为什么是LangChain?
文章目录
- 一、前言
- 二、认识langchain
- 1. langchain的主要组成
- 2. 总览LangChain
- 2. LangChain的六大核心模块
- 1. Models:模型统一接口
- 2. `Prompts`:管理 LLM 输入
- 3. `Chains`:将 LLM 与其他组件相结合,执行多个chain
- 4. `Indexes`:访问外部数据
- a. Loader 加载器
- b. `Document` 文档(解决加载数据超过模型最大输入) 与 `Text Spltters` 文本分割
- d. Vectorstores 向量数据库
- e. Embedding
- 5. `Memory`:记住以前的对话
- 6. `Agents`:访问其他工具,自定义agent中所使用的工具
- 三、经典示例
- 1. 最简单的交互
- 2. 构建本地知识库问答机器人
- 3. 让输出内容 结构化起来
- 4. 使用 Hugging Face 模型
- 4. 通过自然语言执行SQL命令
一、前言
我们知道因为一些不得已的原因,一些国外比较优秀的技术,我们不能看到,比如,如果我们想要借助 OpenAI 或 Hugging Face 创建基于大语言模型的应用程序。若非一些特殊方法,是难以实现的。从cahtgpt发布到今天不过一年时间,市面上的LLM已经百花齐放,不得不感慨技术革命的速度,为了能轻松构建大语言模型应用。不得不提起一个非常强大的第三方开源库:LangChain 。
官方文档
这个库目前非常活跃,已经67Kstart了,每天都在迭代,更新速度飞快。
LangChain 是一个我们与大模型互动的一个桥梁。他主要拥有 2 个能力:
- 作为大模型与本地数据的一个器哦啊两联系起来,也就是将 LLM 模型与外部数据源进行连接
- 让开发者与 LLM 模型进行更加友好的交互
而且:LangChain 是一个旨在帮助您轻松构建大语言模型应用的框架,它可以帮助我们:
- 为各种
不同基础模型提供统一接口(参见Models) - 帮助
管理提示的框架(参见Prompts),能够实现,多个prompt 配合使用。 - 一套中心化接口,用于处理长期记忆(Memory)、外部数据(Indexes)、其他 LLM(Chains)以及 LLM 无法处理的任务的其他代理(例如,计算或搜索)。
LLM 模型:Large Language Model,大型语言模型
LangChain是一个用于开发由语言模型驱动的应用程序的框架。它使应用程序能够:
具有上下文意识:将语言模型与上下文源(提示指令,少量示例,基于其响应的内容等)联系起来。
推理:依靠语言模型进行推理(关于如何根据提供的上下文进行回答,采取什么行动等)。
朗链的主要价值支柱有:
组件:用于处理语言模型的抽象,以及每个抽象的实现集合。组件是模块化的,易于使用,无论你
二、认识langchain
1. langchain的主要组成
LangChain 6大核心模块:
Models:从不同的 LLM 和嵌入模型中进行选择
Prompts:管理 LLM 输入
Chains:将 LLM 与其他组件相结合
Indexes:访问外部数据
Memory:记住以前的对话
Agents:访问其他工具
2. 总览LangChain
langchain是个优雅的框架。
Models:从不同的 LLM 和嵌入模型中进行选择
支持多种模型接口,比如 OpenAI、Hugging Face、AzureOpenAI …
Fake LLM,用于测试
缓存的支持,比如 in-mem(内存)、SQLite、Redis、SQL用量记录
支持流模式(就是一个字一个字的返回,类似打字效果)
Prompts:管理 LLM 输入
Prompt管理,支持各种自定义模板
拥有大量的文档加载器,比如 Email、Markdown、PDF、Youtube …
Indexes:访问外部数据
对索引的支持
文档分割器
向量化
对接向量存储与搜索,比如 Chroma、Pinecone、Qdrand
Chains:将 LLM 与其他组件相结合
LLMChain
各种工具Chain
LangChainHub
2. LangChain的六大核心模块
1. Models:模型统一接口
各种类型的模型和模型集成,比如OpenAI的各个API/GPT-4等等,为各种不同基础模型提供统一接口,也就是说在调用模型的时候,我们可以只通过 一个入口:
比如:这里以 ChatGPT为例,因为特殊原因,api的key,秘钥这些东西 需要申请。
import os
os.environ["OPENAI_API_KEY"] = '你的api key'
from langchain.llms import OpenAIllm = OpenAI(model_name="text-davinci-003",max_tokens=1024)
llm("啥是人工智能")
# 可以选择的模型。以及模型的最大输入 tokenmodel_token_mapping = {"gpt-4": 8192,"gpt-4-0314": 8192,"gpt-4-0613": 8192,"gpt-4-32k": 32768,"gpt-4-32k-0314": 32768,"gpt-4-32k-0613": 32768,"gpt-3.5-turbo": 4096,"gpt-3.5-turbo-0301": 4096,"gpt-3.5-turbo-0613": 4096,"gpt-3.5-turbo-16k": 16385,"gpt-3.5-turbo-16k-0613": 16385,"text-ada-001": 2049,"ada": 2049,"text-babbage-001": 2040,"babbage": 2049,"text-curie-001": 2049,"curie": 2049,"davinci": 2049,"text-davinci-003": 4097,"text-davinci-002": 4097,"code-davinci-002": 8001,"code-davinci-001": 8001,"code-cushman-002": 2048,"code-cushman-001": 2048,}
2. Prompts:管理 LLM 输入
from langchain import PromptTemplate, FewShotPromptTemplateexamples = [{"word": "高兴", "antonym": "悲伤"},{"word": "高大", "antonym": "矮小"},
]example_template =
"""
词语: {word}
反义词: {antonym}\n
"""example_prompt = PromptTemplate(input_variables=["word", "antonym"],template=example_template,
