亚马逊云科技产品测评』活动征文|通过使用Amazon Neptune来预测电影类型初体验
文章目录
- 福利来袭
- Amazon Neptune
- 什么是图数据库
- 为什么要使用图数据库
- 什么是Amazon Neptune
- Neptune 的特点
- 快速入门
- 环境搭建
- notebook
- 图神经网络快速构建
- 加载数据
- 配置端点
- Gremlin 查询
- 清理
- 删除环境
- S3 存储桶删除
授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 Developer Centre, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道
福利来袭
前几天有小伙伴在群里灵魂发问:双11到来之际,阿里云、华为云、腾讯云哪家云服务的价格优惠力度最大?看到这个问题,群友各抒己见,展开了激烈的讨论,最终得出结论:三家国内云服务厂商提供的产品差异不大,价格优惠也不相上下。

看到这里,我将目光默默的转向了国外的云服务厂商亚马逊云(AWS)。大家作为 IT 人应该都知道亚马逊云在全球云市场中的地位举足轻重。据2021年全球云计算IaaS市场报告显示,亚马逊云市场份额高达38.9%,而国内最牛的阿里云也仅占9.5%。
来到亚马逊云的官网,我发现亚马逊云科技提供了100余种产品免费套餐。其中,计算资源Amazon EC2首年12个月免费,750小时/月;存储资源 Amazon S3 首年12个月免费,5GB标准存储容量;数据库资源 Amazon RDS 首年12个月免费,750小时;Amazon Dynamo DB 25GB存储容量 永久免费。

至于 活动地址 嘛,双手奉上,赶快来白嫖呀!同时给大家奉上数据库免费试用链接及上手教程
在AWS帐号注册过程中值得注意的一点:填写信用卡或者借记卡卡号时,虽然网址中标记的是
VISA或者mastercard,其实普通的信用卡也是可以的。
当然除了价格优势之外,亚马逊云科技的优势还体现在以下方面:
- 亚马逊云科技负责云自身的安全合规,不仅保证底层云基础设施和云服务的安全和合规;还提供了超过280多项安全、合规和治理方面的服务与工具。
- 亚马逊云科技有着覆盖全球的基础设施。
- 亚马逊云科技拥有超过200大类的云服务,从广度和深度上都能满足数字化出海和出海数字化的技术需求。
- 亚马逊云科技与全球超过10万家合作伙伴一起为出海企业提供从咨询、迁移到解决方案构建、到云上交付和运维的完整服务。
- 在全球,亚马逊是多个领域的引领者,包括亚马逊电商、智能物流、智能语音助手、智慧零售以及设备等多个领域。
Amazon Neptune
在了解Amazon Neptune之前,我们先来了解一下“图数据库”的概念。
什么是图数据库

如上图所示,将结点的人物和箭头表示的关系构成的图进行存储和查询的数据库就被称为图数据库。图数据库强调数据之间的关联关系,它将数据间的联系视为和数据本身同等重要。
为什么要使用图数据库
在互联网飞速发展的今天,传统的关系型数据库在处理关系操作方面表现出疲软的态势,而图数据库通过存储数据与关系,能将访问数据结点和关系的操作提升至线性时间复杂度,甚至能在一秒内遍历百万级的关系边,性能显著。
我们可以利用图数据库以多种方式表示现实世界实体之间的相互关系,包括行为、所有权、亲属关系、购买选择、个人联系、家庭关系等。以下是截止2021年8月,DB-ENGINES中图数据库前二十位的排行榜名单,我们可以看到Amazon的Neptune排在第八位。接下来就让我们来了解下Amazon Neptune。

什么是Amazon Neptune
Amazon Neptune是一项快速、可靠且完全托管式的图数据库服务,可用来帮助我们轻松构建和运行适用于高度互连数据集的应用程序。Neptune的核心是一个专门打造的高性能图形数据库引擎,此引擎经过优化,可存储数十亿条关系并以数毫秒级延迟查询图形。
Neptune 的特点
Neptune支持流行的图表查询语言Apache TinkerPop W3C SPARQL Grimlin和Neo4J的OpenPher,可让我们构建查询,高效地浏览高度互连数据集。Neptune具有高度可用性,带有只读副本,point-in-time Amazon S3的持续备份以及跨可用区的复制。Neptune提供了数据安全功能,并支持加密静态数据和传输中的数据。Neptune是完全托管的,因此再也无需担心数据库管理任务,例如硬件预配置、软件修补、设置、配置或备份。
光说不练假把式,接下来就让我们操练起来吧!
快速入门
环境搭建
首先我们需要登录到AWS的控制台

