8.spark自适应查询-AQE之自适应调整Shuffle分区数量
目录
- 概述
- 主要功能
- 自适应调整Shuffle分区数量
- 原理
- 默认环境配置
- 修改配置
- 结束
概述
自适应查询执行(AQE)是 Spark SQL中的一种优化技术,它利用运行时统计信息来选择最高效的查询执行计划,自Apache Spark 3.2.0以来默认启用该计划。从Spark 3.0开始,AQE有三个主要功如下
- 自适应查询AQE(Adaptive Query Execution)
- 自适应调整Shuffle分区数量
- 原理
- 默认环境配置
- 修改配置
- 动态调整Join策略
- 动态优化倾斜的 Join
- 自适应调整Shuffle分区数量
主要功能
自适应调整Shuffle分区数量
当spark.sql.adaptive.enabled和spark.sql.adaptive.coalescePartitions.enabled配置均为true时,自适应调整Shuffle分区数量功能就启动了
| 属性名称 | 默认值 | 功能 | 版本 |
|---|---|---|---|
| spark.sql.adaptive.enabled | true | 必备条件之一 | 3.0.0 |
| spark.sql.adaptive.coalescePartitions.enabled | true | 必备条件之二 | 3.0.0 |
| spark.sql.adaptive.advisoryPartitionSizeInBytes | 64 MB | 自适应优化期间shuffle分区的建议大小(以字节为单位)。当Spark合并小的shuffle分区或拆分倾斜的shuffler分区时,它就会生效。 | 3.0.0 |
