10种聚类算法的完整python操作示例
大家好,聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现数据中的有趣模式,例如基于其行为的客户群。有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。相反,最好探索一系列聚类算法以及每种算法的不同配置。在本教程中,你将发现如何在 python 中安装和使用顶级聚类算法。
看完本文后,你将知道:
聚类是在输入数据的特征空间中查找自然组的无监督问题。
对于所有数据集,有许多不同的聚类算法和单一的最佳方法。
在 scikit-learn 机器学习库的 Python 中如何实现、适配和使用顶级聚类算法。
一、聚类
聚类分析,即聚类,是一项无监督的机器学习任务。它包括自动发现数据中的自然分组。与监督学习(类似预测建模)不同,聚类算法只解释输入数据,并在特征空间中找到自然组或群集。
群集通常是特征空间中的密度区域,其中来自域的示例(观测或数据行)比其他群集更接近群集。群集可以具有作为样本或点特征空间的中心(质心),并且可以具有边界或范围。
聚类还可用作特征工程的类型,其中现有的和新的示例可被映射并标记为属于数据中所标识的群集之一。虽然确实存在许多特定于群集的定量措施,但是对所识别的群集的评估是主观的,并且可能需要领域专家。通常,聚类算法在人工合成数据集上与预先定义的群集进行学术比较,预计算法会发现这些群集。
二、聚类算法
有许多类型的聚类算法。许多算法在特征空间中的示例之间使用相似度或距离度量,以发现密集的观测区域。因此,在使用聚类算法之前,扩展数据通常是良好的实践。
一些聚类算法要求您指定或猜测数据中要发现的群集的数量,而另一些算法要求指定观测之间的最小距离,其中示例可以被视为“关闭”或“连接”。因此,聚类分析是一个迭代过程,在该过程中,对所识别的群集的主观评估被反馈回算法配置的改变中,直到达到期望的或适当的结果。scikit-learn 库提供了一套不同的聚类算法供选择。下面列出了10种比较流行的算法:
亲和力传播
聚合聚类
BIRCH
DBSCAN
K-均值
Mini-Batch K-均值
Mean Shift
OPTICS
光谱聚类
高斯混合
每个算法都提供了一种不同的方法来应对数据中发现自然组的挑战。没有最好的聚类算法,也没有简单的方法来找到最好的算法为您的数据没有使用控制实验。在本教程中,我们将回顾如何使用来自 scikit-learn 库的这10个流行的聚类算法中的每一个。这些示例将为您复制粘贴示例并在自己的数据上测试方法提供基础。我们不会深入研究算法如何工作的理论,也不会直接比较它们。让我们深入研究一下。
三、聚类算法示例
现在我们将讲一下如何在 scikit-learn 中使用10个流行的聚类算法。这包括一个拟合模型的例子和可视化结果的例子。这些示例用于将粘贴复制到您自己的项目中,并将方法应用于您自己的数据。
首先,让我们安装库。不要跳过此步骤,因为你需要确保安装了最新版本。你可以使用 pip Python 安装程序安装 scikit-learn 存储库,如下所示:
pip install scikit-learn接下来,让我们确认已经安装了库,并且您正在使用一个现代版本。运行以下脚本以输出库版本号。
# 检查 scikit-learn 版本
import sklearn
print(sklearn.__version__)我们将使用 make _ classification ()函数创建一个测试二分类数据集。数据集将有1000个示例,每个类有两个输入要素和一个群集。这些群集在两个维度上是可见的,因此我们可以用散点图绘制数据,并通过指定的群集对图中的点进行颜色绘制。
这将有助于了解,至少在测试问题上,群集的识别能力如何。该测试问题中的群集基于多变量高斯,并非所有聚类算法都能有效地识别这些类型的群集。因此,本教程中的结果不应用作比较一般方法的基础。下面列出了创建和汇总合成聚类数据集的示例。
# 综合分类数据集
from numpy import where
from sklearn.datasets import make_classification
from matplotlib import pyplot
# 定义数据集
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 为每个类的样本创建散点图
for class_value in range(2):
# 获取此类的示例的行索引
row_ix = where(y == class_value)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()运行该示例将创建合成的聚类数据集,然后创建输入数据的散点图,其中点由类标签(理想化的群集)着色。我们可以清楚地看到两个不同的数据组在两个维度,并希望一个自动的聚类算法可以检测这些分组。
