【论文阅读】Progressive Spatio-Temporal Prototype Matching for Text-Video Retrieval
资料链接
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Li_Progressive_Spatio-Temporal_Prototype_Matching_for_Text-Video_Retrieval_ICCV_2023_paper.pdf
代码链接:https://github.com/imccretrieval/prost
背景与动机

文章发表于ICCV 2023,来自中科大IMCC实验室。
文本-视频检索是近年来比较新兴的领域,随着多模态和大模型的发展,这一领域也迸发出了前所未有的潜力。目前的主流方法是学习一个joint embedding space,将视频和文本编码成特征向量,在空间中含义相近的向量的位置也是相近的,从而通过计算向量间相似度实现检索。本文梳理了近期的一些工作,主要分为以下三个方向:
细粒度匹配:单一的特征向量难以编码丰富的细节信息,需要进行更细粒度的视频文本匹配。
多模态特征:视频有着丰富的多模态信息,使用多种多模态特征可增强检索性能。
大规模预训练:近年来大规模预训练广泛应用,经过预训练的模型检索能力得到显著提升。
作者团队在这一问题上,主要着重于第一个方向的研究。

典型的解决方案是直接对齐整个视频与句子的特征,这会忽视视频内容与文本的内在关系。因此,匹配过程应当同时考虑细粒度的空间内容和各种时间语义事件。这就是细粒度的匹配。
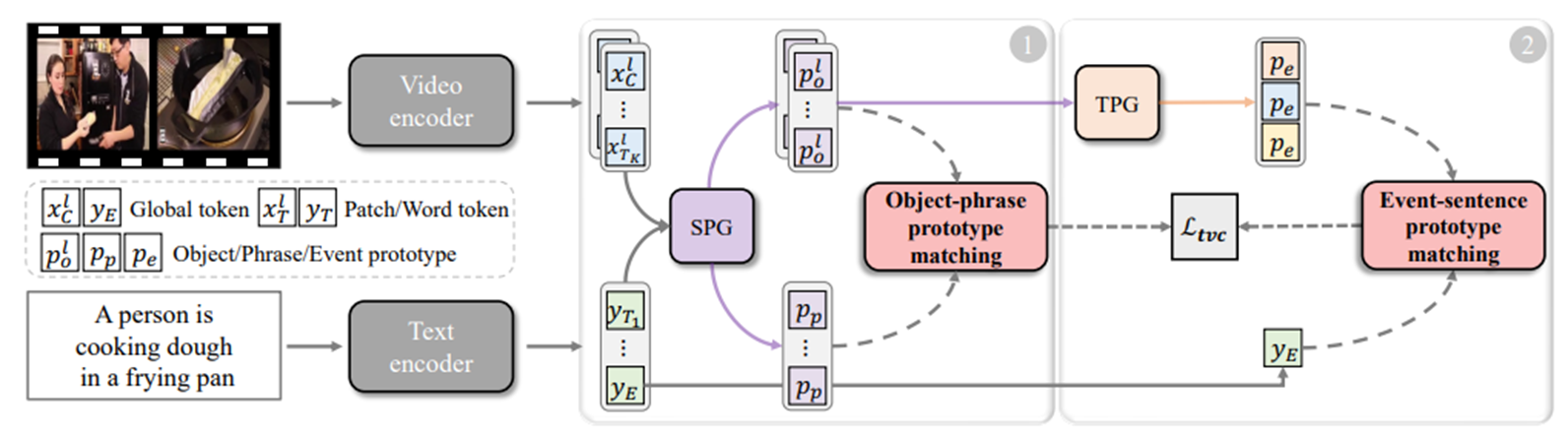
为此,作者团队提出一种具有渐进式时空原型匹配的文本-视频学习框架。它的大致框架如下:

方法
给定一个由n个视频![]() 以及它们对应的m个文本描述
以及它们对应的m个文本描述![]() 组成的数据集,文本-视频检索(TVR)旨在学习一个函数
组成的数据集,文本-视频检索(TVR)旨在学习一个函数![]() ,以有效地衡量模态之间的相似性。
,以有效地衡量模态之间的相似性。
对于文本查询![]() ,应当有:
,应当有: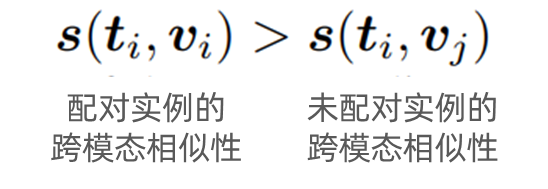
因此,需要强大的文本编码网络和视频编码网络来生成高质量的特征,从而实现有效的匹配。

