数据分析实战 | 关联规则分析——购物车分析
目录
一、数据及分析对象
二、目的及分析任务
三、方法及工具
四、数据读入
五、数据理解
六、数据预处理
七、生成频繁项集
八、计算关联度
九、可视化
一、数据及分析对象
数据集链接:Online Retail.xlsx
该数据集记录了2010年12月01日至2011年12月09日的541909条在线交际记录,包含以下8个属性:
(1)InvoiceNo:订单编号,由6位整数表示,退货单号由字母“C”开头;
(2)StockCode:产品编号,每个不同的产品由不重复的5位整数表示;
(3)Description:产品描述;
(4)Quantity:产品数量,每笔交易的每件产品的数量;
(5)InvoiceDate:订单日期和时间,表示生成每笔交易的日期和时间;
(6)UnitPrice:单价,每件产品的英镑价格;
(7)CustomerID:顾客编号,每位客户由唯一的5位整数表示;
(8)Country:国家名称,每位客户所在国家/地区的名称。
二、目的及分析任务
理解Apriori算法的具体应用
(1)计算最小支持度为0.07的德国客户购买产品的频繁项集。
(2)计算最小置信度为0.8且提升度不小于2的德国客户购买产品的关联关系。
三、方法及工具
能够实现Aprior算法的Python第三方工具包有mlxtend、kiwi-apriori、apyori、apriori_python、efficient-apriori等,比较常用的是mlxtend、apriori_python、efficient-apriori,本项目采用的是mlxtend包。
四、数据读入
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rulesdf_Retails=pd.read_excel("C:\\Users\\LEGION\\AppData\\Local\\Temp\\360zip$Temp\\360$0\\Online Retail.xlsx")
df_Retails.head()
五、数据理解
调用shape属性查看数据框df_Retails的形状。
df_Retails.shape![]()
查看列名称
df_Retails.columnsIndex(['InvoiceNo', 'StockCode', 'Description', 'Quantity', 'InvoiceDate','UnitPrice', 'CustomerID', 'Country'],dtype='object')
对数据框df_Retails进行探索性分析。
df_Retails.describe()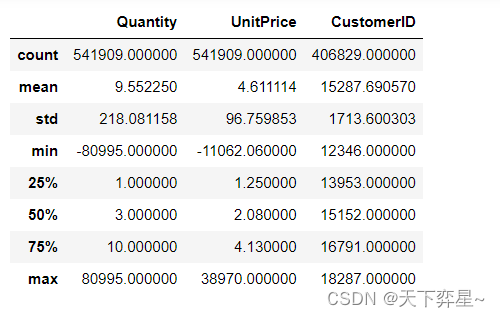
其中,count、mean、std、min、25%、50%、75%和max的含义分别为个数、均值、标准差、最小值、上四分位数、中位数、下四分位数和最大值。
除了describe()方法,还可以调用info()方法查看样本数据的相关信息概览:
df_Retails.info()
从输出结果可以看出,数据框df_Retails的Description和CustomerID两列有缺失值。
看国家一列:
df_Retails.Country.unique()array(['United Kingdom', 'France', 'Australia', 'Netherlands', 'Germany','Norway', 'EIRE', 'Switzerland', 'Spain', 'Poland', 'Portugal','Italy', 'Belgium', 'Lithuania', 'Japan', 'Iceland','Channel Islands', 'Denmark', 'Cyprus', 'Sweden', 'Austria','Israel', 'Finland', 'Bahrain', 'Greece', 'Hong Kong', 'Singapore','Lebanon', 'United Arab Emirates', 'Saudi Arabia','Czech Republic', 'Canada', 'Unspecified', 'Brazil', 'USA','European Community', 'Malta', 'RSA'], dtype=object)
df_Retails["Country"].unique()array(['United Kingdom', 'France', 'Australia', 'Netherlands', 'Germany','Norway', 'EIRE', 'Switzerland', 'Spain', 'Poland', 'Portugal','Italy', 'Belgium', 'Lithuania', 'Japan', 'Iceland','Channel Islands', 'Denmark', 'Cyprus', 'Sweden', 'Austria','Israel', 'Finland', 'Bahrain', 'Greece', 'Hong Kong', 'Singapore','Lebanon', 'United Arab Emirates', 'Saudi Arabia','Czech Republic', 'Canada', 'Unspecified', 'Brazil', 'USA','European Community', 'Malta', 'RSA'], dtype=object)
查看各国家的购物数量:
df_Retails["Country"].value_counts()United Kingdom 495478 Germany 9495 France 8557 EIRE 8196 Spain 2533 Netherlands 2371 Belgium 2069 Switzerland 2002 Portugal 1519 Australia 1259 Norway 1086 Italy 803 Channel Islands 758 Finland 695 Cyprus 622 Sweden 462 Unspecified 446 Austria 401 Denmark 389 Japan 358 Poland 341 Israel 297 USA 291 Hong Kong 288 Singapore 229 Iceland 182 Canada 151 Greece 146 Malta 127 United Arab Emirates 68 European Community 61 RSA 58 Lebanon 45 Lithuania 35 Brazil 32 Czech Republic 30 Bahrain 19 Saudi Arabia 10 Name: Country, dtype: int64
可以看出,英国的客户购买商品数量最多,为495478条记录,其次是德国的客户,为9495条记录。
查看订单编号(InvoiceNo)一列中是否有重复的值。
df_Retails.duplicated(subset=["InvoiceNo"]).any()True
订单编号有重复表示同一个订单中有多个同时购买的产品,符合Apriori算法的数据要求。
六、数据预处理
查看数据中是否有缺失值。
df_Retails.isna().sum()InvoiceNo 0 StockCode 0 Description 1454 Quantity 0 InvoiceDate 0 UnitPrice 0 CustomerID 135080 Country 0 dtype: int64
可以看出,Description的缺失值有1454条,CustomerID的缺失值有135080条。
将商品名称(Description)一列的字符串头尾的空白字符删除:
df_Retails['Description']=df_Retails['Description'].str.strip()再次查看数据集形状;
df_Retails.shape(541909, 8)
查看商品名称(Description)一列的缺失值个数:
df_Retails['Description'].isna().sum()1455
在对商品名称(Description)一列进行空白字符处理后,缺失值增加了一个。去除所有的缺失值:
df_Retails.dropna(axis=0,subset=['Description'],inplace=True)再次查看数据集形状:
df_Retails.shape(540454, 8)
检查此时的数据集是否还有缺失值:
df_Retails['Description'].isna().sum()0
可以看出,数据框df_Retails中商品名称(Description)一列的缺失值已全部删除。
由于退货的订单由字母“C”开头,删除含有C字母的已取消订单:
df_Retails['InvoiceNo']=df_Retails['InvoiceNo'].astype('str')
df_Retails=df_Retails[~df_Retails['InvoiceNo'].str.contains('C')]df_Retails.shape(531166, 8)
将数据改为每一行一条记录,并考虑到内存限制以及德国(Germany)的购物数量位居第二,因此在本项目中只计算德国客户购买的商品的频繁项集及关联规则,全部计算则计算量太大。
df_ShoppingCarts=(df_Retails[df_Retails['Country']=="Germany"].groupby(['InvoiceNo','Description'])['Quantity'].sum().unstack().reset_index().fillna(0).set_index('InvoiceNo'))
df_ShoppingCarts.shape(457, 1695)
df_ShoppingCarts.head()
德国的购物记录共有457条,共包含1695件不同的商品。
查看订单编号(InvoiceNo)一列是否有重复的值:
df_Retails.duplicated(subset=["InvoiceNo"]).any()True
订单编号有重复表示同一个订单中有多个同时购买的产品,符合Apriori算法的数据要求。由于apriori方法中df参数允许的值为0/1或True/False,在此将这些项在数据框中转换为0/1形式,即转换为模型可接受格式的数据即可进行频繁项集和关联度的计算。
def encode_units(x):if x<=0:return 0if x>=1:return 1df_ShoppingCarts_sets=df_ShoppingCarts.applymap(encode_units)七、生成频繁项集
mlxtend.frequnet_patterns的apriori()方法可进行频繁项集的计算,将最小支持度设定为0.07:
df_Frequent_Itemsets=apriori(df_ShoppingCarts_sets,min_support=0.07,use_colnames=True)
df_Frequent_Itemsets