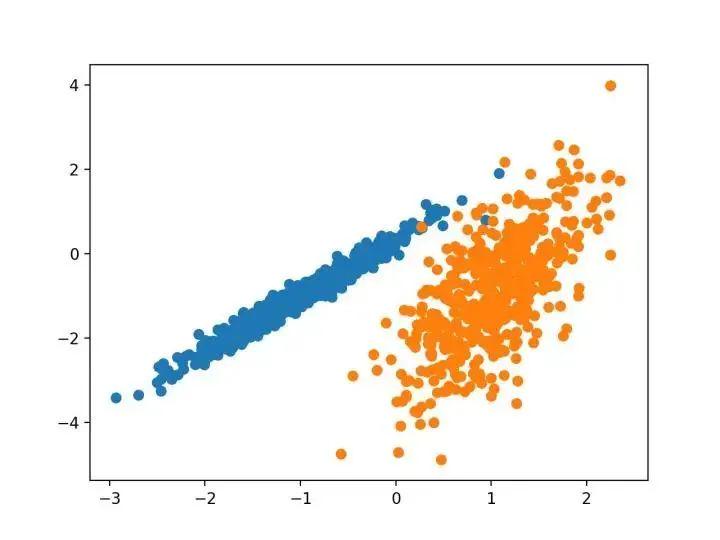
接下来,我们可以开始查看应用于此数据集的聚类算法的示例。我已经做了一些最小的尝试来调整每个方法到数据集。
1.亲和力传播
亲和力传播包括找到一组最能概括数据的范例。它是通过 AffinityPropagation 类实现的,要调整的主要配置是将“ 阻尼 ”设置为0.5到1,甚至可能是“首选项”。
下面列出了完整的示例:
# 亲和力传播聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AffinityPropagation
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = AffinityPropagation(damping=0.9)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
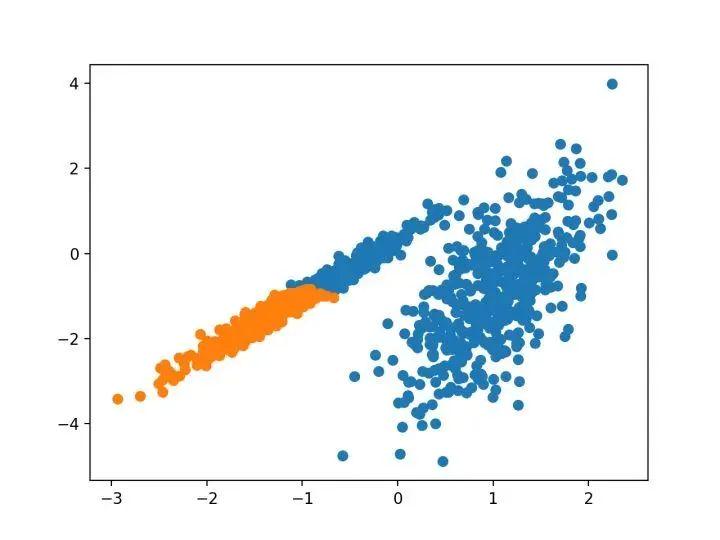
pyplot.show()运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我无法取得良好的结果。
2.聚合聚类
聚合聚类涉及合并示例,直到达到所需的群集数量为止。它是层次聚类方法的更广泛类的一部分,通过 AgglomerationClustering 类实现的,主要配置是“ n _ clusters ”集,这是对数据中的群集数量的估计。下面列出了完整的示例:
# 聚合聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AgglomerativeClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = AgglomerativeClustering(n_clusters=2)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
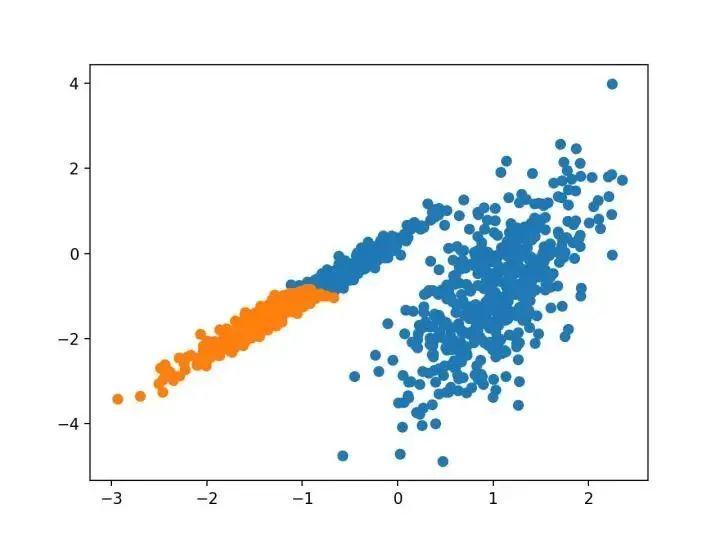
pyplot.show()运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个合理的分组。
3.BIRCH
BIRCH 聚类( BIRCH 是平衡迭代减少的缩写,聚类使用层次结构)包括构造一个树状结构,从中提取聚类质心。它是通过 Birch 类实现的,主要配置是“ threshold ”和“ n _ clusters ”超参数,后者提供了群集数量的估计。下面列出了完整的示例:
# birch聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import Birch
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = Birch(threshold=0.01, n_clusters=2)
# 适配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个很好的分组。
4.DBSCAN
DBSCAN 聚类(其中 DBSCAN 是基于密度的空间聚类的噪声应用程序)涉及在域中寻找高密度区域,并将其周围的特征空间区域扩展为群集。它是通过 DBSCAN 类实现的,主要配置是“ eps ”和“ min _ samples ”超参数。
下面列出了完整的示例:
# dbscan 聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import DBSCAN
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = DBSCAN(eps=0.30, min_samples=9)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,尽管需要更多的调整,但是找到了合理的分组。
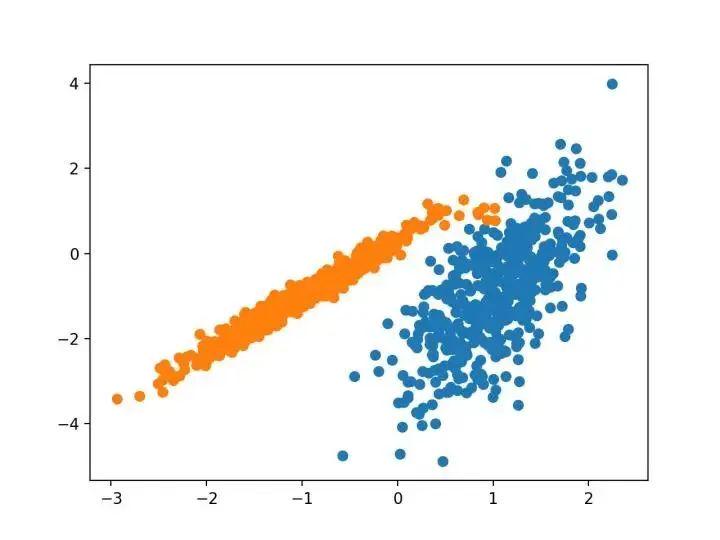
5.K均值
K-均值聚类可以是最常见的聚类算法,并涉及向群集分配示例,以尽量减少每个群集内的方差。它是通过 K-均值类实现的,要优化的主要配置是“ n _ clusters ”超参数设置为数据中估计的群集数量。下面列出了完整的示例:
# k-means 聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import KMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = KMeans(n_clusters=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个合理的分组,尽管每个维度中的不等等方差使得该方法不太适合该数据集。

