mysql数据库的备份和恢复
目录
一、备份和恢复
1、备份:
2、备份的方法:
2.1物理备份:
2.2、逻辑备份
2.3增量备份:
一、备份和恢复
1、备份:
先备份再恢复
备份:完全备份,增量备份
完全备份:将整个数据库完整的进行备份
增量备份:在完全备份的基础之上,对后续新增的内容进行备份
备份的需求:
- 在生产环境中,数据的安全至关重要,任何数据的丢失都可能产生严重的后果。
- 数据为什么会丢失?可能是程序操作,运算错误,磁盘故障,不可预期的事件(地震之类),人为操作等。
2、备份的方法:
冷备份:关机备份,停止mysql服务,然后进行备份
热备份:开机备份,无需关闭mysql服务,然后进行备份
物理备份:对数据库系统的物理文件(数据文件,日志文件,)进行备份
逻辑备份:只是对数据库的逻辑组件进行备份(表结构),以sql语句的形式,把库,表结构以及表数据进行备份保存。(直接在数据库系统中删除全部文件,逻辑备份无法恢复)
2.1物理备份:
一般采用完全备份,对整个数据库进行完整的打包备份
优点:操作简单
缺点:数据库文件占用量是很大的,占用空间太大,备份和恢复的时间都很长,而且需要暂停数据库服务
创建两个库,两张表
安装打包软件:
yum -y install xz
恢复必须建立在备份的基础上
打包备份:
#压缩备份 tar Jcvf /opt/mysql_all_$(date +%F).tar.xz /usr/local/mysql/data/
将/usr/local/mysql/data/目录备份打包到/opt/

解压:
#解压恢复 tar Jxvf /opt/mysql_all_2023-11-06.tar.xz


删库跑路:支持物理删除
删除/usr/local/mysql/data数据库目录:

恢复还原:
之后将备份解压出来的/opt/usr/local/mysql/data,将最后的data目录复制到真正的mysql目录下。/usr/local/mysql/
cp -a usr/local/mysql/data/ /usr/local/mysql/
systemctl restart mysqld.service
检测恢复情况:
数据库迁移:
这里复制过来的所属权限要改一下:
chown -R mysql.mysql data

打包备份最好关闭服务。避免新的数据进入被覆盖,也可能会报错导致恢复失败
如何把本地的数据库迁移上云?
开放式问题:除了演示的之外还有什么方法上云
dts工具支持热迁移。
2.2、逻辑备份
热备份当中的逻辑备份:
这时mysql自带的工具:mysqldump
只能在终端执行
1、备份单个库:
mysqldump -u root -p123456 --databases 库名 > /opt/ku1.sql
结尾必须是.sql
2、备份多个库:
mysqldump -u root -p123456 --databases 库名1 库名2 > /opt/ku1ku2.sql
3、备份全部库:
mysqldump -u root -p123456 --all-databases > /opt/allku.sql
恢复还原:
mysql -u root -p < /opt/sql文件名
热备份开着服务备份:
先看服务起没起,端口起没起
rm -rf data,物理删除,不能恢复
只能逻辑方式删除:命令行删除
mysql -u root -p123456 -e 'show databases;'
mysql -e:执行完一次之后自动退出
逻辑删除库:
恢复还原:
备份还原多个库:
备份:
mysqldump -u root -p --databases ku ku1 > /opt/kuku1.sql
删除库:
多个库一起恢复:
恢复指定库和指定表:
要先指定库或表备份

不进库删除:

恢复:
指定库名进行恢复

恢复多个指定表:
先备份:

删除:

恢复:

检测
异地迁移恢复:
先在主机1备份一个全部备份文件
主机2远程复制:

直接恢复:

可以用sql语句的方式直接备份恢复
实验:mysql1的全部数据库的逻辑备份文件,导入到mysql2,那么有重名的库是否会覆盖,不重名的库是否还在。
总结:
物理冷备份和物理热备份
特点:简单
缺点:占用的备份空间比较大
mysqldump:这是mysql自带的备份文件的命令
特点:方便,简单。但是只能基于逻辑上的表结构表数据恢复。物理删除之后再用逻辑恢复会报错
他也可以作为数据迁移。也会占用大空间。
比较物理备份相对来说占的空间要小的多
2.3增量备份:
新增的数据进行备份
增量备份用的也是mysqldump
特点:没有重复数据,备份量小,时间短
mysqldump增量备份恢复表数据期间,表会锁定。
缺点:备份时锁表,必然会影响业务。超过10G大小时,耗时会比较长,导致服务不可用
增量备份的过程:
- mysql提供的一种二进制日志实现增量备份。
二进制文件怎么来?
修改配置文件:/etc/my.cnf
log-bin=mysql-bin
binlog_format=MIXED
重启服务
mysql二进制日志记录格式有三种:
- STATEMENT:基于sql语句
记录修改的sql语句,在高并发情况下记录sql语句的顺序可能会出错,恢复数据时,可能会导致丢失和误差。效率比较高
- ROW:基于行
精准记录每一行的数据,准确率高,但是恢复的时效率低
- MIXED:既可以根据sql语句,也可以根据行
在正常情况下使用STATEMENT,一旦发生高并发,会智能自动切换到ROW行
先建表插入几个数据,再修改配置文件,重启服务
二进制文件所在目录:
/usr/local/mysql/data

之后表中新加入内容:
查看二进制内容命令:
mysqlbinlog --no-defaults --base64-output=decode-rows -v mysql-bin.000002
刷新命令:会新增一个二进制文件
mysqladmin -u root -p flush-logs

把增量的部分删除:
断点,每次刷新会生成新的一个二进制文件
恢复:
mysqlbinlog --no-defaults --base64-output=decode-rows -v mysql-bin.000003
注意的是要恢复的二进制文件是哪个文件
位置恢复和时间恢复
基于位置点来进行恢复:
1、从某一个点开始恢复到最后
mysqlbinlog --no-defaults --start-position='位置点' 文件名 | mysql -u root -p123456
2、从开头一直恢复到某个位置
mysqlbinlog --no-defaults --stop-position='位置点' 文件名 | mysql -u root -p
3、从指定点开始———指定结束点
mysqlbinlog --no-defaults --start-position='位置点' --stop-position'位置点' 文件名 | mysql -u root -p
打个新的断点,防止写入要操作的断点
查看位置点:
at后面的数字就是位置点
选commit后面的位置点
操作实验:
先mysqladmin -u root -p flush-logs
先刷新出一个二进制备份文件000001
然后创建一个新表test
这样创建的数据1-4都会记录到00001中
然后再mysqladmin -u root -p flush-logs
刷新一个000002二进制备份文件
对表进行操作:新插入5-8
插入5-8的操作就记录在二进制文件000002中
断点会记录所有新增操作,直到下一次新增断点,新操作会记录到新增断点中
再基于位置点恢复的话,是基于二进制备份文件的操作对表进行新增操作,不会像物理和逻辑备份一样,完全清空表的内容。是基于目前表来进行操作。下面的基于时间点操作同理。
基于时间点来进行恢复
- 从某个时间点开始
mysqlbinlog --no-defaults --start-datetime='时间点' 文件 | mysql -u root -p
- 从开头,到指定的结尾时间点
mysqlbinlog --no-defaults --stop-datetime='时间点' 文件 | mysql -u root -p
- 指定时间范围:
mysqlbinlog --no-defaults --start-datetime='时间点' --stop-datetime='时间点' 文件 | mysql -u root -p
查看时间点:
时间格式YYYY-MM-DD HH:MM:SS
基于时间点内的操作:

总结:
在生产中,通过binlog进行增量恢复是非常好用的方法
我们只需要对binlog文件进行备份,随时可以进行备份和恢复
附加题:写一个脚本,每个月的20号对数据库,打一个断点。
断点之后自动进行增量备份
如何打开mysql的默认日志:
打开/etc/my.cnf
错误日志单独记录:
记录通用访问日志:
记录慢查询日志:指定慢查询时间,超过5s才会记录
重启即生效
日志文件在data目录下
MySQL 的日志默认保存位置为 /usr/local/mysql/data
vim /etc/my.cnf
[mysqld]
##错误日志,用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启
log-error=/usr/local/mysql/data/mysql_error.log #指定日志的保存位置和文件名
##通用查询日志,用来记录MySQL的所有连接和语句,默认是关闭的
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
##二进制日志(binlog),用来记录所有更新了数据或者已经潜在更新了数据的语句,记录了数据的更改,可用于数据恢复,默认已开启
log-bin=mysql-bin #也可以 log_bin=mysql-bin
##慢查询日志,用来记录所有执行时间超过long_query_time秒的语句,可以找到哪些查询语句执行时间长,
以便于优化,默认是关闭的
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5 #设置超过5秒执行的语句被记录,缺省时为10秒
systemctl restart mysqld
mysql -u root -p
show variables like 'general%'; #查看通用查询日志是否开启
show variables like 'log_bin%'; #查看二进制日志是否开启
show variables like '%slow%'; #查看慢查询日功能是否开启
show variables like 'long_query_time'; #查看慢查询时间设置
set global slow_query_log=ON; #在数据库中设置开启慢查询的方法
实验:
数据库迁移上云:
1、整体备份
2、sql文件 如果复制到另外一个库,不是重名命的库,是否会被覆盖,相同的表名会不会覆盖,相同的库名会不会覆盖
3、增量备份,位置节点和时间点,注意一下断点
4、一个工具:xtrabackup(DTS)
5、使用工具,要有完整的流程,从安装 使用 备份 结果 报错记录下来,形成文档。
附加题:
写一个脚本,每个月的20号,对数据库打一个断点。
断点之后进行自动进行增量备份。
相关文章:
mysql数据库的备份和恢复
目录 一、备份和恢复 1、备份: 2、备份的方法: 2.1物理备份: 2.2、逻辑备份 2.3增量备份: 一、备份和恢复 1、备份: 先备份再恢复 备份:完全备份,增量备份 完全备份:将整个…...

动态IP和静态IP哪个安全,该怎么选择
随着互联网的普及,越来越多的人开始关注网络安全问题。其中,IP地址作为网络通信中的重要组成部分,也成为了人们关注的焦点。 在IP地址中,动态IP和静态IP是两种不同的分配方式,它们各自具有不同的特点,那么…...

linux复习笔记03(小滴课堂)
find命令: d查找目录: 按照文件权限查找: 600全部权限: -user根据所属主: 上面的例子是找出文件并打印有多少行。 我们也可以把我们查询到的结果复制到其它文件位置中去: 复制成功。 -mtime根据修改时间…...
webgoat-Broken Access ControlI 访问控制失效
Insecure Direct Object References 直接对象引用 直接对象引用是指应用程序使用客户端提供的输入来访问数据和对象。 例子 使用 GET 方法的直接对象引用示例可能如下所示 https://some.company.tld/dor?id12345 https://some.company.tld/images?img12345 https://some.…...

Beaustiful Soup爬虫案例
文章目录 1 第三方库2 爬取2.1 初始化函数2.2 结束时关闭数据库2.3 生成header2.4 获取请求body2.5 解析异步json数据2.6 使用BS4的find方法解析2.7 写入口函数2.8 调用 3 完整代码 1 第三方库 获取随机UA pip install fake-useragent连接数据库 $ pip3 install PyMySQL发起…...
【Redis】Redis与SSM整合Redis注解式缓存Redis解决缓存问题
一,Redis与ssm整合 1.1 pom.xml配置 在pom.xml中配置相关的redis文件 redis文件: <redis.version>2.9.0</redis.version> <redis.spring.version>1.7.1.RELEASE</redis.spring.version><dependency><groupId>red…...

谈一谈SQLite、MySQL、PostgreSQL三大数据库
每一份付出,必将有一份收货,就像这个小小的果实,时间到了,也就会开花结果… 三大数据库概述 SQLite、MySQL 和 PostgreSQL 都是流行的关系型数据库管理系统(RDBMS),但它们在功能、适用场景和性…...

