【Linux基础IO篇】用户缓冲区、文件系统、以及软硬链接
【Linux基础IO篇】用户缓冲区、文件系统、以及软硬链接
目录
- 【Linux基础IO篇】用户缓冲区、文件系统、以及软硬链接
- 深入理解用户缓冲区
- 缓冲区刷新问题
- 缓冲区存在的意义
- File
- 模拟实现C语言中文件标准库
- 文件系统
- 认识磁盘
- 对目录的理解
- 软硬链接
- 软硬链接的删除
- 文件的三个时间
作者:爱写代码的刚子
时间:2023.11.5
前言:本篇博客将介绍缓冲区、磁盘的构成、分区,以及文件系统中的结构、软硬链接
深入理解用户缓冲区
观察几个现象:
正常现象一:
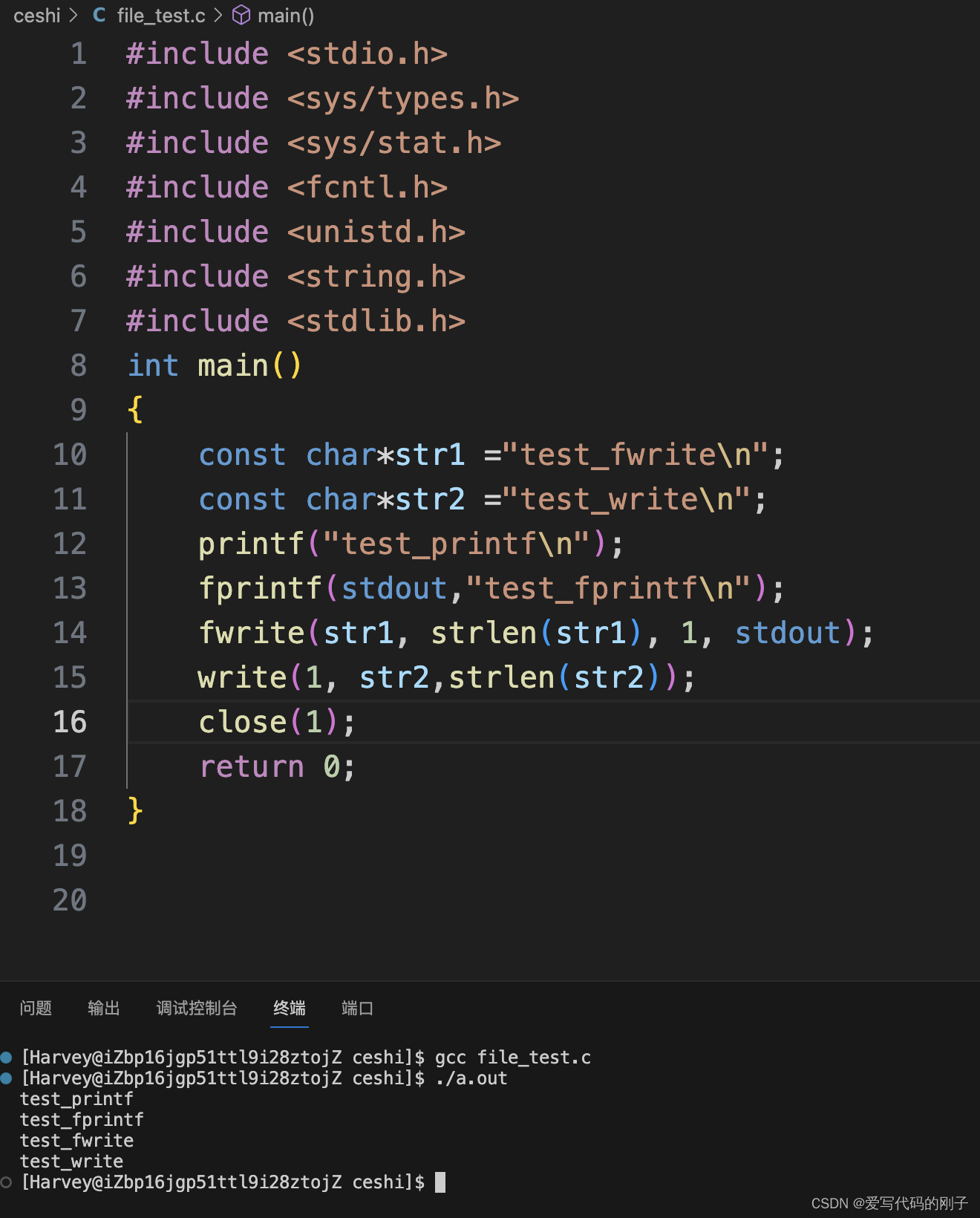
现象二:
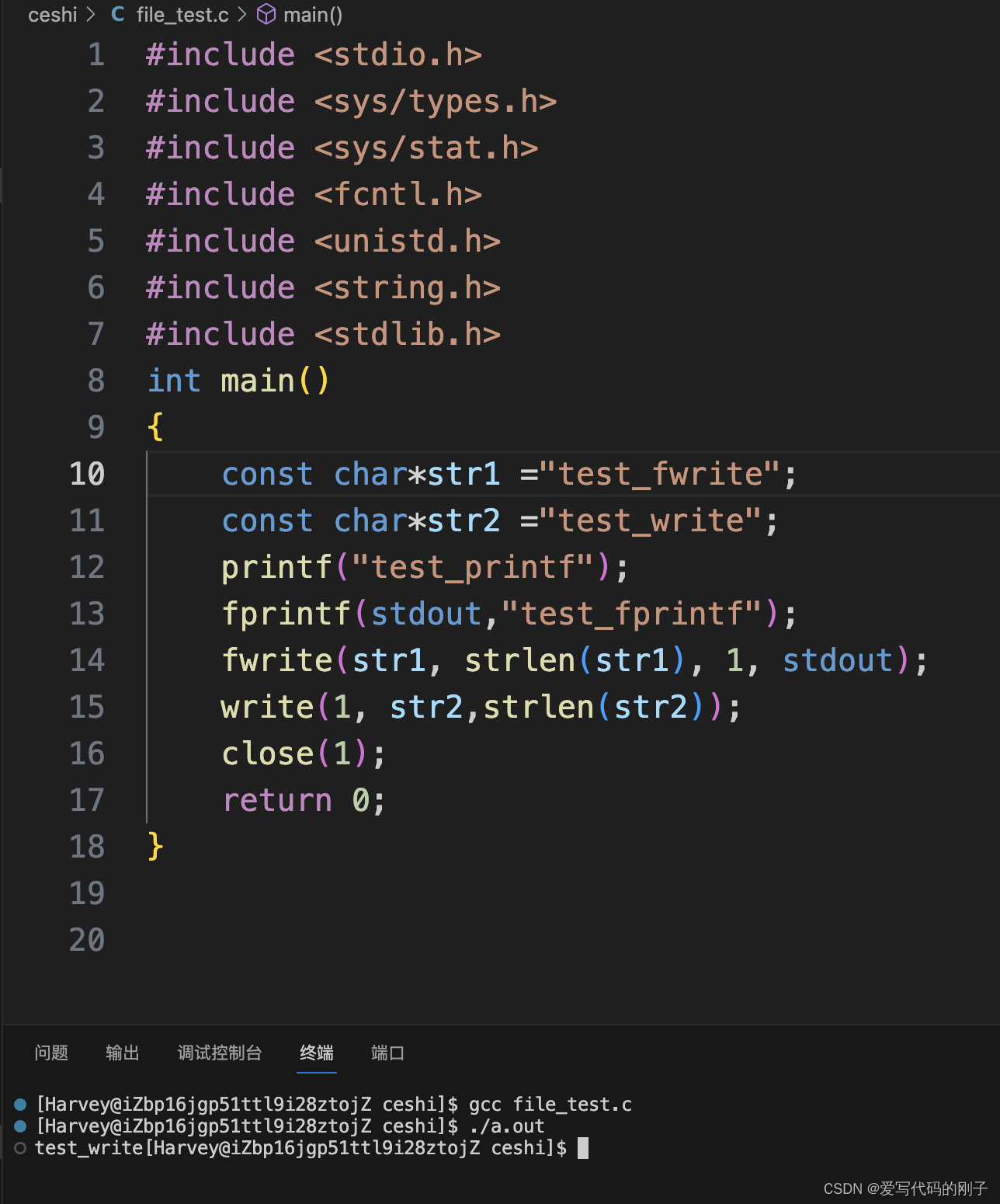
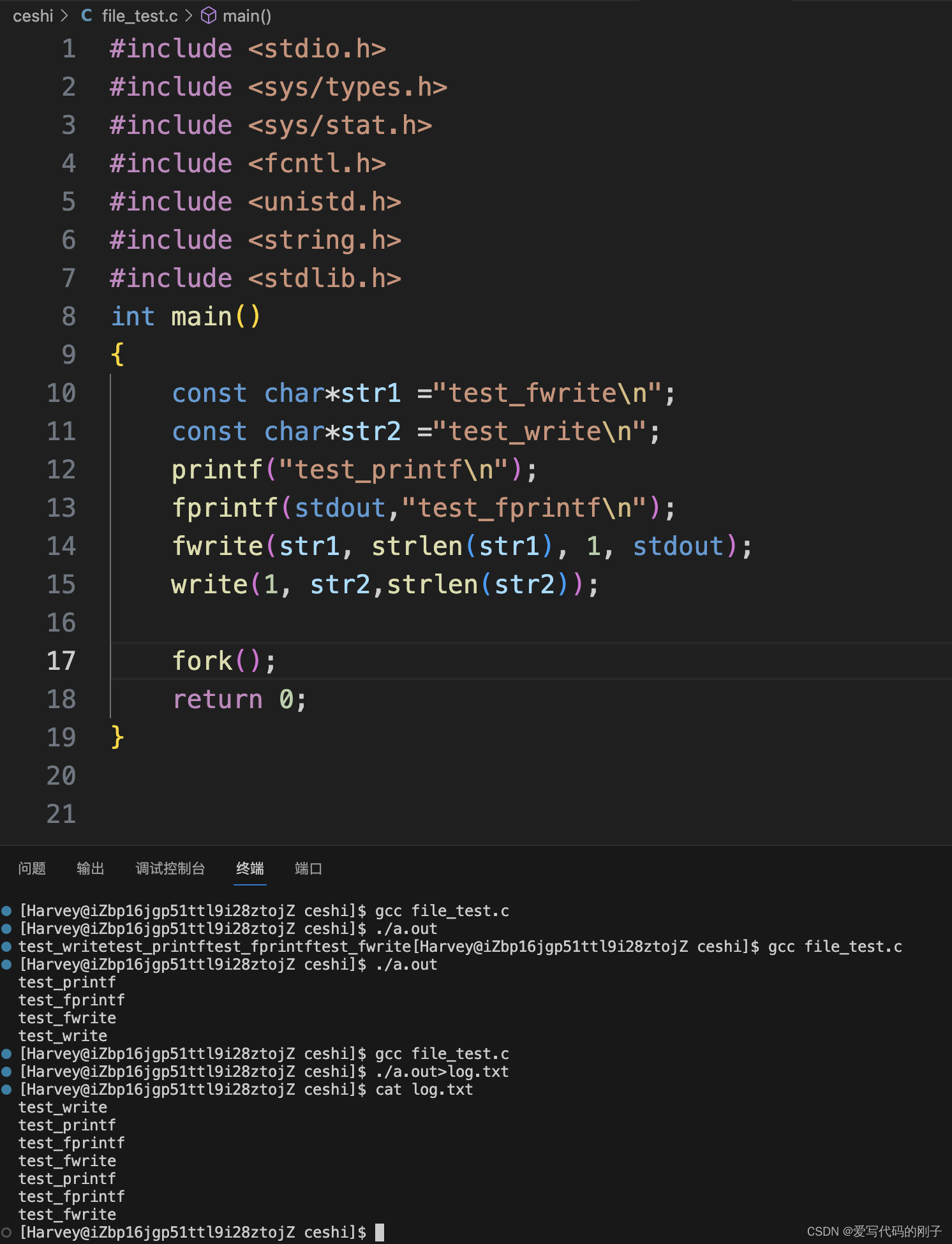
现象三:
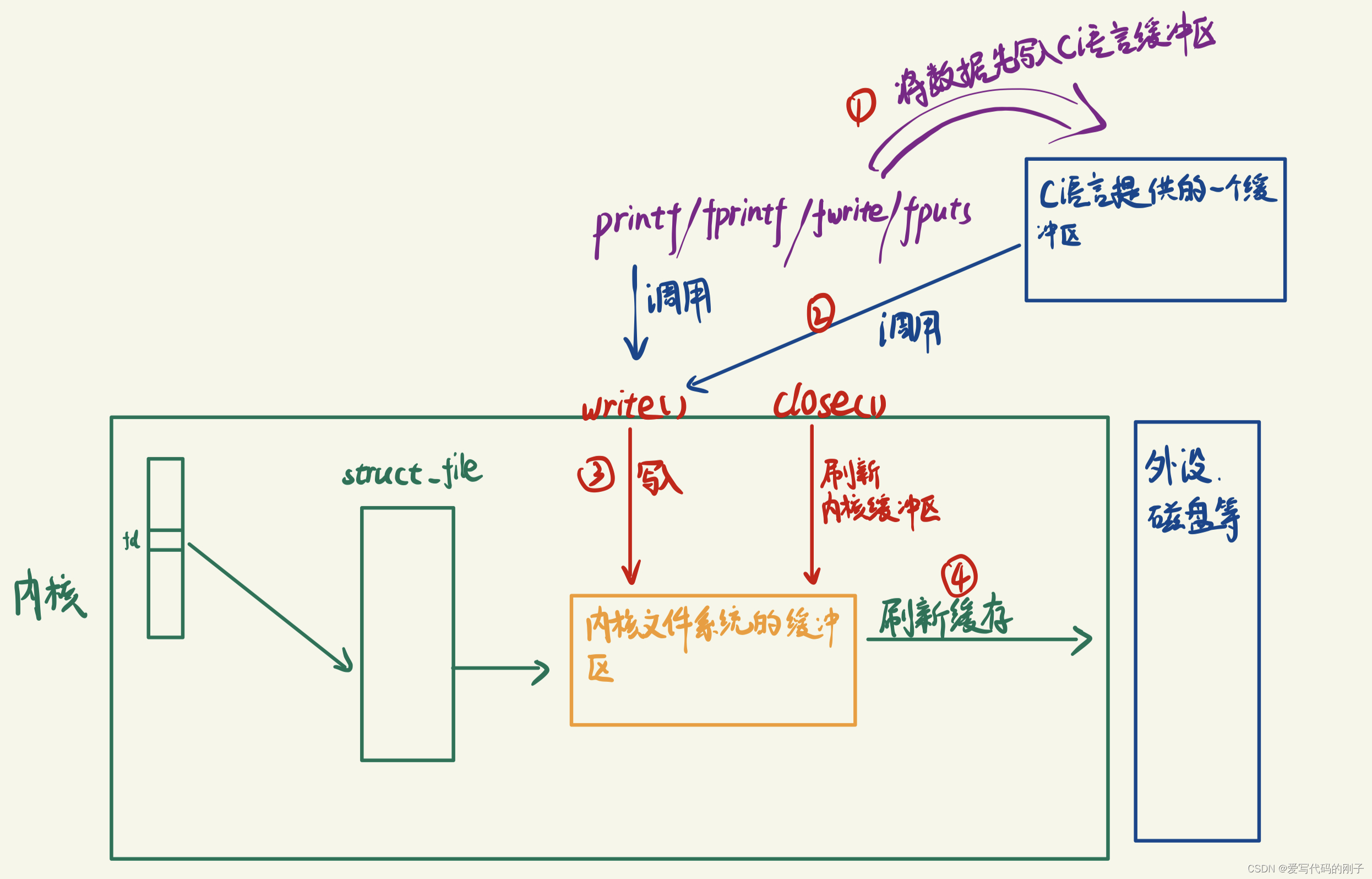
图示:
解释现象:
-
对于现象二:C语言文件操作函数中的字符串不带有’\n’,即数据还停留在C语言的缓冲区中,并未刷新和调用write()函数,将数据刷新到内核系统文件的缓冲区中,而write()函数由于是系统调用函数,能正常执行,但是由于close()函数将显示器文件关闭了,即使进程结束也不能将数据从缓冲区刷新到显示器中。(如果将close函数屏蔽,将会将C语言缓冲区中的数据刷新到显示器)
-
对于现象三:(1)在程序未进行重定向之前,默认是将数据写入显示器中,当遇到’\n’时,将数据从C语言的缓冲区中刷新到内核文件系统的缓冲区,fork()并不影响原本程序的运行。(2)在程序进行重定向之后,数据从向显示器写入变为了向文件中写入,缓冲区从行缓冲变为了全缓冲,所以此时的’\n’并不起作用,所以数据依然存储在C语言的缓冲区中,fork()函数创建子进程时子进程会将父进程的C语言缓冲区进行拷贝,当父子进程结束后将缓冲区里面的内容全部刷新,输出到显示器中。
- 显示器的文件的刷新方案是行刷新,所以在printf执行完就会在遇到’\n’的时候会立即进行刷新,用户刷新的本质就是将数据通过1+write写入到内核中。(目前我们认为,只要将数据刷新到了内核,数据就可以到硬件了)。
缓冲区刷新问题
- 无缓冲 ——直接刷新
- 行缓冲——不刷新,碰到’\n’刷新(显示器)
- 全缓冲——缓冲区满了才刷新(普通文件的写入)
- 进程退出的时候也会刷新缓冲区
缓冲区存在的意义
- 解决效率问题
- 配合格式化(printf中需要将%d等符号进行替换)
File
FILE里面含有对应打开文件等缓冲区字段和维护信息,同时FILE对象属于用户,这个缓冲区属于用户级缓冲区(语言属于用户层)
模拟实现C语言中文件标准库
- Mystdio.h文件:
#ifndef __MYSTDIO_H__
#define __MYSTDIO_H__
//open头文件
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
//
#include <unistd.h>
//
#include <string.h>
#include <stdlib.h>#define FILE_MODE 0666
#define SIZE 1024#define FLUSH_NOW 1//0001
#define FLUSH_LINE 2//0010
#define FLUSH_ALL 4//0100typedef struct IO_FILE{int fileno;int flag;char inbuffer[SIZE];int in_pos;char outbuffer[SIZE];int out_pos;//缓冲区的有效字符和无效字符分界
}_FILE;_FILE* _fopen(const char* filename,const char* flag);
int _fwrite(_FILE *fp,const char*s,int len);
void _fclose(_FILE *fp);#endif
- Mystdio.c文件:
#include "Mystdio.h"_FILE* _fopen(const char* filename,const char* flag)
