nanodet训练自己的数据集、NCNN部署到Android
nanodet训练自己的数据集、NCNN部署到Android
- 一、介绍
- 二、训练自己的数据集
- 1. 运行环境
- 2. 数据集
- 3. 配置文件
- 4. 训练
- 5. 训练可视化
- 6. 测试
- 三、部署到android
- 1. 使用官方权重文件部署
- 1.1 下载权重文件
- 1.2 使用Android Studio部署apk
- 2. 部署自己的模型【暂时存在问题】
- 2.1 生成ncnn模型
- 2.2 部署到android
一、介绍
看看作者自己的介绍吧
NanoDet-Plus 知乎中文介绍
NanoDet 知乎中文介绍

二、训练自己的数据集
1. 运行环境
conda create -n nanodet python=3.8 -y
conda activate nanodetconda install pytorch torchvision cudatoolkit=11.1 -c pytorch -c conda-forgegit clone https://github.com/RangiLyu/nanodet.git
cd nanodetpip install -r requirements.txtpython setup.py develop
2. 数据集
该示例最后使用的是coco格式的标注文件,下方提供了一个voc转coco的脚本。
import os
from tqdm import tqdm
import xml.etree.ElementTree as ET
import jsonclass_names = ["cat", "bird", "dog"]def voc2coco(data_dir, train_path, val_path):xml_dir = os.path.join(data_dir, 'Annotations')img_dir = os.path.join(data_dir, 'JPEGImages')train_xmls = []for f in os.listdir(train_path):train_xmls.append(os.path.join(train_path, f))val_xmls = []for f in os.listdir(val_path):val_xmls.append(os.path.join(val_path, f))print('got xmls')train_coco = xml2coco(train_xmls)val_coco = xml2coco(val_xmls)with open(os.path.join(data_dir, 'coco_train.json'), 'w') as f:json.dump(train_coco, f, ensure_ascii=False, indent=2)json.dump(val_coco, f, ensure_ascii=False, indent=2)print('done')def xml2coco(xmls):coco_anno = {'info': {}, 'images': [], 'licenses': [], 'annotations': [], 'categories': []}coco_anno['categories'] = [{'supercategory': j, 'id': i + 1, 'name': j} for i, j in enumerate(class_names)]img_id = 0anno_id = 0for fxml in tqdm(xmls):try:tree = ET.parse(fxml)objects = tree.findall('object')except:print('err xml file: ', fxml)continueif len(objects) < 1:print('no object in ', fxml)continueimg_id += 1size = tree.find('size')ih = float(size.find('height').text)iw = float(size.find('width').text)img_name = fxml.strip().split('/')[-1].replace('xml', 'jpg')img_name = img_name.split('\\')img_name = img_name[-1]img_info = {}img_info['id'] = img_idimg_info['file_name'] = img_nameimg_info['height'] = ihimg_info['width'] = iwcoco_anno['images'].append(img_info)for obj in objects:cls_name = obj.find('name').textif cls_name == "water":continuebbox = obj.find('bndbox')x1 = float(bbox.find('xmin').text)y1 = float(bbox.find('ymin').text)x2 = float(bbox.find('xmax').text)y2 = float(bbox.find('ymax').text)if x2 < x1 or y2 < y1:print('bbox not valid: ', fxml)continueanno_id += 1bb = [x1, y1, x2 - x1, y2 - y1]categery_id = class_names.index(cls_name) + 1area = (x2 - x1) * (y2 - y1)anno_info = {}anno_info['segmentation'] = []anno_info['area'] = areaanno_info['image_id'] = img_idanno_info['bbox'] = bbanno_info['iscrowd'] = 0anno_info['category_id'] = categery_idanno_info['id'] = anno_idcoco_anno['annotations'].append(anno_info)return coco_annoif __name__ == '__main__':save_dir = './datasets/annotations' # 保存json文件的路径train_dir = './datasets/annotations/train/' # 训练集xml文件的存放路径val_dir = './datasets/annotations/val/' # 验证集xml文件的存放路径voc2coco(save_dir, train_dir, val_dir)
最后数据集的路径如下:
-datasets
|--images
| |--train
| | |--00001.jpg
| | |--00004.jpg
| | |--...
| |--val
| | |--00002.jpg
| | |--00003.jpg
| | |--...
|--annatotions
| |--coco_train.json
| |--coco_val.json
3. 配置文件
以nanodet-m-416.yml为例,对照自己的数据集主要修改以下部分
model:head:num_classes: 3 # 数据集类别数data:train:img_path: F:/datasets/images/train # 训练集图片路径ann_path: F:/datasets/annotations/coco_train.json # 训练集json文件路径val:img_path: F:/datasets/images/val # 验证集图片路径ann_path: F:/datasets/annotations/coco_val.json # 验证集json文件路径device:gpu_ids: [0] # GPUworkers_per_gpu: 8 # 线程数batchsize_per_gpu: 60 # batch sizeschedule:total_epochs: 280 # 总epoch数val_intervals: 10 # 每10个epoch进行输出一次对验证集的识别结果class_names: ["cat", "bird", "dog"] # 数据集类别
4. 训练
python tools/train.py config/legacy_v0.x_configs/nanodet-m-416.yml
如果训练中途断了,需要接着训练。首先修改nanodet-m-416.yml中resume和load_model这两行注释去掉,并将model_last.ckpt的路径补上(注意去掉注释后检查下这两行缩进是否正确),然后再python tools/train.py config/legacy_v0.x_configs/nanodet-m-416.yml。
schedule:resume:load_model: F:/nanodet/workspace/nanodet_m_416/model_last.ckptoptimizer:name: SGDlr: 0.14momentum: 0.9weight_decay: 0.0001报错:
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "F:\Anaconda3\envs\ nanodet\lib\site-packages\torch\lib\shm.dll" or one of its dependencies.方案:减小配置文件中线程数
workers_per_gpu,或者直接设为0不使用并行。
5. 训练可视化
TensorBoard日志保存在./nanodet/workspace/nanodet_m_416路径下,可视化命令如下:
tensorboard --logdir=./nanodet/workspace/nanodet_m_416

