高性能网络编程 - The C10M problem
文章目录
- Pre
- 概述
- 回顾C10K
- 实现C10M的挑战
- 思路总结

Pre
高性能网络编程 - The C10K problem 以及 网络编程技术角度的解决思路
概述
在接下来的10年里,因为IPv6协议下每个服务器的潜在连接数都是数以百万级的,单机服务器处理数百万的并发连接(甚至千万)并非不可能,但我们需要重新审视目前主流OS针对网络编程这一块的具体技术实现
实现C10M(单机千万级并发连接处理能力)确实是一个挑战,但在过去的几年中,有人采用一些创新的方法来应对这一挑战。其中,Errata Security的CEO Robert Graham在Shmoocon 2013大会上的演讲可能提供了一些有趣的见解。 C10M Defending The Internet At Scale
在这个演讲中,Robert Graham可能讨论了一些采用非传统方法来实现高并发连接处理的思路。这些方法可能包括:
-
用户态网络栈:将网络栈移至用户态,以便更灵活地处理连接和网络数据。这种方法可以减少内核级别的开销,并提高性能。
-
事件驱动架构:采用事件驱动编程模型,以便在有事件发生时立即响应,而不是传统的轮询方式。这可以减少不必要的CPU消耗。
-
集群和分布式架构:将服务器架构设计成集群或分布式系统,以分担负载,同时提高容错性。
-
内存映射文件:使用内存映射文件来加速数据读写操作,从而提高I/O性能。
-
高性能编程语言:采用高性能编程语言,如Rust或Go,以减少内存和性能开销。
Robert Graham的结论是:OS的内核不是解决C10M问题的办法,恰恰相反OS的内核正是导致C10M问题的关键所在.
Robert Graham的观点强调了操作系统内核不是解决C10M问题的最佳方式,反而它可能是导致C10M问题的关键。他提出一种创新的思考方式,主张将部分繁重的任务从操作系统内核转移到应用程序,以实现更高级别的并发连接处理能力。
他的观点总结如下:
-
不要让操作系统内核执行所有繁重的任务:应用程序可以高效地处理数据包、内存管理、处理器调度等任务,而将操作系统内核的角色限制为控制层。这样,操作系统主要负责控制而不负担数据处理的任务。
-
设计系统以面向数据层为导向:系统应能够在200个时钟周期内处理数据包,并在14万个时钟周期内处理应用程序逻辑。通过最大限度地减少代码和缓存失效,可以实现高效的性能。
-
专业化可扩展性:C10M问题需要专业化的解决方法,不能简单地依赖操作系统来解决性能问题。开发人员需要自己主动处理性能问题,而不是将其外包给操作系统。
总之,Robert Graham的观点强调了在面对C10M问题时,需要采取一种更加自主和专业化的方法,将操作系统内核的角色限制为控制,将数据处理任务留给应用程序,以实现更高级别的并发连接处理能力。这种方法可能需要深入研究和专业知识,但它代表了一种创新的思考方式,旨在解决高性能网络编程的挑战。
这些方法可能需要深入研究和技术专长,但它们代表了一种不同于传统方式的思考方式,旨在实现更高级别的并发连接处理能力。随着技术的不断发展和创新,我们可能会看到更多的解决方案出现,使C10M成为可能。

