Spring Cloud之多级缓存
目录
传统缓存
多级缓存
JVM进程缓存
Caffeine
缓存驱逐策略
实现进程缓存
常用Lua语法
数据类型
变量声明
循环使用
定义函数
条件控制
安装OpenResty
实现Nginx业务逻辑编写
请求参数解析
实现lua访问tomcat
JSON的序列化和反序列化
Tomcat的集群负载均衡
资料下载:day04-多级缓存
下载完成后跟着案例导入说明去做
传统缓存
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,存在下面的问题
- 请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
- Redis缓存失效时,会对数据库产生冲击

多级缓存

多级缓存主要压力在于nginx,在生产环境中,我们需要通过部署nginx本地缓存集群以及一个nginx反向代理到本地缓存
JVM进程缓存
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
- 分布式缓存,例如Redis:
- 优点:存储容量更大、可靠性更好、可以在集群间共享
- 缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如HashMap、GuavaCache
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
Caffeine
案例测试代码
@Test
void testBasicOps() {// 创建缓存对象Cache<String, String> cache = Caffeine.newBuilder().build();// 存数据cache.put("name", "张三");// 取数据,不存在则返回nullString name = cache.getIfPresent("name");System.out.println("name = " + name);// 取数据,不存在则去数据库查询String defaultName = cache.get("defaultName", key -> {// 这里可以去数据库根据 key查询valuereturn "李四";});System.out.println("defaultName = " + defaultName);
}运行结果如下

缓存驱逐策略
Caffeine提供了三种缓存驱逐策略:
- 基于容量:设置缓存的数量上限
- 基于时间:设置缓存的有效时间
- 基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据,性能较差。
默认情况下,当缓存数据过期时,并不会立即将其清理和驱逐,而是在一次读或写操作后,或是在空闲时间完成对失效数据的驱逐。
基于容量实现
/*基于大小设置驱逐策略:*/@Testvoid testEvictByNum() throws InterruptedException {// 创建缓存对象Cache<String, String> cache = Caffeine.newBuilder()// 设置缓存大小上限为 1.maximumSize(1).build();// 存数据cache.put("name1", "张三");cache.put("name2", "李四");cache.put("name3", "王五");// 延迟10ms,给清理线程一点时间Thread.sleep(10L);// 获取数据System.out.println("name1: " + cache.getIfPresent("name1"));System.out.println("name2: " + cache.getIfPresent("name2"));System.out.println("name3: " + cache.getIfPresent("name3"));}运行结果如下

基于时间实现
/*基于时间设置驱逐策略:*/@Testvoid testEvictByTime() throws InterruptedException {// 创建缓存对象Cache<String, String> cache = Caffeine.newBuilder().expireAfterWrite(Duration.ofSeconds(1)) // 设置缓存有效期为 10 秒.build();// 存数据cache.put("name", "张三");// 获取数据System.out.println("name: " + cache.getIfPresent("name"));// 休眠一会儿Thread.sleep(1200L);System.out.println("name: " + cache.getIfPresent("name"));}运行结果如下

实现进程缓存
利用Caffeine实现下列需求:
- 给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
- 给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
- 缓存初始大小为100
- 缓存上限为10000
添加缓存对象
@Configuration
public class CaffeineConfig {/*** 商品信息缓存* @return*/@Beanpublic Cache<Long, Item> itemCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}/*** 商品库存缓存* @return*/@Beanpublic Cache<Long, ItemStock> itemStockCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}
}在ItemController中写入查询本地缓存的方法
@Autowiredprivate Cache<Long, Item> itemCache;@Autowiredprivate Cache<Long, ItemStock> itemStockCache;@GetMapping("/{id}")public Item findById(@PathVariable("id") Long id) {return itemCache.get(id, key -> {return itemService.query().ne("status", 3).eq("id", key).one();});}@GetMapping("/stock/{id}")public ItemStock findStockById(@PathVariable("id") Long id) {return itemStockCache.get(id,key->{return stockService.getById(id);});}修改完成后,访问localhost:8081/item/10001,观察控制台