)few_shot_prompt = FewShotPromptTemplate(examples=examples,example_prompt=example_prompt,prefix="给出输入词语的反义词",suffix="词语: {input}\n反义词:",input_variables=["input"],example_separator="\n",
)few_shot_prompt.format(input="美丽")
#上面的代码将生成一个提示模板,并根据提供的示例和输入组成以下提示:#给出输入词语的反义词#词语: 高兴
#反义词: 悲伤#词语: 高大
#反义词: 矮小#词语: 美丽
#反义词:
3. Chains:将 LLM 与其他组件相结合,执行多个chain
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains import SimpleSequentialChain# location 链
llm = OpenAI(temperature=1)
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_location"], template=template)
location_chain = LLMChain(llm=llm, prompt=prompt_template)# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_meal"], template=template)
meal_chain = LLMChain(llm=llm, prompt=prompt_template)# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain(chains=[location_chain, meal_chain], verbose=True)
review = overall_chain.run("Rome")
4. Indexes:访问外部数据
访问外部数据,不得不介绍几个额外的,功能,就是langchain自带的几个模块。配合这几个小模块实现,外部数据的访问
a. Loader 加载器
这个就是从指定源进行加载数据的。比如:文件夹 DirectoryLoader、Azure 存储 AzureBlobStorageContainerLoader、CSV文件 CSVLoader、印象笔记 EverNoteLoader、Google网盘 GoogleDriveLoader、任意的网页 UnstructuredHTMLLoader、PDF PyPDFLoader、S3 S3DirectoryLoader/S3FileLoader、Youtube YoutubeLoader 等等,上面只是简单的进行列举了几个,官方提供了超级的多的加载器供你使用。
关于这里的官方介绍
#示例:
from langchain.document_loaders import UnstructuredFileLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI# 导入文本
loader = UnstructuredFileLoader("/content/sample_data/data/lg_test.txt")
# 将文本转成 Document 对象
document = loader.load()
print(f'documents:{len(document)}')
b. Document 文档(解决加载数据超过模型最大输入) 与 Text Spltters 文本分割
当使用loader加载器读取到数据源后,数据源需要转换成 Document 对象后,后续才能进行使用。
Text Spltters ,文本分割就是用来分割文本的。为什么需要分割文本?因为我们每次不管是做把文本当作 prompt 发给 openai api ,还是还是使用 openai api embedding 功能都是有字符限制的。
#示例:from langchain.document_loaders import UnstructuredFileLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI# 导入文本
loader = UnstructuredFileLoader("/content/sample_data/data/lg_test.txt")
# 将文本转成 Document 对象
document = loader.load()
print(f'documents:{len(document)}')# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500,chunk_overlap = 0
)# 切分文本
split_documents = text_splitter.split_documents(document)
print(f'documents:{len(split_documents)}')# 加载 llm 模型
llm = OpenAI(model_name="text-davinci-003", max_tokens=1500)# 创建总结链
chain = load_summarize_chain(llm, chain_type="refine", verbose=True)# 执行总结链,(为了快速演示,只总结前5段)
chain.run(split_documents[:5])
这里有几个参数需要注意:
-
文本分割器的
chunk_overlap参数
这个是指切割后的每个 document 里包含几个上一个 document 结尾的内容,主要作用是为了增加每个 document 的上下文关联。比如,chunk_overlap=0时, 第一个 document 为 aaaaaa,第二个为 bbbbbb;当 chunk_overlap=2 时,第一个 document 为 aaaaaa,第二个为 aabbbbbb。 -
chain 的 chain_type参数
这个参数主要控制了将 document 传递给 llm 模型的方式,一共有 4 种方式:
stuff: 这种最简单粗暴,会把所有的 document 一次全部传给 llm 模型进行总结。如果document很多的话,势必会报超出最大 token 限制的错,所以总结文本的时候一般不会选中这个。
map_reduce: 这个方式会先将每个 document 进行总结,最后将所有 document 总结出的结果再进行一次总结。