回顾C10K
在解决C10K问题时,传统的网络编程模型,如Apache,存在一些明显的限制,这些限制影响了服务器的性能和可扩展性。以下是Apache及其问题的一些方面以及相关的解决方法:
-
性能与可扩展性的区别:性能和可扩展性并不是相同的概念。性能是指服务器在处理连接时的吞吐量和响应时间,而可扩展性是指服务器能够同时处理多少并发连接。对于传统的Apache服务器,性能和可扩展性之间存在明显的差距。
-
短期连接和性能:Apache在处理持续几秒的短期连接(如快速事务)时,性能下降明显。当每秒处理1000个事务时,只能维持约1000个并发连接。如果事务延长到10秒,要维持每秒1000个事务,必须打开1万个并发连接。在这种情况下,即使没有DoS攻击,Apache的性能也会急剧下降,大量下载操作可能导致Apache崩溃。
-
提高处理规模的问题:即使通过硬件升级和处理器速度提高性能,Apache仍然无法处理更多的并发连接。这是因为Apache创建一个CGI进程然后关闭,这个过程并没有扩展。内核使用的O(N^2)算法使服务器难以处理数以万计的并发连接。
解决这些问题的方法可能包括:
-
采用事件驱动服务器模型,如Nginx和Node.js,代替传统的线程服务器。这些服务器能够更高效地处理大量并发连接,因为它们采用异步非阻塞I/O模型,而不是为每个连接创建线程或进程。
-
优化服务器内核以提高性能和可扩展性,例如通过使用更高级的数据结构和算法来改善内核的连接管理。
-
考虑使用缓存、负载均衡和分布式系统来处理大规模并发连接,以提高服务器的性能和可扩展性。
总之,传统的网络编程模型,如Apache,在面对大规模并发连接时存在明显的性能和可扩展性限制,而采用事件驱动服务器模型和优化内核等方法可以改善这些问题。这些方法可以帮助服务器更好地应对C10K问题,并提高性能和规模。
解决并发性能问题的根本方法在于改进操作系统内核,以便在常数时间内查找连接,减少线程切换时间与线程数量的相关性。这主要涉及两个基本问题:
-
连接数与线程数/进程数之间的关系:在传统的操作系统内核中,当数据包到达时,内核需要遍历所有进程以确定由哪个进程来处理这个数据包。这导致了连接数与线程数/进程数之间的关系,增加连接数会增加处理数据包的开销。
-
连接数与选择数/轮询次数(单线程)之间的关系:在单线程轮询模型中,每个数据包需要遍历列表上的所有socket,这会导致连接数与轮询次数之间的关系。
解决这些问题的方法包括:
- 改进操作系统内核,以便在常数时间内查找连接,减少连接查找的开销。
- 使用可扩展的系统调用,如epoll()/IOCompletionPort,以在常数时间内执行socket查询,而不是使用传统的轮询方式。
- 采用异步编程模式,以便服务器能够更高效地处理大规模并发连接。这包括采用事件驱动编程模型,如Nginx和Node.js,以处理连接的事件而不是为每个连接创建线程或进程。
迁移到Nginx和Node类型的服务器时,即使在较低配置的服务器上增加连接数,性能也不会急剧下降,因为这些服务器采用了异步编程模式,并且改进了操作系统内核以提高连接查找的效率。因此,在处理C10K连接时,性能不再受线程数量的限制,而是取决于操作系统内核和服务器的实际处理能力。这也是过去解决C10K问题的常见方法。

