浅谈Elasticsearch查询和搜索
Elasticsearch查询和搜索
Elasticsearch是一个分布式、实时的搜索和分析引擎,广泛应用于全文搜索、日志分析、实时数据分析等场景。Elasticsearch提供了丰富的查询和搜索功能,如查询DSL、过滤、排序、分页、高亮和聚合等。本文将详细介绍如何在Elasticsearch中使用这些功能。
1. 查询DSL
Elasticsearch使用查询DSL(Domain Specific Language)来构建查询。查询DSL是一种基于JSON的查询语言,允许您以简洁、易读的方式构建复杂的查询。
1.1 基本查询
match查询是一个全文搜索查询,用于在一个或多个字段中搜索文本。以下是一个match查询示例:
{"query": {"match": {"title": "Elasticsearch"}}
}
在此示例中,我们构建了一个match查询,用于搜索title字段中包含"Elasticsearch"的文档。
要在Elasticsearch中执行查询,您可以使用_searchAPI。以下是一个使用curl命令执行查询的示例:
curl -X GET "localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'
{"query": {"match": {"title": "Elasticsearch"}}
}
'
1.1.1 Multi-match查询
multi_match查询允许您在多个字段中执行全文搜索。以下是一个multi_match查询示例:
{"query": {"multi_match": {"query": "Elasticsearch","fields": ["title", "content"]}}
}
在此示例中,我们构建了一个multi_match查询,用于搜索title和content字段中包含"Elasticsearch"的文档。
1.1.2 Term查询
term查询用于在一个字段中搜索精确值。以下是一个term查询示例:
{"query": {"term": {"status.keyword": "published"}}
}
在此示例中,我们构建了一个term查询,用于搜索status.keyword字段中值为"published"的文档。
1.1.3 Range查询
range查询用于在一个字段中搜索范围内的值。以下是一个range查询示例:
{"query": {"range": {"publish_date": {"gte": "2021-01-01","lte": "2021-12-31"}}}
}
在此示例中,我们构建了一个range查询,用于搜索publish_date字段中值在"2021-01-01"到"2021-12-31"之间的文档。
1.2 复合查询
复合查询允许您组合多个查询,以构建更复杂的查询条件。
1.2.1 Bool查询
bool查询允许您组合多个查询,使用逻辑运算符(如must、should、must_not和filter)来定义查询条件。以下是一个bool查询示例:
{"query": {"bool": {"must": {"match": {"title": "Elasticsearch"}},"filter": {"range": {"publish_date": {"gte": "2021-01-01"}}}}}
}
在此示例中,我们构建了一个bool查询,用于搜索title字段中包含"Elasticsearch"且publish_date字段大于等于"2021-01-01"的文档。
1.2.2 Disjunction Max查询(Dis Max查询)
dis_max查询允许您在多个查询中选择最高得分的查询结果。以下是一个dis_max查询示例:
{"query": {"dis_max": {"queries": [{"match": {"title": "Elasticsearch"}},{"match": {"content": "Elasticsearch"}}]}}
}
在此示例中,我们构建了一个dis_max查询,用于搜索title和content字段中包含"Elasticsearch"的文档。查询结果将根据最高得分的查询进行排序。
1.3 嵌套查询
嵌套查询用于查询包含嵌套对象的文档。假设我们有一个包含comments嵌套对象的文档,每个评论都有一个author和content字段。以下是一个嵌套查询示例:
{"query": {"nested": {"path": "comments","query": {"bool": {"must": [{"match": {"comments.author": "John Doe"}},{"match": {"comments.content": "Elasticsearch"}}]}}}}
}
在此示例中,我们构建了一个嵌套查询,用于搜索comments.author字段为"John Doe"且comments.content字段包含"Elasticsearch"的文档。
1.4 聚合查询
聚合查询允许您对查询结果进行分组和统计。要在查询中添加聚合,您可以使用aggs参数。以下是一个聚合示例:
{"query": {"match": {"title": "Elasticsearch"}},"aggs": {"by_category": {"terms": {"field": "category.keyword"}}}
}
在此示例中,我们添加了一个名为by_category的聚合,该聚合按category.keyword字段对查询结果进行分组。terms聚合用于计算每个类别中的文档数量。
要获取聚合结果,您可以在响应中查看aggregations字段。以下是一个聚合结果示例:
{..."aggregations": {"by_category": {"buckets": [{"key": "category1","doc_count": 10},{"key": "category2","doc_count": 5}]}}
}
在此示例中,我们可以看到每个类别中的文档数量。例如,category1中有10个文档,category2中有5个文档。
2. 过滤
2.1 过滤与查询的区别
在Elasticsearch中,查询和过滤有以下主要区别:
- 查询(Query):主要用于全文搜索,会计算文档的相关性得分(relevance score)。
- 过滤(Filter):主要用于精确匹配,不计算相关性得分,只返回满足条件的文档。过滤结果会被缓存,因此过滤通常比查询更快。
2.2 使用过滤
过滤允许您根据特定条件筛选查询结果。要在查询中添加过滤条件,您可以使用bool查询的filter子句。以下是一个过滤示例:
{"query": {"bool": {"must": {"match": {"title": "Elasticsearch"}},"filter": {"range": {"publish_date": {"gte": "2021-01-01"}}}}}
}
在此示例中,我们添加了一个range过滤器,用于筛选publish_date字段大于等于"2021-01-01"的文档。
2.3 常见的过滤类型
以下是一些常见的过滤类型:
2.3.1 Term过滤
term过滤用于在一个字段中搜索精确值。以下是一个term过滤示例:
{"query": {"bool": {"filter": {"term": {"status.keyword": "published"}}}}
}
在此示例中,我们构建了一个term过滤器,用于筛选status.keyword字段中值为"published"的文档。
2.3.2 Range过滤
range过滤用于在一个字段中搜索范围内的值。以下是一个range过滤示例:
