在Java中操作Redis
Redis中如何的去存放一个Java对象?
- 直接存放Json类型即可,因为我们Json类型最终就是一个String类型。
Redis的Java客户端
Redis的常用命令是我们操作Redis的基础,那么我们在Java程序当中如何来操作Redis呢?
- 要想基于Java语言来操作Redis数据库,这就需要使用到Redis的Java客户端,就如同我们使用JDBC操作MySQL数据库一样。
Redis的Java客户端很多,常用的几种:
- Jedis
- Lettuce
- Spring Data Redis
像Jedis和Lettuce其实相对来说是比较底层的或者说比较原始的方式来操作,而Spring Data Redis它是Spirng家族的一个框架,对Redis底层的这两个开发包进行了高度的封装,在Spring项目当中,可以使用Spring Data Redis来简化操作。
Spring对Redis客户端进行了整合,提供了Spring Data Redis,在Spring Boot项目当中还提供了对应的 Starter,即spring-boot-starter-data-redis。
Spring Data框架:
- Spring Data框架它里面就封装了操作各种各样数据库的技术!

Spring Data Redis环境准备及介绍
网址:https://spring.io/projects/spring-data-redis
介绍
- Spring Data Redis是Spring的一部分,提供了在Spring应用中通过简单的配置就可以访问Redis服务,对Redis底层开发包进行了高度封装,在Spring项目中,可以使用Spring Data Redis来简化Redis操作。
Spring Data Redis的使用方式:Spring Boot整合Redis
操作步骤:
- 创建SpringBoot工程,勾选起步依赖:Lombok + Spring Web(Web开发的起步依赖) + Spring Data Redis(Acess+Driver) => 在NoSQL里面勾选
- 在application.yml中配置Redis的连接信息
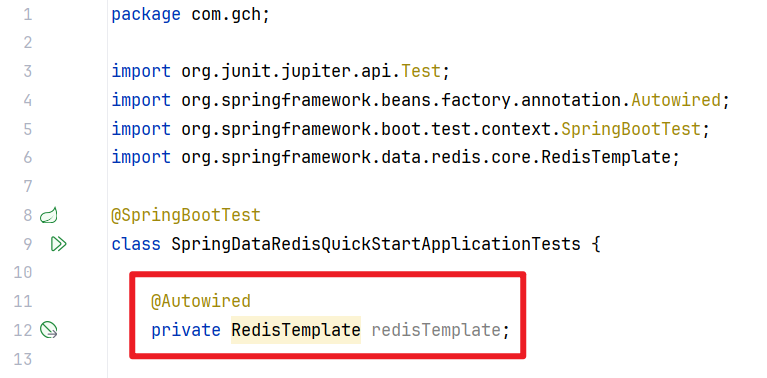
- 在单元测试中,直接注入RedisTemplate对象
- 通过RedisTemplate对象操作Redis
- 因为在Spring Data Redis当中,它就给我们提供了一个操作Redis的一个模版对象:RedisTemplate,RedisTemplate为执行各种Redis操作、异常转换和序列化支持提供了高级抽象!Template - 模版
1. Spring Boot提供了对应的Starter,Maven坐标:引入spring-boot-starter-data-redis依赖
<!-- Redis的起步依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>2. 在application.yml中配置Redis的连接信息:配置Redis数据源
# 配置Redis的连接信息
spring:data:redis:host: 127.0.0.1port: 6379password: 123456database: 0- database:指定使用Redis的哪个数据库,Redis服务启动后默认有16个数据库,编号分别是从0到15,可以通过修改Redis的配置文件来指定数据库的数量。
lettuce是Java用来操作Redis的一个Jar包!
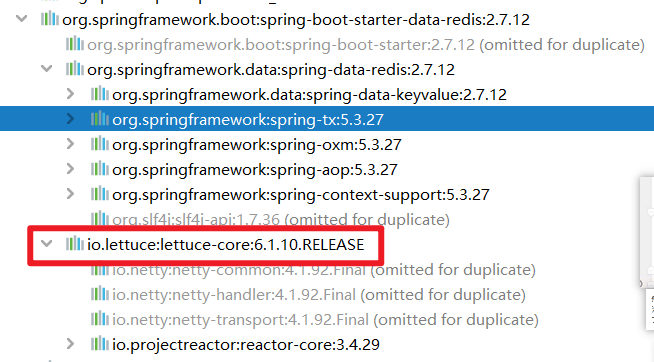 3. 在单元测试类当中注入RedisTemplate
3. 在单元测试类当中注入RedisTemplate
为什么可以直接注入呢?
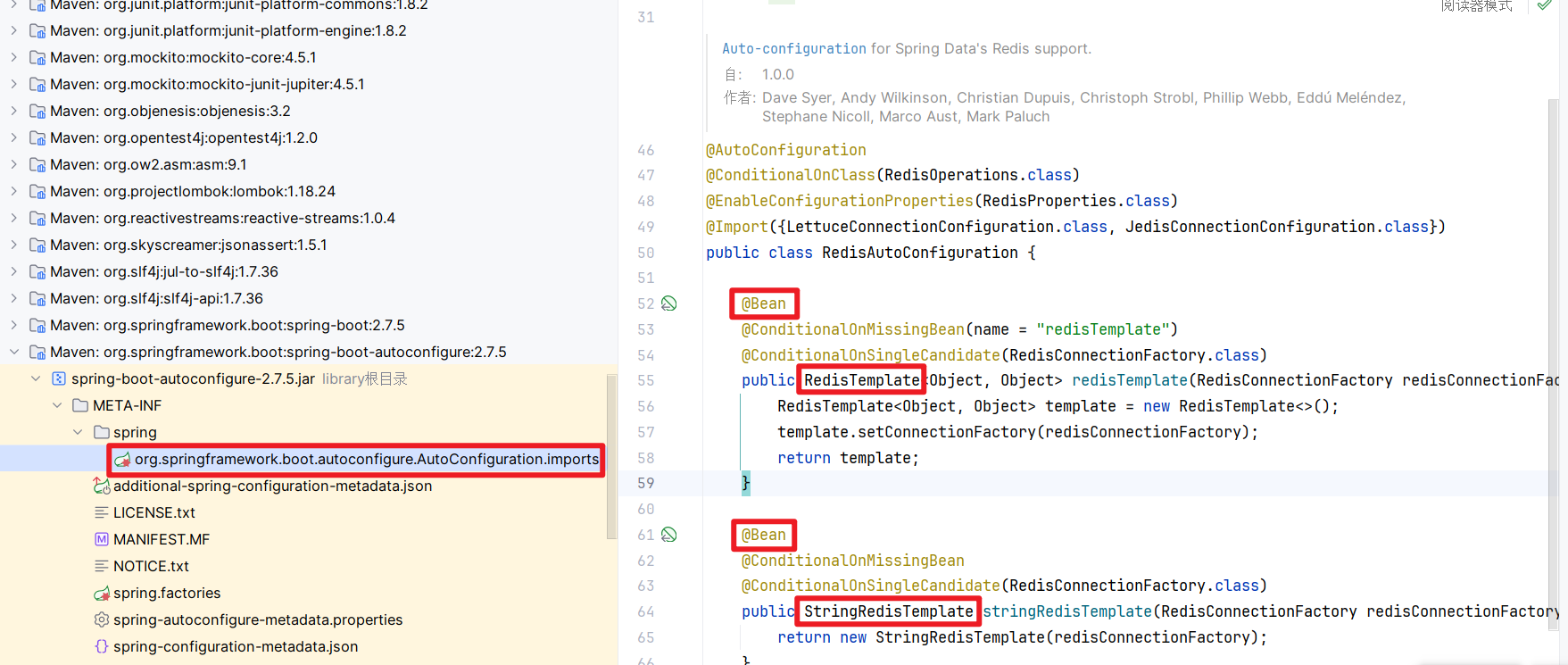
- 因为引入了Redis的起步依赖,所以Spring Boot框架会自动装配RedisTemplate对象!
- RedisAutoConfiguration:RedisTemplate的自动配置类 => SpringBoot自动装配的原理
- 底层还会再声明一个Bean:StringRedisTemplate,它继承了RedisTemplate,并且限制了泛型为<String,String>!
Spring Data Redis中提供了一个高度封装的类:RedisTemplate,RedisTemplate针对大量相关的API进行了归类封装,将同一数据类型的操作封装为对应的Operation接口,具体分类如下:
-
ValueOperations:String数据操作
-
SetOperations:Set类型数据操作
-
ZSetOperations:ZSet类型数据操作
-
HashOperations:Hash类型的数据操作
-
ListOperations:List类型的数据操作