采用 CLIP 作为骨干网络。给定输入视频,均匀地选择L个帧作为关键帧,提取连续特征:
![]()
其中![]() 是全局帧token特征,K是Patch数量,D是特征维数,Xi的Shape是(K+1) × D。
是全局帧token特征,K是Patch数量,D是特征维数,Xi的Shape是(K+1) × D。
给定查询文本,添加开始token和结束token,输出文本token特征可以定义为:
![]()
其中,![]() 是全局文本token特征,M和D分别是单词和特征维数,yi的Shape是(M+2) × D。
是全局文本token特征,M和D分别是单词和特征维数,yi的Shape是(M+2) × D。
方法 - 总体框架
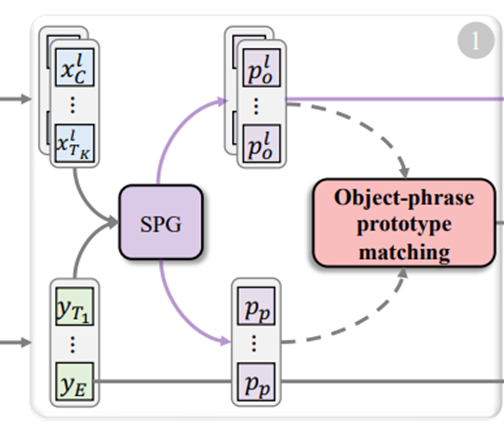
对象-短语原型匹配阶段
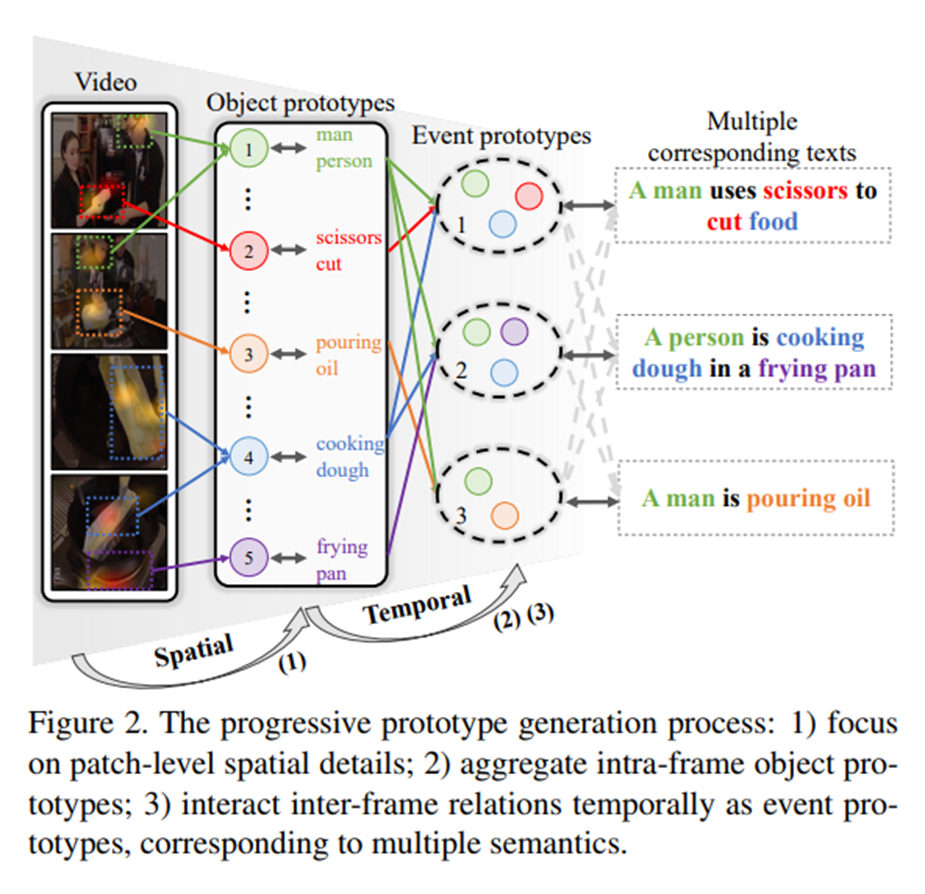
空间原型生成机制预测关键Patch或单词,这些Patch或单词被聚合成对象或短语原型。重要的是,优化对象-短语原型之间的局部对齐有助于模型感知空间细节。
事件-句子原型匹配阶段
设计了一个时间原型生成机制,将帧内对象与帧间时间关系相互关联。这样逐步生成的事件原型可以揭示视频中的语义多样性,用于动态匹配。
方法 - 对象短语原型匹配
相较于现有方法学习一个单一的Patch-Event投影,作者团队使用分而治之的方式解耦时空建模过程。
首先进行Patch-对象和单词-短语的空间原型聚合,来揭示关键的局部细节。
分为两个步骤:
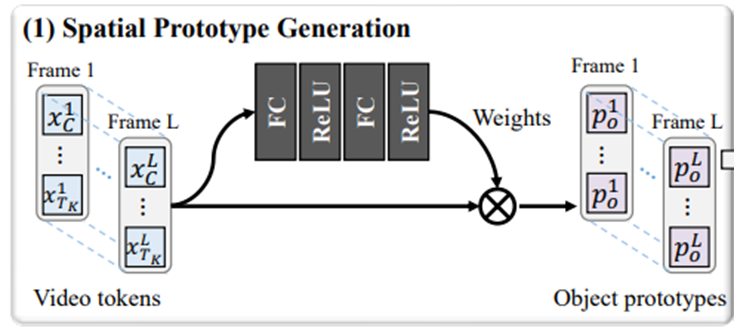
空间原型生成 Spatial Prototype Generation(SPG)
对于Patch特征,首先需要生成它们的空间对象原型:
使用两个全连接(FC)层和ReLU函数来预测稀疏权重![]() ,其中No是对象原型的数目,这样就可以避免对象原型受到冗余Patch的影响,从而使得对象原型更准确、集中。
,其中No是对象原型的数目,这样就可以避免对象原型受到冗余Patch的影响,从而使得对象原型更准确、集中。
![]() 其中,Po为对象原型, Shape为No×D。
其中,Po为对象原型, Shape为No×D。
对于文本,同样借鉴SPG机制,并设计了一个类似的网络结构来聚合单词标记,生成短语原型![]() 。
。
对象-短语匹配 Object-Phrase Matching