{"query": {"bool": {"filter": {"range": {"publish_date": {"gte": "2021-01-01","lte": "2021-12-31"}}}}}
}
在此示例中,我们构建了一个range过滤器,用于筛选publish_date字段中值在"2021-01-01"到"2021-12-31"之间的文档。
2.3.3 Exists过滤
exists过滤用于筛选包含特定字段的文档。以下是一个exists过滤示例:
{"query": {"bool": {"filter": {"exists": {"field": "author"}}}}
}
在此示例中,我们构建了一个exists过滤器,用于筛选包含author字段的文档。
2.3.4 Bool过滤
bool过滤允许您组合多个过滤条件,使用逻辑运算符(如must、should、must_not)来定义过滤条件。以下是一个bool过滤示例:
{"query": {"bool": {"filter": [{"term": {"status.keyword": "published"}},{"range": {"publish_date": {"gte": "2021-01-01"}}}]}}
}
在此示例中,我们构建了一个bool过滤器,用于筛选status.keyword字段中值为"published"且publish_date字段大于等于"2021-01-01"的文档。
2.3.5 Geo距离过滤
geo_distance过滤用于筛选距离给定地理坐标一定范围内的文档。以下是一个geo_distance过滤示例:
{"query": {"bool": {"filter": {"geo_distance": {"distance": "100km","location": {"lat": 40.7128,"lon": -74.0060}}}}}
}
在此示例中,我们构建了一个geo_distance过滤器,用于筛选距离纬度40.7128、经度-74.0060的地理坐标100公里以内的文档。
2.4 组合查询和过滤
在实际应用中,您可能需要根据多个条件对文档进行查询和过滤。以下是一个组合查询和过滤的示例:
{"query": {"bool": {"must": {"match": {"title": "Elasticsearch"}},"filter": [{"term": {"status.keyword": "published"}},{"range": {"publish_date": {"gte": "2021-01-01"}}}]}}
}
在此示例中,我们构建了一个bool查询,用于搜索title字段中包含"Elasticsearch"的文档。同时,我们添加了两个过滤器,用于筛选status.keyword字段中值为"published"且publish_date字段大于等于"2021-01-01"的文档。
3. 排序
3.1 基本排序
在 Elasticsearch 中,我们可以使用 _sort 参数来指定排序字段。例如,我们有一个名为 products 的索引,其中包含了一些商品信息,我们可以根据商品的价格(price)进行升序排序:
GET /products/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}}]
}
在这个例子中,我们使用了 match_all 查询来获取所有的商品,然后通过 sort 参数指定了按照 price 字段进行升序排序。order 参数可以接受 asc(升序)和 desc(降序)两个值。
3.2 多字段排序
有时候,我们需要根据多个字段进行排序。在 Elasticsearch 中,我们可以在 sort 参数中指定多个排序字段。例如,我们可以先根据商品的价格进行升序排序,然后再根据商品的评分(rating)进行降序排序:
GET /products/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}},{"rating": {"order": "desc"}}]
}
在这个例子中,我们在 sort 参数中指定了两个排序字段,分别是 price 和 rating。Elasticsearch 会先根据 price 进行排序,然后再根据 rating 进行排序。
3.3 按照距离排序
Elasticsearch 支持按照地理位置进行排序。例如,我们有一个名为 shops 的索引,其中包含了一些商店的信息,我们可以根据商店的位置(location)和用户的位置进行排序:
GET /shops/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"location": {"lat": 40.715,"lon": -73.988},"order": "asc","unit": "km"}}]
}
在这个例子中,我们使用了 _geo_distance 排序,它会根据商店的位置(location)和用户的位置(经纬度)计算距离,并按照距离进行排序。order 参数用于指定排序方式,unit 参数用于指定距离的单位。
3.4 按照评分排序
在 Elasticsearch 中,我们可以使用 _score 参数来按照文档的评分进行排序。例如,我们可以根据商品的名称(name)进行搜索,并按照评分进行降序排序:
GET /products/_search
{"query": {"match": {"name": "iphone"}},"sort": [{"_score": {"order": "desc"}}]
}
在这个例子中,我们使用了 match 查询来搜索商品名称中包含 iphone 的商品,然后通过 sort 参数指定了按照评分进行降序排序。
3.5 自定义排序
Elasticsearch 支持使用脚本(Script)来自定义排序。例如,我们可以根据商品的价格(price)和销量(sales)计算一个综合得分,并按照综合得分进行排序:
GET /products/_search
{"query": {"match_all": {}},"sort": [{"_script": {"type": "number","script": {"source": "doc['price'].value * 0.8 + doc['sales'].value * 0.2"},"order": "desc"}}]
}
在这个例子中,我们使用了 _script 排序,它允许我们使用脚本来计算一个自定义的排序值。在这里,我们使用了一个简单的公式 doc['price'].value * 0.8 + doc['sales'].value * 0.2 来计算综合得分,其中 price 占 80%,sales 占 20%。然后我们通过 order 参数指定了按照综合得分进行降序排序。
需要注意的是,使用脚本排序可能会影响查询性能,因此在实际应用中需要权衡性能和灵活性。
3.6 排序缺失值处理
在 Elasticsearch 中,如果排序字段中存在缺失值,我们可以使用 missing 参数来指定如何处理这些缺失值。例如,我们可以将缺失的价格(price)视为最低价格:
GET /products/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc","missing": "_first"}}]
}
在这个例子中,我们使用了 missing 参数,并将其设置为 _first,这意味着缺失值将被视为最小值,因此在升序排序时,它们将排在最前面。我们还可以将 missing 设置为 _last(将缺失值视为最大值)或者一个具体的数值。
4. 分页
4.1 基本分页
