mysql的备份和恢复
备份:完全备份 增量备份
完全备份:将整个数据库完整的进行备份
增量备份:在完全备份的基础之上,对后续新增的内容进行备份
备份的需求
1、在生产环境中,数据的安全至关重要,任何数据的都可能产生非常严重的后果
2、数据为什么会丢失,程序操作,运算错我,磁盘故障,不可预期的时间(地震之类),人为操作
冷备份:关机备份,停止mysql服务,然后进行备份
热备份:开机备份,无须关闭mysql服务,进行备份
物理备份:对数据库系统的物理文件(数据文件,日志文件),进行备份
逻辑备份,只是对数据库的逻辑组件进行备份,(表结构),以sql语句的形式,把库,表结构,表数据进行备份保存
(直接在数据库系统中删除全部文件)
物理备份:完全备份,对整个数据库进行完整的打包备份
优点:操作简单
缺点:数据库文件占用量是很大,占用空间太大,备份和恢复的时间很长,且需要暂定数据库服务
打包备份最好是把服务关掉,避免有新的数据进入,被覆盖,也可能会导致恢复失败
冷备份实验
终端
关闭mysql服务
systemctl stop mysqld.service
安装xz服务
yum -y install xz
进入mysql目录下
cd /usr/local/mysql/
打包
tar Jcvf /opt/mysql_all_$(date+%F).tar.xz data
解压刚刚压缩的文件
cd /opt/
tar Jxvf mysql_all_.tar.xz
删除源文件

恢复数据
把解压过的文件复制到mysql的目录下

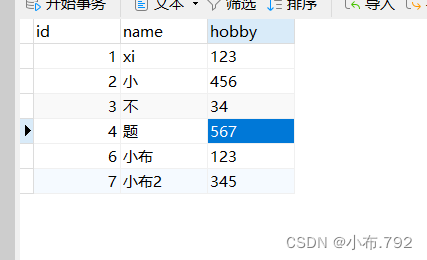
表数据没有发生变化,保持原有的数据
远程复制
把终端2 的mysql的data文件删除
 通过远程复制,复制终端1的mysql的data文件到终端2
通过远程复制,复制终端1的mysql的data文件到终端2

在复制mysql目录下
注意点:在复制到mysql目录下查看data文件的文件所属ll
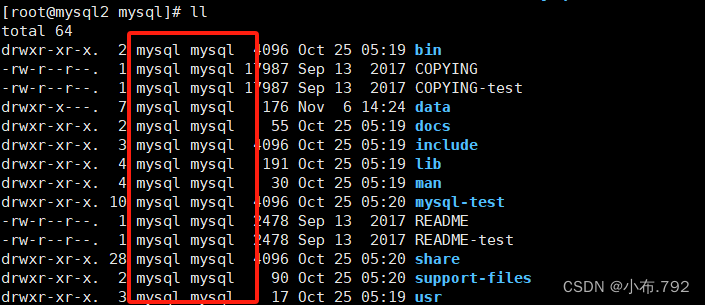
热备份当中的逻辑备份
mysqldump 这是mysql自带的工具
mysqldump
备份单个库
mysqldump -u root -p123456 --databases 库名 > /opt/文件名.sql
备份多个库
mysqldump -u root -p123456 --databases 库名1 库名2 > /opt/文件名.sql
备份所有库
mysqldump -u root -p123456 --all-databases > /opt/文件名.sql
指定连接mysql之后执行完命令,自动退出
mysql -u root -p123456 -e 'show databases;'
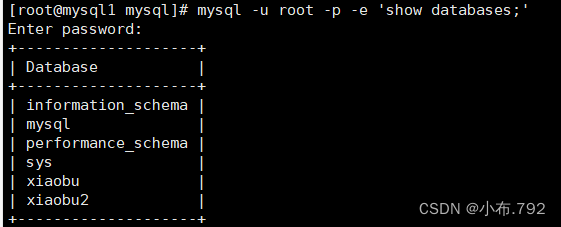
实例
备份单个库

