pandas教程:Hierarchical Indexing 分层索引、排序和统计
文章目录
- Chapter 8 Data Wrangling: Join, Combine, and Reshape(数据加工:加入, 结合, 变型)
- 8.1 Hierarchical Indexing(分层索引)
- 1 Reordering and Sorting Levels(重排序和层级排序)
- 2 Summary Statistics by Level (按层级来归纳统计数据)
- 3 Indexing with a DataFrame’s columns(利用DataFrame的列来索引)
Chapter 8 Data Wrangling: Join, Combine, and Reshape(数据加工:加入, 结合, 变型)
在很多应用中,数据通常散落在不同的文件或数据库中,并不方便进行分析。这一章主要关注工具,能帮我们combine, join, rearrange数据。
8.1 Hierarchical Indexing(分层索引)
Hierarchical Indexing是pandas中一个重要的特性,能让我们在一个轴(axis)上有多个index levels(索引层级)。它可以让我们在低维格式下处理高维数据。这里给出一个简单的例子,构建一个series,其index是a list of lists:
import pandas as pd
import numpy as np
data = pd.Series(np.random.randn(9),index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],[1, 2, 3, 1, 3, 1, 2, 2, 3]])
data
a 1 0.6360822 -1.4130613 -0.530704
b 1 -0.0416343 -0.042303
c 1 0.4299112 0.783350
d 2 0.2843283 -0.360963
dtype: float64
其中我们看到的是把MultiIndex作为index(索引)的,美化过后series。
data.index
MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],labels=[[0, 0, 0, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 2, 0, 1, 1, 2]])
对于这种分层索引对象,partial indexing(部分索引)也是能做到的,这种方法可以让我们简洁地选中数据的一部分:
data['b']
1 -0.041634
3 -0.042303
dtype: float64
data['b': 'c']
b 1 -0.0416343 -0.042303
c 1 0.4299112 0.783350
dtype: float64
data.loc[['b', 'd']]
b 1 -0.0416343 -0.042303
d 2 0.2843283 -0.360963
dtype: float64
selection(选中)对于一个内部层级(inner level)也是可能的:
data.loc[:, 2]
a -1.413061
c 0.783350
d 0.284328
dtype: float64
分层索引的作用是改变数据的形状,以及做一些基于组的操作(group-based)比如做一个数据透视表(pivot table)。例子,我们可以用unstack来把数据进行重新排列,产生一个DataFrame:
data.unstack()
| 1 | 2 | 3 | |
|---|---|---|---|
| a | 0.636082 | -1.413061 | -0.530704 |
| b | -0.041634 | NaN | -0.042303 |
| c | 0.429911 | 0.783350 | NaN |
| d | NaN | 0.284328 | -0.360963 |
相反的操作是stack:
data.unstack().stack()
a 1 0.6360822 -1.4130613 -0.530704
b 1 -0.0416343 -0.042303
c 1 0.4299112 0.783350
d 2 0.2843283 -0.360963
dtype: float64
之后的章节会对unstack和stack做更多介绍。
对于dataframe,任何一个axis(轴)都可以有一个分层索引:
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],columns=[['Ohio', 'Ohio', 'Colorado'],['Green', 'Red', 'Green']])
frame
| Ohio | Colorado | |||
|---|---|---|---|---|
| Green | Red | Green | ||
| a | 1 | 0 | 1 | 2 |
| 2 | 3 | 4 | 5 | |
| b | 1 | 6 | 7 | 8 |
| 2 | 9 | 10 | 11 | |
每一层级都可以有一个名字(字符串或任何python对象)。如果有的话,这些会显示在输出中:
frame.index.names = ['key1', 'key2']
frame.columns.names = ['state', 'color']
frame
| state | Ohio | Colorado | ||
|---|---|---|---|---|
| color | Green | Red | Green | |
| key1 | key2 | |||
| a | 1 | 0 | 1 | 2 |
| 2 | 3 | 4 | 5 | |
| b | 1 | 6 | 7 | 8 |
| 2 | 9 | 10 | 11 | |
这里我们要注意区分行标签(row label)中索引的名字’state’和’color’。
如果想要选中部分列(partial column indexing)的话,可以选中一组列(groups of columns):
frame['Ohio']
| color | Green | Red | |
|---|---|---|---|
| key1 | key2 | ||
| a | 1 | 0 | 1 |
| 2 | 3 | 4 | |
| b | 1 | 6 | 7 |
| 2 | 9 | 10 |
MultiIndex能被同名函数创建,而且可以重复被使用;在DataFrame中给列创建层级名可以通过以下方式:
pd.MultiIndex.from_arrays([['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']],names=['state', 'color'])
MultiIndex(levels=[['Colorado', 'Ohio'], ['Green', 'Red']],labels=[[1, 1, 0], [0, 1, 0]],names=['state', 'color'])
1 Reordering and Sorting Levels(重排序和层级排序)
有时候我们需要在一个axis(轴)上按层级进行排序,或者在一个层级上,根据值来进行排序。swaplevel会取两个层级编号或者名字,并返回一个层级改变后的新对象(数据本身并不会被改变):
