【K-means聚类算法】实现鸢尾花聚类
文章目录
- 前言
- 一、数据集介绍
- 二、使用步骤
- 1.导包
- 1.2加载数据集
- 1.3绘制二维数据分布图
- 1.4实例化K-means类,并且定义训练函数
- 1.5训练
- 1.6可视化展示
- 2.聚类算法
- 2.1.可视化生成
- 3其他聚类算法进行鸢尾花分类
前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、数据集介绍
鸢尾花数据集:鸢尾花开源数据集,共包含150条记录
二、使用步骤
1.导包
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
1.2加载数据集
# 直接从sklearn中获取数据集
iris = datasets.load_iris()
X = iris.data[:, :4] # 表示我们取特征空间中的4个维度
print(X.shape)
1.3绘制二维数据分布图
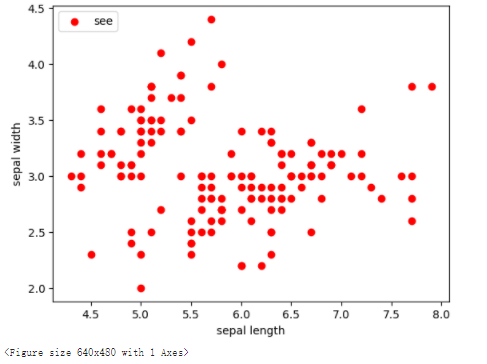
# 取前两个维度(萼片长度、萼片宽度),绘制数据分布图
plt.scatter(X[:, 0], X[:, 1], c="red", marker='o', label='see')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
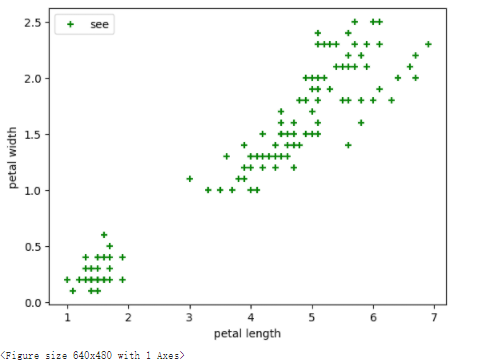
# 取后两个维度(花瓣长度、花瓣宽度),绘制数据分布图
plt.scatter(X[:, 2], X[:, 3], c="green", marker='+', label='see')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()
1.4实例化K-means类,并且定义训练函数
def Model(n_clusters):estimator = KMeans(n_clusters=n_clusters)# 构造聚类器return estimatordef train(estimator):estimator.fit(X) # 聚类
1.5训练
# 初始化实例,并开启训练拟合
estimator=Model(4)
train(estimator)
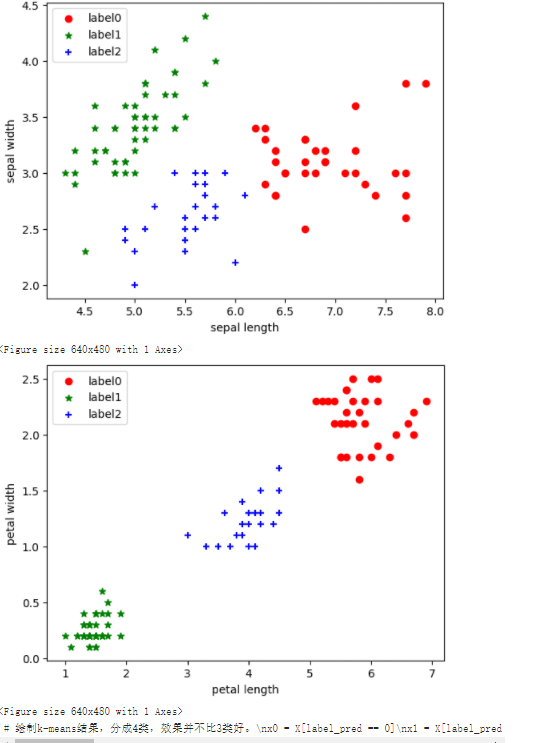
1.6可视化展示
label_pred = estimator.labels_ # 获取聚类标签
# 绘制k-means结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show() # 绘制k-means结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 2], x0[:, 3], c="red", marker='o', label='label0')
plt.scatter(x1[:, 2], x1[:, 3], c="green", marker='*', label='label1')
plt.scatter(x2[:, 2], x2[:, 3], c="blue", marker='+', label='label2')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show() '''# 绘制k-means结果,分成4类,效果并不比3类好。
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
x3 = X[label_pred == 3]
plt.scatter(x0[:, 2], x0[:, 3], c="red", marker='o', label='label0')
plt.scatter(x1[:, 2], x1[:, 3], c="green", marker='*', label='label1')
plt.scatter(x2[:, 2], x2[:, 3], c="blue", marker='+', label='label2')
plt.scatter(x2[:, 2], x2[:, 3], c="yellow", marker='X', label='label3')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show() '''
2.聚类算法
代码如下(示例):