删除这个库
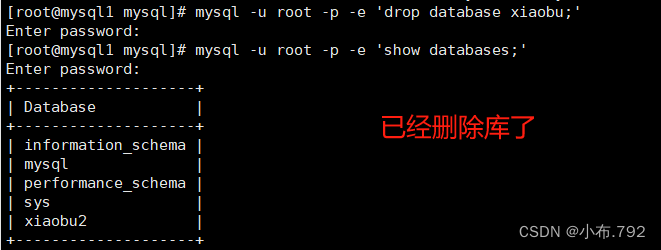
还原
命令行备份和恢复
创建库
create database xiaobu;
创建表
create table info (id int(4) not null primary key,name char(5) default null,hobby varchar(10) default null
);
对多个库备份
备份
mysqldump -u root -p --databases 库名1 库名2 > /opt文件名.sql
删除
mysql -u root -p -e 'drop database 库名1;'
mysql -u root -p -e 'drop database 库名2;'
恢复多个
mysql -u root -p < /opt/库名.sql备份所有
mysqldump -uroot -p --all-databases > /opt/ 文件名.sql
删除
mysql -u root -p -e 'drop database 库名1;'
mysql -u root -p -e 'drop database 库名2;'
恢复多个
mysql -u root -p < /opt/库名.sql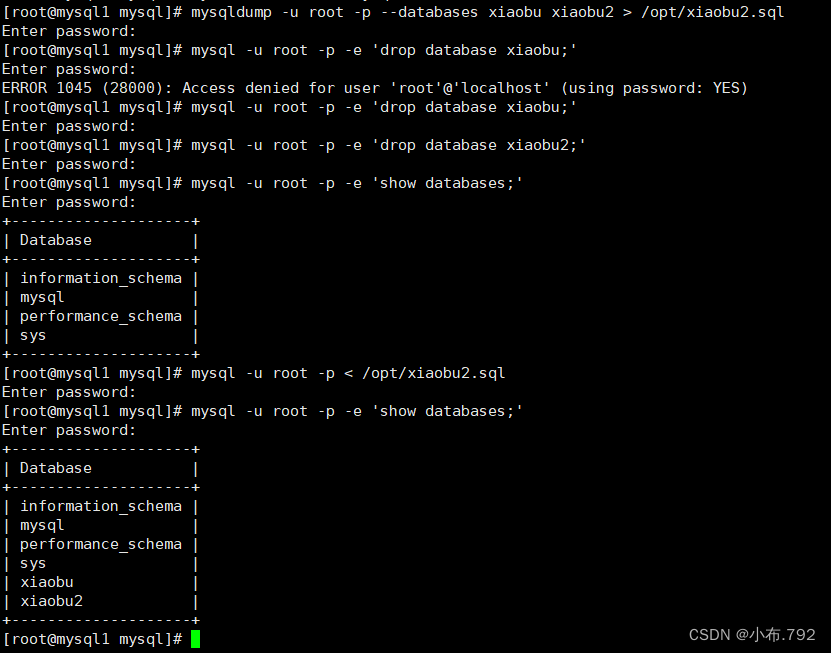
如何恢复指定库,指定表
单个表备份
mysqldump -u root -p 库名 表名 > /opt/文件名.sql
不进入数据库删除
mysql -u root -p -e 'drop table 库名.表名'
恢复
mysql -u root -p 库名 < /opt/文件名.sql多个表
mysqldump -u root -p 库名 表名1 表名2 > /opt/文件名.sql
删除
mysql -u root -p -e 'drop table 库名.表名1'
mysql -u root -p -e 'drop table 库名.表名2'
恢复
mysql -u root -p 库名 < /opt/文件名.sql
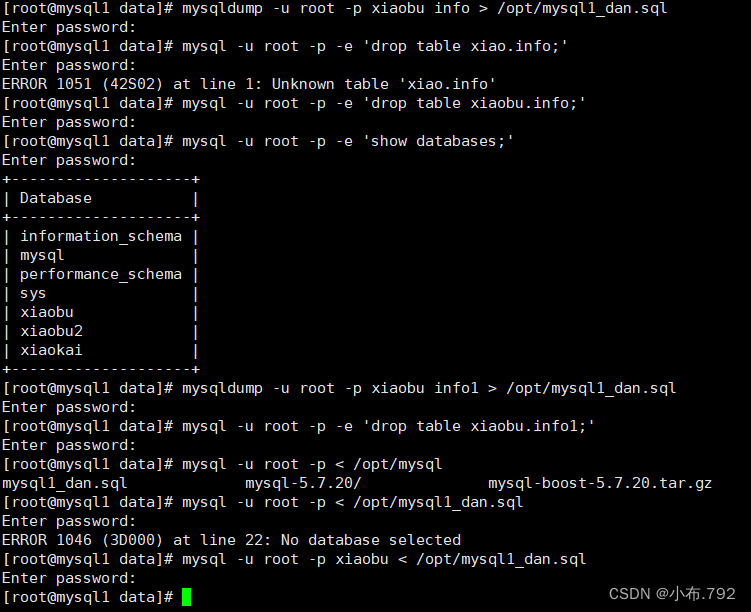
物理冷备份和物理热备份
特点:简单
数据量,占用的备份空间比较大
mysqldump 这是mysql自带的备份文件的命令
特点:方便,简单,但是只能给予逻辑上的表结构和表数据恢复,物理删除之后再用逻辑恢复会报错
它也可以作为数据迁移,占用大空间,比较物理备份相对来说占的空间要小的多
增量备份
mysqldump 支持增量备份
没有重复数据,备份量小,时间端
mysqldump增量备份恢复表数据期间,表会锁定(优点)
缺点:备份时锁表,必然会影响业务,超过10G,耗时会比较长,导致服务不可用
增量备份的过程
1、mysql提供的二进制日志文件的实现增量备份
二进制文件怎么来?
修改配置文件(vim /etc/my.conf)
log-bin=mysql-bin binlog_format=MIXED
mysql二进制记录格式有三种
1、STATENET:基于sql语句
纪录修改的sql语句,高并发情况下,纪录sql语句时候的顺序可能会出错,恢复数据时可能会导致丢失和误差,效率比较高
2、ROW:基于行
精确纪录每一行的数据,准确率高,但是恢复的时效率低
3、MIXED :既可以根据SQL语句,也可以根据行
在正常情况下使用STATEENT,一旦发生高并发,会智能自动切换到row行
重启服务