【微软技术栈】C#.NET 中的本地化
本文内容 资源文件注册本地化服务使用 IStringLocalizer<T> 和 IStringLocalizerFactory将其放在一起 本地化是针对应用支持的每个区域性,将应用资源转换为本地化版本的过程。 只有在完成本地化评审步骤,以验证全球化应用是否做好本地化准备后&a…...
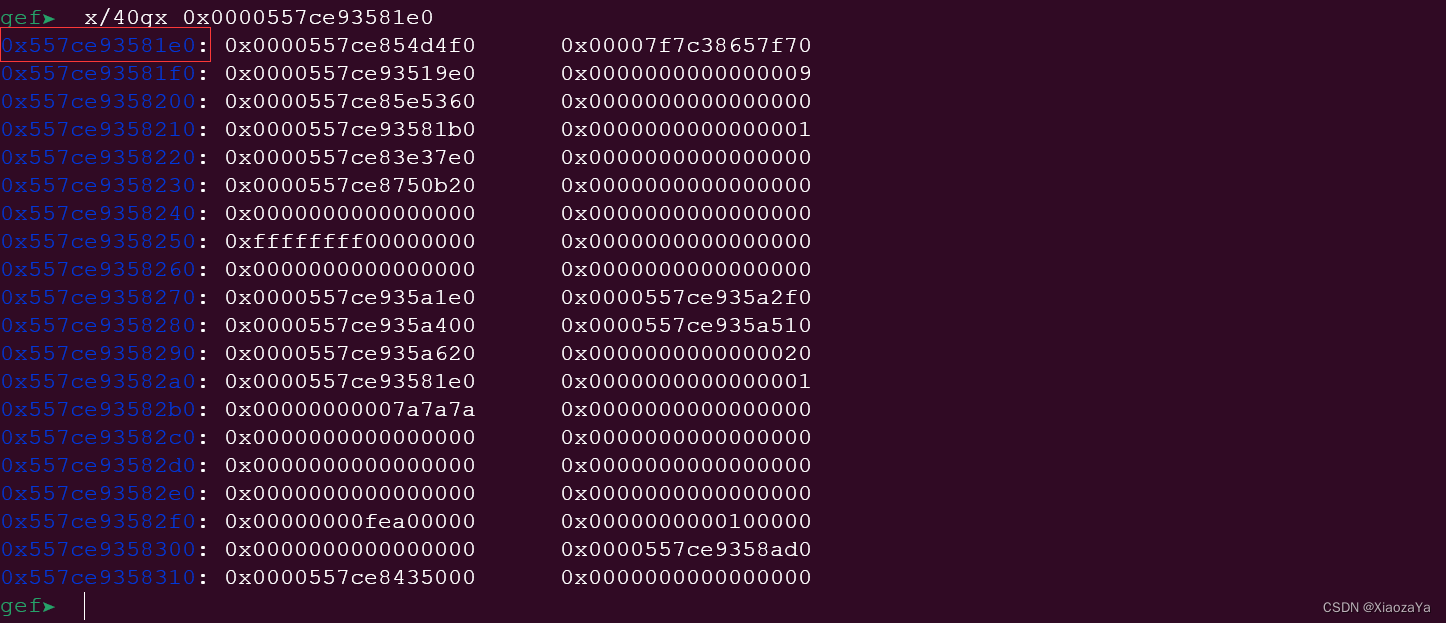
【qemu逃逸】华为云2021-qemu_zzz
前言 虚拟机用户名:root 无密码 设备逆向 经过逆向分析,可得实例结构体大致结构如下: 其中 self 指向的是结构体本身,cpu_physical_memory_rw 就是这个函数的函数指针。arr 应该是 PCI 设备类结构体没啥用,就直接用…...

vue递归获取树形菜单
文章目录 前言什么是递归? 一、数据集二、 递归函数三、打印树形结构展示 前言 什么是递归? 程序调用自身的编程技巧称为递归( recursion)。 递归 粗略的理解为 循环 ,只不过 递归 是调用自身。 在实际使用中…...