在 Elasticsearch 中,我们可以使用 from 和 size 参数来实现分页。from 参数表示起始文档的位置(从 0 开始),size 参数表示每页文档的数量。例如,我们有一个名为 products 的索引,其中包含了一些商品信息,我们可以获取第一页的商品(每页 10 个):
GET /products/_search
{"query": {"match_all": {}},"from": 0,"size": 10
}
在这个例子中,我们使用了 match_all 查询来获取所有的商品,然后通过 from 和 size 参数指定了分页信息。这里 from 为 0,表示从第一个文档开始,size 为 10,表示每页包含 10 个文档。
4.2 深度分页
在 Elasticsearch 中,我们可以通过调整 from 参数的值来实现深度分页。例如,我们可以获取第二页的商品(每页 10 个):
GET /products/_search
{"query": {"match_all": {}},"from": 10,"size": 10
}
在这个例子中,我们将 from 参数的值设置为 10,表示从第 11 个文档开始。其他参数保持不变。
需要注意的是,深度分页可能会影响查询性能。因为 Elasticsearch 需要跳过 from 参数指定的文档数量,这可能会导致较高的内存和 CPU 消耗。在实际应用中,我们应该尽量避免使用过大的 from 值。
4.3 分页限制
Elasticsearch 默认允许查询的最大文档数量为 10000。这意味着,如果我们使用 from 和 size 参数进行分页,from + size 的值不能超过 10000。例如,以下查询将会失败:
GET /products/_search
{"query": {"match_all": {}},"from": 9900,"size": 200
}
在这个例子中,from + size 的值为 10100,超过了默认的最大文档数量。为了解决这个问题,我们可以使用 index.max_result_window 参数来调整最大文档数量。例如,我们可以将其设置为 20000:
PUT /products/_settings
{"index": {"max_result_window": 20000}
}
需要注意的是,增加最大文档数量可能会导致更高的内存和 CPU 消耗。在实际应用中,我们应该根据需求和资源情况来调整这个参数。
4.4 搜索结果遍历
对于大量数据的遍历,我们可以使用 Elasticsearch 的 Scroll API。Scroll API 可以在一定时间内保留查询快照,从而避免深度分页带来的性能问题。以下是一个使用 Scroll API 的例子:
# 初始化 scroll
GET /products/_search?scroll=1m
{"query": {"match_all": {}},"size": 10
}```json
# 使用 scroll_id 获取下一页结果
GET /_search/scroll
{"scroll": "1m","scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndU..."
}
在这个例子中,我们首先使用 scroll 参数初始化了一个 scroll 上下文,并设置了一个 1 分钟的保留时间。然后,我们使用 size 参数指定每次获取 10 个文档。在获取下一页结果时,我们需要使用上一次查询返回的 scroll_id。这个过程可以重复进行,直到所有文档都被遍历完。
需要注意的是,当遍历完成后,我们应该及时清除 scroll 上下文,以释放资源:
DELETE /_search/scroll
{"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndU..."
}
4.5 分页与排序
在使用 Elasticsearch 进行分页时,我们通常需要对查询结果进行排序。例如,我们可以根据商品的价格(price)进行升序排序,并获取第一页的商品(每页 10 个):
GET /products/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}}],"from": 0,"size": 10
}
在这个例子中,我们使用了 sort 参数来指定排序字段,并通过 from 和 size 参数指定了分页信息。这样,我们可以获取按照价格排序的商品列表,并进行分页展示。
5. 高亮
5.1 基本高亮
在 Elasticsearch 中,我们可以使用 highlight 参数来实现高亮。例如,我们有一个名为 articles 的索引,其中包含了一些文章信息,我们可以根据文章的标题(title)和内容(content)进行搜索,并高亮匹配的关键词:
GET /articles/_search
{"query": {"multi_match": {"query": "Elasticsearch","fields": ["title", "content"]}},"highlight": {"fields": {"title": {},"content": {}}}
}
在这个例子中,我们使用了 multi_match 查询来搜索标题和内容中包含 “Elasticsearch” 的文章,然后通过 highlight 参数指定了高亮字段。这里我们指定了 title 和 content 两个字段进行高亮。
查询结果中,每个文档都会包含一个 highlight 字段,其中包含了高亮后的文本片段。默认情况下,高亮的关键词会被包裹在 <em> 标签中。
5.2 高亮标签
在 Elasticsearch 中,我们可以自定义高亮标签。例如,我们可以将高亮关键词包裹在 <strong> 标签中:
GET /articles/_search
{"query": {"multi_match": {"query": "Elasticsearch","fields": ["title", "content"]}},"highlight": {"pre_tags": ["<strong>"],"post_tags": ["</strong>"],"fields": {"title": {},"content": {}}}
}
在这个例子中,我们使用了 pre_tags 和 post_tags 参数来指定高亮标签。这里我们将高亮关键词包裹在 <strong> 标签中。
5.3 高亮片段
在 Elasticsearch 中,我们可以控制高亮片段的数量和长度。例如,我们可以设置每个字段最多返回 3 个高亮片段,每个片段最多包含 150 个字符:
GET /articles/_search
{"query": {"multi_match": {"query": "Elasticsearch","fields": ["title", "content"]}},"highlight": {"number_of_fragments": 3,"fragment_size": 150,"fields": {"title": {},"content": {}}}
}
在这个例子中,我们使用了 number_of_fragments 和 fragment_size 参数来控制高亮片段。这里我们设置了每个字段最多返回 3 个高亮片段,每个片段最多包含 150 个字符。
5.4 高亮类型
Elasticsearch 支持多种高亮类型,包括 plain(默认)、postings 和 fvh。不同的高亮类型在性能和功能上有所差异。例如,我们可以使用 postings 高亮类型来提高高亮性能:
GET /articles/_search