6. 测试
方法一:
python demo/demo.py image --config config/legacy_v0.x_configs/nanodet-m-416.yml --model nanodet_m_416.ckpt --path test.jpg
方法二:
运行demo\demo-inference-with-pytorch.ipynb脚本(修改代码中from demo.demo import Predictor为from demo import Predictor)

三、部署到android
1. 使用官方权重文件部署
1.1 下载权重文件
1)在F:\nanodet\demo_android_ncnn\app\src\main路径下新建一个文件夹assets;
2)将F:\nanodet\demo_android_ncnn\app\src\main\cpp\ncnn-20211208-android-vulkan路径下的nanodet-plus-m_416.bin和nanodet-plus-m_416.param复制到F:\nanodet\demo_android_ncnn\app\src\main\assets下,并重命名为nanodet.bin和nanodet.param;
3)(可选)下载Yolov4和v5的ncnn模型到F:\nanodet\demo_android_ncnn\app\src\main\assets路径下;

1.2 使用Android Studio部署apk
使用Android Studio打开F:\nanodet\demo_android_ncnn文件夹,按照自己的安卓版本选择相应的Platforms,值得注意的是,NDK需要安装21.0.6113669版本的,否则会报错类似“No version of NDK matched the requested version 21.0.6113669. Versions available locally: 21.3.6528147”。【详细操作可以查看我之前的文章中的1.2节:【终端目标检测01】基于NCNN将YOLOX部署到Android】

部署结果:

2. 部署自己的模型【暂时存在问题】
2.1 生成ncnn模型
- 先转换为onnx文件:
python tools/export_onnx.py --cfg_path config\legacy_v0.x_configs\nanodet-m-416.yml --model_path nanodet_m_416.ckpt
- 再转换为ncnn模型:
使用在线转换https://convertmodel.com/

将转换后的bin和param文件放置到assets文件夹下,可以重命名为nanodet.bin和nanodet.param,也可以修改jni_interface.cpp文件中NanoDet::detector = new NanoDet(mgr, "nanodet_self-sim-opt.param", "nanodet_self-sim-opt.bin", useGPU);
2.2 部署到android
我使用的是nanodet-m-416.yml训练了自己的模型,按照官方的文档修改nanodet.h中超参数,make project和run app都没有报错,但是手机运行程序时识别有问题(类别并不是我自己数据集的类别),暂时还没发现问题所在。

