JDBC SQL Server Source Connector: 一览与实践

在快速发展的数据驱动业务环境中,确保数据在各个系统间高效、准确地同步至关重要。为了进一步的数据处理和分析,经常需要将这些数据同步到其他数据处理系统。Apache SeaTunnel 提供了一个强大而灵活的数据集成框架,使得从 SQL Server 到其他系统的数据同步变得简单且高效。
本文档将指导您如何配置 Apache SeaTunnel,使用 JDBC SQL Server Source Connector 来实现数据的有效同步。
JDBC SQL Server Source Connector
支持 SQL Server 版本
-
服务器:2008(或更高版本,仅供信息参考)
支持以下引擎
Spark
Flink
Seatunnel Zeta
主要特点
-
[x] 批处理 -
[ ] 流处理 -
[x] 精准一次性 -
[x] 列投影 -
[x] 并行处理 -
[x] 支持用户定义拆分
支持查询 SQL 并能够实现投影效果。
描述
通过 JDBC 读取外部数据源数据。
支持的数据源信息
| 数据源 | 支持的版本 | 驱动 | URL | Maven |
|---|---|---|---|---|
| SQL Server | 支持版本 >= 2008 | com.microsoft.sqlserver.jdbc.SQLServerDriver | jdbc:sqlserver://localhost:1433 | 下载 |
数据库依赖
请下载与 'Maven' 对应的支持列表,并将其复制到 '
数据类型映射
SQL Server 数据类型 Seatunnel 数据类型 BIT BOOLEAN TINYINT
SMALLINTSHORT INTEGER INT BIGINT LONG DECIMAL
NUMERIC
MONEY
SMALLMONEYDECIMAL((指定列的指定列大小)+1,
(获取指定列的小数点右边的数字的数量。)))REAL FLOAT FLOAT DOUBLE CHAR
NCHAR
VARCHAR
NTEXT
NVARCHAR
TEXTSTRING DATE LOCAL_DATE TIME LOCAL_TIME DATETIME
DATETIME2
SMALLDATETIME
DATETIMEOFFSETLOCAL_DATE_TIME TIMESTAMP
BINARY
VARBINARY
IMAGE
UNKNOWN尚不支持 源选项
名称 类型 必需 默认值 描述 url 字符串 是 - JDBC 连接的 URL。例如:jdbc:sqlserver://127.0.0.1:1434;database=TestDB driver 字符串 是 - 用于连接到远程数据源的 JDBC 类名,如果使用 SQL Server,则值为 com.microsoft.sqlserver.jdbc.SQLServerDriver。user 字符串 否 - 连接实例的用户名 password 字符串 否 - 连接实例的密码 query 字符串 是 - 查询语句 connection_check_timeout_sec 整数 否 30 等待用于验证连接的数据库操作完成的秒数 partition_column 字符串 否 - 并行处理的分区列,仅支持数值类型。 partition_lower_bound 长整数 否 - 用于扫描的 partition_column 最小值,如果未设置,SeaTunnel 将查询数据库获取最小值。 partition_upper_bound 长整数 否 - 用于扫描的 partition_column 最大值,如果未设置,SeaTunnel 将查询数据库获取最大值。 partition_num 整数 否 作业并行度 分区计数的数量,仅支持正整数。默认值为作业并行度。 fetch_size 整数 否 0 对返回大量对象的查询,您可以配置查询中使用的行抓取大小,以减少满足选择条件所需的数据库命中次数,从而提高性能。
零表示使用 JDBC 默认值。common-options 否 - 源插件的常见参数,请参阅 源常用选项 以获取详细信息。 提示
如果未设置 partition_column,则将以单一并发运行;如果设置了 partition_column,则将根据任务的并发度进行并行执行。
任务示例
简单:
简单的单一任务以读取数据表
# 定义运行时环境
env {
# 您可以在此处设置 Flink 配置
execution.parallelism = 1
job.mode = "BATCH"
}
source{
Jdbc {
driver = com.microsoft.sqlserver.jdbc.SQLServerDriver
url = "jdbc:sqlserver://localhost:1433;databaseName=column_type_test"
