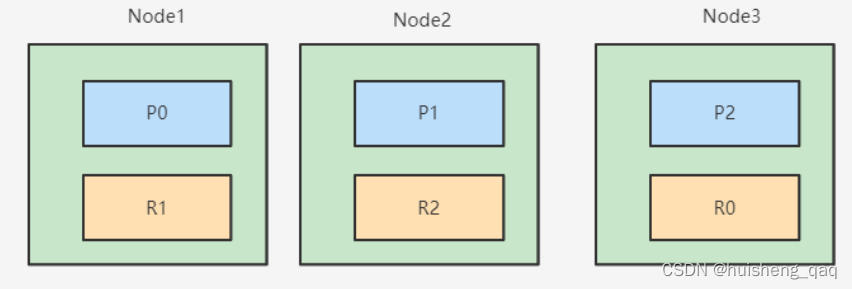
分片数和节点数有关,如有一个三个节点组成的集群,那么设三个分片,那么会根据默认的hash算法,一个节点中就会有一个分片,就会是下图中的P0、P1、P2和R0、R1、R2这种情况
在非单机的情况下,副本分片一般和主分片不在一个节点上面,副本分片一般是在同一个集群中的不同结点上面,具体在哪个结点上面,需要通过这个Master主结点去分配
单节点的分片数目也不宜设置过多,因为过多的话会影响算分的结果性,同时也会浪费很多资源
2,集群搭建
2.1,es集群搭建
在第一篇文章中,讲解了es的单节点集群的搭建方式,那么es集群的搭建,需要有三台机器,重复单节点的搭建即可,并且都可以简单的通过docker的方式搭建
主要就是修改这个 elasticsearch.yml 中的文件中的内容,最主要的就是修改这个discovery.seed_hosts 中的三台搭建了es结点的服务器的host主机号,用于节点发现,之前单机设置的是只有当前结点的主机号。
在指定这个结点的名称时,这个yml文件设置的这个node.name也要不一致,第一台设置node-1,第二胎设置为node-2,第三台设置为node-3,在初始化集群节点的时候,需要将这三个值配置到 cluster.initial_master_nodes 属性中
# 指定集群名称3个节点必须一致
cluster.name: docker-cluster
#指定节点名称,每个节点名字唯一
node.name: node-1
#是否有资格为master节点,默认为true
node.master: true
#是否为data节点,默认为true
node.data: true
# 绑定ip,开启远程访问,可以配置0.0.0.0
network.host: 0.0.0.0
#指定web端口
#http.port: 9200
#指定tcp端口
#transport.tcp.port: 9300
#用于节点发现,三个节点的主机号
discovery.seed_hosts: ["xxx.xxx.xxx.166", "xxx.xxx.xxx.167", "xxx.xxx.xxx.168"]
#7.0新引入的配置项,初始仲裁,仅在整个集群首次启动时才需要初始仲裁。
#该选项配置为node.name的值,指定可以初始化集群节点的名称
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"
2.2,kibana安装
这个在第一篇安装也详细的讲解过,但是在 kibana.yml 中,也需要修改部分配置如下,需要把es所在服务器的主机号以及端口号进行配置
server.port: 5601
server.host: "xxx.xxx.xxx.166"
elasticsearch.hosts: ["http://xxx.xxx.xxx.166:9200","http://xxx.xxx.xxx.167:9200","http://xxx.xxx.xxx.168:9200"]
i18n.locale: "zh-CN"
3,X-pack安全认证
为了解决数据的安全性,防止出现数据被抓包的可能,因此需要为每台机器上面的结点创建一个安全认证,这里选择通过这个 x-pack的方式实现
首先进入每一台机器的容器中,如这个166这台
docker exec -it elasticsearch /bin/bash
随后直接执行下面的命令,随后会出现提示,需要输入两次密码
// 为集群创建一个证书
elasticsearch-certutil ca
继续执行下面的命令
// 为集群中的结点生成证书和私钥
elasticsearch-certutil cert --ca elastic-stack-ca.p12
执行成功之后,给es文件夹下的两个文件授权
chmod 777 elastic-certificates.p12
随后再修改每台机器中 elasticsearch.yml 中的配置,在原有的基础上,在增加以下的参数
## elasticsearch.yml 配置
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.client_authentication: required
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
在增加完上面的安全认证之后,随后在增加这个开启xpack安全认证的配置,依旧是每台服务中的这个 elasticsearch.yml 中
xpack.security.enabled: true # 开启xpack认证机制
随后重启es服务,重启完成之后,再进入这个es
docker exec -it elasticsearch /bin/bash
进入es之后,再输入一下命令
elasticsearch-setup-passwords interactive
进入到里面之后,可以发现这里面可以设置es,kibana,logstach等system系统的一些密码,可以手动的创建密码
Enter password for [elastic]:
Reenter password for [elastic]:
Enter password for [apm_system]:
passwords must be at least [6] characters long
Try again.
Enter password for [apm_system]:
Reenter password for [apm_system]:
Enter password for [kibana_system]:
Reenter password for [kibana_system]:
Enter password for [logstash_system]:
Reenter password for [logstash_system]:
Enter password for [beats_system]:
Reenter password for [beats_system]:
Enter password for [remote_monitoring_user]:
Reenter password for [remote_monitoring_user]:
1234Changed password for user [apm_system]
56Changed password for user [kibana_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]
比如给kibana设置密码,直接在进入kibana内部,随后再打开这个 kibana.yml 配置,随后修改往这个yml文件中加入以下的账号密码
elasticsearch.username: "kibana"
elasticsearch.password: "123456"
再重启这个kibana之后,就可以发现在打开这个kibana的之后,是需要输入这个上面配置的账号密码的
4,Node结点类型
4.1,不同结点的配置
上面提到了节点的类型有Master主结点、Master eligible从节点、Coordinaing协调结点、Data数据节点等节点,而每一个结点都是一个java进程,并且最初都是可以参与选举的从节点,那么在进行配置的时候,就需要通过不同的参数,设置成不同的结点
设置节点类型的参数如下,需要通过这几个属性设置对应的结点
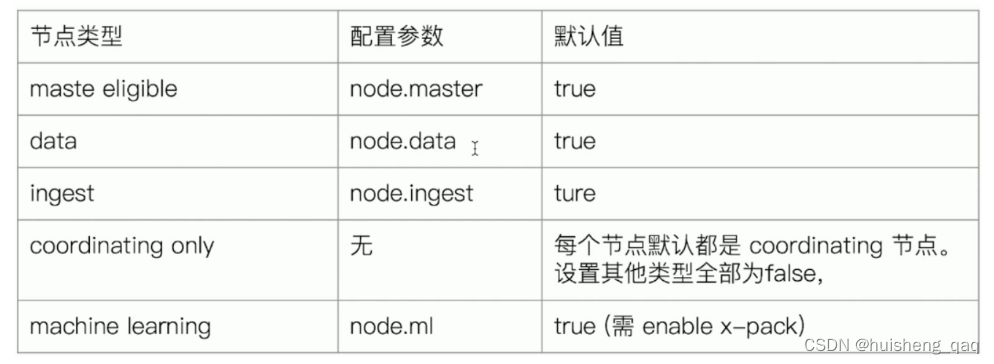
设置成主结点的方式如下,只需要一个node.master为true即可,其他的全部设置为false
node.master: true node.ingest: false node.data: false
设置成数据节点的方式如下,只需要node.data的值为true即可,其他的设置成false
node.master: false node.ingest: false node.data: true
设置成ingest节点的方式如下,只需要node.ingest为true即可,其他的设置成false
node.master: false node.ingest: false node.data: true
协调结点可以直接将三个值全部设置为false,如果并没有设置协调结点,那么在接收到请求的节点就默认当成协调节点
node.master: false node.ingest: false node.data: false
4.2,单一职责的好处
上面说了同一个进程,通过不同的参数设置,实现不同的功能,通过不同角色实现单一职责,从而增加整个ElasticSearch的高可用性
- 如单一职责的Master主结点,主要用于索引和分片的管理,如创建删除等等,影响整个集群数据的结点,因此在实际开发中,可以选择低配置的CPU、RAM处理器和磁盘等
- 如这个可以参与选举的默认的从结点,主要用于负责集群的状态管理,主结点挂了就参与选举称为主结点,在实际开发中,也可以选择低配置的CPU、RAM处理器和磁盘等
- 如这个处理数据大Data结点,负责数据处理,解决水平扩展等问题,可以使用高配置的CPU、RAM处理器以及磁盘
- 如这个ingest结点,主要也是负责数据的处理,那么也可以使用这个高配置的CPU,中配置的RAM处理器和低配置的磁盘
- 而这个协调者结点,主要负责数据的接收和转发,并且最后需要对查询的数据进行计算和汇总,那么需要高配置的CPU、高配置的RAM处理器和低配置的磁盘即可
当系统重有大量的复杂的查询时,可以通过增加协调者结点的个数,来增加查询的性能。
当磁盘容量无法满足需求或者读写的压力比较大时,可以增加数据节点
相关文章:
【ElasticSearch系列-06】Es集群架构的搭建以及集群的核心概念
ElasticSearch系列整体栏目 内容链接地址【一】ElasticSearch下载和安装https://zhenghuisheng.blog.csdn.net/article/details/129260827【二】ElasticSearch概念和基本操作https://blog.csdn.net/zhenghuishengq/article/details/134121631【三】ElasticSearch的高级查询Quer…...