在控制台顶上搜索cloudshell

打开cloudshell之后如果出现如下页面,需要切换一下节点,如图所示

然后我们就可以创建 S3 存储桶了

其中cheetah-qing为自己的桶名,需要自定义。
我发现该桶名不支持下划线“_”。
接着我们需要通过命令来创建“堆栈“,命令如下:
aws cloudformation create-stack --stack-name get-started-neptune-ml --template-url https://s3.amazonaws.com/ee-assets-prod-us-east-1/modules/4f0f18a83e6148e895b10d87d4d89068/v1/gcr-buildon-selfpace/gcr-buildon-neptune-ml-nested-stack.json --capabilities CAPABILITY_IAM --region us-east-1 --disable-rollback

执行完命令后,大约需要等待30分钟:此时后台会启动一系列的服务。
我们可以通过在控制台顶上搜索
cloudformation来查看堆栈是否创建完成,如果get-started-neptune-ml显示CREATE_COMPLETE表示服务创建完成。
notebook
在搜索栏输入neptune,点击进入,导航栏选择“笔记本”,点击右侧的“查看笔记本文档”。

倘若没有 notebook,需确定地区是否选择正确,默认为美国东部,其次确认后台服务是否都启动完成。
图神经网络快速构建
我们可以根据上方打开的“ Amazon Neptune ML ”笔记来进行操作。在控制台输入命令来检查集群是否已正确配置可以运行 Neptune ML。

开始试验之前先来张步骤图感受下

加载数据
我们使用 Bulk Loader来加载数据,其流程与将数据摄入Amazon Neptune完全相同。通过编写脚本可以实现自动执行从MovieLens网站下载数据,调整数据格式,并将数据载入Neptune的全过程。脚本如下:
s3_bucket_uri="s3://cheetah-qing"
# remove trailing slashes
s3_bucket_uri = s3_bucket_uri[:-1] if s3_bucket_uri.endswith('/') else s3_bucket_uri
cheetah-qing为我们刚才创建的桶名称
执行response = neptune_ml.prepare_movielens_data(s3_bucket_uri)命令即可下载 MovieLens 数据,并将其调整为可被 Neptune 的 Bulk Loader 兼容的格式。
执行结果为
Completed Processing, data is ready for loading using the s3 url below:
s3://cheetah-qing/neptune-formatted/movielens-100k
操作完成后,执行%load -s {response} -f csv -p OVERSUBSCRIBE --run加载数据。

配置端点
执行命令来创建端点,并获取到推理端点的端点名称。
setup_node_classification=True
setup_node_regression=True
setup_link_prediction=True
setup_edge_classification=True
setup_edge_regression=Trueendpoints=neptune_ml.setup_pretrained_endpoints(s3_bucket_uri, setup_node_classification, setup_node_regression, setup_link_prediction, setup_edge_classification, setup_edge_regression)node_classification_endpoint=endpoints['node_classification_endpoint_name']['EndpointName']
node_regression_endpoint=endpoints['node_regression_endpoint_name']['EndpointName']
link_prediction_endpoint=endpoints['prediction_endpoint_name']['EndpointName']
edge_classification_endpoint=endpoints['edge_classification_endpoint_name']['EndpointName']
edge_regression_endpoint=endpoints['edge_regression_endpoint_name']['EndpointName']
Gremlin 查询
现在终于到了我们的电影类型预测环节了,我们一起来看看如何使用这些端点借助 Gremlin 查询进行推断。
在预测电影类型前,我们先执行