user = SA
password = "Y.sa123456"
query = "select * from full_types_jdbc"
}
}
transform {
# 如果您想要获取有关如何配置 seatunnel 和查看变换插件的完整列表的更多信息,
# 请转到 [seatunnel.apache.org/docs/transform-v2/sql](https://seatunnel.apache.org/docs/transform-v2/sql)
}
sink {
Console {}
}并行:
使用您配置的分片字段和分片数据并行读取您的查询表,如果您希望读取整个表,可以这样做:
env {
# 您可以在此处设置 Flink 配置
execution.parallelism = 10
job.mode = "BATCH"
}
source {
Jdbc {
driver = com.microsoft.sqlserver.jdbc.SQLServerDriver
url = "jdbc:sqlserver://localhost:1433;databaseName=column_type_test"
user = SA
password = "Y.sa123456"
# 根据需要定义查询逻辑
query = "select * from full_types_jdbc"
# 并行分片读取字段
partition_column = "id"
# 片段数量
partition_num = 10
}
}
transform {
# 如果您想要获取有关如何配置 Seatunnel 和查看转换插件的完整列表的更多信息,
# 请转到 https://seatunnel.apache.org/docs/transform-v2/sql
}
sink {
Console {}
}并行:
使用您配置的分片字段和分片数据并行读取您的查询表,如果您希望读取整个表,可以这样做:
env {
# 您可以在此处设置 Flink 配置
execution.parallelism = 10
job.mode = "BATCH"
}
source {
Jdbc {
driver = com.microsoft.sqlserver.jdbc.SQLServerDriver
url = "jdbc:sqlserver://localhost:1433;databaseName=column_type_test"
user = SA
password = "Y.sa123456"
# 根据需要定义查询逻辑
query = "select * from full_types_jdbc"
# 并行分片读取字段
partition_column = "id"
# 片段数量
partition_num = 10
}
}
transform {
# 如果您想要获取有关如何配置 Seatunnel 和查看转换插件的完整列表的更多信息,
# 请转到 https://seatunnel.apache.org/docs/transform-v2/sql
}
sink {
Console {}
}并行:
使用您配置的分片字段和分片数据并行读取您的查询表,如果您希望读取整个表,可以这样做:
env {
# 您可以在此处设置 Flink 配置
execution.parallelism = 10
job.mode = "BATCH"
}
source {
Jdbc {
driver = com.microsoft.sqlserver.jdbc.SQLServerDriver
url = "jdbc:sqlserver://localhost:1433;databaseName=column_type_test"
user = SA
password = "Y.sa123456"
# 根据需要定义查询逻辑
query = "select * from full_types_jdbc"
# 并行分片读取字段
partition_column = "id"
# 片段数量
partition_num = 10
}
}
transform {
# 如果您想要获取有关如何配置 Seatunnel 和查看转换插件的完整列表的更多信息,
# 请转到 https://seatunnel.apache.org/docs/transform-v2/sql
}
sink {
Console {}
}并行:
使用您配置的分片字段和分片数据并行读取您的查询表,如果您希望读取整个表,可以这样做:
env {
# 您可以在此处设置 Flink 配置
execution.parallelism = 10
job.mode = "BATCH"
}
source {
Jdbc {
driver = com.microsoft.sqlserver.jdbc.SQLServerDriver