查看数据框df_Frequent_Itemsets的形状:
df_Frequent_Itemsets.shape(39, 2)
可以看出,满足最小支持度0.07的频繁项集有39个。
八、计算关联度
将提升度(lift)作为度量计算关联规则,并设置阈值为1,表示计算具有正相关关系的关联规则。该任务由mlxtend.frequent_patterns的association_rules()方法实现:
df_AssociationRules=association_rules(df_Frequent_Itemsets,metric="lift",min_threshold=1)
df_AssociationRules
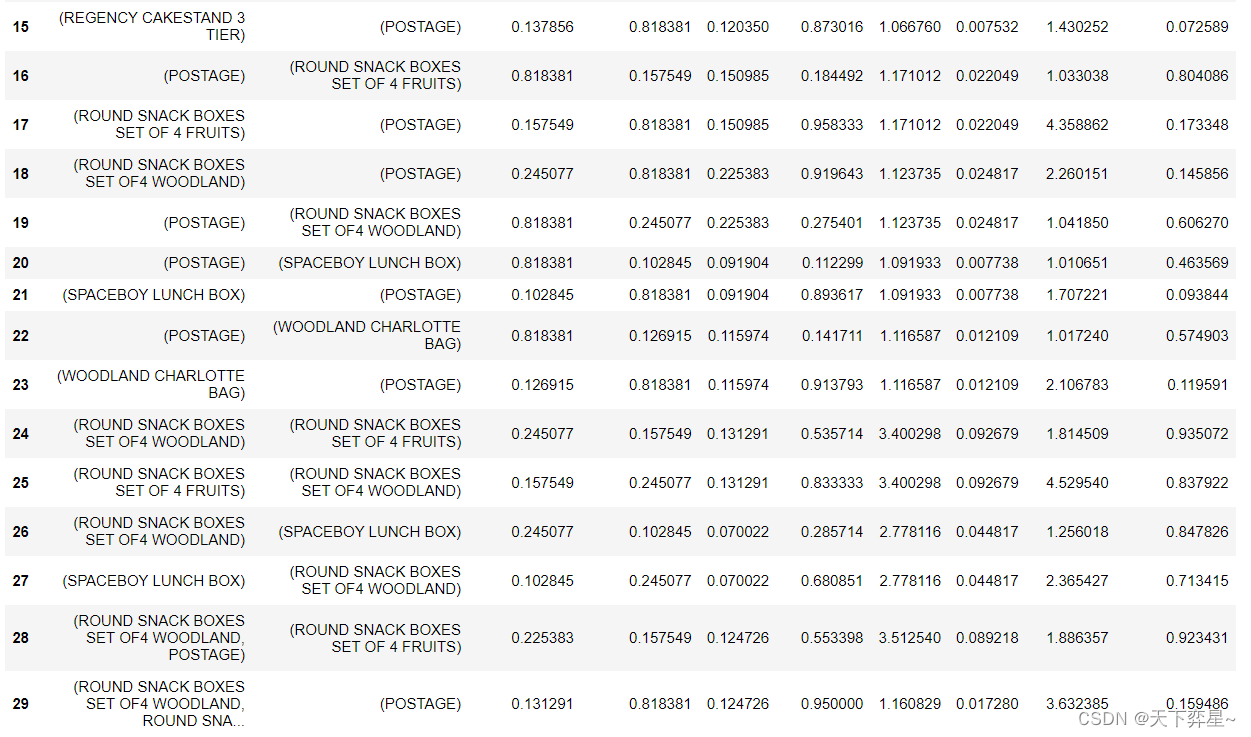