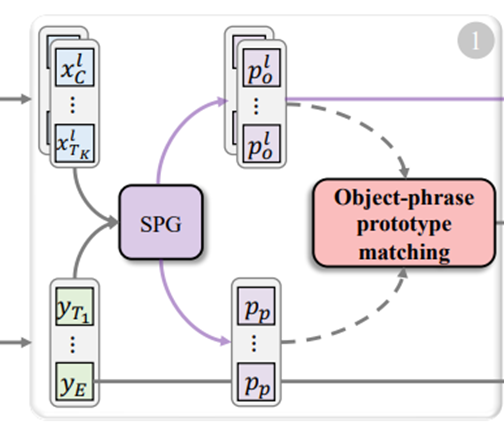
基于上一步骤生成的对象、文本原型,实现对象-短语原型匹配。
计算每个帧内的对象-短语原型的最大相似度,将最相似的短语原型和每个对象原型关联起来,反映了跨模态的细粒度分配。
然后,对于多帧对象相似度矩阵,找到跨帧序列的最大相似度分数,得到置信度更高的对象-短语匹配概率。最后将匹配得分求和,得到最终的相似性Sop:
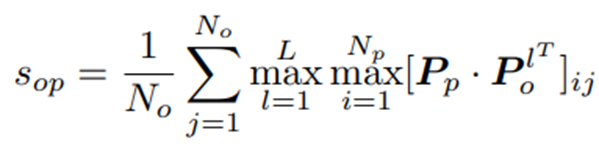
其中,No是对象原型的数量、Np是短语原型的数量、L是帧的数量。
这一部分的矩阵处理细节如下所示:
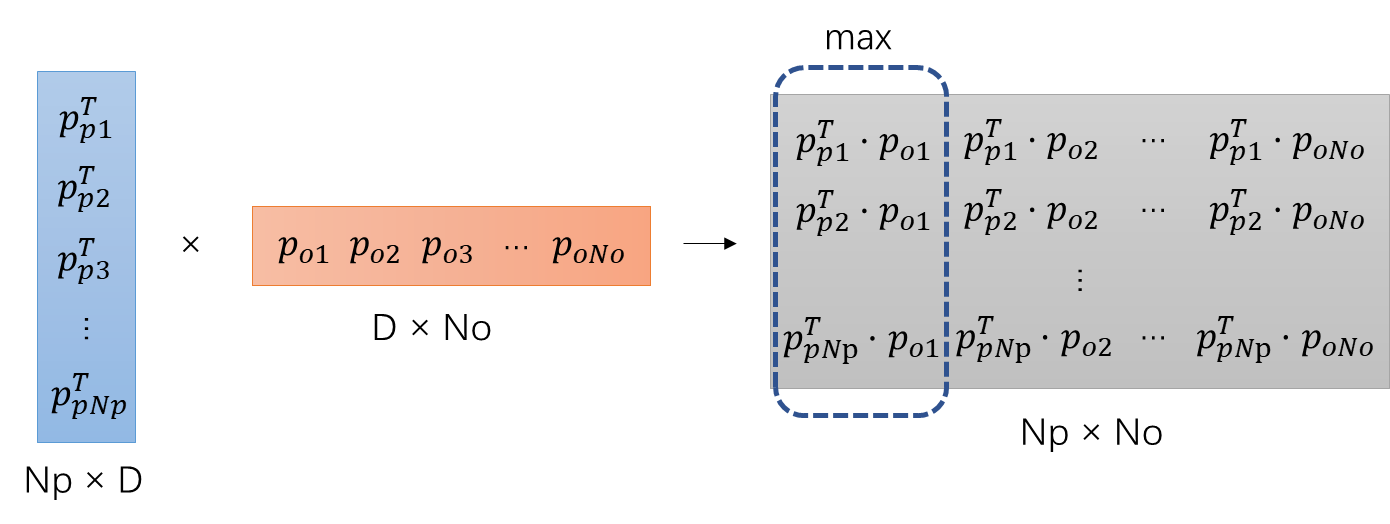
Pp与Po相乘以后,得到的矩阵首先按列取最大值,得到下面的矩阵:
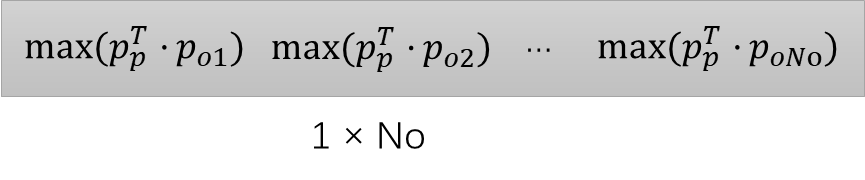
它的含义是,对于每个对象原型![]() ,其与短语原型的最大相似度。
,其与短语原型的最大相似度。
然后,对于每个关键帧都有一个上述的矩阵,在跨帧之间再取对于每个对象原型与短语原型的最大相似度,从而得到置信度更高的对象-短语匹配分数:
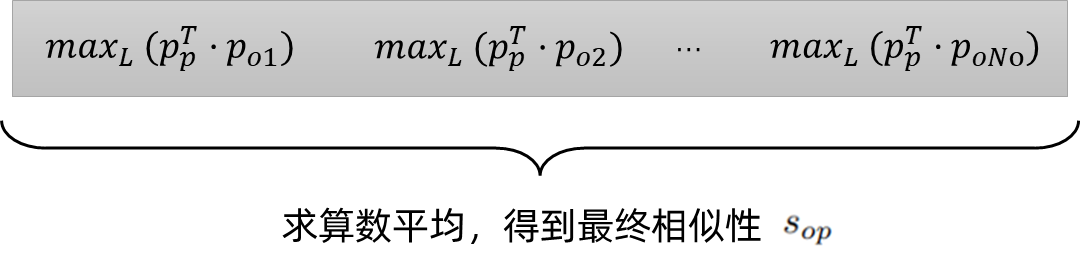
方法 – 事件句子原型匹配
接下来,到了事件句子原型匹配阶段。
时间原型生成 Temporal Prototype Generation(TPG)
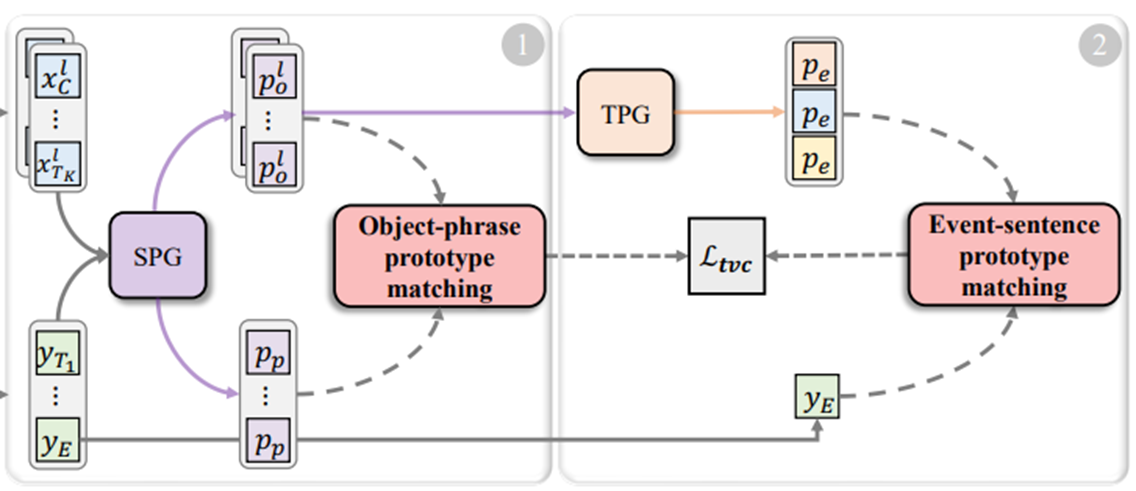
直接基于全局帧特征获得视频级特征会导致模型不能感知局部细节,并且只能得到单一的视频级特征。
作者团队提出一种渐进式的方法,逐步将对象原型聚合到帧原型中,然后进行帧间交互,以生成各种事件原型。
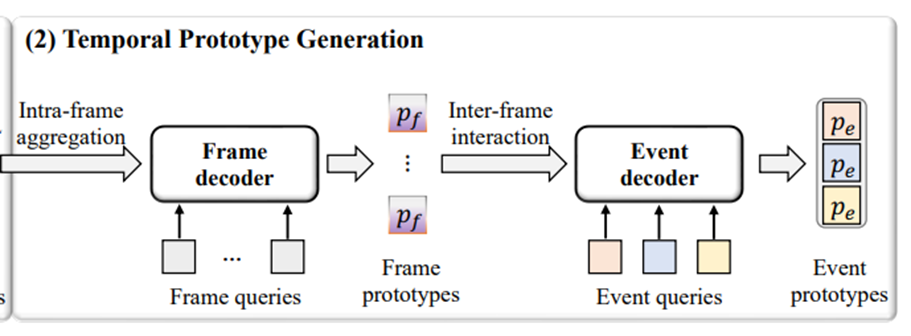
首先设计一个帧解码器,将所有对象原型![]() 聚合到帧级原型
聚合到帧级原型![]() 中:
中:
![]()
其中,![]() 是帧Query(Learnable),Ko和Vo是对象原型Po的线性变换后的特征。
是帧Query(Learnable),Ko和Vo是对象原型Po的线性变换后的特征。
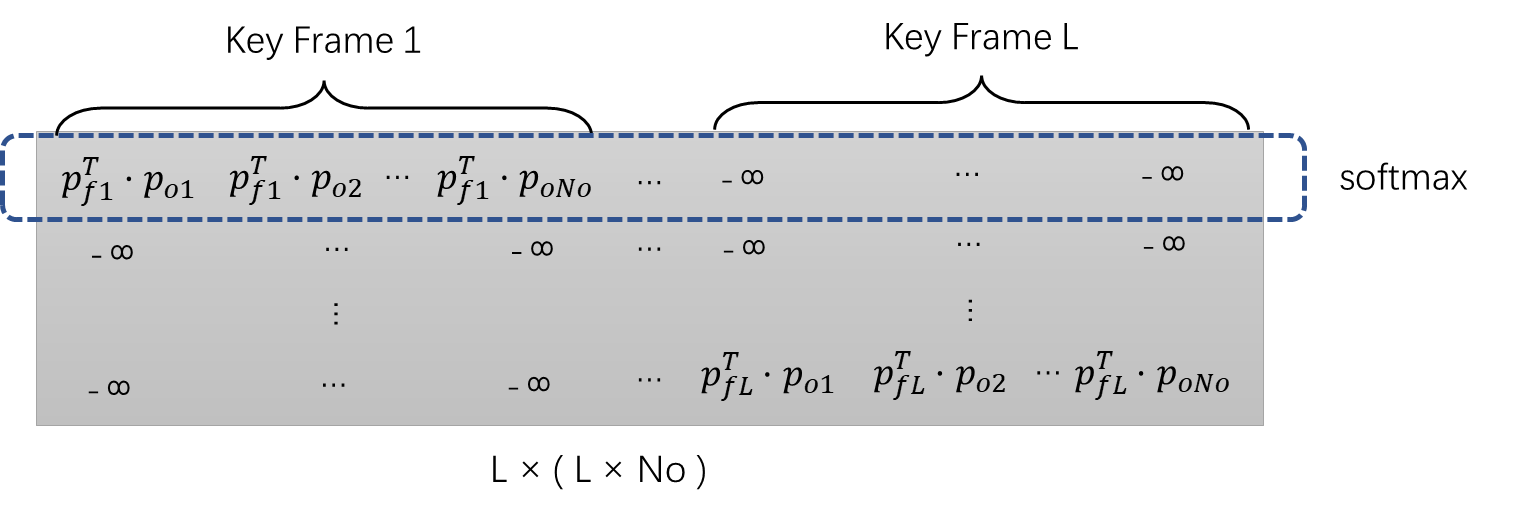
注意力掩码![]() 的定义是:
的定义是:
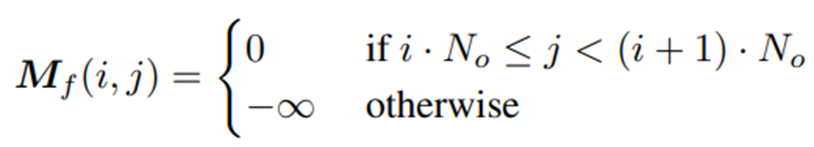
这一部分的矩阵处理细节如下所示:


注意观察Mf与![]() 的关联,可以理解它的作用是使得注意力仅存在于同一帧的对象原型之间,从而不受到其他帧的对象原型的干扰。
的关联,可以理解它的作用是使得注意力仅存在于同一帧的对象原型之间,从而不受到其他帧的对象原型的干扰。

![]()
Softmax后的权重再乘以对应帧的𝑣𝑜,从而得到帧原型矩阵Pf,形状为(L × D)
后面使用全局帧信息Qf进行一个Residual Connection。
将帧原型pf和相应帧的原始全局特征xc相加,以增强模型的稳健性:![]()
然后,使用一个动态事件解码器来学习Pf中的帧间关系,它可以获得不同的事件原型![]() 来展示视频的丰富信息。
来展示视频的丰富信息。
其中,![]() 是事件Query(Learnable),Kf和Vf是帧原型Pf的线性变换后的特征。
是事件Query(Learnable),Kf和Vf是帧原型Pf的线性变换后的特征。
在训练过程中,每个事件Query都学习如何自适应地聚焦于视频帧原型,而多个Query隐含地保证了一定的事件多样性。
事件句子匹配 Event-Sentence Matching
由于同一个视频通常对应多个文本语义描述,我们直接使用全局文本表示yE作为句子原型与事件原型Pe进行对齐,找到句子原型与事件原型的最大相似度,作为最终的相似性Ses:
![]()
方法 – 训练与推断
训练阶段
采用InfoNCE损失函数来优化batch内的原型匹配。将文本-视频对视为正样本,同时考虑batch内的其他成对组合作为负样本:
![]()
其中,Sop、Ses分别为来自 对象短语原型匹配 和 事件句子原型匹配阶段 的 对象-短语原型相似度 和 句子-事件原型相似度 。