url = "jdbc:sqlserver://localhost:1433;databaseName=column_type_test"
user = SA
password = "Y.sa123456"
# 根据需要定义查询逻辑
query = "select * from full_types_jdbc"
# 并行分片读取字段
partition_column = "id"
# 片段数量
partition_num = 10
}
}
transform {
# 如果您想要获取有关如何配置 Seatunnel 和查看转换插件的完整列表的更多信息,
# 请转到 https://seatunnel.apache.org/docs/transform-v2/sql
}
sink {
Console {}
}分段并行读取示例:
这是一个快速并行读取数据的分片示例
env {
# 您可以在此处设置引擎配置
execution.parallelism = 10
}
source {
# 这是一个示例源插件,仅用于测试和展示源插件的功能
Jdbc {
driver = com.microsoft.sqlserver.jdbc.SQLServerDriver
url = "jdbc:sqlserver://localhost:1433;databaseName=column_type_test"
user = SA
password = "Y.sa123456"
query = "select * from column_type_test.dbo.full_types_jdbc"
# 并行分片读取字段
partition_column = "id"
# 片段数量
partition_num = 10
}
# 如果您想要获取有关如何配置 Seatunnel 和查看源插件的完整列表的更多信息,
# 请转到 https://seatunnel.apache.org/docs/connector-v2/source/Jdbc
}
transform {
# 如果您想要获取有关如何配置 Seatunnel 和查看转换插件的完整列表的更多信息,
# 请转到 https://seatunnel.apache.org/docs/transform-v2/sql
}
sink {
Console {}
# 如果您想要获取有关如何配置 Seatunnel 和查看接收插件的完整列表的更多信息,
# 请转到 https://seatunnel.apache.org/docs/connector-v2/sink/Jdbc
}
相关文章:
JDBC SQL Server Source Connector: 一览与实践
在快速发展的数据驱动业务环境中,确保数据在各个系统间高效、准确地同步至关重要。为了进一步的数据处理和分析,经常需要将这些数据同步到其他数据处理系统。Apache SeaTunnel 提供了一个强大而灵活的数据集成框架,使得从 SQL Server 到其他系…...

WebDAV之π-Disk派盘 + Keepass2Android
推荐一款密码管理器,允许人们使用复杂的组合进行登录,而不必记住所有的组合。 Keepass2Android可以支持大多数安卓互联网浏览器, Android设备上同步软件,还支持通过WebDAV添加葫芦儿派盘。 Keepass2Android 目前安全方面最大的问题之一是大多数人几乎在任何地方都使用通用…...

AspectJX - Android开发平台的AOP框架
官网 GitHub - HujiangTechnology/gradle_plugin_android_aspectjx: A Android gradle plugin that effects AspectJ on Android project and can hook methods in Kotlin, aar and jar file. 项目简介 一个基于AspectJ并在此基础上扩展出来可应用于Android开发平台的AOP框架…...

【TDK 电容 】介电质 代码 对应温度及变化率
JB 电解质是什么?没找到,只有TDK有,也只有这个温度的区别,并且已经停产在售。 对比发现是mouser网站关于电容的描述错误。下图显示正确的,再然后是错误的。 在TDK官网,这样的描述 温度特性 分类标准代码温…...

随笔--解决ubuntu虚拟环境的依赖问题
文章目录 问题一:在conda虚拟环境中报错ImportError: libcupti.so.11.7:cannot open shared object file: No such file or directory解决步骤问题二: RuntimeError: CUDA error: CUBLAS_STATUS_INVALID_VALUE when calling cublasSgemmStridedBatched( …...
