pandas教程:Reading and Writing Data in Text Format (以文本格式读取和写入数据)
文章目录
- Chapter 6 Data Loading, Storage, and File Formats(数据加载,存储,文件格式)
- 6.1 Reading and Writing Data in Text Format (以文本格式读取和写入数据)
- 1 Reading Text Files in Pieces(读取一部分文本)
- 2 Writing Data to Text Format (写入数据到文本格式)
- 3 Working with Delimited Formats
- 4 JSON Data
- 5 XML and HTML: Web Scraping (网络爬取)
- Parsing XML with lxml.objectify
Chapter 6 Data Loading, Storage, and File Formats(数据加载,存储,文件格式)
input和output大多可以分为几类:读取文本文件或其他一些存储在磁盘上的格式,从数据库加载数据,利用web API来获取网络资源。
6.1 Reading and Writing Data in Text Format (以文本格式读取和写入数据)
pandas有很多用来读取表格式数据作为dataframe的函数,下面列出来一些。其中read_csv和read_tabel是最经常用到的:
这里我们给出这些函数的大致功能,就是把test data变为dataframe。这些函数的一些可选参数有以下几类:
-
Indexing(索引)能把返回的一列或多列作为一个
dataframe。另外也可以选择从文件中获取列名或完全不获取列名 -
Type inference and data conversion(类型推测和数据转换)这个包括用户自己定义的转换类型和缺失值转换
-
Datetime parsing(日期解析)包含整合能力,可以把多列中的时间信息整合为一列
-
Iterating(迭代)支持对比较大的文件进行迭代
-
Unclean data issues(未清洗的数据问题)跳过行或柱脚,评论,或其他一些小东西,比如csv中的逗号
因为现实中的数据非常messy(杂乱),所以有一些数据加载函数(特别是read_csv)的轩轩也变得越来越多。对于众多参数感觉不知所措是正常的(read_csv有超过50个参数)。具体的可以去看pandas官网给出的例子。
一些函数,比如pandas.read_csv实现type inference,因为column data type不是数据类型的一种。这意味着我们没有必要指定哪些columns是数值,哪些是整数,哪些是字符串。其他一些数据格式,比如HDF5,数据类型是在格式里的。
先来一个CSV文件热热身(CSV文件指的是用逗号隔开数据的文件):
!cat ../examples/ex1.csv
a,b,c,d,message
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
cat是unix下的一个shell command。如果是用windows,用type代替cat
import pandas as pd
df = pd.read_csv('../examples/ex1.csv')
df
| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
我们也可以用read_table来指定分隔符:
pd.read_table('../examples/ex1.csv', sep=',')
| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
一个文件不会总是有header row(页首行),考虑下面的文件:
!cat ../examples/ex2.csv
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
读取这样的文件,设定column name:
pd.read_csv('../examples/ex2.csv', header=None)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
pd.read_csv('../examples/ex2.csv', names=['a', 'b', 'c', 'd', 'message'])
| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
如果想要从多列从构建一个hierarchical index(阶层型索引),传入一个包含列名的list:
!cat ../examples/csv_mindex.csv
key1,key2,value1,value2
one,a,1,2
one,b,3,4
one,c,5,6
one,d,7,8
two,a,9,10
two,b,11,12
two,c,13,14
two,d,15,16
parsed = pd.read_csv('../examples/csv_mindex.csv',index_col=['key1', 'key2'])
parsed
| value1 | value2 | ||
|---|---|---|---|
| key1 | key2 | ||
| one | a | 1 | 2 |
| b | 3 | 4 | |
| c | 5 | 6 | |
| d | 7 | 8 | |
| two | a | 9 | 10 |
| b | 11 | 12 | |
| c | 13 | 14 | |
| d | 15 | 16 |
在一些情况下,一个table可能没有固定的分隔符,用空格或其他方式来分隔。比如下面这个文件:
list(open('../examples/ex3.txt'))
[' A B C\n','aaa -0.264438 -1.026059 -0.619500\n','bbb 0.927272 0.302904 -0.032399\n','ccc -0.264273 -0.386314 -0.217601\n','ddd -0.871858 -0.348382 1.100491\n']
可以看到区域是通过不同数量的空格来分隔的。这种情况下,可以传入一个正则表达式给read_table来代替分隔符。用正则表达式为\s+,我们得到:
result = pd.read_table('../examples/ex3.txt', sep='\s+')
result
| A | B | C | |
|---|---|---|---|
| aaa | -0.264438 | -1.026059 | -0.619500 |
| bbb | 0.927272 | 0.302904 | -0.032399 |
| ccc | -0.264273 | -0.386314 | -0.217601 |
| ddd | -0.871858 | -0.348382 | 1.100491 |
因为列名比行的数量少,所以read_table推测第一列应该是dataframe的index。
这个解析器功能有很多其他参数能帮你解决遇到文件格式异常的问题(可以见之后的表格)。比如,我们要跳过第一、三、四行,使用skiprows:
!cat ../examples/ex4.csv
# hey!
a,b,c,d,message
# just wanted to make things more difficult for you
# who reads CSV files with computers, anyway?
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
pd.read_csv('../examples/ex4.csv', skiprows=[0, 2, 3])
| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
对于缺失值,pandas使用一些sentinel value(标记值)来代表,比如NA和NULL:
!cat ../examples/ex5.csv
something,a,b,c,d,message
one,1,2,3,4,NA
two,5,6,,8,world
three,9,10,11,12,foo
result = pd.read_csv('../examples/ex5.csv')
result
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | one | 1 | 2 | 3.0 | 4 | NaN |
| 1 | two | 5 | 6 | NaN | 8 | world |
| 2 | three | 9 | 10 | 11.0 | 12 | foo |
pd.isnull(result)
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | True |
| 1 | False | False | False | True | False | False |
| 2 | False | False | False | False | False | False |
na_values选项能把我们传入的字符识别为NA,导入必须是list:
result = pd.read_csv('../examples/ex5.csv', na_values=['NULL'])
result
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | one | 1 | 2 | 3.0 | 4 | NaN |
| 1 | two | 5 | 6 | NaN | 8 | world |
| 2 | three | 9 | 10 | 11.0 | 12 | foo |
我们还可以给不同的column设定不同的缺失值标记符,这样的话需要用到dict:
sentinels = {'message': ['foo', 'NA'],'something': ['two']}
