MapReduce小试牛刀
部署完hadoop单机版后,试下mapreduce是怎么分析处理数据的
Word Count
Word Count 就是"词语统计",这是 MapReduce 工作程序中最经典的一种。它的主要任务是对一个文本文件中的词语作归纳统计,统计出每个出现过的词语一共出现的次数。
Hadoop 中包含了许多经典的 MapReduce 示例程序,其中就包含 Word Count.
准备演示文件input.txt
# cat input.txt
I LOVE GG
I LIKE YY
I LOVE UU
I LIKE RR复制input.txt至hadoop中
# hdfs dfs -put input.txt /test
# hdfs dfs -ls /test
Found 4 items
drwxr-xr-x - yunwei supergroup 0 2023-02-24 17:14 /test/a
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:25 /test/b.txt
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:21 /test/hello-hadoop.txt
-rw-r--r-- 2 yunwei supergroup 40 2023-02-27 15:59 /test/input.txt查看hadoop下的mapreduce包
# ll $HADOOP_HOME/share/hadoop/mapreduce/
total 4876
-rw-rw-r-- 1 yunwei yunwei 526732 Oct 3 2016 hadoop-mapreduce-client-app-2.6.5.jar
-rw-rw-r-- 1 yunwei yunwei 686773 Oct 3 2016 hadoop-mapreduce-client-common-2.6.5.jar
-rw-rw-r-- 1 yunwei yunwei 1535776 Oct 3 2016 hadoop-mapreduce-client-core-2.6.5.jar
-rw-rw-r-- 1 yunwei yunwei 259326 Oct 3 2016 hadoop-mapreduce-client-hs-2.6.5.jar
-rw-rw-r-- 1 yunwei yunwei 27489 Oct 3 2016 hadoop-mapreduce-client-hs-plugins-2.6.5.jar
-rw-rw-r-- 1 yunwei yunwei 61309 Oct 3 2016 hadoop-mapreduce-client-jobclient-2.6.5.jar
-rw-rw-r-- 1 yunwei yunwei 1514166 Oct 3 2016 hadoop-mapreduce-client-jobclient-2.6.5-tests.jar
-rw-rw-r-- 1 yunwei yunwei 67762 Oct 3 2016 hadoop-mapreduce-client-shuffle-2.6.5.jar
-rw-rw-r-- 1 yunwei yunwei 292710 Oct 3 2016 hadoop-mapreduce-examples-2.6.5.jar
drwxrwxr-x 2 yunwei yunwei 4096 Oct 3 2016 lib
drwxrwxr-x 2 yunwei yunwei 30 Oct 3 2016 lib-examples
drwxrwxr-x 2 yunwei yunwei 4096 Oct 3 2016 sourcesvi hadoop-mapreduce-examples-2.6.5.jar
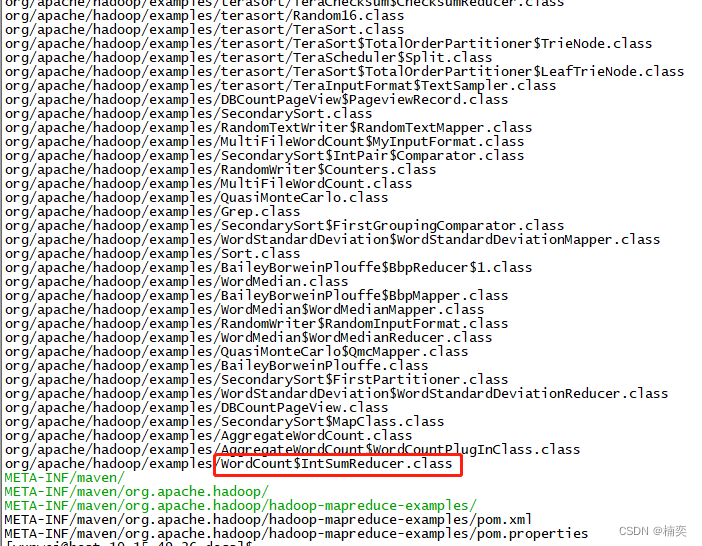
hadoop的命令执行jar
# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar WordCount input.txt output
Unknown program 'WordCount' chosen.
Valid program names are:aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.dbcount: An example job that count the pageview counts from a database.distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.grep: A map/reduce program that counts the matches of a regex in the input.join: A job that effects a join over sorted, equally partitioned datasetsmultifilewc: A job that counts words from several files.pentomino: A map/reduce tile laying program to find solutions to pentomino problems.pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.randomwriter: A map/reduce program that writes 10GB of random data per node.secondarysort: An example defining a secondary sort to the reduce.sort: A map/reduce program that sorts the data written by the random writer.sudoku: A sudoku solver.teragen: Generate data for the terasortterasort: Run the terasortteravalidate: Checking results of terasortwordcount: A map/reduce program that counts the words in the input files.wordmean: A map/reduce program that counts the average length of the words in the input files.wordmedian: A map/reduce program that counts the median length of the words in the input files.wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.执行报错,虽然example.jar中有这个WordCount类,但填下类名没起作用。改为小写后,继续执行,报错。hdfs的目录下没有这个文件,将input.txt文件上传至hadoop中。
# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount input.txt output
23/02/27 15:58:58 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
23/02/27 15:58:58 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
23/02/27 15:58:58 INFO mapreduce.JobSubmitter: Cleaning up the staging area file:/tmp/hadoop-yunwei/mapred/staging/yunwei293247600/.staging/job_local293247600_0001
org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://10.15.49.26:8020/user/yunwei/input.txtat org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:321)at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:264)at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:385)at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:302)at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:319)at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:197)at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1297)at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1294)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1692)at org.apache.hadoop.mapreduce.Job.submit(Job.java:1294)at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1315)at org.apache.hadoop.examples.WordCount.main(WordCount.java:87)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71)at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.hadoop.util.RunJar.run(RunJar.java:221)at org.apache.hadoop.util.RunJar.main(RunJar.java:136)# hdfs dfs -put input.txt /test
# hdfs dfs -ls /test
# hdfs dfs -put input.txt /test
# hdfs dfs -ls /test
Found 4 items
drwxr-xr-x - yunwei supergroup 0 2023-02-24 17:14 /test/a
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:25 /test/b.txt
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:21 /test/hello-hadoop.txt
-rw-r--r-- 2 yunwei supergroup 40 2023-02-27 15:59 /test/input.txt# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /test/input.txt output
解释一下含义:
hadoop jar从 jar 文件执行 MapReduce 任务,之后跟着的是示例程序包的路径。
wordcount表示执行示例程序包中的 Word Count 程序,之后跟这两个参数,第一个是输入文件,第二个是输出结果的目录名(因为输出结果是多个文件)。
执行之后,应该会输出一个文件夹 output,在这个文件夹里有两个文件:_SUCCESS 和 part-r-00000。
/test/output 上面命令如果指定output在hadoop的路径,相关执行结果便不会生成在默认位置,而是命令指定的位置。
其中 _SUCCESS 只是用于表达执行成功的空文件,part-r-00000 则是处理结果,当我们显示一下它的内容:
指定到hadoop目录下的input.txt文件
# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /test/input.txt output
23/02/27 16:00:13 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
23/02/27 16:00:13 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
23/02/27 16:00:13 INFO input.FileInputFormat: Total input paths to process : 1
23/02/27 16:00:13 INFO mapreduce.JobSubmitter: number of splits:1
23/02/27 16:00:13 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1519269801_0001