| spark.sql.adaptive.coalescePartitions.parallelismFirst | true | 当为true时,Spark在合并连续的shuffle分区时会忽略Spark.sql.adaptive.advisoryPartitionSizeInBytes(默认64MB)指定的目标大小,并且只遵循Spark.sql.adaptive.salecePartitions.minPartitionSize(默认1MB)指定的最小分区大小,以最大限度地提高并行性。这是为了在启用自适应查询执行时避免性能回归。建议将此配置设置为false,并遵守spark.sql.adaptive.advisoryPartitionSizeInBytes指定的目标大小。 | 3.2.0 |
原理
Spark在处理海量数据的时候,其中的Shuffle过程是比较消耗资源的,也比较影响性能,因为它需要在网络中传输数据。
shuffle 中的一个关键属性是:分区的数量。
分区的最佳数量取决于数据自身大小,但是数据大小可能在不同的阶段、不同的查询之间有很大的差异,这使得这个数字很难精准调优。
如果分区数量太多,每个分区的数据就很小,读取小的数据块会导致IO效率降低,并且也会产生过多的task, 这样会给Spark任务带来更多负担。
如果分区数量太少,那么每个分区处理的数据可能非常大,处理这些大分区的数据可能需要将数据溢写到磁盘(例如:排序或聚合操作),这样也会降低计算效率。
Spark初始会设置一个较大的Shuffle分区个数,这个数值默认是200,后续在运行时会根据动态统计到的数据信息,将小的分区合并,也就是慢慢减少分区数量。