存在一次数据库查询。后续再次查询相同id数据不会再次查询数据库。至此实现了JVM进程缓存。

常用Lua语法
Nginx与Redis的业务逻辑编写并不是通过Java语言,而是通过Lua。Lua是一种轻量小巧的脚本语言,用标准的C语言编写并以源代码形式开放,其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
入门案例,输出hello world
在linux中创建一个文本文件
touch hello.lua
# 进入vi模式
vi hello.lua
# 打印hello world。输入以下内容
print("hello world")# 保存退出后,运行lua脚本
lua hello.lua
或是直接输入命令启动lua控制台
lua
直接输入命令即可

数据类型
| 数据类型 | 描述 |
| nil | 表示一个无效值,类似于Java中的null,但在条件表达式中代表false |
| boolean | 包含:true与false |
| number | 表示双精度类型的实浮点数(简单来说,是数字都可以使用number表示) |
| string | 字符串,由单引号或双引号来表示 |
| function | 由C或是Lua编写的函数 |
| table | Lua中的表其实是一个“关联数组”,数组的索引可以是数字,字符串或表类型。在 Lua里,table的创建是通过“构造表达式”来完成,最简单构造表达式是{},用来创建一个空表。 |
变量声明
Lua声明变量的时候,并不需要指定数据类型
-- local代表局部变量,不加修饰词,代表全局变量
local str ='hello'
local num =10
local flag =true
local arr ={'java','python'} --需要注意的是,访问数组元素时,下标是从1开始
local table ={name='Jack',age=10} --类似于Java中的map类型,访问数据时是通过table['key']或是table.key循环使用
-- 声明数组
local arr={'zhangsan','lisi','wangwu'}
-- 进行循环操作
for index,value in ipairs(arr) doprint(index,value)
end
-- lua 脚本中,for循环从do开始end结束,数组解析使用ipairs
-- 声明table
local table={name='zhangsan',age=10}
-- 进行循环操作
for key,value in pairs(table) doprint(key,value)
end
-- table解析使用pairs执行lua脚本

定义函数
-- 声明数组
local arr={'zhangsan','lisi','wangwu'}
-- 定义函数
local function printArr(arr)for index,value in ipairs(arr) doprint(index,value)end
end
-- 执行函数
printArr(arr)执行lua脚本

条件控制
| 操作符 | 描述 | 实例 |
| and | 逻辑与操作符。若A为false,则返回A,否则返回B | (A and B)为false |
| or | 逻辑或操作符。若A为true,则返回A,否则返回B | (A or B)为true |
| not | 逻辑非操作符。与逻辑运算结果相反 | not(A and B)为true |
-- 声明数组
local table={name='zhangsan',sex='boy',age=15}
-- 定义函数
local function printTable(arr)if(not arr) thenprint('table中不存在该字段')return nilendprint(arr)
end
-- 执行函数
printTable(table.name)
printTable(table.addr)执行lua脚本

安装OpenResty
是基于Nginx的一个组件,主要作用是对Nginx编写业务逻辑
yum install -y pcre-devel openssl-devel gcc --skip-brokenyum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
# 如果失败则先执行下面一条语句后再执行上面这条
yum install -y yum-utils yum install -y openrestyyum install -y openresty-opm配置nginx的环境变量
vi /etc/profile# 在最下面插入如下信息
export NGINX_HOME=/usr/local/openresty/nginx
export PATH=${NGINX_HOME}/sbin:$PATH# 保存后刷新配置
source /etc/profile修改/usr/local/openresty/nginx/conf/nginx.conf配置文件如下
#user nobody;
worker_processes 1;
error_log logs/error.log;events {worker_connections 1024;
}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;server {listen 8081;server_name localhost;location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}启动nginx
# 启动nginx
nginx
# 重新加载配置
nginx -s reload
# 停止
nginx -s stop
启动后,访问虚拟机的8081端口,如果正常跳转页面如下