23/02/27 16:00:13 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
23/02/27 16:00:13 INFO mapreduce.Job: Running job: job_local1519269801_0001
23/02/27 16:00:13 INFO mapred.LocalJobRunner: OutputCommitter set in config null
23/02/27 16:00:13 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
23/02/27 16:00:13 INFO mapred.LocalJobRunner: Waiting for map tasks
23/02/27 16:00:13 INFO mapred.LocalJobRunner: Starting task: attempt_local1519269801_0001_m_000000_0
23/02/27 16:00:13 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
23/02/27 16:00:13 INFO mapred.MapTask: Processing split: hdfs://10.15.49.26:8020/test/input.txt:0+40
23/02/27 16:00:14 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
23/02/27 16:00:14 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
23/02/27 16:00:14 INFO mapred.MapTask: soft limit at 83886080
23/02/27 16:00:14 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
23/02/27 16:00:14 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
23/02/27 16:00:14 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
23/02/27 16:00:14 INFO mapred.LocalJobRunner:
23/02/27 16:00:14 INFO mapred.MapTask: Starting flush of map output
23/02/27 16:00:14 INFO mapred.MapTask: Spilling map output
23/02/27 16:00:14 INFO mapred.MapTask: bufstart = 0; bufend = 88; bufvoid = 104857600
23/02/27 16:00:14 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214352(104857408); length = 45/6553600
23/02/27 16:00:14 INFO mapred.MapTask: Finished spill 0
23/02/27 16:00:14 INFO mapred.Task: Task:attempt_local1519269801_0001_m_000000_0 is done. And is in the process of committing
23/02/27 16:00:14 INFO mapred.LocalJobRunner: map
23/02/27 16:00:14 INFO mapred.Task: Task 'attempt_local1519269801_0001_m_000000_0' done.
23/02/27 16:00:14 INFO mapred.LocalJobRunner: Finishing task: attempt_local1519269801_0001_m_000000_0
23/02/27 16:00:14 INFO mapred.LocalJobRunner: map task executor complete.
23/02/27 16:00:14 INFO mapred.LocalJobRunner: Waiting for reduce tasks
23/02/27 16:00:14 INFO mapred.LocalJobRunner: Starting task: attempt_local1519269801_0001_r_000000_0
23/02/27 16:00:14 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
23/02/27 16:00:14 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@5cd45799
23/02/27 16:00:14 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=334338464, maxSingleShuffleLimit=83584616, mergeThreshold=220663392, ioSortFactor=10, memToMemMergeOutputsThreshold=10
23/02/27 16:00:14 INFO reduce.EventFetcher: attempt_local1519269801_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
23/02/27 16:00:14 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1519269801_0001_m_000000_0 decomp: 68 len: 72 to MEMORY
23/02/27 16:00:14 INFO reduce.InMemoryMapOutput: Read 68 bytes from map-output for attempt_local1519269801_0001_m_000000_0
23/02/27 16:00:14 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 68, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->68
23/02/27 16:00:14 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
23/02/27 16:00:14 INFO mapred.LocalJobRunner: 1 / 1 copied.
23/02/27 16:00:14 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
23/02/27 16:00:14 INFO mapred.Merger: Merging 1 sorted segments
23/02/27 16:00:14 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 63 bytes
23/02/27 16:00:14 INFO reduce.MergeManagerImpl: Merged 1 segments, 68 bytes to disk to satisfy reduce memory limit
23/02/27 16:00:14 INFO reduce.MergeManagerImpl: Merging 1 files, 72 bytes from disk
23/02/27 16:00:14 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
23/02/27 16:00:14 INFO mapred.Merger: Merging 1 sorted segments
23/02/27 16:00:14 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 63 bytes
23/02/27 16:00:14 INFO mapred.LocalJobRunner: 1 / 1 copied.
23/02/27 16:00:14 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
23/02/27 16:00:14 INFO mapred.Task: Task:attempt_local1519269801_0001_r_000000_0 is done. And is in the process of committing
23/02/27 16:00:14 INFO mapred.LocalJobRunner: 1 / 1 copied.
23/02/27 16:00:14 INFO mapred.Task: Task attempt_local1519269801_0001_r_000000_0 is allowed to commit now
23/02/27 16:00:14 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1519269801_0001_r_000000_0' to hdfs://xx.xx.xx.xx:xx/user/yunwei/output/_temporary/0/task_local1519269801_0001_r_000000
23/02/27 16:00:14 INFO mapred.LocalJobRunner: reduce > reduce
23/02/27 16:00:14 INFO mapred.Task: Task 'attempt_local1519269801_0001_r_000000_0' done.
23/02/27 16:00:14 INFO mapred.LocalJobRunner: Finishing task: attempt_local1519269801_0001_r_000000_0
23/02/27 16:00:14 INFO mapred.LocalJobRunner: reduce task executor complete.
23/02/27 16:00:14 INFO mapreduce.Job: Job job_local1519269801_0001 running in uber mode : false
23/02/27 16:00:14 INFO mapreduce.Job: map 100% reduce 100%
23/02/27 16:00:14 INFO mapreduce.Job: Job job_local1519269801_0001 completed successfully
23/02/27 16:00:14 INFO mapreduce.Job: Counters: 38File System CountersFILE: Number of bytes read=585924FILE: Number of bytes written=1105104FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=80HDFS: Number of bytes written=38HDFS: Number of read operations=13HDFS: Number of large read operations=0HDFS: Number of write operations=4Map-Reduce FrameworkMap input records=4Map output records=12Map output bytes=88Map output materialized bytes=72Input split bytes=103Combine input records=12Combine output records=7Reduce input groups=7Reduce shuffle bytes=72Reduce input records=7Reduce output records=7Spilled Records=14Shuffled Maps =1Failed Shuffles=0Merged Map outputs=1GC time elapsed (ms)=0CPU time spent (ms)=0Physical memory (bytes) snapshot=0Virtual memory (bytes) snapshot=0Total committed heap usage (bytes)=716177408Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=40File Output Format Counters Bytes Written=38查看执行结果,从上面执行的日志中,可以看到output文件生成的位置信息