测试时将以SELECT workorder,unitid,partid,partname,routeid,lineid from ods.xx where dt ='2023-06-24' group by workorder,unitid,partid ,partname ,routeid,lineid 语句进行测试,为了看出 Shuffle 的效果,group 字段多了一些
将初始的 Shuffle 分区数量设置为 5,所以在 Shuffle 过程中数据会产生5 个分区。如果没有开启自适应调整Shuffle分区数量这个策略,Spark会启动5个Recuce任务来完成最后的聚合。但是这里面有3个非常小的分区,为每个分区分别启动一个单独的任务会浪费资源,并且也无法提高执行效率。如下图:
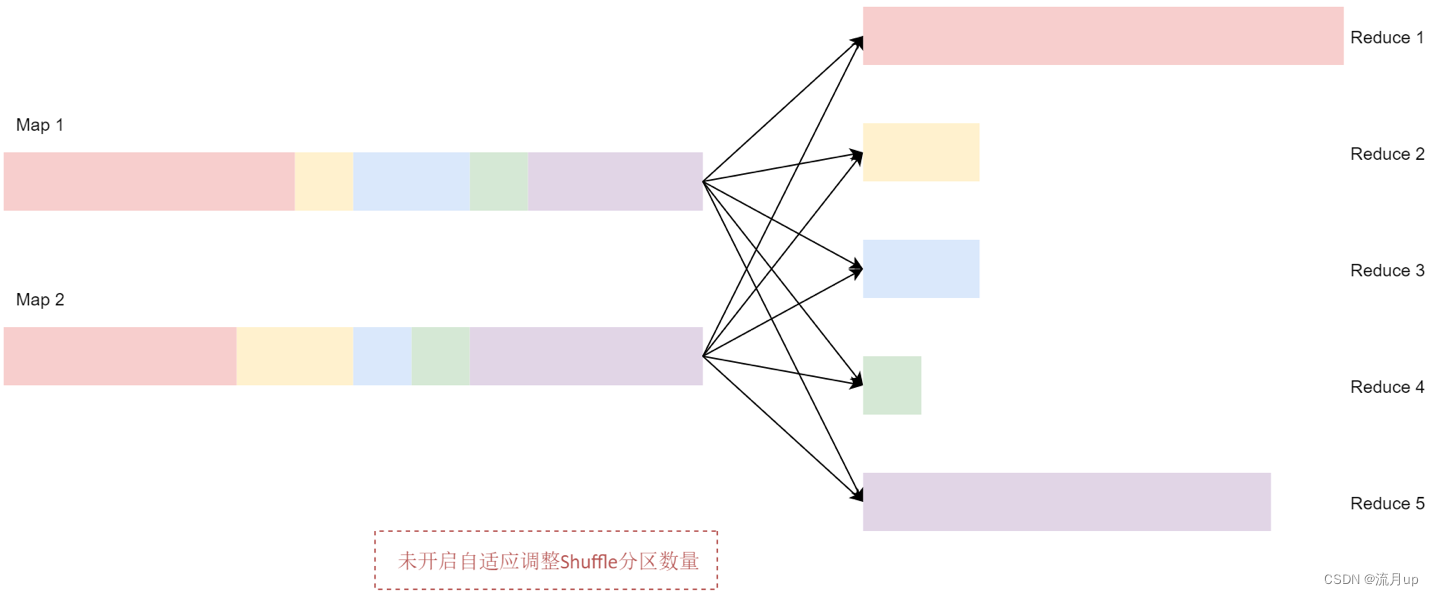
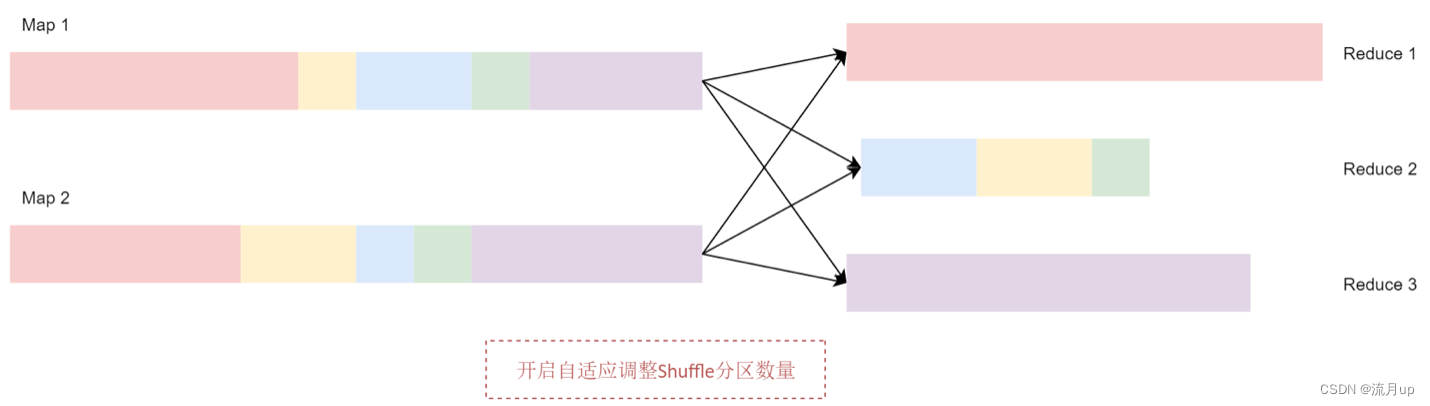
开启自适应调整 Shuffle 分区数量之后,Spark 会将这3个数据量比较小的分区合并为 1 个分区,让1个reduce任务处理
默认环境配置
测试案例:
案例环境,使用的是
spark 3.2.4,kyuubi 1.7.1版本,使用一张20亿的表做优化测试的,也可以准备一个json文件,加载后转成DataFrame
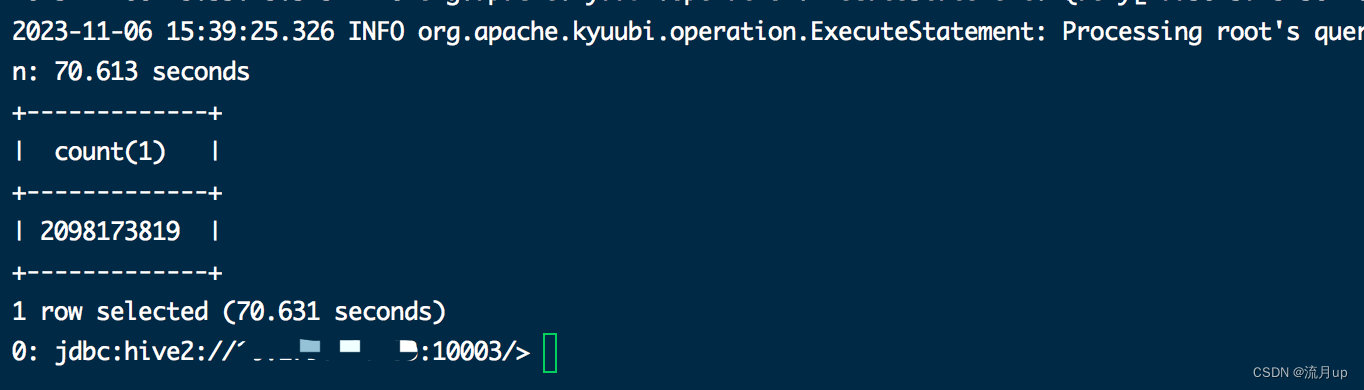
SELECT workorder,unitid,partid,partname,routeid,lineid from ods.xx where dt ='2023-06-24' group by workorder,unitid,partid ,partname ,routeid,lineid
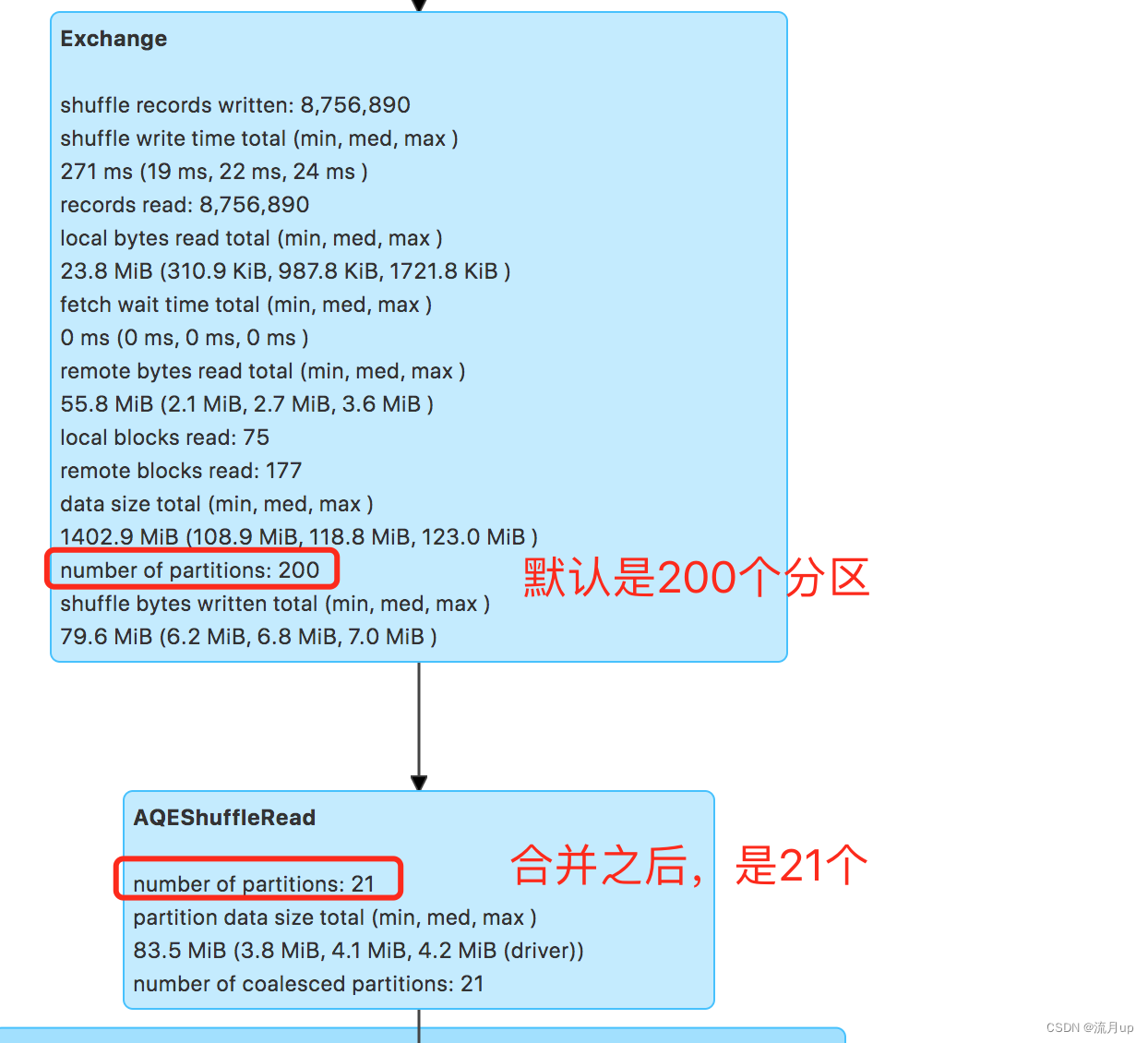