frame.swaplevel('key1', 'key2')
| state | Ohio | Colorado | ||
|---|---|---|---|---|
| color | Green | Red | Green | |
| key2 | key1 | |||
| 1 | a | 0 | 1 | 2 |
| 2 | a | 3 | 4 | 5 |
| 1 | b | 6 | 7 | 8 |
| 2 | b | 9 | 10 | 11 |
另一方面,sort_index则是在一个层级上,按数值进行排序。比如在交换层级的时候,通常也会使用sort_index,来让结果按指示的层级进行排序:
frame.sort_index(level=1)
| state | Ohio | Colorado | ||
|---|---|---|---|---|
| color | Green | Red | Green | |
| key1 | key2 | |||
| a | 1 | 0 | 1 | 2 |
| b | 1 | 6 | 7 | 8 |
| a | 2 | 3 | 4 | 5 |
| b | 2 | 9 | 10 | 11 |
frame.sort_index(level='color')
frame.sort_index(level='state')
# 这两个语句都会报错
(按照我的理解,level指的是key1和key2,key1是level=0,key2是level=1。可以看到下面的结果和上面是一样的:)
frame.sort_index(level='key2')
| state | Ohio | Colorado | ||
|---|---|---|---|---|
| color | Green | Red | Green | |
| key1 | key2 | |||
| a | 1 | 0 | 1 | 2 |
| b | 1 | 6 | 7 | 8 |
| a | 2 | 3 | 4 | 5 |
| b | 2 | 9 | 10 | 11 |
frame.swaplevel(0, 1).sort_index(level=0) # 把key1余key2交换后,按key2来排序
| state | Ohio | Colorado | ||
|---|---|---|---|---|
| color | Green | Red | Green | |
| key2 | key1 | |||
| 1 | a | 0 | 1 | 2 |
| b | 6 | 7 | 8 | |
| 2 | a | 3 | 4 | 5 |
| b | 9 | 10 | 11 | |
如果index是按词典顺序那种方式来排列的话(比如从外层到内层按a,b,c这样的顺序),在这种多层级的index对象上,数据选择的效果会更好一些。这是我们调用sort_index(level=0) or sort_index()
2 Summary Statistics by Level (按层级来归纳统计数据)
在DataFrame和Series中,一些描述和归纳统计数据都是有一个level选项的,这里我们可以指定在某个axis下,按某个level(层级)来汇总。比如上面的DataFrame,我们可以按 行 或 列的层级来进行汇总:
frame
| state | Ohio | Colorado | ||
|---|---|---|---|---|
| color | Green | Red | Green | |
| key1 | key2 | |||
| a | 1 | 0 | 1 | 2 |
| 2 | 3 | 4 | 5 | |
| b | 1 | 6 | 7 | 8 |
| 2 | 9 | 10 | 11 | |
frame.sum(level='key2')
| state | Ohio | Colorado | |
|---|---|---|---|
| color | Green | Red | Green |
| key2 | |||
| 1 | 6 | 8 | 10 |
| 2 | 12 | 14 | 16 |
frame.sum(level='color', axis=1)
| color | Green | Red | |
|---|---|---|---|
| key1 | key2 | ||
| a | 1 | 2 | 1 |
| 2 | 8 | 4 | |
| b | 1 | 14 | 7 |
| 2 | 20 | 10 |
3 Indexing with a DataFrame’s columns(利用DataFrame的列来索引)
把DataFrame里的一列或多列作为行索引(row index)是一件很常见的事;另外,我们可能还希望把行索引变为列。这里有一个例子:
frame = pd.DataFrame({'a': range(7), 'b': range(7, 0, -1),'c': ['one', 'one', 'one', 'two', 'two','two', 'two'],'d': [0, 1, 2, 0, 1, 2, 3]})
frame
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0 | 7 | one | 0 |
| 1 | 1 | 6 | one | 1 |
| 2 | 2 | 5 | one | 2 |
| 3 | 3 | 4 | two | 0 |
| 4 | 4 | 3 | two | 1 |
| 5 | 5 | 2 | two | 2 |
| 6 | 6 | 1 | two | 3 |
DataFrame的set_index会把列作为索引,并创建一个新的DataFrame:
frame2 = frame.set_index(['c', 'd'])
frame2
| a | b | ||
|---|---|---|---|
| c | d | ||
| one | 0 | 0 | 7 |
| 1 | 1 | 6 | |
| 2 | 2 | 5 | |
| two | 0 | 3 | 4 |
| 1 | 4 | 3 | |
| 2 | 5 | 2 | |
| 3 | 6 | 1 |
默认删除原先的列,当然我们也可以留着:
frame.set_index(['c', 'd'], drop=False)
| a | b | c | d | ||
|---|---|---|---|---|---|
| c | d | ||||
| one | 0 | 0 | 7 | one | 0 |
| 1 | 1 | 6 | one | 1 | |
| 2 | 2 | 5 | one | 2 | |
| two | 0 | 3 | 4 | two | 0 |
| 1 | 4 | 3 | two | 1 | |
| 2 | 5 | 2 | two | 2 | |
| 3 | 6 | 1 | two | 3 |
另一方面,reset_index的功能与set_index相反,它会把多层级索引变为列:
frame2.reset_index()
| c | d | a | b | |
|---|---|---|---|---|
| 0 | one | 0 | 0 | 7 |
| 1 | one | 1 | 1 | 6 |
| 2 | one | 2 | 2 | 5 |
| 3 | two | 0 | 3 | 4 |
| 4 | two | 1 | 4 | 3 |
| 5 | two | 2 | 5 | 2 |
| 6 | two | 3 | 6 | 1 |
相关文章:

pandas教程:Hierarchical Indexing 分层索引、排序和统计
文章目录 Chapter 8 Data Wrangling: Join, Combine, and Reshape(数据加工:加入, 结合, 变型)8.1 Hierarchical Indexing(分层索引)1 Reordering and Sorting Levels(重排序和层级排序)2 Summa…...
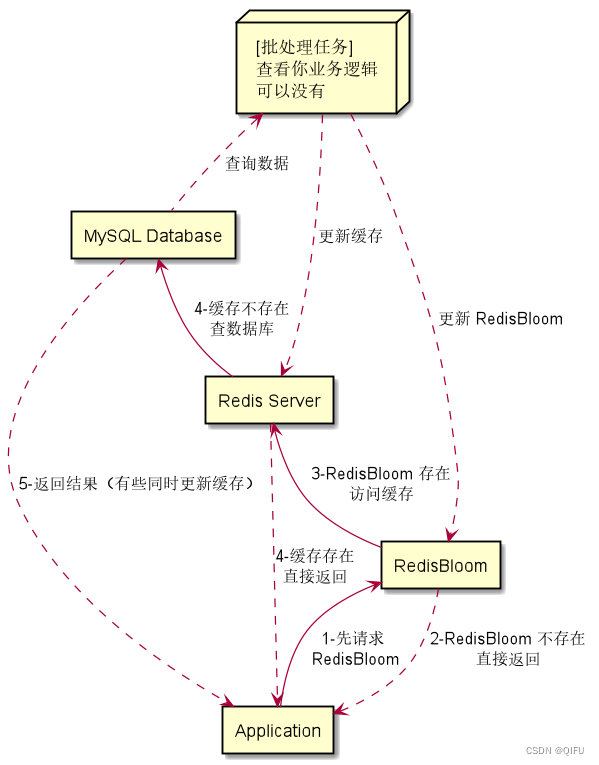
Redis 扩展 RedisBloom 插件,解决缓存击穿、穿透
文章目录 一、概述二、编译准备2.1 升级 make2.2 安装 Python3 三、编译 RedisBloom四、测试 RedisBloom五、应用场景5.1 缓存击穿5.2 缓存穿透5.3 原理总结 六、存在的问题 如果您对Redis的了解不够深入请关注本栏目,本栏目包括Redis安装,Redis配置文件…...