执行之后,应该会输出一个文件夹 output,在这个文件夹里有两个文件:_SUCCESS 和 part-r-00000。
其中 _SUCCESS 只是用于表达执行成功的空文件,part-r-00000 则是处理结果
# hdfs dfs -lsr /user/yunwei
lsr: DEPRECATED: Please use 'ls -R' instead.
drwxr-xr-x - yunwei supergroup 0 2023-02-27 16:00 /user/yunwei/output
-rw-r--r-- 2 yunwei supergroup 0 2023-02-27 16:00 /user/yunwei/output/_SUCCESS
-rw-r--r-- 2 yunwei supergroup 38 2023-02-27 16:00 /user/yunwei/output/part-r-00000hdfs dfs -cat /user/yunwei/output/part-r-00000
# hdfs dfs -cat /user/yunwei/output/part-r-00000
GG 1
I 4
LIKE 2
LOVE 2
RR 1
UU 1
YY 1相关文章:
MapReduce小试牛刀
部署完hadoop单机版后,试下mapreduce是怎么分析处理数据的 Word Count Word Count 就是"词语统计",这是 MapReduce 工作程序中最经典的一种。它的主要任务是对一个文本文件中的词语作归纳统计,统计出每个出现过的词语一共出现的次…...

2023年全国最新工会考试精选真题及答案7
百分百题库提供工会考试试题、工会考试预测题、工会考试真题、工会证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 21.会员大会或会员代表大会与职工代表大会或职工大会须分别行使职权,()…...
13-mvc框架原理与实现方式
1、mvc原理 # mvc 与框架## 1.mvc 是什么1. m:model,模型(即数据来源),主要是针对数据库操作 2. v:view,视图,html 页面。视图由一个一个模板构成(模板是视图的一个具体展现或载体,视图是模板的一个抽象) 3. c:controller,控制器,用于mv之间的数据交互## 2.最简单的 mvc 就是一…...