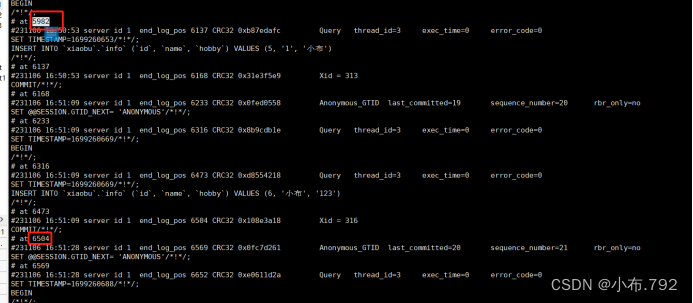
查看备份的二进制文件(必须在data目录下查看)
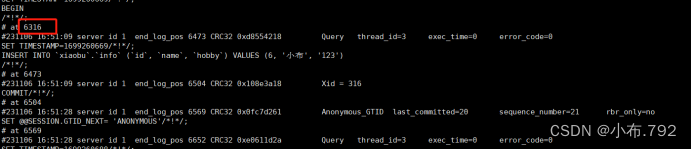
mysqlbinlog --no-defaults --base64-output=decode-rows -v mysql-bin.000001
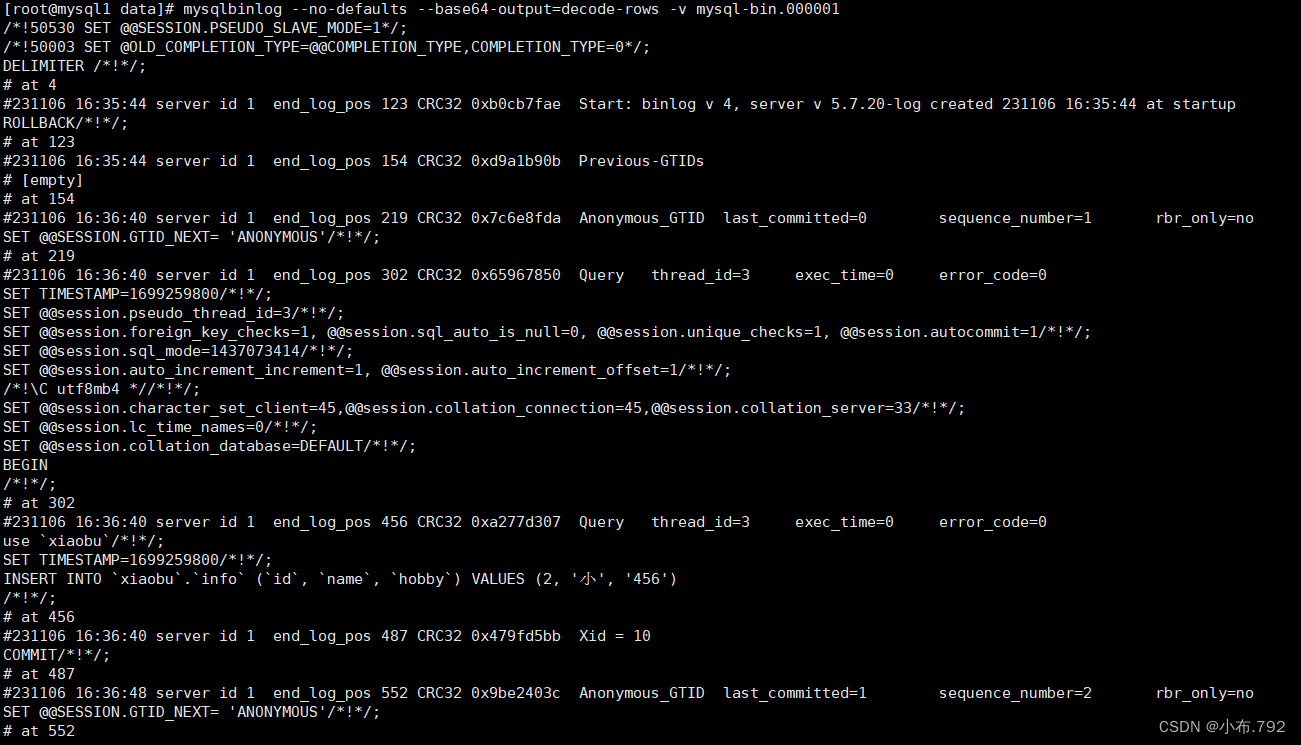
mysqladmin -u root -p flush-logs 刷新日志文件(打印断点)
就会生成一个日志文件00002

删除表里的内容(删除之前要断点)
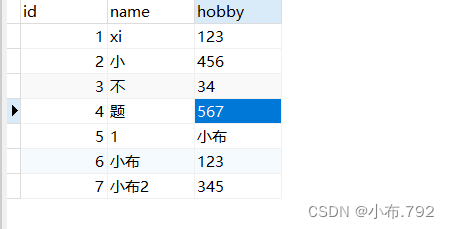
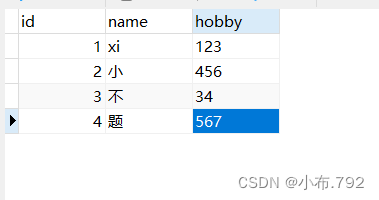
如何恢复
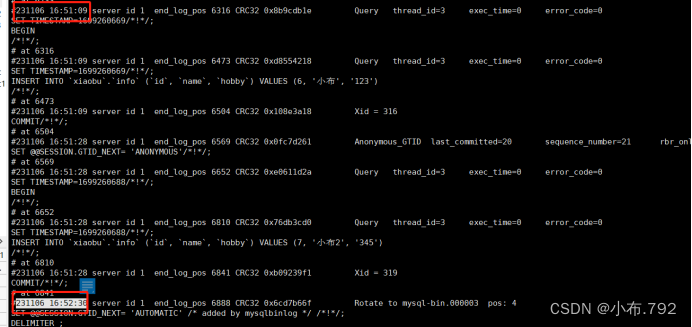
mysqlbinsql --no-defaults mysql-bin.000003 | mysql -u root -p
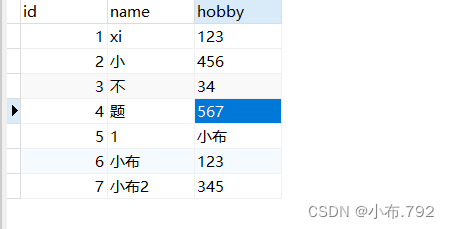
- 增量备份,位置节点和时间点,注意一下断点
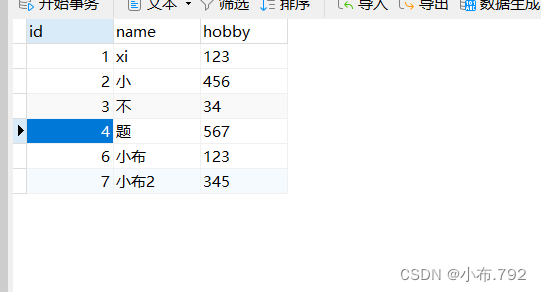
基于位置节点
从某一个点开始,恢复到最后
mysqlbinlog --no-defaults --start-position='位置点' 文件名 | mysql -u root -p
从开头,一直恢复到某个位置
mysqlbinlog --no-defaults --stop-position='位置点' 文件名 | mysql -u root -p
从指定点---指定结束点
mysqlbinlog --no-defaults --start-position='位置点' --stop-position='位置点' 文件名 | mysql -u root -p
从某一个点开始,恢复到最后
![]()
从开头,一直恢复到某个位置
![]()