package com.gch;import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;import java.util.concurrent.TimeUnit;@SpringBootTest
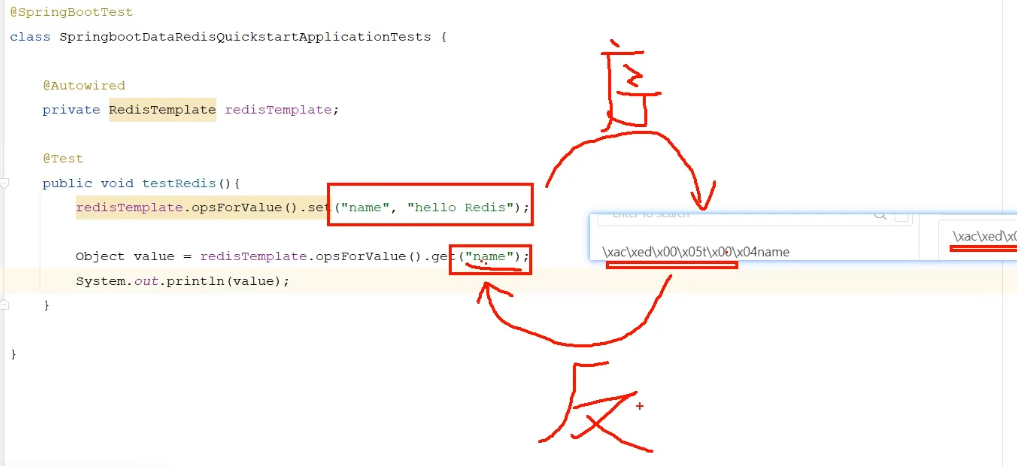
class SpringDataRedisQuickStartApplicationTests {// 注入RedisTemplate对象@Autowiredprivate RedisTemplate redisTemplate;/*** 往Redis当中写入String类型的数据并设置过期时间* @param key* @param value* @param timeout Key的过期时间* @return 返回写入的Value*/public Object setString(String key, Object value, Long timeout) {// 往Redis当中写入String类型的数据redisTemplate.opsForValue().set(key, value);// 如果时限不为nullif (timeout != null) {/*** 则对该Key设置有效期 / 过期时间* 补充:在Redis里面默认是会开启这个持久化机制的,相当于每个数据都会持久化到硬盘里面去的* 每次把Redis当成数据库用:对Key不设置有效期,每次查询都会把它放在Redis里面(内存)* 如果对Key不设置有效期,它就会一直存储在内存里面,而内存又是非常有限的,最终有一天会把内存撑爆* 直接就导致Redis服务崩了,所以,注意事项:对我们的Redis的Key一定要去设置一个有效期*/redisTemplate.expire(key, timeout, TimeUnit.SECONDS);}// 获取写入的Value并返回return redisTemplate.opsForValue().get(key);}@Testpublic void testRedis() {// 查找返回所有的Key,返回值是一个Set集合System.out.println(redisTemplate.keys("*"));// 往Redis当中写入String类型的数据System.out.println("name = " + setString("name", "Redis", 1000L));}
}
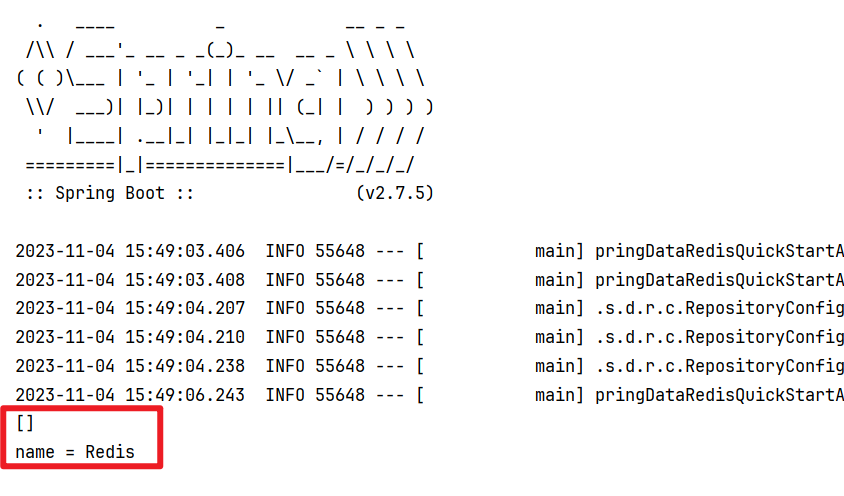
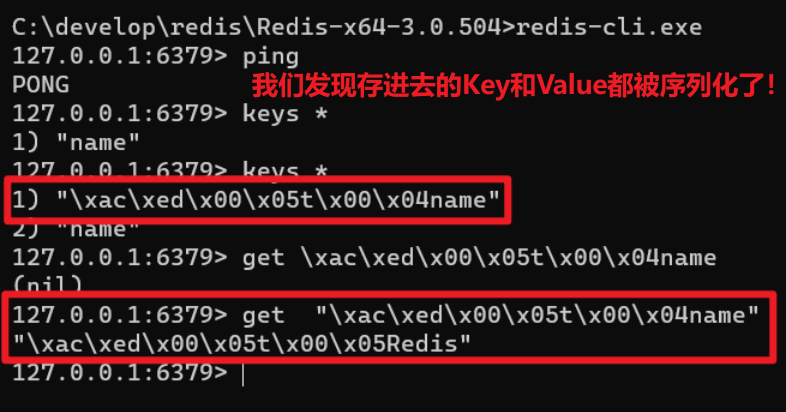
- 我们会发现我们存到Redis中的数据和原始数据有差别,这是为什么呢?
我们来看以下RedisTemplate的源码:


- 通过上面源码我们发现,Spring Boot框架会自动装配RedisTemplate对象,但是默认的Key和Value的序列化器为JdkSerializationRedisSerializer,默认是采用JDK序列化器,虽然说RedisTemplate可以接收任意Object作为值写入到Redis,但是写入前会把Object序列化为字节形式,从而导致我们存到Redis中的数据和原始数据有差别,因为我们要进行设置,我们可以自己定义声明了一个名为redisTemplate的Bean,自己来手动定义序列化方式,从而让源码中的RedisTemplate不声明,以此来覆盖掉源码当中的Bean。
JDK序列化器的缺点:
- 可读性差
- 内存占用较大,但是JDK的序列化方式效率要高一些
SpringDataRedis - 序列化方式配置
package com.gch.config;import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;/*** 声明当前类是一个配置类* @Configuration里面封装了@Component,@Service里面封装的也是@Component*/
@Slf4j
@Configuration
public class RedisConfig {/*** 自定义RedisTemplate* @param redisConnectionFactory* @return*/@Beanpublic RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {log.info("开始创建Redis模板对象....");RedisTemplate<Object, Object> template = new RedisTemplate<>();// 设置redis的连接工厂对象template.setConnectionFactory(redisConnectionFactory);/*** 设置redis key的序列化器* 指定大Key以及Hash中的小Key的序列化方式* 建议只去设置Key的序列化范式,因为Value的形式多种多样,因为不同类型的数据它的序列化方式是不一样的* 等价于template.setKeySerializer(RedisSerializer.string()); => 按照字符串的方式来序列化*/template.setKeySerializer(new StringRedisSerializer()); // 设置Key的序列化方式template.setHashKeySerializer(new StringRedisSerializer()); // 设置Hash Key的序列化方式return template;}
}
 操作常见类型数据
操作常见类型数据
1. 操作String字符串类型数据
/*** 操作String字符串类型的数据*/@Testvoid testString() {// 存数据,并设置过期时间redisTemplate.opsForValue().set("name","Jerry",300L,TimeUnit.SECONDS);// 取数据,并打印输出Object name = redisTemplate.opsForValue().get("name");System.out.println("name = " + name);// 当该数据不存在时才写入/存数据(setnx),Absent:不存在,该方法返回值类型为Boolean,返回true代表执行成功(成功写入)Boolean result = redisTemplate.opsForValue().setIfAbsent("count","528",528L,TimeUnit.SECONDS);System.out.println(result == true ? "写入成功,count = " + redisTemplate.opsForValue().get("count") : "该数据存在,无法写入");}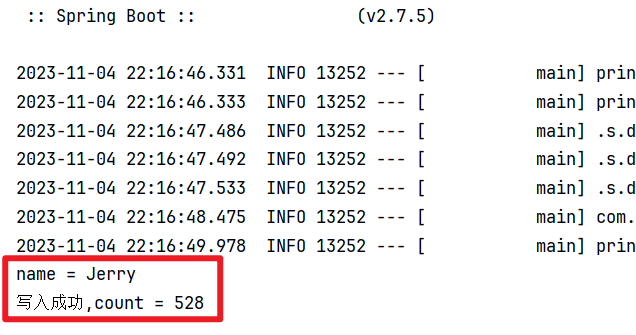
2. 操作List列表类型数据
/*** 操作List列表类型的数据:lpush,lpop,rpush,rpop*/@Testvoid testList() {// lpushredisTemplate.opsForList().leftPushAll("list01","A","B","C","D","E","F");// 获取List列表中元素的个数Long list01Size = redisTemplate.opsForList().size("list01");System.out.println("list01列表中元素的个数为:" + list01Size);// range-获取List list01 = redisTemplate.opsForList().range("list01",0L,-1L);System.out.println("lpush后list01列表中出元素的顺序为:" + list01);// lpop-leftPop(K key):删除并返回存储在Key列表中的第一个元素Object firstObj = redisTemplate.opsForList().leftPop("list01");System.out.println("存储在list01列表中的第一个元素为:" + firstObj);System.out.println("-------------------分割线条--------------------");// rpushredisTemplate.opsForList().rightPushAll("list02","A","B","C","D","E","F");// 获取List列表中元素的个数Long list02Size = redisTemplate.opsForList().size("list02");System.out.println("list02列表中元素的个数为:" + list02Size);// range-获取List list02 = redisTemplate.opsForList().range("list02",0L,-1L);System.out.println("rpush后list02列表中取出元素的顺序为:" + list02);// rpop-rightPop(K key):删除并返回存储在Key列表中的最后一个元素Object lastObj = redisTemplate.opsForList().rightPop("list02");System.out.println("存储在list02列表中的最后一个元素为:" + lastObj);}
3. 操作Set集合类型数据