VBA技术资料MF80:选择文件及文件夹
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。我的教程一共九套,分为初级、中级、高级三大部分。是对VBA的系统讲解,从简单的入门,到…...
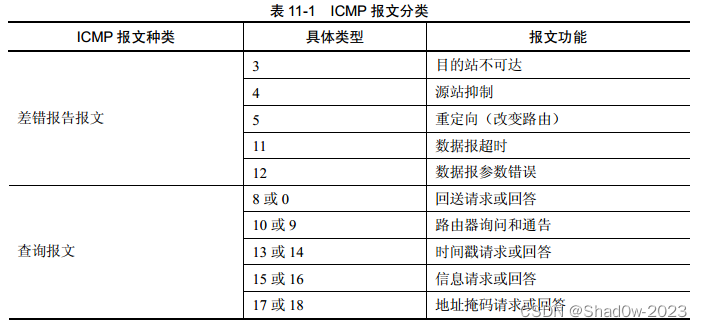
网络层:控制平面
路由选择算法 路由选择算法就是为了在端到端的数据传输中,选择路径上路由器的最好的路径。通常,一条好的路径指具有最低开销的路径。最低开销路径是指源和目的地之间具有最低开销的一条路。 根据集中式还是分散式来划分 集中式路由选择算法:…...
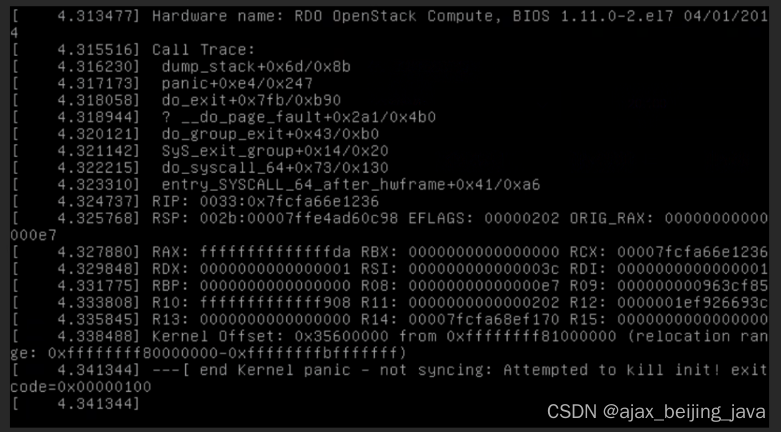
Ubuntu 系统内核 kernel panic
Ubuntu 系统内核 kernel panic 不能进入系统:报错end kernel panic -not syncing: attemped to kill init! exit code 0x00000100 系统启动的时候,按下‘e’键进入grub编辑界面,编辑grub菜单,选择“kernel /vmlinuz-XXXXro root…...