{int f=0;int fd=-1;if(strcmp(flag,"w")==0){f=O_CREAT|O_WRONLY|O_TRUNC;fd= open(filename,f,FILE_MODE);}else if(strcmp(flag,"r")==0){f=O_CREAT|O_RDONLY|O_TRUNC;fd= open(filename,f,FILE_MODE);}else if(strcmp(flag,"a")==0){f=O_APPEND;fd= open(filename,f);}else{return NULL;}if(fd==-1) return NULL;//创建文件结构对象_FILE* fp=(_FILE*)malloc(sizeof(_FILE));if(fp==NULL)return NULL;fp->fileno = fd;fp->flag= FLUSH_LINE;fp->out_pos=0;return fp;
}
int _fwrite(_FILE *fp,const char*s,int len)
{memcpy(&fp->outbuffer[fp->out_pos],s,len);//这里省略了异常处理fp->out_pos+=len;if(fp->flag & FLUSH_NOW){write(fp->fileno,fp->outbuffer,fp->out_pos);fp->out_pos=0;}else if(fp->flag & FLUSH_LINE){if(fp->outbuffer[fp->out_pos-1]=='\n')//'\n'可能出现在字符中间,这时候需要对字符串做裁剪{write(fp->fileno,fp->outbuffer,fp->out_pos);fp->out_pos=0;}}else if(fp->flag & FLUSH_ALL){if(fp->out_pos==SIZE){write(fp->fileno,fp->outbuffer,fp->out_pos);//全写出去fp->out_pos=0;}}return len;//成功写入的长度
}
void _fflush(_FILE *fp)
{if(fp->out_pos>0){write(fp->fileno,fp->outbuffer,fp->out_pos);fp->out_pos=0;}
}
void _fclose(_FILE *fp)
{if(fp==NULL)return ;_fflush(fp);close(fp->fileno);free(fp);
}
Main.c文件:
#include "Mystdio.h"#define myfile "test.txt"
int main()
{_FILE* fp=_fopen(myfile,"w");if(fp==NULL){return 1;}int cnt =10;while(cnt--){const char* msage = "hello Linux\n";_fwrite(fp,msage,strlen(msage));sleep(1);}//_fflush(fp)return 0;
}测试:
makefile文件:
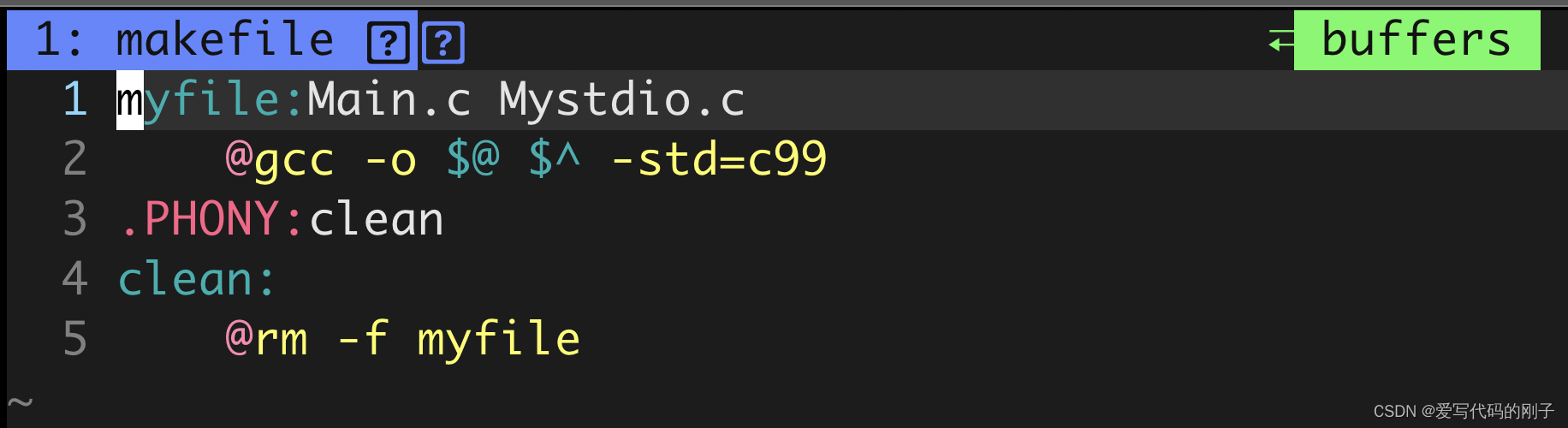
while :;do cat test.txt;sleep 1;echo “----------------------”;done持续打印文件内容
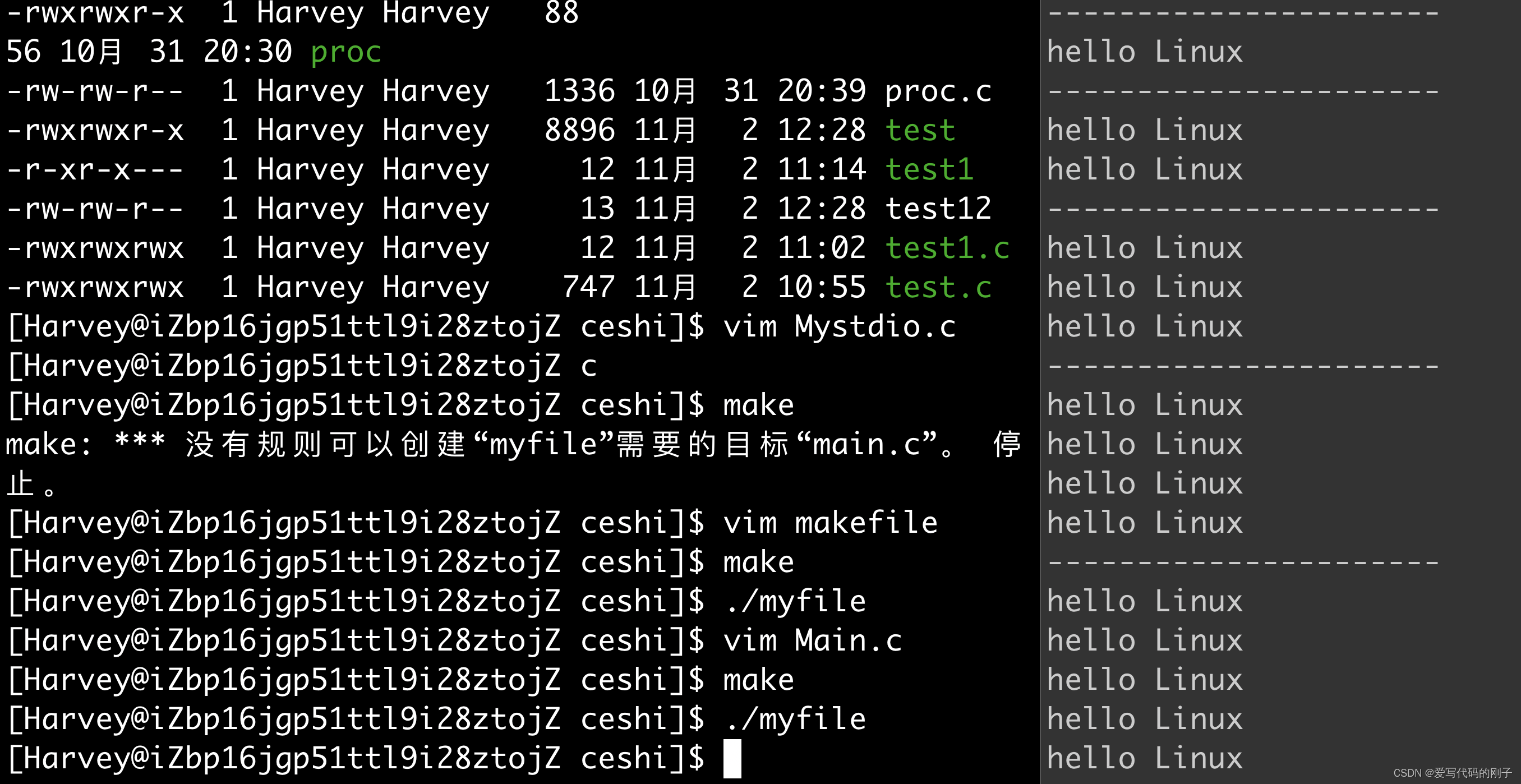
一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。 printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后 但是进程退出之后,会统一刷新,写入文件当中。 但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的 一份数据,随即产生两份数据。write没有变化,说明没有所谓的缓冲。
printf fwrite 库函数会自带缓冲区(用户级缓冲区),而 write系统调用没有带缓冲区。(为了提升整机性能,OS也会提供相关内核级缓冲区)
文件系统
认识磁盘
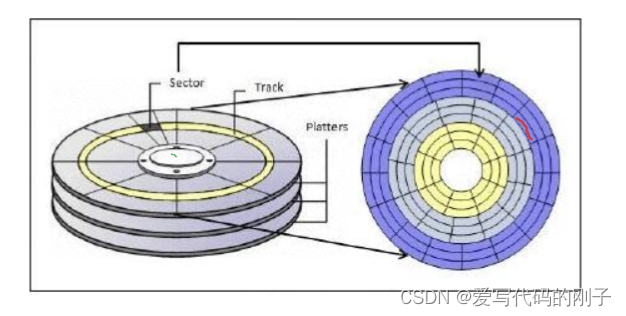
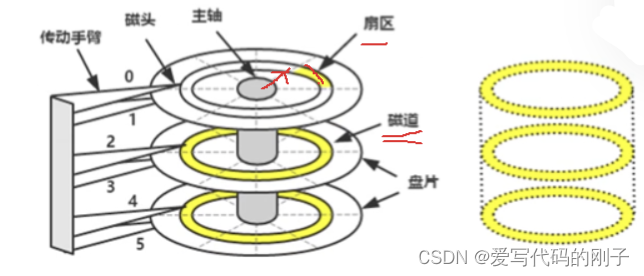
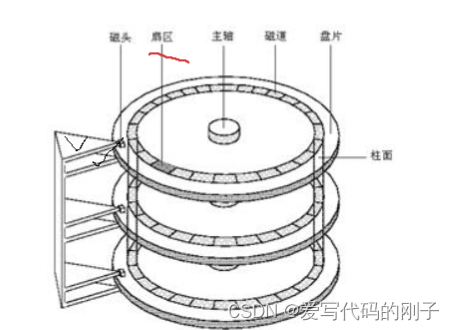