{"query": {"multi_match": {"query": "Elasticsearch","fields": ["title", "content"]}},"highlight": {"type": "postings","fields": {"title": {},"content": {}}}
}
在这个例子中,我们使用了 type 参数来指定高亮类型。这里我们将高亮类型设置为 postings。需要注意的是,使用 postings 高亮类型时,我们需要在索引设置中启用 term_vector:
PUT /articles
{"mappings": {"properties": {"title": {"type": "text","term_vector": "with_positions_offsets"},"content": {"type": "text","term_vector": "with_positions_offsets"}}}
}
在这个例子中,我们在创建索引时为 title 和 content 字段启用了 term_vector。这样,我们就可以使用 postings 高亮类型来提高高亮性能。
5.5 高亮查询
在某些情况下,我们可能需要根据不同的查询条件来高亮文本。Elasticsearch 支持使用 highlight_query 参数来指定高亮查询。例如,我们可以根据文章的标题(title)和内容(content)进行搜索,但只高亮标题中的关键词:
GET /articles/_search
{"query": {"multi_match": {"query": "Elasticsearch","fields": ["title", "content"]}},"highlight": {"fields": {"title": {"highlight_query": {"match": {"title": "Elasticsearch"}}}}}
}
在这个例子中,我们使用了 highlight_query 参数来指定高亮查询。这里我们设置了只高亮标题中的关键词。
6. 聚合
6.1 基本聚合
在 Elasticsearch 中,我们可以使用 aggs 参数来实现聚合。例如,我们有一个名为 sales 的索引,其中包含了一些销售记录,我们可以根据商品类别(category)进行分组,并计算每个类别的销售总额(amount):
GET /sales/_search
{"size": 0,"aggs": {"category_stats": {"terms": {"field": "category.keyword"},"aggs": {"total_amount": {"sum": {"field": "amount"}}}}}
}
在这个例子中,我们使用了 terms 聚合来根据商品类别进行分组,然后使用了 sum 聚合来计算每个类别的销售总额。这里我们将聚合结果命名为 category_stats。
查询结果中,会包含一个名为 aggregations 的字段,其中包含了聚合结果。在这个例子中,我们可以获取每个类别的销售总额。
6.2 按照范围聚合
在 Elasticsearch 中,我们可以使用 range 聚合来根据指定的范围进行分组。例如,我们可以根据销售额(amount)的范围进行分组,统计不同范围内的销售记录数量:
GET /sales/_search
{"size": 0,"aggs": {"amount_ranges": {"range": {"field": "amount","ranges": [{ "to": 100 },{ "from": 100, "to": 500 },{ "from": 500 }]}}}
}
在这个例子中,我们使用了 range 聚合来根据销售额的范围进行分组。这里我们定义了三个范围:小于 100、100 到 500、大于 500。查询结果中,我们可以获取不同范围内的销售记录数量。
6.3 日期聚合
在 Elasticsearch 中,我们可以使用 date_histogram 聚合来根据日期进行分组。例如,我们可以根据销售日期(date)进行分组,统计每个月的销售总额(amount):
GET /sales/_search
{"size": 0,"aggs": {"monthly_sales": {"date_histogram": {"field": "date","calendar_interval": "month"},"aggs": {"total_amount": {"sum": {"field": "amount"}}}}}
}
在这个例子中,我们使用了 date_histogram 聚合来根据销售日期进行分组。这里我们设置了 calendar_interval 参数为 month,表示按照月份进行分组。查询结果中,我们可以获取每个月的销售总额。
6.4 嵌套聚合
在 Elasticsearch 中,我们可以使用嵌套聚合来实现多层分组。例如,我们可以先根据商品类别(category)进行分组,然后再根据销售员(salesperson)进行分组,统计每个类别下每个销售员的销售总额(amount):
GET /sales/_search
{"size": 0,"aggs": {"category_stats": {"terms": {"field": "category.keyword"},"aggs": {"salesperson_stats": {"terms": {"field": "salesperson.keyword"},"aggs": {"total_amount": {"sum": {"field": "amount"}}}}}}}
}
在这个例子中,我们首先使用了 terms 聚合来根据商品类别进行分组,然后在每个类别下再使用 terms 聚合根据销售员进行分组。最后,我们使用了 sum 聚合来计算每个类别下每个销售员的销售总额。查询结果中,我们可以获取多层分组的统计信息。
6.5 按照过滤条件聚合
在 Elasticsearch 中,我们可以使用 filter 聚合来根据过滤条件进行分组。例如,我们可以根据销售员(salesperson)为 “Alice” 的条件进行过滤,统计满足条件的销售总额(amount):
GET /sales/_search
{"size": 0,"aggs": {"alice_sales": {"filter": {"term": {"salesperson.keyword": "Alice"}},"aggs": {"total_amount": {"sum": {"field": "amount"}}}}}
}
在这个例子中,我们使用了 filter 聚合来根据销售员为 “Alice” 的条件进行过滤。然后我们使用了 sum 聚合来计算满足条件的销售总额。查询结果中,我们可以获取 “Alice” 的销售总额。
总结
本文详细介绍了Elasticsearch的查询和搜索功能,包括查询DSL、过滤、排序、分页、高亮和聚合等。通过使用这些功能,您可以构建复杂的查询和分析,以满足各种业务场景和需求。希望本文能为您提供有关如何在Elasticsearch中使用查询和搜索功能的有用信息。
相关文章:

浅谈Elasticsearch查询和搜索
Elasticsearch查询和搜索 Elasticsearch是一个分布式、实时的搜索和分析引擎,广泛应用于全文搜索、日志分析、实时数据分析等场景。Elasticsearch提供了丰富的查询和搜索功能,如查询DSL、过滤、排序、分页、高亮和聚合等。本文将详细介绍如何在Elastics…...

SLAM从入门到精通(被忽视的基础图像处理)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 工业上用激光slam的多,用视觉slam的少,这是大家都知道的常识。毕竟对于工业来说,健壮和稳定是我们必须要考虑的…...