从结果可以看出各项关联规则的详细信息。
以第一条关联规则为{6 RIBBONS RUSTIC CHARM}—>{POSTAGE}为例,{6 RIBBONS RUSTIC CHARM}的支持度为0.102845,{POSTAGE}的支持度为0.818381,项集{{6 RIBBONS RUSTIC CHARM,POSTAGE}的支持度为0.091904,客户购买6 RIBBONS RUSTIC CHARM的同时也购买POSTAGE的置信度为0.893617,提升度为1.091933,规则杠杆率(即当6 RIBBONS RUSTIC CHARM和POSTAGE一起出现的次数比预期多)为0.007738,规则确信度(与提升度类似,但用差值表示,确信度越大则6 RIBBONS RUSTIC CHARM和POSTAGE关联关系越强)为1.707221。
查看数据框df_AssocaitionRules的形状:
df_AssociationRules.shape(34, 10)
可以看出,总共输出了34条关联规则。接着筛选提升度不小于2且置信度不小于0.8的关联规则:
df_A=df_AssociationRules[(df_AssociationRules['lift']>2)&(df_AssociationRules['confidence']>=0.8)]
df_A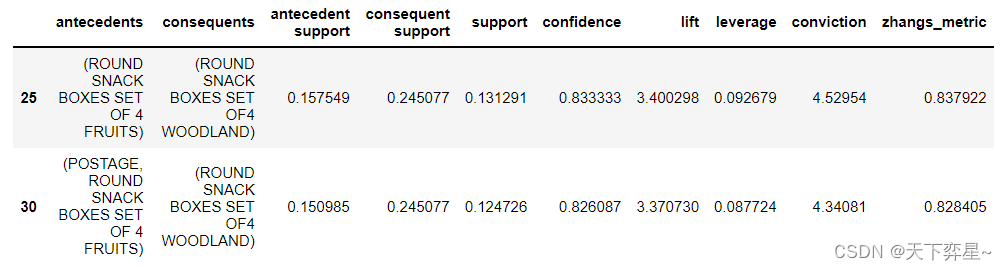
由此可知,提升度不小于2且满足最小置信度0.8的强关联规则有两条,分别为:{ROUND SNACK BOXES SET OF 4 FRUITS}—>{ROUND SNACK BOXES SET OF4 WOODLAND}和{POSTAGE, ROUND SNACK BOXES SET OF 4 FRUITS}—>{ROUND SNACK BOXES SET OF4 WOODLAND}。
九、可视化
绘制出提升度不小于1的关联规则的散点图,横坐标设置为支持度,纵坐标为置信度,散点的大小表示提升度。该可视化任务由matplotlib.pyplot的scatter函数实现:
import matplotlib.pyplot as plt#将点的大小放大20倍
plt.scatter(x=df_AssociationRules['support'],y=df_AssociationRules['confidence'],s=df_AssociationRules['lift']*20) plt.show()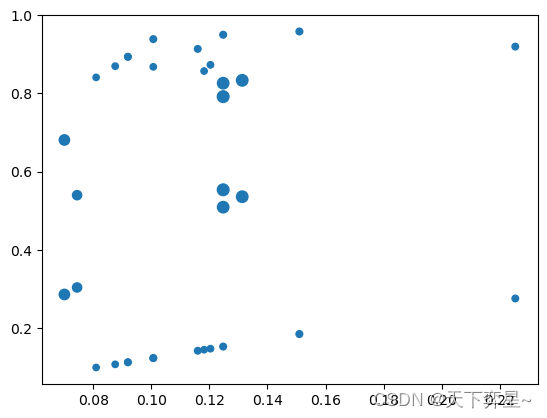
相关文章:
数据分析实战 | 关联规则分析——购物车分析
目录 一、数据及分析对象 二、目的及分析任务 三、方法及工具 四、数据读入 五、数据理解 六、数据预处理 七、生成频繁项集 八、计算关联度 九、可视化 一、数据及分析对象 数据集链接:Online Retail.xlsx 该数据集记录了2010年12月01日至2011年12月09日…...