- 磁头是一面一个,磁头和盘面不接触,磁头臂会进行摆动来定位柱面或磁道(磁臂运动越少,效率越高,反之越低),所以在软件设计上一定要有意识将相关数据放在一起
磁盘的逻辑结构是线性的(对磁盘理解和建模)
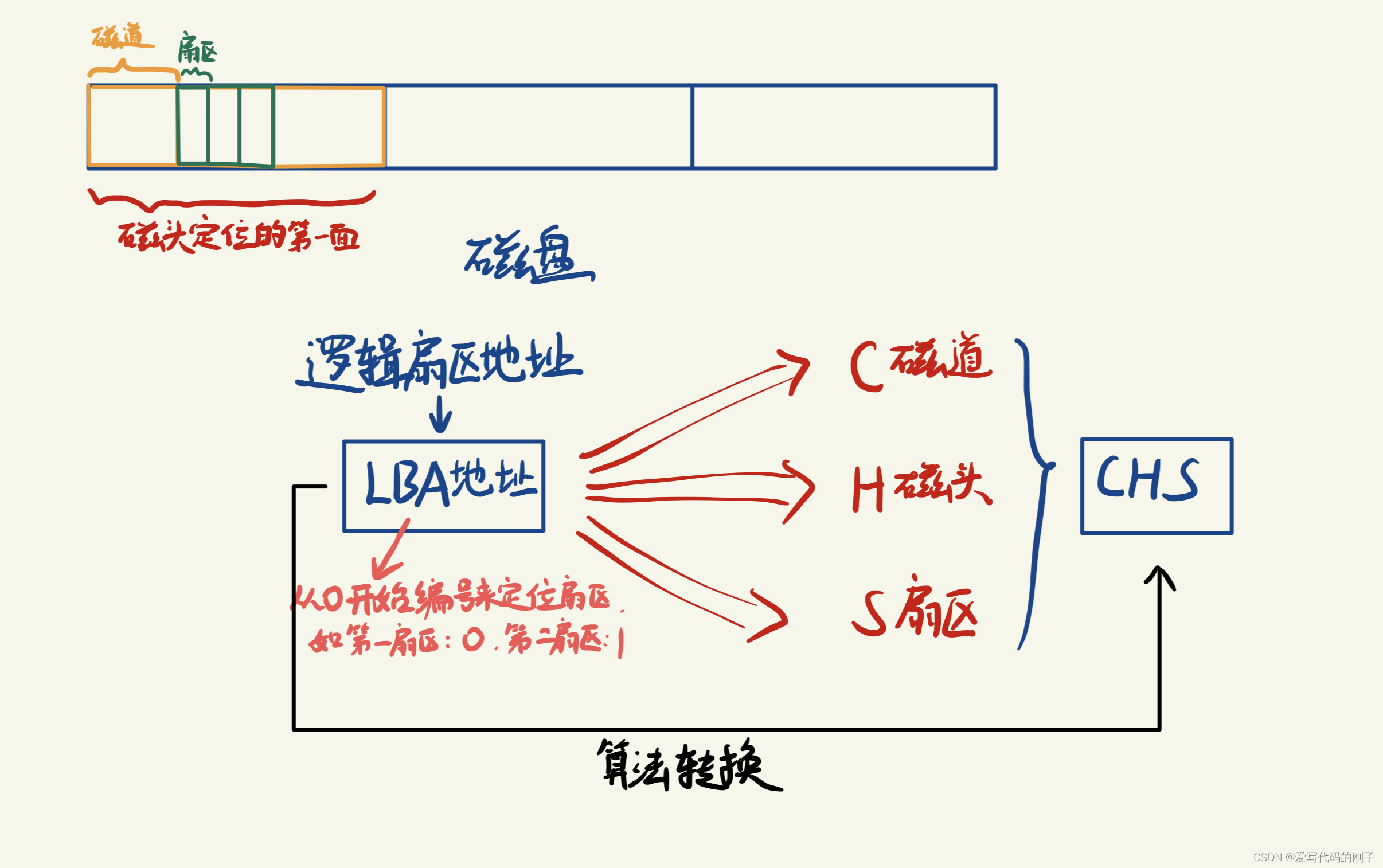
- 扇区的一般大小是512字节或者4kb
不仅CPU有寄存器,其他设备(外设)也存在寄存器