相关文章:
nanodet训练自己的数据集、NCNN部署到Android
nanodet训练自己的数据集、NCNN部署到Android 一、介绍二、训练自己的数据集1. 运行环境2. 数据集3. 配置文件4. 训练5. 训练可视化6. 测试 三、部署到android1. 使用官方权重文件部署1.1 下载权重文件1.2 使用Android Studio部署apk 2. 部署自己的模型【暂时存在问题】2.1 生成…...
含泪整理的超全窗口函数:数据开发必备
最近在搞一些面试和课程答辩的时候,问什么是窗口函数,知道哪些窗口函数?最多的答案就是row_number、rank、dense_rank,在问一下还有其他的吗?这时同学就蒙了,还有其他的窗口函数?其实上面的回答也只是专用窗口函数&am…...

CCF ChinaSoft 2023 论坛巡礼 | NASAC青年软件创新奖论坛
2023年CCF中国软件大会(CCF ChinaSoft 2023)由CCF主办,CCF系统软件专委会、形式化方法专委会、软件工程专委会以及复旦大学联合承办,将于2023年12月1-3日在上海国际会议中心举行。 本次大会主题是“智能化软件创新推动数字经济与社…...

ES 未分片 导致集群状态飘红
GET /_cluster/allocation/explain ALLOCATION_FAILED:由于分片分配失败而未分配。 CLUSTER_RECOVERED:由于集群恢复而未分配。 DANGLING_INDEX_IMPORTED:由于导入了悬空索引导致未分配。 EXISTING_INDEX_RESTORED:由于恢复为已关…...
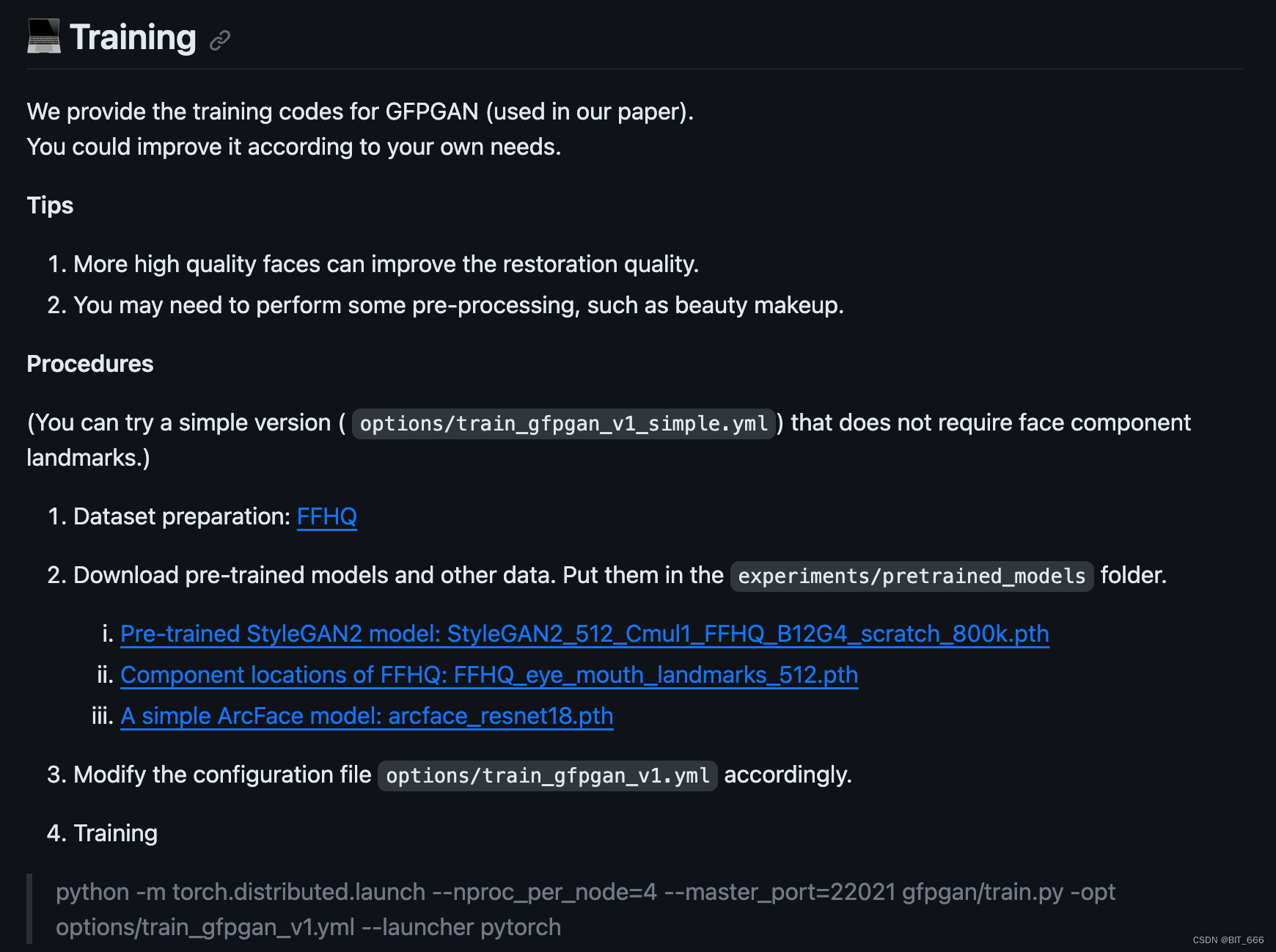
Python - 面向现实世界的人脸复原 GFP-GAN 简介与使用
目录 一.引言 二.GFP-GAN 简介 1.GFP-GAN 数据 2.GFP-GAN 架构 3.GFP-GAN In Wave2Lip 三.GFPGAN 实践 1.环境搭建 2.模型下载 3.代码测试 4.测试效果 四.总结 一.引言 近期 wav2lip 大火,其通过语音驱动唇部动作并对视频质量进行修复,其中…...