/*** 操作Set集合类型的元素:sadd,smembers,scard*/@Testvoid testSet() {// saddredisTemplate.opsForSet().add("set01","A","B","C","D","E","F","A","B","C");// sizeLong set01Size = redisTemplate.opsForSet().size("set01");System.out.println("set01集合中元素的个数为:" + set01Size);// smembersSet<Object> set01 = redisTemplate.opsForSet().members("set01");System.out.println("set01集合中元素的顺序为:" + set01);System.out.println("-----------分割线-----------");// saddredisTemplate.opsForSet().add("set02","C","D","E","G","H","I");// sizeLong set02Size = redisTemplate.opsForSet().size("set02");System.out.println("set02集合中元素的个数为:" + set02Size);// smembersSet<Object> set02 = redisTemplate.opsForSet().members("set02");System.out.println("set02集合中元素的顺序为:" + set02);// sinter:获取两个集合的交集 union:求并集 diff:求差集Set<Object> sinterSet = redisTemplate.opsForSet().intersect("set01","set02");System.out.println("set01集合与set02集合的交集为:" + sinterSet);}
4. 操作Hash哈希类型数据
/*** 操作Hash类型的数据:hset,hget,hmset,hmget,hkeys,hvals*/@Testvoid testHash() {// hset = put()redisTemplate.opsForHash().put("tb_user","name","Rose");// hmset:批量操作 - putAll()Map<String,Object> map = new HashMap<>();map.put("age","6");map.put("year","2008");redisTemplate.opsForHash().putAll("tb_user",map);// hgetObject value = redisTemplate.opsForHash().get("tb_user","year");System.out.println("year = " + value);// hmget:取多个Field的值List<Object> valueList = redisTemplate.opsForHash().multiGet("tb_user", Arrays.asList("name","age","year"));System.out.println(valueList);// hkeys Key:获取指定哈希键所有的FieldSet<Object> allField = redisTemplate.opsForHash().keys("tb_user");System.out.println("哈希表中所有的Field为:" + allField);// hvals Key:获取哈希表中所有的ValueList allValue = redisTemplate.opsForHash().values("tb_user");System.out.println("哈希表中所有的Value为:" + allValue);// hgetall key:获取所有的Field和Value entries()Map<String,Object> all = redisTemplate.opsForHash().entries("tb_user");System.out.println("哈希表中所有的Field和Value为:" + all);}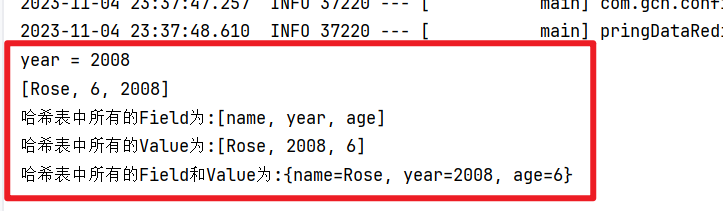 5. 操作ZSet有序集合类型数据
5. 操作ZSet有序集合类型数据
/*** ZSet有序集合类型数据的操作*/@Testvoid testZSet() {// zaddredisTemplate.opsForZSet().add("ZSetType","Java",80);redisTemplate.opsForZSet().add("ZSetType","Web",75);redisTemplate.opsForZSet().add("ZSetType","Go",90);redisTemplate.opsForZSet().add("ZSetType","Python",85);redisTemplate.opsForZSet().add("ZSetType","Rust",98);// 按分数从小到大,升序排序 => zrangeSet<Object> range = redisTemplate.opsForZSet().range("ZSetType",0,-1);System.out.println("编程语言按分数从小到大,升序排序为:" + range);// 按分数从大到小,降序排序 => zreverangeSet<Object> reverseRange = redisTemplate.opsForZSet().reverseRange("ZSetType",0,-1);System.out.println("编程语言按分数从大到小,降序排序为:" + reverseRange);// rangeByScore(key,min,max) 获取按照指定分数区间的Value并按照从小到大,升序排序,返回值类型为Set// reverseRangeByScore(key,min,max) 获取指定分数区间的Value并按照从大到小,降序顺序,返回值类型为Set}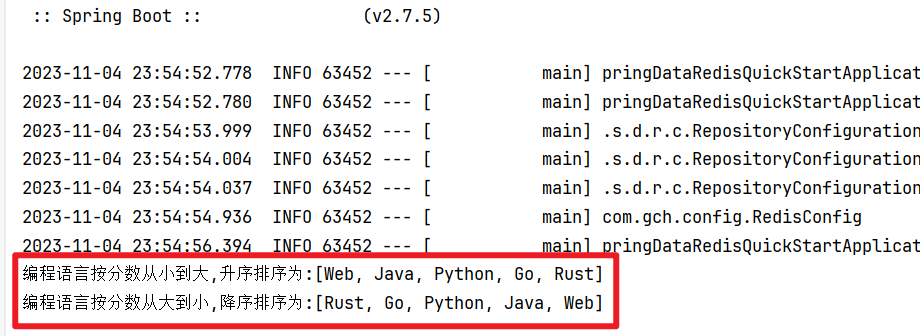 通用命令操作
通用命令操作
/*** 通用命令的操作* 补充:要使用同一格式来进行序列化与反序列化*/@Testvoid testCommon() {// 1. 获取所有的KeySet<Object> allKeys = redisTemplate.keys("*");System.out.println("所有的Key为:" + allKeys);// 2. 删除KeyBoolean result = redisTemplate.delete("key");System.out.println(result == true ? "删除成功" : "删除失败");}
在项目当中的真实应用是要保存对象:使用Redis的二进制形式存放对象(序列化)
方案1:在Redis当中存放一个对象,使用JSON序列化与反序列化(太Low了~!)