#1. 函数distEclud()的作用:用于计算两个向量的距离def distEclud(x,y):return np.sqrt(np.sum((x-y)**2)) #2. 函数randCent()的作用: 用来为给定的数据集构建一个包含k个随机质心的集合
def randCent(dataSet,k):# 3.m,n分别被赋值为?# m = 150 ,n = 4m,n = dataSet.shape centroids = np.zeros((k,n))#4.补充range()中的参数for i in range(k): index = int(np.random.uniform(0,m)) # 产生0到150的随机数(在数据集中随机挑一个向量做为质心的初值)centroids[i,:] = dataSet[index,:] #把对应行的四个维度传给质心的集合# print(centroids) return centroids# k均值聚类算法
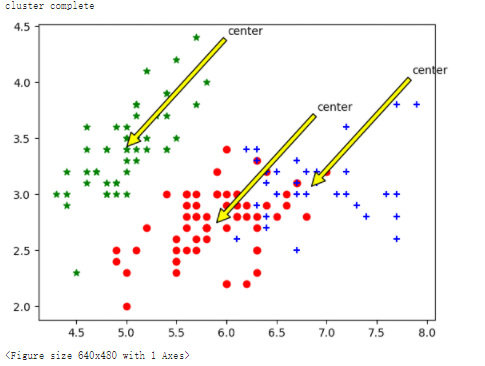
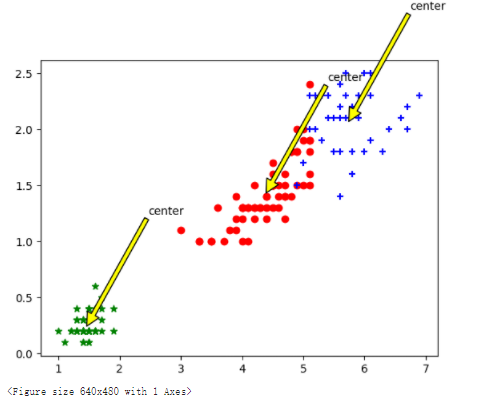
def KMeans(dataSet,k): m = np.shape(dataSet)[0] #行数150# 第一列存每个样本属于哪一簇(四个簇)# 第二列存每个样本的到簇的中心点的误差# print(m)clusterAssment = np.mat(np.zeros((m,2)))# .mat()创建150*2的矩阵clusterChange = True# 5.centroids = randCent(dataSet,k)的作用:初始化质心centroidscentroids = randCent(dataSet,k)# 6.补充while循环的条件。while clusterChange:clusterChange = False# 遍历所有的样本# 7.补充range()中的参数。for i in range(m):minDist = 100000.0minIndex = -1# 遍历所有的质心#8.补充range()中的参数:for j in range(k):# 计算该样本到3个质心的欧式距离,找到距离最近的那个质心minIndexdistance = distEclud(centroids[j,:],dataSet[i,:])if distance < minDist:#9.补充minDist;minIndex的赋值代码minDist = distance#分类的索引minIndex = j# 更新该行样本所属的簇if clusterAssment[i,0] != minIndex:clusterChange = TrueclusterAssment[i,:] = minIndex,minDist**2#更新质心for j in range(k):pointsInCluster = dataSet[np.nonzero(clusterAssment[:,0].A == j)[0]] # 获取对应簇类所有的点(x*4)#10.补充axis后的赋值:centroids[j,:] = np.mean(pointsInCluster,axis=0) # 求均值,产生新的质心# print(clusterAssment[0:150,:])print("cluster complete")return centroids,clusterAssmentdef draw(data,center,assment):length=len(center)fig=plt.figuredata1=data[np.nonzero(assment[:,0].A == 0)[0]]data2=data[np.nonzero(assment[:,0].A == 1)[0]]data3=data[np.nonzero(assment[:,0].A == 2)[0]]# 选取前两个维度绘制原始数据的散点图plt.scatter(data1[:,0],data1[:,1],c="red",marker='o',label='label0')plt.scatter(data2[:,0],data2[:,1],c="green", marker='*', label='label1')plt.scatter(data3[:,0],data3[:,1],c="blue", marker='+', label='label2')# 绘制簇的质心点for i in