Xcode15 framework ‘CoreAudioTypes‘ not found
Xcode15遇见"framework ‘CoreAudioTypes’ not found。" 可尝试移除CoreAudioTypes,添加CoreAudio。 CoreAudio是CoreAudioTypes的套壳。 CoreAudio/CoreAudioTypes.h头文件内容 /*CoreAudio/CoreAudioTypes.h has moved to CoreAudioTypes/CoreAudi…...

torch.cuda.is_available()=false的原因
1、检查是否为nvidia显卡; 2、检查GPU是否支持cuda; 3、命令行cmd输入nvidia-smi(中间没有空格),查看显卡信息,cuda9.2版本只支持Driver Version>396.26;如果小于这个值,那么你就需要更新显…...

asp.net docker-compose添加网关和网关配置
打开docker-compose.yml 添加 killsb-social-apigw:image: ${REGISTRY:-killsbdapr}/killsb-social-apigw:${TAG:-latest}build:context: .dockerfile: src/ApiGateways/SocialEnvoy/Dockerfile 在路径src\ApiGateways\SocialEnvoy 添加envoy.yaml admin:access_log_path: …...
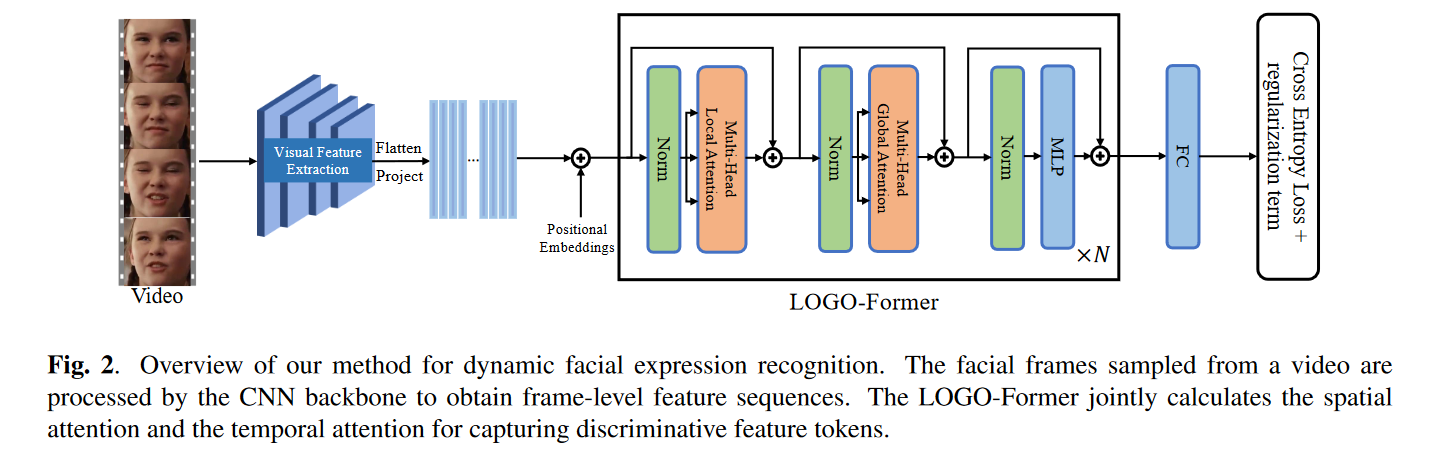
论文阅读:LOGO-Former: Local-Global Spatio-Temporal Transformer for DFER(ICASSP2023)
文章目录 摘要动机与贡献具体方法整体架构输入嵌入生成LOGO-Former多头局部注意力多头全局注意力 紧凑损失正则化 实验思考总结 本篇论文 LOGO-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition发表在ICASSP(声学顶会…...
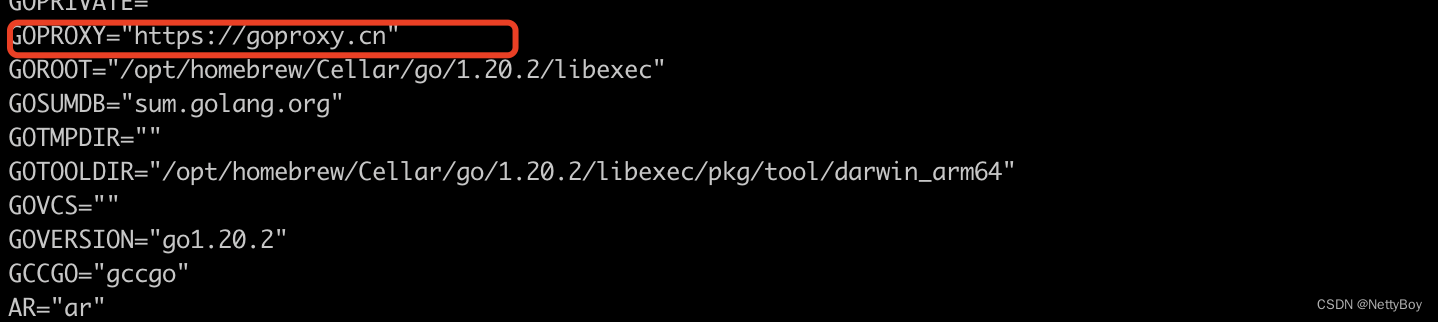
【GO】项目import第三方的依赖包
目录 一、导入第三方包 1.执行命令 2.查看go环境变量参数 3.查看go.mod文件的变化情况 二、程序里如何import 1. import依赖包 2. 程序编写 本次学习go如果依赖第三方的包,并根据第三方的包提供的接口进行编程,这里需要使用go get命令。下面将go…...
【Linux基础IO篇】用户缓冲区、文件系统、以及软硬链接
【Linux基础IO篇】用户缓冲区、文件系统、以及软硬链接 目录 【Linux基础IO篇】用户缓冲区、文件系统、以及软硬链接深入理解用户缓冲区缓冲区刷新问题缓冲区存在的意义 File模拟实现C语言中文件标准库 文件系统认识磁盘对目录的理解 软硬链接软硬链接的删除文件的三个时间 作者…...
电脑软件:推荐一款电脑多屏幕管理工具DisplayFusion
