032、数据增广*
之——泛化性提升
杂谈
深度学习的数据增强(Data Augmentation)是一种技术,用于通过对原始数据进行多样性的变换和扩充,以增加训练数据的多样性,提高模型的泛化能力。这有助于减轻过拟合问题,提高深度学习模型的性能。以下是深度学习数据增强的一些方法以及一些成功的案例:
数据增强方法:
图像数据增强:
- 镜像翻转:对图像进行水平或垂直翻转,增加图像的多样性。
- 旋转:以不同的角度旋转图像。
- 平移:平移图像的位置,以模拟不同拍摄角度。
- 放缩:对图像进行缩小或放大。
- 亮度、对比度、色彩调整:改变图像的亮度、对比度或颜色。
文本数据增强:
- 同义词替换:将一些词替换为其同义词,以增加文本的多样性。
- 词序变换:随机改变文本中词语的顺序。
- 插入、删除、替换字符:对文本进行字符级别的操作,以增加噪音和多样性。
声音数据增强:
- 增加噪声:向声音数据中添加噪声,以增加多样性。
- 时间伸缩:对声音数据进行时间尺度的变化。
- 频域变换:在声音数据的频域上进行操作。
成功案例:
图像分类:
- ImageNet竞赛:在ImageNet图像分类竞赛中,数据增强被广泛使用。训练集中的图像进行了多种变换,包括翻转、旋转、缩放等。这些技术帮助了深度卷积神经网络(CNN)在图像分类任务上取得巨大成功。
目标检测:
- Faster R-CNN:Faster R-CNN是一种流行的目标检测算法,使用了数据增强来改进检测性能。通过对训练图像进行多样性的变换,模型在不同环境下能更好地识别目标。
自然语言处理:
- BERT:BERT是一种预训练的语言模型,通过对文本进行多种数据增强操作,如遮蔽、替换、乱序等,来学习文本的上下文信息。BERT的成功影响了自然语言处理领域的各种任务,如情感分析、问答等。
语音识别:
- SpecAugment:SpecAugment是一种用于语音识别的数据增强方法,通过在声谱图上进行时间和频域的变换来改进语音识别模型的性能。
这些案例表明,数据增强是深度学习中的一种重要技术,可以显著提高模型的性能和泛化能力。不同领域的数据增强方法可能有所不同,但它们都通过增加数据多样性来帮助模型更好地理解和泛化数据。
正文
1.数据增广
数据增广,顾名思义就是在现有数据基础上去做增强、扩充、调整。

理想情况下训练出来的model在实际部署上完全不一样。

所以希望在训练时候就能够考虑尽可能多的干扰与数据变化情况,以免出现泛化性能差的现象:

一般来说是随机在线生成的,可以理解为随机正则项:

2.方法
2.1 翻转
数据增广要考虑到本身的应用场景,要是一些完全不可能上下颠倒的物体,翻转增广是没有意义的。

2.2 切割
随机方式切割图片并变回固定形状:

2.3 颜色
色调、饱和度、亮度:


2.4 其他数字图像处理
旋转跳跃、瑞锐化、虚化、消除、噪声:

3.实现
导包导图:
import torch
import torchvision
from torch import nn
from d2l import torch as d2l# d2l.set_figsize()
d2l.set_figsize()
img = d2l.Image.open(r'D:\apycharmblackhorse\project\_04_pytorch\basic_class\data/pikaqiu.jpg')
d2l.plt.imshow(img);列举函数:
#一个列举函数,传入图片和方法
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):Y = [aug(img) for _ in range(num_rows * num_cols)]d2l.show_images(Y, num_rows, num_cols, scale=scale)
随机水平翻转随机垂直翻转:
print("随机水平翻转")
apply(img, torchvision.transforms.RandomHorizontalFlip())print("随机垂直翻转")
apply(img, torchvision.transforms.RandomVerticalFlip())

随机裁剪:
print("随机裁剪") #裁剪图像大小,与原始图像比例随机范围,高宽比随机范围
cut_aug=torchvision.transforms.RandomResizedCrop(200,(0.1,1),(0.5,2))
apply(img, cut_aug)
颜色变化:
print("颜色变化") #亮度、对比度、饱和度和色调,上下幅值
color_aug=torchvision.transforms.ColorJitter(brightness=0.5,contrast=0.5,saturation=0.5,hue=0.5)
apply(img, color_aug)
多种增广方法合并:
print("多种增广方法")
augs=torchvision.transforms.Compose([torchvision.transforms.RandomVerticalFlip(),cut_aug,color_aug])
apply(img, augs)