软考高级系统架构设计师系列案例考点专题六:面向服务架构设计
软考高级系统架构设计师系列案例考点专题六:面向服务架构设计 一、面向服务架构设计内容大纲二、SOA概述和发展三、SOA和微服务的区别四、SOA的参考架构五、SOA主要协议和规范六、SOA设计标准和原则七、SOA设计模式八、SOA构建和实施一、面向服务架构设计内容大纲 SOA概述和发…...

【入门Flink】- 07Flink DataStream API【万字篇】
DataStream API 是 Flink 的核心层 API。一个 Flink 程序,其实就是对DataStream的各种转换。 代码基本上都由以下几部分构成: 执行环境(Execution Environment) 1)创建执行环境StreamExecutionEnvironment StreamExe…...

AI:55-基于深度学习的人流量检测
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌在这个漫长的过程,中途遇到了不少问题,但是…...

node版本管理工具nvm
node版本管理工具nvm 要在本地拥有多个 Node.js 版本,并根据不同的环境切换不同的 Node.js 版本,你可以使用工具如 nvm(Node Version Manager)来管理和切换 Node.js 版本。 以下是关于如何使用这两个工具的简要说明:…...

stable-diffusion-webui安装Wav2Lip
常见错误 1.错误:Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check 修改代码: launch_utils.py 删除三个地方:...
Nacos-2.2.2源码修改集成高斯数据库GaussDB,postresql
一 ,下载代码 Release 2.2.2 (Apr 11, 2023) alibaba/nacos GitHub 二, 执行打包 mvn -Prelease-nacos -Dmaven.test.skiptrue -Drat.skiptrue clean install -U 或 mvn -Prelease-nacos ‘-Dmaven.test.skiptrue’ ‘-Drat.skiptrue’ clean instal…...

Linux 内核中根据文件inode号获取其对应的struct inode
文章目录 前言一、简介二、iget_locked2.1 简介2.2 内核中使用2.3 LKM demo 三、ext4_iget3.1 简介3.2 LKM demo 前言 文件inode号和struct inode结构体请参考: Linux文件路径,目录项,inode号关联 Linux文件系统 struct inode 结构体解析 一…...
Pycharm-community-2021版安装和配置
一、下载Pycharm-community-2021 1.从官网下载pycharm-community Pycharm 版本官网 二、安装PyCharm 1.打开下载完成的安装包,点击Next 2.安装PyCharm到其他位置,点击Next 3.一定把更新PATH变量勾上,可以创建桌面快捷方式,创建关联,最后…...
飞书开发学习笔记(一)-应用创建和测试
飞书开发学习笔记(一)-应用创建和测试 一.前言 现在大企业用的办公IM软件中,飞书是口碑最好的,不得不说,字节在开发产品方面,确实有自己独到的竞争力,比如说抖音、头条、飞书。在办公会议和云文档的体验上,其它的办公…...