refine: 这种方式会先总结第一个 document,然后在将第一个 document 总结出的内容和第二个 document 一起发给 llm 模型在进行总结,以此类推。这种方式的好处就是在总结后一个 document 的时候,会带着前一个的 document 进行总结,给需要总结的 document 添加了上下文,增加了总结内容的连贯性。
map_rerank: 这种一般不会用在总结的 chain 上,而是会用在问答的 chain 上,他其实是一种搜索答案的匹配方式。首先你要给出一个问题,他会根据问题给每个 document 计算一个这个 document 能回答这个问题的概率分数,然后找到分数最高的那个 document ,在通过把这个 document 转化为问题的 prompt 的一部分(问题+document)发送给 llm 模型,最后 llm 模型返回具体答案。
d. Vectorstores 向量数据库
因为数据相关性搜索其实是向量运算。所以,不管我们是使用 openai api embedding 功能还是直接通过向量数据库直接查询,都需要将我们的加载进来的数据 Document 进行向量化,才能进行向量运算搜索。转换成向量也很简单,只需要我们把数据存储到对应的向量数据库中即可完成向量的转换。
官方也提供了很多的向量数据库供我们使用。
#示例:
from langchain.vectorstores import Chroma# 持久化数据
docsearch = Chroma.from_documents(documents, embeddings, persist_directory="D:/vector_store")
docsearch.persist()# 加载数据
docsearch = Chroma(persist_directory="D:/vector_store", embedding_function=embeddings)
e. Embedding
用于衡量文本的相关性。这个也是 OpenAI API 能实现构建自己知识库的关键所在。
他相比 fine-tuning 最大的优势就是,不用进行训练,并且可以实时添加新的内容,而不用加一次新的内容就训练一次,并且各方面成本要比 fine-tuning 低很多。
5. Memory:记住以前的对话
使用Memory实现一个带记忆的对话机器人
from langchain.memory import ChatMessageHistory
from langchain.chat_models import ChatOpenAIchat = ChatOpenAI(temperature=0)# 初始化 MessageHistory 对象
history = ChatMessageHistory()# 给 MessageHistory 对象添加对话内容
history.add_ai_message("你好!")
history.add_user_message("中国的首都是哪里?")# 执行对话
ai_response = chat(history.messages)
print(ai_response)
6. Agents:访问其他工具,自定义agent中所使用的工具
自定义agent中所使用的工具
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
from langchain.tools import BaseTool
from langchain.llms import OpenAI
from langchain import LLMMathChain, SerpAPIWrapperllm = OpenAI(temperature=0)# 初始化搜索链和计算链
search = SerpAPIWrapper()
llm_math_chain = LLMMathChain(llm=llm, verbose=True)# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [Tool(name = "Search",func=search.run,description="useful for when you need to answer questions about current events"),Tool(name="Calculator",func=llm_math_chain.run,description="useful for when you need to answer questions about math")
]# 初始化 agent
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)# 执行 agent
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")
三、经典示例
1. 最简单的交互
用 LangChain 加载 OpenAI 的模型,并且完成一次问答。我们需要先设置我们的 openai 的 key,这个 key 可以在用户管理里面创建。
import os
os.environ["OPENAI_API_KEY"] = '你的api key'
然后,我们进行导入和执行
from langchain.llms import OpenAIllm = OpenAI(model_name="text-davinci-003",max_tokens=1024)
llm("怎么评价人工智能")
2. 构建本地知识库问答机器人
从本地读取多个文档构建知识库,并且使用 Openai API 在知识库中进行搜索并给出答案。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain.document_loaders import DirectoryLoader
from langchain.chains import RetrievalQA# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader('/content/sample_data/data/', glob='**/*.txt')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma.from_documents(split_docs, embeddings)# 创建问答对象
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever(), return_source_documents=True)
# 进行问答
result = qa({"query": "科大讯飞今年第一季度收入是多少?"})
print(result)
3. 让输出内容 结构化起来