【C++】继承详解
本篇要分享的内容是关于继承的内容哼哼哼啊啊啊啊啊啊啊啊啊啊啊啊啊啊 以下为本篇目录 目录 1.简单了解继承 2.继承的简单定义 3.继承简单使用 4.继承方式 4.1基类的privat 4.2基类的protected 4.3不可见与private的区别 5.父子类对象赋值转换 6.继承的作用域 7.子…...

react:swr接口缓存
useSWR 是一个 React Hooks,是 HTTP 缓存库 SWR 的核心方法之一。SWR 是一个轻量级的 React Hooks 库,通过自动缓存数据来实现 React 的数据获取。 第一个参数是被缓存的数据的 key, 第二个参数是一个函数,该函数返回数据或者一个…...
2023-11 | 短视频批量下载/爬取某个用户的所有视频 | Python
这里以鞠婧祎的个人主页为demo https://www.douyin.com/user/MS4wLjABAAAACV5Em110SiusElwKlIpUd-MRSi8rBYyg0NfpPrqZmykHY8wLPQ8O4pv3wPL6A-oz 【2023-11-4 23:02:52 星期六】可能后面随着XX的调整, 方法不再适用, 请注意 找到接口 找到https://www.douyin.com/aweme/v1/web/…...

【JAVA学习笔记】66 - 本章作业(IO流)
项目代码 https://github.com/yinhai1114/Java_Learning_Code/tree/main/IDEA_Chapter19/src/com/yinhai/homework 1.使用File类和FileWriter类 (1)在判断e盘下是否有文件夹mytemp,如果没有就创建mytemp public class Homework01 {public static void main(String…...
vscode中 vue3+ts 项目的提示失效,volar插件失效问题解决方案
文章目录 前情提要bug回顾解决方案最后 前情提要 说起来很耻辱,从mac环境换到window环境,vscode的配置都是云端更新过来的,应该是一切正常才对,奇怪的是我的项目环境出现问题了,关于组件的ts和追踪都没有效果ÿ…...
Elasticsearch:在 ES|QL 中使用 DISSECT 和 GROK 进行数据处理
目录 DISSECT 还是 GROK? 或者两者兼而有之? 使用 DISSECT 处理数据 Dissect pattern 术语 例子 DISSECT 关键修饰符 右填充修饰符 (->) 附加修饰符 () 添加顺序修饰符( 和 /n) 命名的跳过键(?…...

基于自适应自回归模型的高级人工智能概念及其实现
基于自适应自回归模型的高级人工智能概念及其实现 摘要:一、引言:二、方法:三、讨论:四、结论:草稿实现计算摘要: 在人工智能研究领域中,预测未来的信息往往会遇到信息不明确的问题,尤其是在自回归模型中,这一问题尤为突出。本研究提出一个新颖的假设,将能自主解决信…...
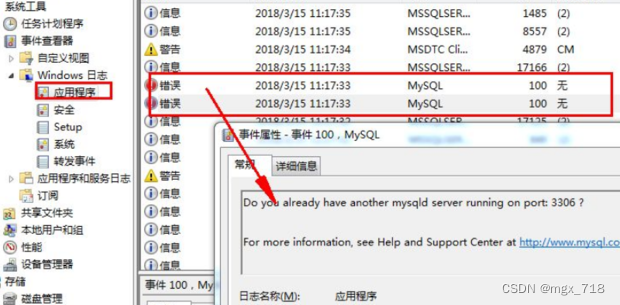
windows的mysql启动错误,查看windows日志
1、点击左下角开始按钮,计算机上右键,点击【管理】。 2、在计算机管理界面依次找到【系统工具】,选择【时间查看器】,打开【windows日志】,点击【应用程序】 3、在右侧找到,最新的mysql错误信息。双击查看。…...
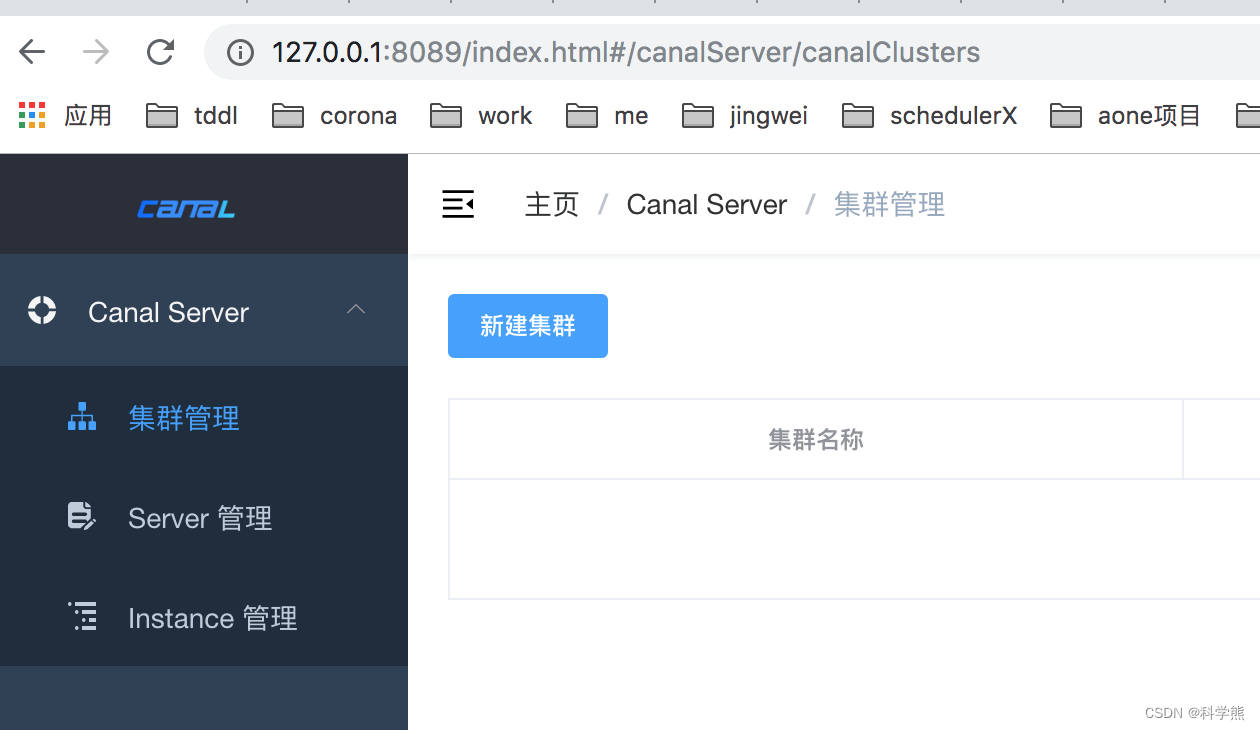
centos7部署Canal与Canal集成使用
1、简介 canal [kə’nl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费 早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigge…...