方案2:直接使用Redis自带的序列化方式存储对象~!
- 注意:保存在Redis当中的数据是要被序列化的(存放二进制的时候必须要把对象序列化的),因此一个对象要想能够成功的保存到Redis当中,那么该对象所归属的类就必须要实现一个接口:Serializable序列化接口,否则直接存放运行后程序会报错!
- 因此,在后续的项目当中,所有的实体类都要实现Serializable序列化接口!
- 注意:需要序列化的对象一定要实现Serializable序列化接口!
package com.gch.pojo;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;import java.io.Serializable;@Data
@AllArgsConstructor
@NoArgsConstructor
/*** 该实体类想要存放到Redis当中,就必须被序列化,因此要实现Serializable接口*/
public class User implements Serializable {private String name;private Integer age;
}
/*** 保存对象:保存在Redis当中的数据是要被序列化的*/@Testvoid testObject() {// 保存对象redisTemplate.opsForValue().set("tb_user",new User("Jerry",6));// 获取对象Object obj = redisTemplate.opsForValue().get("tb_user");System.out.println("保存的对象数据为:" + obj.toString());}

相关文章:
在Java中操作Redis
Redis中如何的去存放一个Java对象? 直接存放Json类型即可,因为我们Json类型最终就是一个String类型。 Redis的Java客户端 Redis的常用命令是我们操作Redis的基础,那么我们在Java程序当中如何来操作Redis呢? 要想基于Java语言…...

【服务器】fiber协程模块
fiber协程模块 以下是从sylar服务器中学的,对其的复习; sylar的fiber协程模块是基于ucontext_t实现非对称协程 函数只有两个行为:调用与返回。一旦函数返回后,它在栈上所拥有的状态将被销毁。协程相比函数多了两个动作…...

SparkML
SparkML SparkML_lr_train :读取py处理后的train表用于训练,将训练模型保存好。 SparkML_lr_predict :读取训练好的模型,读取py处理后的test表用于预测。将预测结果写入normal_data中,根据id修改stream_is_normal的值。…...

实时定位与路径优化:跑腿App系统开发中的地理信息技术
本文将介绍如何使用地理信息技术实现实时定位和路径优化功能,以提高跑腿服务的效率。 实时定位 用户位置获取 # 示例:获取用户的实时位置 def get_user_location(user_id):# 使用GPS或网络定位技术获取用户的地理坐标# 返回经度和纬度信息return lon…...

Tomcat的HTTP Connector
https://tomcat.apache.org/tomcat-10.1-doc/config/http.html 一个Connector代表一个接收请求、返回响应的端点(endpoint)。 HTTP Connector 元素代表一个支持HTTP/1.1的Connector组件。一个这样的组件在服务端一个指定的TCP端口上监听连接。一个Serv…...