maven 添加 checkstyle 插件约束代码规范
本例示例,是引用 http 链接这种在线 checkstyle.xml 文件的配置方式,如下示例: <properties><maven.checkstyle.plugin.version>3.3.0</maven.checkstyle.plugin.version><!--支持本地绝对路径、本地相对路径、HTTP远程…...

什么是MySQL的执行计划(Explain关键字)?
什么是Explain Explain被称为执行计划,在语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,模拟MySQL优化器来执行SQL语句,执行查询时,会返回执行计划的信息,并不执行这条SQL。(注意&…...

编码格式科普ASCII unicode utf-8 usc-2 GB2312
1.ASCII(标准版) 可以表示所有英文字符(包括大写和小写)和数字,长度为7bit,最多可以表示0-127 个值,2的7次方个数字。比如比如“a” 对照ASCII码的值为97(十进制)或11000…...

Pycharm中新建一个文件夹下__init__.py文件有什么用
在PyCharm中新建一个文件夹下的__init__.py文件有以下几个作用: 声明文件夹为一个Python包:__init__.py文件的存在告诉Python解释器该文件夹是一个Python包。当你导入该文件夹下的模块时,Python会将其视为一个包而不是普通的文件夹。这允许你…...

OracleBulkCopy c#批量插入oracle数据库的方法
datatable中的数据 存入oracle表中,要求 二者字段名一致,如果不一致,通过这个实现对应: bulkCopy.ColumnMappings.Add("SERVNUMBER", "SN"); 首先要引入Oracle.DataAccess.dll文件(在oracle客户端…...

046_第三代软件开发-虚拟屏幕键盘
第三代软件开发-虚拟屏幕键盘 文章目录 第三代软件开发-虚拟屏幕键盘项目介绍虚拟屏幕键盘 关键字: Qt、 Qml、 虚拟键盘、 qtvirtualkeyboard、 自定义 项目介绍 欢迎来到我们的 QML & C 项目!这个项目结合了 QML(Qt Meta-Object L…...

MySQL主从搭建,实现读写分离(基于docker)
一 主从配置原理 mysql主从配置的流程大体如图: 1)master会将变动记录到二进制日志里面; 2)master有一个I/O线程将二进制日志发送到slave; 3) slave有一个I/O线程把master发送的二进制写入到relay日志里面; 4…...

uni-app android picker选择默认月份
微信小程序选中月份后下次再点开是上次的选中的月份,而编译的android应用只默认当前月份 <picker mode"date" ref"picker" :disabled"disabled" :value"date" fields"month" change"bindDateChange&quo…...
Go 接口-契约介绍
Go 接口-契约介绍 文章目录 Go 接口-契约介绍一、接口基本介绍1.1 接口类型介绍1.2 为什么要使用接口1.3 面向接口编程1.4 接口的定义 二、空接口2.1 空接口的定义2.2 空接口的应用2.2.1 空接口作为函数的参数2.2.2 空接口作为map的值 2.3 接口类型变量2.4 类型断言 三、尽量定…...

变压器试验VR虚拟仿真操作培训提升受训者技能水平
VR电气设备安装模拟仿真实训系统是一种利用虚拟现实技术来模拟电气设备安装过程的培训系统。它能够为学员提供一个真实、安全、高效的学习环境,帮助他们更好地掌握电气设备的安装技能。 华锐视点采用VR虚拟现实技术、MR混合现实技术、虚拟仿真技术、三维建模技术、人…...