下载https://download.csdn.net/download/mo3408/88514558 一、软件简介 DisplayFusion是一款多屏幕管理工具,它可以让用户更轻松地管理连接到同一台计算机上的多个显示器。 二、软件功能 2.1 多个任务栏 通过在每个显示器上显示任务栏,让您的窗口管理更…...
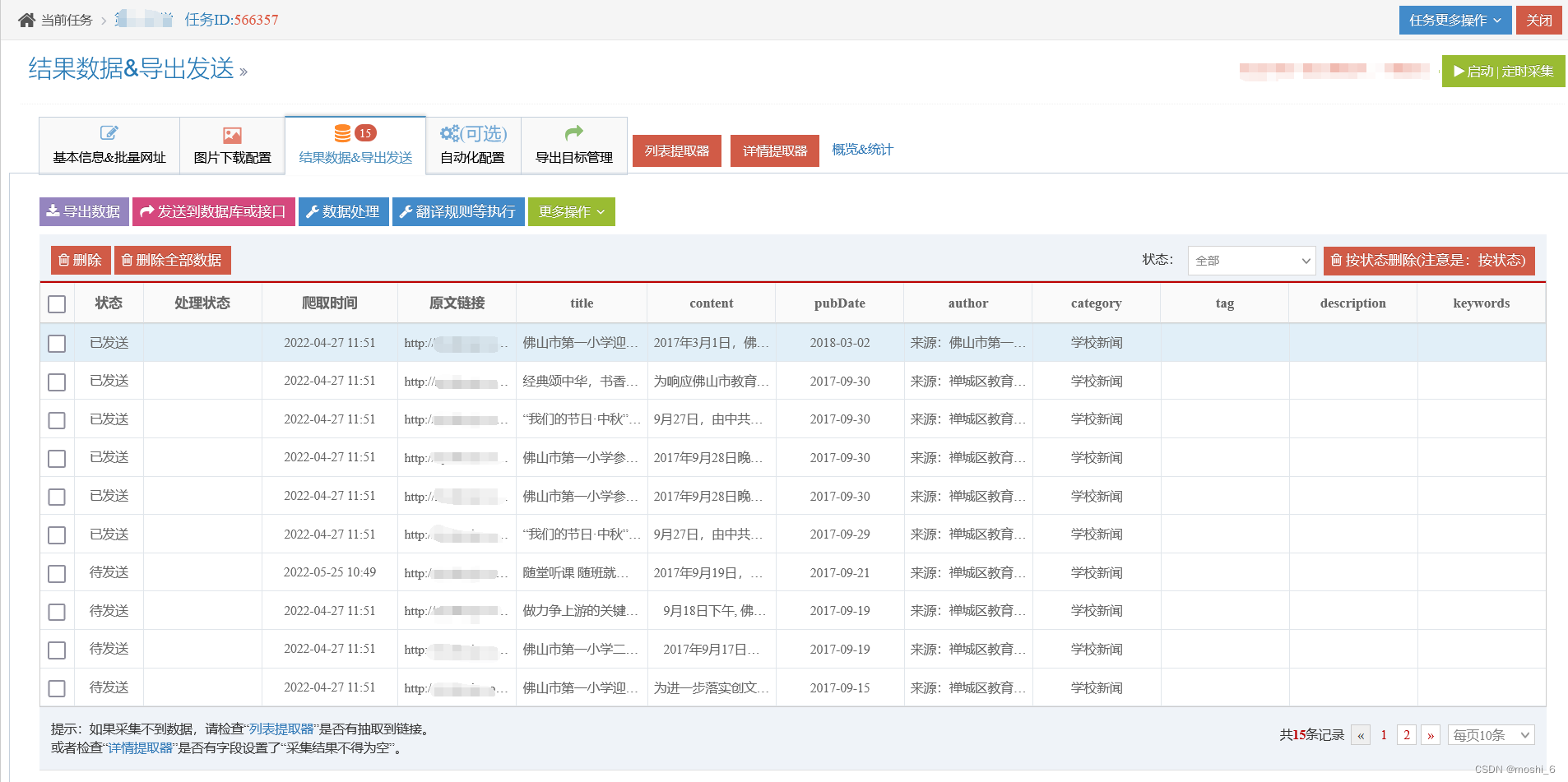
免费好用的网页采集工具软件推荐
在众多各具特色的采集器软件中,真正好用的采集器软件有哪些? 自己一个个去查找和尝试无疑会耗费大量的时间和精力。 因此,在深入体验大多数采集器后,给大家推荐几款优秀且好用的免费网页采集器软件。 本文将对这几款采集器进行…...
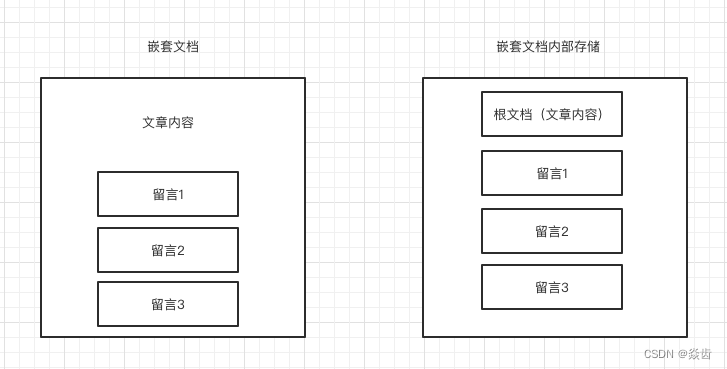
6.ELK之Elasticsearch嵌套(Nested)类型
0、前言 在Elasticsearch实际应用中经常会遇到嵌套文档的情况,而且会有“对象数组彼此独立地进行索引和查询的诉求”。在ES中这种嵌套文档称为父子文档,父子文档“彼此独立地进行查询”至少有以下两种方式: 1)父子文档。在ES的5.…...
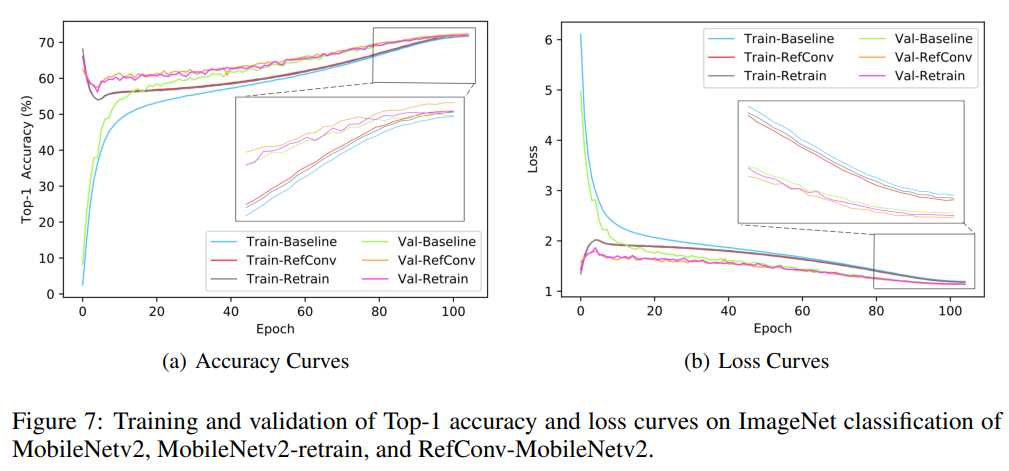
RefConv: 重参数化的重新聚焦卷积(论文翻译)
文章目录 摘要1、简介2、相关研究2.1、用于更好性能的架构设计2.2、结构重参数化2.3、权重重参数化方法 3、重参数化的重聚焦卷积3.1、深度RefConv3.2、普通的RefConv3.3、重聚焦学习 4、实验4.1、在ImageNet上的性能评估4.2、与其他重参数化方法的比较4.3、目标检测和语义分割…...