实现Nginx业务逻辑编写
先分析请求转发流程。打开win系统上的nginx路由配置文件
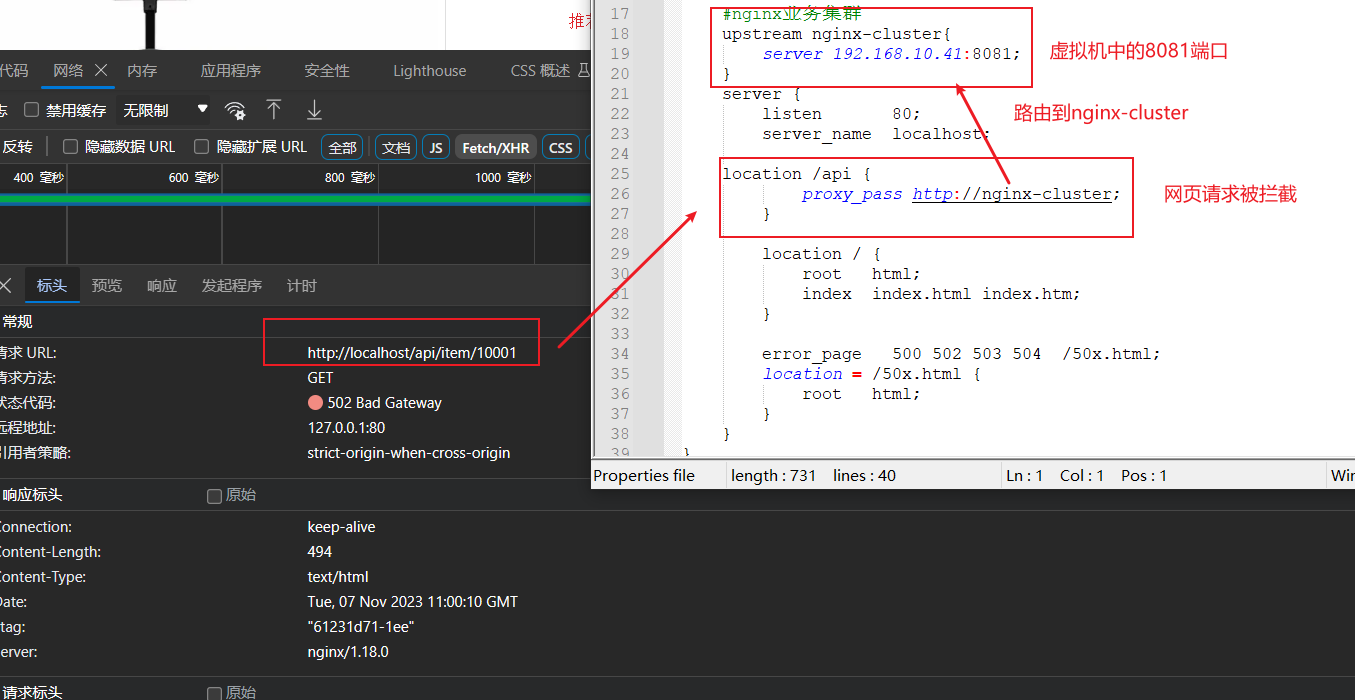
接下来就需要对虚拟机中的nginx添加业务逻辑了
对虚拟机Nginx中的配置文件添加如下代码
# 放入http模块下#lua 模块lua_package_path "/usr/local/openresty/lualib/?.lua;;";#c模块 lua_package_cpath "/usr/local/openresty/lualib/?.so;;"; # 放入server模块下location /api/item {# 响应类型为jsondefault_type application/json;# 响应结果来源content_by_lua_file lua/item.lua;}编写lua脚本
在nginx目录下创建lua文件夹,并创建lua脚本
mkdir lua
touch lua/item.lua先使用假数据测试是否可以正常响应
ngx.say('{"id":10001,"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":17900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')访问localhost/item.html?id=10001。查看控制台是否正常响应。如果出现如下错误,去观察win系统下的nginx日志,我的打印了如下错误
2023/11/07 19:29:38 [error] 16784#2812: *34 connect() failed (10061: No connection could be made because the target machine actively refused it) while connecting to upstream, client: 127.0.0.1, server: localhost, request: "GET /api/item/10001 HTTP/1.1", upstream: "http://192.168.10.10:8081/api/item/10001", host: "localhost", referrer: "http://localhost/item.html?id=10001"