训练应用:主要是跑不动,之后回过头来再整理:
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2lall_images = torchvision.datasets.CIFAR10(train=True, root="../data",download=True)
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8);train_augs = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor()])test_augs = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])def load_cifar10(is_train, augs, batch_size):dataset = torchvision.datasets.CIFAR10(root="../data", train=is_train,transform=augs, download=True)dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,shuffle=is_train, num_workers=d2l.get_dataloader_workers())return dataloaderdef train_batch_ch13(net, X, y, loss, trainer, devices):"""用多GPU进行小批量训练"""if isinstance(X, list):# 微调BERT中所需X = [x.to(devices[0]) for x in X]else:X = X.to(devices[0])y = y.to(devices[0])net.train()trainer.zero_grad()pred = net(X)l = loss(pred, y)l.sum().backward()trainer.step()train_loss_sum = l.sum()train_acc_sum = d2l.accuracy(pred, y)return train_loss_sum, train_acc_sumdef train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices=d2l.try_all_gpus()):"""用多GPU进行模型训练"""timer, num_batches = d2l.Timer(), len(train_iter)animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],legend=['train loss', 'train acc', 'test acc'])net = nn.DataParallel(net, device_ids=devices).to(devices[0])for epoch in range(num_epochs):# 4个维度:储存训练损失,训练准确度,实例数,特点数metric = d2l.Accumulator(4)for i, (features, labels) in enumerate(train_iter):timer.start()l, acc = train_batch_ch13(net, features, labels, loss, trainer, devices)metric.add(l, acc, labels.shape[0], labels.numel())timer.stop()if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[3],None))test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {metric[0] / metric[2]:.3f}, train acc 'f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on 'f'{str(devices)}')batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)def init_weights(m):if type(m) in [nn.Linear, nn.Conv2d]:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)def train_with_data_aug(train_augs, test_augs, net, lr=0.001):train_iter = load_cifar10(True, train_augs, batch_size)test_iter = load_cifar10(False, test_augs, batch_size)loss = nn.CrossEntropyLoss(reduction="none")trainer = torch.optim.Adam(net.parameters(), lr=lr)train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)train_with_data_aug(train_augs, test_augs, net)结果:
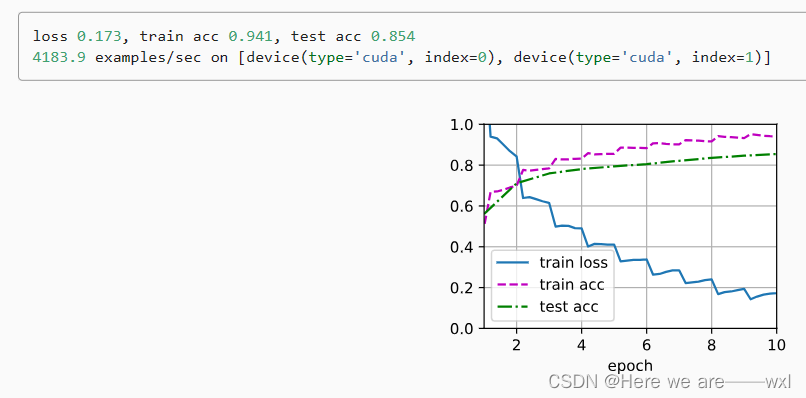
小结
-
图像增广基于现有的训练数据生成随机图像,来提高模型的泛化能力。
-
为了在预测过程中得到确切的结果,我们通常对训练样本只进行图像增广,而在预测过程中不使用带随机操作的图像增广。
-
深度学习框架提供了许多不同的图像增广方法,这些方法可以被同时应用。
相关文章:
032、数据增广*
之——泛化性提升 杂谈 深度学习的数据增强(Data Augmentation)是一种技术,用于通过对原始数据进行多样性的变换和扩充,以增加训练数据的多样性,提高模型的泛化能力。这有助于减轻过拟合问题,提高深度学习模…...