由上两个图,可以看出21任务,每个任务只是 3~4 M 这样,原因是因
spark.sql.adaptive.coalescePartitions.parallelismFirst = true
修改配置
spark.sql.adaptive.coalescePartitions.parallelismFirst=false


可以看出,两三千万的数据,shuffle 处理上还是有倾斜的,但海量数据下,基本上是接近64m的。
结束
至此,自适应调整Shuffle分区数量,就结束了。
相关文章:
8.spark自适应查询-AQE之自适应调整Shuffle分区数量
目录 概述主要功能自适应调整Shuffle分区数量原理默认环境配置修改配置 结束 概述 自适应查询执行(AQE)是 Spark SQL中的一种优化技术,它利用运行时统计信息来选择最高效的查询执行计划,自Apache Spark 3.2.0以来默认启用该计划。…...

【Java 进阶篇】Java Filter 快速入门
欢迎来到这篇有关 Java Filter 的快速入门指南!如果你是一名 Java 开发者或者正在学习 Java Web 开发,Filter 是一个强大的工具,可以帮助你管理和控制 Web 应用程序中的请求和响应。本文将向你解释 Filter 的基本概念,如何创建和配…...
Pytorch R-CNN目标检测-汽车car
概述 目标检测(Object Detection)就是一种基于目标几何和统计特征的图像分割,它将目标的分割和识别合二为一,通俗点说就是给定一张图片要精确的定位到物体所在位置,并完成对物体类别的识别。其准确性和实时性是整个系统的一项重要能力。 R-CNN的全称是Region-CNN(区域卷积神经…...

【PG】PostgreSQL13主从流复制部署(详细可用)
目录 版本 部署主从注意点 1 主库上创建复制用户 2 主库上修改pg_hba.conf文件 3 修改文件后重新加载配置使其生效 4 主库上修改配置文件 5 重启主库pg使参数生效 6 部署从库 7 备份主库数据至从库 停止从库 备份从库的数据库目录 新建数据库数据目录data 创建和…...

学习pytorch15 优化器
优化器 官网如何构造一个优化器优化器的step方法coderunning log出现下面问题如何做反向优化? 官网 https://pytorch.org/docs/stable/optim.html 提问:优化器是什么 要优化什么 优化能干什么 优化是为了解决什么问题 优化模型参数 如何构造一个优化器…...