range(length):plt.annotate('center',xy=(center[i,0],center[i,1]),xytext=\(center[i,0]+1,center[i,1]+1),arrowprops=dict(facecolor='yellow'))# plt.annotate('center',xy=(center[i,0],center[i,1]),xytext=\# (center[i,0]+1,center[i,1]+1),arrowprops=dict(facecolor='red'))plt.show()# 选取后两个维度绘制原始数据的散点图plt.scatter(data1[:,2],data1[:,3],c="red",marker='o',label='label0')plt.scatter(data2[:,2],data2[:,3],c="green", marker='*', label='label1')plt.scatter(data3[:,2],data3[:,3],c="blue", marker='+', label='label2')# 绘制簇的质心点for i in range(length):plt.annotate('center',xy=(center[i,2],center[i,3]),xytext=\(center[i,2]+1,center[i,3]+1),arrowprops=dict(facecolor='yellow'))plt.show()
2.1.可视化生成
代码如下(示例):
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
dataSet= iris.data[:, :4]
k = 3
centroids,clusterAssment = KMeans(dataSet,k)
draw(dataSet,centroids,clusterAssment)
3其他聚类算法进行鸢尾花分类
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
# 直接从sklearn中获取数据集
iris = datasets.load_iris()
X = iris.data[:, :4] # 表示我们取特征空间中的4个维度
print(X.shape)
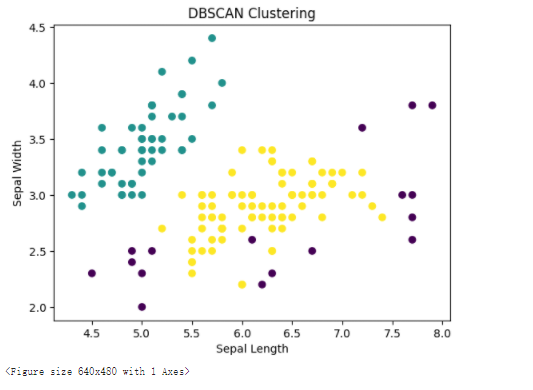
from sklearn.cluster import DBSCAN
# 导入数据集
iris = datasets.load_iris()
X = iris.data[:, :4] # 取前四个特征
# 使用DBSCAN聚类算法
dbscan = DBSCAN(eps=0.5, min_samples=5)
labels = dbscan.fit_predict(X)
# 绘制分类结果
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('DBSCAN Clustering')
plt.show()
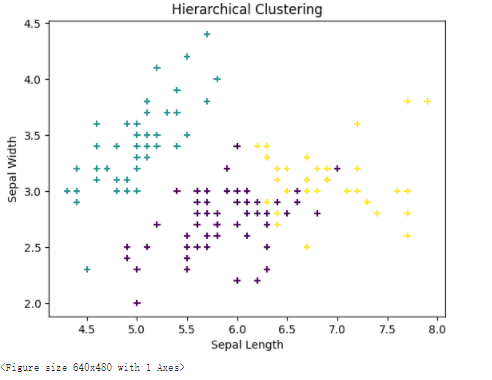
from sklearn.cluster import AgglomerativeClustering
# 使用层次聚类算法
hierarchical = AgglomerativeClustering(n_clusters=3)
labels = hierarchical.fit_predict(X)
# 绘制分类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, marker='+')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('Hierarchical Clustering')
plt.show()
相关文章:
【K-means聚类算法】实现鸢尾花聚类
文章目录 前言一、数据集介绍二、使用步骤1.导包1.2加载数据集1.3绘制二维数据分布图1.4实例化K-means类,并且定义训练函数1.5训练1.6可视化展示2.聚类算法2.1.可视化生成3其他聚类算法进行鸢尾花分类 前言 例如:随着人工智能的不断发展,机器…...
什么是代理IP池?如何判断IP池优劣?
代理池充当多个代理服务器的存储库,提供在线安全和匿名层。代理池允许用户抓取数据、访问受限制的内容以及执行其他在线任务,而无需担心被检测或阻止的风险。代理池为各种在线活动(例如网页抓取、安全浏览等)提高后勤保障。 读完…...