实现C10M的挑战
实现1千万的并发连接挑战意味着需要应对以下方面的要求和挑战:
-
1千万的并发连接数:服务器需要能够同时处理1千万个活跃连接,这意味着需要非常高的连接管理和处理能力。
-
100万个连接/秒:服务器需要每秒处理100万个连接请求,而每个连接通常会持续约10秒,这要求服务器具备出色的连接建立和管理速度。
-
10GB/秒的连接:服务器需要具备10GB/秒的连接带宽,以支持快速连接到互联网,这需要高性能的网络设备和带宽管理。
-
1千万个数据包/秒:估计服务器需要每秒处理1千万个数据包,这要求服务器具备强大的数据包处理和传输能力,以及高效的网络栈。
-
10微秒的延迟:服务器需要具备非常低的延迟,以快速响应连接请求和数据包传输,但随着连接数量的增加,延迟可能会增加,需要有效的延迟管理。
-
10微秒的抖动:服务器需要保持延迟的稳定性,以限制最大延迟,避免不稳定的延迟对性能产生负面影响。
-
并发10核技术:服务器软件需要支持更多核的服务器,通常情况下,软件能够轻松扩展到四核,但为了支持更多核的服务器,可能需要重新设计和重写软件,以充分利用多核处理器。
这些要求和挑战需要在硬件、操作系统、网络设备和服务器软件层面进行深入的优化和改进,以实现10M的并发连接。这是一个复杂而高度技术性的挑战,通常需要专业知识和资源,以满足如此高的性能和可扩展性要求。
实现C10M(1千万)的并发连接挑战确实主要在软件层面,而不是硬件层面。以下是一些主要原因和解决思路:
-
初始设计目标:Unix操作系统最初的设计目标是作为电话网络的控制系统,而不是作为服务器操作系统。因此,Unix内核和操作系统的设计主要关注用户和任务的控制,而没有专门考虑高性能数据处理。这导致了在处理大规模并发连接时性能瓶颈。
-
多核处理器:现代处理器通常具有多个核心,而传统的操作系统代码使用多线程或多任务来提高性能。然而,如何有效利用多核处理器来提高性能和可扩展性是一个关键问题。
-
内存访问速度和缓存:内存访问速度相对较慢,而CPU内部缓存的容量有限。在处理大规模并发连接时,需要在有限的时间内完成数据包处理,因此需要考虑内存访问速度和缓存的优化。
解决思路包括:
-
数据包直接传递到业务逻辑:避免数据包经过复杂的Linux内核协议栈,将数据包直接传递给应用层的业务逻辑进行处理,减少性能下降和内存占用。
-
多线程的核间绑定:将不同线程绑定到不同的处理核心,最大化核心CACHE利用,实现无锁设计,避免进程切换消耗。
-
内存优化:预留业务所需内存,脱离Linux内核的管理,并采用更大的内存分页,减少地址转换等性能消耗。
这些措施有助于提高操作系统和服务器软件的性能,以满足C10M级别的并发连接要求。这表明在处理大规模并发连接时,软件的设计和优化是至关重要的,硬件性能也需要充分发挥,但不是性能瓶颈所在。
思路总结
解决C10M问题需要综合考虑多个方面,以下是一些关键思路的总结:
-
网卡问题:网卡的内核工作效率可能不高,需要通过自己的驱动程序和管理来提高网卡性能,远离操作系统的干预。
-
CPU问题:传统的内核方法无法有效协调大规模的并发连接,需要采用不同的方法。一种解决方案是Linux管理前两个CPU核心,而应用程序管理其余的CPU核心,以避免资源争用和提高性能。
-
内存问题:内存管理需要特别关注,以实现高效的数据处理。在系统启动时,分配大部分内存给应用程序管理的大内存页,以减少内存访问的性能消耗。
-
控制层与数据层分离:一种解决思路是将控制层交给操作系统(如Linux),而应用程序负责数据层的管理。这意味着应用程序与内核之间几乎没有交互,没有线程调度、系统调用或中断。这样的分离可以提高性能和可扩展性。
总的来说,解决C10M问题需要综合考虑硬件和软件方面的优化措施,以实现高性能和高并发的连接处理。这也要求在熟悉的编程和开发环境中进行定制硬件和软件的开发,以满足C10M级别的性能要求。