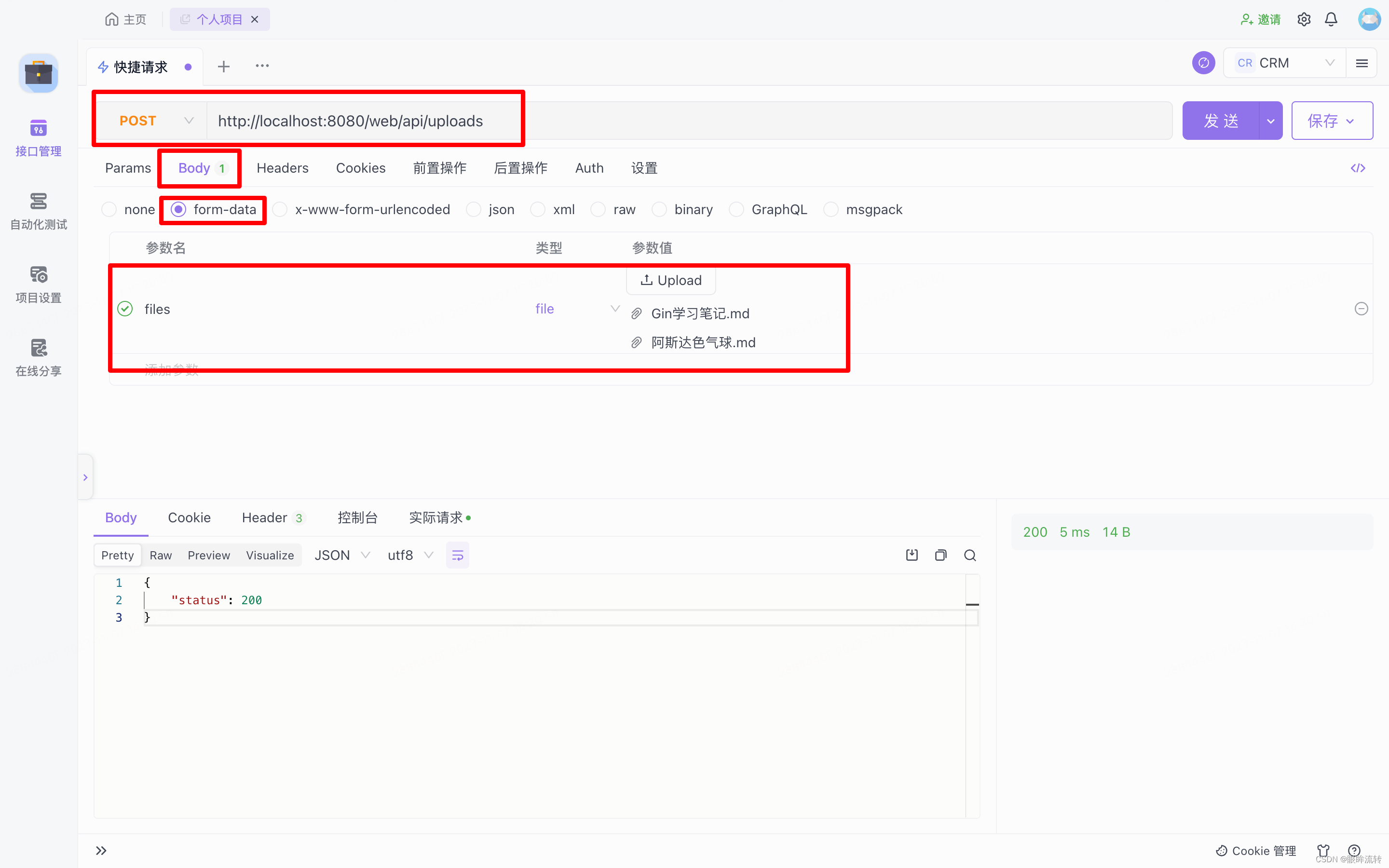
Gin学习笔记
Gin学习笔记 Gin文档:https://pkg.go.dev/github.com/gin-gonic/gin 1、快速入门 1.1、安装Gin go get -u github.com/gin-gonic/gin1.2、main.go package mainimport ("github.com/gin-gonic/gin""net/http" )func main() {// 创建路由引…...

使用 OpenTracing 和 LightStep 监控无服务器功能
无服务器功能的采用在企业组织内达到了创纪录的水平。有趣的是,鉴于越来越多的采用和兴趣,许多监控解决方案孤立了在这些环境中执行的代码的性能,或者仅提供有关执行的基本指标。为了了解应用程序的性能,我想知道存在哪些瓶颈、时…...