6.Mini-Batch K-均值
Mini-Batch K-均值是 K-均值的修改版本,它使用小批量的样本而不是整个数据集对群集质心进行更新,这可以使大数据集的更新速度更快,并且可能对统计噪声更健壮。它是通过 MiniBatchKMeans 类实现的,要优化的主配置是“ n _ clusters ”超参数,设置为数据中估计的群集数量。下面列出了完整的示例:
# mini-batch k均值聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MiniBatchKMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = MiniBatchKMeans(n_clusters=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,会找到与标准 K-均值算法相当的结果。
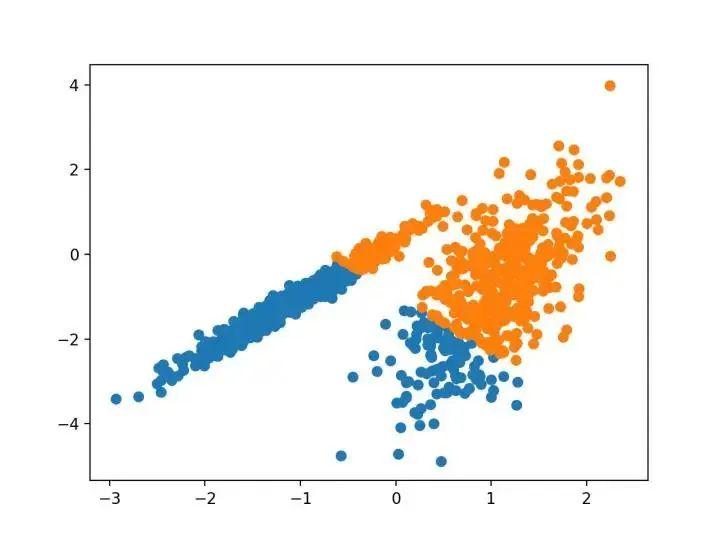
7.均值漂移聚类
均值漂移聚类涉及到根据特征空间中的实例密度来寻找和调整质心。它是通过 MeanShift 类实现的,主要配置是“带宽”超参数。下面列出了完整的示例:
# 均值漂移聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MeanShift
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = MeanShift()
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以在数据中找到一组合理的群集。
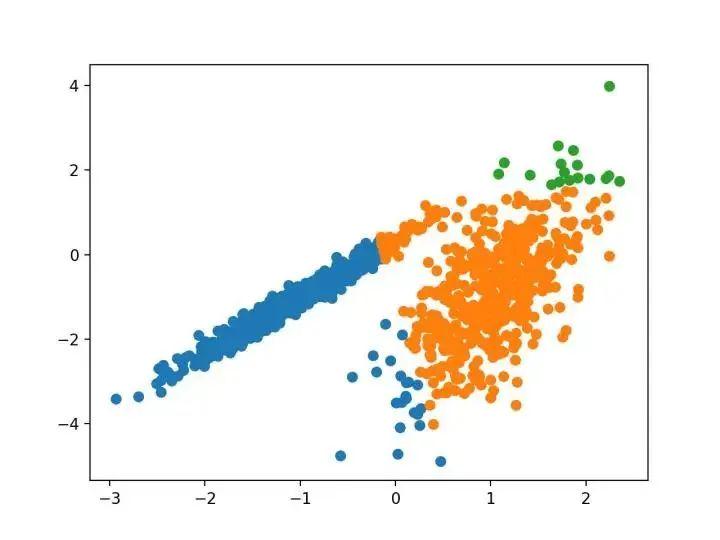
8.OPTICS
OPTICS 聚类( OPTICS 短于订购点数以标识聚类结构)是上述 DBSCAN 的修改版本。它是通过 OPTICS 类实现的,主要配置是“ eps ”和“ min _ samples ”超参数。
下面列出了完整的示例:
# optics聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import OPTICS
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = OPTICS(eps=0.8, min_samples=10)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我无法在此数据集上获得合理的结果。
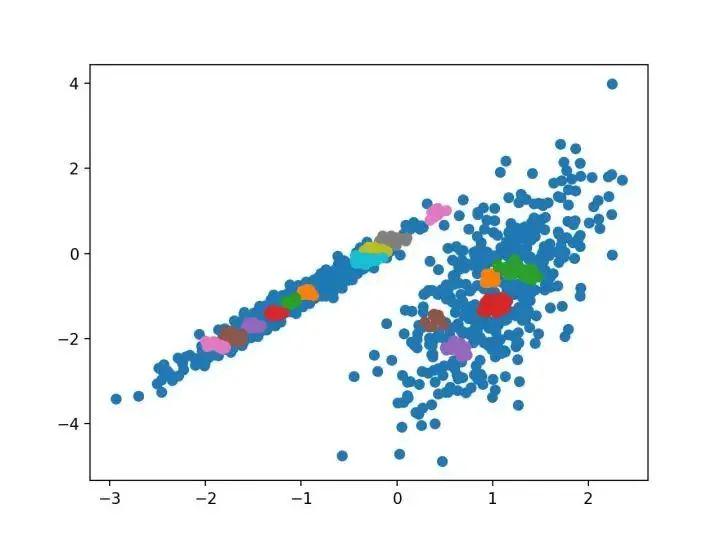
9.光谱聚类
光谱聚类是一类通用的聚类方法,取自线性线性代数。它是通过 Spectral 聚类类实现的,而主要的 Spectral 聚类是一个由聚类方法组成的通用类,取自线性线性代数。要优化的是“ n _ clusters ”超参数,用于指定数据中的估计群集数量。下面列出了完整的示例:
# spectral clustering
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import SpectralClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = SpectralClustering(n_clusters=2)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,找到了合理的集群。
10.高斯混合模型
高斯混合模型总结了一个多变量概率密度函数,顾名思义就是混合了高斯概率分布。它是通过 Gaussian Mixture 类实现的,要优化的主要配置是“ n _ clusters ”超参数,用于指定数据中估计的群集数量。下面列出了完整的示例:
# 高斯混合模型
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.mixture import GaussianMixture
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = GaussianMixture(n_components=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
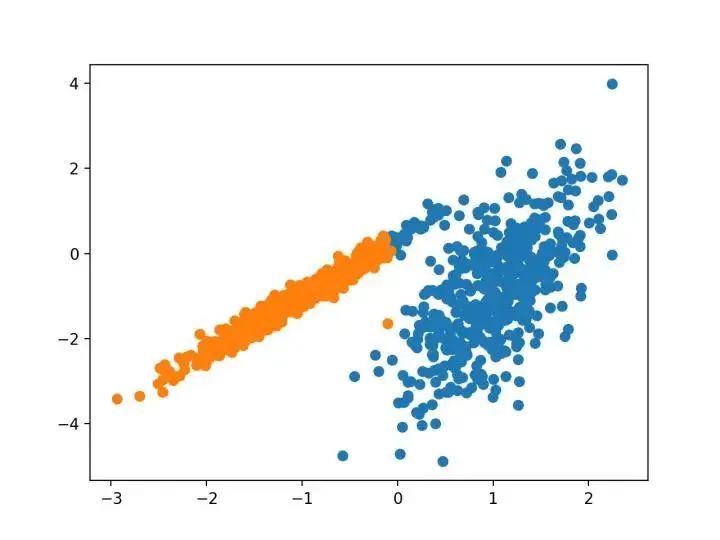
pyplot.show()运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我们可以看到群集被完美地识别。这并不奇怪,因为数据集是作为 Gaussian 的混合生成的。
相关文章:
10种聚类算法的完整python操作示例
大家好,聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现数据中的有趣模式,例如基于其行为的客户群。有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。相反,最好探索一系…...