推理阶段
直接对最终相似度匹配加权了时空匹配得分:![]()
其中![]() 是空间匹配因子。
是空间匹配因子。
实验 – 评价指标与结果
Recall@K (R@K)
这个指标衡量在前K个检索结果中正确匹配的比例。
Median Rank (MdR)
中位数排名指标表示正确匹配项在所有检索结果中的中位数排名。
Mean Rank (MnR)
平均排名指标表示所有正确匹配项在所有检索结果中的平均排名。
实验 – 消融实验
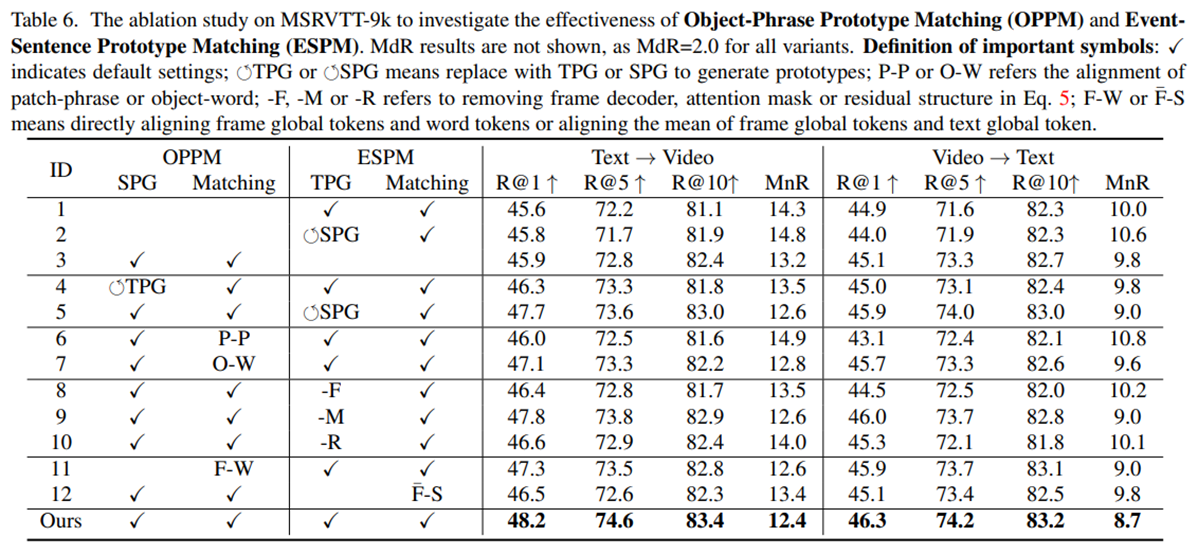
- 只使用ESPM时,R@1下降了2.6个点,证实了细粒度空间细节对于ESPM的补充作用。
- 只使用OPPM时,模型性能仍然较差,因为其缺乏对时间的理解,无法解决关系模糊性。
- 将SPG替换为TPG,性能下降说明了原始视频标记中存在冗余,SPG能够有效地过滤冗余信息。
- 将TPG替换为SPG,性能下降说明了帧间信息的交互对于生成更好得到事件原型是很重要的
- -F、-M、-R(移除帧解码器、attention mask、残差连接)的结果下降,表明帧内的局部对象关系和全局帧特征共同补充了全面的帧级空间信息。
- P-P、O-W(使用patch-phrase或object-word,而不是原型)表明使用原型匹配能减缓模态对齐问题。
- F-W、F-S(直接使用CLS或直接使用平均池化获得帧token)会影响信息的细节,从而降低性能。
- 在原型数量的设置上,也进行了实验,最后确定了最好的原型配置。表明在原型太多时会引入局部噪音,而太少时则无法表达语义。
- 同时也针对空间匹配因子β做了测试,找到了最合适的β值。表明需要同时合理地利用底层细粒度的空间信息和时间原型匹配,才能得到好的结果。
实验 – 定性分析
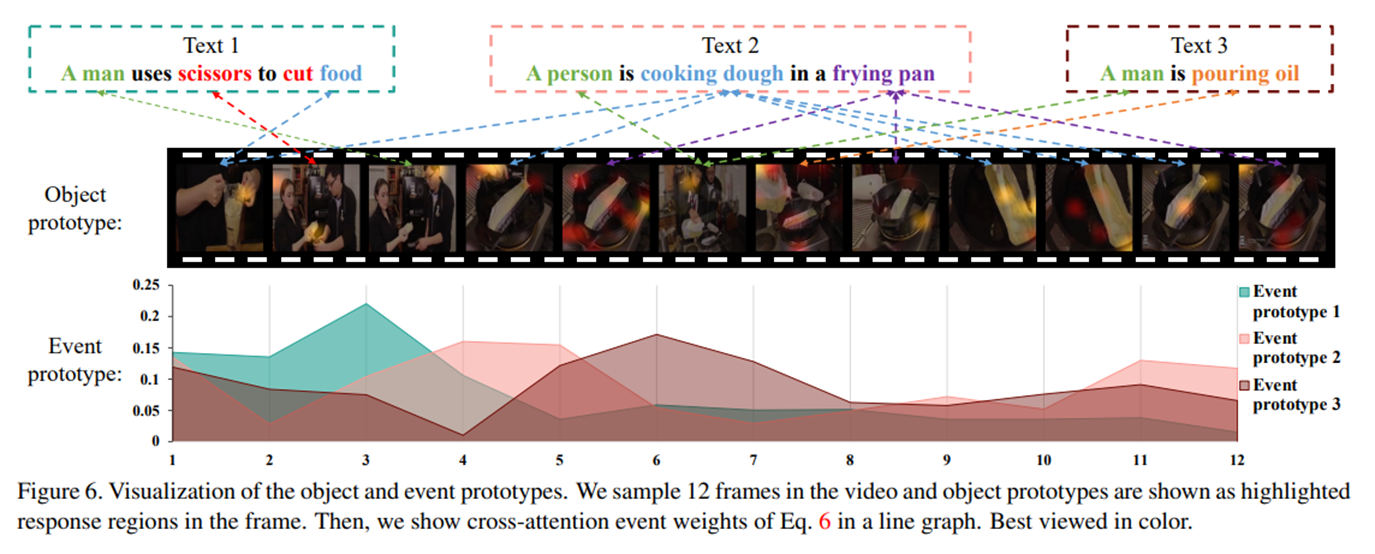
原型可视化
通过对象原型和时间原型的可视化图片,可以看见它们之间具体的匹配关系。可以看到不同的事件原型在不同帧上的权重差异很大,说明模型能够学习到时间关系。