【Mybatis小白从0到90%精讲】12:Mybatis删除 delete, 推荐使用主键删除!
文章目录 前言XML映射文件方式推荐使用主键删除注解方式工具类前言 在实际开发中,我们经常需要删除数据库中的数据,MyBatis可以使用XML映射文件或注解来编写删除(delete)语句,下面是两种方法的示例。 XML映射文件方式 Mapper: int delete(int id);Mapper.xml:...

RocketMQ批量发送消息❓
优点: 批量发送消息可以提高rocketmq的生产者性能和吞吐量。 使用场景: 发送大量小型消息时;需要降低消息发送延迟时;需要提高生产者性能时; 注意事项: 消息列表的大小不能超过broker设置的最大消息大小;消息列表…...

一键同步chromedriver版本
ChromeDriver是一个控制Chrome浏览器的驱动程序,它和Selenium一起被广泛用于Web自动化测试。然而,随着Chrome版本的升级,我们需要不断更新ChromeDriver以保持其与Chrome的兼容性。这个过程既费时又繁琐,而且对于非技术人员来说可能…...
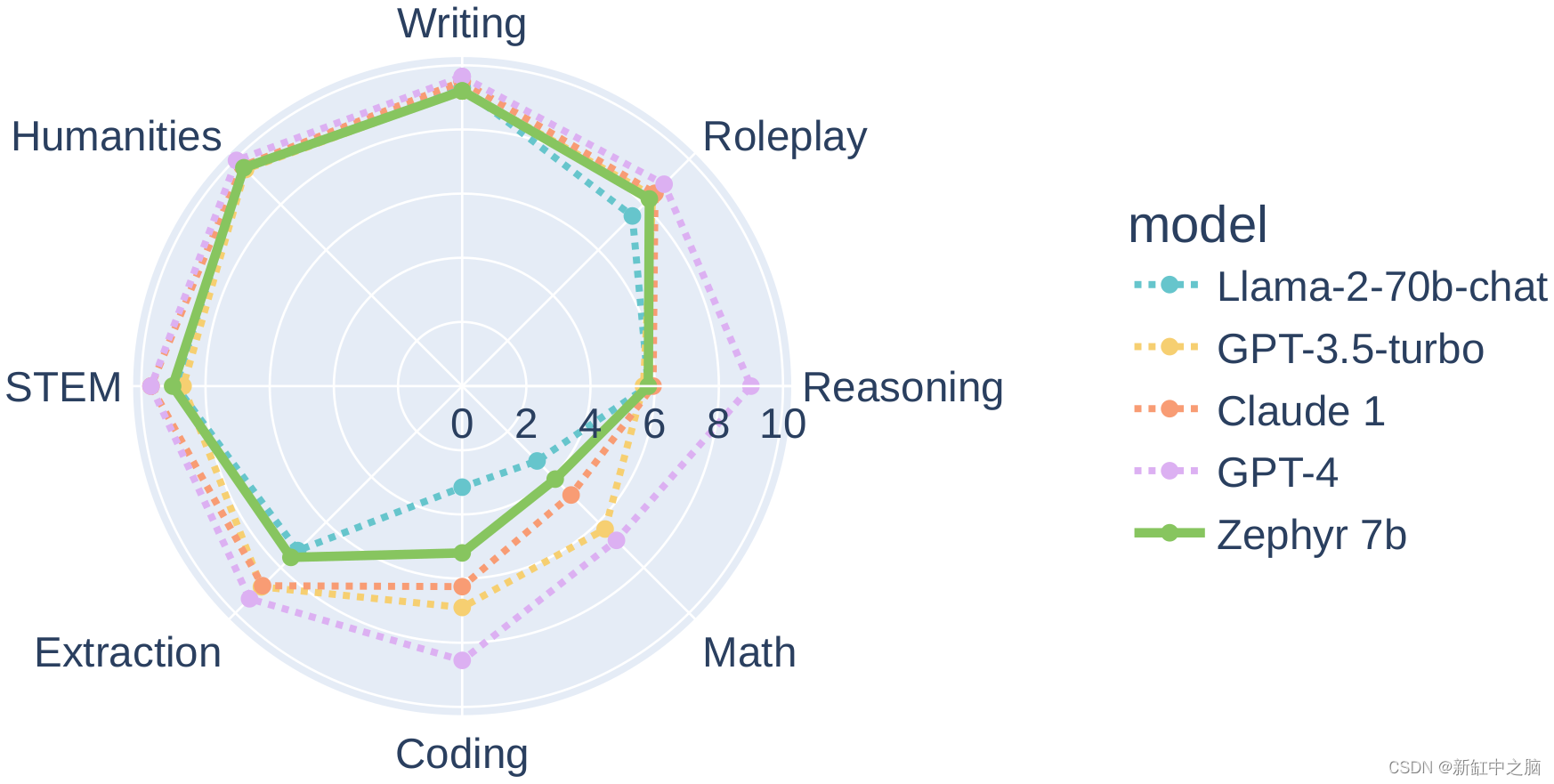
Zephyr-7B-β :类GPT的高速推理LLM
Zephyr 是一系列语言模型,经过训练可以充当有用的助手。 Zephyr-7B-β 是该系列中的第二个模型,是 Mistralai/Mistral-7B-v0.1 的微调版本,使用直接偏好优化 (DPO) 在公开可用的合成数据集上进行训练 。 我们发现,删除这些数据集的…...