解决方法,打开任务管理器,将所有关于nginx的服务全部结束再次重启win系统下的nginx即可。如果不是此类错误,请查看linux系统下的错误日志。
请求参数解析
| 参数格式 | 参数实例 | 参数解析代码示例 |
| 路径占位符 | /item/1001 | 拦截路径中:location ~ /item/(\d+){} ~:表示使用正则表达式 (\d+):表示至少有一位数字 Lua脚本中:local id = ngx.var[1] 匹配到的参数会存入ngx.var数组中,通过下标获取 |
| 请求头 | id:1001 | 获取请求头,返回值是table类型 local headers = ngx.req.get_headers() |
| Get请求参数 | ?id=1001 | 获取GET请求参数,返回值是table类型 local getParams = ngx.req.get_uri_args() |
| Post表单参数 | id=1001 | 读取请求体:ngx.req.read_body() 获取POST表单参数,返回值是table类型 local postParams = ngx.req.get_post_args() |
| JSON参数 | {"id": 1001} | 读取请求体:ngx.reg.read bodv() 获取body中的ison参数,返回值是string类型 local jsonBody = ngx.req.get_body_data() |
修改linux中nginx的配置文件,实现参数解析
location ~ /api/item/(\d+) {# 响应类型为jsondefault_type application/json;# 响应结果来源content_by_lua_file lua/item.lua;}修改lua脚本
-- 获取参数
local id = ngx.var[1]
-- 返回结果
ngx.say('{"id":'..id..',"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":17900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')访问id为10002的参数,可以发现id随着参数改变,而不是伪数据了