构建合作伙伴生态系统刻不容缓
合作伙伴关系管理(PRM)系统是否已死?向合作伙伴生态系统的转变将如何改变我们未来管理合作伙伴计划的方式? 自PC革命以来,间接销售和渠道营销一直普遍存在于技术领域,通过其他公司的销售团队和人脉来增加销售,是一种明…...
)
剑指 Offer 55 - I. 二叉树的深度(java解题)
剑指 Offer 55 - I. 二叉树的深度(java解题)1. 题目2. 解题思路3. 数据类型功能函数总结4. java代码1. 题目 输入一棵二叉树的根节点,求该树的深度。从根节点到叶节点依次经过的节点(含根、叶节点)形成树的一条路径&a…...
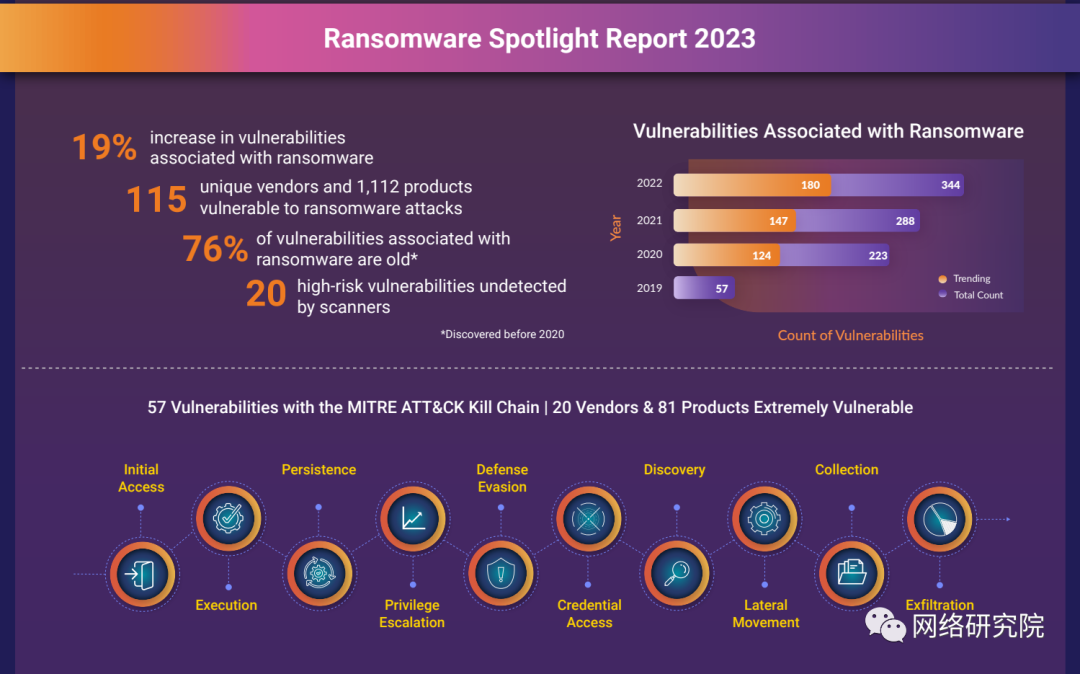
威胁行为者将旧漏洞武器化以发起勒索软件攻击
勒索软件运营商比以往任何时候都更加依赖未打补丁的系统来获得对受害者网络的初始访问权限。 一份新报告显示,攻击者正在互联网和暗网中积极搜索可用于勒索软件攻击的旧漏洞和已知漏洞。 其中许多缺陷已存在多年,对尚未修补或更新易受攻击系统的组织构…...