、Sleep(1)、SwitchToThread())
Sleep(0)、Sleep(1)、SwitchToThread()
当 timeout 参数为 0 时(如 Sleep(0)),操作系统会检查可运行队列中是否有高于或等于当前线程优先级的其他就绪线程。如果有,当前线程将被移除并放弃处理器时间,让其他线程执行。如果没有高优先级的线程,当前…...
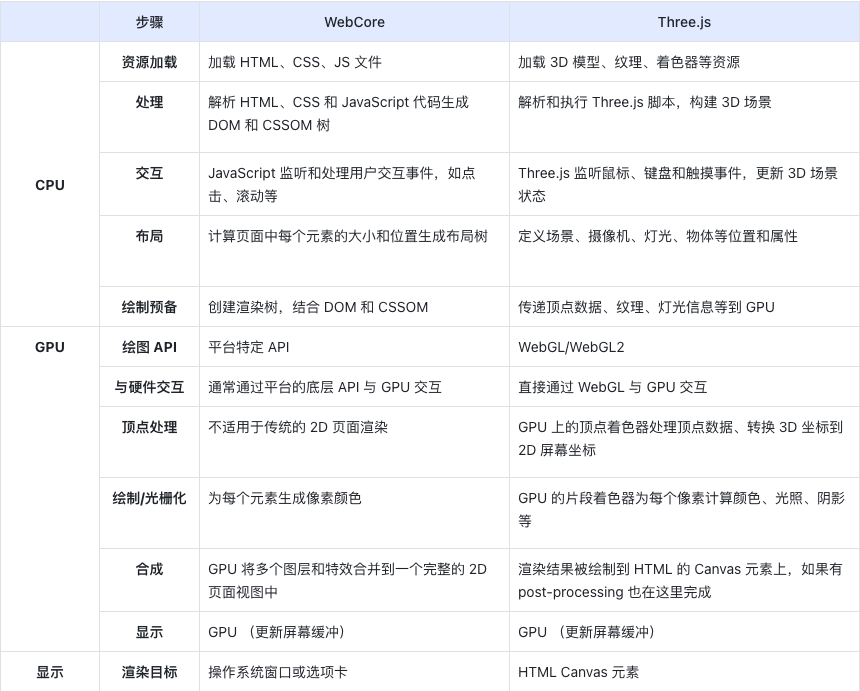
前端食堂技术周刊第 103 期:10 月登陆 Web 平台的新功能、TS 5.3 RC、React 2023 状态、高并发的哲学原理、Web 资源加载优先级
美味值:🌟🌟🌟🌟🌟 口味:夏梦玫珑 食堂技术周刊仓库地址:https://github.com/Geekhyt/weekly 大家好,我是童欧巴。欢迎来到前端食堂技术周刊,我们先来看下…...
数据类型转换)
Python(三)数据类型转换
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一份大厂面试资料《史上最全大厂面试题》,Springboot、微服务、算法、数据结构、Zookeeper、Mybatis、Dubbo、linux、Kafka、Elasticsearch、数据库等等 …...

linq to sql性能优化技巧
linq to sql 是一个代码生成器和ORM工具,他自动为我们做了很多事情,这很容易让我们对他的性能产生怀疑 linq to sql 是一个代码生成器和ORM工具,他自动为我们做了很多事情,这很容易让我们对他的性能产生怀疑。但是也有几个测试证明显示在做好优化的情况下,linq to sql的…...