实现lua访问tomcat
nginx提供了内部API用来发送http请求
local resp = ngx.location.capture("/path",{method = ngx.HTTP_GET,-- 请求方式args = {a=1,b=2},-- get方式传参数body ="c=3&d=4" -- post方式传参数
})返回响应结果内容包括:
- resp.status:响应状态码
- resp.header:响应头,是一个table
- resp.body:响应体,就是响应数据
需要注意的是,/path不会指定IP地址和端口而是会被内部拦截,这个时候我们还需要编写一个路由器,发送到对应的服务器。修改linux中的nginx.conf文件添加如下配置
location /item {proxy_pass http://192.168.10.11:8081;}发起Http请求我们可以封装成一个方法,让其他请求发起时也可以调用,因此,我们可以在lualib文件夹下,创建lua脚本。
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)local resp = ngx.location.capture(path,{method = ngx.HTTP_GET,args = params,})if not resp then-- 记录错误信息,返回404ngx.log(ngx.ERR, "http not found, path: ", path , ", args: ", args)ngx.exit(404)endreturn resp.body
end
-- 将方法导出
local _M = { read_http = read_http
}
return _M修改item.lua脚本,不再返回伪数据,而是查询真实的数据
-- 导入common函数库
local common = require('common')
local read_http = common.read_http-- 获取参数
local id = ngx.var[1]
-- 查询商品信息
local itemJSON = read_http('/item/'..id,nil)
-- 查询库存信息
local stockJSON = read_http('/item/stock/'..id,nil)
-- 返回结果
ngx.say(itemJSON)这里只返回了商品信息,接下来访问其他id的商品,查看是否可以查询出商品信息
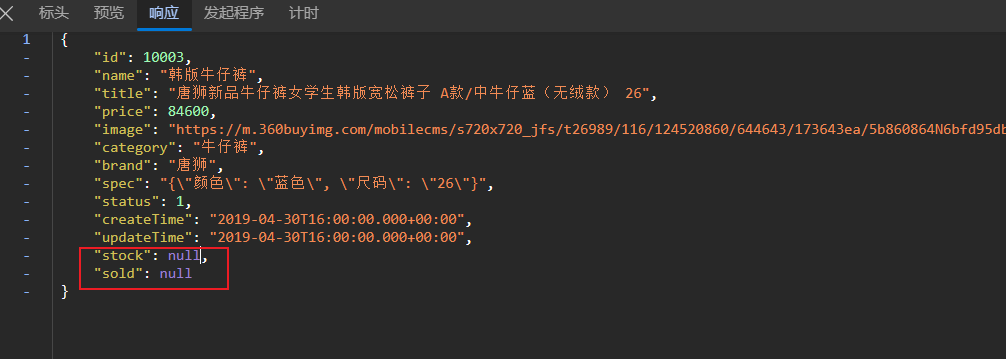
JSON的序列化和反序列化
引入cjson模块,实现序列化与反序列化
-- 导入common函数库
local common = require('common')
local cjson = require('cjson')
local read_http = common.read_http-- 获取参数
local id = ngx.var[1]
-- 查询商品信息
local itemJSON = read_http('/item/'..id,nil)
-- 查询库存信息
local stockJSON = read_http('/item/stock/'..id,nil)
-- 反序列化JSON商品信息为table类型数据
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
-- 数据组合
item.stock = stock.stock
item.sold = stock.sold-- 序列化为JSON
-- 返回结果
ngx.say(cjson.encode(item))
Tomcat的集群负载均衡
这里我们访问的服务端口是写死的,但通常tomcat是一个集群,因此,我们需要修改我们linux的配置文件,配置tomcat集群
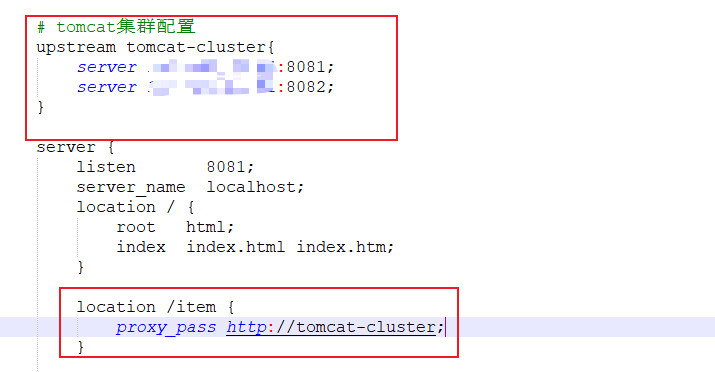
由于Tomcat的负载均衡策略为轮询,那么就会产生一个问题,tomcat集群的进程缓存是不共享的,也就是说,第一次访问8081生成的缓存,在第二次访问8082时,是不存在的,会在8082也生成一份相同的缓存。所以我们需要保证访问同一个id的请求,会被路由到存在缓存的那个tomcat服务器上。这就需要我们修改负载均衡算法。实际实现很简单,只需要在tomcat集群配置添加一行
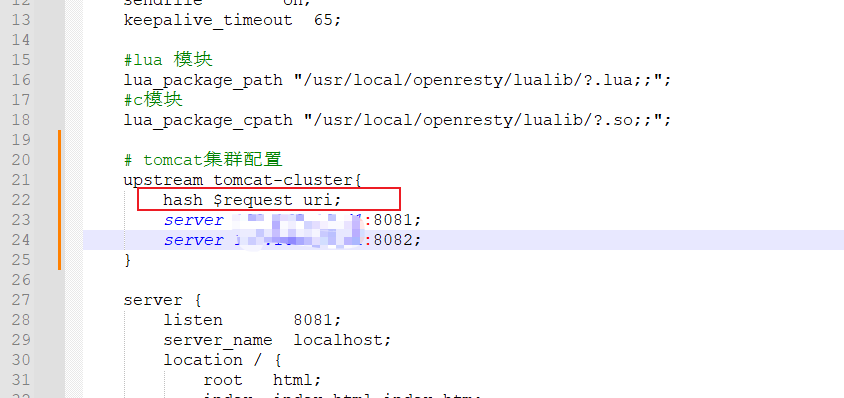
实现原理是,nginx会对拦截到的请求进行hash算法,然后对集群数量进行取余。从而保证对同一个id的请求都会被路由到同一个tomcat服务器。
相关文章:
Spring Cloud之多级缓存
目录 传统缓存 多级缓存 JVM进程缓存 Caffeine 缓存驱逐策略 实现进程缓存 常用Lua语法 数据类型 变量声明 循环使用 定义函数 条件控制 安装OpenResty 实现Nginx业务逻辑编写 请求参数解析 实现lua访问tomcat JSON的序列化和反序列化 Tomcat的集群负载均衡 …...