2023北京健博会/第十届中国国际大健康产博览会
China-DJK北京健博会,立足北京打造国内外大健康产业快速融合发展平台; 大健康时代:20年前没有健康产业,如今健康产业成了全球经济中唯“不缩水”的行业,早已被国际经济学界确定为“无限广阔的兆亿产业”。据机构数据&…...
Python学习笔记之环境搭建
Python学习笔记之环境搭建1. 下载Python2. Windows 安装最新Python3. Linux 安装最新PythonPython是一种编程语言,可以让您更快地工作并更有效地集成系统。 您可以学习使用Python,并立即看到生产力的提高和维护成本的降低。 Python是荷兰程序员吉多范罗苏…...

死锁的总结
哲学家死锁造成的原因:我有你需要的,但你已经有了 饥饿与死锁的区别 死锁一旦发生一定又饥饿现象,但是饥饿现象产生不一定是死锁 历史上对于死锁的声音 死锁的方案 前面两个都是不允许死锁出现 前面都是概念性的东西 后面我们研究如何破坏…...

强化学习RL 01~ 数学基础
目录 RL理解要点 1. RL数学基础 1.1 Random Variable 随机变量 1.2 概率密度函数 Probability Density Function(PDF) 1.3 期望 Expectation 1.4 随机抽样 Random Sampling 2. RL术语 Terminologies 2.1 agent、state 和 action 2.2 策略 policy π 2.3 奖励 reward …...
Java的运算符
目录 一、什么是运算符 二、算术运算符 1. 基本四则运算符:加减乘除模( - * / %) 2、增量运算符 - * % 3. 自增/自减运算符 -- 三、关系运算符 四、 逻辑运算符(重点) 1. 逻辑与 && 2. 逻辑或 || 3. 逻辑非 ! 4. 短路求值…...

扫地机器人(蓝桥杯C/C++)
题目描述 小明公司的办公区有一条长长的走廊,由 NN 个方格区域组成,如下图所示。 走廊内部署了 KK 台扫地机器人,其中第 ii 台在第 A_iAi 个方格区域中。已知扫地机器人每分钟可以移动到左右相邻的方格中,并将该区域清扫干净。…...
如何理解API?API 是如何工作的?(5分钟诠释)
大家可能最近经常听到 API 这个概念,那什么是API,它又有什么特点和好处呢? wiki 百科镇楼 …[APIs are] a set of subroutine definitions, protocols, and tools for building application software. In general terms, it’s a set of cle…...

PAT--1111 对称日
央视新闻发了一条微博,指出 2020 年有个罕见的“对称日”,即 2020 年 2 月 2 日,按照 年年年年月月日日 格式组成的字符串 20200202 是完全对称的。 给定任意一个日期,本题就请你写程序判断一下,这是不是一个对称日&a…...