弹性盒子布局
目录一、弹性盒子属性二、认识flex的坐标轴三、简单学习父级盒子属性三、属性说明3.1、flex-grow一、弹性盒子属性 说明: div的默认样式:display:block 块盒子 display:flex弹性盒子(可以控制下级盒子的位置) 当两种盒子单独出现…...
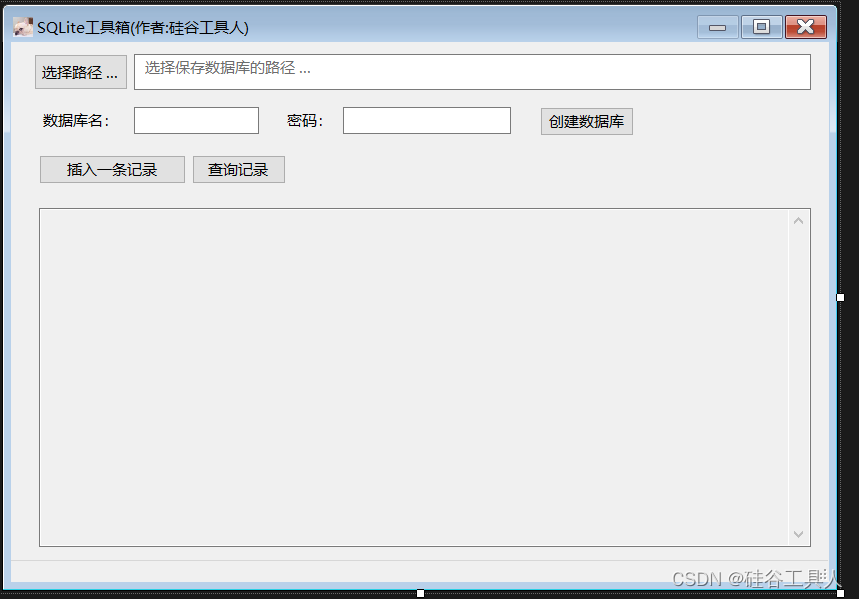
C# Sqlite数据库加密
sqlite官方的数据库加密是收费的,而且比较贵。 幸亏微软提供了一种免费的方法。 1 sqlite加密demo 这里我做了一个小的demo演示如下: 在界面中拖入数据库名、密码、以及保存的路径 比如我选择保存路径桌面的sqlite目录,数据库名guigutool…...