[算法日志]图论刷题 沉岛思想的运用
[算法日志]图论刷题: 沉岛思想的运用 leetcode 695 岛屿最大面积 给你一个大小为 m x n 的二进制矩阵 grid . 岛屿 是由一些相邻的 1 (代表土地) 构成的组合, 这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻. 你可以假设 grid 的四个边缘都被 0(…...

Web服务器的搭建
网站需求: 1.基于域名www.openlab.com可以访问网站内容为 welcome to openlab!!! 2.给该公司创建三个网站目录分别显示学生信息,教学资料和缴费网站,基于www.openlab.com/student 网站访问学生信息,www.openlab.com/data网站访问教…...

如何使用 GTX750 或 1050 显卡安装 CUDA11+
前言 由于兼容性问题,使得我们若想用较新版本的 PyTorch,通过 GPU 方式训练模型,也得更换较新版本得 CUDA 工具包。然而 CUDA 的版本又与电脑显卡的驱动程序版本关联,如果是低版本的显卡驱动程序安装 CUDA11 及以上肯定会失败。 比…...

跟着森老师学React Hooks(1)——使用Vite构建React项目
Vite是一款构建工具,对ts有很好的支持,最近也是在前端越来越流行。 以往的React项目的初始化方式大多是通过脚手架create-react-app(本质是webpack),其实比起Vite来构建,启动会慢一些。 所以这次跟着B站的一个教程,使用…...
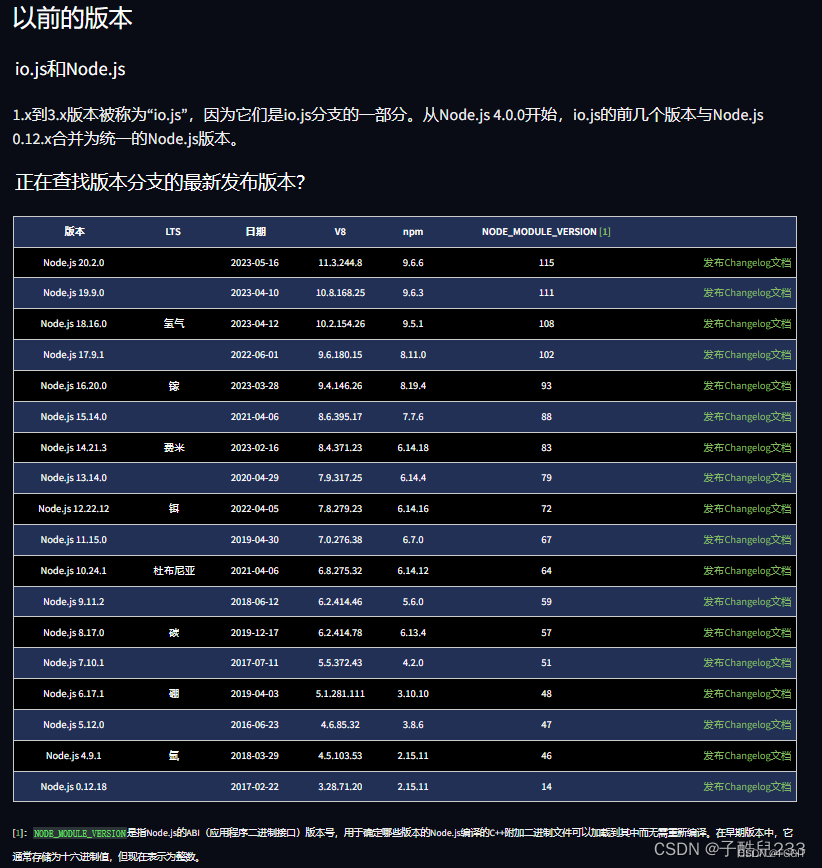
强力解决使用node版本管理工具 NVM 出现的问题(找不到 node,或者找不到 npm)
强力解决使用node版本管理工具 NVM 出现的问题(找不到 node,或者找不到 npm) node与npm版本对应关系 nvm是好用的Nodejs版本管理工具, 通过它可以方便地在本地调换Node版本。 2020-05-28 Node当前长期稳定版12.17.0,…...