【flink】RowData copy/clone方式
说明:一般用户常用的是GenericRowData。flink内部则多使用BinaryRowData。 方法一、循环解决(不推荐): 代码较为复杂需要根据RowType获取到内部fields的logicalType,再使用RowData.createFieldGetter方法创建fieldGetters。 public static …...
网页图标工具
工具地址...

掌动智能:功能测试及拨测主要功能
在企业中对于功能测试及拨测而言,用户只需提供应用包和产品文档,由资深测试专家设计并执行测试,覆盖核心场景,包含特定业务流程以及行业通用特殊场景,支持需求定制。 执行过程严格监控,依据应用功能和业务需…...
)
第11章 Java集合(二)
目录 内容说明 章节内容 一、Set接口 二、HashSet集合 三、LinkedHashSet集合 四、TreeSet集合...
Transformer和ELMo模型、word2vec、独热编码(one-hot编码)之间的关系
下面简要概述了Transformer和ELMo模型、word2vec、独热编码(one-hot编码)之间的关系: 独热编码(One-hot Encoding)是一种最基本的词表示方法,将词表示为高维稀疏向量。它与ELMo、word2vec和Transformer的关…...

您与1秒钟测量两千个尺寸之间仅差一台智能测径仪!
随着产线的发展,自动化程度越来越高,生产速度越来越快,人们对产品的品质要求越来越高,对检测也提出了更高的要求。传统的检测与测量手段已经很难满足测量效率要求,业内迫切需要一种新型高效率的测量设备。 产线多种多样…...
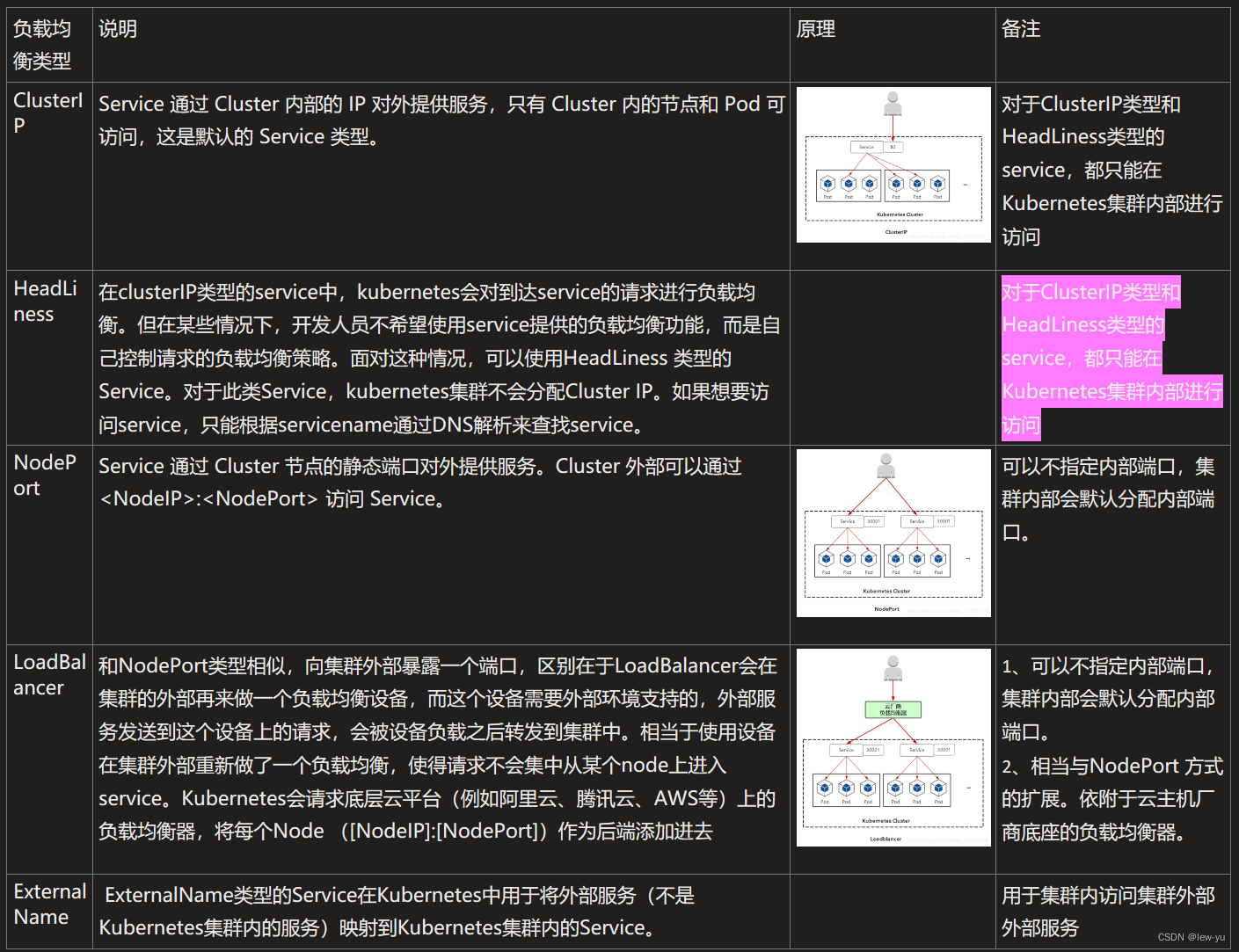
k8s之service五种负载均衡byte的区别
1,什么是Service? 1.1 Service的概念 在k8s中,service 是一个固定接入层,客户端可以通过访问 service 的 ip 和端口访问到 service 关联的后端pod,这个 service 工作依赖于在 kubernetes 集群之上部署的一个附件&a…...
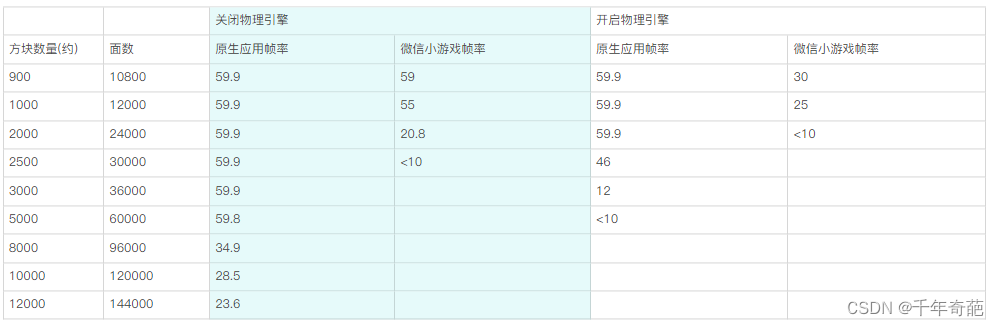
Unity项目转微信小游戏保姆教程,繁杂问题解决,及微信小游戏平台简单性能测试
前言 借着某人需求,做了一波简单的技术调研:将Unity项目转换为微信小游戏。 本文主要内容:Unity转换小游戏的步骤,遇到问题的解决方法,以及简单的性能测试对比 微信小游戏的限制 微信小游戏对程序包体大小有严格限制…...