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAIllm = OpenAI(model_name="text-davinci-003")# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [ResponseSchema(name="bad_string", description="This a poorly formatted user input string"),ResponseSchema(name="good_string", description="This is your response, a reformatted response")
]# 初始化解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser.get_format_instructions()template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly{format_instructions}% USER INPUT:
{user_input}YOUR RESPONSE:
"""# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate(input_variables=["user_input"],partial_variables={"format_instructions": format_instructions},template=template
)promptValue = prompt.format(user_input="welcom to califonya!")
llm_output = llm(promptValue)# 使用解析器进行解析生成的内容
output_parser.parse(llm_output)
4. 使用 Hugging Face 模型
#使用 Hugging Face 模型之前,需要先设置环境变量
import os
os.environ['HUGGINGFACEHUB_API_TOKEN'] = ''
- 使用
在线的 Hugging Face 模型
from langchain import PromptTemplate, HuggingFaceHub, LLMChaintemplate = """Question: {question}
Answer: Let's think step by step."""prompt = PromptTemplate(template=template, input_variables=["question"])
llm = HuggingFaceHub(repo_id="google/flan-t5-xl", model_kwargs={"temperature":0, "max_length":64})
llm_chain = LLMChain(prompt=prompt, llm=llm)question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print(llm_chain.run(question))
- 将 Hugging Face 模型直接
拉到本地使用
from langchain import PromptTemplate, LLMChain
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, AutoModelForSeq2SeqLMmodel_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id)pipe = pipeline("text2text-generation",model=model,tokenizer=tokenizer,max_length=100
)local_llm = HuggingFacePipeline(pipeline=pipe)
print(local_llm('What is the capital of France? '))template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])llm_chain = LLMChain(prompt=prompt, llm=local_llm)
question = "What is the capital of England?"
print(llm_chain.run(question))
将模型拉到本地使用的好处:
训练模型
可以使用本地的 GPU
有些模型无法在 Hugging Face 运行
4. 通过自然语言执行SQL命令
我们通过 SQLDatabaseToolkit 或者 SQLDatabaseChain 都可以实现执行SQL命令的操作
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAIdb = SQLDatabase.from_uri("sqlite:///../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db)agent_executor = create_sql_agent(llm=OpenAI(temperature=0),toolkit=toolkit,verbose=True
)agent_executor.run("Describe the playlisttrack table")
from langchain import OpenAI, SQLDatabase, SQLDatabaseChaindb = SQLDatabase.from_uri("mysql+pymysql://root:root@127.0.0.1/chinook")
llm = OpenAI(temperature=0)db_chain = SQLDatabaseChain(llm=llm, database=db, verbose=True)
db_chain.run("How many employees are there?")
参考文献:
[1].https://blog.csdn.net/lht0909/article/details/130412875
[2].https://blog.csdn.net/v_JULY_v/article/details/131552592
[3].https://developer.aliyun.com/article/1221923
[4].https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/#jie-gou-hua-shu-chu
相关文章:

为什么是LangChain?
文章目录 一、前言二、认识langchain1. langchain的主要组成2. 总览LangChain2. LangChain的六大核心模块1. Models:模型统一接口2. Prompts:管理 LLM 输入3. Chains:将 LLM 与其他组件相结合,执行多个chain4. Indexes:…...
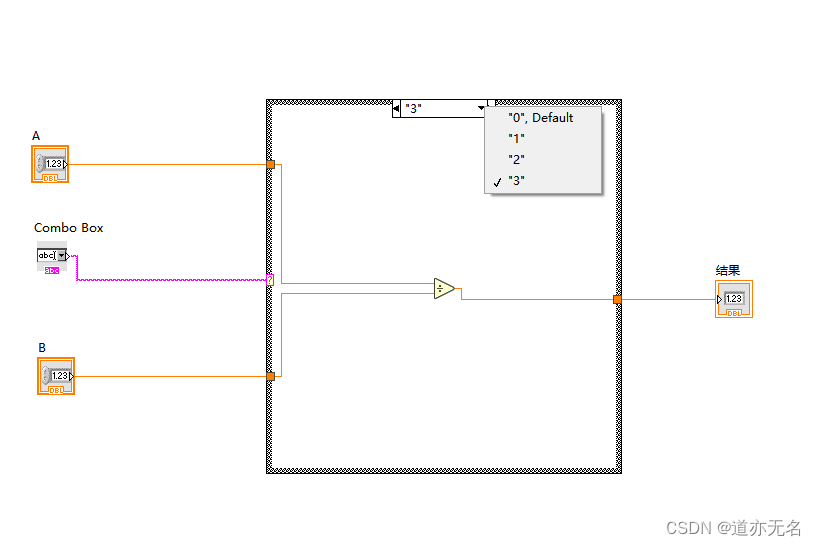
Labview的分支判断
和其他的编程语言一样的。都会有switch,case, if ,else; 再combo box中实现 再后台程序中对应的写上逻辑就好了。...