将Pytorch搭建的ViT模型转为onnx模型
本文尝试将pytorch搭建的ViT模型转为onnx模型。 首先将博主上一篇文章中搭建的模型ViT Vision Transformer超详细解析,网络构建,可视化,数据预处理,全流程实例教程-CSDN博客转存为.pth torch.save(model, my_vit_model.pth) 然…...
图神经网络(GNN)性能优化方案汇总,附37个配套算法模型和代码
图神经网络的表达能力对其性能和应用范围有着重要的影响,是GNN研究的核心问题和发展方向。增强表达能力是扩展GNN应用范围、提高性能的关键所在。 目前GNN的表达能力受特征表示和拓扑结构这两个因素的影响,其中GNN在学习和保持图拓扑方面的缺陷是限制表…...
)
国科大移动互联网考试资料(2023+2020+2018真题+答案)
老师王文杰。真题附加2022部分...

ModStart系统安全规范建议
1 不要使用弱密码 很多人为了系统管理方便(或者是懒),经常会设置类似 123456、admin 这样的管理密码,这样的密码很容易被暴力软件扫描出来。 2 不要使用默认配置 默认的软件系统设置、默认的系统端口、默认的网站设置在发生漏洞…...
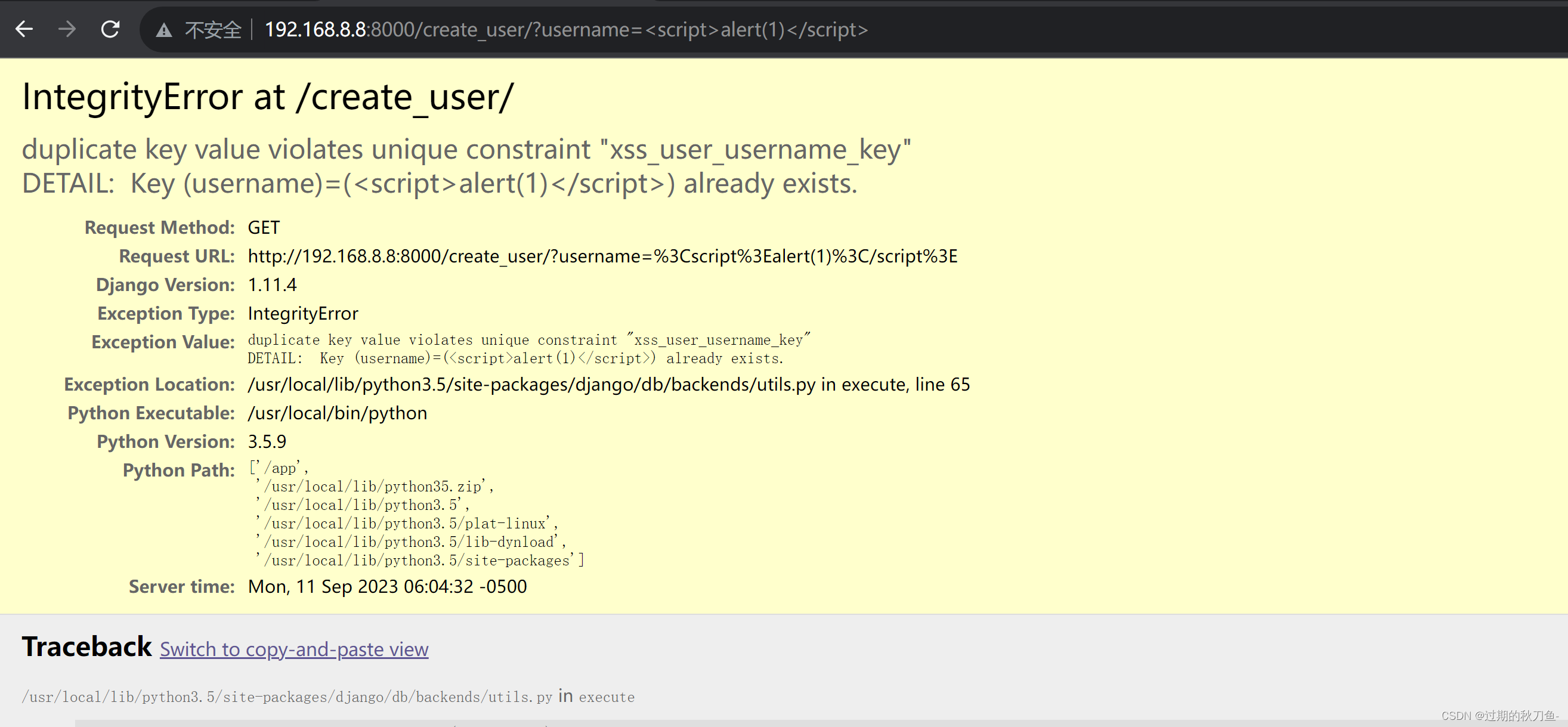
【漏洞复现】Django_debug page_XSS漏洞(CVE-2017-12794)
感谢互联网提供分享知识与智慧,在法治的社会里,请遵守有关法律法规 文章目录 1.1、漏洞描述1.2、漏洞等级1.3、影响版本1.4、漏洞复现1、基础环境2、漏洞分析3、漏洞验证 说明内容漏洞编号CVE-2017-12794漏洞名称Django_debug page_XSS漏洞漏洞评级影响范…...