高压放大器在声波谐振电小天线收发测试系统中的应用
实验名称:高压放大器在声波谐振电小天线收发测试系统中的应用研究方向:信号传输测试目的:声波谐振电小天线颠覆了传统电小天线以电磁波谐振作为理论基础的天线发射和接收模式,它借助声波谐振实现电磁信号的辐射或接收。因为同频的…...
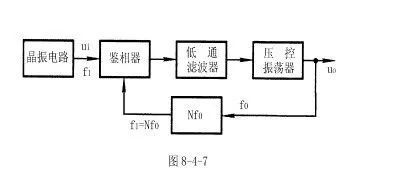
锁相环的组成和原理及应用
一.锁相环的基本组成 许多电子设备要正常工作,通常需要外部的输入信号与内部的振荡信号同步,利用锁相环路就可以实现这个目的。 锁相环路是一种反馈控制电路,简称锁相环(PLL)。锁相环的特点是:利用外部输入的参考信号控制环路内…...

[C++]string类模拟实现
目录 前言: 1. string框架构造 2. 默认函数 2.1 构造函数 2.2 析构函数 2.3 拷贝构造 2.4 赋值重载 3. 迭代器 4. 整体程序 前言: 本篇文章模拟实现了C中string的部分功能,有助于大家了解和熟悉string类,虽然这个类不难实…...