力扣最热一百题——盛水最多的容器
终于又来了。我的算法记录的文章已经很久没有更新了。为什么呢? 这段时间都在更新有关python的文章,有对python感兴趣的朋友可以在主页找到。 但是这也并不是主要的原因 在10月5号我发布了我的第一篇博客,大家也可以看见我的每一篇算法博客…...

备份扫描工具 god_bak
Part1 前言 不想写东西,或者说换种说法 有些东西还没写完,有些系列也还没整完。就放一个昨天摸鱼写的东西。 如图,每个系列都还是会按照自己的风格来写,代码审计实战等都会结合自己挖掘或审计过的案例进行结合知识点的风格去写&…...
)
软考 系统架构设计师系列知识点之数字孪生体(2)
接前一篇文章:软考 系统架构设计师系列知识点之数字孪生体(1) 所属章节: 第11章. 未来信息综合技术 第5节. 数字孪生体技术概述 2. 数字孪生体的定义 AFRL(Air Force Research Laboratory,美国空军研究实…...

CSS实现文本左右对齐
因为文本里面有中午符号,英文,英文符号等,导致设置宽度以后右侧凌乱,可以通过以下代码设置样式,让文本工整对齐。 让我们看一下设置前和设置后的对比图片: 效果图如下:(左边是设置…...

利用exec命令进入docker容器时的报错问题
进入Docker 容器 docker exec [CONTAINER ID] bin/bash报错问题 一、详细报错信息 执行docker exec -it [containerId] /bin/bash报错: OCI runtime exec failed: exec failed: unable to start container process: exec: "/bin/bash": stat /bin/ba…...

Java 与C++ 语言的一些区别
Java 与C 语言的一些区别 前言不同之外 前言 之前用C、C 的多,目前开始学习和接触 Java ,拿Java和C 做一个对比,帮助快速掌握Java的开发。 不同之外 数据类型的差别: java中 byte 类型类似于c/c 中的char类型 boolean 与C 的bo…...

npm ERR! network ‘proxy‘ config is set properly. See: ‘npm help config解决方法
这个错误提示通常表示在使用 npm 安装包时出现了网络连接问题。具体来说,可能是由于以下原因之一: 你的网络连接不稳定或者被防火墙拦截了。你的计算机设置了代理,但是 npm 没有正确配置代理。npm 的配置文件中的 registry 配置不正确&#…...

An Empirical Study of Instruction-tuning Large Language Models in Chinese
本文是LLM系列文章,针对《An Empirical Study of Instruction-tuning Large Language Models in Chinese》的翻译。 汉语大语言模型指令调整的实证研究 摘要1 引言2 指令调整三元组3 其他重要因素4 迈向更好的中文LLM5 结论局限性 摘要 ChatGPT的成功验证了大型语…...

[MICROSAR Adaptive] --- 开发环境准备
Ubuntu 20.04/22.04版本默认的cmake版本不超过3.19,gcc/g++为9.x版本 而ap开发要求cmake版本大于3.19,gcc/g++版本为gcc-7 1 安装高版本cmake cmake源码下载路径 https://cmake.org/files/tar zxvf cmake-3.19.2.tar.gz cd cmake-3.19.2 ./bootstrap --prefix=/usr/local …...

Yolov5 batch 推理
前言 想要就有了 代码 import shutil import time import traceback import torchimport os import cv2 class PeopleDetect(object):def __init__(self, repo_or_dir, weight_path, confidence) -> None:self.model torch.hub.load(repo_or_dir, "custom", p…...

【ARFoundation学习笔记】ARFoundation基础(下)
写在前面的话 本系列笔记旨在记录作者在学习Unity中的AR开发过程中需要记录的问题和知识点。难免出现纰漏,更多详细内容请阅读原文。 文章目录 TrackablesTrackableManager可跟踪对象事件管理可跟踪对象 Session管理 Trackables 在AR Foundation中,平面…...

《UML和模式应用(原书第3版)》2024新修订译本部分截图
DDD领域驱动设计批评文集 做强化自测题获得“软件方法建模师”称号 《软件方法》各章合集 机械工业出版社即将在2024春节前后推出《UML和模式应用(原书第3版)》的典藏版。 受出版社委托,UMLChina审校了原中译本并做了一些修订。同比来说&a…...
JSP 学生成绩查询管理系统eclipse开发sql数据库serlvet框架bs模式java编程MVC结构
一、源码特点 JSP 学生成绩查询管理系统 是一套完善的web设计系统,对理解JSP java编程开发语言有帮助,比较流行的servlet框架系统具有完整的源代码和数据库,eclipse开发系统主要采用B/S模式 开发。 java 学生成绩查询管理系统 代码下载链接…...