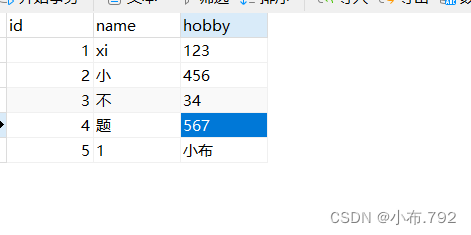
从指定点---指定结束点
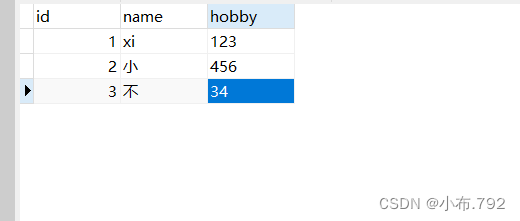


基于时间点
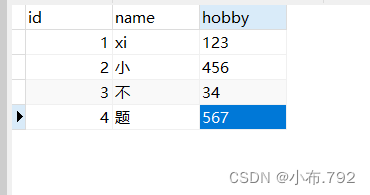
1、从某个时间点开始 恢复到最后
mysqlbinlog --no-defaults --start-datetime='时间点' 文件 | mysql -u root -p
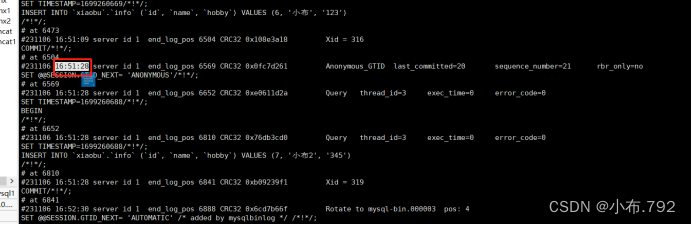
2、从开头,到指定的结尾时间点
mysqlbinlog --no-defaults --stop-datetime='时间点' 文件 | mysql -u root -p
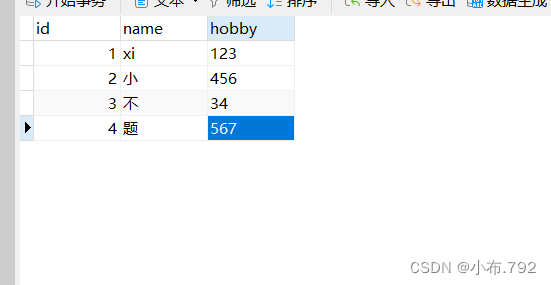
3、指定时间范围
mysqlbinlog --no-defaults --start-datetime='时间点' --stop-datetime='时间点' 文件 | mysql -u root -p
从某个时间点开始 恢复到最后
![]()

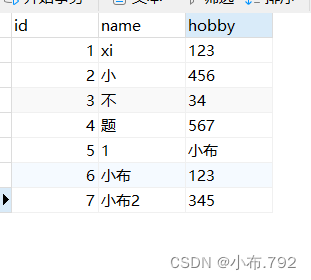
从开头,到指定的结尾时间点
![]()
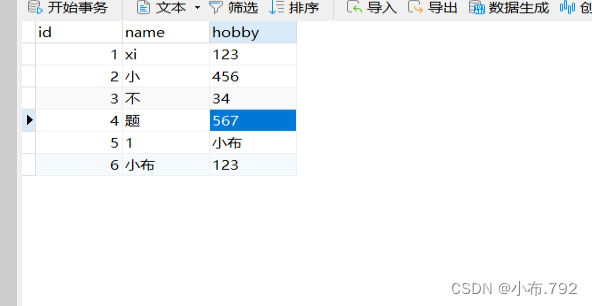
指定时间范围
![]()
总结
在生产中,通过binlog进行增量恢复是非常好用的方法
我们只要需要对binlog文件进行备份,随时可以进行备份和恢复
附加题
写个脚本,每个月的20号,对数据库打一个断点
断点之后进行自动进行增量备份
如何纪录日志文件的错误日志
log-error=/usr/local/mysql/data/mysql_error.log
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5
相关文章:
mysql的备份和恢复
备份:完全备份 增量备份 完全备份:将整个数据库完整的进行备份 增量备份:在完全备份的基础之上,对后续新增的内容进行备份 备份的需求 1、在生产环境中,数据的安全至关重要,任何数据的都可能产生非常严重…...