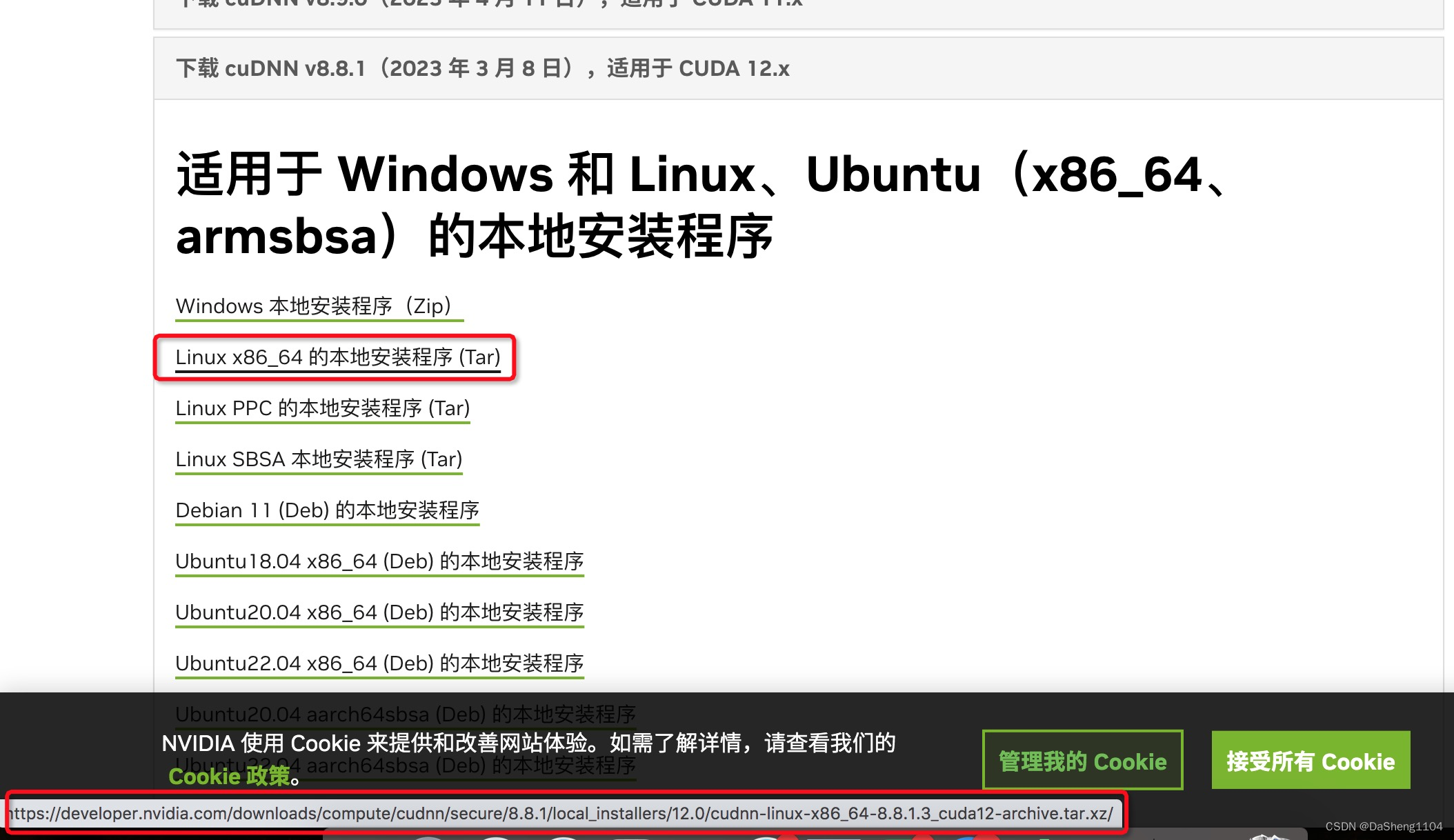
ubuntu20.04 安装cudnn
中文地址是.cn:cuDNN 历史版本 | NVIDIA 开发者 英文地址是.com:cuDNN 历史版本 | NVIDIA 开发者 1、下载cudnn:cudnn-local-repo-ubuntu2004-8.8.1.3_1.0-1_amd64.deb 解压并安装:sudo dpkg -i cudnn-local-repo-ubuntu2004-8.8…...