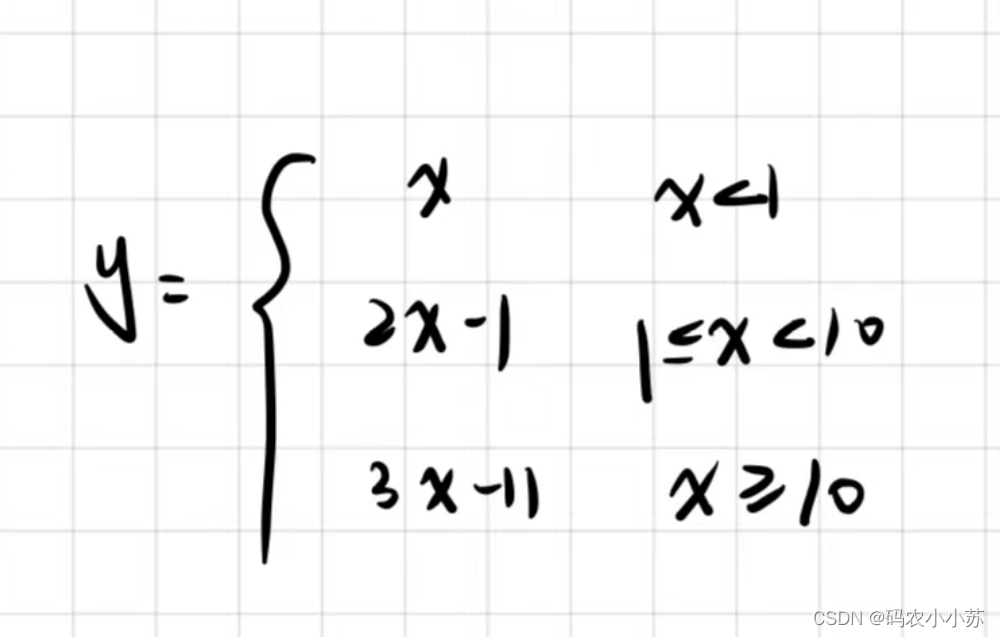
C语言--分段函数--switch语句
如何用switch语句写分段函数呢?⭐️ 首先介绍一下switch语句的语法规则⭐️ switch(整形表达式) {case 常量表达式1; //标签必须唯一语句块1;break;case 常量表达式2; //if(a0),而case中时系统自动加语句块2;break;c…...
)
动态规划31(Leetcode188买卖股票的最佳时机4)
代码: 我的状态方程: buy[i][j]max{buy[i−1][j],sell[i−1][j-1]−price[i]} 题解里的: buy[i][j]max{buy[i−1][j],sell[i−1][j]−price[i]} ..没理解题解的 但我的通过了 class Solution {public int maxProfit(int k, int[] pric…...

npm包管理相关命令
前置条件,准备npm账号,并登录,npm login 或者 npm adduser (这一行同样需要输入账号密码登录,之后就不用登录了) 验证是否登录:npm whoami 还可以查看用户简介:npm profile get …...