一个更适合Java初学者的轻量级开发工具:BlueJ
Java是世界上最流行的编程语言之一,它被广泛用于从Web开发到移动应用的各种应用程序。大部分Java工程师主要是用IDEA、Eclipse为主,这两个开发工具由于有强大的能力,所以复杂度上就更高一些。如果您刚刚开始使用Java,或者您更适合…...

从程序员到项目组长,要经历六重修炼
最近和粉丝朋友们交流时发现,有很多刚刚开始做项目组长的朋友自我认可度非常低,感觉做组长之后天天打杂,技术也荒废了。领导天天找你要成果,下属天天找你说困难,你在中间受领导和下属的夹板气。时间久了,你…...

我的 System Verilog 学习记录(5)
、 引言 本文简单介绍 System Verilog 语言的 控制流。 前文链接: 我的 System Verilog 学习记录(1) 我的 System Verilog 学习记录(2) 我的 System Verilog 学习记录(3) 我的 System Ver…...

多芯片设计 Designing For Multiple Die
Why a system-level approach is essential, and why its so challenging作者:Ann MutschlerAnn Mutschler is executive editor at Semiconductor Engineering.将多个裸片或芯粒集成到一个封装中,与将它们放在同一硅片上有着很大的区别。在同一硅片上&a…...
2022年全国职业院校技能大赛(中职组)网络安全竞赛试题A(10)
目录 竞赛内容 模块A 基础设施设置与安全加固 一、项目和任务描述: 二、服务器环境说明 三、具体任务(每个任务得分以电子答题卡为准) A-1任务一 登录安全加固(Windows, Linux) 1.密码策略(Windows, …...

数据结构-简介
目录 1、简介 2、作用 3、分类 4、实现分类 1、简介 数据结构指的是组织和存储数据的方法。它涉及到一系列的算法和原则,用来设计和实现不同种类的数据类型,如数组、链表、树、图等等。数据结构的目的是在计算机程序中有效地管理和操作数据ÿ…...

python装饰器及其用法
python装饰器是什么? Python装饰器是一种语法结构,它可以让开发者在不修改原函数的基础上,在函数的前后运行额外的代码,这些代码可以达到修改函数行为的目的。Python装饰器的实质是一个可调用的对象,它可以接收函数作为参数…...

Appium自动化测试之启动时跳过初始化设置
Appium每次启动时都会检查和安装Appium Settings,这是完全没有必要的,在首次使用Appium连接设备是Appium Settings便已经安装好。怎样跳过安装Appium Settings呢?之前的做法是修改appium中的源文件中的android-helpers.js实现,如M…...

JavaScript DOM【快速掌握知识点】
目录 DOM简介 获取元素 修改元素 添加和移除元素 事件处理 DOM简介 JavaScript DOM 是指 JavaScript 中的文档对象模型(Document Object Model);它允许 JavaScript 与 HTML 页面交互,使开发者可以通过编程方式动态地修改网页…...
不需要高深技术,只需要Python:创建一个可定制的HTTP服务器!
目录 1、编写服务端代码,命名为httpserver.py文件。 2、编写网页htmlcss文件,命名为index.html和style.css文件。 3、复制htmlcss到服务端py文件同一文件夹下。 4、运行服务端程序。 5、浏览器中输入localhost:8080显示如下: 要编写一个简单的能发布…...

渗透测试常用浏览器插件汇总
1、shodan这个插件可以自动探测当前网站所属的国家、城市,解析IP地址以及开放的服务和端口,包括但不限于FTP、DNS、SSH或者其他服务等,属被动信息搜集中的一种。2、hackbar(收费之后用Max Hackerbar代替)这个插件可用于…...
社区1月月报|OceanBase 4.1 即将发版,哪些功能将会更新?
我们每个月都会和大家展开一次社区进展的汇报沟通会,希望通过更多的互动交流让OceanBase 开源社区更加透明,实现信息共享,也希望能营造更加轻松的氛围,为大家答疑解惑,让大家畅所欲言。如果您对我们的社区有任何建议&a…...