# 把message列中的foo和NA识别为NA,把something列中的two识别为NApd.read_csv('../examples/ex5.csv', na_values=sentinels)
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | one | 1 | 2 | 3.0 | 4 | NaN |
| 1 | NaN | 5 | 6 | NaN | 8 | world |
| 2 | three | 9 | 10 | 11.0 | 12 | NaN |
1 Reading Text Files in Pieces(读取一部分文本)
对于一些比较大的文件,我们想要一次读取一小部分,或者每次迭代一小部分。在我们看一个比较大的文件前,先设置一下pandas中显示的数量:
pd.options.display.max_rows = 10
result = pd.read_csv('../examples/ex6.csv')
result
| one | two | three | four | key | |
|---|---|---|---|---|---|
| 0 | 0.467976 | -0.038649 | -0.295344 | -1.824726 | L |
| 1 | -0.358893 | 1.404453 | 0.704965 | -0.200638 | B |
| 2 | -0.501840 | 0.659254 | -0.421691 | -0.057688 | G |
| 3 | 0.204886 | 1.074134 | 1.388361 | -0.982404 | R |
| 4 | 0.354628 | -0.133116 | 0.283763 | -0.837063 | Q |
| ... | ... | ... | ... | ... | ... |
| 9995 | 2.311896 | -0.417070 | -1.409599 | -0.515821 | L |
| 9996 | -0.479893 | -0.650419 | 0.745152 | -0.646038 | E |
| 9997 | 0.523331 | 0.787112 | 0.486066 | 1.093156 | K |
| 9998 | -0.362559 | 0.598894 | -1.843201 | 0.887292 | G |
| 9999 | -0.096376 | -1.012999 | -0.657431 | -0.573315 | 0 |
10000 rows × 5 columns
如果只是想要读取前几行(不读取整个文件),指定一下nrows:
pd.read_csv('../examples/ex6.csv', nrows=5)
| one | two | three | four | key | |
|---|---|---|---|---|---|
| 0 | 0.467976 | -0.038649 | -0.295344 | -1.824726 | L |
| 1 | -0.358893 | 1.404453 | 0.704965 | -0.200638 | B |
| 2 | -0.501840 | 0.659254 | -0.421691 | -0.057688 | G |
| 3 | 0.204886 | 1.074134 | 1.388361 | -0.982404 | R |
| 4 | 0.354628 | -0.133116 | 0.283763 | -0.837063 | Q |
读取文件的一部分,可以指定chunksize:
chunker = pd.read_csv('../examples/ex6.csv', chunksize=1000)
chunker
<pandas.io.parsers.TextFileReader at 0x1121558d0>
pandas返回的TextParser object能让我们根据chunksize每次迭代文件的一部分。比如,我们想要迭代ex6.csv, 计算key列的值的综合:
chunker = pd.read_csv('../examples/ex6.csv', chunksize=1000)tot = pd.Series([])
for piece in chunker:tot = tot.add(piece['key'].value_counts(), fill_value=0)tot = tot.sort_values(ascending=False)
tot[:10]
E 368.0
X 364.0
L 346.0
O 343.0
Q 340.0
M 338.0
J 337.0
F 335.0
K 334.0
H 330.0
dtype: float64
TextParser有一个get_chunk方法,能返回任意大小的数据片段:
chunker = pd.read_csv('../examples/ex6.csv', chunksize=1000)chunker.get_chunk(10)
| one | two | three | four | key | |
|---|---|---|---|---|---|
| 0 | 0.467976 | -0.038649 | -0.295344 | -1.824726 | L |
| 1 | -0.358893 | 1.404453 | 0.704965 | -0.200638 | B |
| 2 | -0.501840 | 0.659254 | -0.421691 | -0.057688 | G |
| 3 | 0.204886 | 1.074134 | 1.388361 | -0.982404 | R |
| 4 | 0.354628 | -0.133116 | 0.283763 | -0.837063 | Q |
| 5 | 1.817480 | 0.742273 | 0.419395 | -2.251035 | Q |
| 6 | -0.776764 | 0.935518 | -0.332872 | -1.875641 | U |
| 7 | -0.913135 | 1.530624 | -0.572657 | 0.477252 | K |
| 8 | 0.358480 | -0.497572 | -0.367016 | 0.507702 | S |
| 9 | -1.740877 | -1.160417 | -1.637830 | 2.172201 | G |
2 Writing Data to Text Format (写入数据到文本格式)
可以输出位csv格式:
data = pd.read_csv('../examples/ex5.csv')
data
| something | a | b | c | d | message | |
|---|---|---|---|---|---|---|
| 0 | one | 1 | 2 | 3.0 | 4 | NaN |
| 1 | two | 5 | 6 | NaN | 8 | world |
| 2 | three | 9 | 10 | 11.0 | 12 | foo |
data.to_csv('../examples/out.csv')
!cat ../examples/out.csv
,something,a,b,c,d,message
0,one,1,2,3.0,4,
1,two,5,6,,8,world
2,three,9,10,11.0,12,foo
其他一些分隔符也可以使用(使用sys.stdout可以直接打印文本,方便查看效果):
import sys
data.to_csv(sys.stdout, sep='|')
|something|a|b|c|d|message
0|one|1|2|3.0|4|
1|two|5|6||8|world
2|three|9|10|11.0|12|foo
缺失值会以空字符串打印出来,我们可以自己设定缺失值的指定符:
data.to_csv(sys.stdout, na_rep='NULL')
,something,a,b,c,d,message
0,one,1,2,3.0,4,NULL
1,two,5,6,NULL,8,world
2,three,9,10,11.0,12,foo
如果不指定,行和列会被自动写入。当然也可以设定为不写入:
data.to_csv(sys.stdout, index=False, header=False)
one,1,2,3.0,4,
two,5,6,,8,world
three,9,10,11.0,12,foo
你可以指定只读取一部分列,并按你选择的顺序读取:
data.to_csv(sys.stdout, index=False, columns=['a', 'b', 'c'])
a,b,c
1,2,3.0
5,6,
9,10,11.0
series也有一个to_csv方法:
import numpy as np
dates = pd.date_range('1/1/2000', periods=7)ts = pd.Series(np.arange(7), index=dates)ts.to_csv('../examples/tseries.csv')
!cat ../examples/tseries.csv
2000-01-01,0
2000-01-02,1
2000-01-03,2
2000-01-04,3
2000-01-05,4
2000-01-06,5
2000-01-07,6
3 Working with Delimited Formats
对于大部分磁盘中的表格型数据,用pandas.read_table就能解决。不过,有时候一些人工的处理也是需要的。
当然,有时候,一些格式不正确的行能会把read_table绊倒。为了展示一些基本用法,这里先考虑一个小的CSV文件:
!cat ../examples/ex7.csv
"a","b","c"
"1","2","3"
"1","2","3"
对于单个字符的分隔符,可以使用python内建的csv方法。只要给csv.reader一个打开的文件即可:
import csv
f = open('../examples/ex7.csv')
reader = csv.reader(f)
迭代这个reader:
for line in reader:print(line)
['a', 'b', 'c']
['1', '2', '3']
['1', '2', '3']