来验证图谱中,Forrest Gump 这个 movie 的 genre不包含任何 genre 值。
接下来我们修改这个查询,来预测 Apollo 13 的类型,开始之前先来设置一下:
- 指定要在 Gremlin 查询中使用的推理端点:
g.with("Neptune#ml.endpoint","<INSERT ENDPOINT NAME>") - 指定我们想要获取该属性的预测值:
with("Neptune#ml.classification")
将这些内容结合在一起就可以得到下方的查询,该查询可通过我们的产品知识图谱预测电影 Forrest Gump 的 genre。执行命令:
%%gremlin
g.with("Neptune#ml.endpoint","${node_classification_endpoint}").V().has('title', 'Forrest Gump (1994)').properties("genre").with("Neptune#ml.classification").value()

查看结果可知,预测结果似乎是正确的,Forrest 似乎被正确预测为 Drama 类型。
很多情况下,我们可能需要预测一个节点的多个类别。例如在我们的产品知识图谱中,一部电影很可能被归类为多个类型,我们可能需要预测所有这些类型。默认情况下,Neptune ML 会返回排名第一的结果,但我们可以使用 .with("Neptune#ml.limit",3) 配置选项指定希望返回的结果数量。一起看看针对Forrest Gump 返回的,排名前三的结果吧。

Neptune ML 返回的每个值都有一个与之关联的置信度分数,而无论预测结果的置信度如何,上述查询都会返回排名前三的结果。虽然该分数在查询时不可用,但它可用于筛选掉置信度较低的预测。
假设我们想要返回Forrest Gump预测的排名前三的类型,但前提是这些结果必须满足特定的置信度要求。为此,可以使用.with("Neptune#ml.threshold",0.2D)选项为查询添加筛选器,如下所示。

如上所示,目前我们只得到了 Drama 这个预测类型,因为这是唯一高于阈值的预测结果。
清理
我们已经使用Amazon Neptune来完成了预测电影类型的初体验,我们之前创建的 SageMaker 端点依然在运行并会按照标准费率产生费用。如果已完成 Neptune ML 的试用工作,希望避免产生这种重复性的成本,那么可以运行neptune_ml.delete_pretrained_endpoints(endpoints)来删除所创建的推断端点。
除了推断端点的成本外,我们之前使用的CloudFormation脚本也创建了多个额外资源。如果我们的全部操作均已完成,那么我们得删除 CloudFormation 栈,以避免产生重复的费用。
删除环境
为了防止之后的额外扣费,必须进行下面的删除环境操作,

S3 存储桶删除
选择 cloudshell,执行aws s3 rb s3://cheetah-qing --force删除 S3 存储桶

至此,我们的使用Amazon Neptune来完成预测电影类型的初体验就已经完成了,现在我们来总结一下它的优势:
- Amazon Neptune 支持 Gremlin 和 SPARQL 的开放图谱 API,并为这些图形模型及其查询语言提供高性能。
- Neptune 可在三个可用区内支持最多 15 个低延迟读取副本,从而扩展读取容量并每秒执行超过 10 万个图形查询。
- Neptune 旨在提供超过 99.99% 的可用性。其存储系统具有容错能力并能自我修复,专为云而构建,可以跨三个可用区复制六个数据副本。
- Amazon Neptune 为您的数据库提供多级安全保护,包括使用 Amazon VPC 进行网络隔离、支持终端节点访问的 IAM 身份验证、HTTPS 加密的客户端连接、使用您通过 AWS Key Management Service (KMS) 创建和控制的密钥对静态数据进行加密。
- Neptune 会自动持续地监控您的数据库并将其备份到 Amazon S3.因此可实现精细的时间点恢复。
如果有问题或者有更好的体验方式,欢迎留言或私信阿Q呦,我们一起进步!
相关文章:
亚马逊云科技产品测评』活动征文|通过使用Amazon Neptune来预测电影类型初体验
文章目录 福利来袭Amazon Neptune什么是图数据库为什么要使用图数据库什么是Amazon NeptuneNeptune 的特点 快速入门环境搭建notebook 图神经网络快速构建加载数据配置端点Gremlin 查询清理 删除环境S3 存储桶删除 授权声明:本篇文章授权活动官方亚马逊云科技文章转…...