融云荣登「2023 年度 PaaS 企业排行榜」
11 月 2 日,中国科学院旗下《互联网周刊》颁布“2023 年度 PaaS 企业排行榜”,融云荣登榜单。关注【融云全球互联网通信云】了解更多 根据中国信息通信研究院《云计算白皮书 2023》:2022 年,PaaS 增长强势,总收入 342 …...

YOLOv8轻量化模型:模型轻量化设计 | 轻量级可重参化EfficientRep| 来自YOLOv6思想
💡💡💡本文解决什么问题:在几乎不保证精度下降的前提下,轻量级模型创新设计 EfficientRep 在关键点检测任务中 | GFLOPs从9.6降低至8.5, mAP50从0.921下降至0.912,mAP50-95从0.697提升至0.779 YOLO轻量化模型专栏:http://t.csdnimg.cn/AeaEF 1.YOLOv6介绍 论文…...
【JavaSE】基础笔记 - 类和对象(下)
目录 1、this引用 1.1、为什么要有this引用 1.2、什么是this引用 1.3、 this引用的特性 2、 对象的构造及初始化 2.1、 如何初始化对象 2.2、构造方法 2.2.1、概念 2.2.2、特性 2.3、默认初始化 2.4、就地初始化 上篇:【JavaSE】基础笔记 - 类和对象&#…...

浅析刚入门Python初学者的注意事项
文章目录 一、注意你的Python版本1.print()函数2.raw_input()与input()3.比较符号,使用!替换<>4.repr函数5.exec()函数 二、新手常遇到的问题1、如何写多行程序?2、如何执行.py文件?3、and,or,not4、True和False…...

2023NOIP A层联测26 总结
T1 求 ∑ i 1 n ∑ j i n ( ⨁ k i j a k ) 2 \sum\limits_{i1}^n\sum\limits_{ji}^n\left(\bigoplus\limits_{ki}^{j}a_k\right)^2 i1∑nji∑n(ki⨁jak)2, n , a i ≤ 2 1 0 5 n,a_i\le2\times10^5 n,ai≤2105。先转成前缀和,然后就没思…...
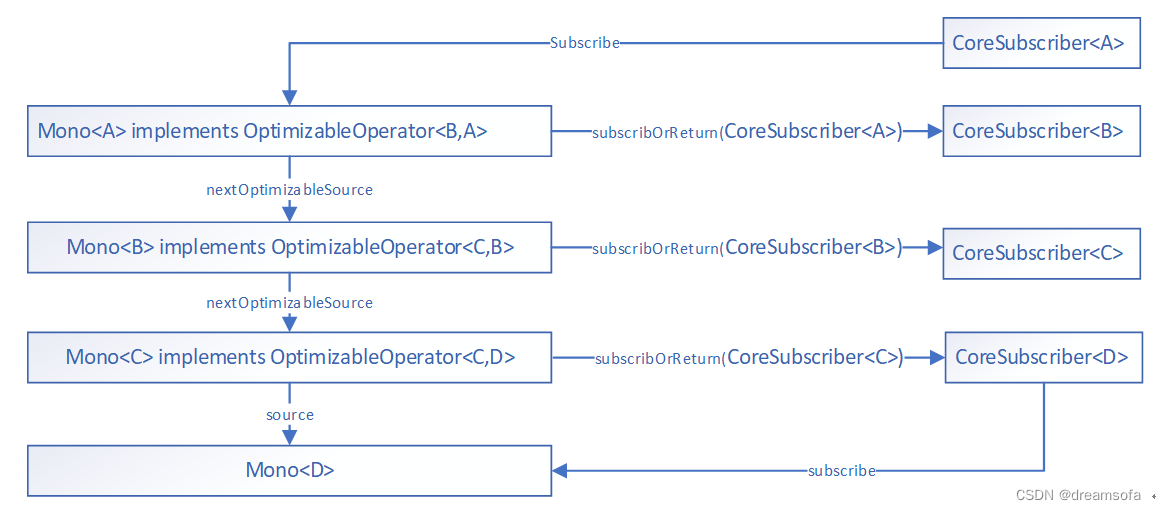
响应式编程-Project Reactor Mono 介绍
响应式编程-Project Reactor Mono 介绍 本文以Mono的角度来介绍Reactor编程,Flux的使用同理。 初体验 Web应用 controller 方法在Spring webmvc 和 Spring webFlux下Controller方法实现示例如下: Spring webmvc: GetMapping("/test1") …...
R语言实操记录——导出高清图片(矢量图)
R语言 R语言实操记录——导出高清图片(矢量图) 文章目录 R语言一、起因(闲聊,可跳过)二、如何在R中导出高清图片(矢量图)2.1、保存为EPS图片格式后转AI编辑2.2、保存为PDF格式(推荐…...
Apache Doris 开源最顶级基于MPP架构的高性能实时分析数据库
背景介绍 Apache Doris是一个基于MPP架构的易于使用,高性能和实时的分析数据库,以其极高的速度和易用性而闻名。海量数据下返回查询结果仅需亚秒级响应时间,不仅可以支持高并发点查询场景,还可以支持高通量复杂分析场景。 这些都…...
webgoat-Request Forgeries 请求伪造
(A8:2013) Request Forgeries Cross-Site Request Forgeries 跨站请求伪造,又称一键攻击或会话骑乘,简称CSRF (有时发音为 sea-surf)或 XSRF,是一种恶意利用网站,其中传输未经授权的命令 来自网站信任的用…...