接下来,我们可以根据自己的需要来处理数据。一步步来,首先,把文件读取成一个list of lines:
with open('../examples/ex7.csv') as f:lines = list(csv.reader(f))
把lines分成header line和data lines:
header, values = lines[0], lines[1:]
然后我们可以用一个字典表达式来构造一个有列的字典,以及用zip(\*values)反转行为列:
data_dict = {h: v for h, v in zip(header, zip(*values))}
data_dict
{'a': ('1', '1'), 'b': ('2', '2'), 'c': ('3', '3')}
header
['a', 'b', 'c']
print([x for x in zip(*values)])
[('1', '1'), ('2', '2'), ('3', '3')]
CSV有很多功能。我们可以定义一个新的分隔符格式,比如字符串的引号,行结束时的回车,这里我们利用csv.Dialect来构造一个子类:
class my_dialect(csv.Dialect):lineterminator = '\n'delimiter = ';'quotechar = '"'quoting = csv.QUOTE_MINIMALf = open('../examples/ex7.csv')
reader = csv.reader(f, dialect=my_dialect)
for line in reader:print(line)
['a,"b","c"']
['1,"2","3"']
['1,"2","3"']
当然,也可以设定一个分隔符参数给csv.reader,而不用单独定义一个子类:
reader = csv.reader(f, delimiter='|')
for line in reader:print(line)f.close()
对于一些更复杂的文件,比如用多种字符来做分隔符,就不能知网用csv模块来处理了。这种情况下,要先做string的split,或者用re.split
写入的话,可以用csv.write。它可以写入与csv.reader中设定一样的文件:
with open('../examples/mydata.csv', 'w') as f:writer = csv.writer(f, dialect=my_dialect)writer.writerow(('one', 'two', 'three'))writer.writerow(('1', '2', '3'))writer.writerow(('4', '5', '6'))writer.writerow(('7', '8', '9'))
!cat ../examples/mydata.csv
one;two;three
1;2;3
4;5;6
7;8;9
4 JSON Data
JSON (short for JavaScript Object Notation)已经是发送HTTP请求的标准数据格式了。这种格式比起表个性的CSV更自由一些:
obj = """
{"name": "Wes", "places_lived": ["United States", "Spain", "Germany"], "pet": null, "siblings": [{"name": "Scott", "age": 30, "pets": ["Zeus", "Zuko"]}, {"name": "Katie", "age": 38, "pets": ["Sixes", "Stache", "Cisco"]}]
}
"""
JSON是很接近python代码的,除了他的缺失值为null和一些其他的要求。基本的类型是object(dicts), array(lists), strings, numbers, booleans, and nulls. 所以的key必须是string。有很多读取JSON的库,这里用json,它也是python内建的库。把JSON string变为python格式,用json.loads:
import json
result = json.loads(obj)
result
{'name': 'Wes','pet': None,'places_lived': ['United States', 'Spain', 'Germany'],'siblings': [{'age': 30, 'name': 'Scott', 'pets': ['Zeus', 'Zuko']},{'age': 38, 'name': 'Katie', 'pets': ['Sixes', 'Stache', 'Cisco']}]}
使用json.dumps,可以把python object转换为JSON:
asjson = json.dumps(result)
如何把JSON转变为DataFrame或其他一些结构呢。可以把a list of dicts(JSON object)传给DataFrame constructor而且可以自己指定传入的部分:
siblings = pd.DataFrame(result['siblings'], columns=['name', 'age'])
siblings
| name | age | |
|---|---|---|
| 0 | Scott | 30 |
| 1 | Katie | 38 |
pandas.read_json可以自动把JSON数据转变为series或DataFrame:
!cat ../examples/example.json
[{"a": 1, "b": 2, "c": 3},{"a": 4, "b": 5, "c": 6},{"a": 7, "b": 8, "c": 9}]
5, “c”: 6},
{“a”: 7, “b”: 8, “c”: 9}]
pandas.read_json假设JSON数组中的每一个Object,是表格中的一行:
data = pd.read_json('../examples/example.json')
data
| a | b | c | |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 |
| 2 | 7 | 8 | 9 |
如果想要输出结果为JSON,用to_json方法:
print(data.to_json())
{"a":{"0":1,"1":4,"2":7},"b":{"0":2,"1":5,"2":8},"c":{"0":3,"1":6,"2":9}}
print(data.to_json(orient='records'))
[{"a":1,"b":2,"c":3},{"a":4,"b":5,"c":6},{"a":7,"b":8,"c":9}]
orient='records'表示输出的数据结构是 列->值 的形式:
records : list like [{column -> value}, ... , {column -> value}]
5 XML and HTML: Web Scraping (网络爬取)
python有很多包用来读取和写入HTML和XML格式。比如:lxml, Beautiful Soup, html5lib。其中lxml比较快,其他一些包则能更好的处理一些复杂的HTML和XML文件。
pandas有一个内建的函数,叫read_html, 这个函数利用lxml和Beautiful Soup这样的包来自动解析HTML,变为DataFrame。这里我们必须要先下载这些包才能使用read_html:
conda install lxml
pip install beautifulsoup4 html5lib
pandas.read_html函数有很多额外选项,但是默认会搜索并试图解析含有<tagble>tag的表格型数据。结果是a list of dataframe:
tables = pd.read_html('../examples/fdic_failed_bank_list.html')
len(tables)
1
tables
[ Bank Name City ST CERT \0 Allied Bank Mulberry AR 91 1 The Woodbury Banking Company Woodbury GA 11297 2 First CornerStone Bank King of Prussia PA 35312 3 Trust Company Bank Memphis TN 9956 4 North Milwaukee State Bank Milwaukee WI 20364 .. ... ... .. ... 542 Superior Bank, FSB Hinsdale IL 32646 543 Malta National Bank Malta OH 6629 544 First Alliance Bank & Trust Co. Manchester NH 34264 545 National State Bank of Metropolis Metropolis IL 3815 546 Bank of Honolulu Honolulu HI 21029 Acquiring Institution Closing Date \0 Today's Bank September 23, 2016 1 United Bank August 19, 2016 2 First-Citizens Bank & Trust Company May 6, 2016 3 The Bank of Fayette County April 29, 2016 4 First-Citizens Bank & Trust Company March 11, 2016 .. ... ... 542 Superior Federal, FSB July 27, 2001 543 North Valley Bank May 3, 2001 544 Southern New Hampshire Bank & Trust February 2, 2001 545 Banterra Bank of Marion December 14, 2000 546 Bank of the Orient October 13, 2000 Updated Date 0 November 17, 2016 1 November 17, 2016 2 September 6, 2016 3 September 6, 2016 4 June 16, 2016 .. ... 542 August 19, 2014 543 November 18, 2002 544 February 18, 2003 545 March 17, 2005 546 March 17, 2005 [547 rows x 7 columns]]