Mastering Makefile:模块化编程技巧与经验分享
在Linux项目管理中,Makefile是一个强大的工具,它可以帮助我们自动化编译和测试过程。然而,随着项目的增长,Makefile可能会变得越来越复杂,难以管理。在这篇文章中,我将分享一些模块化编程的技巧和经验&…...
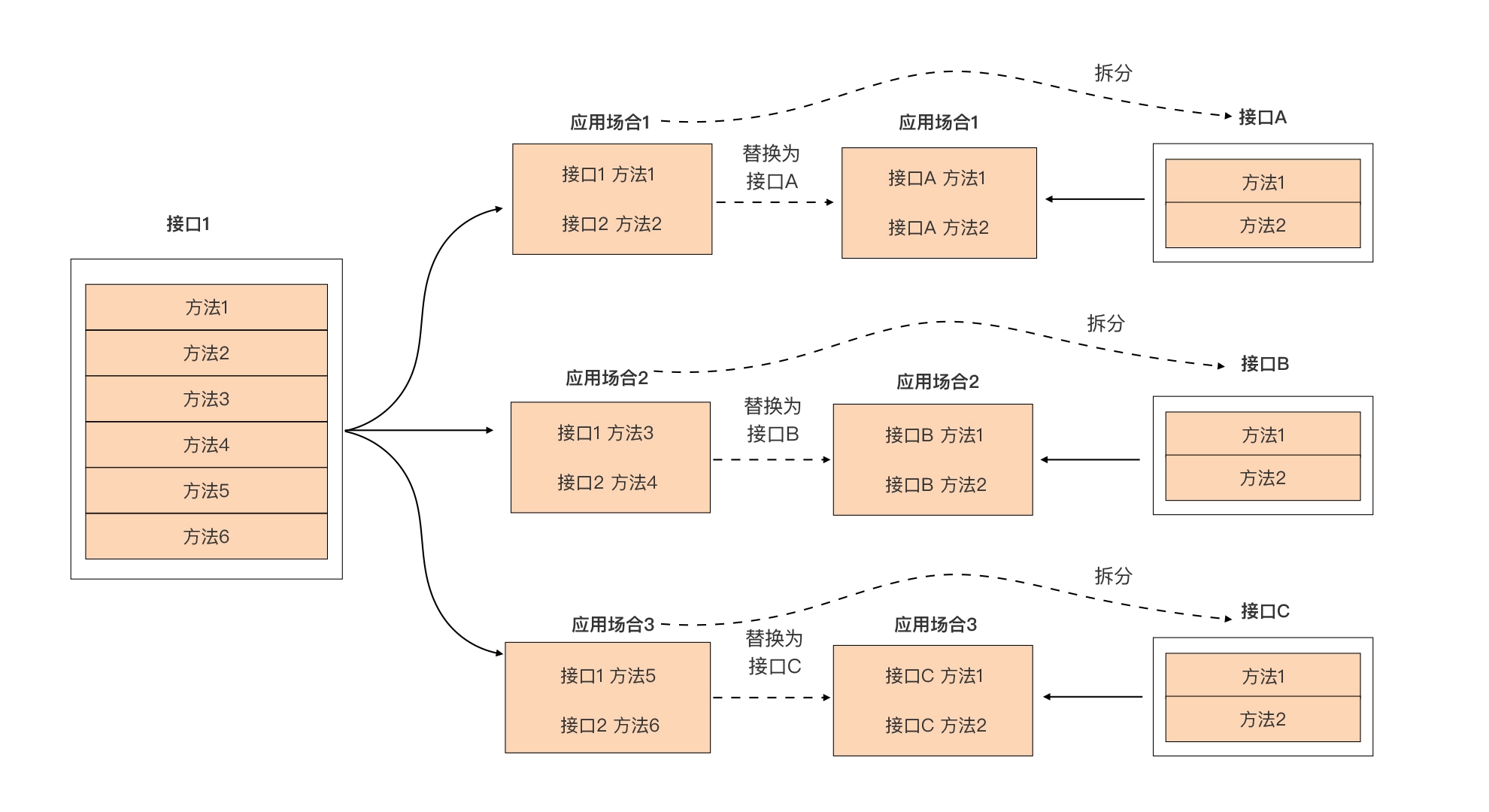
el-input输入校验插件(正则表达式)
使用方法:在main.js文件中注册插件然后直接在<el-input>加入‘v-插件名’ (1)在main.js文件: // 只能输入数字指令 import onlyNumber from /directive/only-number; Vue.use(onlyNumber); (2)在src/directive文件夹中 &a…...
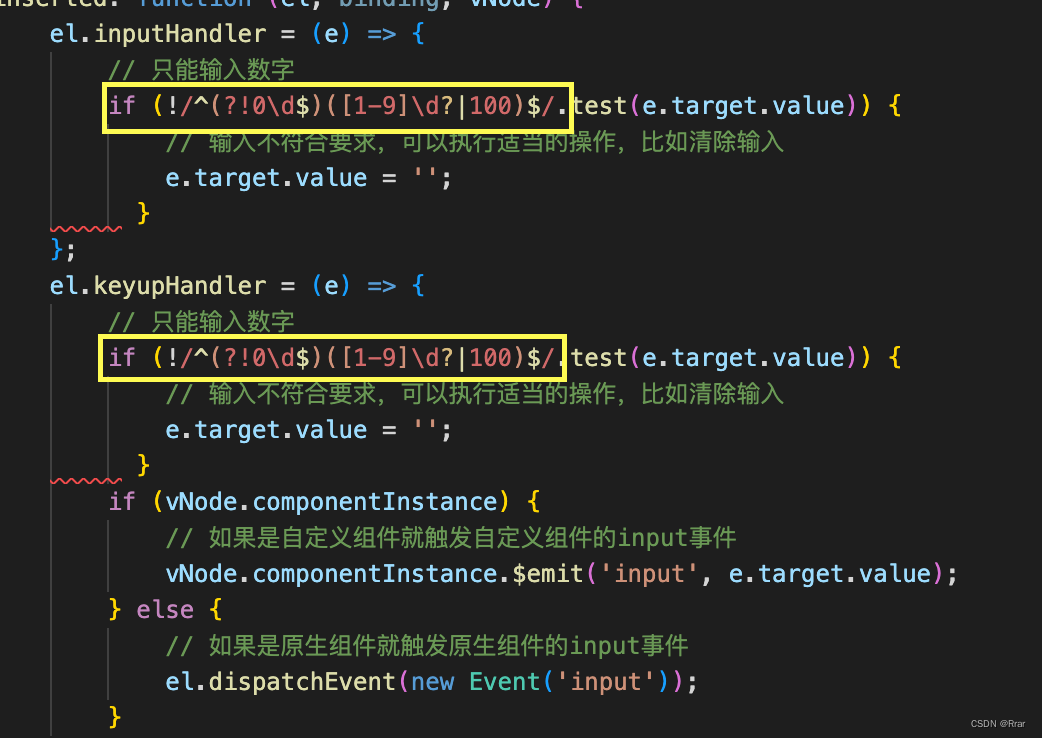
【Matplotlib】plt.plot() X轴横坐标展示完整整数坐标
比如说,我的数据应该是 x轴从2到21的20个整数 y轴对应值 但是直接plot的话x轴显示居然有小数点什么鬼 可以这样改...