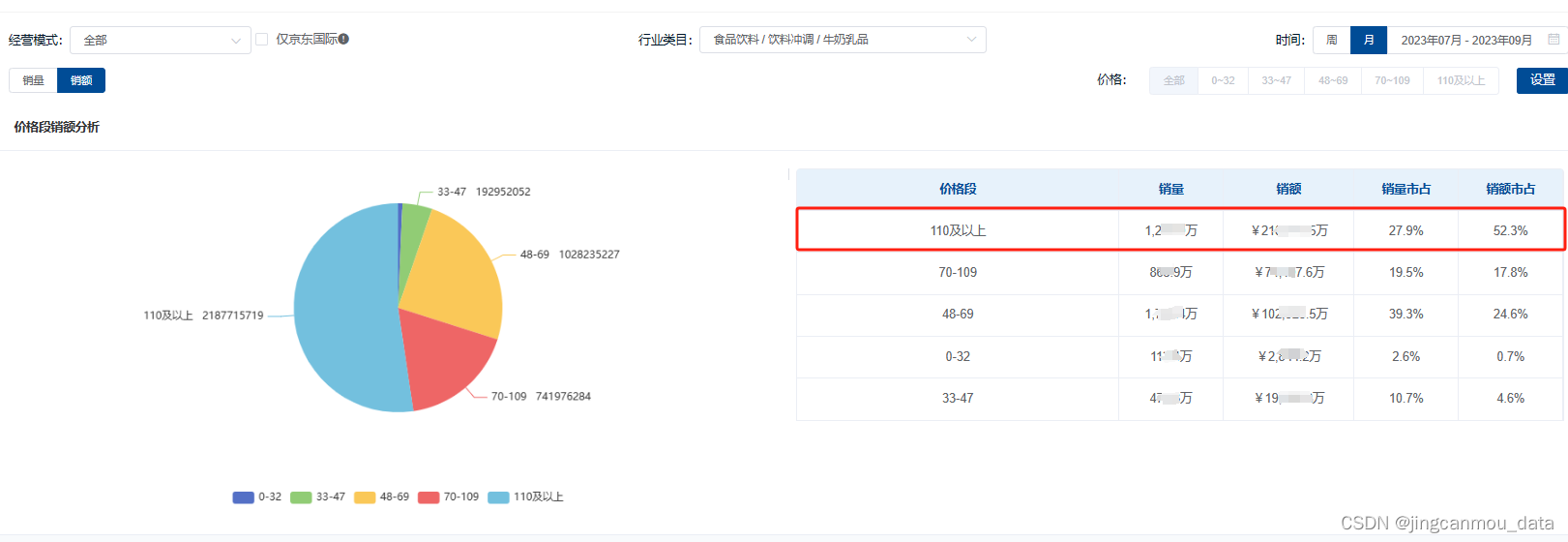
2023年Q3乳品行业数据分析(乳品市场未来发展趋势)
随着人们生活水平的不断提高以及对健康生活的追求不断增强,牛奶作为优质蛋白和钙的补充品,市场需求逐年增加。 今年Q3,牛奶乳品市场仍呈增长趋势。根据鲸参谋电商数据分析平台的相关数据显示,2023年7月-9月,牛奶乳品市…...
)
软考 系统架构设计师系列知识点之边缘计算(2)
接前一篇文章:软考 系统架构设计师系列知识点之边缘计算(1) 所属章节: 第11章. 未来信息综合技术 第4节. 边缘计算概述 3. 边缘计算的特点 边缘计算是在靠近物或数据源头的网络边缘侧,融合网络、计算、存储、应用核心…...
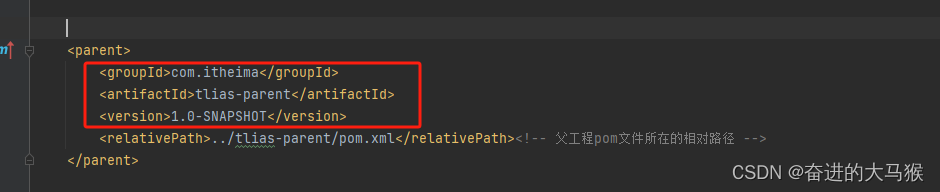
Maven中的继承与聚合
一,继承 前面我们将项目拆分成各个小模块,但是每个小模块中有很多相同的依赖于是我们创建一个父工程将模块中相同的依赖定义在父工程中,然后子工程继承父工程Maven作用:简化依赖配置,统一依赖管理,可以实现多重继承像J…...
第三章 UI开发的点点滴滴
一、常用控件的使用方法 1.TextView android:gravity"center" 可选值:top、bottom、left、right、center等,可以用"|"来同时指定多个值,center表示文字在垂直和水平方向都居中 android:textSize 指定文字的大小&#…...
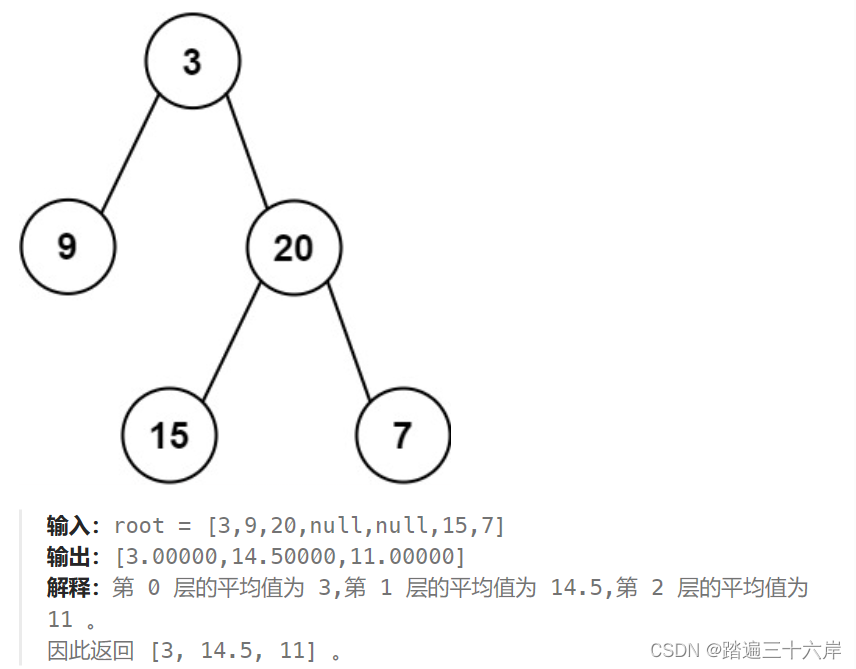
637. 二叉树的层平均值
描述 : 给定一个非空二叉树的根节点 root , 以数组的形式返回每一层节点的平均值。与实际答案相差 10-5 以内的答案可以被接受。 题目 : 637. 二叉树的层平均值 分析 : 这个题和前面的几个一样,只不过是每层都先将元素保存下来,最后求平均就行了: 解…...