【获奖论文】2023年数学建模国赛优秀获奖论文
论文篇幅过长,本文仅展示少部分;共计14篇完整PDF获奖论文。 关注在微信公众号:数学建模BOOM,回复“2023国赛”获取。 注意!是在公众号回复,不是在b站。 优秀论文部分内容展示: 更多A~E题的完…...

美团三年,总结的10条血泪教训
在美团的三年多时光,如同一部悠长的交响曲,高高低低,而今离开已有一段时间。闲暇之余,梳理了三年多的收获与感慨,总结成10条,既是对过去一段时光的的一个深情回眸,也是对未来之路的一份期许。 …...

【CSP认证考试】202309-1:坐标变换(其一)100分解题思路+代码
解题思路 暴力解决,不考虑时空开销就一直用for循环也可以做出来。按照题目意思输入两个数组,然后将第一个输入的数组的x部分累加起来记作x,再将y部分累加起来记作y。再将第二个数组的x部分都加上x,y部分加上y。最后输出第二个数组…...

剩余参数和展开运算符的区别
一、剩余参数 剩余参数语法允许在函数定义时,将多个参数表示为一个参数数组。 使用剩余参数,可以将不定数量的参数作为一个数组接收,并在函数内部对其进行操作。剩余参数使用三个点 (…) 加上一个参数名来表示,通常用于函数的最后…...

ES6的基础用法
本文会着重讲解es6,帮助大家熟悉es6和掌握es6的写法 1,let 没有变量提升,使用变量在变量定义之前,这点和var有很大区别 不允许重复声明 只在块级作用域里有效 暂时性死区 console.log(a) //报错,因为在未定义前调用l…...