相关文章:
高性能网络编程 - The C10M problem
文章目录 Pre概述回顾C10K实现C10M的挑战思路总结 Pre 高性能网络编程 - The C10K problem 以及 网络编程技术角度的解决思路 概述 在接下来的10年里,因为IPv6协议下每个服务器的潜在连接数都是数以百万级的,单机服务器处理数百万的并发连接࿰…...
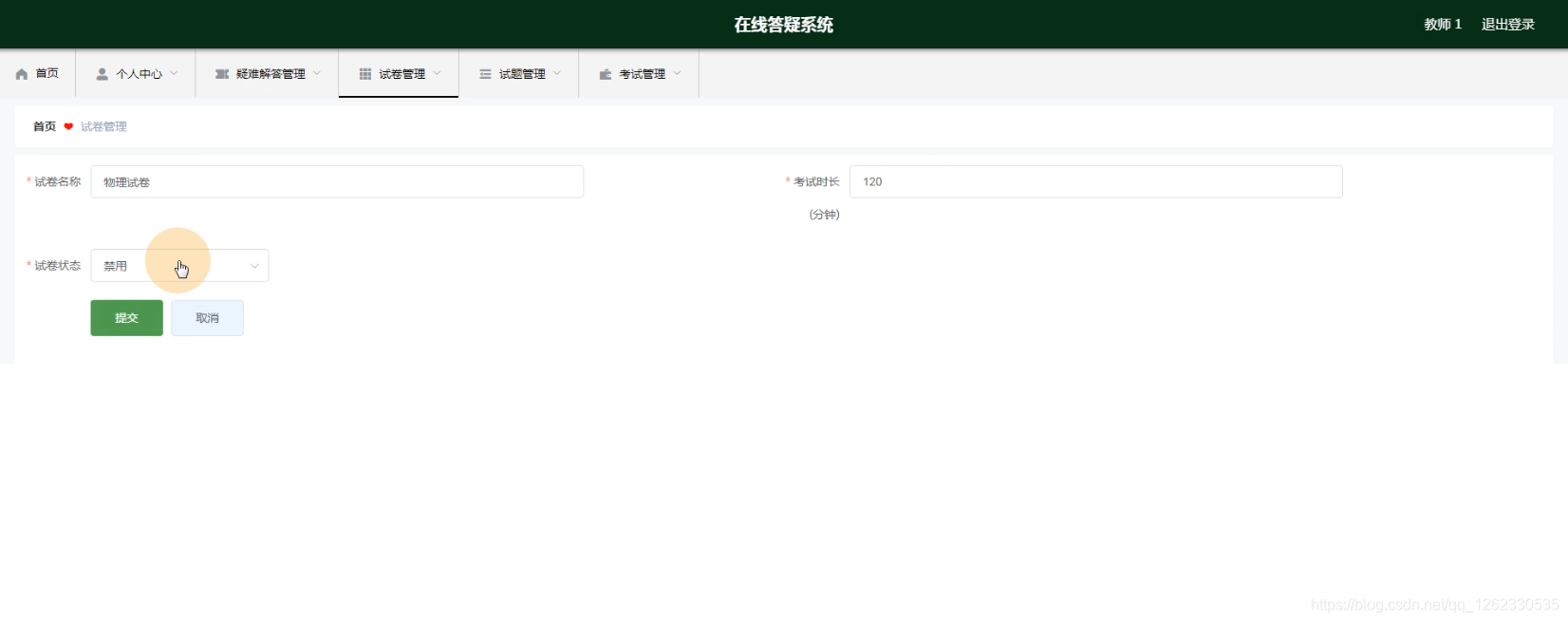
java计算机毕业设计SpringBoot在线答疑系统
项目介绍 本文从学生的功能要求出发,建立了在线答疑系统,系统中的功能模块主要是实现管理员权限;首页、个人中心、学生管理、教师管理、问题发布管理、疑难解答管理。教师权限:首页、个人中心、疑难解答管理、试卷管理、试题管理…...
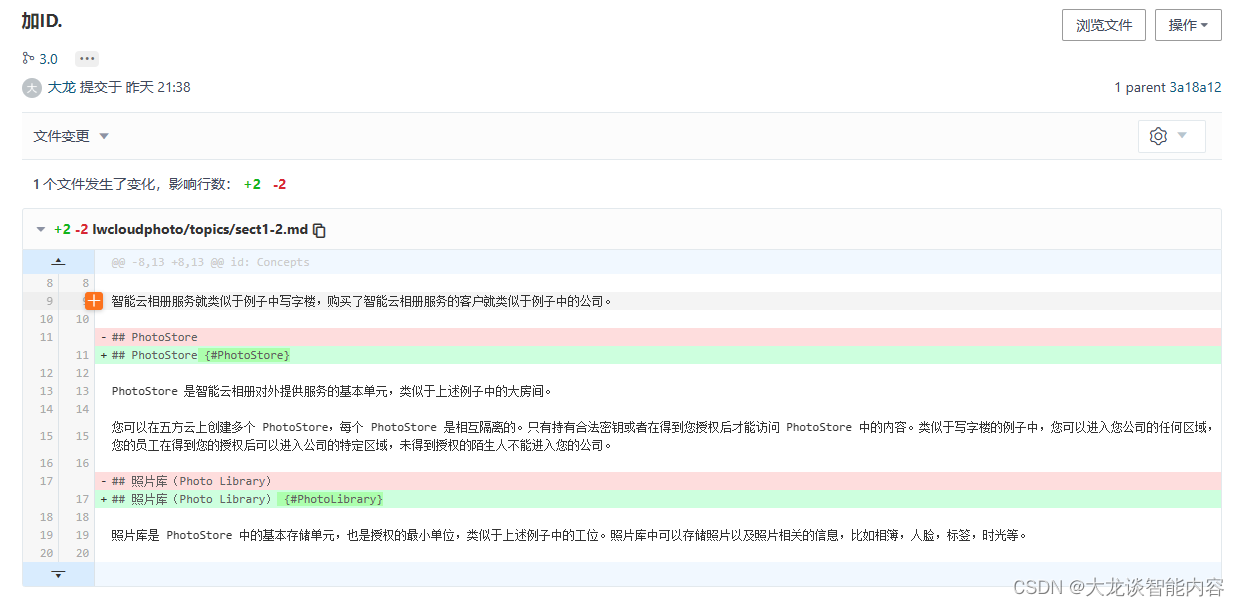
Doc as Code (4):使用Git做版本管理,而不是使用目录做版本管理
▲ 搜索“大龙谈智能内容”关注GongZongHao▲ 在引入版本管理工具之前,文档工程师使用文件系统提供的功能来管理文件。大家是这样工作的: 文件按照分类放在不同的目录里,使用编辑器(如:MS Word)打开文档进…...