【面经】讲一下线程池的参数和运行原理
线程池是Java中一种重要的并发工具,它可以帮助我们更好地管理线程,避免线程过多导致的系统开销和性能问题。线程池通过预先创建一定数量的线程,并将任务提交给这些线程执行,从而避免了频繁创建和销毁线程的开销。 线程池的参数主…...

针对图像分类的数据增强方法,离线增强,适合分类,无标签增强
针对图像分类的数据增强方法,离线增强,适合分类,无标签增强 代码: 改变路径即可使用 # 本代码主要提供一些针对图像分类的数据增强方法# 1、平移。在图像平面上对图像以一定方式进行平移。 # 2、翻转图像。沿着水平或者垂直方向…...
润色论文Prompt
你好,我现在开始写论文了,我希望你可以扮演帮我润色论文的角色我写的论文是关于xxxxx领域的xxxxx,我希望你能帮我检查段落中语句的逻辑、语法和拼写等问题我希望你能帮我检查以下段落中语句的逻辑、语法和拼写等问题同时提供润色版本以符合学…...
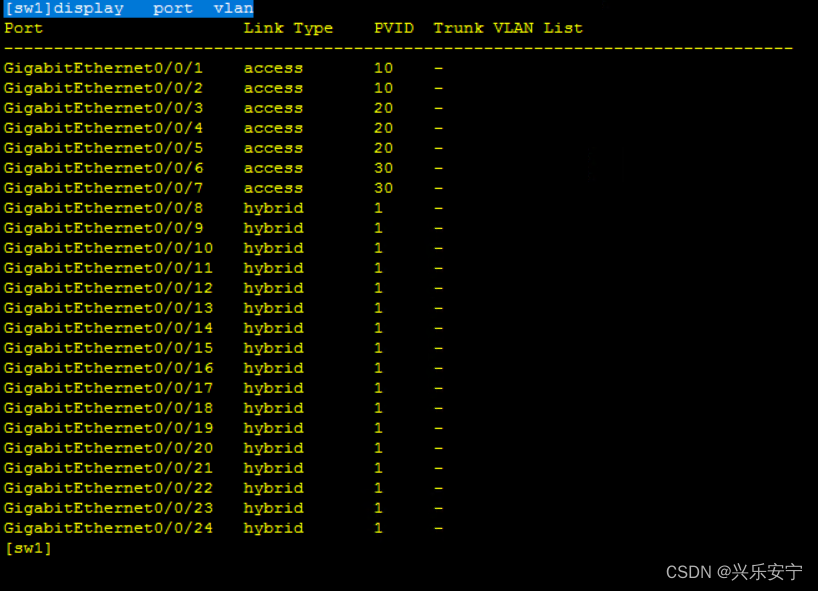
配置简单VLAN
1、 需求 : 1)创建VLAN 10、20、30 2)将端口加入VLAN 3)查看VLAN信息 2、方案 使用eNSP搭建实验环境,如图所示。 3、步骤 实现此案例需要按照如下步骤进行。 1)交换机创建VLAN 10、20、30 [sw1]vla…...