standard_init_linux.go:211: exec user process caused “exec format error“
在使用docker搭建hue的过程中出现了如下错误: standard_init_linux.go:211: exec user process caused "exec format error"docker日志 [roots14 bin]# docker logs fa5b1c4e0614 standard_init_linux.go:211: exec user process caused "exec format error&q…...
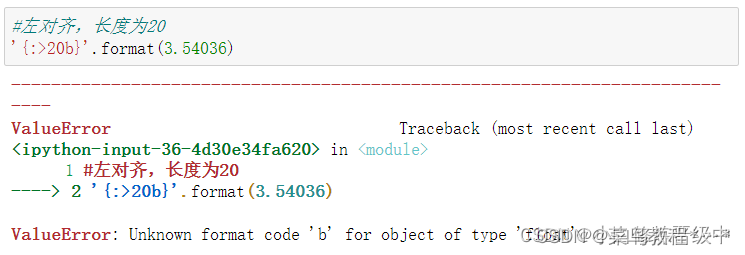
python的format函数的用法及实例
目录 1.format函数的语法及用法 (1)语法:{}.format() (2)用法:用于格式化字符串。可以接受无限个参数,可以指定顺序。返回结果为字符串。 2.实例 (1)不设置位置&…...
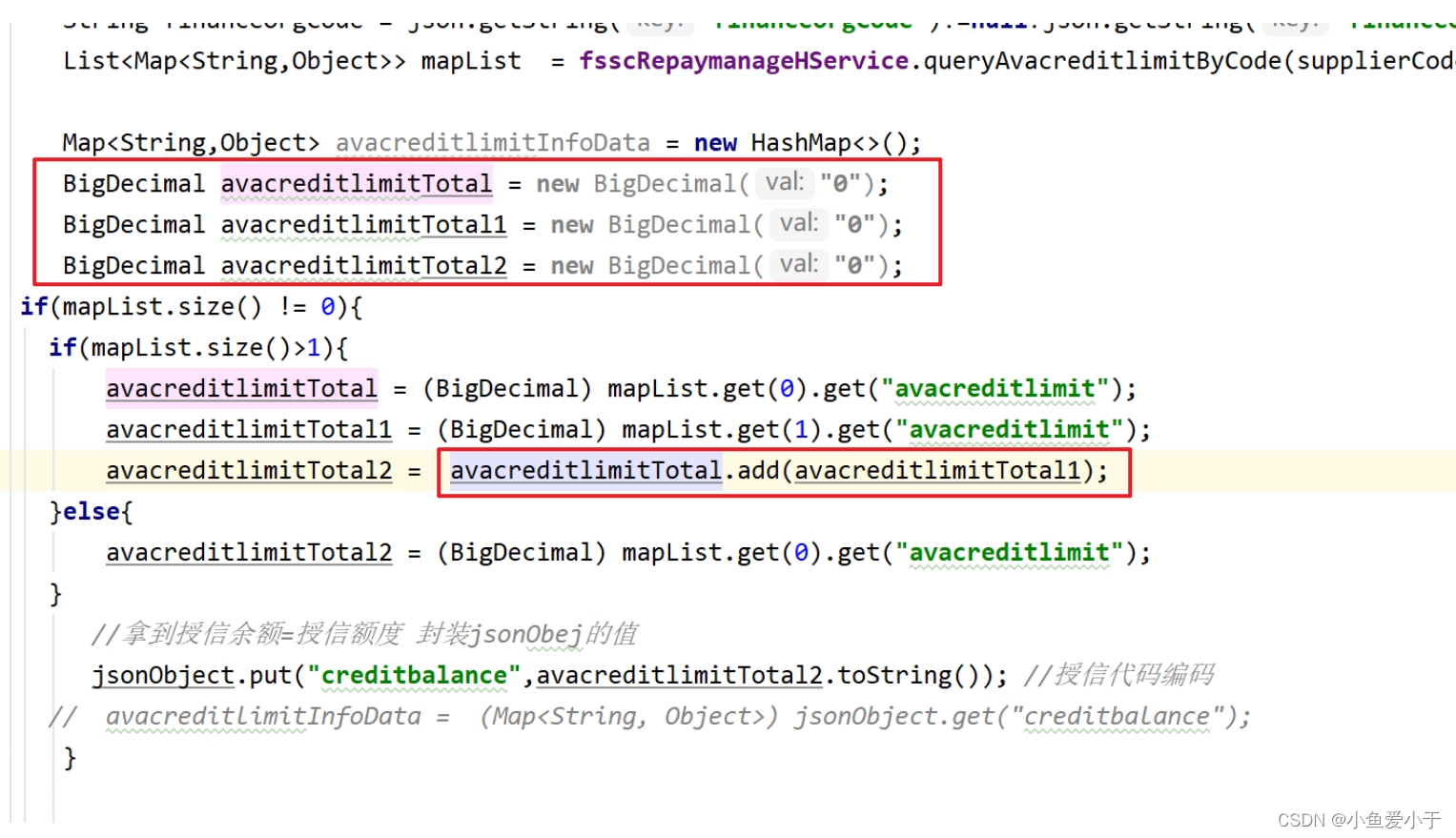
BigDecimal 类型的累加操作
BigDecimal 累加操作 .add操作...
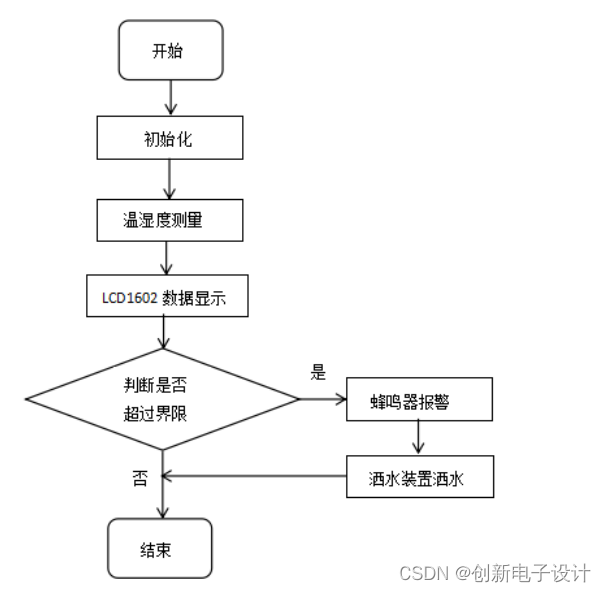
基于单片机的土壤温湿度控制系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 技术交流认准下方 CSDN 官方提供的联系方式 文章目录 概要 一、温湿度控制系统的整体规划2.3系统的总体构架 二、温度湿度控制系统硬件设计3.1系统硬件概述 三、 温湿度系统软件…...