【Codeforces】 CF1870E Another MEX Problem
题目链接 CF方向 Luogu方向 题目解法 解法1 考虑优化 d p dp dp 转移次数,即只转移有用的区间 不难发现, m e x ( l , r ) m e x ( l 1 , r ) mex(l,r)mex(l1,r) mex(l,r)mex(l1,r) 或 m e x ( l , r ) m e x ( l , r − 1 ) mex(l,r)mex(l,r-1…...

【Objective-C】Objective-C汇总
方法定义 参考:https://www.yiibai.com/objective_c/objective_c_functions.html Objective-C编程语言中方法定义的一般形式如下 - (return_type) method_name:( argumentType1 )argumentName1 joiningArgument2:( argumentType2 )argumentName2 ... joiningArgu…...

怎么查找性别为女性的不同学历层次不同学位以及所有人不同职务职称的人数
怎么查找性别为女性的不同学历层次不同学位以及所有人不同职务职称的人数 需求分析: 1.统计性别为女性的所获学位下不同学历层次的人数 2.统计不同职务职称的不同学位和学历层次的人数代码 def cal_xuewei_number(self):# 读取表格文件table pd.read_excel("…...

浅谈Elasticsearch查询和搜索
Elasticsearch查询和搜索 Elasticsearch是一个分布式、实时的搜索和分析引擎,广泛应用于全文搜索、日志分析、实时数据分析等场景。Elasticsearch提供了丰富的查询和搜索功能,如查询DSL、过滤、排序、分页、高亮和聚合等。本文将详细介绍如何在Elastics…...

SLAM从入门到精通(被忽视的基础图像处理)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 工业上用激光slam的多,用视觉slam的少,这是大家都知道的常识。毕竟对于工业来说,健壮和稳定是我们必须要考虑的…...
【C++】继承详解
本篇要分享的内容是关于继承的内容哼哼哼啊啊啊啊啊啊啊啊啊啊啊啊啊啊 以下为本篇目录 目录 1.简单了解继承 2.继承的简单定义 3.继承简单使用 4.继承方式 4.1基类的privat 4.2基类的protected 4.3不可见与private的区别 5.父子类对象赋值转换 6.继承的作用域 7.子…...

react:swr接口缓存
useSWR 是一个 React Hooks,是 HTTP 缓存库 SWR 的核心方法之一。SWR 是一个轻量级的 React Hooks 库,通过自动缓存数据来实现 React 的数据获取。 第一个参数是被缓存的数据的 key, 第二个参数是一个函数,该函数返回数据或者一个…...
2023-11 | 短视频批量下载/爬取某个用户的所有视频 | Python
这里以鞠婧祎的个人主页为demo https://www.douyin.com/user/MS4wLjABAAAACV5Em110SiusElwKlIpUd-MRSi8rBYyg0NfpPrqZmykHY8wLPQ8O4pv3wPL6A-oz 【2023-11-4 23:02:52 星期六】可能后面随着XX的调整, 方法不再适用, 请注意 找到接口 找到https://www.douyin.com/aweme/v1/web/…...

【JAVA学习笔记】66 - 本章作业(IO流)
项目代码 https://github.com/yinhai1114/Java_Learning_Code/tree/main/IDEA_Chapter19/src/com/yinhai/homework 1.使用File类和FileWriter类 (1)在判断e盘下是否有文件夹mytemp,如果没有就创建mytemp public class Homework01 {public static void main(String…...
vscode中 vue3+ts 项目的提示失效,volar插件失效问题解决方案
文章目录 前情提要bug回顾解决方案最后 前情提要 说起来很耻辱,从mac环境换到window环境,vscode的配置都是云端更新过来的,应该是一切正常才对,奇怪的是我的项目环境出现问题了,关于组件的ts和追踪都没有效果ÿ…...
Elasticsearch:在 ES|QL 中使用 DISSECT 和 GROK 进行数据处理
目录 DISSECT 还是 GROK? 或者两者兼而有之? 使用 DISSECT 处理数据 Dissect pattern 术语 例子 DISSECT 关键修饰符 右填充修饰符 (->) 附加修饰符 () 添加顺序修饰符( 和 /n) 命名的跳过键(?…...