【机器学习3】有监督学习经典分类算法
1 支持向量机 在现实世界的机器学习领域, SVM涵盖了各个方面的知识, 也是面试题目中常见的基础模型。 SVM的分类结果仅依赖于支持向量,对于任意线性可分的两组点,它 们在SVM分类的超平面上的投影都是线性不可分的。 2逻辑回归 …...
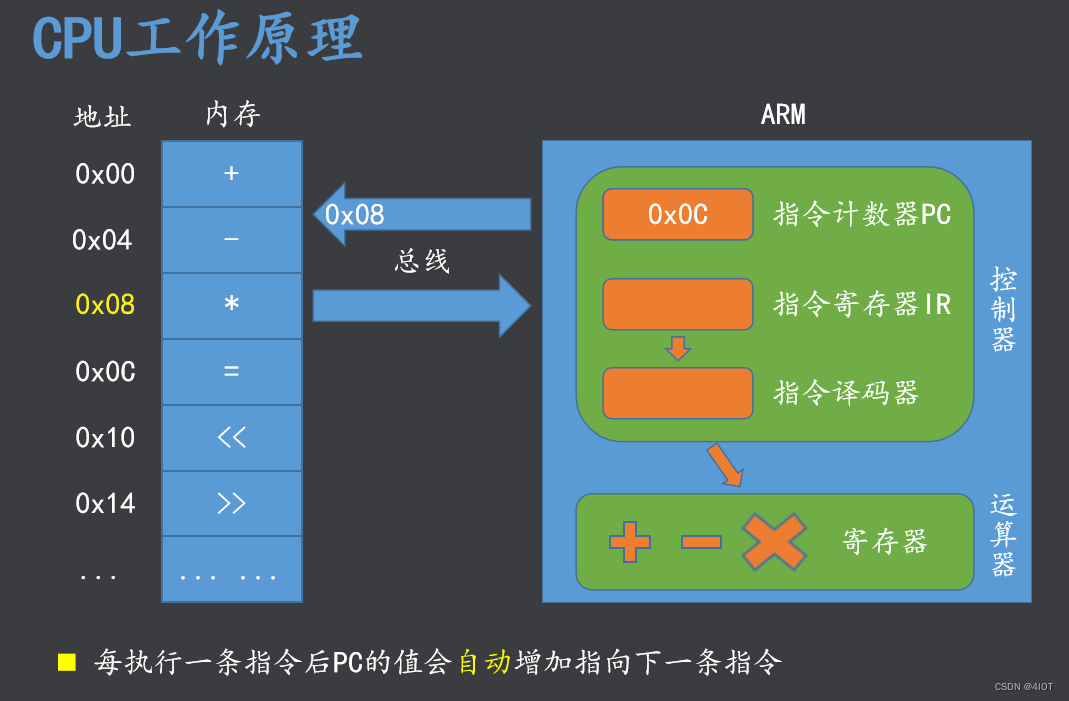
lv11 嵌入式开发 计算机硬件基础 1
目录 1 导学 1.1回顾及导学 1.2 嵌入式系统分层 1.3 linux底层开发 2 ARM体系结构与接口技术课程导学 3 计算机基础 3.1 计算机的进制 3.2 计算机组成 3.3 总线 4 多级存储结构与地址空间 4.1 多级存储概念 4.2 地址空间 5 CPU工作原理 6 练习 1 导学 1.1回顾及导…...
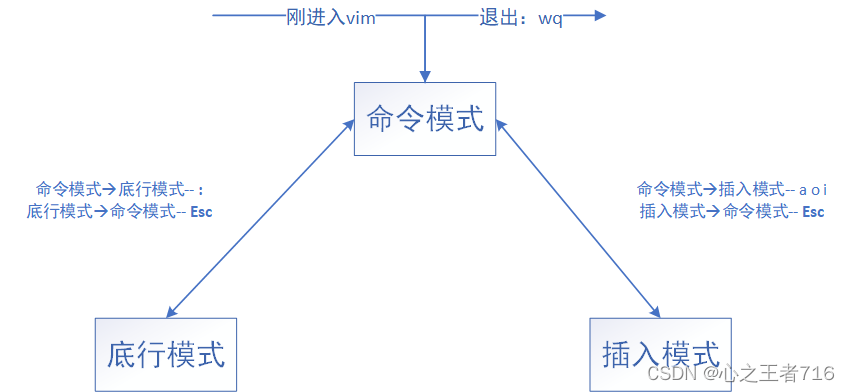
【Linux】vim
文章目录 一、vim是什么?二 、命令模式三、插入模式四、底行模式五、vim配置 一、vim是什么? Vim是一个强大的文本编辑器,它是Vi的增强版,支持多种语法高亮、插件扩展、多模式操作等功能。Vim有三种基本的工作模式:命…...

cstring函数
string 1.char str[]类型 fgets(s,10000,stdin) cin.getline(cin,10000) strlen(str) sizeof 求静态数组长度 2.string类型 getline(cin,a) cin.getline(cin,10000) str.lenth() str.size() cin 遇到空格就停止 3.gets 函数 char str[20]; gets(str); 4.puts 函…...
【owt】p2p client mfc 工程梳理
1年前构建的,已经搞不清楚了。所以梳理下,争取能用较新的webrtc版本做测试。最早肯定用这个测试跑通过 【owt】p2p Signaling Server 运行、与OWT-P2P-MFC 交互过程及信令分析官方的mfc客户端 估计是构造了多个不同的webrc版本的客户端...