服务器数据库中了elbie勒索病毒怎么办,elbie勒索病毒解密,数据恢复
网络技术的不断成熟,为企业的生产运营提供了强有力的支撑,但是,随之而来的网络安全威胁也不断增加。云天数据恢复中心陆陆续续接到很多企业的求助,企业的服务器数据库e遭到了elbie勒索病毒攻击,导致企业计算机系统瘫痪…...
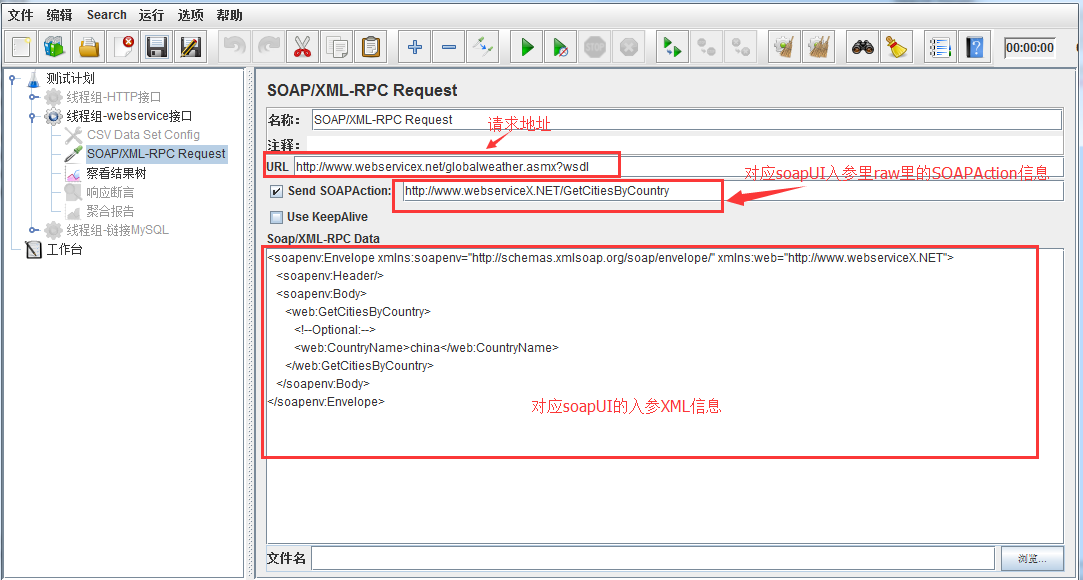
接口测试及接口测试工具
首先,什么是接口呢? 接口一般来说有两种,一种是程序内部的接口,一种是系统对外的接口。 系统对外的接口:比如你要从别的网站或服务器上获取资源或信息,别人肯定不会把数据库共享给你,他只能给你…...

JUC包工具类介绍二
JUC包工具类介绍二 异步任务 Callable Callable接口定义一个异步任务,当Callable接口提交到ExecutorService进行异步执行时,返回结果通过Java Future获取。Callable接口同样可以获取任务执行时的异常。 public class MyCallable implements Callable&…...

第8章_聚合函数
文章目录 1 聚合函数介绍1.1 AVG和SUM函数1.2 MIN和Max函数1.3 COUNT函数演示代码 2 GROUP BY2.1 基本使用2.2 使用多个列分组2.3 演示代码 3 HAVING3.1 基本使用3.2 WHERE和HAVING的对比3.3 演示代码 4 SELECT的执行过程4.1 查询的结构4.2 SELECT执行顺序4.3 SQL的执行原理演示…...
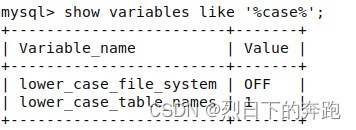
Mysql8与mariadb的安装与常用设置
一、v10服务器mariadb的安装与常用设置 V10服务器默认安装了mariadb数据库。也可使用命令sudo yum install mariadb手动安装或升级默认安装的版本。 1.1 修改数据库密码 systemctl restart mariadb,重启mariadb服务;mysql -u root -p,要求输入密码直接回车&#…...