failures = tables[0]
failures.head()
| Bank Name | City | ST | CERT | Acquiring Institution | Closing Date | Updated Date | |
|---|---|---|---|---|---|---|---|
| 0 | Allied Bank | Mulberry | AR | 91 | Today's Bank | September 23, 2016 | November 17, 2016 |
| 1 | The Woodbury Banking Company | Woodbury | GA | 11297 | United Bank | August 19, 2016 | November 17, 2016 |
| 2 | First CornerStone Bank | King of Prussia | PA | 35312 | First-Citizens Bank & Trust Company | May 6, 2016 | September 6, 2016 |
| 3 | Trust Company Bank | Memphis | TN | 9956 | The Bank of Fayette County | April 29, 2016 | September 6, 2016 |
| 4 | North Milwaukee State Bank | Milwaukee | WI | 20364 | First-Citizens Bank & Trust Company | March 11, 2016 | June 16, 2016 |
这里我们做一些数据清洗和分析,比如按年计算bank failure的数量:
close_timestamps = pd.to_datetime(failures['Closing Date'])
close_timestamps.dt.year.value_counts()
2010 157
2009 140
2011 92
2012 51
2008 25...
2004 4
2001 4
2007 3
2003 3
2000 2
Name: Closing Date, dtype: int64
Parsing XML with lxml.objectify
XML(eXtensible Markup Language)是另一种常见的数据格式,支持阶层型、嵌套的数据。这里我们演示如何用lxml来解析一个XML格式文件。
纽约都会交通局发布了巴士和地铁的时间表。每一个地跌或巴士都有一个不同的文件(比如Performance_NNR.xml对应Metro-North Railroad):
<INDICATOR><INDICATOR_SEQ>373889</INDICATOR_SEQ> <PARENT_SEQ></PARENT_SEQ><AGENCY_NAME>Metro-North Railroad</AGENCY_NAME><INDICATOR_NAME>Escalator Availability</INDICATOR_NAME><DESCRIPTION>Percent of the time that escalators are operational systemwide. The availability rate is based on physical observations performed the morning of regular business days only. This is a new indicator the agency began reporting in 2009.</DESCRIPTION><PERIOD_YEAR>2011</PERIOD_YEAR> <PERIOD_MONTH>12</PERIOD_MONTH> <CATEGORY>Service Indicators</CATEGORY> <FREQUENCY>M</FREQUENCY> <DESIRED_CHANGE>U</DESIRED_CHANGE> <INDICATOR_UNIT>%</INDICATOR_UNIT> <DECIMAL_PLACES>1</DECIMAL_PLACES> <YTD_TARGET>97.00</YTD_TARGET> <YTD_ACTUAL></YTD_ACTUAL> <MONTHLY_TARGET>97.00</MONTHLY_TARGET> <MONTHLY_ACTUAL></MONTHLY_ACTUAL>
</INDICATOR>
使用lxml.objectify,我们可以解析文件,通过getroot,得到一个指向XML文件中root node的指针:
from lxml import objectifypath = '../datasets/mta_perf/Performance_MNR.xml'
parsed = objectify.parse(open(path))
root = parsed.getroot()
root.INDICATOR 返回一个生成器,每次调用能生成一个<INDICATOR>XML元素。每一个记录,我们产生一个dict,tag name(比如YTD_ACTUAL)作为字典的key:
data = []skip_fields = ['PARENT_SEQ', 'INDICATOR_SEQ', 'DESIRED_CHANGE', 'DECIMAL_PLACES']for elt in root.INDICATOR:el_data = {}for child in elt.getchildren():if child.tag in skip_fields:continueel_data[child.tag] = child.pyvaldata.append(el_data)
然后我们把这个dict变为DataFrame:
perf = pd.DataFrame(data)
perf.head()
| AGENCY_NAME | CATEGORY | DESCRIPTION | FREQUENCY | INDICATOR_NAME | INDICATOR_UNIT | MONTHLY_ACTUAL | MONTHLY_TARGET | PERIOD_MONTH | PERIOD_YEAR | YTD_ACTUAL | YTD_TARGET | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Metro-North Railroad | Service Indicators | Percent of commuter trains that arrive at thei... | M | On-Time Performance (West of Hudson) | % | 96.9 | 95 | 1 | 2008 | 96.9 | 95 |
| 1 | Metro-North Railroad | Service Indicators | Percent of commuter trains that arrive at thei... | M | On-Time Performance (West of Hudson) | % | 95 | 95 | 2 | 2008 | 96 | 95 |
| 2 | Metro-North Railroad | Service Indicators | Percent of commuter trains that arrive at thei... | M | On-Time Performance (West of Hudson) | % | 96.9 | 95 | 3 | 2008 | 96.3 | 95 |
| 3 | Metro-North Railroad | Service Indicators | Percent of commuter trains that arrive at thei... | M | On-Time Performance (West of Hudson) | % | 98.3 | 95 | 4 | 2008 | 96.8 | 95 |
| 4 | Metro-North Railroad | Service Indicators | Percent of commuter trains that arrive at thei... | M | On-Time Performance (West of Hudson) | % | 95.8 | 95 | 5 | 2008 | 96.6 | 95 |
XML数据能得到比这个例子更复杂的情况。每个tag都有数据。比如一个而HTML链接,也是一个有效的XML:
from io import StringIO
tag = '<a href="http://www.google.com">Google</a>'
root = objectify.parse(StringIO(tag)).getroot()
我们可以访问任何区域的tag(比如href):
root
<Element a at 0x114860948>
root.get('href')
'http://www.google.com'
root.text
'Google'
相关文章:
)
pandas教程:Reading and Writing Data in Text Format (以文本格式读取和写入数据)
文章目录 Chapter 6 Data Loading, Storage, and File Formats(数据加载,存储,文件格式)6.1 Reading and Writing Data in Text Format (以文本格式读取和写入数据)1 Reading Text Files in Pieces(读取一部分文本&…...