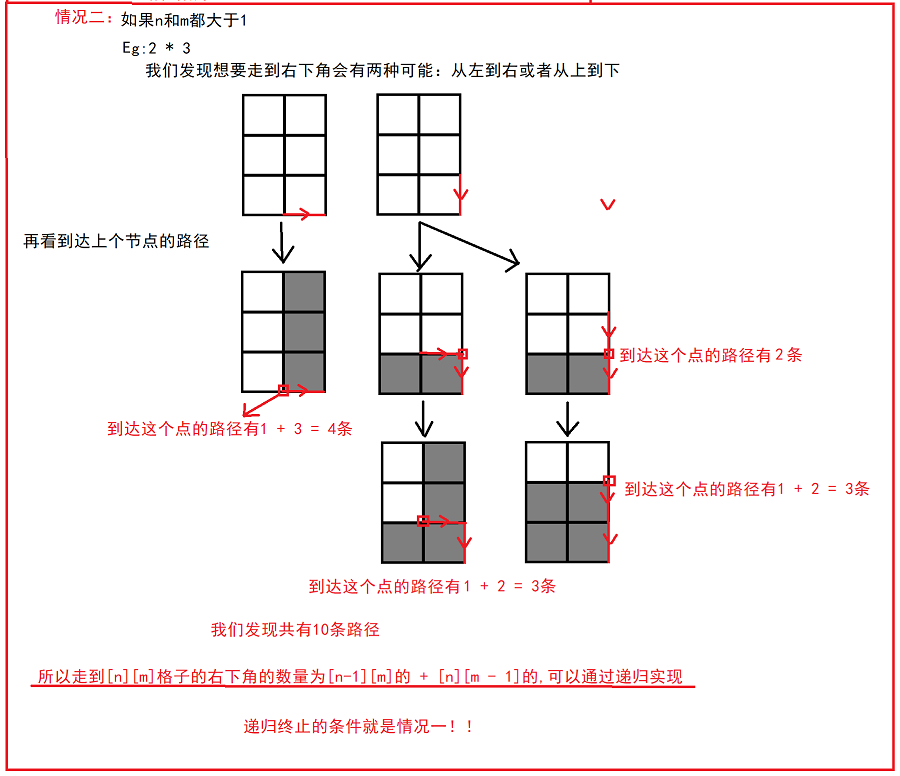
【Java笔试强训】Day9(CM72 另类加法、HJ91 走方格的方案数)
CM72 另类加法 链接:另类加法 题目: 给定两个int A和B。编写一个函数返回AB的值,但不得使用或其他算数运算符。 题目分析: 代码实现: package Day9;public class Day9_1 {public int addAB(int A, int B) {// wr…...

从Bayer到4 Cell:手把手解析手机Sensor像素排列的演进与Remosaic算法
从Bayer到4 Cell:手机Sensor像素排列的演进与Remosaic算法深度解析 当你在夜晚用手机拍摄城市灯光时,是否注意到画面中那些若隐若现的噪点?而白天拍摄时,同样的手机却能捕捉到惊人的细节。这背后隐藏着手机影像传感器近十年来最关…...

隐私安全第一!用HY-MT1.5-7B搭建本地翻译服务,完整教程分享
隐私安全第一!用HY-MT1.5-7B搭建本地翻译服务,完整教程分享 在数据隐私日益受到重视的今天,你是否还在为翻译敏感文档而担忧?无论是企业内部的技术文档、法律合同,还是涉及个人隐私的沟通内容,将文本上传到…...
)
别再死记公式了!用奇偶模分析法手把手拆解平行耦合微带线(附Python仿真验证)
奇偶模分析法:像庖丁解牛一样拆解平行耦合微带线 记得刚入行射频设计时,面对平行耦合微带线的网络参量分析,那些复杂的矩阵公式让我头疼不已。直到导师告诉我:"别急着背公式,先理解奇偶模分析法的精髓——它就像庖…...

Obsidian知识图谱可视化:Smart Connections Visualizer插件深度解析
1. 项目概述:为你的知识库装上“关系雷达” 如果你和我一样,是个重度 Obsidian 用户,并且已经用上了强大的 Smart Connections 插件来挖掘笔记间的智能关联,那你一定体会过那种感觉:面对一个笔记,你知道它…...
)
从RTSP到Web浏览器:手把手教你用FFmpeg+Nginx搭建低延迟视频流媒体服务器(SpringBoot+Vue3调用示例)
构建企业级低延迟视频流媒体平台:FFmpegNginx全链路技术解析 在智能安防、远程医疗和工业物联网等实时性要求严苛的场景中,如何将传统监控设备的RTSP流稳定、高效地传输到Web浏览器,是许多开发者面临的技术挑战。本文将深入剖析基于FFmpegNgi…...

我的世界开服神器!土豆互联公益免费 4H8G 面板服太香了
我的世界开服神器!土豆互联公益免费 4H8G 面板服太香了 经常玩我的世界的小伙伴应该都知道,想要和好朋友一起联机游玩,自建服务器是最好的选择。但市面上的服务器要么价格昂贵,要么免费配置极低,运行大型模组整合包就…...

【深度解析】AI Design-to-Code 工作流:从视觉概念到可运行前端原型
摘要 Claude Design 与新版 Codex 代表了 AI 设计工具的新方向:不再停留于图片生成,而是将视觉概念、界面代码、响应式适配和迭代优化连接成完整开发链路。本文结合实战代码,解析 Design-to-Code 的核心流程。 背景介绍:AI 设计工…...

PEMFC水淹膜干故障深度诊断【附代码】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,查看文章底部二维码(1)基于FLUENT的多物理场仿真与故障数据集构建&#x…...

为什么你的Python桌面App启动要8秒?这7个编译期优化开关,让冷启时间压进1.2秒内!
更多请点击: https://intelliparadigm.com 第一章:Python跨端应用编译优化概览 Python 作为解释型语言,天然面临跨平台部署时的性能与体积挑战。当面向桌面(Windows/macOS/Linux)、移动(Android/iOS&#…...

Windows 11终极优化指南:用Win11Debloat快速清理系统并提升性能
Windows 11终极优化指南:用Win11Debloat快速清理系统并提升性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutt…...