蓝桥杯双周赛算法心得——串门(双链表数组+双dfs)
大家好,我是晴天学长,树和dfs的结合,其邻接表的存图方法也很重要。需要的小伙伴可以关注支持一下哦!后续会继续更新的。💪💪💪 1) .串门 2) .算法思路 串门(怎么存图很关键…...

mysql 配置主从复制 及 Slave_SQL_Running = no问题排查
一、配置主数据库 1、在mysql 配置文件my.cnf中设置主数据库配置 server-id1 //唯一的标示符 log-binmysql-bin //开启二进制日志2、重启数据库 3、安全规范的写法是新建一个用户给这个用户复制的权限(直接用root也可以不建议) CREATE USER repl% IDEN…...

再获5G RedCap能力认证!宏电5G RedCap工业智能网关通过中国联通5G物联网OPENLAB开放实验室测试验证
近日,中国联通5G物联网OPENLAB开放实验室携手宏电股份完成5G RedCap工业智能网关端到端的测试验证,并颁发OPENLAB实验室面向RedCap终端的认证证书,为RedCap产业规模推广、全行业赋能打下坚实基础。 中国联通5G物联网OPENLAB开放实验室是中国…...

牛客--汽水瓶python
某商店规定:三个空汽水瓶可以换一瓶汽水,允许向老板借空汽水瓶(但是必须要归还)。 小张手上有n个空汽水瓶,她想知道自己最多可以喝到多少瓶汽水。 数据范围:输入的正整数满足 1≤n≤100 注意ÿ…...
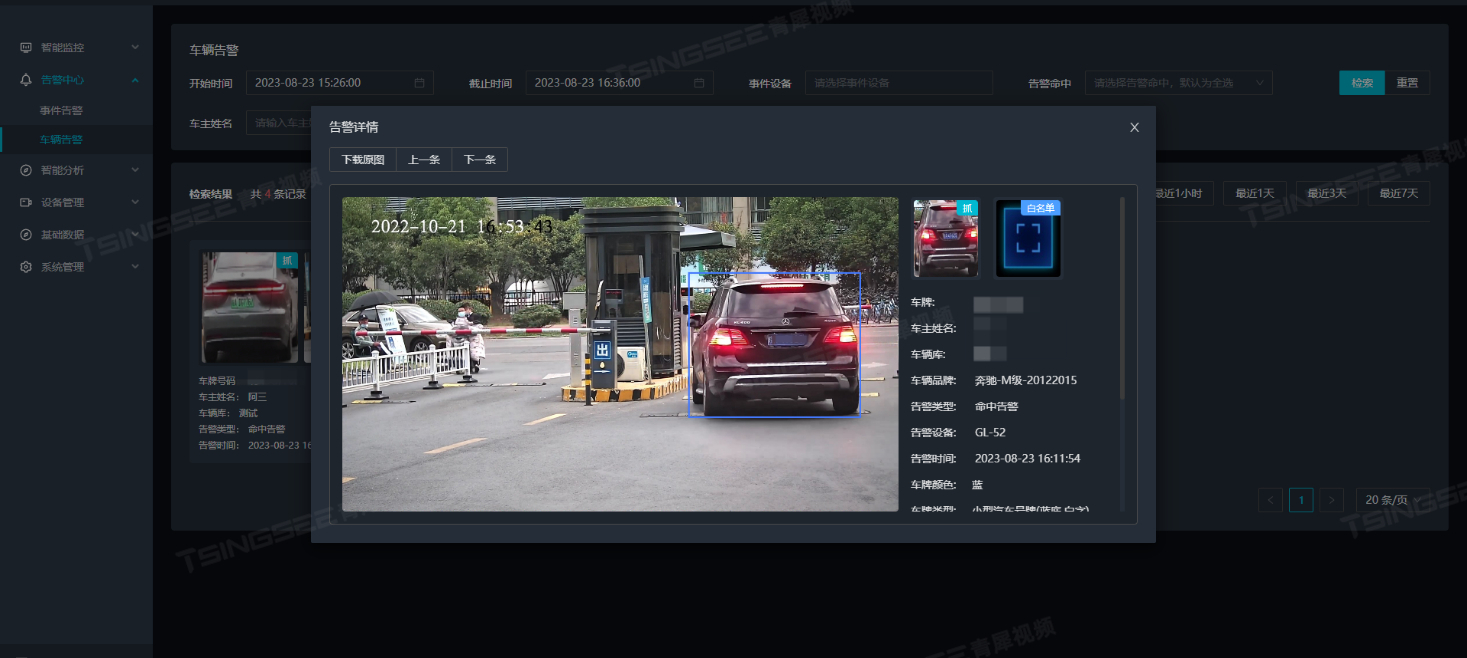
TSINGSEE智能分析网关V4车辆结构化数据检测算法及车辆布控
车辆结构化视频AI检测技术,可通过AI识别对视频图像中划定区域内的出现的车辆进行检测、抓拍和识别,系统通过视频采集设备获取车辆特征信息,经过预处理之后,接入AI识别算法并与车辆底库进行对比,快速识别车辆身份和属性…...
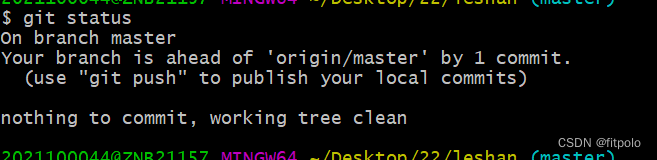
git解决冲突的方法。
1、 cherry-pick git fetch ssh://jingyou.caigerrit.transtekcorp.com:29418/leshan refs/changes/23/34123/3 && git cherry-pick FETCH_HEAD2、 文件解冲突! 3、 cherry-pick完整。 git cherry-pick --continue4、查看状态。 5、 push。 git push o…...

[MT8766][Android12] 取消WIFI热点超过10分钟没有连接自动关闭设定
文章目录 开发平台基本信息问题描述解决方法 开发平台基本信息 芯片: MT8766 版本: Android 12 kernel: msm-4.19 问题描述 之前有个需求要设备默认开启WIFI热点,默认开启usb共享网络;而热点在原生的设定里面有个超时机制,如果在限定时间内…...