pandas教程:Hierarchical Indexing 分层索引、排序和统计
文章目录 Chapter 8 Data Wrangling: Join, Combine, and Reshape(数据加工:加入, 结合, 变型)8.1 Hierarchical Indexing(分层索引)1 Reordering and Sorting Levels(重排序和层级排序)2 Summa…...
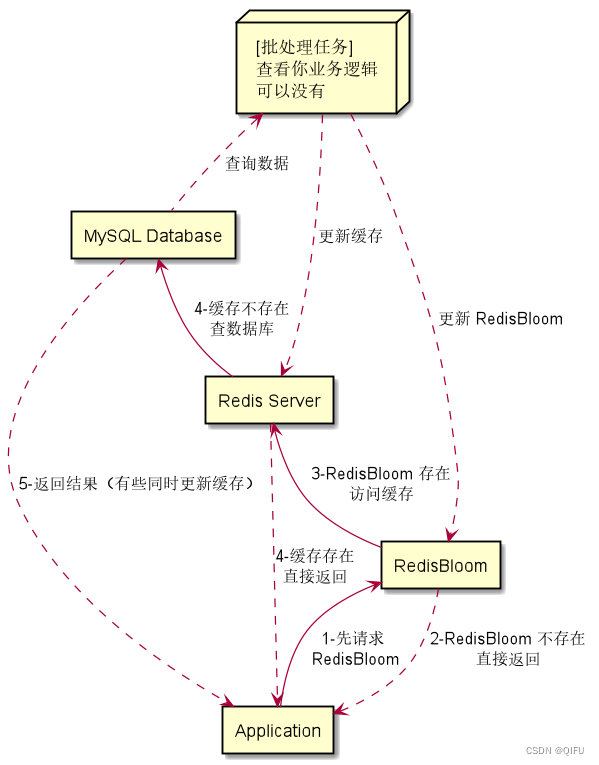
Redis 扩展 RedisBloom 插件,解决缓存击穿、穿透
文章目录 一、概述二、编译准备2.1 升级 make2.2 安装 Python3 三、编译 RedisBloom四、测试 RedisBloom五、应用场景5.1 缓存击穿5.2 缓存穿透5.3 原理总结 六、存在的问题 如果您对Redis的了解不够深入请关注本栏目,本栏目包括Redis安装,Redis配置文件…...

VBA技术资料MF80:选择文件及文件夹
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。我的教程一共九套,分为初级、中级、高级三大部分。是对VBA的系统讲解,从简单的入门,到…...
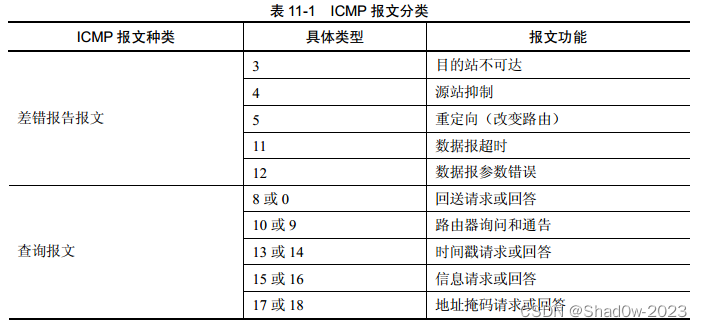
网络层:控制平面
路由选择算法 路由选择算法就是为了在端到端的数据传输中,选择路径上路由器的最好的路径。通常,一条好的路径指具有最低开销的路径。最低开销路径是指源和目的地之间具有最低开销的一条路。 根据集中式还是分散式来划分 集中式路由选择算法:…...
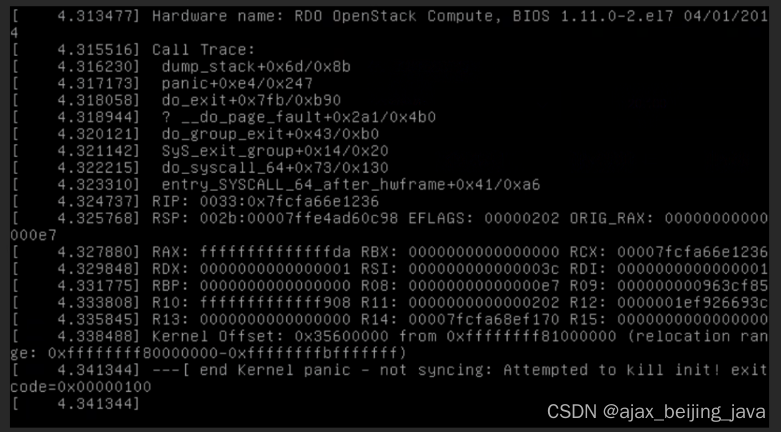
Ubuntu 系统内核 kernel panic
Ubuntu 系统内核 kernel panic 不能进入系统:报错end kernel panic -not syncing: attemped to kill init! exit code 0x00000100 系统启动的时候,按下‘e’键进入grub编辑界面,编辑grub菜单,选择“kernel /vmlinuz-XXXXro root…...

【flink】RowData copy/clone方式
说明:一般用户常用的是GenericRowData。flink内部则多使用BinaryRowData。 方法一、循环解决(不推荐): 代码较为复杂需要根据RowType获取到内部fields的logicalType,再使用RowData.createFieldGetter方法创建fieldGetters。 public static …...
网页图标工具
工具地址...

掌动智能:功能测试及拨测主要功能
在企业中对于功能测试及拨测而言,用户只需提供应用包和产品文档,由资深测试专家设计并执行测试,覆盖核心场景,包含特定业务流程以及行业通用特殊场景,支持需求定制。 执行过程严格监控,依据应用功能和业务需…...
)
第11章 Java集合(二)
目录 内容说明 章节内容 一、Set接口 二、HashSet集合 三、LinkedHashSet集合 四、TreeSet集合...
Transformer和ELMo模型、word2vec、独热编码(one-hot编码)之间的关系
下面简要概述了Transformer和ELMo模型、word2vec、独热编码(one-hot编码)之间的关系: 独热编码(One-hot Encoding)是一种最基本的词表示方法,将词表示为高维稀疏向量。它与ELMo、word2vec和Transformer的关…...