左手 Jira,右手 Polarion,驶入互联网和制造业十字路口的新能源汽车
笔者之前一直在互联网公司从事软件研发,创立 Bytebase 之后,才开始接触到各行各业的用户。最近来自汽车行业的客户不少,所以就翻翻相关资料。周末微信收到了一条推送,提到汽车行业的软件研发管理,也由此了解到了 Polar…...

网络安全(黑客)-0基础小白自学
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 2.网络安全市场 一、是市场需求量高; 二、则是发展相对成熟…...

ActiveMQ、RabbitMQ、RocketMQ、Kafka介绍
一、消息中间件的使用场景 消息中间件的使用场景总结就是六个字:解耦、异步、削峰 1.解耦 如果我方系统A要与三方B系统进行数据对接,推送系统人员信息,通常我们会使用接口开发来进行。但是如果运维期间B系统进行了调整,或者推送过…...

unity打AB包,AssetBundle预制体与图集(二)
第二步:加载AB包的资源,用于显示 using System.Collections; using System.Collections.Generic; using System.IO; using UnityEngine; using UnityEngine.Networking; using UnityEngine.U2D; using UnityEngine.UI;public class GameLaunch : MonoBe…...
【网络安全 --- web服务器解析漏洞】IIS,Apache,Nginx中间件常见解析漏洞
一,工具及环境准备 以下都是超详细保姆级安装教程,缺什么安装什么即可(提供镜像工具资源) 1-1 VMware 16.0 安装 【网络安全 --- 工具安装】VMware 16.0 详细安装过程(提供资源)-CSDN博客文章浏览阅读20…...

Python基础——注释、缩进、语法、标识符、关键字
注释 Python中单行注释用#表示,多行注释由3对双引号或单引号包裹:可以使用快捷键CTRLR进行注释 # 我是单行注释"""我是多行注释 """缩进 python使用“缩进”即一行代码前的空白区域确定代码之间的逻辑关系和层次关系。…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

AI大模型应用开发全攻略:从入门到精通,掌握LLM、RAG、Agent核心技能!“
本文全面介绍了AI大模型应用开发的核心技术和实践。从大模型API交互基础,到关键参数Messages和Tools的作用,深入解析了RAG、ReAct、Agent等应用范式。文章还探讨了Fine-tuning微调和Prompt提示词工程的重要性,强调工程实践与业务需求相结合。…...

文件-语言-系统:基础IO-2.0——IO重定向接口,语言层缓冲区,系统级缓冲区。内核级分析!
bit::Shadow✧(≖ ◡ ≖✿ 目录 重定向接口dup2() ">" ">>" "<" 函数原型 输出重定向1和2的使用 文件描述符表 ./a.out运行: "./a.out >"默认重定向是fd 1 合并标准输入输出 缓冲区 什么是缓冲…...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...

Office RibbonX Editor:简单三步打造你的专属Office界面
Office RibbonX Editor:简单三步打造你的专属Office界面 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...