对磁盘进行分区
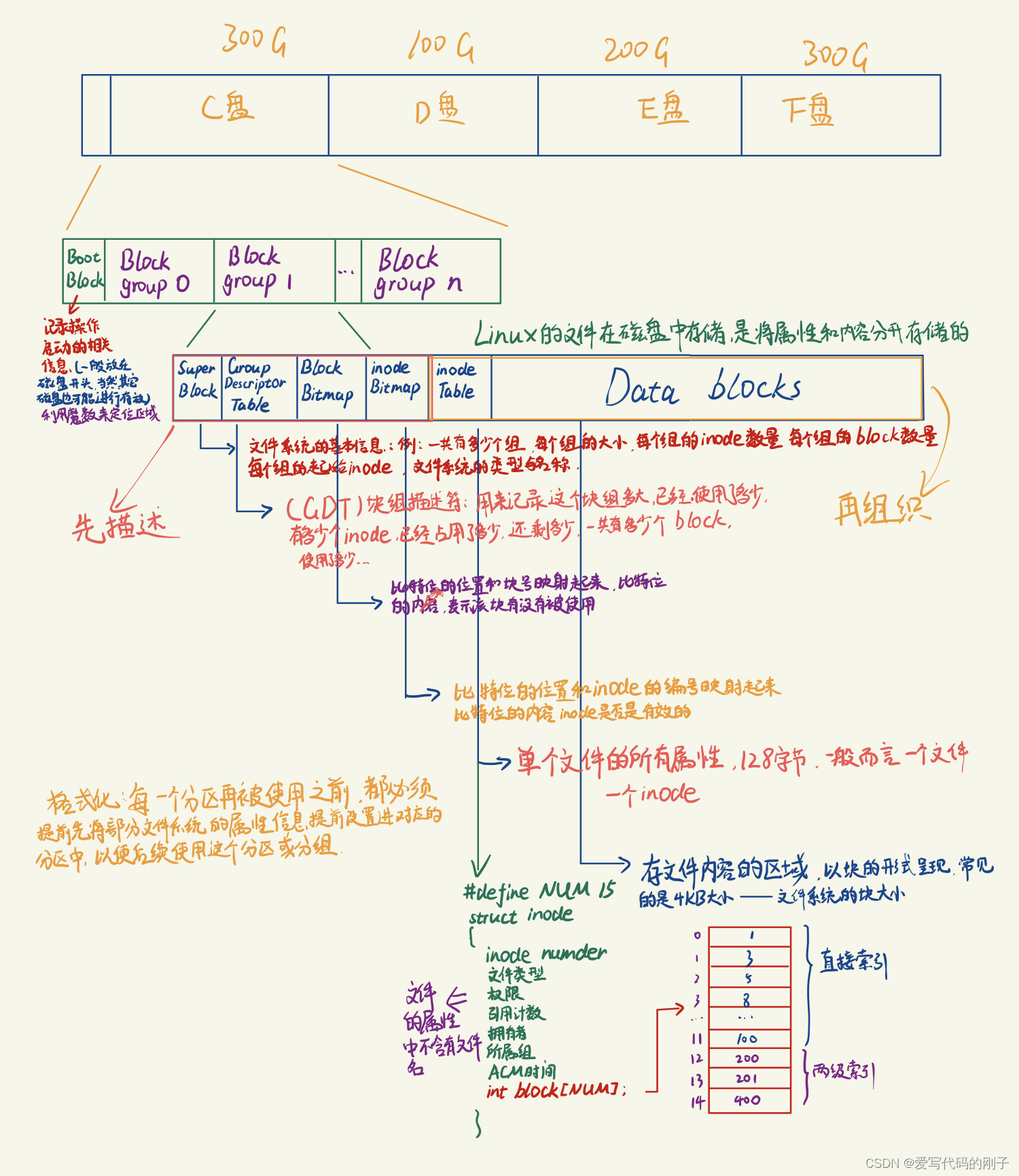
关于inode中的block数组:
inode中有struct inode结构体,里面包括了文件所有的属性,和一个blocks[15]数组,其中的下标[0, 11]直接保存的就是该文件对应的blocks编号,下标[12, 15]指向一个datablock,但是这个datablock不保存有效数据,而保存文件所适用的其它块的编号。(相当于一个二级索引)
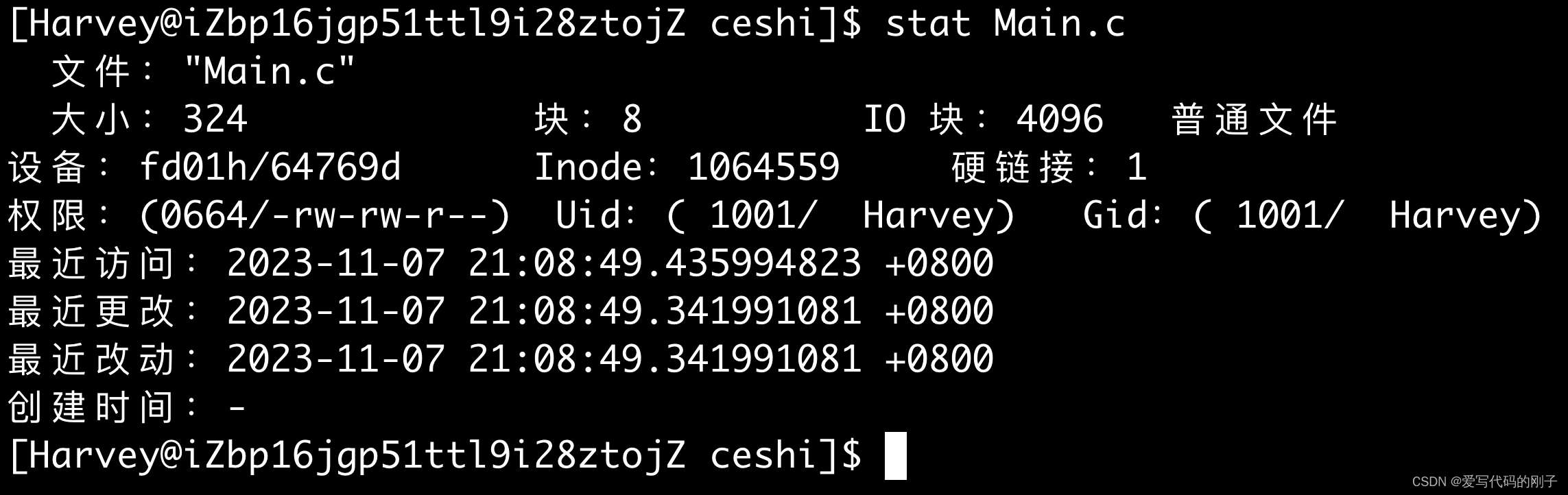
stat +文件名查看文件的具体信息
ls -lia查看所有文件的信息(包括文件的inode)
ls -i查看当前目录下各文件的inode编号
启动块的大小是确定的,而块组的大小是由格式化的时候确定的,并且不可以更改。
文件 = 内容 + 属性,二者都是数据,都要存储。Linux采用的是将内容和属性数据分开存储的方案,内容在block中(4KB),内容是可以无限增多的。属性数据在inode中(128字节),文件的属性是稳定的。
注意一个要点,inode可能会存在用完的情况
- Linux系统中,一个文件一个inode,每一个inode。每一个inode都有自己的inode编号(inode的设置是以分区为单位的,不能跨分区)
对目录的理解
Linux下一切皆文件,目录也是一个文件,通过文件名(对应的inode编号)-> 找到自己所处的目录 -> 根据目录的inode,找到目录的data block -> 将文件名和inode编号的映射关系写入到目录的数据块中。