前端纯函数和副作用概念,且在react上的体现详解
什么是纯函数 纯函数是这样一种函数,即相同的输入,永远会得到相同的输出的函数,而且没有任何可观察的副作用。 什么是副作用 副作用是在计算结果的过程中,系统状态的一种变化,或者与外部世界进行的可观察的交互。 个…...

转行软件测试3年了,听前辈说测试前途是IT里最low的,我慌了......
互联网行业的技术岗位一般分为研发、测试和运维,虽然前些年测试一直都不如研发岗位那么吃香。但现在随着国内对软件测试的重视,我国互联网企业对软件测试的需求在未来还将继续增大。听起来软件测试的就业形势一片大好,那么到底软件测试的发展…...
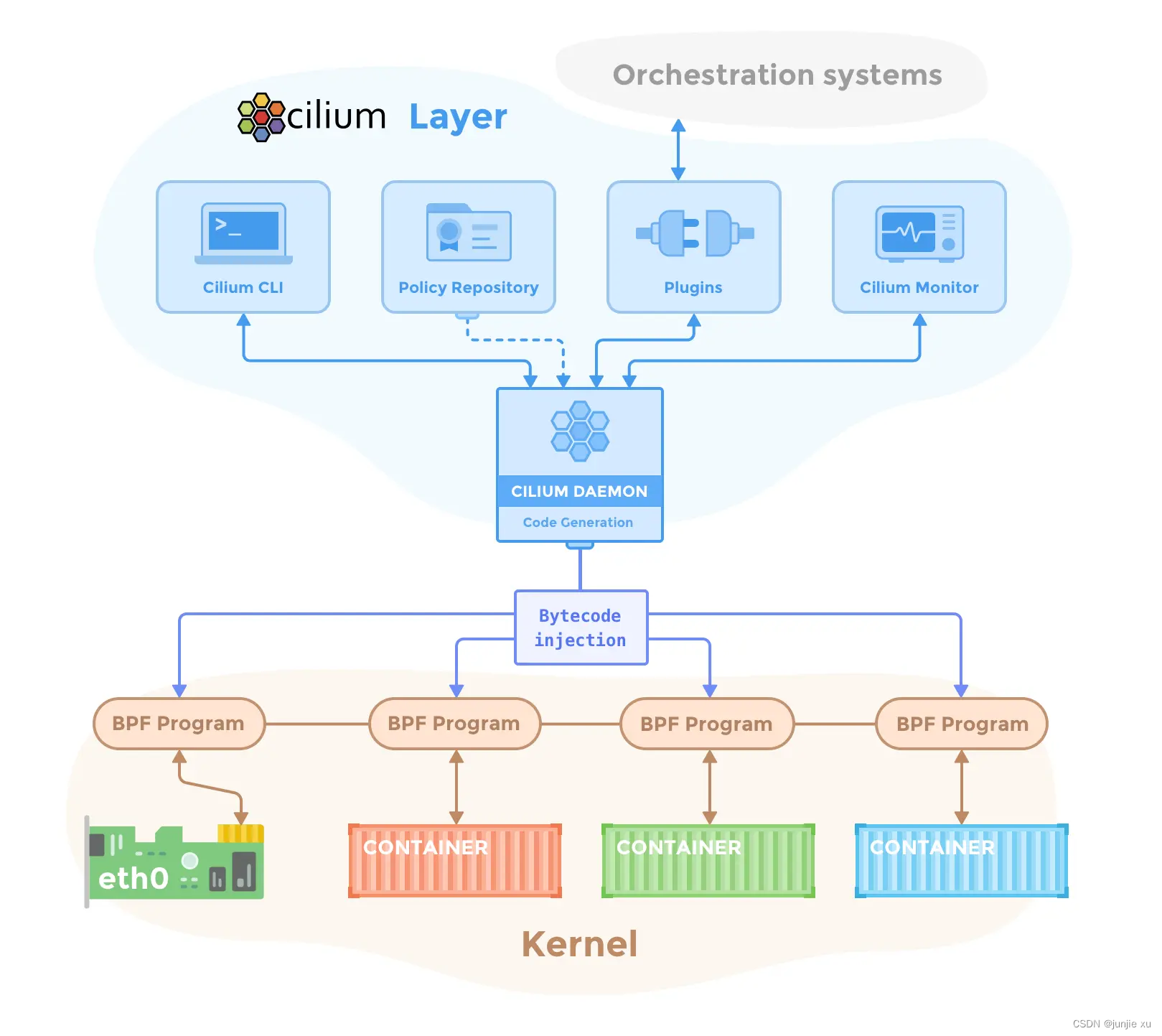
CNI 网络流量 5.1 Cilium 介绍和原理
文章目录简介安装组件和原理Cilium-agent初始化IPAMCNICilium cli 的使用bpfMap 的操作Cilium-agentEbpf简介 Cilium 是一个用于容器网络领域的开源项目,主要是面向容器而使用,用于提供并透明地保护应用程序工作负载(如应用程序容器或进程&a…...