深入剖析Golang中单例模式
前言 虽说Golang并不是C、Java这种传统的面向对象语言,而是偏向于面向接口编程的语言。但是Golang依旧有接口、结构体、组合等概念去模拟所谓面向对象中非常重要的设计模式。基于面向对象的模型去编写代码往往能编写成高内聚、低耦合、扩展性极强、难出bug的高质量…...
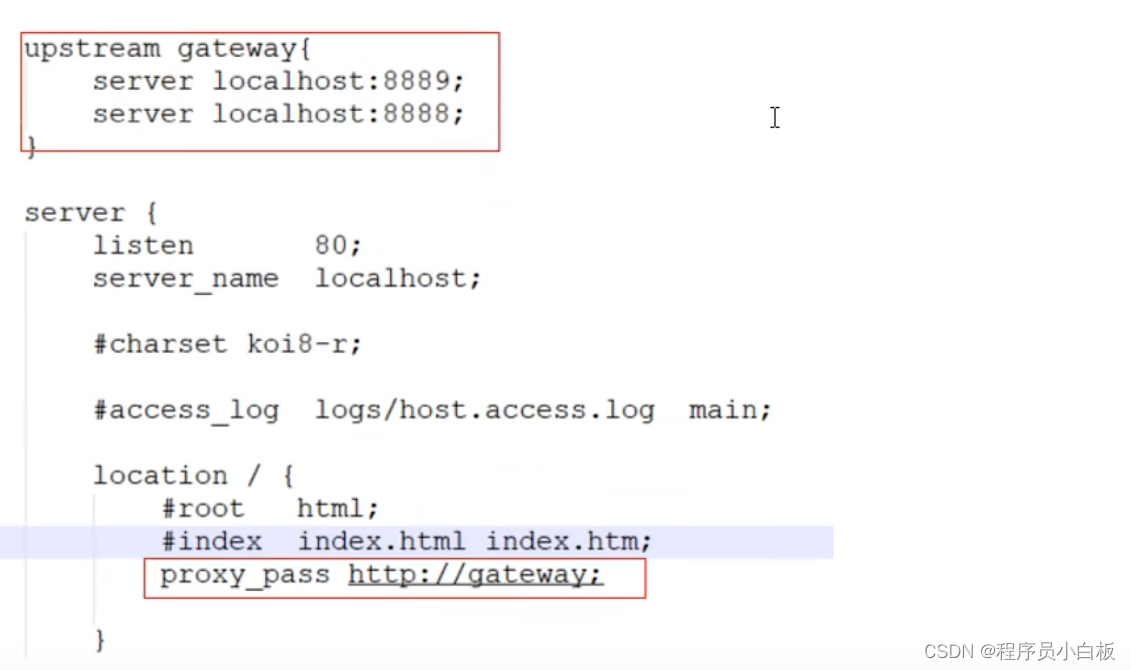
Java之SpringCloud Alibaba【八】【Spring Cloud微服务Gateway整合sentinel限流】
一、Gateway整合sentinel限流 网关作为内部系统外的一层屏障,对内起到-定的保护作用,限流便是其中之- - .网关层的限流可以简单地针对不同路由进行限流,也可针对业务的接口进行限流,或者根据接口的特征分组限流。 1、添加依赖 <dependency><groupId>c…...
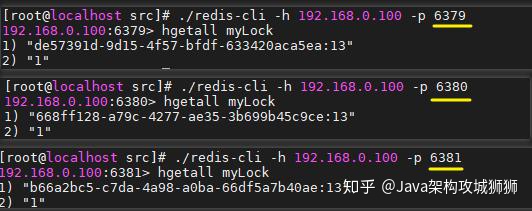
深入解析 Redis 分布式锁原理
一、实现原理 1.1 基本原理 JDK 原生的锁可以让不同线程之间以互斥的方式来访问共享资源,但如果想要在不同进程之间以互斥的方式来访问共享资源,JDK 原生的锁就无能为力了。此时可以使用 Redis 来实现分布式锁。 Redis 实现分布式锁的核心命令如下&am…...

[unity]多脚本情况下update函数的执行顺序
序 有的时候,执行某些脚本时会有先后顺序的要求。unity是按什么顺序来执行脚本的?如何设置? 默认的执行顺序 官方文档里面有个很长的图: Unity - Manual: Order of execution for event functions (unity3d.com) 根据文档&…...