基于自适应自回归模型的高级人工智能概念及其实现
基于自适应自回归模型的高级人工智能概念及其实现 摘要:一、引言:二、方法:三、讨论:四、结论:草稿实现计算摘要: 在人工智能研究领域中,预测未来的信息往往会遇到信息不明确的问题,尤其是在自回归模型中,这一问题尤为突出。本研究提出一个新颖的假设,将能自主解决信…...
windows的mysql启动错误,查看windows日志
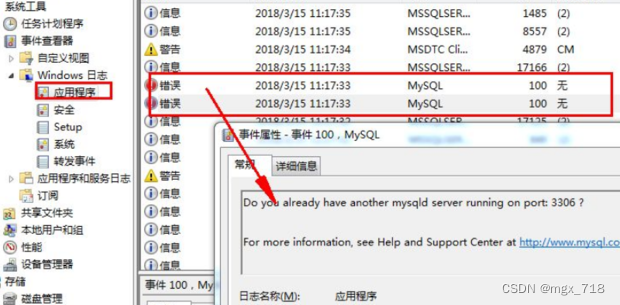
1、点击左下角开始按钮,计算机上右键,点击【管理】。 2、在计算机管理界面依次找到【系统工具】,选择【时间查看器】,打开【windows日志】,点击【应用程序】 3、在右侧找到,最新的mysql错误信息。双击查看。…...
centos7部署Canal与Canal集成使用
1、简介 canal [kə’nl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费 早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigge…...
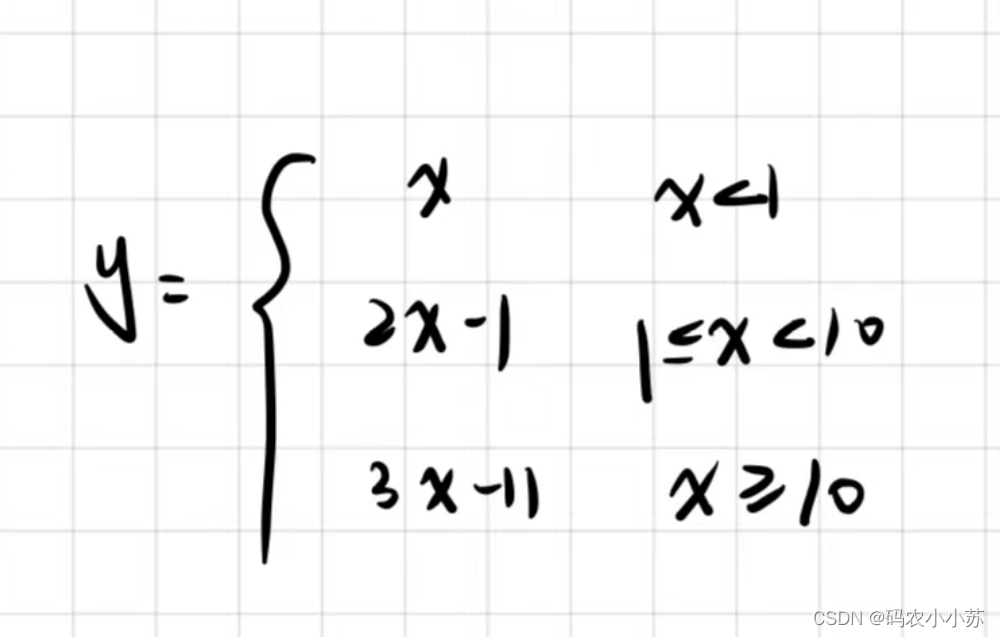
C语言--分段函数--switch语句
如何用switch语句写分段函数呢?⭐️ 首先介绍一下switch语句的语法规则⭐️ switch(整形表达式) {case 常量表达式1; //标签必须唯一语句块1;break;case 常量表达式2; //if(a0),而case中时系统自动加语句块2;break;c…...
)
动态规划31(Leetcode188买卖股票的最佳时机4)
代码: 我的状态方程: buy[i][j]max{buy[i−1][j],sell[i−1][j-1]−price[i]} 题解里的: buy[i][j]max{buy[i−1][j],sell[i−1][j]−price[i]} ..没理解题解的 但我的通过了 class Solution {public int maxProfit(int k, int[] pric…...

npm包管理相关命令
前置条件,准备npm账号,并登录,npm login 或者 npm adduser (这一行同样需要输入账号密码登录,之后就不用登录了) 验证是否登录:npm whoami 还可以查看用户简介:npm profile get …...