软考高级系统架构设计师系列之:软考高级系统架构设计师论文专题
软考高级系统架构设计师系列之:软考高级系统架构设计师论文专题 一、论文相关内容二、论文专题大纲三、论文考试方式四、历年真题汇总分析五、论文常见问题六、论文评分标准七、搭建论文万能模版八、论文万能模版公式九、搭建论文万能模版—摘要十、搭建论文万能模版—背景十一…...

目标检测中的评价指标
目标检测中的评价指标 将检测目标分为正样本和负样本。 真阳性(true positives , TP) : 正样本被正确识别为正样本。 假阳性(false positives, FP): 负样本被错误识别为正样本。 假阴性(false negatives, FN&#…...

【AI编程】ai编程插件汇总iFlyCode、codegeex
1、iFlyCode 开发公司:讯飞 支持IDE: VS Code、IntelliJ IDEA、CLion、PyCharm、WebStorm 支持语言: Python、JavaScript、C、Java 下载地址:https://iflycode.xfyun.cn/ iFlyCode 快捷键列表: Tab 采纳建议 Esc 拒绝建议 Alt\ 主动…...

算法通关村第八关|黄金挑战|二叉树的最近公共祖先
二叉树的最近公共祖先 找p和q就行,找不到p和q的节点就返回null,找到的就层层返回p或q,其他的还是返回null。直到某一层的left和right都不为null说明得到了最近公共节点,再将这个节点层层返回。如果p和q存在祖先和子节点的关系&am…...