Maven中<scope>中等级的区别
标签指定了依赖项的级别吗,默认是compile (编译)。意味着依赖项将会在编译时和运行时都被包含在项目中 <scope> 标签指定了依赖项的级别为 import 。除了 import 级别,Maven还支持以下几种级别: compile &#x…...

别再乱装CUDA了!保姆级教程:从显卡驱动到PyTorch 2.x,一次搞定Windows深度学习环境
深度学习环境配置避坑指南:从显卡驱动到PyTorch 2.x全流程解析 刚接触深度学习的开发者,往往在环境配置阶段就遭遇重重阻碍。显卡驱动与CUDA版本不匹配、cuDNN安装失败、PyTorch下载缓慢等问题,让许多初学者在起步阶段就耗费大量时间。本文将…...

RobotStudio机器人轨迹规划:从工件坐标到流畅路径的实战指南
1. 工件坐标系的创建与校准 在RobotStudio中规划机器人轨迹的第一步,就是建立准确的工件坐标系。这就像盖房子前要先打好地基,坐标系就是机器人运动的"地基"。我见过不少新手直接开始示教点位,结果发现机器人总是跑偏,就…...

lingbot-depth-vitl14镜像兼容性说明:insbase-cuda124-pt250-dual-v7底座深度适配细节
lingbot-depth-vitl14镜像兼容性说明:insbase-cuda124-pt250-dual-v7底座深度适配细节 1. 引言:为什么你需要关注这个深度估计模型? 如果你正在做机器人、自动驾驶或者AR/VR相关的项目,肯定遇到过这样的问题:怎么让机…...

3个秘诀让城通网盘下载提速10倍:ctfileGet工具全解析
3个秘诀让城通网盘下载提速10倍:ctfileGet工具全解析 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet ctfileGet是一款专注于获取城通网盘直连地址的开源工具,通过本地解析技术帮…...

intv_ai_mk11快速上手:浏览器输入URL→发送‘帮我写周报’→获得带数据亮点的Word格式草稿
intv_ai_mk11快速上手:浏览器输入URL→发送帮我写周报→获得带数据亮点的Word格式草稿 1. 什么是intv_ai_mk11 intv_ai_mk11是一款基于Llama架构的AI对话助手,拥有7B参数规模,运行在GPU服务器上。它能像真人助手一样理解你的需求࿰…...

基于ELK的口罩检测日志分析与可视化
基于ELK的口罩检测日志分析与可视化 1. 引言 在公共场所部署口罩检测系统后,我们面临着一个新的挑战:如何实时监控系统运行状态、快速定位问题、并优化检测性能?传统的日志查看方式已经无法满足需求,我们需要一个能够集中管理、…...

WarcraftHelper:让经典魔兽争霸III在现代电脑上焕发新生的全能助手
WarcraftHelper:让经典魔兽争霸III在现代电脑上焕发新生的全能助手 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸III在宽…...

PyTorch 2.8镜像实际效果:torch.compile+FlashAttention-2双优化下的吞吐量提升对比
PyTorch 2.8镜像实际效果:torch.compileFlashAttention-2双优化下的吞吐量提升对比 1. 镜像环境与技术亮点 PyTorch 2.8深度学习镜像为开发者提供了一个开箱即用的高性能计算环境。基于RTX 4090D 24GB显卡和CUDA 12.4的深度优化组合,这个镜像特别适合需…...
)
伯克利Octo机器人框架实战:5步搞定跨平台任务迁移(附代码)
伯克利Octo机器人框架实战:5步搞定跨平台任务迁移(附代码) 在机器人开发领域,硬件平台的多样性一直是阻碍算法快速部署的主要瓶颈。想象一下,你花费数月为WidowX机械臂开发的抓取算法,当实验室新购入UR5工业…...
)
OpenCompass本地评测大模型实战指南(2025最新版)
1. 为什么你需要OpenCompass本地评测 最近两年大模型发展太快了,各种新模型层出不穷。作为开发者,你是不是经常遇到这样的困惑:这个新发布的模型到底效果如何?和之前用的模型相比优势在哪里?官方公布的benchmark数据靠…...