您与1秒钟测量两千个尺寸之间仅差一台智能测径仪!
随着产线的发展,自动化程度越来越高,生产速度越来越快,人们对产品的品质要求越来越高,对检测也提出了更高的要求。传统的检测与测量手段已经很难满足测量效率要求,业内迫切需要一种新型高效率的测量设备。 产线多种多样…...
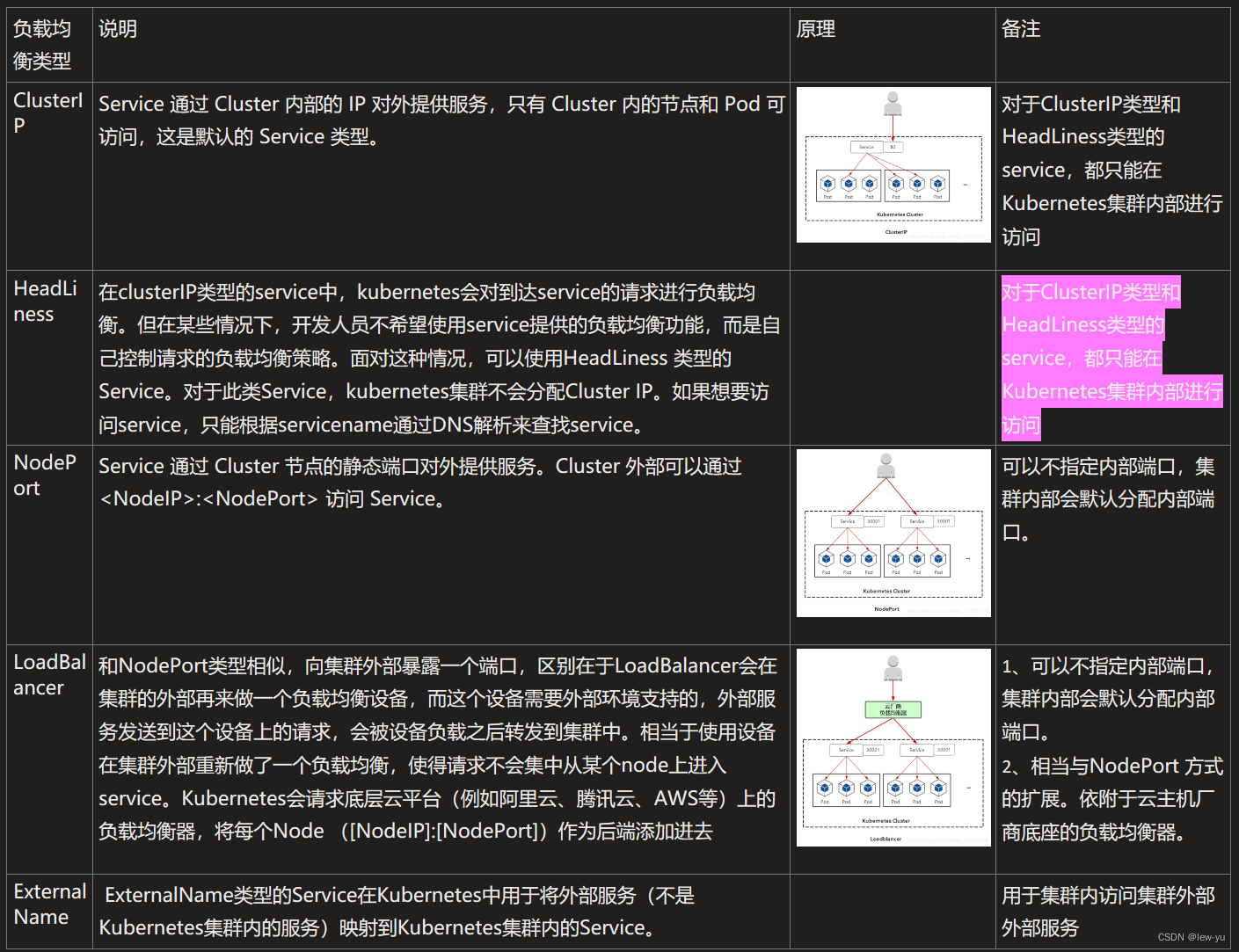
k8s之service五种负载均衡byte的区别
1,什么是Service? 1.1 Service的概念 在k8s中,service 是一个固定接入层,客户端可以通过访问 service 的 ip 和端口访问到 service 关联的后端pod,这个 service 工作依赖于在 kubernetes 集群之上部署的一个附件&a…...
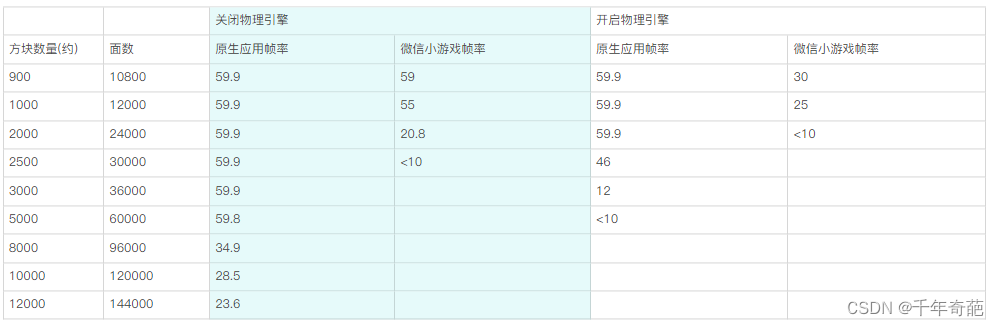
Unity项目转微信小游戏保姆教程,繁杂问题解决,及微信小游戏平台简单性能测试
前言 借着某人需求,做了一波简单的技术调研:将Unity项目转换为微信小游戏。 本文主要内容:Unity转换小游戏的步骤,遇到问题的解决方法,以及简单的性能测试对比 微信小游戏的限制 微信小游戏对程序包体大小有严格限制…...
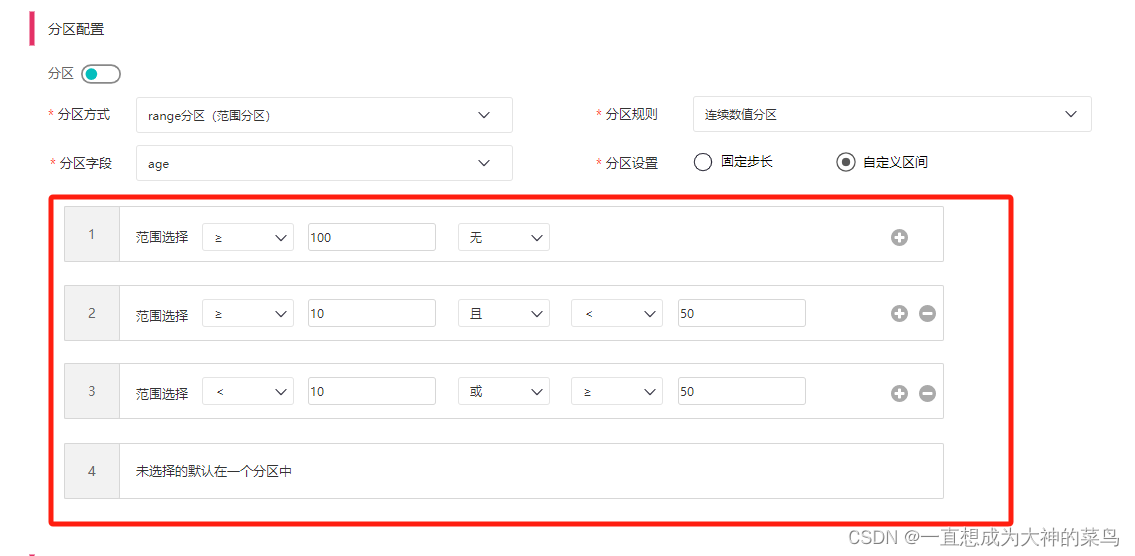
json字符串转为开闭区间
1.需求背景 1.1 前端页面展示 1.2 前后端约定交互json 按照页面每一行的从左到右 * 示例 [{"leftSymbol":">","leftNum":100,"relation":"无","rightSymbol":null,"rightNum":0}, {"left…...
Pixel Epic应用场景:律所用其快速生成法律合规风险分析报告(含引用标注)
Pixel Epic应用场景:律所用其快速生成法律合规风险分析报告(含引用标注) 1. 法律合规报告生成的新范式 在法律服务领域,合规风险分析报告是律所日常工作中的重要产出。传统方式下,律师需要花费大量时间查阅法规条文、…...