避开这3个坑,你的OpenCV连通域面积缺陷检测才算入门
避开这3个坑,你的OpenCV连通域面积缺陷检测才算入门 在工业质检领域,连通域分析是最基础却最容易翻车的技术之一。许多工程师能够快速写出findContours和contourArea的代码,却在真实产线上遭遇误检漏检的尴尬。本文将从三个高频踩坑场景出发&…...

如何通过DellFanManagement实现戴尔笔记本风扇的精准控制
如何通过DellFanManagement实现戴尔笔记本风扇的精准控制 【免费下载链接】DellFanManagement A suite of tools for managing the fans in many Dell laptops. 项目地址: https://gitcode.com/gh_mirrors/de/DellFanManagement 戴尔笔记本用户常常面临散热管理困境&…...
Pixelle-Video:5分钟学会用AI自动生成多语言短视频
Pixelle-Video:5分钟学会用AI自动生成多语言短视频 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 你是否想过,只…...

移动端PDF预览的终极解决方案:pdfh5.js如何完美解决手势缩放与性能难题
移动端PDF预览的终极解决方案:pdfh5.js如何完美解决手势缩放与性能难题 【免费下载链接】pdfh5 项目地址: https://gitcode.com/gh_mirrors/pdf/pdfh5 在移动端开发中,PDF预览一直是个棘手的技术挑战。传统的PDF查看方案往往在移动设备上表现不佳…...

基于多维数据分析的PID参数智能优化系统:工业级控制性能提升框架
基于多维数据分析的PID参数智能优化系统:工业级控制性能提升框架 【免费下载链接】PIDtoolbox PIDtoolbox is a set of graphical tools for analyzing blackbox log data 项目地址: https://gitcode.com/gh_mirrors/pi/PIDtoolbox PIDtoolbox是一款面向工业…...

OpenAI向全云厂商开放:与微软七年独家协议终结,这对中国AI意味着什么?
大家好,我是LeafStay。AI科技 今天(4月28日),一件可能改变全球AI产业格局的事情,悄悄落地了。OpenAI和微软联合宣布:双方终结延续七年的独家合作协议,OpenAI的产品从此可以向亚马逊AWS、谷歌云等…...

NewTab Redirect! 终极指南:如何彻底掌控你的浏览器新标签页
NewTab Redirect! 终极指南:如何彻底掌控你的浏览器新标签页 【免费下载链接】NewTab-Redirect NewTab Redirect! is an extension for Google Chrome which allows the user to replace the page displayed when creating a new tab. 项目地址: https://gitcode.…...

蓝桥杯单片机省赛代码复盘:从I2C驱动到数码管显示,一个完整工程如何拆解调试
蓝桥杯单片机竞赛代码深度解析:从模块拆解到系统调试实战 第一次拿到蓝桥杯单片机竞赛的完整工程代码时,我盯着满屏的寄存器操作和硬件驱动函数,感觉就像面对一个精密但陌生的机械装置——每个零件都在运转,但我却不知道它们如何协…...
)
Python大模型微调框架选型决策树(2024权威Benchmark实测TOP5框架吞吐/显存/收敛性对比)
更多请点击: https://intelliparadigm.com 第一章:Python大模型本地微调框架选型决策树总览 在资源受限的本地环境中开展大语言模型微调,框架选型直接决定训练可行性、显存效率与工程可维护性。当前主流开源方案在量化支持、LoRA/QLoRA集成度…...

戴尔笔记本风扇终极管理指南:免费开源智能散热解决方案
戴尔笔记本风扇终极管理指南:免费开源智能散热解决方案 【免费下载链接】DellFanManagement A suite of tools for managing the fans in many Dell laptops. 项目地址: https://gitcode.com/gh_mirrors/de/DellFanManagement 你是否曾因戴尔笔记本风扇噪音过…...