- 问题1:为什么同一个目录下不能存在同名文件?
因为一个文件只存在一个inode,文件名是作为key值去找inode的,如果存在同名文件就会破坏对应的映射关系。
- 问题2:为什么没有w权限就不能创建文件?
即便是能创建文件,也不能将该文件与inode的映射关系写到数据块中。
- 问题3:为什么没有r权限就不能查看文件?
无法拿到该目录文件中文件与inode之间的映射关系
- 问题4:为什么没有x权限就不能进入目录?
不让用户更改环境变量中的目录信息
查找任何一个文件时,我们必须从当前目录递归到根目录,然后从根目录信息中查找对应子目录的inode信息(效率会低)
所以Linux中会存在提升效率的方法,将常用的路径信息进行缓存(dentry缓存,里面的结构算法较复杂)
软硬链接
建立软链接
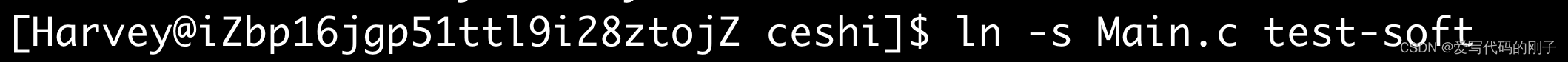


软链接的inode不同
软连接又叫符号链接,软连接文件相当于源文件来说是一个独立的文件,该文件有自己的inode号,但是该文件只包含了源文件的路径名,所以软连接文件的大小要比源文件小得多。软连接就类似于Windows操作系统当中的快捷方式。软链接保存的是对应文件的所在路径
ln -s 对应的路径 软链接的名字添加快捷方式
建立硬链接