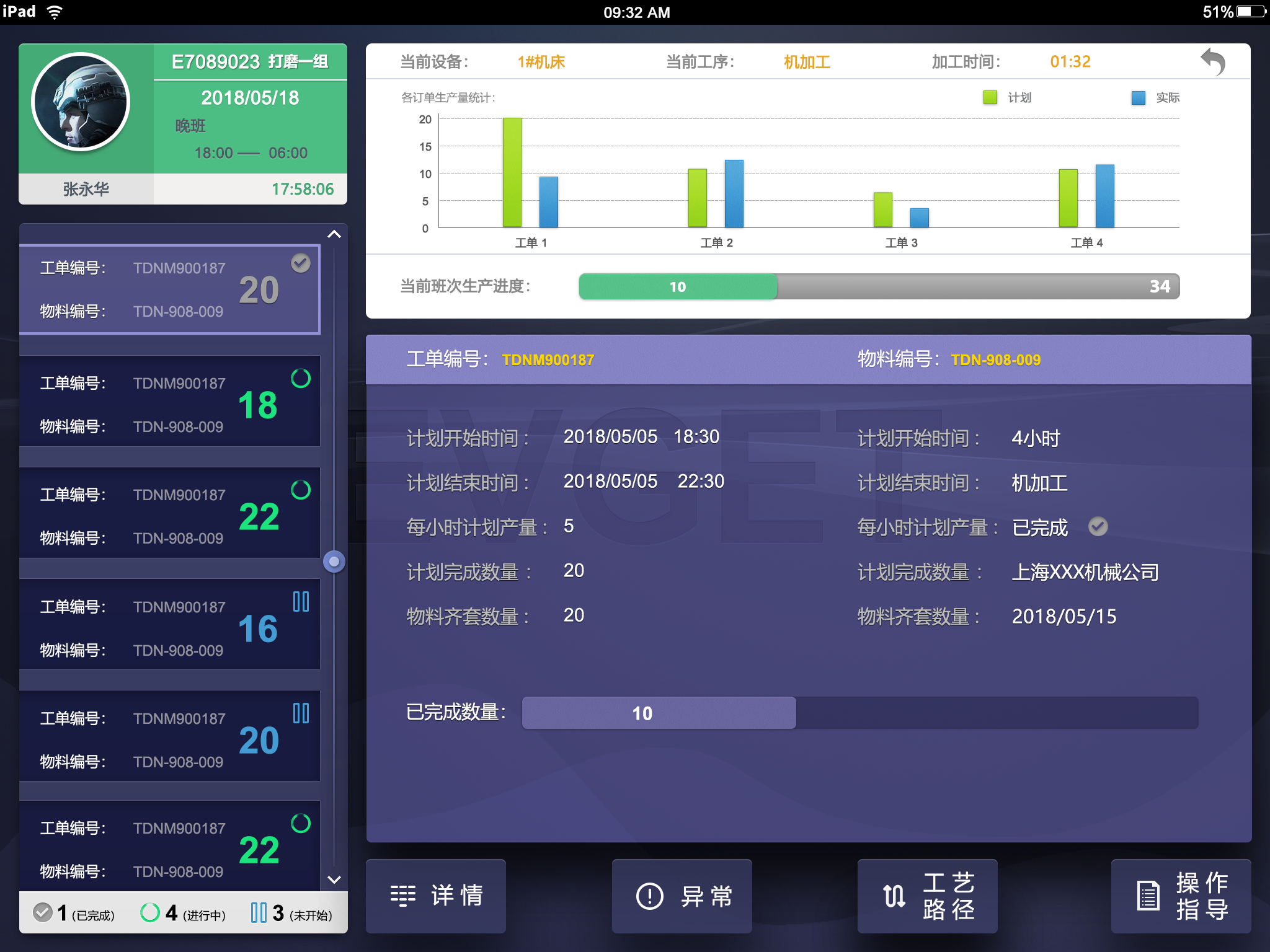
机加行业MES解决方案,助力企业打造数字化透明车间
机械加工行业的主要原材料占整个生产物料成本的95%~99%,以挖掘机为例,原材料有各种规格的钢板、焊丝、焊条、油漆以及各种气体等,其中主要原材料是钢板,占原材料比率的98%以上。 因此机械加工mes的原材料管理是机械加工行业信息化…...
C/C++每日一练(20230227)
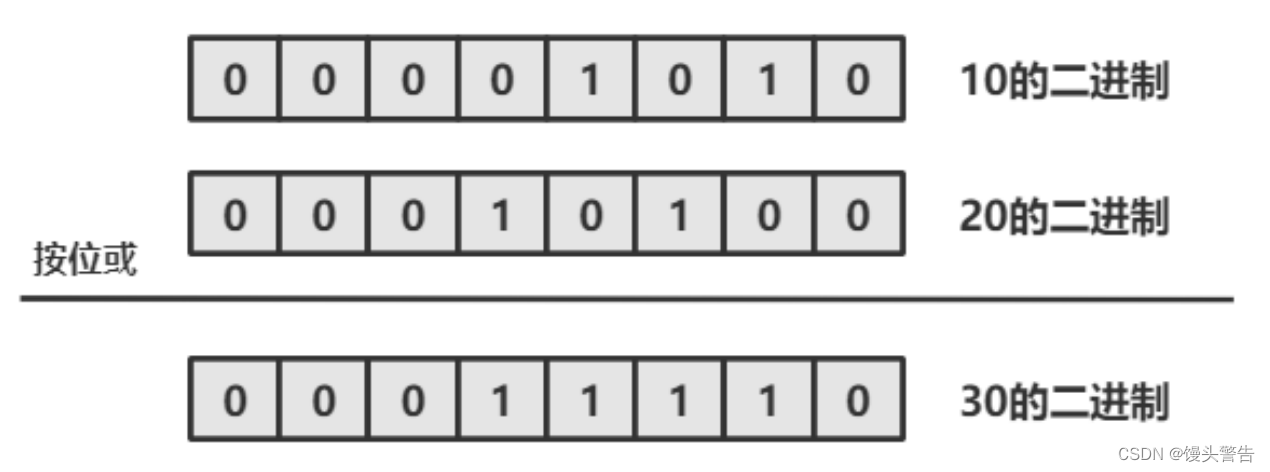
目录 1. 按要求排序数组 ★ 2. Z 字形变换 ★★ 3. 下一个排列 ★★ 1. 按要求排序数组 给你一个整数数组 arr 。请你将数组中的元素按照其二进制表示中,数字 1 的数目升序排序。 如果存在多个数字二进制中 1 的数目相同,则必须将它们按照数值大小…...