【flask跨域问题】解决它
大概7-8年前,前后端还没开始分离或者刚开始分离的之前,跨域问题很多。 后来我就没在遇到过了,这次做一个小项目,又遇到了,记录下。 现在前端的脚手架都自己能解决了。 1. 跨域 是因为出于浏览器的同源策略限制。同源…...

虚幻引擎:如何在工程里面添加插件
1.在自己的项目中安装插件 在content目录下创建一个Plugins的文件,将插件文件放进去即可 2.在软件上安装,这样所有创建的项目都会带有此插件 将插件放在自己软件的这个目录下就好了...
SpringCloud Alibaba 【四】Openfeign
Openfeign配置与使用 前言介绍openfeign使用openfeign导入依赖启动类正式使用测试结果 前言 在springcloud中消费者项目需要调用提供者项目的接口,一开始用的是RestTemplate中的方法。但是RestTemplate进行远程调用时,直接调用controller层的接口&#…...

语音信号的线性预测分析、合成及MATLAB编程设计实现
需要的基础:AR模型、列文森-杜宾递推法 推荐阅读: 基于线性预测的语音编码原理解析 基于线性预测的语音编码原理解析 这篇文章和上一篇类似 语音信号的线性预测分析及其Matlab源码 这篇文章是要付费看的,但是他能预览的那部分写的确实好 语…...
rabbitMQ rascal/amqplib报错 Error: Unexpected close 排查
以下是一些可能导致此 RabbitMQ 客户端或任何其他 RabbitMQ 客户端中的套接字读取或写入失败的常见场景 1.错过(客户端)心跳 第一个常见原因是RabbitMQ 检测到心跳丢失。发生这种情况时,RabbitMQ 将添加一个有关它的日志条目,然…...
一文1600字使用Postman搞定各种接口token实战(建议收藏)
现在许多项目都使用jwt来实现用户登录和数据权限,校验过用户的用户名和密码后,会向用户响应一段经过加密的token,在这段token中可能储存了数据权限等,在后期的访问中,需要携带这段token,后台解析这段token才…...
Vue自定义组件学习笔记
专业描述: vue关于自定义组件的描述中,父子组件是相对的概念,父组件表示引用当前组件的组件,子组件就是当前组件; 1)关于props和emits选项的理解 1.props:我们平时写的.vue文件实际上就是一个自定义组件,只是一般不会考虑复用性,不会去设置props选项,…...