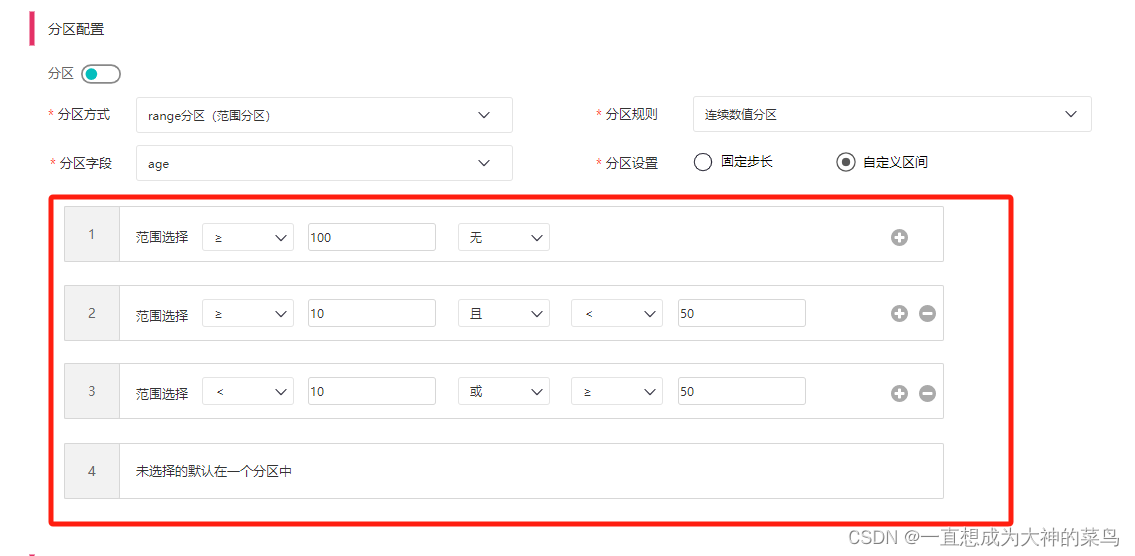
json字符串转为开闭区间
1.需求背景 1.1 前端页面展示 1.2 前后端约定交互json 按照页面每一行的从左到右 * 示例 [{"leftSymbol":">","leftNum":100,"relation":"无","rightSymbol":null,"rightNum":0}, {"left…...
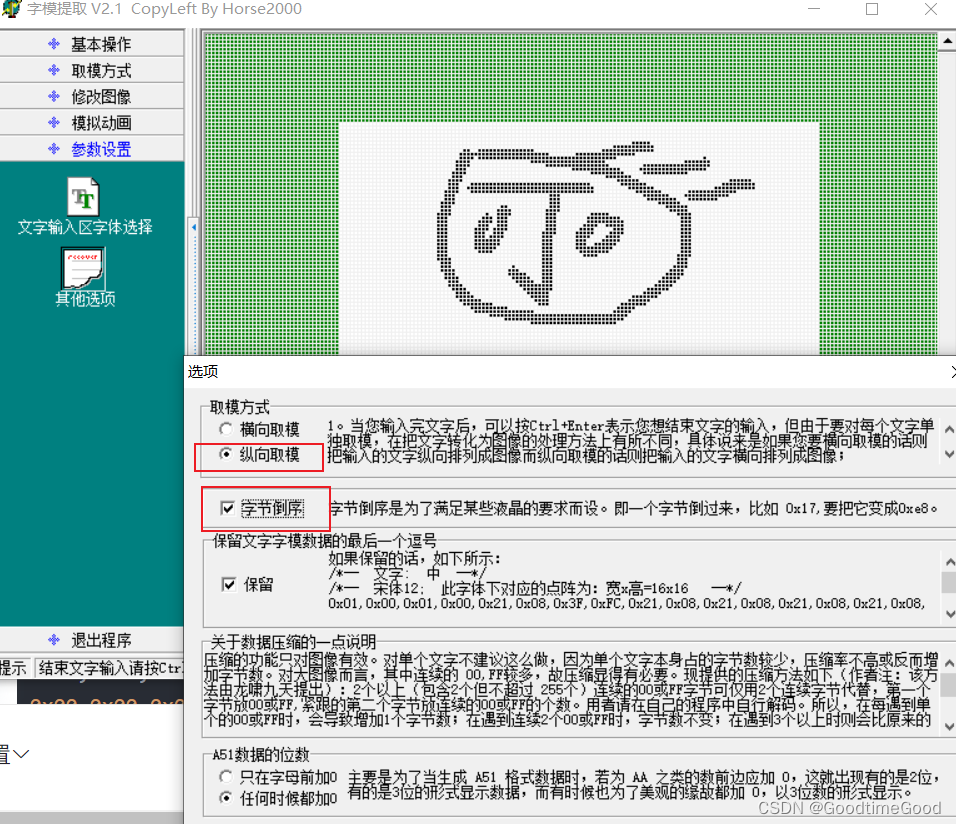
STM32 IIC 实验
1. 可以选择I2C1,也可以选择I2C2,或者同时选择,同时运行 配置时钟信号 为节约空间,选择这两个,然后选择GENERATE CODE 二、HAL_I2C_Mem_Write I2C_HandleTypeDef *hi2c:I2C设备句柄 uint16_t DevAddress&am…...
第六章 包图组织模型|系统建模语言SysML实用指南学习
仅供个人学习记录 概述 包是容器的一个例子。包中的模型元素称为可封装元素,这些元素可以是包、用例和活动。由于包本身也是可封装元素,因此可以支持包层级。 每个有名称的模型元素也必须是命名空间的一份子,命名空间使得每个元素均能够通过…...