指令重排序
指令重排序是现代处理器在执行指令时的一种优化技术,其目的是为了提高处理器执行指令的效率。这种优化手段会对指令进行重新排序,以提高并行度和性能。 为何会发生指令重排序: 处理器性能优化: 为了更好地利用现代处理器的流水线、…...

【Head First 设计模式】-- 观察者模式
背景 客户有一个WeatherData对象,负责追踪温度、湿度和气压等数据。现在客户给我们提了个需求,让我们利用WeatherData对象取得数据,并更新三个布告板:目前状况、气象统计和天气预报。 WeatherData对象提供了4个接口: …...

JavaWeb篇_01——JavaEE简介【面试常问】
JavaEE简介 什么是JavaEE JavaEE(Java Enterprise Edition),Java企业版,是一个用于企业级web开发平台,它是一组Specification。最早由Sun公司定制并发布,后由Oracle负责维护。在JavaEE平台规范了在开发企业级web应用…...

QtC++与QRadioButton详解
介绍 QRadioButton 是 Qt 中的一个重要部件,用于创建单选按钮,它有以下几个主要作用和特点: 单选功能: QRadioButton 用于创建单选按钮,用户可以从一组互斥的选项中选择一个。这在用户界面设计中常用于需要用户从多个…...
移远EC600U-CN开发板 day01
1.官方文档快速上手,安装驱动,下载QPYcom QuecPython 快速入门 - QuecPython (quectel.com)https://python.quectel.com/doc/Getting_started/zh/index.html 注意: (1)打开开发板步骤 成功打开之后就可以连接开发板…...