Windows下OpenClaw全攻略:Qwen3.5-9B-AWQ-4bit接入与避坑指南
Windows下OpenClaw全攻略:Qwen3.5-9B-AWQ-4bit接入与避坑指南 1. 为什么选择OpenClawQwen3.5组合? 去年我在处理大量图片素材归档时,发现手动分类效率极低。直到尝试将OpenClaw与Qwen3.5-9B-AWQ-4bit镜像结合,才真正体会到本地A…...

PCIe C++代理实例化
为了能调用PCIe AVIP的C用户接口,先要在C仿真文件中对PCIe C代理做一个实例化声明。PCIe C代理负责两件事:从C仿真程序获得事务报文,并将其通过信号接口发送给BFM。从信号接口接收事务响应报文,并将其发送给C仿真程序。注意&#…...

深度解析Godot资源提取:构建专业级解包方案
深度解析Godot资源提取:构建专业级解包方案 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 在游戏开发与逆向工程领域,Godot资源提取技术已成为开发者探索游戏内部结构的核心…...

小白也能轻松上手!通义千问2.5-7B+Ollama快速入门
小白也能轻松上手!通义千问2.5-7BOllama快速入门 1. 为什么选择通义千问2.5-7B? 通义千问2.5-7B-Instruct是阿里云2024年9月发布的中等规模开源大模型,拥有70亿参数,专为指令跟随任务优化。这个模型特别适合想在本地运行AI但又不…...

2025届最火的十大降重复率助手解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 知网在近期对AIGC检测功能进行了升级,能够精准地识别出通过人工智能生成的文本内…...
)
告别MoveIt!用Pinocchio、OMPL和Ruckig手搓一个轻量级机械臂规划模块(附完整C++代码)
轻量级机械臂规划模块:Pinocchio、OMPL与Ruckig的黄金组合 在机器人开发领域,机械臂的运动规划一直是核心挑战之一。传统ROS生态中的MoveIt框架虽然功能全面,但其重型架构和高耦合性往往成为追求高性能和灵活性的开发者的桎梏。本文将带你探索…...

降AI后怎么做知网查重不超标:降AI和查重双通过的操作方法
降AI后怎么做知网查重不超标:降AI和查重双通过的操作方法 被问了太多次降AI后查重相关的问题,写一篇完整教程。 主要工具是嘎嘎降AI(www.aigcleaner.com),4.8元。第一次用的话有些细节知道和不知道差别挺大的。 操作…...

[x-cmd] 写给计算机科学爱好者的 x-cmd 入门指南
写给计算机科学爱好者的 x-cmd 入门指南 为什么要用 命令行 整合多样能力: 当你长期只需要做一件事时,其实只需熟悉这项业务的图形用户界面(例如一个网页控制台);但如果要处理多项业务时: 例如,在开发时,…...

QCS6490实战解码:从参数到场景的性能跃迁指南
1. QCS6490硬件性能的实战价值解码 第一次拿到QCS6490开发板时,我对着参数表发呆了半小时——12TOPS算力、5路ISP、Wi-Fi 6E这些参数看起来很厉害,但到底能解决哪些实际问题?经过三个月的项目实战,我发现这款芯片的真正价值在于将…...