Docker指定容器使用内存
Docker指定容器使用内存 作者:铁乐与猫 如果是还没有生成的容器,你可以从指定镜像生成容器时特意加上 run -m 256m 或 --memory-swap512m来限制。 -m操作指定的是物理内存,还有虚拟交换分区默认也会生成同样的大小,而–memory-…...

做什么数据表格啊,要做就做数据可视化
是一堆数字更易懂,还是图表更易懂?很明显是图表,特别是数据可视化图表。数据可视化是一种将大量数据转化为视觉形式的过程,通过图形、图表、图像等方式呈现数据,以便更直观地理解和分析。 数据可视化更加生动、形象地…...

CSS特效003:太阳、地球、月球的旋转
GPT能够很好的应用到我们的代码开发中,能够提高开发速度。你可以利用其代码,做出一定的更改,然后实现效能。 css实战中,这种球体间的旋转,主要通过rotate()旋转函数来实现。实际上,蓝色的地球和黑色的月球…...

云计算的大模型之争,亚马逊云科技落后了?
文丨智能相对论 作者丨沈浪 “OpenAI使用了Azure的智能云服务”——在过去的半年,这几乎成为了微软智能云最好的广告词。 正所谓“水涨船高”,凭借OpenAI旗下的ChatGPT在全球范围内爆发,微软趁势拉了一波自家的云计算业务。2023年二季度&a…...
【form校验】3.0项目多层list嵌套
const { required, phoneOrMobile } CjmForm.rules; export default function detail() {const { query } getRouterInfo(location);const formRef useRef(null);const [crumbList, setCrumbList] useState([{url: "/wenling/Reviewer",name: "审核人员&quo…...

公共功能测试用例
1、UI测试 布局是否合理,输入框、按钮是否对齐 行列间距是否保持一致弹出窗口垂直居中对其界面的设计风格是否与UI的设计风格一致 系统是否使用统一风格的控件界面的文字是否简洁易懂,是否有错别字 兼容性测试:不同浏览器、版本、分辨率下&a…...

【电路笔记】-并联RLC电路分析
并联RLC电路分析 文章目录 并联RLC电路分析1、概述2、AC的行为3、替代配置3.1 带阻滤波器3.2 带通滤波器 4、总结 电子器件三个基本元件的串联行为已在我们之前的文章系列 RLC 电路分析中详细介绍。 在本文中,介绍了另一种称为并联 RLC 电路的关联。 在第一部分中&a…...

ros1 client
Client(客户端):发布海龟生成请求 [类似Publisher] Serve(服务端):海龟仿真器,接收请求 [类似于Subscriber] Service(服务):生成海龟的具体内容,其中服务类型…...
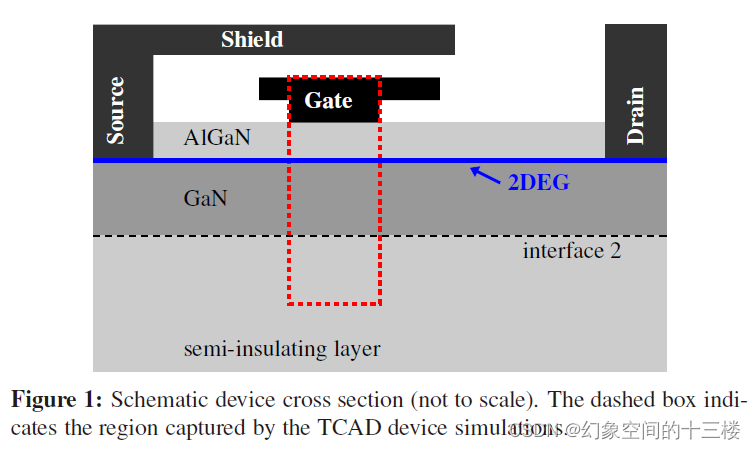
射频功率放大器应用中GaN HEMT的表面电势模型
标题:A surface-potential based model for GaN HEMTs in RF power amplifier applications 来源:IEEE IEDM 2010 本文中的任何第一人称都为论文的直译 摘要:我们提出了第一个基于表面电位的射频GaN HEMTs紧凑模型,并将我们的工…...
——EEG特征提取方法详解)
CSP(Common Spatial Patterns)——EEG特征提取方法详解
基于CSP的运动想象 EEG 特征提取和可视化参考前文:https://blog.csdn.net/qq_43811536/article/details/134273470?spm1001.2014.3001.5501 目录 1. CSP是什么?1.1 CSP的含义1.2 CSP算法1.3 CSP特征的特点 2. CSP特征在EEG信号分类任务中的应用2.1 任务…...