OpenClaw+千问3.5-9B爬虫方案:智能解析与数据入库
OpenClaw千问3.5-9B爬虫方案:智能解析与数据入库 1. 为什么需要智能爬虫 去年我接手了一个市场调研项目,需要从30多个电商平台抓取商品信息和用户评价。传统爬虫开发让我吃尽苦头——每个网站都要单独写解析规则,反爬机制层出不穷ÿ…...

工业冷水机控制程序西门子1200plc含压缩机,电子膨胀阀控制策略,饱和温度计算公式
工业冷水机控制程序西门子1200plc含压缩机,电子膨胀阀控制策略,饱和温度计算公式凌晨三点钟的冷水机组房,设备轰鸣声中闪烁着PLC运行指示灯。手指划过TP1200触摸屏的瞬间,压缩机启动电流曲线在屏幕上划出漂亮的爬坡轨迹——这就是…...

从设计到上线:基于快马平台开发一个具备完整功能的qclaw官网实战指南
从设计到上线:基于快马平台开发一个具备完整功能的qclaw官网实战指南 最近接手了一个qclaw官网的开发需求,需要从零开始构建一个具备完整功能的官方网站。经过调研,我选择了InsCode(快马)平台作为开发环境,因为它不仅提供了完整的…...

插件冲突频发?三招让你的WPS回归清爽
插件冲突频发?三招让你的WPS回归清爽 【免费下载链接】WPS-Zotero An add-on for WPS Writer to integrate with Zotero. 项目地址: https://gitcode.com/gh_mirrors/wp/WPS-Zotero 当你在WPS中处理学术文档时,突然发现工具栏上出现了两个Zotero插…...

Arduino压力变送器信号处理库:模拟传感器线性标定与鲁棒读取
1. 项目概述PressureTransducer 是一个面向嵌入式传感器应用的轻量级 Arduino 库,专为模拟式压力变送器(Analog Pressure Transducer)设计。其核心价值不在于提供复杂驱动或协议栈,而在于将硬件信号链中多级、易出错的手动计算封装…...

硬件电路设计方法论与实战技巧
1. 硬件电路设计系统方法论作为一名从业十年的硬件工程师,我深知从理论到实践的鸿沟有多大。很多新手工程师在掌握了基础电路知识后,面对实际项目时仍然手足无措。硬件设计不是简单的元器件堆砌,而是一个系统工程,需要建立完整的设…...

JTAG接口原理、故障诊断与安全操作指南
1. JTAG接口基础解析作为一名从事FPGA开发多年的工程师,我经常需要与JTAG接口打交道。这个看似简单的四线接口,在实际工作中却经常给我们带来各种"惊喜"。今天我就结合自己踩过的坑,系统地讲讲JTAG那些事儿。JTAG(Joint Test Actio…...

OpenClaw+Phi-3-vision-128k-instruct图文处理实战:本地部署与多模态任务自动化
OpenClawPhi-3-vision-128k-instruct图文处理实战:本地部署与多模态任务自动化 1. 为什么选择这个技术组合? 去年我开始尝试用AI处理日常工作中的图文混合内容时,遇到了一个典型困境:现有的云端多模态服务要么价格昂贵ÿ…...
)
告别截图贴图!用MATLAB的text函数+LaTeX,在图像任意位置添加公式注释(含α, β, ∑等符号)
科研图像标注革命:MATLABLaTeX实现动态公式嵌入全攻略 在学术论文与科研报告中,数据可视化图表的质量直接影响研究成果的呈现效果。传统方式中,研究者往往需要先导出图像,再通过第三方软件(如Photoshop或PPT࿰…...

Vue3项目实战:CKEditor5自定义构建与插件深度集成指南
1. 为什么需要自定义CKEditor5构建 第一次在Vue3项目中使用CKEditor5时,我直接安装了官方提供的经典编辑器包(ckeditor/ckeditor5-build-classic)。但很快就发现一个问题:默认构建缺少很多常用功能。比如字体颜色、背景色、对齐方…...