手机是否能登陆国际腾讯云服务器?
在当今社会,跟着互联网的开展,越来越多的用户开始运用云服务器来存储和处理数据。其间,腾讯云服务器作为国内知名的云服务器供给商,受到了广大用户的欢迎。可是,有一些用户可能还不清楚手机是否能登陆腾讯云服务器。本…...

5分钟Python安装实战(MAC版本)
最近在学习Chatgpt接口,官方提供三种方式调用Chatgpt接口,分别是curl、python、node.js:具体介绍我放在下方图片 因为熟悉Python,所以我选择了python这种方式,顺便记录下安装过程,整体并不复杂,…...
python自动化测试(十一):写入、读取、修改Excel表格的数据
目录 一、写入 1.1 安装 xlwt 1.2 增加sheet页 1.2.1 新建sheet页 1.2.2 sheet页写入数据 1.2.3 excel保存 1.2.4 完整代码 1.2.5 同一坐标,重复写入 二、读取 2.1 安装读取模块 2.2 读取sheet页 2.2.1 序号读取shee页 2.2.2 通过sheet页的名称读取she…...

【milkv】添加LCD屏GC9306
前言 本章介绍如何添加LCD屏GC9306驱动。 电路图 dts build\boards\cv180x\cv1800b_milkv_duo_sd\dts_riscv\cv1800b_milkv_duo_sd.dts &spi2 {status "okay";/delete-node/ spidev0;gc9306: gc93060{compatible "sitronix,gc9306";reg <0&g…...

设计模式--开篇
什么是设计模式 设计模式是软件开发过程中面临的通用问题的解决方案。 使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性 按使用目的分类 创建型–主要用于创建对象 单例模式-某个类只能有一个实例,提供一个全局的访问点工厂方法模式-创建…...

Android 原生进度条ProgressBar【自带】【水平风格】自定义
由于不想从零开始自定义,Android原生的进度条就已经很够用了呀! <ProgressBarandroid:id"id/pb_storage"style"style/Widget.AppCompat.ProgressBar.Horizontal"android:layout_width"match_parent"android:l…...
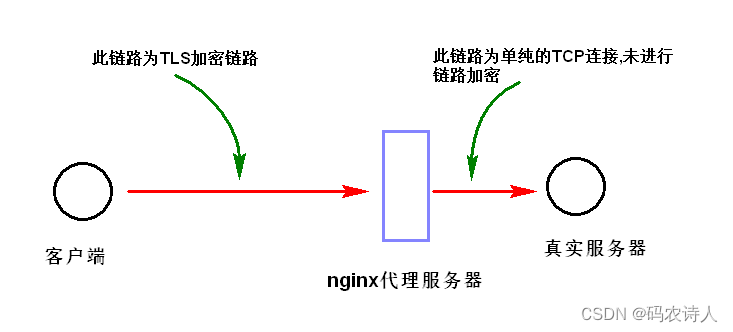
Nginx实现tcp代理并支持TLS加密实验
Nginx源码编译 关于nginx的搭建配置具体参考笔者之前的一篇文章:实时流媒体服务器搭建试验(nginxrtmp)_如何在线测试流媒体rtmp搭建成功了吗-CSDN博客中的前半部分;唯一变化的是编译参数(添加stream模块并添加其对应ss…...
vue3+setup 解决:this.$refs引用子组件报错 is not a function
一、如果在父组件中以下四步都没问题的话,再看下面步骤 二、如果父组件引用的是index页面 请在 头部加上以下代码 (如果是form页面请忽略这一步) <template> <a-modalv-model:visible"visible"title"头部名称&…...

189. 轮转数组
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向右轮转 3 步: [5,6,7,1,2,3,4…...
com.alibaba:tools:jar com.alibaba:jconsole:jar
com.alibaba:tools:jar com.alibaba:jconsole:jar...
洛谷 P1020 [NOIP1999 普及组] 导弹拦截【一题掌握三种方法:动态规划+贪心+二分】最长上升子序列LIS解法详解
P1020 [NOIP1999 普及组] 导弹拦截 前言题目题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示题目分析注意事项 代码动态规划(NOIP要求:时间复杂度O(n^2^))贪心二分(O(nlgn)) 后话额外测试用例样例输入 #1…...

golang的管道阻塞问题
package mainimport ("fmt""sync"//"time" ) var wg sync.WaitGroup func writeData(intchan chan int){defer wg.Done()for i : 1; i < 9; i {intchan<-ifmt.Println("写入的数据为:",i)//time.Sleep(time.Seco…...