检索结果
通过举例分析说明了对象-短语原型匹配提供了重要的细粒度空间知识,从而能够给出更好的查询结果。
总结
提出了一种新颖的文本-视频检索框架,称为ProST,将匹配过程分解为互补的对象-短语和事件-句子原型对齐。
在对象-短语原型匹配阶段,设计了空间原型生成机制,以便专注于重要的视频内容并加强精细的空间对齐。
在事件-句子原型匹配阶段,他们使用时间原型生成机制逐渐生成多样化的事件原型,并学习动态的一对多关系。
希望通过这篇论文不仅能够提供有关互补的时空匹配的重要性的见解,还能够促进未来的研究,通过解决设计缺陷而不是主要是尝试和错误来推动文本-视频检索领域的进展。
个人感受
读完这篇文章,唯一的感觉就是太花了,实在是太花了。学习之路任重而道远!
相关文章:
【论文阅读】Progressive Spatio-Temporal Prototype Matching for Text-Video Retrieval
资料链接 论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Li_Progressive_Spatio-Temporal_Prototype_Matching_for_Text-Video_Retrieval_ICCV_2023_paper.pdf 代码链接:https://github.com/imccretrieval/prost 背景与动机 文章发…...
)
python --- 类与对象(二)
类属性与方法 类的私有属性 __private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。 类的方法 在类的内部,使用 def 关键字来定义一个方法…...
任正非说:华为以前还出现过可笑的工号文化,看官大官小的指令
你好!这是华研荟【任正非说】系列的第33篇文章,让我们聆听任正非先生的真知灼见,学习华为的管理思想和管理理念。 一、要把可以规范化的管理都变成扳铁路道岔,使岗位操作标准化、制度化。 来源于任正非先生2003年的讲话《在理性与…...

用Python舞动数据的魔力:探索数据分析的艺术之路
用Python舞动数据的魔力:探索数据分析的艺术之路 前言什么是Python数据分析Python介绍数据分析介绍Python和数据分析的关系 python数据分析的作用金融领域社交媒体领域电子商务领域医疗领域物流和供应链管理领域 Python数据分析教材 前言 打开招聘网站,…...
iOS 让界面元素的文字随着语言的更改而变化——本地化文字跟随
在我的 App 内置的设置中,修改了语言,这时需要让当前界面的文本跟着改变语言。 解决方法是:添加一个观察者,观察 localize 本地语言的通知,然后一有变化就调用自定义的方法执行操作。(而设置中其实是改变了…...

Xcode15更新内容
参考博客: 【WWDC 2023】Xcode 15 更新内容 文章目录 1. xcode15起,项目内创建的图片可以使用点语法访问2.2. UIKit项目也可以使用预览功能3. Xcode新增标签功能4.Log分类 1. xcode15起,项目内创建的图片可以使用点语法访问 2.2. UIKit项目也…...

【数据集标注制作】视频剪切标注1——类DarkLabel软件
视频标注 用于从视频中标注数据,用于YOLO网络的目标检测。旨在实现单次鼠标标注能生成多张被标注图像,实现数据集快速制作! 从视频中,通过鼠标框选指定区域,形成掩码box鼠标选定区域后,根据设定的成像尺寸…...
一体化HIS医疗信息管理系统源码:云HIS、云电子病历、云LIS
基于云计算技术的B/S架构的HIS系统,为医疗机构提供标准化的、信息化的、可共享的医疗信息管理系统,实现医患事务管理和临床诊疗管理等标准医疗管理信息系统的功能。系统利用云计算平台的技术优势,建立统一的云HIS、云病历、云LIS,…...

NSSCTF逆向题解
[SWPUCTF 2021 新生赛]简简单单的逻辑 直接把key打印出来,然后整理一下result,让key和result进行异或 key[242,168,247,147,87,203,51,248,17,69,162,120,196,150,193,154,145,8] data[0xbc,0xfb,0xa4,0xd0,0x03,0x8d,0x48,0xbd,0x4b,0x00,0xf8,0x27,0x…...