亚马逊云科技产品测评』活动征文|通过使用Amazon Neptune来预测电影类型初体验
文章目录 福利来袭Amazon Neptune什么是图数据库为什么要使用图数据库什么是Amazon NeptuneNeptune 的特点 快速入门环境搭建notebook 图神经网络快速构建加载数据配置端点Gremlin 查询清理 删除环境S3 存储桶删除 授权声明:本篇文章授权活动官方亚马逊云科技文章转…...

【获奖论文】2023年数学建模国赛优秀获奖论文
论文篇幅过长,本文仅展示少部分;共计14篇完整PDF获奖论文。 关注在微信公众号:数学建模BOOM,回复“2023国赛”获取。 注意!是在公众号回复,不是在b站。 优秀论文部分内容展示: 更多A~E题的完…...

美团三年,总结的10条血泪教训
在美团的三年多时光,如同一部悠长的交响曲,高高低低,而今离开已有一段时间。闲暇之余,梳理了三年多的收获与感慨,总结成10条,既是对过去一段时光的的一个深情回眸,也是对未来之路的一份期许。 …...

【CSP认证考试】202309-1:坐标变换(其一)100分解题思路+代码
解题思路 暴力解决,不考虑时空开销就一直用for循环也可以做出来。按照题目意思输入两个数组,然后将第一个输入的数组的x部分累加起来记作x,再将y部分累加起来记作y。再将第二个数组的x部分都加上x,y部分加上y。最后输出第二个数组…...

剩余参数和展开运算符的区别
一、剩余参数 剩余参数语法允许在函数定义时,将多个参数表示为一个参数数组。 使用剩余参数,可以将不定数量的参数作为一个数组接收,并在函数内部对其进行操作。剩余参数使用三个点 (…) 加上一个参数名来表示,通常用于函数的最后…...

ES6的基础用法
本文会着重讲解es6,帮助大家熟悉es6和掌握es6的写法 1,let 没有变量提升,使用变量在变量定义之前,这点和var有很大区别 不允许重复声明 只在块级作用域里有效 暂时性死区 console.log(a) //报错,因为在未定义前调用l…...