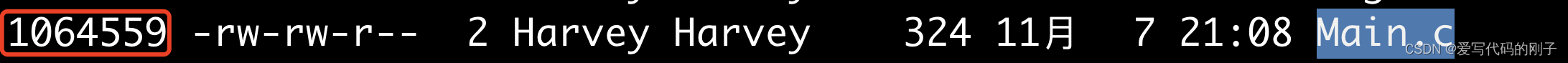

硬链接的inode相同,同时文件的引用计数变为了2
- 硬连接数本质就是该文件inode属性中的计数器count,标识有几个文件名和我的inode建立了映射关系。简言之,就是有几个文件名指向我的inode(文件本身)硬链接就是让多个不在或者同在一个目录下的文件名,同时能够修改同一个文件,其中一个修改后,所有与其有硬链接的文件都一起修改了。
为什么文件被创建出来,默认的硬连接数是1?
- 如果硬链接数是0,那么就应该是被关闭的文件了,所以至少应该从1开始。此外,普通文件的文件名,本身就和自己的inode具有映射关系,且只有1个,所以文件的默认硬连接数是1。
创建一个新目录时引用计数默认为2
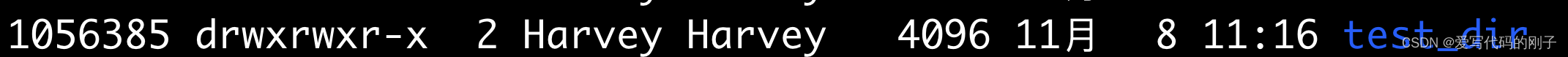
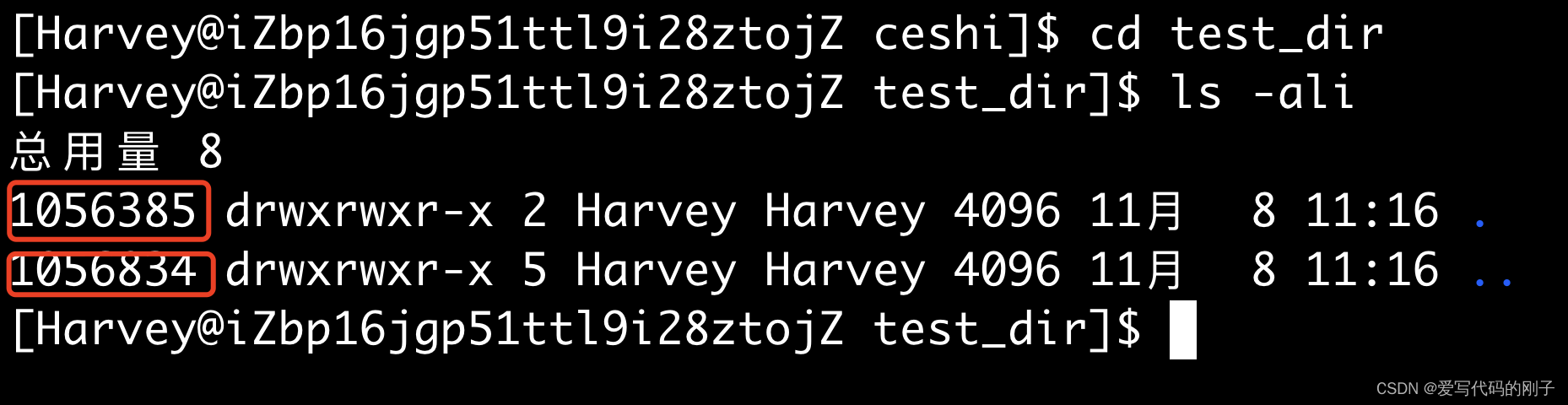
- 我们也可以根据系统的硬连接数,不进入文件,从而估算出文件的目录数(一个目录下相邻的子目录数 = 该目录的硬连接数 - 2)。因此,硬链接的一个作用就是进行路径切换。
软硬链接的删除
unlink(unlink也可以删除普通文件,与rm没什么区别)

文件的三个时间
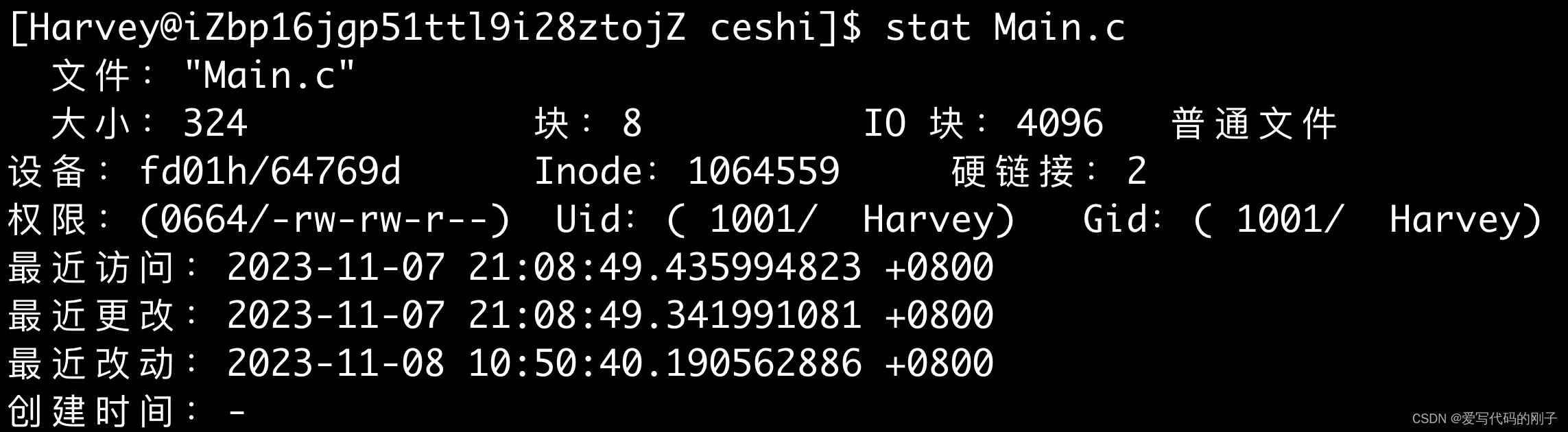
这其中包含了文件的三个时间信息:
- Access: 文件最后被访问的时间。
- Modify: 文件内容最后的修改时间。
- Change: 文件属性最后的修改时间。
当我们修改文件内容时,文件的大小一般会随之改变,所以Modify的改变会带动Change一起改变,但对该文件属性一般不会影响文件内容,所以一般情况下Change的改变不会带动Modify的改变。此外,我们可以使用touch命令把这三个时间都更新到最新状态。(当一文件存在时使用touch命令,此时touch命令的作用变为更新文件信息)。
相关文章:
【Linux基础IO篇】用户缓冲区、文件系统、以及软硬链接
【Linux基础IO篇】用户缓冲区、文件系统、以及软硬链接 目录 【Linux基础IO篇】用户缓冲区、文件系统、以及软硬链接深入理解用户缓冲区缓冲区刷新问题缓冲区存在的意义 File模拟实现C语言中文件标准库 文件系统认识磁盘对目录的理解 软硬链接软硬链接的删除文件的三个时间 作者…...
电脑软件:推荐一款电脑多屏幕管理工具DisplayFusion
下载https://download.csdn.net/download/mo3408/88514558 一、软件简介 DisplayFusion是一款多屏幕管理工具,它可以让用户更轻松地管理连接到同一台计算机上的多个显示器。 二、软件功能 2.1 多个任务栏 通过在每个显示器上显示任务栏,让您的窗口管理更…...
免费好用的网页采集工具软件推荐
在众多各具特色的采集器软件中,真正好用的采集器软件有哪些? 自己一个个去查找和尝试无疑会耗费大量的时间和精力。 因此,在深入体验大多数采集器后,给大家推荐几款优秀且好用的免费网页采集器软件。 本文将对这几款采集器进行…...
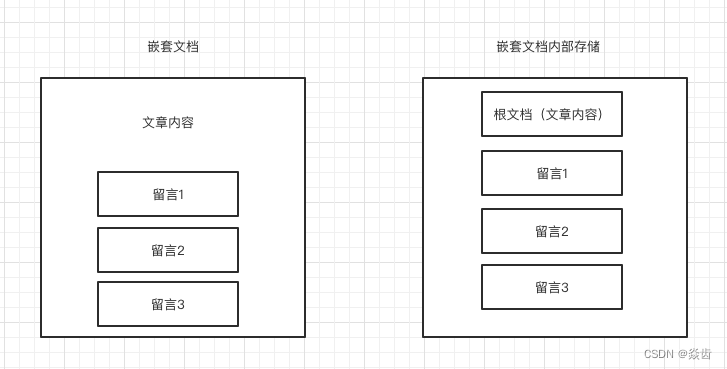
6.ELK之Elasticsearch嵌套(Nested)类型
0、前言 在Elasticsearch实际应用中经常会遇到嵌套文档的情况,而且会有“对象数组彼此独立地进行索引和查询的诉求”。在ES中这种嵌套文档称为父子文档,父子文档“彼此独立地进行查询”至少有以下两种方式: 1)父子文档。在ES的5.…...
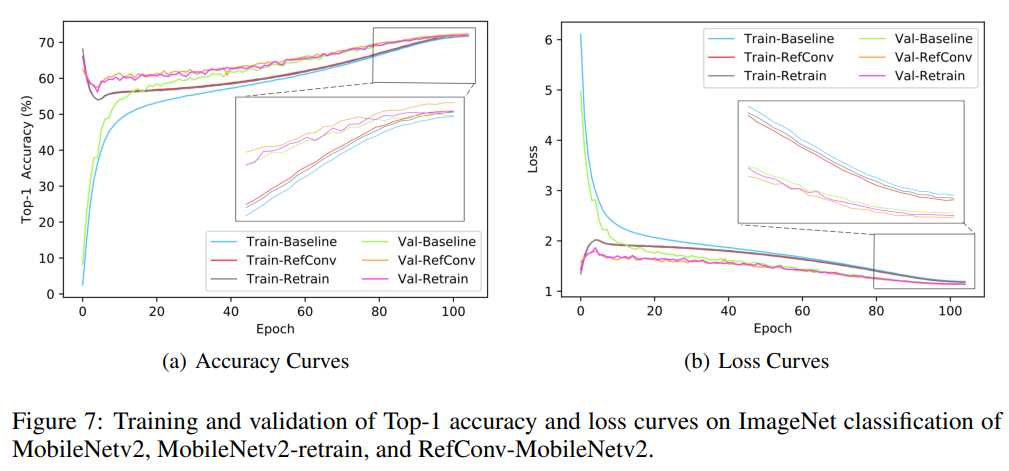
RefConv: 重参数化的重新聚焦卷积(论文翻译)
文章目录 摘要1、简介2、相关研究2.1、用于更好性能的架构设计2.2、结构重参数化2.3、权重重参数化方法 3、重参数化的重聚焦卷积3.1、深度RefConv3.2、普通的RefConv3.3、重聚焦学习 4、实验4.1、在ImageNet上的性能评估4.2、与其他重参数化方法的比较4.3、目标检测和语义分割…...