[ubuntu]ubuntu22.04默认源和国内源
sudo vi /etc/apt/sources.list 请选择和系统对应的版本,查看系统版本命令: lsb_release -a Distributor ID: Ubuntu Description: Ubuntu 22.04 LTS Release: 22.04 Codename: jammy Ubuntu不同的版本配置的有…...

Map和ForEach的区别,For in和For of的区别
Map和ForEach的区别: 共同点:都可以遍历数组,this指向window,都不会改变原数组。 不同点:map返回一个数组,不会对空数组进行检测,如果是空数组map的话还是返回一个空数组,而空数组…...

json字符串属性名与实体类字段名转换
在项目开发过程中,会遇到实体类字段名与交互的json对象属性名不一致的情况,比如前段使用的是下划线方式定义,后端采用的是驼峰式定义,其他系统使用t表示一个时间戳,自己的系统使用timestamp定义。遇到这种情况…...

Vue Vuex模块化编码
正常写vuex的index的时候如果数据太多很麻烦,如有的模块是管理用户信息或修改课程等这两个是不同一个种类的,如果代码太多会造成混乱,这时候可以使用模块化管理 原始写法 如果功能模块太多很乱 import Vue from vue import Vuex from vuex …...

消费者忠诚度研究:群狼调研帮您制定忠诚客户计划
在当今竞争激烈的市场环境中,消费者忠诚度对于企业的成功至关重要。消费者忠诚度不仅关系到企业的市场份额和盈利能力,还直接影响着企业的品牌形象和声誉。群狼调研作为一家专业的市场研究机构,专注于消费者忠诚度研究,为企业提供…...

接口幂等性详解
1. 什么是幂等性 幂等性指的是对同一个操作的多次执行所产生的影响与一次执行的影响相同。无论操作执行多少次,系统状态都应该保持一致。 在计算机科学和网络领域中,幂等性通常用来描述服务或操作的特性。对于RESTful API或HTTP方法,一个幂…...

Java操作redis常见类型数据存储
一,Java连接Redis 1.1 导入依赖 打开IDEA在pom.xml导入依赖 注意:要在dependencies标签中导入 <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version> &…...
【深度学习】pytorch——Autograd
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ 深度学习专栏链接: http://t.csdnimg.cn/dscW7 pytorch——Autograd Autograd简介requires_grad计算图没有梯度追踪的张量ensor.data 、tensor.detach()非叶子节点的梯度计算图特点总结 利用Autograd实…...

【ARM 安全系列介绍 1 -- 奇偶校验与海明码校验详细介绍】
文章目录 奇偶校验介绍奇偶校验 python 实现奇偶校验C代码实现 海明码详细介绍 奇偶校验介绍 奇偶校验是一种错误检测方法,广泛应用于计算机内部以及数据通信领域。其基本原理是为了使得一组数据(通常是一字节8位)中的“1”的个数为偶数或奇…...

分享34个发布商会PPT,总有一款适合您
分享34个发布商会PPT,总有一款适合您 链接:https://pan.baidu.com/s/1jP9toqTZONWeDIcxvw1wxg?pwd8888 提取码:8888 Python采集代码下载链接:采集代码.zip - 蓝奏云 学习知识费力气,收集整理更不易。知识付费甚…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

基于雷达与光敏传感器的低功耗智能窗防设备设计与实现
1. 项目概述:一个基于雷达与光敏的智能窗防设备几年前,我因为一次短暂的出差,家里空置了几天,回来后就一直琢磨着怎么给家里的窗户加点“动静”。市面上的智能安防摄像头固然好,但要么需要复杂的布线,要么云…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

OpenRASP原理与实战:Java应用层实时防护技术详解
1. 为什么我宁愿花三天部署OpenRASP,也不愿再写第五个自定义WAF过滤器去年冬天,我在给一家做在线教育SaaS平台做安全加固时,连续踩了三个坑:第一次用NginxLua写了套SQL注入规则,结果学生提交的“SELECT * FROM courses…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...