智能中仍存在着许多未被发现的逻辑
自然规律不仅包括精确的也包括模糊的,即模糊的基本自然律意味着自然界中的现象与规律并不是绝对精确的,存在一定的模糊性和不确定性。因此,用数学来完全描述和预测这些现象可能会有限制。 智能与人工智能(AI)抑或智能化…...

基于公共业务提取的架构演进——外部依赖防腐篇
背景 有了前两篇的帐号权限提取和功能设置提取的架构演进后,有一个问题就紧接着诞生了,对于诸多业务方来说,关键数据源的迁移如何在各个产品落地? 要知道这些数据都很关键: - 对于帐号,获取不到帐号信息是…...
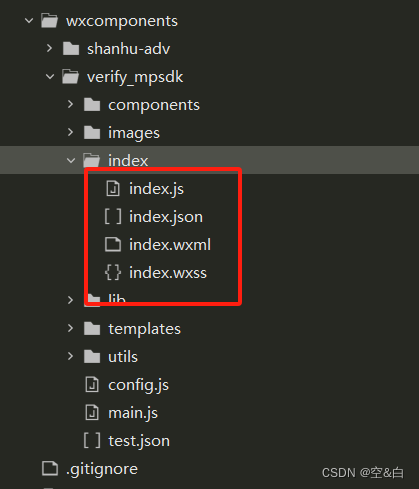
uniapp小程序接入腾讯云【增强版人脸核身接入】
文档地址:https://cloud.tencent.com/document/product/1007/56812 企业申请注册这边就不介绍了,根据官方文档去申请注册。 申请成功后,下载【微信小程序sdk】 一、解压sdk,创建wxcomponents文件夹 sdk解压后发现是原生小程序代…...

Sass 最基础的语法
把每个点最简单的部分记录一下,方便自己查找 官方文档链接 Sass 笔记 1. & 父选择器,编译后为父选择器2. : 嵌套属性3. $ 变量3.1 数据类型3.2 变量赋值3.3. 数组3.4. map 4. 算数运算符5. #{}插值语法5.1 可以在选择器或属性名中使用变量5.2 将有引…...

2023年11月数据库流行度最新排名
点击查看最新数据库流行度最新排名(每月更新) 2023年11月数据库流行度最新排名 TOP DB顶级数据库索引是通过分析在谷歌上搜索数据库名称的频率来创建的 一个数据库被搜索的次数越多,这个数据库就被认为越受欢迎。这是一个领先指标。原始数…...
JavaEE-部署项目到服务器
本部分内容为:安装依赖:JDK,Tomcat,Mysql;部署项目到服务器 什么是Tomcat Tomcat简单的说就是一个运行JAVA的网络服务器,底层是Socket的一个程序,它也是JSP和Serlvet的一个容器。 为什么我们需要…...

计算机网络期末复习-Part1
1、列举几种接入网技术:ADSL,HFC,FTTH,LAN,WLAN ADSL(Asymmetric Digital Subscriber Line):非对称数字用户线路。ADSL 是一种用于通过电话线连接到互联网的技术,它提供…...
Redis系列-Redis过期策略以及内存淘汰机制【6】
目录 Redis系列-Redis过期策略以及内存淘汰机制【6】redis过期策略内存淘汰机制算法LRU算法LFU 其他场景对过期key的处理FAQ为什么不用定时删除策略? Ref 个人主页: 【⭐️个人主页】 需要您的【💖 点赞关注】支持 💯 Redis系列-Redis过期策略以及内存淘…...

多语言翻译软件 Mate Translate mac中文版特色功能
Mate Translate for Mac是一款多语言翻译软件,Mate Translate mac可以帮你翻译超过100种语言的单词和短语,使用文本到语音转换,并浏览历史上已经完成的翻译。你还可以使用Control S在弹出窗口中快速交换语言。 Mate Translate Mac版特色功能…...

Python GUI标准库tkinter实现与记事本相同菜单的文本编辑器(一)
介绍: Windows操作系统中自带了一款记事本应用程序,通常用于记录文字信息,具有简单文本编辑功能。Windows的记事本可以新建、打开、保存文件,有复制、粘贴、删除等功能,还可以设置字体类型、格式和查看日期时间等。 …...
堆栈溢出异常)
Decimal.ToString()堆栈溢出异常
Decimal.ToString() 堆栈溢出异常 导致以下报错: A process serving application pool XXX suffered a fatal communication error with the Windows Process Activation Service. The process id was 7132. The data field contains the error number. Application pool …...