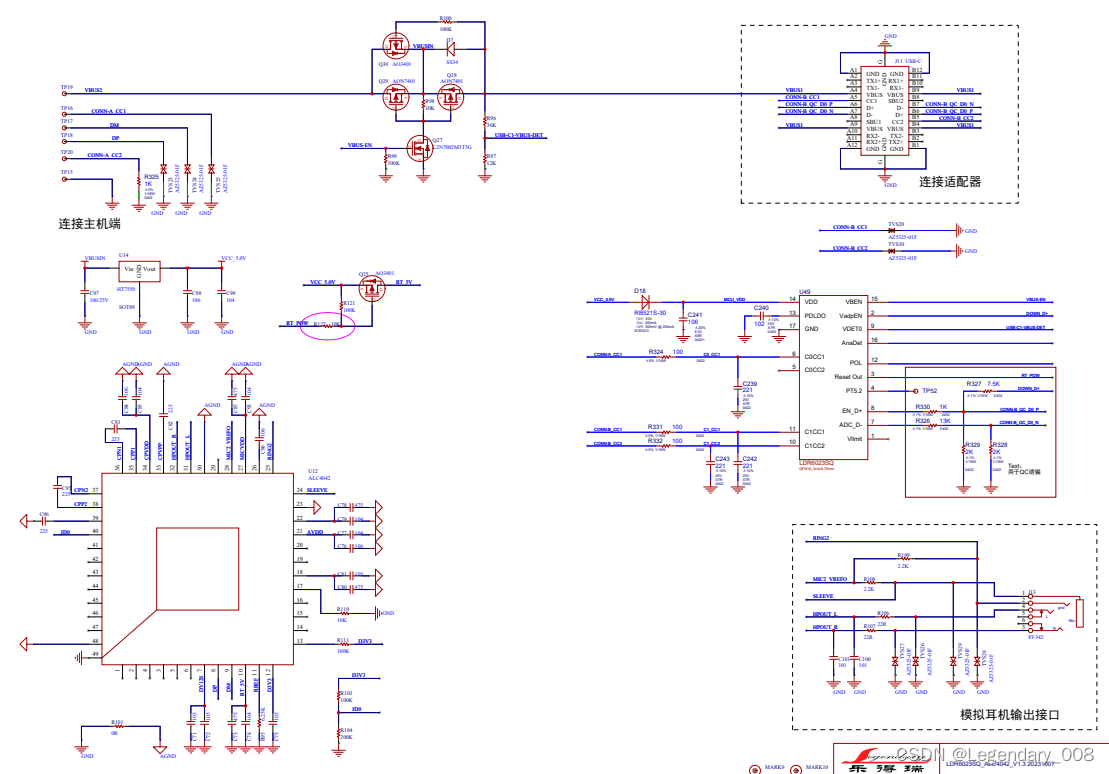
手机转接器实现原理,低成本方案讲解
USB-C PD协议里,SRC和SNK双方之间通过CC通信来协商请求确定充电功率及数据传输速率。当个设备需要充电时,它会发送消息去给适配器请求充电,此时充电器会回应设备的请求,并告知其可提供的档位功率,设备端会根据适配器端…...

RDS for MySQL 是什么
RDS for MySQL 是一种托管型数据库服务,RDS代表“关系数据库服务”(Relational Database Service)。这是云服务提供商提供的一种服务,用于简化关系数据库的设置、操作和扩展。对于MySQL版本的RDS,意味着它是专门为运行MySQL数据库管理系统的实…...
Java开发注意事项和细节说明
👨🎓👨🎓博主:发量不足 个人简介:耐心,自信来源于你强大的思想和知识基础!! 📑📑本期更新内容:Java开发注意事项和细节说明&…...
springboot中使用Java代码进行MongoDB集合数据备份
有时候mongo的集合中数据量太大,查询或翻页时可能会超过最大数量报错,可以给mongo的集合进行备份并保留最近一段时间的数据即可 下面是通过Java代码进行mongo的集合备份单元测试 import cn.hutool.core.date.DateUtil; import com.nuoyi.study.dao.mongo…...