广域网加速的作用:企业为什么需要广域网加速?
由于局域网与广域网之间巨大的带宽鸿沟,通过增加带宽来满足膨胀的流量需求是不切实际的。 并且广域网带宽成本较高,增加广域网带宽对任何企业都意味着巨大的成本负担。这些使得控制 管理广域网带宽使用成为必需。 企业为什么要加速广域网? 对重要的企…...
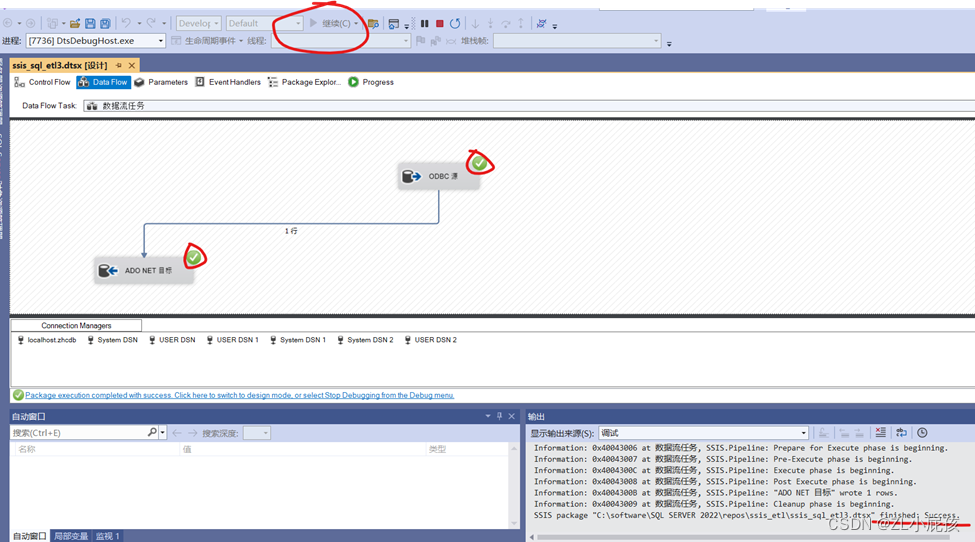
SQL SERVER Inregration Services-OLE DB、Oracle和ODBC操作
OLE DB链接器 OLE DB插件下载:https://learn.microsoft.com/zh-cn/sql/connect/oledb/download-oledb-driver-for-sql-server?viewsql-server-ver16 配置OLE DB Connection Manager 在点击“新建”时,会弹出警告信息“不支持指定的提供程序࿰…...
尚硅谷大数据项目《在线教育之实时数仓》笔记006
视频地址:尚硅谷大数据项目《在线教育之实时数仓》_哔哩哔哩_bilibili 目录 第9章 数仓开发之DWD层 P041 P042 P043 P044 P045 P046 P047 P048 P049 P050 P051 P052 第9章 数仓开发之DWD层 P041 9.3 流量域用户跳出事务事实表 P042 DwdTrafficUserJum…...

Linux-源码安装go
使用go 1.14 版本 #wget https://golang.org/dl/go1.14.15.linux-amd64.tar.gz #tar zxvf go1.14.15.linux-amd64.tar.gz #mv go /usr/local/ #vim /etc/profile export GOROOT/usr/local/go export GOBIN$GOROOT/bin export GOPKG$GOROOT/pkg/tool/linux_amd64 export GO…...

如何检测小红书账号是否被限流?哪些原因会导致账号被限流?
hi,同学们,本期是第5期AI运营技巧篇,文章底部准备了粉丝福利,看完后可领取! 最近好多新手学员运营小红书账号,可能会遇到这样的问题:发布的内容小眼睛少得可怜?搜索不到自己的笔记&…...
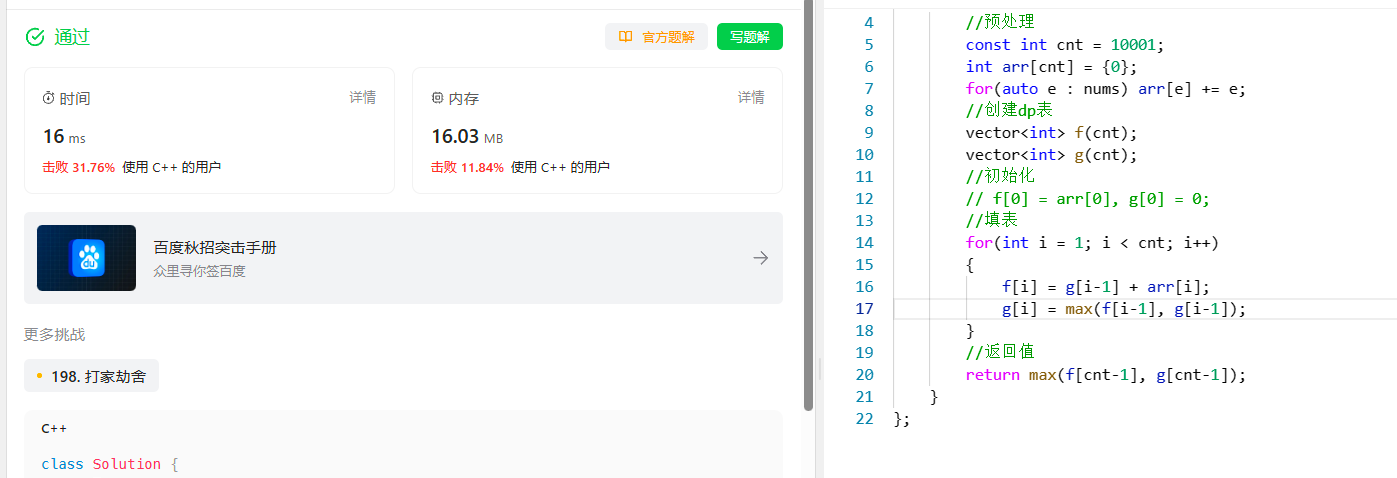
[动态规划] (十三) 简单多状态 LeetCode 740.删除并获得点数
[动态规划] (十三) 简单多状态: LeetCode 740.删除并获得点数 文章目录 [动态规划] (十三) 简单多状态: LeetCode 740.删除并获得点数题目解析解题思路状态表示状态转移方程初始化和填表顺序返回值 代码实现总结 740. 删除并获得点数 题目解析 (1) 给定一个整数数组。 (2) 选…...
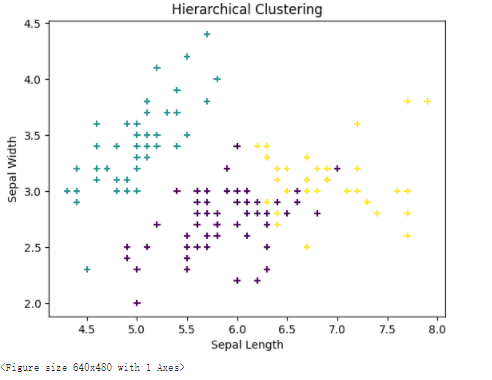
【K-means聚类算法】实现鸢尾花聚类
文章目录 前言一、数据集介绍二、使用步骤1.导包1.2加载数据集1.3绘制二维数据分布图1.4实例化K-means类,并且定义训练函数1.5训练1.6可视化展示2.聚类算法2.1.可视化生成3其他聚类算法进行鸢尾花分类 前言 例如:随着人工智能的不断发展,机器…...
什么是代理IP池?如何判断IP池优劣?
代理池充当多个代理服务器的存储库,提供在线安全和匿名层。代理池允许用户抓取数据、访问受限制的内容以及执行其他在线任务,而无需担心被检测或阻止的风险。代理池为各种在线活动(例如网页抓取、安全浏览等)提高后勤保障。 读完…...