【笔试题】位运算
记录一些常见的位运算题: 1、实现对一个8bit数据(unsigned char类型)的指定位(例如第n位)置0或者置1操作,并保持其他地位不变。 unsigned char reg;/* 对第n位置0 */ reg &~ (1 << n);/* 对第n位…...
RT-Thread 10. 使用keil4编译GD32F450
1. 修改keil路径 2.增加MCU型号宏定义 3. 在ENV界面输入 scons -c scons --targetmdk44. 编译 scons --verbose提示错误 Warning: L6310W: Unable to find ARM libraries. Error: L6411E: No compatible library exists with a definition of startup symbol __main. Finish…...

Vue 跨域的两种解决方式
一、通过 proxy 解决跨域 1.1 baseURL 配置 对 axios 二次封装时,baseURL 设置为 /api。 const serviceAxios axios.create({baseURL: /api,timeout: 10000, // 请求超时设置withCredentials: false, // 跨域请求是否需要携带 cookie });1.2 vue.config.js 配置…...

【windows Docker 安装mysql:只需3条命令】
如下 docker pull mysql docker run --name mysql -p 3306:3306 -v D:/dockerFile/mysql/data:/var/lib/mysql/ -v D:/dockerFile/mysql/conf/my.cnf:/etc/mysql/my.cnf -e MYSQL_ROOT_PASSWORDroot -d mysql:latest --default-authentication-pluginmysql_native_password do…...
【软件逆向】如何逆向Unity3D+il2cpp开发的安卓app【IDA Pro+il2CppDumper+DnSpy+AndroidKiller】
教程背景 课程作业要求使用反编译技术,在游戏中实现无碰撞。正常情况下碰撞后角色死亡,修改为直接穿过物体不死亡。 需要准备的软件 il2CppDumper。DnSpy。IDA Pro。AndroidKiller。 一、使用il2CppDumper导出程序集 将{my_game}.apk后缀修改为{my_…...

vue3ref和reactive
Vue 3中的ref和reactive是两个重要的响应式API。 ref用于将基本数据类型转换为响应式数据,它返回一个包含value属性的响应式对象。ref适合用于单个值的响应式需求,例如计数器、表单数据等。示例代码: <template><div><p>…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...

3步快速解密中兴光猫配置:ZET工具终极实战指南
3步快速解密中兴光猫配置:ZET工具终极实战指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 中兴光猫配置解密工具是每个网络管理员必备的神器!Z…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...