Redis性能调优:深度剖析与示例解析
标题:Redis性能调优:深度剖析与示例解析 引言 Redis是一款强大的开源内存数据库,广泛应用于高性能系统。然而,为了充分发挥Redis的性能,需要进行合理的性能调优。本博客将深入介绍Redis性能调优的策略和示例…...

oracle查询前几条数据的方法
在Oralce中实现select top N:由于Oracle不支持select top 语句,所以在oracle中经常是用order by 跟rownum的组合来实现select top n的查询。 方法1: SELECT * FROM (SELECT * FROM EMP ORDER BY SAL DESC) WHERE ROWNUM < 5 --抽取处记录…...

c#弹性和瞬态故障处理库Polly
1. 重试(Retry) Policy .Handle<Exception>() //指定需要重试的异常类型 .Retry(2,(ex,count,context)> { //指定发生异常重试的次数Console.WriteLine($ "重试次数{count},异常{ex.Message}" ); }) …...

20231107-前端学习炫酷菜单效果和折叠侧边栏
炫酷菜单效果 代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>炫酷菜单效果</title><…...
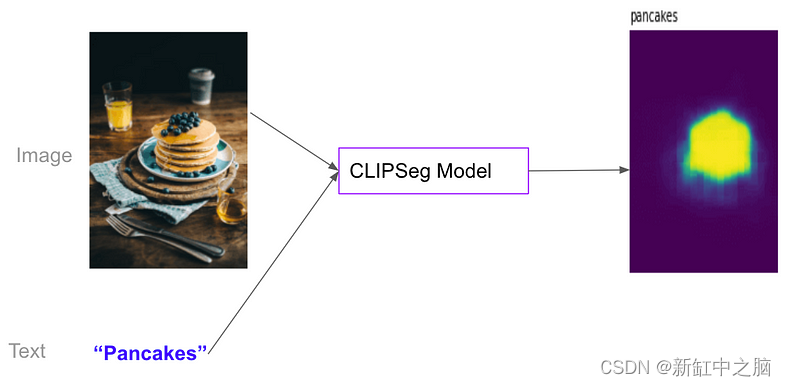
基于CLIP的图像分类、语义分割和目标检测
OpenAI CLIP模型是一个创造性的突破; 它以与文本相同的方式处理图像。 令人惊讶的是,如果进行大规模训练,效果非常好。 在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 3D…...
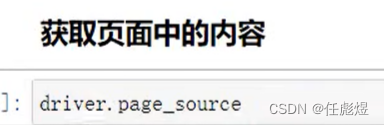
python爬虫(数据获取——selenium)
环境测试 from selenium import webdriverchromedriver_path r"C:\Program Files\Google\Chrome\Application\chromedriver.exe" driver webdriver.Chrome()url "https://www.xinpianchang.com/discover/article?fromnavigator" driver.get(url)drive…...

[wp]NewStarCTF 2023 WEEK5|WEB
前言:比赛是结束了,但我的学习还未结束,看看自己能复习几道题吧,第四周实在太难 Final 考点: ThinkPHP 5.0.23 RCE一句话木马上传SUID提权(find) 解题: 首先页面就给了ThinkPHP V5, 那无非考…...

未将对象引用设置到对象实例
环境 vs 2017 qt 5.13.0 qt-vs-addin 2.10 qt 项目打开的vs 2010 的项目 配置完成之后可以编译执行,但是新建qt 类提示 未将对象引用设置到对象实例 问题 插件的版本太高了使用低版本的,到qt 官网下载Index of /official_releases/vsaddin 下载q…...
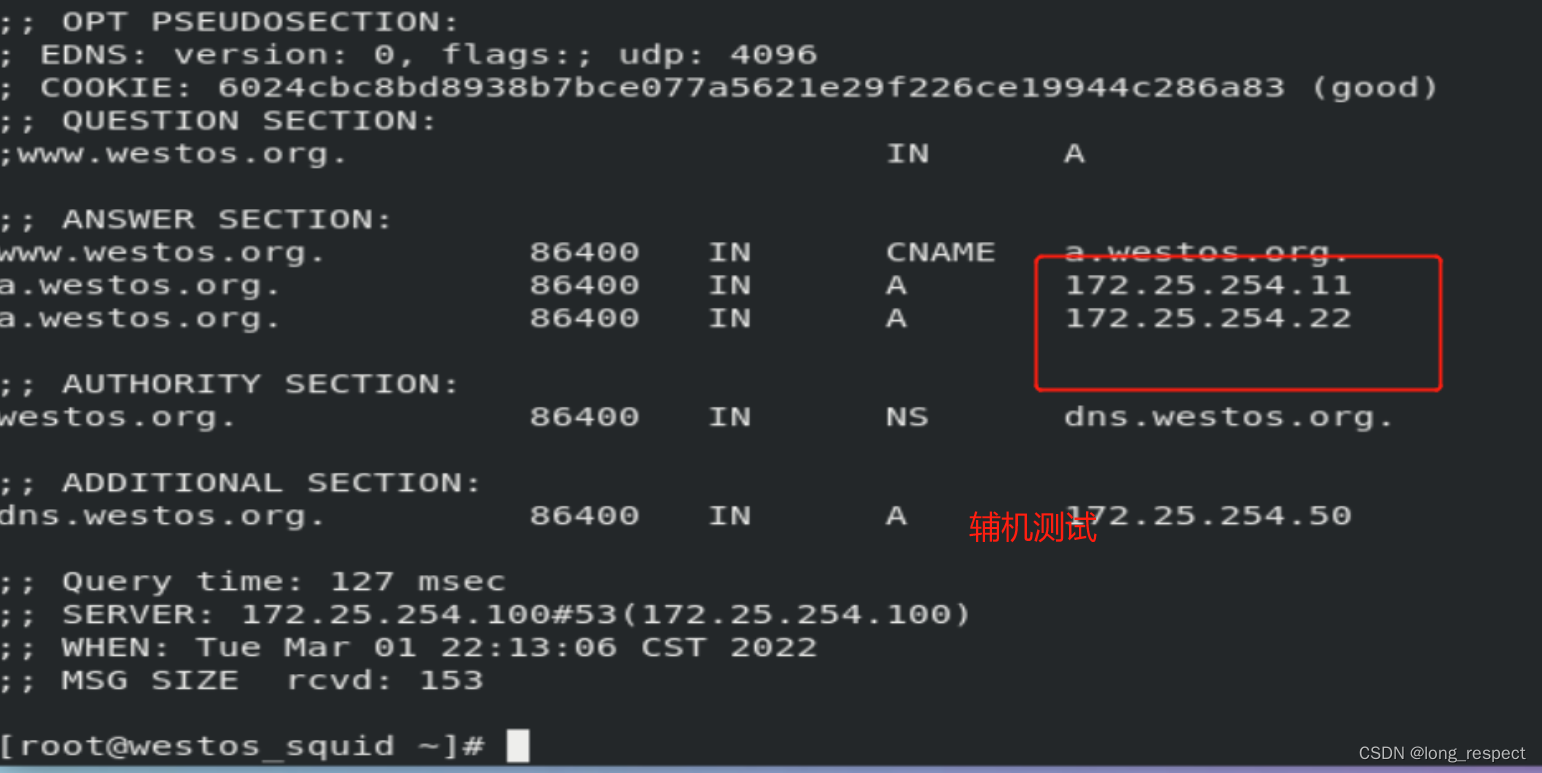
网络的地址簿:Linux DNS服务的全面指南
1 dns 1.1 dns(域名解析服务)介绍 当访问 www.baidu.com 首先查询/etc/hosts,如果没有再去查询/etc/resolv.conf,还是没有就去查询域名服务器 关于客户端: /etc/resolv.conf ##dns指向文件 nameserver 172.25.254.20测试&…...