【面经】讲一下线程池的参数和运行原理
线程池是Java中一种重要的并发工具,它可以帮助我们更好地管理线程,避免线程过多导致的系统开销和性能问题。线程池通过预先创建一定数量的线程,并将任务提交给这些线程执行,从而避免了频繁创建和销毁线程的开销。 线程池的参数主…...

针对图像分类的数据增强方法,离线增强,适合分类,无标签增强
针对图像分类的数据增强方法,离线增强,适合分类,无标签增强 代码: 改变路径即可使用 # 本代码主要提供一些针对图像分类的数据增强方法# 1、平移。在图像平面上对图像以一定方式进行平移。 # 2、翻转图像。沿着水平或者垂直方向…...
润色论文Prompt
你好,我现在开始写论文了,我希望你可以扮演帮我润色论文的角色我写的论文是关于xxxxx领域的xxxxx,我希望你能帮我检查段落中语句的逻辑、语法和拼写等问题我希望你能帮我检查以下段落中语句的逻辑、语法和拼写等问题同时提供润色版本以符合学…...

生产节拍混乱,在制品积压严重该怎么破解?——2026制造业柔性生产与Agent自动化实战指南
在2026年的工业4.0深化阶段,制造企业面临的市场环境已发生剧变。 消费者对个性化、定制化产品的需求,迫使工厂从“大批量流水线”全面转向“小批量、多批次”的柔性生产模式。 然而,许多企业在转型中陷入了生产节拍混乱与在制品(W…...

终极解决方案:30秒快速重置JetBrains IDE试用期,免费延长开发工具使用时间
终极解决方案:30秒快速重置JetBrains IDE试用期,免费延长开发工具使用时间 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经因为JetBrains IDE试用期到期而中断开发工作ÿ…...

增量式知识图谱持续构建系统应用【附代码】
(1)面向火电厂故障文档的实体关系联合抽取模型: 针对故障文本中实体特征稀疏和实体嵌套问题,提出了一种融合双向编码表示与跨层记忆网络的关系抽取模型。采用预训练语言模型作为底层编码器,获取上下文相关的字向量表示…...

【Backend Flow工程实践 12】Collection / Property / Filter:为什么对象查询能力决定 Backend 脚本工程上限?
作者:Darren H. Chen 方向:Backend Flow / 后端实现流程 / EDA 工具工程 / Tcl 脚本工程 demo:LAY-BE-12_collection_property_filter 标签:Backend Flow、EDA、Tcl、Collection、Property、Filter、Design Object Model、后端实现…...

NVIDIA Profile Inspector 完整指南:解锁显卡隐藏性能的10个专业技巧
NVIDIA Profile Inspector 完整指南:解锁显卡隐藏性能的10个专业技巧 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector 是一款强大的开源工具,专为追求极…...

视觉语言模型在图表密集对齐任务中的扩展规律研究
1. 视觉语言模型在图表密集对齐任务中的表现规律 视觉语言模型(VLMs)在图表理解任务中展现出了令人惊讶的扩展规律。最近的研究发现,在大多数密集对齐子任务中,VLMs遵循着明显的规模扩展规律——随着模型参数量的增加,…...

终极指南:如何快速将网页转换为可编辑的Figma设计稿
终极指南:如何快速将网页转换为可编辑的Figma设计稿 【免费下载链接】figma-html Convert any website to editable Figma designs 项目地址: https://gitcode.com/gh_mirrors/fi/figma-html 你是否曾经想要将任何网站的设计快速转换为Figma中的可编辑图层&a…...

【优化分配】基于遗传算法GA求解多因素加权竞价博弈频谱分配优化问题附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书…...
)
实测雷达数据处理避坑:用MATLAB手把手教你计算信噪比(附代码与数据)
雷达数据处理实战:信噪比计算中的关键陷阱与MATLAB解决方案 雷达信号处理中,信噪比(SNR)是评估系统性能的核心指标之一。但看似简单的功率比值计算,在实际操作中却暗藏诸多陷阱。本文将从一个工程师的实际项目复盘视角,剖析雷达数…...

微信数据安全终极指南:理解数据保护与合规使用
微信数据安全终极指南:理解数据保护与合规使用 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 在数字时代,微信聊天记录承载着我们的工作沟通、个人回忆和重要信息,数据安全与隐私保护成…...