指令重排序
指令重排序是现代处理器在执行指令时的一种优化技术,其目的是为了提高处理器执行指令的效率。这种优化手段会对指令进行重新排序,以提高并行度和性能。 为何会发生指令重排序: 处理器性能优化: 为了更好地利用现代处理器的流水线、…...

【Head First 设计模式】-- 观察者模式
背景 客户有一个WeatherData对象,负责追踪温度、湿度和气压等数据。现在客户给我们提了个需求,让我们利用WeatherData对象取得数据,并更新三个布告板:目前状况、气象统计和天气预报。 WeatherData对象提供了4个接口: …...

JavaWeb篇_01——JavaEE简介【面试常问】
JavaEE简介 什么是JavaEE JavaEE(Java Enterprise Edition),Java企业版,是一个用于企业级web开发平台,它是一组Specification。最早由Sun公司定制并发布,后由Oracle负责维护。在JavaEE平台规范了在开发企业级web应用…...

QtC++与QRadioButton详解
介绍 QRadioButton 是 Qt 中的一个重要部件,用于创建单选按钮,它有以下几个主要作用和特点: 单选功能: QRadioButton 用于创建单选按钮,用户可以从一组互斥的选项中选择一个。这在用户界面设计中常用于需要用户从多个…...
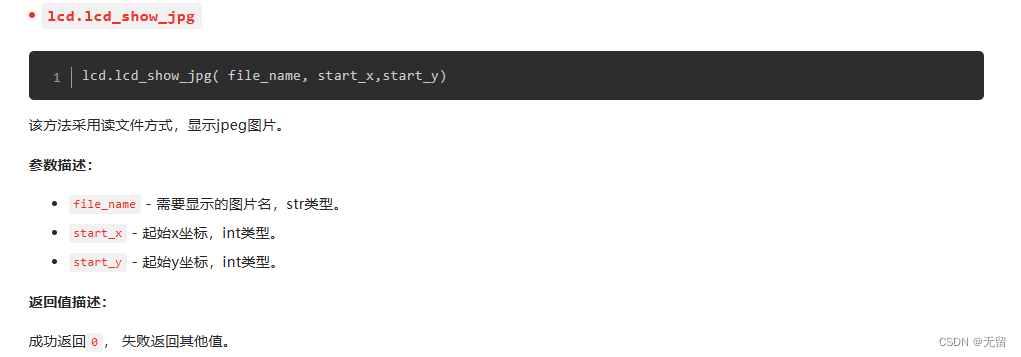
移远EC600U-CN开发板 day01
1.官方文档快速上手,安装驱动,下载QPYcom QuecPython 快速入门 - QuecPython (quectel.com)https://python.quectel.com/doc/Getting_started/zh/index.html 注意: (1)打开开发板步骤 成功打开之后就可以连接开发板…...
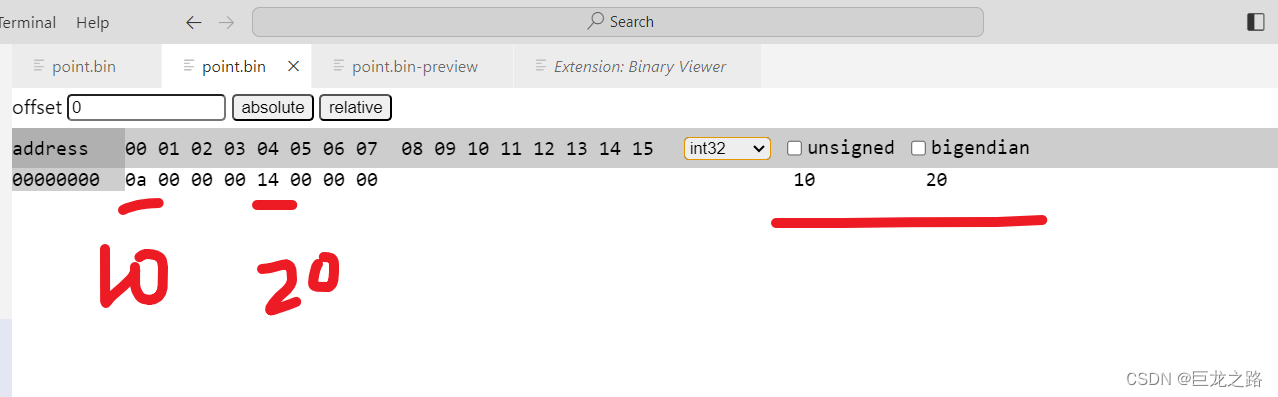
【C/C++】什么是POD(Plain Old Data)类型
2023年11月6日,周一下午 目录 POD类型的定义标量类型POD类型的特点POD类型的例子整数类型:C 风格的结构体:数组:C 风格的字符串:std::array:使用 memcpy 对 POD 类型进行复制把POD类型存储到文件中,并从文…...
注册虾皮买家号需要哪些资料?
注册虾皮买家号其实是很简单的,使用相应国家的手机号及对应的环境就可以注册了的,如果想要账号更方便使用,也可以绑定邮箱进行认证。 而如果想要使用shopee买家通系统进行自动化的注册,那么对于资料就有一定的要求了。 1、手机号…...