standard_init_linux.go:211: exec user process caused “exec format error“
在使用docker搭建hue的过程中出现了如下错误: standard_init_linux.go:211: exec user process caused "exec format error"docker日志 [roots14 bin]# docker logs fa5b1c4e0614 standard_init_linux.go:211: exec user process caused "exec format error&q…...
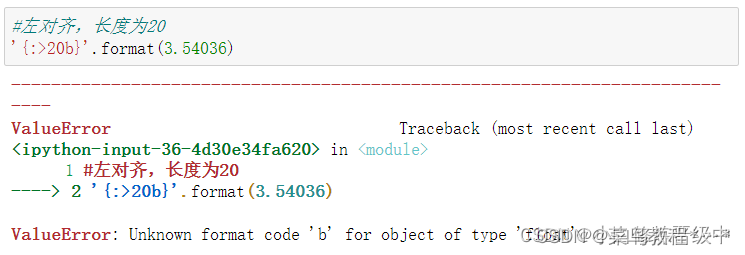
python的format函数的用法及实例
目录 1.format函数的语法及用法 (1)语法:{}.format() (2)用法:用于格式化字符串。可以接受无限个参数,可以指定顺序。返回结果为字符串。 2.实例 (1)不设置位置&…...
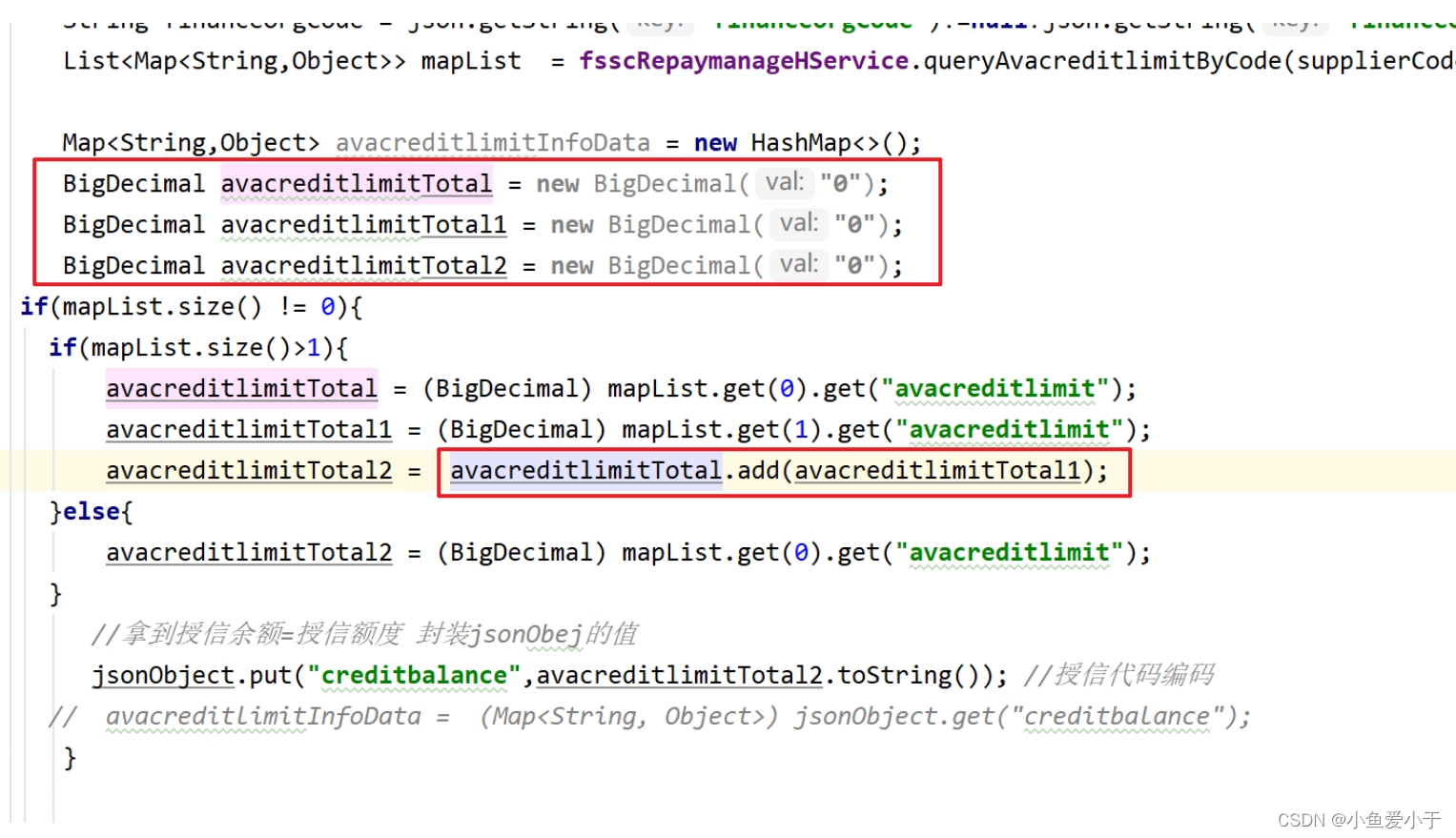
BigDecimal 类型的累加操作
BigDecimal 累加操作 .add操作...
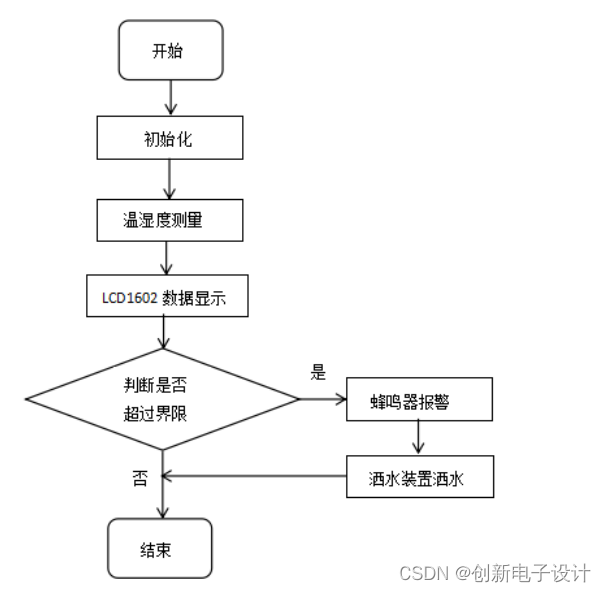
基于单片机的土壤温湿度控制系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 技术交流认准下方 CSDN 官方提供的联系方式 文章目录 概要 一、温湿度控制系统的整体规划2.3系统的总体构架 二、温度湿度控制系统硬件设计3.1系统硬件概述 三、 温湿度系统软件…...

服务器数据库中了elbie勒索病毒怎么办,elbie勒索病毒解密,数据恢复
网络技术的不断成熟,为企业的生产运营提供了强有力的支撑,但是,随之而来的网络安全威胁也不断增加。云天数据恢复中心陆陆续续接到很多企业的求助,企业的服务器数据库e遭到了elbie勒索病毒攻击,导致企业计算机系统瘫痪…...
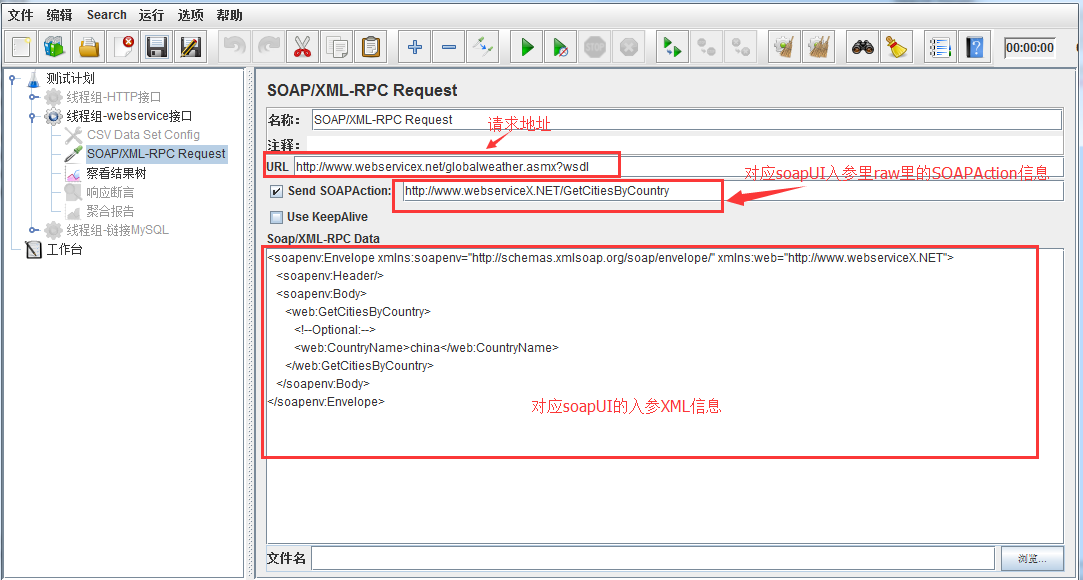
接口测试及接口测试工具
首先,什么是接口呢? 接口一般来说有两种,一种是程序内部的接口,一种是系统对外的接口。 系统对外的接口:比如你要从别的网站或服务器上获取资源或信息,别人肯定不会把数据库共享给你,他只能给你…...