总结SpringBoot1.x迁移到2.x需要注意的问题
SpringBoot1.x和SpringBoot2.x版本差异化还是比较大的,有些三方依赖组件有些是基于2.0版本为标准升级的,当我们将项目由1.0升级到2.0时会出现依赖的方法不存在或方法错误,需要逐个去调整,下面总结了我们升级实践过程中遇到的一些问…...

Api接口小知识
应用程序接口API(Application Programming Interface),是提供特定业务输出能力、连接不同系统的一种约定。这里包括外部系统与提供服务的系统(中控系统)或者后台不同的系统之间的交互点。包括外部接口、内部接口、内部接口有包括&…...

「JVM 高效并发」Java 协程
Java 语言抽象和隐藏了各种操作系统线程差异性的接口,这曾经是它区别于其他编程语言的一大优势,但在某些场景下,却已经出现了疲态; 文章目录1. 内核线程的局限2. 协程的复苏3. Java 的解决方案1. 内核线程的局限 在微服务架构中&…...

轻量级日志聚合器Shiplog:中小团队分布式日志管理实践
1. 项目概述:一个为开发者打造的轻量级日志聚合器如果你是一名后端开发者,或者正在维护一个分布式微服务系统,那么对“日志”这个词一定又爱又恨。爱的是,它是排查线上问题的唯一“时光机”;恨的是,当服务实…...
)
Angular+Claude协同开发全栈实践(企业级项目落地手册)
更多请点击: https://intelliparadigm.com 第一章:AngularClaude协同开发全栈实践(企业级项目落地手册) 在现代企业级应用开发中,前端框架与AI辅助编程的深度集成正成为提效关键。Angular 提供结构化、可扩展的单页应…...

企业级ai应用如何通过taotoken实现稳定低成本的多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级AI应用如何通过Taotoken实现稳定低成本的多模型调用 在构建面向生产环境的企业级AI应用时,开发团队常常面临两个…...

智能家居生态博弈下,如何构建本地优先的自主智能家居系统
1. 智能家居生态的十字路口:当选择变成非此即彼几年前,如果你问我怎么搭建一个智能家居,我可能会兴致勃勃地跟你聊起各种开源平台、五花八门的协议和那些充满极客气质的独立品牌设备。那时候,市场像个热闹的集市,虽然有…...

5G网络部署挑战与云原生技术解决方案
1. 5G网络部署的核心挑战与技术演进5G作为第五代移动通信技术,正在全球范围内加速商用部署。与4G网络相比,5G在峰值速率、连接密度和时延等关键指标上实现了数量级提升。这种性能飞跃主要依赖于三项关键技术突破:Massive MIMO(大规…...

解锁HexView自动化:Bat脚本驱动S19/HEX文件处理实战
1. 为什么需要自动化处理S19/HEX文件 在汽车电子开发领域,我们经常需要处理各种固件文件,比如S19、HEX等格式。这些文件包含了嵌入式系统的机器代码,是软件最终要烧录到芯片中的形态。每次软件更新时,开发人员都要对这些文件进行一…...
)
告别手写代码!用Simulink+STM32CubeMX给F103点个灯(保姆级图文教程)
零代码玩转STM32:Simulink与CubeMX联动的LED控制实战指南 在嵌入式开发领域,传统的手写代码方式正逐渐被模型化设计工具所革新。想象一下,只需拖拽几个功能模块,设置几个参数,就能让STM32微控制器按照你的想法工作——…...

Cursor Pro破解工具终极指南:5步实现永久免费使用的完整教程
Cursor Pro破解工具终极指南:5步实现永久免费使用的完整教程 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...

如何轻松解锁Cursor Pro完整功能:一键激活与无限使用的完整指南
如何轻松解锁Cursor Pro完整功能:一键激活与无限使用的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...

从IR压降到远程采样:大电流PCB供电设计的实战经验与陷阱规避
1. 项目背景与问题浮现几年前,我参与了一个项目,主电源是一个标准的开放式机架电源,需要为一个位于机箱内相对较远的模块提供5V、约20A的直流电。最初的供电路径设计是依靠PCB走线,我们使用了1盎司铜厚的板材。问题很快就出现了&a…...