小腿筋膜炎怎么治疗最有效
小腿筋膜炎症状主要有疼痛、肌肉紧张、活动受限等。 1.疼痛:小腿筋膜炎主要会导致炎症性疼痛,没有固定的压痛点,通常以踝关节、膝关节活动时疼痛为主。疼痛呈持续性,或者反复发作,尤其是在晨起或者天气变化、劳累、受…...
After Effects 2024 v24.0.2(AE2024)
After Effects 2024是视频特效和动态图形设计软件。以下是After Effects 2024的主要功能和特点: 支持创建各种令人惊叹的视觉效果,例如粒子系统、合成特效、绿屏抠像等。支持动画制作,包括关键帧动画、形状动画、运动跟踪等工具,…...
自己实现一个自动检测网卡状态,并设置ip地址
阅读本文前,请先学习下面几篇文章 《搞懂进程组、会话、控制终端关系,才能明白守护进程干嘛的?》 《简简单单教你如何用C语言列举当前所有网口!》 《Linux下C语言操作网卡的几个代码实例!特别实用》 《安卓如何设置…...
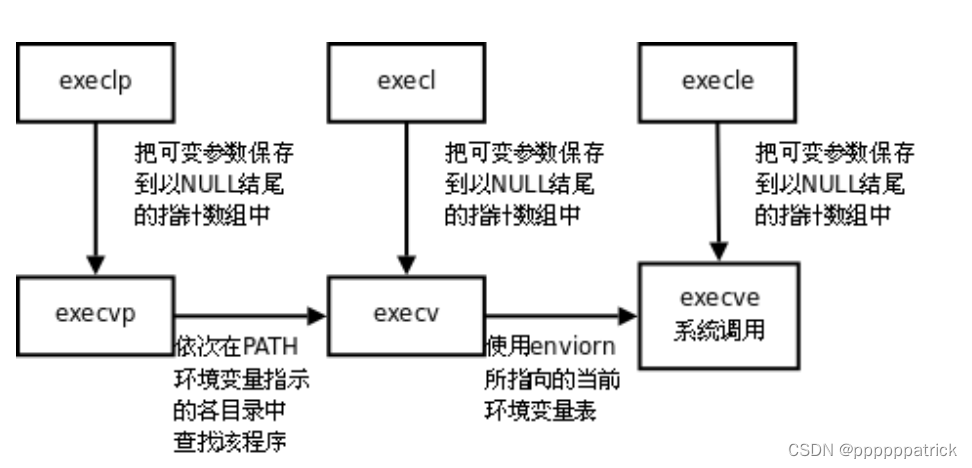
【Linux】进程程序替换
文章目录 替换原理站在进程的角度站在程序的角度初体验及理解原理 替换函数函数解释命名理解exec系列函数与main函数之间的关系在一个程序中调用我们自己写的程序 替换原理 创建子进程的目的是什么? ->想让子进程执行父进程代码的一部分 执行父进程对应的磁盘代码…...
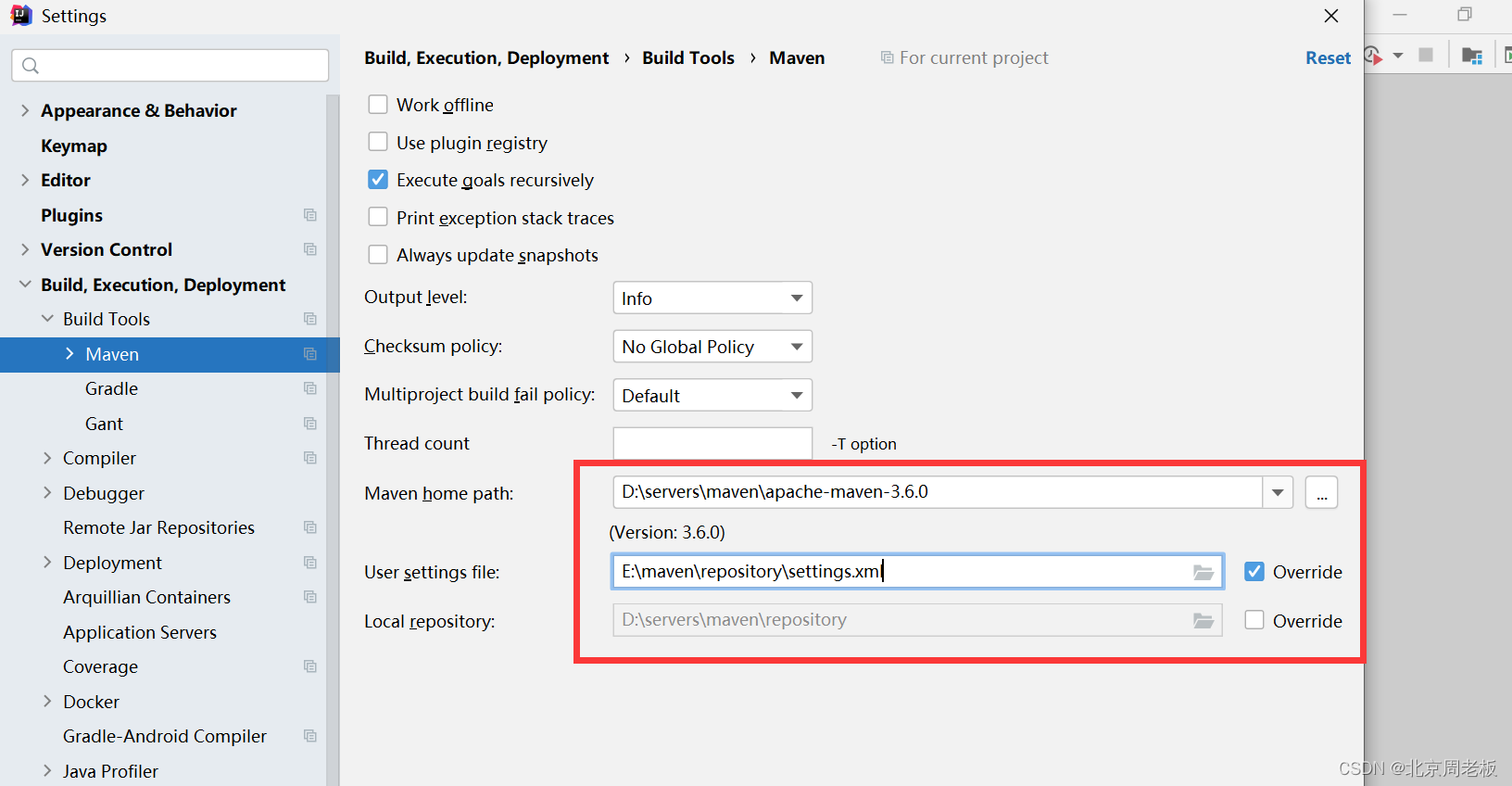
项目构建工具maven的基本配置+idea 中配置 maven
👑 博主简介:知名开发工程师 👣 出没地点:北京 💊 2023年目标:成为一个大佬 ——————————————————————————————————————————— 版权声明:本文为原创文…...

【解密ChatGPT】:从过去到未来,揭示其发展与变革
🎊专栏【ChatGPT】 🌺每日一句:天行健,君子以自强不息,地势坤,君子以厚德载物 ⭐欢迎并且感谢大家指出我的问题 文章目录 一、ChatGPT的发展历程 二、ChatGPT的技术原理 三、ChatGPT的应用场景 四、ChatGPT的未来趋势 五、总结 引言:随着…...

系统架构设计】计算机公共基础知识: 5 数学与经济管理
一 运筹方法 1 线性规划 线性规划问题的数学模型通常由线性目标函数、线性约束条件、变量非负条件组成,特点如下: (1)线性规划的可行解域是由一组线性约束条件形成的。 (2)如果存在两个最优解,则连接这两点的线段内所有的点都是最优解,而线段两端延长线上可能会超出…...

Visual Studio 2019光标变成灰色方块问题
文章目录 Visual Studio 2019光标变成灰色方块问题问题描述解决方案 Visual Studio 2019光标变成灰色方块问题 问题描述 单击和双击都无法选中单词,总是选择整行或者是当前光标处的前几个字符一起选中,没有规则,貌似选择单词复制࿰…...

OpenClaw社区贡献指南:为Qwen3-14b_int4_awq开发并分享自定义技能
OpenClaw社区贡献指南:为Qwen3-14b_int4_awq开发并分享自定义技能 1. 为什么我们需要更多社区技能 上周我尝试用OpenClaw自动整理电脑里堆积如山的PDF论文时,发现现有的文件处理技能无法识别某些特殊格式的学术文献。这个痛点让我意识到:Op…...

Scikit-learn的随机SVD真的能“超快”降维吗?先看清代价
先说结论随机SVD确实能大幅提升PCA速度,尤其在样本量大的场景,但代价是可控的精度损失和随机性引入这种优化更适合离线或准实时处理,在严格实时边缘系统中仍可能成为瓶颈,需要结合硬件加速选择随机SVD前,必须明确业务对…...

Unity性能优化终极利器:MeshFusion Pro
在现代游戏开发中,性能优化始终是一个核心问题。尤其是在大型场景或高复杂度模型的项目中,Draw Call 过多、顶点数量庞大以及实时生成对象都会严重拖慢游戏帧率,影响用户体验。为了应对这些挑战,Unity 开发者社区中出现了大量优化…...

HP 现在可以零成本构建原生 iOS 和 Android 应用 NativePHP for Mobile v3 发布
插件化架构 v3 版本最大的变化是引入了模块化插件系统。此前版本中集成在核心包里的原生功能,现在被拆分成独立的插件。 每个插件都是一个独立的 Composer 包,包含 Swift 和 Kotlin 代码、权限清单以及原生依赖。开发者只需安装实际用到的插件…...
)
PyTorch实战:如何用潜在扩散模型生成高清图像(附DDPM/DDIM/PLMS对比)
PyTorch实战:潜在扩散模型采样方法全面评测与优化指南 1. 潜在扩散模型核心架构解析 潜在扩散模型(Latent Diffusion Models, LDM)已成为当前生成式AI领域最具突破性的技术之一。与直接在像素空间操作的扩散模型不同,LDM通过变分自…...

嵌入式字符LCD进度条库:LcdProgressBar轻量实现
1. 项目概述LcdProgressBar是一个面向嵌入式 LCD 显示场景的轻量级进度条绘制库,专为基于字符型液晶显示屏(Character LCD)的资源受限系统设计。其核心定位并非替代图形 LCD 的矢量渲染能力,而是以极低内存开销和确定性执行时间&a…...

电子元器件失效分析与预防实战指南
1. 电子元器件失效的底层逻辑剖析 电子元器件失效的本质是材料特性、环境应力与时间因素共同作用的结果。作为一名硬件工程师,我处理过数百例元器件失效案例,发现失效模式往往遵循"应力-损伤-失效"的因果链。理解这个链条,才能从根…...

Linux who命令实现:文件读写与系统编程实践
1. 从零实现Linux who命令:深入理解文件读写与系统编程作为一个常年与Linux打交道的开发者,我始终认为理解系统命令的实现原理是提升编程能力的最佳途径。今天我们就来解剖who这个看似简单却内涵丰富的命令,通过亲手实现它来掌握Linux文件操作…...

Claude Code 常用命令
先记住一个最重要的动作 在 Claude Code 里,直接输入 /,就能看到当前可用的全部命令。 继续输入 / 加上字母,还可以快速筛选命令。 官方文档也特别说明了一点:并不是所有命令对每个用户都可见。 有些命令会受到平台、套餐、环境或终端能力的影响。一张图先建立命令体系 新…...

TCP/IP协议族与网络体系结构实战解析
1. 计算机网络体系结构解析计算机网络体系结构是理解整个互联网通信的基础框架。目前主流的体系结构有三种:OSI七层模型、TCP/IP四层模型和教学用的五层模型。作为一名从业十年的网络工程师,我发现在实际工作中TCP/IP四层模型的应用最为广泛。OSI七层模型…...