专业高考美术如何拿高分?拆解历年教学成果背后的质检工序
美术生的高分作品,往往是“质检”出来的很多家长认为艺术创作全凭感觉,但在高考美术的竞技场上,高分卷其实是高度标准化的产物。一份出色的历年教学成果,核心不在于学生画了多少张,而在于每一张画经历了怎样的“质检”…...

核能监管文档多模态AI检索系统开发与优化
1. 项目概述:面向核能监管文档的欧洲开源视觉语言模型优化在核能行业,技术文档与监管材料的处理一直是个棘手的挑战。想象一下,一位核电站安全工程师需要快速查找关于"反应堆800米外辐射限值"的具体规定——这通常意味着要在成堆的…...

AD布线层切换快捷键设置保姆级教程:从Customization菜单到肌肉记忆养成
AD布线层切换快捷键设置全攻略:从零基础到肌肉记忆养成 PCB设计工程师的日常工作中,布线层切换是最频繁的操作之一。每次右手离开鼠标去按小键盘的加减号,或是同时按住CtrlShift再滚动滚轮,这些看似微小的操作在一天数百次的重复中…...

**蓝绿部署实战:用 Go 实现无中断服务更新的优雅方案**在现代微服务架构中,**持续交
蓝绿部署实战:用 Go 实现无中断服务更新的优雅方案 在现代微服务架构中,持续交付(CD) 和 零停机发布(Zero Downtime Deployment) 已成为标配能力。而蓝绿部署(Blue-Green Deployment)…...

别再手动拉Excel报表了!用Power BI Desktop连接你的业务数据,5分钟生成动态看板
别再手动拉Excel报表了!用Power BI Desktop连接你的业务数据,5分钟生成动态看板 每周一早晨,市场部的李经理都要花两小时从CRM、ERP和网站后台导出十几个CSV文件,在Excel里用VLOOKUP拼接待客数据。当他把第5个版本的周报邮件发出时…...

AXI总线配置与SoC设计实战指南
1. AXI总线基础与配置参数解析AXI(Advanced eXtensible Interface)总线作为AMBA(Advanced Microcontroller Bus Architecture)协议家族的核心成员,已成为现代SoC设计的标准互连方案。其采用分离的地址/数据通道、支持乱…...
)
别再只用MAPE了!当预测值接近零时,试试这个更稳健的指标MAAPE(附Python代码示例)
别再只用MAPE了!当预测值接近零时,试试这个更稳健的指标MAAPE(附Python代码示例) 在零售库存预测、金融交易量分析或医疗设备需求规划中,数据科学家常常遇到一个棘手问题:当实际观测值接近零时,…...

我把 iOS 存钱 App 移植到鸿蒙:number 精度丢失坑了我两天
做了个什么东西 我有一个独立开发的存钱 App 叫「聚沙攒钱」,iOS 版上线快两年了。核心功能就是设一个储蓄目标,比如攒钱买耳机或者攒旅行基金,每次存钱会有硬币掉落动画,配合成就徽章和连续打卡,让存钱这件事不那么无…...

5分钟掌握MediaFire批量下载:Python脚本轻松下载整个文件夹
5分钟掌握MediaFire批量下载:Python脚本轻松下载整个文件夹 【免费下载链接】mediafire_bulk_downloader Script for bulk downloading entire mediafire folders for free using python. 项目地址: https://gitcode.com/gh_mirrors/me/mediafire_bulk_downloader…...
STM32串口高效通信实战:用HAL_UART_Transmit_IT+DMA打造不卡顿的日志输出系统
STM32串口高效通信实战:用HAL_UART_Transmit_ITDMA打造不卡顿的日志输出系统 在实时控制系统开发中,日志输出是调试和状态监控的重要手段。但当系统需要处理电机控制、传感器数据采集等高实时性任务时,传统的阻塞式串口打印往往会成为性能瓶颈…...