输电线路AR可视化巡检降低作业风险
随着现代工业的快速发展,各行业的一线技术工人要处理的问题越来越复杂,一些工作中棘手的问题迫切需要远端专家的协同处理。但远端专家赶来现场往往面临着专家差旅成本高、设备停机损失大、专业支持滞后、突发故障无法立即解决等痛点。传统的远程协助似乎…...

Seelen-UI终极指南:5分钟打造你的专属Windows桌面环境
Seelen-UI终极指南:5分钟打造你的专属Windows桌面环境 【免费下载链接】Seelen-UI The Fully Customizable Desktop Environment for Windows 10/11. 项目地址: https://gitcode.com/GitHub_Trending/se/Seelen-UI 想要彻底改造Windows 10/11的桌面体验吗&am…...

PrismML发布1比特模型:突破大模型运行困境,提升智能密度
【导语:大型模型在智能手机和数据中心运行面临难题,PrismML构建超密集智能解决方案,推出1比特Bonsai系列模型,内存占用、速度、能耗等方面表现出色,重塑模型设计方式。】超密集智能:解决大模型运行难题大型…...

PaddleNLP:面向产业级应用的大语言模型全流程开发套件技术深度解析
PaddleNLP:面向产业级应用的大语言模型全流程开发套件技术深度解析 【免费下载链接】PaddleNLP PaddleNLP是一款基于飞桨深度学习框架的大语言模型(LLM)开发套件,支持在多种硬件上进行高效的大模型训练、无损压缩以及高性能推理。PaddleNLP 具备简单易用…...

MySQL--Day02
约束 约束是作用于表中字段上的规则,用于限制存储在表中的数据 为了保证数据库中数据的正确性、有效性、完整性非空约束 NOT NULL唯一约束 UNIQUE主键约束 PRIMARY KEY默认约束 DEFAULT检查约束 CHECK CREATE TABLE user(id int primary key auto_increm…...

Windows 11硬件限制突破与系统升级完全指南
Windows 11硬件限制突破与系统升级完全指南 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat 当你的电脑因TPM 2.0或CPU世…...

春联生成模型快速上手:输入‘幸福‘、‘平安‘等关键词,自动生成对仗工联
春联生成模型快速上手:输入幸福、平安等关键词,自动生成对仗工联 1. 春联生成器简介 春节贴春联是中国人延续千年的传统习俗,但创作一副对仗工整、寓意吉祥的春联并不容易。现在,借助AI技术,任何人都能轻松生成专业水…...

intv_ai_mk11保姆级教程:解决页面打开但生成慢、服务启动失败等6类问题
intv_ai_mk11保姆级教程:解决页面打开但生成慢、服务启动失败等6类问题 1. 快速了解intv_ai_mk11 intv_ai_mk11是一个基于Llama架构的中等规模文本生成模型,特别适合处理通用问答、文本改写、解释说明和简短创作等任务。这个镜像已经完成了本地部署&am…...

如何高效保存B站视频?BiliTools全能下载解决方案让你无忧离线观看
如何高效保存B站视频?BiliTools全能下载解决方案让你无忧离线观看 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliT…...

手把手教你用Cline插件零成本调用AI Ping的GLM-4.7,5分钟搞定一个React组件
5分钟实战:用Cline插件调用GLM-4.7生成React表单组件 最近在帮团队优化一个后台管理系统时,发现表单页面的重复开发消耗了大量时间。直到同事推荐了AI Ping的GLM-4.7模型配合VSCode的Cline插件,才真正体会到AI辅助编程的"开箱即用"…...

AI图像增强:让模糊照片重获新生的实用工具
AI图像增强:让模糊照片重获新生的实用工具 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 在数字时代,我们每个人的手机相册里都藏着珍贵的回忆—…...