王道p18 第12题假设 A中的 n个元素保存在一个一维数组中,请设计一个尽可能高效的算法,找出A的主元素。若存在主元素,则输出该元素:否则输出-1
视频讲解在:👇 p18 第12题 c语言实现王道数据结构课后习题_哔哩哔哩_bilibili 从前向后扫描数组元素,标记出一个可能成为主元素的元素 Num。然后重新计数,确认 Num 是否是主元素。 我们可分为以下两步: 1.选取候选的主元素。依…...
OpenTiny Vue 3.11.0 发布:增加富文本、ColorPicker等4个新组件,迎来了贡献者大爆发!
非常高兴跟大家宣布,2023年10月24日,OpenTiny Vue 发布了 v3.11.0 🎉。 OpenTiny 每次大版本发布,都会给大家带来一些实用的新特性,8.14 我们发布了 v3.10.0 版本,增加了4个新组件,组件 Demo 支…...

vivado查看报告和消息5
1、可配置报告策略 “ Configurable Report Strategies ” ( 可配置报告策略 ) 支持在 Vivado 工程模式下运行综合与实现的每个步骤之后选择 要运行的报告命令。根据设计阶段、设计复杂性和用户首选项, 需自动生成一组不同的报告以供频繁查…...

用STM32CubeMX和HAL库快速上手WS2812B:告别手动计算延时,一键生成驱动框架
基于STM32CubeMX的WS2812B智能灯光控制:从零构建现代化驱动方案在智能硬件和物联网设备快速发展的今天,WS2812B可编程LED灯带因其丰富的色彩表现和简单的单线控制方式,成为创客和工程师们最喜爱的显示组件之一。然而,传统的寄存器…...

森优时铁锌维发根养黑用三个月真实效果实测:内服营养养黑的客观测评
"森优时铁锌维发根养黑用三个月真实效果实测显示,针对压力、熬夜引发的早白问题,通过内服补充毛囊所需营养的方式,多数使用者能感受到发根韧性提升、新生发色素沉淀改善,整体改善效果因人而异,合规的营养补充是目…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

ZYNQ中断避坑指南:PL端信号线如何正确‘连线’到PS端处理函数?
ZYNQ中断系统深度解析:从硬件信号到软件响应的全链路实践 在嵌入式系统开发中,中断处理是实时响应的核心机制。对于ZYNQ这种集成了ARM处理器(PS)和可编程逻辑(PL)的异构计算平台,其中断系统既有传统处理器的特性,又具备FPGA灵活定…...

基于Arduino UNO的真随机数生成与数据持久化在Tambola游戏机中的应用
1. 项目概述:用Arduino UNO打造一台全自动Tambola游戏机如果你玩过或者听说过Tambola(在印度非常流行的游戏,在欧美也叫Bingo或Housie),就知道它的核心玩法是主持人从一个装有数字球的容器中随机抽取号码,玩…...

Unity中MMD初音资源导入与动画落地全流程指南
1. 这不是普通模型包:初音跳舞资源在Unity中的真实价值定位“Unity初音跳舞精品模型动画资源分享”——看到这个标题,很多刚接触Unity的美术向开发者第一反应是:“哇,能直接放进项目里做Demo了!”但我在带三个独立游戏…...

基于Arduino Uno与MQ-2传感器的智能气体检测报警系统DIY全攻略
1. 项目概述与核心思路最近在捣鼓家里的智能安防,琢磨着能不能自己做一个成本可控、反应灵敏的气体检测报警装置。市面上成品烟雾报警器虽然成熟,但要么功能单一,要么价格不菲,而且很难根据自己的需求进行定制化调整,比…...
)
【小白快速上手】 OpenClaw 安装部署全流程(含安装包)
OpenClaw 一键安装包|一键部署,告别复杂环境配置 适配系统:Windows10/11 64 位当前版本:v2.7.5(虾壳云版)核心优势:全程可视化操作,无需命令行、无需手动配置 Python/Node.js&#…...