技术分享 | app自动化测试(Android)-- 属性获取与断言
断言是 UI 自动化测试的三要素之一,是 UI 自动化不可或缺的部分。在使用定位器定位到元素后,通过脚本进行业务操作的交互,想要验证交互过程中的正确性就需要用到断言。 常规的UI自动化断言 分析正确的输出结果,常规的断言一般包…...

flutter实现上拉到底部加载更多数据
实现上拉加载数据,效果如下: flutter滚动列表加载数据 使用的库主要是infinite_scroll_pagination , 安装请查看官网 接口用的是https://reqres.in/提供的接口 请求接口用到的库是dio 下面主要是介绍如何使用infinite_scroll_pagination实现上拉加载…...
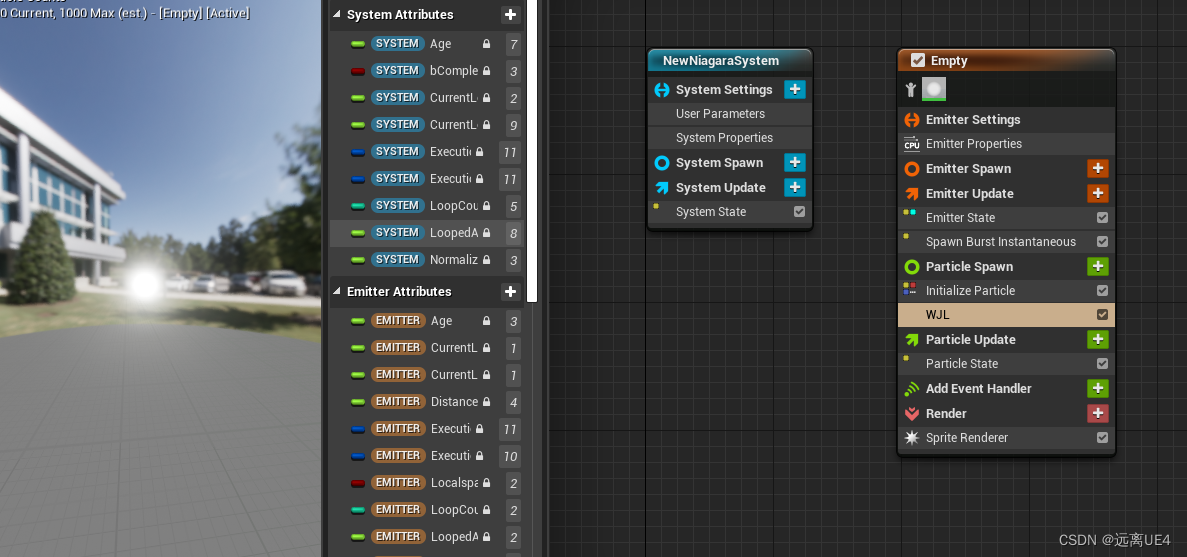
UE4 Niagara Module Script 初次使用笔记
这里可以创建一个Niagara模块脚本 创建出来长这样 点击号,输出staticmesh,点击它 这样就可以拿到对应的一些模型信息 这里的RandomnTriCoord是模型的坐标信息 根据坐标信息拿到位置信息 最后的Position也是通过Map Set的号,选择Particles的P…...