用HTML + javaScript快速完成excel表格信息除重并合并
今天突然接到一个工作,要把两个存储在.xls的主体信息表,除重后合并成一个主体信息表,并且补充主体类型和所在县区这两列信息。 完成这项工作的方法有很多,如果信息表中的信息量不大的话,手工处理一下也行,如…...

高性能网络编程 - The C10M problem
文章目录 Pre概述回顾C10K实现C10M的挑战思路总结 Pre 高性能网络编程 - The C10K problem 以及 网络编程技术角度的解决思路 概述 在接下来的10年里,因为IPv6协议下每个服务器的潜在连接数都是数以百万级的,单机服务器处理数百万的并发连接࿰…...

【信创验收倒计时】:Java系统通过等保2.0+国密SM2/SM4+中间件适配的9项必检清单
更多请点击: https://intelliparadigm.com 第一章:信创验收背景与Java系统国产化适配总体要求 在国家信息技术应用创新战略持续深化的背景下,信创项目验收已从“能用”全面转向“好用、安全、可控”。Java 系统作为政务、金融、能源等关键领…...

idea控制台如何实时grep搜索?
安装Grep Console 插件即可,运行时右键即可配合ctrl f 实现实时过滤,高亮显示 ;...

springboot+vue3的BS架构勤工助学信息管理系统设计与实现
目录同行可拿货,招校园代理 ,本人源头供货商系统功能模块划分核心业务流程设计技术实现要点数据统计分析功能系统安全设计项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 系统功能模块划…...

Mac新手必看:保姆级Git+SourceTree配置指南,从SSH密钥到拉取代码一气呵成
Mac开发者入门:Git与SourceTree全流程配置实战手册 刚接触开发的Mac用户往往会在配置开发环境时遇到各种"小坑"。记得我第一次在Mac上配置Git和SourceTree时,花了整整一个下午才搞明白为什么SSH连接总是失败。本文将带你避开这些陷阱…...

PEMFC水淹膜干故障深度诊断【附代码】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,查看文章底部二维码(1)基于FLUENT的多物理场仿真与故障数据集构建&#x…...

长芯微LD7984完全P2P替代AD7984,是一款18位、逐次逼近型模数转换器ADC
描述长芯微LD7984是一款18位、逐次逼近型模数转换器(ADC),采用单电源(VDD)供电。它内置一个低功耗、高速、18位采样ADC和一个多功能串行接口端口。在CNV上升沿,该器件对IN与IN-之间的模拟输入电压差进行采样,范围从-REF至REF。基准电压(REF)由…...

3分钟快速安装微软商店:Windows 11 LTSC系统完整指南
3分钟快速安装微软商店:Windows 11 LTSC系统完整指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否正在使用Windows 11 LTSC版本&…...

戴尔XPS 16评测:均衡大屏笔记本,但售价偏高
戴尔XPS 16(2026款)戴尔此次推出XPS 16,似乎有两个目标:一是重振XPS品牌——该品牌去年曾一度停售,直至今年1月在CES展上宣布回归;二是将其定位于高端内容创作笔记本(如华硕ProArt P16、联想Yog…...

想要副业增收、入职网安?这份 SRC 漏洞挖掘全流程指南,帮你快速上手漏洞挖掘
凌晨两点,大学生张三盯着电脑屏幕突然跳出的「高危漏洞奖励到账」提示,手抖得差点打翻泡面——这是他挖到人生第一个SRC漏洞(某电商平台的越权访问漏洞)后收到的第一笔奖金,金额足够支付三个月生活费。这样的故事&…...
)
Oracle数据库工程师入门培训实战教程(从Oracle11g 到 Oracle19c)
Oracle数据库工程师入门培训实战教程(从Oracle11g 到 Oracle19c) 一、参考资料 【Oracle数据库工程师入门培训实战教程(从Oracle11g 到 Oracle19c)】 https://www.bilibili.com/video/BV1UJH9eLEpg/?share_sourcecopy_web&vd…...