JUC包工具类介绍二
JUC包工具类介绍二 异步任务 Callable Callable接口定义一个异步任务,当Callable接口提交到ExecutorService进行异步执行时,返回结果通过Java Future获取。Callable接口同样可以获取任务执行时的异常。 public class MyCallable implements Callable&…...

第8章_聚合函数
文章目录 1 聚合函数介绍1.1 AVG和SUM函数1.2 MIN和Max函数1.3 COUNT函数演示代码 2 GROUP BY2.1 基本使用2.2 使用多个列分组2.3 演示代码 3 HAVING3.1 基本使用3.2 WHERE和HAVING的对比3.3 演示代码 4 SELECT的执行过程4.1 查询的结构4.2 SELECT执行顺序4.3 SQL的执行原理演示…...
Mysql8与mariadb的安装与常用设置
一、v10服务器mariadb的安装与常用设置 V10服务器默认安装了mariadb数据库。也可使用命令sudo yum install mariadb手动安装或升级默认安装的版本。 1.1 修改数据库密码 systemctl restart mariadb,重启mariadb服务;mysql -u root -p,要求输入密码直接回车&#…...

突破B站字幕处理瓶颈:BiliBiliCCSubtitle全流程解决方案
突破B站字幕处理瓶颈:BiliBiliCCSubtitle全流程解决方案 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 一、问题发现:字幕处理的现实困境…...

打破设备壁垒:Sunshine让游戏自由流动的串流革命
打破设备壁垒:Sunshine让游戏自由流动的串流革命 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想象一下:你在客厅的高性能电脑上开始了一场紧张刺激的3A大…...

StructBERT中文情感识别效果展示:电影评论情感极性与票房相关性验证
StructBERT中文情感识别效果展示:电影评论情感极性与票房相关性验证 1. 项目概述与背景 StructBERT 情感分类 - 中文 - 通用 base 是百度基于 StructBERT 预训练模型微调后的中文通用情感分类模型,专门用于识别中文文本的情感倾向。这个模型在中文 NLP…...

如何从微信聊天记录中提取数据价值:WeChatMsg的完整解决方案
如何从微信聊天记录中提取数据价值:WeChatMsg的完整解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we…...

终极CPU稳定性测试指南:CoreCycler单核心轮询测试完全教程
终极CPU稳定性测试指南:CoreCycler单核心轮询测试完全教程 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitcode.…...

NCNN+OpenCV+Vulkan三件套:Windows环境下的深度学习加速实战教程
NCNNOpenCVVulkan三件套:Windows环境下的深度学习加速实战教程 在深度学习模型部署的战场上,Windows平台往往被开发者视为"次优选择"——直到NCNN、OpenCV和Vulkan这个黄金组合的出现。这个三件套解决方案正在改变游戏规则:NCNN提供…...

从一篇TIE论文的稳定性分析入手,手把手复现Bode图判据的MATLAB实现
从TIE论文案例到MATLAB实践:Bode图判据的稳定性分析全解析 在电力电子系统设计中,LCL型并网逆变器的稳定性分析一直是工程师面临的挑战。2015年发表在IEEE Transactions on Industrial Electronics上的那篇经典论文,为我们提供了一个绝佳的研…...

智能体AI崛起:本体论如何赋能药物研发新纪元?——2026智能体年深度解析
智能体AI作为生成式AI的进化方向,赋予AI决策和行动能力,在生命科学领域应用前景广阔。本文探讨了智能体AI的定义、架构及应用,重点分析了本体论如何通过语义标准化和跨系统映射,解决智能体在处理复杂科学知识、实现跨语言和系统语…...
实战部署与优化指南)
神州数码无线网络(AC+AP)实战部署与优化指南
1. 神州数码ACAP无线网络部署前的规划准备 第一次接触神州数码无线网络方案时,我被它简洁的架构设计惊艳到了。AC(无线控制器)AP(接入点)的组网模式,特别适合500-2000平米的中型企业办公环境。但在真正动手…...

7步掌握MetaGPT:从单行需求到完整软件的多智能体革命
7步掌握MetaGPT:从单行需求到完整软件的多智能体革命 【免费下载链接】MetaGPT 🌟 The Multi-Agent Framework: First AI Software Company, Towards Natural Language Programming 项目地址: https://gitcode.com/GitHub_Trending/me/MetaGPT 想…...