【Spring Boot 源码学习】JedisConnectionConfiguration 详解
Spring Boot 源码学习系列 JedisConnectionConfiguration 详解 引言往期内容主要内容1. RedisConnectionFactory1.1 单机连接1.2 集群连接1.3 哨兵连接 2. JedisConnectionConfiguration2.1 RedisConnectionConfiguration2.2 导入自动配置2.3 相关注解介绍2.4 redisConnectionF…...
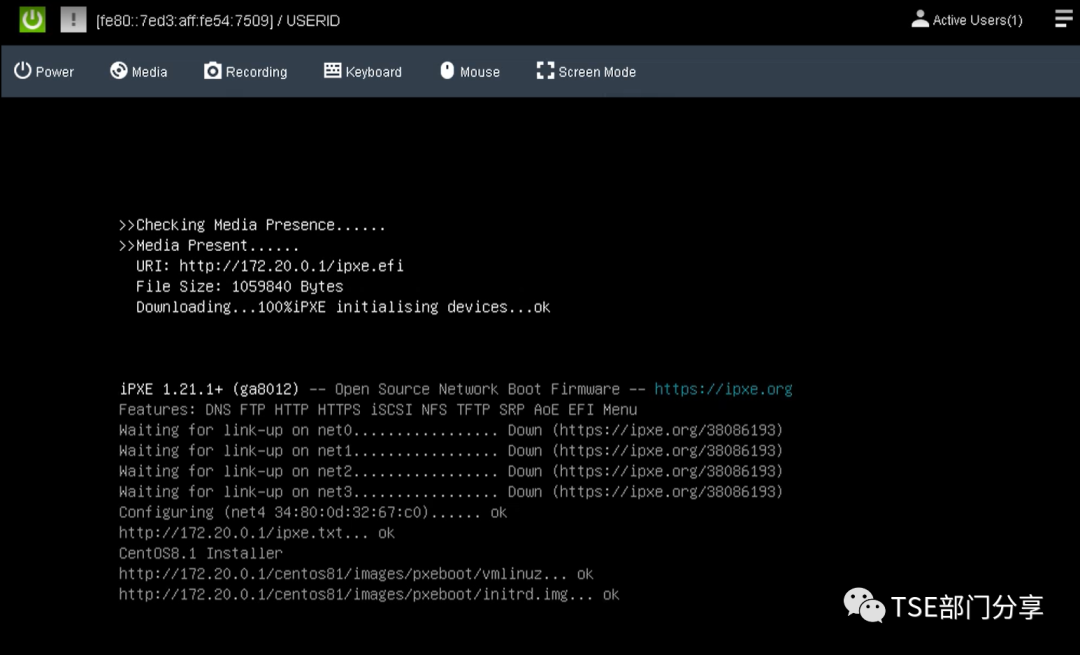
联想服务器-HTTP boot安装Linux系统
HTTP boot与传统PXE的主要差异 HTTP不再需要使用UDP协议的tftp服务(连接不可靠、不支持大文件)了,只需要dhcp 和http 两个服务即可,支持较稳定的大文件传输。 实验环境 ThinkSystem服务器SR650V2 SR660V2 通过HTTP boot安装Cen…...

容器滚动更新过程中流量无损
应用在发布或重启的期间会出现少量的 5xx 异常,应该如何解决? 我们发现导致流量有损的原因有很多,比如: 上线时,应用在就绪前收到流量,导致请求无法被处理; 下线时,应用没有做优雅…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

收藏必看|2026 版大厂 AI 岗位薪资曝光!普通程序员转型大模型最全指南
深夜收到大厂 HR 好友发来的内部资料,再三叮嘱切勿对外泄露。如今网络信息传播速度极快,这份 2026 年企业 AI 岗真实薪资内幕,也值得给广大程序员、零基础入行小白参考借鉴。 翻看完整薪资台账后,真切感受到当下大模型赛道的薪资差…...

从入门到实践:EEG公开数据集分类与应用场景全解析
1. EEG公开数据集入门指南刚接触脑电信号分析的研究者,常常会被一个问题困扰:"我应该从哪里获取可靠的EEG数据?"作为一个在这个领域摸爬滚打多年的研究者,我完全理解这种困惑。记得我第一次接触EEG研究时,光…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...

Git Bash 中无法启动 Claude Code ?
最近需要在 git bash 中跑 Claude Code 。git bash 是随 git for windows 套件安装的,很久没更新了,结果启动 Claude Code 报错:Warning: no stdin data received in 3s, proceeding without it. If piping from a slow command, redirect st…...

Claude Agent SDK 从 0 到 1 快速上手教程
Claude Agent SDK 从 0 到 1 快速上手教程 什么是 Claude Agent SDK? Claude Agent SDK 是 Anthropic 官方推出的用于构建 AI 智能体的开发工具包。它基于 Claude Code 构建,让开发者能够以编程方式创建、扩展和定制由 Claude 驱动的应用程序。与简单的聊天机器人不同,基于…...