w64devkit架构解析:Windows原生C/C++工具链的工程化实现
w64devkit架构解析:Windows原生C/C工具链的工程化实现 【免费下载链接】w64devkit Portable C and C Development Kit for x64 (and x86) Windows 项目地址: https://gitcode.com/gh_mirrors/w6/w64devkit w64devkit作为一个专为Windows平台设计的便携式C、C…...

OpenClaw智能压缩插件:解决AI Agent上下文爆炸的工程实践
1. 项目概述:为AI Agent“瘦身”的智能压缩插件 如果你正在使用OpenClaw这类多智能体协作框架,大概率会遇到一个头疼的问题:上下文爆炸。随着任务链的延伸,工具调用、子智能体回复、系统日志会像滚雪球一样,迅速填满有…...

深入解读Vivado FFT IP核的AXI-Stream接口:手把手教你搭建数据流控制系统
Vivado FFT IP核AXI-Stream接口实战:构建高可靠数据流系统的五个关键策略 在FPGA信号处理系统中,FFT运算作为频谱分析的核心环节,其性能直接影响整个数据处理链路的效率。Xilinx Vivado提供的FFT IP核通过AXI-Stream接口实现了模块化设计&am…...

Matlab与Qianfan-OCR-4B联动:科学计算环境中的文档数据分析
Matlab与Qianfan-OCR-4B联动:科学计算环境中的文档数据分析 1. 科研数据处理的新思路 想象一下这样的场景:实验室里堆满了各种论文扫描件和实验数据图表,你需要手动录入这些数据到Matlab进行分析。这个过程不仅耗时耗力,还容易出…...

通过受管控的控制平面加速商品陈列优化
作者:来自 Elastic Alexander Marquardt, Honza Krl 及 Taylor Roy 搜索行为的变化不应该需要一个工程工单。了解受管控的控制平面如何让业务团队在数小时内更新搜索策略,而无需部署,也无需承担风险。 Elasticsearch 新手?参加我…...

告别IDM试用期限制:开源脚本实现永久激活的完整指南
告别IDM试用期限制:开源脚本实现永久激活的完整指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 你是否厌倦了Internet Download Manager…...

从导弹防御到深空探测:STK EOIR传感器建模,在Win10系统下的多场景应用入门
从导弹防御到深空探测:STK EOIR传感器建模的多场景实战指南 当我们需要模拟太空中的光学现象时,STK EOIR模块就像一把瑞士军刀——它既能处理导弹防御中的红外追踪,也能规划月球车的可见光成像路径。这个工具的强大之处在于,用同一…...

Process Phoenix进阶应用:多进程架构下的状态管理终极指南
Process Phoenix进阶应用:多进程架构下的状态管理终极指南 【免费下载链接】ProcessPhoenix Process Phoenix facilitates restarting your application process. 项目地址: https://gitcode.com/gh_mirrors/pr/ProcessPhoenix Process Phoenix是一款专注于A…...

AI绘画新玩具!图图的嗨丝造相实测:简单描述就能生成惊艳的渔网袜角色图
AI绘画新玩具!图图的嗨丝造相实测:简单描述就能生成惊艳的渔网袜角色图 最近在玩AI绘画的朋友,可能都遇到过这样的烦恼:想让AI画一个穿着渔网袜的角色,结果要么画成了纯黑色的紧身裤,要么网格纹理歪歪扭扭…...
)
远程办公新选择:除了腾讯云,ToDesk云电脑如何成为我的主力‘云主机’(含分屏、外设连接技巧)
远程办公生产力革命:ToDesk云电脑的全场景实战指南 站在星巴克角落用平板电脑调试3D建模参数,机场候机时掏出手机继续写代码,家中老旧笔记本突然流畅运行4K视频剪辑——这些看似矛盾的场景,正随着云电脑技术的成熟变得触手可及。不…...