JavaEE的渊源
JavaEE的渊源 1. JavaEE的起源2. JavaEE与Spring的诞生3. JavaEE发展历程(2003-2007)4. JavaEE发展历程(2009-至今)5. Java的Spec数目与网络结构 1. JavaEE的起源 我们首先来讲一下JavaEE的起源 ,为什么要来讲起源 ? …...

html中使用JQ自定义锚点偏移量
问题:一般情况下使用href跳转达到效果。如果页面中头部固定住了,点击瞄点的时候自动是最上面,头部会给它覆盖掉一部分,所以要在点击之后额外再加头部高度 <a href"#aa">Technical Documents</a><div id&…...
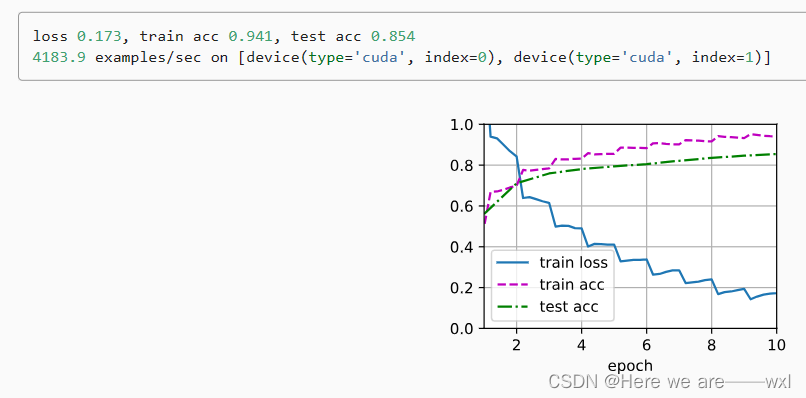
032、数据增广*
之——泛化性提升 杂谈 深度学习的数据增强(Data Augmentation)是一种技术,用于通过对原始数据进行多样性的变换和扩充,以增加训练数据的多样性,提高模型的泛化能力。这有助于减轻过拟合问题,提高深度学习模…...

力扣最热一百题——盛水最多的容器
终于又来了。我的算法记录的文章已经很久没有更新了。为什么呢? 这段时间都在更新有关python的文章,有对python感兴趣的朋友可以在主页找到。 但是这也并不是主要的原因 在10月5号我发布了我的第一篇博客,大家也可以看见我的每一篇算法博客…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

Python PIL 画矩形框
基础代码 from PIL import Image, ImageDraw# 打开图片 img Image.open(your_image.jpg)# 创建绘图对象 draw ImageDraw.Draw(img)# 矩形坐标 (x1, y1, x2, y2) coords (23, 21, 69, 76)# 画矩形框(红色,线宽2) draw.rectangle(coords, ou…...

上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷?
更多请点击: https://intelliparadigm.com 第一章:上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷? 在软件交付生命周期末期,传统人工代码审计与通用SAST工具常因误报率高、上下文理解弱而漏检高危漏…...

轻量化部署,异地机房快速接入,多机房管理不用再大动干戈
随着业务拓展,不少企业、单位陆续建起异地分部机房、多区域节点机房。传统资产管理系统部署复杂、对接困难,异地机房接入成本高、周期长,改造繁琐,让很多运维团队望而却步,只能继续沿用分散人工管理,资产混…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...
)
保姆级避坑指南:在Ubuntu 22.04上搞定ROS2 Humble、PX4与Gazebo的联合仿真(附Empy版本降级)
保姆级避坑指南:Ubuntu 22.04下ROS2 Humble与PX4联合仿真的21个关键陷阱当你在Ubuntu 22.04上第一次尝试搭建ROS2 Humble、PX4与Gazebo的联合仿真环境时,可能会遇到比预期更多的挑战。这不是一个简单的"复制粘贴命令就能完成"的任务——版本冲…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...