使用 Rust 进行程序
首先,我们需要安装必要的库。在终端中运行以下命令来安装 scraper 和 reqwest 库: rust cargo install scraper reqwest 然后,我们可以开始编写程序。以下是一个基本的爬虫程序,用于爬取 上的图片: rust use reqwe…...

第10章 增长和扩展你的 Micro SaaS 应用程序
接下来,我们进入真正增长 Micro SaaS 应用用户群和订阅收入的激动人心的话题。 即使在增长阶段,你也不能忽视客户满意度,确保你与时俱进,在路线图上添加你承诺的功能,然后通过 SaaS 营销吸引更多用户。 也就是说,让我们来看看增长您的 Micro SaaS 应用程序的关键战略要…...
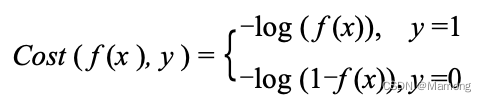
第八章《搞懂算法:逻辑回归是怎么回事》笔记
8.1 如何理解逻辑回归 逻辑回归根据给定的自变量数据集来估计事件的发生概率,由于结果是一个概率,因此因变量的范围在 0 和 1 之间。 逻辑回归的与线性回归一样,也是以线性函数为基础的;而与线性回归不同的是,逻辑回…...

【WinForm详细教程八】WinForm中的TreeView控件
文章目录 TreeView 基本的知识属性方法事件 TreeView 案例演示案例一:案例二: TreeView 控件 用于展示分层数据,它以树形结构展示信息,每个节点可以有一个或多个子节点。TreeView 控件允许用户以可展开和可折叠的形式查看复杂的层…...

突破数据采集困境:Easy-Scraper 重构网页信息提取范式
突破数据采集困境:Easy-Scraper 重构网页信息提取范式 【免费下载链接】easy-scraper Easy scraping library 项目地址: https://gitcode.com/gh_mirrors/ea/easy-scraper 在数据驱动决策的时代,网页数据采集如同挖掘数字金矿。但传统工具往往陷入…...

Vue 3 Teleport:打破 DOM 层级的“传送门”
Vue 3 Teleport:打破 DOM 层级的“传送门” 在现代前端开发中,组件化是构建复杂用户界面的基石。我们习惯于将 UI 拆分成一颗颗独立的组件,像搭积木一样组合成完整的页面。然而,这种嵌套结构在带来逻辑内聚性的同时,也…...

一文读懂:智能体身份权限治理演进实录
序章当一个实验性的“咖啡外卖”智能体(BrewSense),从服务几位工程师的小工具,演变为数千人依赖的自动化伙伴时,会发生什么?这不仅仅是用户量和调用量的激增,更是一场关于身份、权限与信任的治理…...

如何通过自动化工具高效获取阴阳师游戏资源?完整实践指南
如何通过自动化工具高效获取阴阳师游戏资源?完整实践指南 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化工具是一款功能强大的智能辅助应用,…...

FireRedASR-AED-L在软件测试中的应用:语音交互功能自动化测试
FireRedASR-AED-L在软件测试中的应用:语音交互功能自动化测试 你有没有想过,那些能听懂你说话的手机应用、智能音箱或者车载系统,它们的“听力”到底准不准?开发团队是怎么确保你每次说“播放音乐”或者“导航回家”,…...

UNIX文件系统设计:一切皆文件的原理与实践
UNIX 文件系统设计哲学:一切皆文件的深度解析1. 核心设计理念1.1 统一I/O抽象模型UNIX系统最核心的设计原则是提供访问各类输入/输出资源的统一范式。系统将所有I/O资源抽象为"文件"对象,通过同一套API接口暴露给用户空间。这种设计使得开发者…...
)
CentOS 7下OnlyOffice离线部署全攻略:从依赖包下载到一键配置(避坑指南)
CentOS 7下OnlyOffice离线部署全攻略:从依赖包下载到一键配置(避坑指南) 在企业内网或安全隔离环境中部署文档协作平台时,OnlyOffice凭借其开源特性和丰富的编辑功能成为首选方案。本文将深入探讨如何在CentOS 7系统中实现完全离线…...

软件外包公司的“末路”:印度同行都慌了?——软件测试从业者的专业视角
在当今数字化浪潮中,软件外包行业曾是全球经济的重要引擎,尤其以印度为代表的外包巨头,凭借低成本人力优势主导了全球市场。然而,随着人工智能(AI)技术的迅猛发展,这一模式正面临前所未有的挑战…...
)
当NB-IoT遇上同步轨道卫星:GEO场景下的定时关系增强全指南(基于3GPP Release 17最新规范)
GEO卫星场景下NB-IoT定时关系增强技术解析 1. GEO卫星通信与NB-IoT的技术融合挑战 地球静止轨道(GEO)卫星通信与窄带物联网(NB-IoT)技术的结合,为全球物联网覆盖提供了革命性解决方案。GEO卫星位于地球赤道上空35,786公…...

A-59F 多功能语音处理模组:覆盖全场景人群,让每一次语音都清晰无噪
在门禁对讲、会议扩音、车载通话、导游喊话、监护设备、智能工牌等各类语音设备中,啸叫刺耳、环境嘈杂、回音不断、拾音模糊、通话断续是所有人共同的痛点。一款真正解决问题的核心硬件 ——A-59F 多功能语音处理模组,它集成扩音防啸叫、AI ENC 降噪、AE…...