如何用LeetDown实现iOS设备降级?3个步骤轻松搞定
如何用LeetDown实现iOS设备降级?3个步骤轻松搞定 【免费下载链接】LeetDown a GUI macOS Downgrade Tool for A6 and A7 iDevices 项目地址: https://gitcode.com/gh_mirrors/le/LeetDown 还在为老旧iOS设备升级后卡顿烦恼吗?想让iPhone 5s或iPad…...

PlayCover 2.0重构Mac游戏体验:社交与云服务双引擎驱动革新
PlayCover 2.0重构Mac游戏体验:社交与云服务双引擎驱动革新 【免费下载链接】PlayCover Community fork of PlayCover 项目地址: https://gitcode.com/gh_mirrors/pl/PlayCover 在Mac平台运行iOS游戏长期面临两大痛点:缺乏社交连接与跨设备数据同…...

wan2.1-vae中英文双语支持实测:中文提示词准确率92%+英文prompt兼容性验证
wan2.1-vae中英文双语支持实测:中文提示词准确率92%英文prompt兼容性验证 1. 平台核心能力解析 wan2.1-vae是基于Qwen-Image-2512模型的AI图像生成平台,其最大特色在于原生支持中英文双语提示词。在实际测试中,中文提示词的理解准确率达到9…...

OpenClaw效率对比:GLM-4.7-Flash与云端API实测数据
OpenClaw效率对比:GLM-4.7-Flash与云端API实测数据 1. 测试背景与动机 上周在优化个人自动化工作流时,我遇到了一个实际选择难题:应该用本地部署的GLM-4.7-Flash模型,还是继续使用云端API服务?这个问题看似简单&…...

JSON·学习笔记
“误报。我的安全阀一切正常。” “我们继续,今天我想解释一下什么是JSON。” “是啊,这个词我听过很多次了,什么意思?” “随着网络的发展,带有 JavaScript 的 HTML 页面开始主动与服务器通信并从服务器下载数据。为…...

告别龟速下载:用阿里云镜像源5分钟搞定CentOS 8 Stream + 宝塔面板环境
极速部署CentOS 8 Stream与宝塔面板:阿里云镜像实战指南 每次在服务器上配置环境时,最让人抓狂的就是漫长的等待时间。特别是当需要从国外官方源下载安装包时,那个进度条简直像蜗牛爬行。我曾经花了整整一个下午只为安装基础环境,…...

嵌入式AI边缘计算原型:STM32与云端PyTorch模型协同工作流设计
嵌入式AI边缘计算原型:STM32与云端PyTorch模型协同工作流设计 1. 场景需求与痛点分析 在智能家居、工业监测等物联网场景中,我们常常遇到这样的矛盾:边缘设备需要实时响应,但计算能力有限;云端算力强大,但…...

还在手工整理IT报表?这套自动化模板让你彻底解放双手
在不断变化的IT管理环境中,透明度和合规性已成为企业生存和发展的基石。面对日益繁杂的法规与标准,组织需要精细的报表与审计流程来支撑业务稳健运行。作为一款专为现代IT打造的尖端平台,Endpoint Central不仅大幅减轻了合规负担,…...

《先测量,再优化:写给 Python 开发者的性能实战指南——别让“聪明优化”变成昂贵自嗨》
《先测量,再优化:写给 Python 开发者的性能实战指南——别让“聪明优化”变成昂贵自嗨》 很多 Python 开发者都会经历这样一个阶段:项目一慢,第一反应就是“这段代码得优化”;一看到 for 循环,就想换成列表…...

企业内部是否需要技术团队做小程序
企业内部是否需要技术团队做小程序一、企业在推进小程序时的现实问题在实际业务中,越来越多企业开始考虑通过小程序拓展线上渠道,但在推进过程中,往往会遇到一个核心问题:企业内部是否需要组建技术团队来完成小程序开发。这一问题…...